ua cac technews s - nsfcac.arizona.edunsfcac.arizona.edu/docs/cac_tech-news-issue-final-2.pdf · ua...
TRANSCRIPT

Fall 2008
UA CAC Technews UA CAC Technews UA CAC Technews
Inside this issue
About the center ........................ 1
Letter From Director................... 2
Autonomic Computing: The Next Era to Design Self* Systems and Applications................................ 3
A Physics Aware Programming Paradigm .................................... 4
Scale‐Right Provisioning for Next Generation Datacenters ............. 8
Autonomic Performance/Power Optimizations in Next Generation Datacenters ................................ 9
On Going Projects ......................11
About the Center Autonomic Computing (AC) refers to a broad range of scientific and engineering R&D on
methods, architectures and technologies for the design, implementation, integration and evaluation of special‐ and general‐purpose computing systems, components and applications Such systems aim to self‐govern and self‐manage themselves in order to minimize cost and risk, accommodate complexity and uncertainty or enable systems of systems with large numbers of components. This has been the mission of the NSF Industry/University Cooperative Center for Autonomic Computing (NSF CAC) with three major universities (Florida, Arizona and Rutgers, the State University of New Jersey) and more than twenty companies and governmental agencies. CAC research activities will advance several disciplines that impact the specification, design, engineering and integration of AC and information processing systems. They include design and evaluation methods, algorithms, architectures, information processing, software, mathematical foundations and benchmarks for autonomic systems. Solutions will be studied at different levels of both centralized and distributed systems, including the hardware, networks, storage, middleware, services and information layers. Collectively, the participating universities have research and education programs whose strengths cover the technical areas of the center. Within this broad scope, the specific research activities will vary over time as a reflection of center’s member needs and the evolution of the AC field.
Volume 1, Issue 1 Visit our website: http://nsfcac.arizona.edu

needed to establish, maintain and operate large IT infrastructures. Autonomic Computing (AC) models IT infrastructures and their applications as closed‐loop control systems that need to be continuously monitored, analyzed followed by corrective actions when‐ ever any of the desired behavior properties (e.g., performance, fault, security) are violated. Such AC techniques are inspired by strategies used by biological systems to deal with complexity, dynamism, heterogeneity and uncertainty. The design space for de‐ signing AC systems spans multiple disciplines such as distributed computing, virtualization, control theory, artificial intelligence, statistics, software architectures, mathematical programming, and networking. Our research efforts will accelerate the research and development of core autonomic technologies and services. It will also establish strong collaboration programs with the US IT indus‐ try, specifically the Arizona IT industry (e.g. IBM, Raytheon, Intel and Avirtec) to develop next generation information and communi‐ cation technologies and services that are inherently Autonomic.
In this newsletter, we highlight our ongoing autonomic research activities and how to apply them to wide range of applications/ domains with profound impact on economy and industry such as Autonomic Management of IT infrastructure (specifically perform‐ ance/power of large‐scale datacenters, network defense system, survivable systems and services, and control and management of Wireless networks), Autonomic Scientific/Engineering Applications (specifically accelerating the research and discovery of grand challenges water and climate issues, optimizing the design and engineering of net‐centric weapon systems), and Autonomic health‐ care systems and services.
In summary, the NSF‐CAC will not only advance the science of autonomic computing, but also accelerate the transfer of tech‐ nolo0gy to industry and contribute to the education of a workforce capable of designing and deploying autonomic computing sys‐ tems to many sectors‐‐‐from homeland security and defense, to business agility to the global change science. Furthermore, the cen‐ ter will leave its mark on the education and training of a new generation of scientists that have the skills and know‐how to create knowledge in new transformative ways.
As we move forward, we would like to invite you to join the center so together we can develop innovative autonomic technolo‐ gies and services that will revolutionize how to design and deploy next generation information and communications services.
Salim Hariri, Director UA NSF Center for Autonomic Computing
“The mission of the NSF‐CAC is to advance the knowledge of designing Information Technology systems & services to make them self‐governed and self‐managed”
Letter From The Director It is my pleasure to introduce to you the
National Science Foundation Center for Auto‐ nomic Computing (NSF CAC) ‐ a center funded through the NSF Industry/University Coopera‐ tive Research Centers program, industry, gov‐ ernment agencies and matching funds from member universities, which currently include the University of Florida (Lead), the University of Arizona and Rutgers, The State University of New Jersey. The mission of the center is to ad‐ vance the knowledge of designing Information Technology (IT) systems and services to make them self‐governed and self‐managed. This will be achieved through developing innovative
designs, programming paradigms and capabili‐ ties for computing systems.
The explosive growth of IT infrastructures, coupled with the diversity of their components and a shortage of skilled IT workers, have re‐ sulted in systems whose control and timely management exceeds human ability. Current IT management solutions are costly, ineffective and labor intensive. According to estimates by the International Data Corporation (IDC), worldwide costs of server management and administration will reach approximately US $150 Billion by 2010 and are estimated to rep‐ resent more than 60% of the total spending
2

