unambiguous + unlimited = unsupervised marti hearst school of information, uc berkeley invited talk,...
Post on 19-Dec-2015
214 views
TRANSCRIPT

Unambiguous + Unlimited = Unsupervised
Marti HearstSchool of Information, UC Berkeley
Invited Talk, University of TorontoJanuary 31, 2006
This research supported in part by NSF DBI-0317510

Invited talk: University of Toronto, 2006
Natural Language Processing
The ultimate goal: write programs that read and understand stories and conversations.
This is too hard! Instead we tackle sub-problems. There have been notable successes lately:
Machine translation is vastly improved Decent speech recognition in limited circumstances Text categorization works with some accuracy

Invited talk: University of Toronto, 2006
Why is text analysis difficult?
One reason: enormous vocabulary size. The average English speaker’s vocabulary
is around 50,000 words, Many of these can be combined with
many others, And they mean different things when they
do!

Invited talk: University of Toronto, 2006
What’s a Robot to Do?
Decorate the cake with the frosting. Decorate the cake with the kids. Throw out the cake with the frosting.
Get the sock from the cat with the gloves. Get the glove from the cat with the socks.
It’s in the plastic water bottle. It’s in the plastic bag dispenser.

Invited talk: University of Toronto, 2006
How to tackle this problem?
The field was stuck for quite some time. CYC: hand-enter all semantic concepts and
relations A new approach started around 1990 How to do it:
Get large text collections Compute statistics over the words in those
collections Many different algorithms for doing this.

Invited talk: University of Toronto, 2006
Size Matters
Recent realization: bigger better than smarter! Banko and Brill ’01: “Scaling to Very, Very Large
Corpora for Natural Language Disambiguation”, ACL

Invited talk: University of Toronto, 2006
Example Problem
Grammar checker example:Which word to use? <principal> <principle>
Look at which words surround each use:
I am in my third year as the principal of Anamosa High School.
School-principal transfers caused some upset.
This is a simple formulation of the quantum mechanical uncertainty principle.
Power without principle is barren, but principle without power is futile. (Tony Blair)

Invited talk: University of Toronto, 2006
Using Very, Very Large Corpora
Keep track of which words are the neighbors of each spelling in well-edited text, e.g.: Principal: “high school” Principle: “rule”
At grammar-check time, choose the spelling best predicted by the surrounding words.
Surprising results: Log-linear improvement even to a billion words! Getting more data is better than fine-tuning
algorithms!

Invited talk: University of Toronto, 2006
The Effects of LARGE Datasets
From Banko & Brill ‘01

Invited talk: University of