Autonomic Computing: The Next Era to Designing Self* Systems and Applications
by Salim Hariri by Salim Hariri by Salim Hariri Advances in computing and communication technologies and software tools have resulted in
an explosive growth in networked‐applications and information services that cover all aspects of our life. These services and applications are inherently complex, dynamic and heterogeneous. Similarly, the underlying information infrastructures such as the Internet are complex, heterogeneous and dynamic. This combination exacerbates complexities related to application development, configuration and man‐ agement, and makes current computing paradigms brittle and inefficient. As a result, applications, pro‐ gramming environments and information infrastructures are rapidly becoming unmanageable, insecure and inefficient when handling runtime changes. This has led researchers to consider alternative pro‐
gramming paradigms and management techniques that are based on strategies used by biological systems to deal with complexity, dynamism, heterogeneity and uncertainty.
Autonomic computing is inspired by the human autonomic nervous system that handles complexity and uncertainties, and aims at realizing computing systems and applications capable of managing themselves with minimum human intervention. In this paper we first give an overview of the architecture of the autonomic nervous system and use it to motivate our approach to develop the autonomic computing paradigm. We then illustrate how this paradigm can be used to control and manage complex applications.
The Need for Integration and Automation The control and management of computing systems have evolved from an environment in which a single process running on a
computer system to a large, complex and dynamic environment in which multiple processes running on geographically dispersed heterogeneous computers that could span several continents (e.g., Grid). The techniques to design computing systems and services that meet their requirements have been mainly ad hoc. Initially, designers focused on developing effi‐ cient parallel processing and high performance architecture to improve system and application performance. As the deployment of computing systems and applications spread to many areas, especially those where failures can be catastrophic and life threatening, the reliability and avail‐ ability of such systems and applications become a major concern. This requirement has driven separate research activities that have focused on reliability and fault tolerance computing. In a similar manner, the re‐ search in computing security has mainly addressed the needs to protect the integrity and the confidentiality of computing systems and their ser‐ vices without consideration to other important system attributes such as performance, reliability, and configuration. Consequently, this has lead to the development of specialized and isolated computing systems and applications that can efficiently optimize a few of the system attributes or functionalities, but not all of them.
However, next generation computing systems and applications need to run fast, reliably, securely and cost‐effectively. The ad‐ hoc integration (Figure 1) of the techniques that have been developed to manage performance, security, and fault‐tolerance results in systems that are costly, insecure and unmanageable, as actions performed by the security engines, for example, might cancel ac‐ tions taken by high performance computing engines. Furthermore, the performance, security and fault tolerance requirements of such systems and applications might change continuously at runtime. Hence, it is essentially critical for next generation computing systems and/or software architectures to be holistic in addressing systems and applications requirements, which needs to be done in
3
Figure 1: Integration of isolated solutions is inefficient, costly, inse‐ cure and unmanageable.

integrated and timely manners. The complexity, heterogeneity and dynamism of networked systems and their applications have re‐ sulted into systems whose control and timely management exceeds human ability.
Autonomic Components and Systems This has led researchers to consider alternative design paradigms and management techniques that are based on strategies used
by biological systems to deal with complexity, dynamism, heterogeneity and uncertainty – a vision that has been referred to as auto‐ nomic computing. Autonomic computing is inspired by the human autonomic nervous system and aims at realizing computing sys‐ tems and applications that are capable of managing themselves with minimum human intervention. There have been several efforts to characterize the main features that make a computing sys‐ tem or an application autonomic. However, most of these tech‐ niques agree that an autonomic system must at least support the following four features: 1. Self‐Protecting: Be able to detect attacks and protect its
resources from both internal and external attacks. 2. Self‐Optimizing: Be able to detect sub‐optimal behaviors
and intelligently perform self‐optimization functions. 3. Self‐Healing: Be able to detect hardware and/or software
failures and should have the ability to reconfigure itself to continue its operations in spite of failures.
4. Self‐Configuring: Be able to dynamically change the con‐ figuration of its resources in order to maintain overall sys‐ tem and application requirements. Large scale autonomic computing systems can be dynami‐
cally composed from smaller Autonomic Components (AComs) where each component supports in a seamless manner any combination of the four properties mentioned above. That means, each ACom can be dynamically and automatically con‐ figured, seamlessly tolerate any component failure, automatically detect component attacks and protect against them, and automatically change its configuration parameters to improve performance once it deteriorates beyond certain performance threshold. Once such autonomic components become available, we can dynamically build autonomic computing systems (see Figure 2) to meet any static requirements and runtime changes.
A Physics Aware Programming Paradigm by Salim Hariri and Yeliang Zhang by Salim Hariri and Yeliang Zhang by Salim Hariri and Yeliang Zhang
Large scale scientific applications generally experience different execution phases at runtime and each phase has different com‐ putational, communication and storage requirements as well as different physical characteristics. An optimal solution or numerical scheme for one execution phase might not be appropriate for the next phase of the application execution. Choosing the ideal nu‐ merical algorithms and solutions for all application runtime phases remains an active research area. A new programming methodol‐ ogy, A novel new approach to develop and implement applications based on autonomic computing principles is critically needed. Autonomic Programming (AP) paradigm enables application developers to identify the appropriate solution methods to exploit the heterogeneity and the dynamism of the application execution states. Once an application is developed based on AP paradigm, an Autonomic Runtime Manager (ARM) can then periodically monitors and analyzes the runtime characteristics of the application to identify its current execution phase (state). For each change in the application execution phase, ARM will exploit the spatial and tem‐ poral attributes of the application in the current state to identify the ideal numerical algorithms/solvers that optimize its perform‐ ance. We have evaluated this programming paradigm using a real world application (Variable Saturated Aquifer Flow and Transport (VSAFT2D)) commonly used in subsurface modeling. We evaluated the performance gain of the AP paradigm with up to 2,000,000 nodes in the computation domain implemented on 32 processors. Our experimental results show that by exploiting the application
4
Figure 2: Holistic Approach: Autonomic Computing System

physics characteristics at runtime and applying the appropriate numerical scheme with adapted spatial and temporal attributes, a significant speedup can be achieved (around 80%) and the overhead injected by ARM is negligible. We also show that the results us‐ ing AP is as accurate as the numerical solutions that use fine grid resolution.
Motivation In the domain of scientific computations, discretization of time and space is usually encountered in a large class of problems such
as hydrology underground water study, Stokes problem, thermo‐mechanical, Computational Fluid Dynamics (CFD) and Elastohydro‐ dynamic Lubrication problems. Most of these problems are solved by dividing computation domain into small grids (represented by spatial characteristics Dx, Dy and Dz) and advancing the computation in a small time step (represented by temporal characteristics Dt) until the desired results obtained. However, most of the applications are generally time dependent and their volatile nature make them hard to be solved. As time evolves, these problems will evolve into different phases with different physical characteristics. For example, in wildfire simulation, for over fifty years, attempts have been made to understand and predict the behavior (intensity, propagation speed and direction, and modes of spread) of wildfires. However, the factors that determine wildfire behavior are com‐ plex; they include fuel characteristics and configurations, chemical reactions, balances between different modes of heat transfer, t o ‐
pography, and fire/atmosphere interactions. These factors influence a fire’s behavior over a wide range of time and spatial scales while the dynamism of the problem and the complicated interactions between these factors make accurate wildfire simulation diffi‐ cult. Multiple physical phases not only exist in wildfire simulation, it also exists in forefront astronomical research such as superno‐ vae. The supernovae core‐collapse problem being modeled is inherently multi‐phased, heterogeneous (in time, space and computa‐ tional complexity) and dynamic. It involves hydrodynamics, nuclear fusion and transport phases. Each simulation phase requires dif‐ ferent computational models with computational resources and the transition from one phase to the next and the computational models applicable at each phase and their computational requirements are determined by criteria based on local state and known only at runtime.
Autonomic Programming (AP) Paradigm Most of the current execution techniques of applications use one algorithm to implement all the phases of the application execu‐
tion, but a static solution or numerical scheme for all the execution phase might not be ideal to handle the dynamism of the problem as discussed in Section 1. Some techniques use application errors to refine the solution as in Adaptive Mesh Refinement (SAMR) where the mesh size is refined to achieve a smaller error rate on particular computation domain. In this scheme, the error is used to drive the dynamic changes in the grid point size that might or might not optimize the application performance. In our AP approach, we apply a novel programming paradigm that takes into consideration the current application’s physical properties and derive spatial and temporal characteristics from such properties at runtime. In this programming paradigm, the appropriate solution that can meet the desired accuracy and improve performance will be determined for each application phase at runtime. This programming tech‐ nique is general and can be applied to Finite Element Method, Domain Decomposition Method, and Finite Volume Approximations.
For example, let us consider a Variable Saturated Aquifer Flow and Transport (VSAFT2D) application kernel developed at The University of Arizona. The major computing step in this routine is matrix solving routine. For two different hydraulic media: Slit and Sand, the routine goes through several phases, where in some phases it is possible to enlarge Dx and Dy by 10 and reduce the time step by 10 without affecting the stability of the algorithm and its accuracy. Table 1 shows the performance gains that can be obtained when that is exploited in the AP paradigm. It is clear from this Table that several order of magnitudes can be obtained by just exploit‐
5
Computational Requirements Science Driven Solution
Grid point selection Assume that there are 500,000 Gridpoints along x and y. The computational require‐ ment is (500,000x500,000) x 1000 x 1000= 25x10 16 floating point operations 10 Gflops processor
Since it’s a saturated situation, Ks and Kc are constants and Kc < Ks. We can enlarge Dx and Dy by 10 and reduce the time step by 10. Then the computational requirement i s (50,000x50,000) x100 x 1000= 25x10 13 25 10 3
Table 1
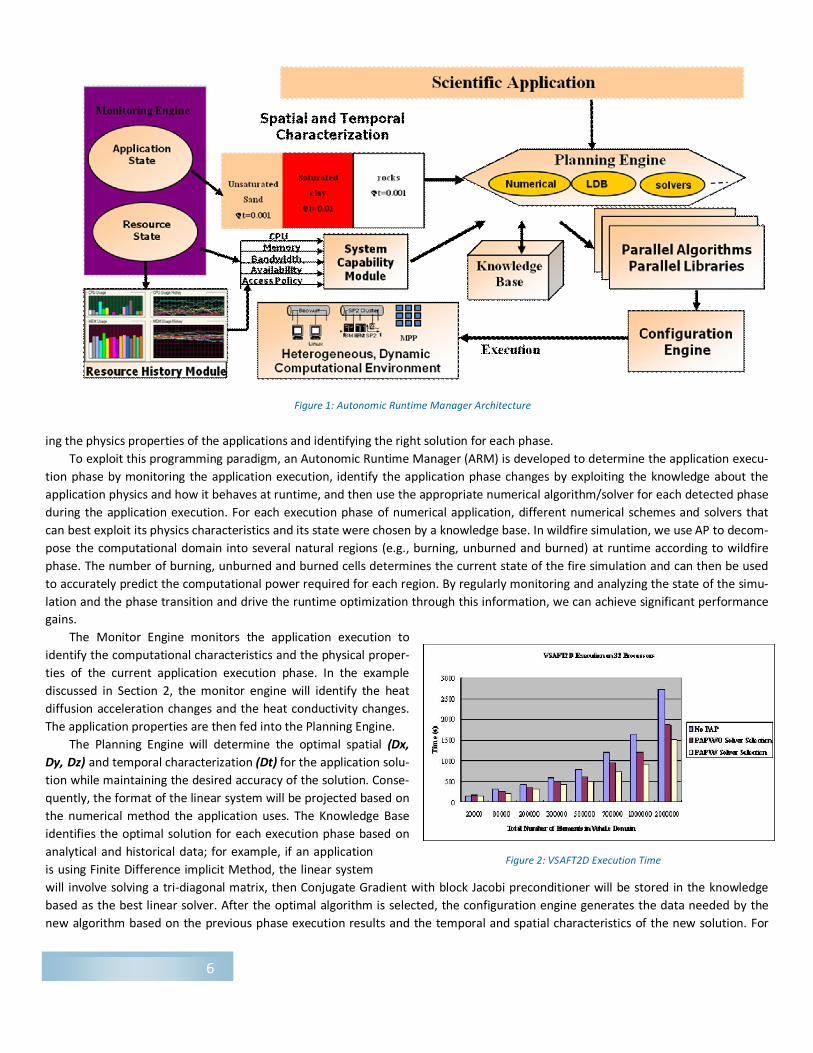
ing the physics properties of the applications and identifying the right solution for each phase. To exploit this programming paradigm, an Autonomic Runtime Manager (ARM) is developed to determine the application execu‐
tion phase by monitoring the application execution, identify the application phase changes by exploiting the knowledge about the application physics and how it behaves at runtime, and then use the appropriate numerical algorithm/solver for each detected phase during the application execution. For each execution phase of numerical application, different numerical schemes and solvers that can best exploit its physics characteristics and its state were chosen by a knowledge base. In wildfire simulation, we use AP to decom‐ pose the computational domain into several natural regions (e.g., burning, unburned and burned) at runtime according to wildfire phase. The number of burning, unburned and burned cells determines the current state of the fire simulation and can then be used to accurately predict the computational power required for each region. By regularly monitoring and analyzing the state of the simu‐ lation and the phase transition and drive the runtime optimization through this information, we can achieve significant performance gains.
The Monitor Engine monitors the application execution to identify the computational characteristics and the physical proper‐ ties of the current application execution phase. In the example discussed in Section 2, the monitor engine will identify the heat diffusion acceleration changes and the heat conductivity changes. The application properties are then fed into the Planning Engine.
The Planning Engine will determine the optimal spatial (Dx, Dy, Dz) and temporal characterization (Dt) for the application solu‐ tion while maintaining the desired accuracy of the solution. Conse‐ quently, the format of the linear system will be projected based on the numerical method the application uses. The Knowledge Base identifies the optimal solution for each execution phase based on analytical and historical data; for example, if an application is using Finite Difference implicit Method, the linear system will involve solving a tri‐diagonal matrix, then Conjugate Gradient with block Jacobi preconditioner will be stored in the knowledge based as the best linear solver. After the optimal algorithm is selected, the configuration engine generates the data needed by the new algorithm based on the previous phase execution results and the temporal and spatial characteristics of the new solution. For
6
Figure 2: VSAFT2D Execution Time
Figure 1: Autonomic Runtime Manager Architecture

example, regenerate grid values using interpolation and extrapolation after we change the grid size. After the configuration engine finishes its job, the application resumes its execution with the new configuration.
We evaluate the performance of the PAP approach with transient problem setting as shown in Figure 2. For simplicity, we only consider the spatial characteristics of the application such as determining the ideal grid size for each phase, although our approach can support both of adaptations types (spatial and temporal). Furthermore, we assume the area is divided evenly between silt and sand (each represents 50% of the computational domain). In reality, this distribution varies depending on the area being modeled. In fact, the more heterogeneous the computational domain is, the more performance gain that can be achieved by using the PAP para‐ digm; traditional programming techniques suffer more degradation in performance because the adopted solution must satisfy all domains by choosing the most conservative solution. We compare the performance of PAP implementation of VSAF2SD with the im‐ plementation that uses the finest grid resolution. We execute the code with finest grid size and with PAP approach in which PARM chooses dynamically the optimal grid size for each phase of the application execution that ran for a total simulation period of 0.3 day.
The execution time of this application on different number of nodes is shown in Figure 2. For 2M nodes, PAP approach achieved an 81% performance gain when compared with the finest grid implementation.
Importance of the research problem This research will formulate methodologies and develop infrastructures for building the next generation scientific and engineer‐
ing simulations of complex physical phenomenon on widely distributed, highly heterogeneous and dynamic, networked computa‐ tional environment. The simulations targeted by this effort will be built as dynamics compositions of autonomous components that integrate scalable distributed (and heterogeneous) computing with interactive control and computational steering, collaborative analysis, and scientific databases and data archives. Composing, configuring and managing the execution of these applications to ex‐ ploit the underlying computational power in spite of its heterogeneity and dynamism will present significant challenges. Our pro‐ gramming paradigm, execution model, component frameworks and runtime infrastructures will help researchers better understand the operations and performance issues of applications, limitations of algorithms and architectures. It will also enable the develop‐ ment of “smarter” algorithms and applications that are capable of sensing the state of their environments and reacting to optimize overall execution, utilization and performance. Finally, this research will support the trend toward the next generation of an inte‐ grated software development life cycle that allows users to describe the requirements of the application components at each phase of its life cycle. These requirements can then be used by compilers and runtime systems to produce applications that are controllable, observable, and maintainable.
7

Scale‐Right Provisioning for Next Generation Data‐ centers
by Mazin Yousif by Mazin Yousif by Mazin Yousif Scale‐Right Provisioning (SRP) is intended to streamline deployment, allocation, management of compute,
memory and I/O resources and scaling to efficiently react to runtime changes (e.g., failure, and workload). Adopting this will mitigate many of datacenters’ inefficiencies such as: (i) Provisioning for peak loads and some‐ times for multiple peak loads resulting in low average resources utilization (< 25%); (ii) Lack of autonomic fea‐ tures such as the inability to self‐optimize when runtime workloads vary, inability to self‐configure when re‐ sources are added/removed and inability to self‐ heal when failures happen; and (iii) Manageability, which has remained ad‐hoc with considerable overhead on Total Cost of Ownership (TCO).
The premise of this project is to degenerate the physical resources (e.g., servers, network switches and SAN or NAS devices) in an enclosure (or server farm or rack or …) into pools of virtual resources. Then, based on the workload’s re‐ sources requirements and its executions con‐ straints such as Service Level Agreement (SLA), security and availability, a set of compute, mem‐ ory, network and storage virtual resources are selected and launched as a dynamic virtual plat‐ form (Virtual Machine) to run the workload. Also, we provide the ability to automatically scale up/ down resources allocated to a dynamic platform as runtime demands change. For example, when a running workload on a dynamic platform requires more compute power, one or more virtual logical threads from the resource pool is added in to this VM. Similar arrangements can be made for other scenarios of runtime changes such as power, SLA or availability. The specific features we plan to support include, but not limited to: (i) Ability to manage an enclosure of compute & I/O nodes independent of system software, and relying on high‐level policies; (ii) Ability to create dynamic platforms from pools of compute/memory and I/O resources with capaci‐
ties that match workloads’ requirements; (iii) Ability to dynamically scale resources allocated to a dynamic platform up/down based on runtime changes (e.g., workload & failure); (iv) Ability to enforce various power budgeting schemes within the enclosure, as well as thermal‐gradient characteristics; (v) Ability to mitigate failures through the integration of a Fault Prediction Agents to predict failures and gracefully migrate workloads from one dynamic platform to another; and (vii) Ability to perform fabric topology configuration to optimize resource allocation to dynamic platforms. The Proof of Concept (PoC) for this project will include mechanisms to create: (i) pools of virtual resources; and (ii) a comprehensive autonomic management infrastructure. The first could be established through Virtual Machine Monitors (VMM) in each server or create an enclosure‐wide VMM (EVMM). To create the EVMM, it is necessary to enhance existing VMMs with capabilities allowing them to communicate with each other and collaborate to project one aggregate VMM. Specifically: (i) Enable arbitrary grouping of resources to create dynamic platforms, and help cre‐ ate multiple of such platforms within an enclosure; (ii) Presents abstraction of the platforms to enable decoupling of hardware and software resources guaranteeing security and isolation; (iii) Help to dynamically allocate/de‐allocate/reallocate resources within an enclosure and as as‐ signed to a platform; (iv) Helps manage the enclosure independently of system software; and (v)
8
The vision of the capabilities provided by EVMM and EAM is to allow future backplanes to mimic current server mother‐ boards. Specifically, what is on current servers’ motherboards is chips (processors, chipsets, ...) and a BIOS that enables them to expose themselves as a platform to run system soft‐ ware (OS or VMM). Similarly, EVMM enable of compute and I/O resources in various physi‐ cal platforms to be aggre‐ gated and exposed as dynamic platform on which system software will run.

Helps redirect events to appropriate blade where a platform resides or to the management platform. The autonomic management infrastructure includes multiple components: (i) Resource‐Autonomic Manager (RAM) in each
server with monitoring and limited decision capabilities based on locally collected data; (ii) Platform Autonomic Manager (PAM) with ability to make decisions at the platform‐level; and (iii) Enclosure Autonomic Manager (EAM) that will have visibility to the whole en‐ closure. Specifically, the EAM is tasked with capabilities such as: (i) Self discovery and configuration of servers, inventory and catalog‐ ing capabilities at the enclosure level; (ii) Provisioning platform to boot OS images and applications based on system‐level policies; (iii) Selecting virtual resources and launching dynamic platforms to run workloads; (v) Transparently migrating or scaling dynamic plat‐ form resources up/down based on runtime changes; (vi) Enforcing high‐level policies such as those related to power and SLA; and (vii) projecting all information on a user interface to allow user to view both physical and virtual configurations in the enclosure.
Autonomic Performance/Power Optimizations in Next Generation Datacenters
by Mazin Yousif by Mazin Yousif by Mazin Yousif The goal of this project is to design innovative autonomic framework and architecture to integrate in traditional server platforms
and enclosures to intelligently optimize their performance/watt. To achieve this goal, we plan to extend our performance/watt opti‐ mization at the resource‐level to the platform‐, enclosure‐ and datacenter‐levels. The central ideas behind this research, which in‐ cludes power and thermal optimizations are: (i) to proactively detect and reduce resource over‐provisioning in server platforms such that it is just right‐sized to handle the requirements of the application; and (ii) migrate virtual machines from one physical server in an enclosure to another server to eliminate thermal hot spots and smooth thermal gradients within the enclosure, reducing cooling costs. This holistic multi‐variable mathematically rigorous optimization approach for determining optimal performance/watt lends itself best to achieve the desired goals.
Most early work on server power management has either focused on specific components such as the processor or used heuris‐ tics to address base power consumption in server clusters or have ignored thermal ramifications completely. This motivated us to adopt a holistic approach for system‐level power management within a server farm or enclosure where we exploit interactions and dependencies among different resources and platforms.
We consider an enclosure with multiple servers – each consists of multi‐core processors and multi‐rank memory subsystems plus other resources. The Autonomic Enclosure consists of three hierarchies of management, as shown the first Figure – the Enclosure Autonomic Manager (EAM) at the enclosure level; the Platform Autonomic Manager (PAM) at the platform‐level; and Core Manager (CM) and Rank Manager (RM) at the individual processor core and memory rank, respectively. EAM ensures that all platforms within the enclosure operate within the pre‐determined thermal gradient and thermal/power envelope by migrating virtual machines run‐ ning specific workloads from one platform to another. PAM’s objective is to ensure that platform resources (processor/memory) are configured to meet the dynamic application resource requirements such that additional platform capacity can be transitioned to low‐power states. In this manner both the EAM and PAM save total power without hurting application per‐ formance. The platform power and performance parameters together determine the platform operating point in an n‐dimensional space at any instant of time during the lifetime of the application. PAM manages the platform power and performance by maintaining the platform operating point within a predetermined safe operating zone, as the example shown in the second Figure. PAM predicts the trajectory of the operating point as it changes in response to changes in the nature and arrival rate of the incoming workload and triggers a platform reconfiguration whenever the operating point drifts outside of the safe operating zone. See how we used this approach for memory performance/watt optimizations, where
9
Platform Energy
steadystate behaviour
transient behaviour
ss
t
safe operating zone anomalous operating zone
d z decision
Platform waitTime
Platform procTime
Platform reqLoss
Memory Miss Ratio
Memory Endtoend Delay
Memory reqLoss
t ss ss
t
t
t
ss d z
d z
d z
d z

we specifically monitor additional parameters such as memory miss ratio, memory end‐to‐end delay and memory request loss to determine the best memory configuration that would maintain the platform response time within the safe operating region .
Platform state is defined by the number of processor cores in active state, the number of memory ranks in the active state and I/ O devices. Since the performance of the platform state depends on the physical configuration of the platform, PAM platform recon‐ figuration decision actually involves a platform state transition from the current state to a target state that would maintain the per‐ formance while giving the smallest power consumption. The search for this ideal target state is formulated as an optimization prob‐ lem.
EAM will rely on thermal sensors that will be placed in critical positions within the enclosure and platforms. Data from all these sensors will be collected by EAM, which will make decisions based on the thermal gradient and presence/absence of thermal hot spots within the enclosure, the set of resources required by the running workloads and the decisions PAM has undertaken. One inter‐ esting research challenge is the sensitivity to data inaccuracies when moving across the hierarchy from the component managers to the platform managers to the enclosure manager.
This project will develop innovative management techniques at the resource level to address the following research challenges: 1) How to efficiently and accurately model power and energy consumption from a system‐level perspective that involves complex interactions of different classes of devices such as processor, memory, network and I/O? A system‐level view of these components would present more opportunities for power savings since we can exploit the non‐mutually exclusive behaviors of these components to set them at power states such that the global system power consumption is minimal; 2) How to predict, in real‐time, the behavior of system resources and their power consumptions, as workloads change dynamically by several order of magnitude within a day or a week; and 3) How to design efficient and self‐adjusting optimization mechanisms that can continuously learn, execute, monitor, and improve themselves in meeting the collective objectives of power, thermal and performance optimizations? Game theory and data mining techniques will be exploited to address this research challenge.
10

On Going Projects Autonomic Defense System
by Youssif Al by Youssif Al by Youssif Al‐ ‐ ‐Nashif Nashif Nashif Recently, the need for an efficient cyber defense system has become extremely critical. The Internet is per‐
vading almost every aspect of life and business, and along with this exponential growth comes the critical need to secure these systems from unauthorized disclosure, transfer, modification, or destruction is vital. The increase in the number of attacks and their complexity is due to an increase in the number of applications with vulnerabilities and the number of attackers equipped with fast networks and processing units. Cyber attacks are growing increas‐ ingly in complexity and sophistication.
Complex attacks present a significant threat to the security of information infrastructure and can lead to catastrophic results. Attacks typically exploit vulnerabilities in networks, system software, and protocols. For ex‐ ample, some attacks misuse network resources’ limitations, protocol vulnerabilities, or application vulnerability to reach their goals. Furthermore, these attacks vary in their speed, complexity, and dynamicity.
We are designing and implementing a multilevel anomaly‐based Auto‐ nomic Defense System (ADS), which is capable of detecting any type of attacks targeting resources, with low false alerts and high detection rates. The main concept behind the ADS is the zooming in to the correct level of granularity to analyze cyber behaviors. Once the zooming is locked to the correct level of granularity, the cyberspace is monitored, the process of selecting the correct features to improve detection is applied, and then aggregation and correla‐ tion is used to the reduced the number of analyzed records with minimum loss in information. After that the anomaly based detection technique is used to detect abnormal behavior in the cyberspace. Once an abnormal behavior is detected, the risk and impact analysis process is triggered to recommend the best set of actions to be applied with minimum loss in cyber operation func‐ tionality. Finally, the recommended set of actions are either applied automati‐ cally or prompted for administrator confirmation in the visualization and man‐ agement console.
Autonomic Application Security Management by Ram Prasad V by Ram Prasad V by Ram Prasad V
Network monitoring systems can be broadly classified into signature‐based and anomaly‐based. Signa‐ ture‐based systems are limited by the number of anomalies they can detect as they rely on signatures stored in a database) while anomaly‐based systems have high false‐positive rate. The existing payload/application anom‐ aly detection systems use either byte distributions or work on the first line of the payload. Such an approach limits the number of attacks that can be detected and can work only for certain protocols (e.g., GET request of HTTP).
Our payload‐based anomaly detection system—a major component of the Autonomic Network Defense (AND) System—classifies network traffic into objects such as headers, text, images, audio and video. The system consists of three major routines: (i) A sniffer module to collect normal traffic and store it in a database; (ii) A model generator routine which uses the collected traffic to model each of the above mentioned objects; and (iii) a detector routine to scan real‐time traffic to detect deviations from the normal behavior.
We have implemented the following HTTP header models: 1. Language model: This model is used to profile the byte distribution of the HTTP headers. It helps us in detecting anomalies such
as shell code injection as HTTP uses ASCII based headers and presence of code will alter the byte distributions present in the
11

packets. 2. Keyword/Value based model: These models divide the
headers into “keyword‐value” pairs. The standard key‐ words are specified in the HTTP specification (rfc‐2616). The keywords are profiled and the various statistics are generated for the values of these keywords. From these statistics, we build the following models: ◊ Keyword average, maximum and mode: The mode, the average length and the maximum length of the value for each keyword are determined during the model building stage. During the detection phase, the profiled values are checked against the real time val‐ ues and any deviation is flagged.
◊ New keywords: HTTP allows users to define new key‐ words. But the interpretation of the keywords de‐ pends on the server and the client. Hence, the pres‐ ence of any new keyword denotes a deviation from the normal behavior (especially since we profile the normal behavior of the traffic).
◊ Keyword ordering: We study the ordering of keywords in the normal case. The ordering is profiled and any deviation from the normal ordering is flagged. The change in the ordering can be attributed to hand crafted packets or buffer overflow attacks.
◊ Time window based model: Our detection routine works in a time window. The traffic is collected for certain duration, say 10 seconds and then the models are verified. At the same time, the traffic is analyzed over the time window. Any similarity of packets is flagged as it can correspond to scanning or denial of service attacks.
We have developed a framework called AND ‐ Tcpdump framework to monitor multiple application level protocols simultane‐ ously. Based on which applications to monitor, the framework segregates the payload information and hands‐over relevant packets to different application protocol handlers. The framework now has the capability to monitor the control port of FTP and detect all the data ports where the transfers are scheduled to happen.
The next stage of our project will be to profile java scripts present in text‐based traffic. The script from the payload is extracted and byte codes are generated using the spider‐monkey web engine of the Mozilla browser. The generated byte codes are then pro‐ filed. During detection, the generated byte codes are compared with the profiled values. We are also looking at analyzing image traf‐ fic. In case of image traffic, the analysis will look at the various distributions. Anomalies will represent the deviation in distribution. We intend to use MATLAB to analyze and examine the image traffic during the model building stages.
Accelerated Discovery Cycle Development Environment Yaser Jararweh Yaser Jararweh Yaser Jararweh
In the face of rapid global changes the considerable recent advances in ecosystem science have nonetheless failed to keep pace with the accelerating need to better understand “how the world works”. The science of global change requires a new model for the comprehensive study of complex systems that quantitatively com‐ bine: (a) experimental infrastructure that encompasses realistically complex earth systems, but simultaneously allows for precise manipulation of that system with (b) networks of field monitoring stations measuring whole ecosystem dynamics using a diverse array of instrumentation. To realize this integration between experimental and observational data, information integration and informatics capacity are needed to both ingest the massive datasets needed to capture large‐scale dynamic ecosystem complexity, and to instantly process and update it in order to test contrasting mechanistic models and drive the next set of experiments. Furthermore, to ensure that such an approach is accessible to the entire scientific community, the data, models, and knowledge generated need to be easily accessible and visualized. Currently, no coupled physical and computational infrastructure exists to address this pressing need. A computational collaboration
12

that can support such integration would generate immedi‐ ate transformative science opportunities.
Cyber‐infrastructure and information technology accelerate the way many sciences are conducted in rapidly evolving multi‐disciplinary fields such as, biomedical infor‐ matics, ecosystems sciences, geosciences, and bioinformat‐ ics, etc. These scientific fields are characterized by huge amounts of data streaming and data processing. For exam‐ ple in the context of ecosystem observation architecture, hundreds of sensors scattered in the field collect tempera‐ ture, humidity, respiration etc information. This leads to large amount of data collection from the sensor network.
There is a need for Accelerated Discovery Cycles (ADCs) for integrating experimental and observational data to capture large‐scale dynamic ecosystem complexity, to instantly process massive datasets, to test contrasting mechanistic models and to drive the next set of experi‐ ments. The overreaching objective is to enable ADCs by coupling recent advances in computational models and cyber‐systems with the unique experimental infrastructure of Biosphere 2 (B2), a large‐scale earth system science facility now under management by the University of Arizona.
In the context of ADCs, there is a need for software development environment for modeling complex systems and a middle‐ ware for data streaming from the field into the models. Kepler is an open source tool that enables the end user to design scientific workflows in order to manage scientific data and perform complex analysis on the data. Ring Buffered Network Bus (RBNB) Data Tur‐ bine is a middleware system that is used to integrate sensor‐based environment observing systems with Data Processing systems. Currently the integration between Kepler and Data Turbine is limited to reading from the Data Turbine only. In ADC, multiple hy‐ potheses are tested with different assimilation models. These models run on a distributed computing environment, therefore capa‐ bility of simultaneous reads and writes to the Data Turbine is a necessity.
In this work we show how to integrate Kepler with RBNB Data Turbine to achieve this capability. We also exploit the open‐ source features of Kepler system and create customized processing models in order to accelerate and automate the experiments in ecosystems research.
Anomaly‐based Fault Management in Distributed Systems Byoung Kim Byoung Kim Byoung Kim
The increased complexity, interconnected‐ ness, dependency and the asynchronous interac‐ tions among components (e.g., hardware re‐ sources such as computers, servers, network de‐ vices, and software such as applications and mid‐ dleware) makes fault detection and tolerance a challenging research problem. In this project, we present innovative concepts and self‐healing ar‐ chitectures analyzing pattern transition sequences of length n during a window interval to detect hardware/software faults as well as root‐cause analysis of system and application faults. We use three‐dimensional array of features to capture spatial and temporal variability on which our
13

anomaly analysis engine operates and produces an alert when normal‐operations captured patterns are violated due to software or hardware failure. Our main contributions are the innovative analysis methodology and the selection of the system and application features to detect and identify any anomalous behavior that is triggered by software of hardware failures. Our preliminary results show a detection rate of above 99.9% with no occurrences of false alarms for a wide range of scenarios.
Survivability Modeling and Analysis Seungchan Oh Seungchan Oh Seungchan Oh
Our dependence on Information Technologies (IT) has introduced a new form of vulnerability that gives cyber‐attackers the opportunity to launch attacks against our national infrastructure (national defense systems, air traffic control systems, power grind control systems, etc.) . Understanding the vulnerability of our Cyber‐ infrastructure and how to quantify it becomes critically important to secure and protect our IT services and re‐ sources. The formal definition of survivability is the ability of the system to provide essential services in case of faults, attacks or accidents in a timely manner. Security in general focuses on recognition and resistance of at‐ tacks, but survivability includes faults and accidents.
The quantification of survivability can be used to analyze the robustness and survivability of different topologies and distribution of cyberspace resources. Additionally we can im‐ prove the survivability of a system by locating the vulnerable hardware and/or software components so they can be hard‐ ened. Very few research has been conducted to quantify the survivability of IT systems and their services due to its challeng‐ ing complexity. In our approach, we adopt Ellison’s description of survival systems that should have three properties (3R) – Resistance, Recognition and Recovery. In our approach, the possible attacks (faults and accidents) are divided into sub‐ events and then we calculate how the system responses to those events in resisting, recognizing and recovering from these events.
Service‐Oriented Architecture Sankaranarayanan Veeramoni Mythili Sankaranarayanan Veeramoni Mythili Sankaranarayanan Veeramoni Mythili
The increased complexity, heterogeneity and the dynamism of networked systems and applications make current configuration and management tools to be ineffective. A new paradigm to dynamically configure and manage large‐scale complex and heterogeneous networked systems is critically needed. In this project, we are implementing an autonomic system, Autonomia, that is based on the principles of autonomic computing that can handle efficiently complexity, dynamism and uncertainty in configuring networked systems and their applications. Autonomia provides dynamic programmable control and management services to support the development and deployment of autonomic applications. It can automate the dynamic allocation of re‐ sources to achieve high performance and fault tolerant operations. It provides a secure, open computing en‐ vironment with automated deployment, registration and discovery of components. Our autonomic management is implemented us‐ ing two software modules: Component Management Interface (CMI) that enables us to specify the configuration policies and opera‐ tional policies associated with each component that can be a hardware resource or a software component; and Component Runtime Manger (CRM) that monitors the component operational state through well defined management interface ports.
Major Autonomia modules include System Management Editor, Autonomic Management Library, Component Runtime Manager (CRM) and Compound Component Runtime Manager (CCRM). System Management Editor is used to specify the component manage‐ ment requirements according to the specified CMI schema. Autonomic Management Library is a set of common services/
14

functionalities (e.g., fault‐tolerant service) we have developed that can be invoked by the Compound Component Runtime Manager (CCRM). CRM is a runtime manager that aims at monitoring the component behavior and controls its operation in order to maintain the desired component attributes and functionalities. Compound CRM (CCRM): Several autonomic components (e.g., autonomic serv‐ ers, clusters, and software systems) can be controlled and managed by one autonomic system that we refer to as an Autonomic Com‐ pound Component (ACC), and the corresponding CRM refers to CCRM. In a similar way, larger autonomic systems can be built by com‐ posing several autonomic compound components as so to create hierarchical management structure.
System Management Editor (SME): It is used to specify the component management requirements according to the specified CMI schema. Each autonomic component requires a CMI associated to it, no matter it is basic component or compound component.
Autonomic Management Library (AML): It is a set of common services/functionalities (e.g., fault tolerant service) we have devel‐ oped that can be invoked by any Component Runtime Manager in an autonomic component. The library includes machine learning algorithms, which can be used for decision making module; fault detection algorithms, which help identifying the faults; system and application performance measurement functions; configuration interface functions, which measure the specified attributes and ef‐ fect the configuration changes with format we defined (component information base); and some security detection utilities we devel‐ oped, like checking if host is alive, port is open etc .
Component Runtime Manager (CRM): It monitors the component behaviors and controls its operations in order to maintain its desired operational requirements.
Compound Component Runtime Manager (CCRM): Several autonomic components can be hierarchically controlled and man‐ aged by CCRM.
15

Benefits of NSF CAC Membership CAC members will have access to leading‐edge developments in autonomic computing and to knowledge accumulated by academic researchers and other industry partners. New members will join a growing list of founding members that currently includes BAE Systems, EWA Government Systems, IBM, Intel, Merrill‐Lynch, Microsoft, Northrop‐ Grumman, NEC, Raytheon, Xerox, Avirtec, Imaginestics, and ISCA Technologies. Benefits of membership include:
◊ Collaboration with faculty, graduate students, post‐doctoral researchers and other center partners;
◊ Choice of project topics to be funded by members’ own contributions; ◊ Formal periodic project reviews along with continuous informal interaction and
timely access to reports, papers and intellectual property generated by the cen‐ ter.
◊ Access to unique world‐class equipment, facilities, and other CAC infrastructure; ◊ Internships and recruitment opportunities among excellent graduate students. ◊ Leveraging of investments, projects and activities by all CAC members. ◊ Spin‐off initiatives leading to new partnerships, customers or teaming for com‐
petitive proposals to funded programs
Funding Per NSF guidelines, industry and government contributions in the form of annual CAC memberships ($35K/year per regular
membership), coupled with baseline funds from NSF and university matching funds, directly support the Center's expenses for
personnel, equipment, travel, and supplies. Memberships provide funds to support the Center's graduate students on a one‐to‐
one basis, and thus the size of the annual membership fee is directly proportional to the cost of supporting one graduate student,
while NSF and university funds support various other costs of operation. Multiple annual memberships may be contributed by
any organization wishing to support multiple students and/or projects. The initial operating budget for CAC is projected to be ap‐
proximately $1.5M/year, including NSF and universities contributions, in an academic environment that is very cost effective.
Thus, a single regular membership is an exceptional value. It represents less than 3% of the projected annual budget of the Center
yet reaps the full benefit of Center activities, a research program that could be significantly more expensive in an industry or gov‐
ernment facility.
Universities To Become a Member Contact us at Director: Salim Hariri (520) 621‐4378 [email protected] Co‐Director:Mazin Yousif (503) 819‐4638 [email protected] Research Director: Youssif Al‐Nashif (520)‐621‐9915 [email protected] Business Manager: Firas Barakat (520) 548‐6325 [email protected] ECE Dept. 1230 E. Speedway Tucson, AZ 85721‐0104 http://nsfcac.arizona.edu
Members
The University of Florida,
the University of Arizona and
Rutgers, the State University of
New Jersey, have established a
national research center for
autonomic computing (CAC).
This center is funded through
the Industry/University Coop‐
erative Research Center pro‐
gram of the National Science
Foundation, CAC members
from industry and government,
and university matching funds.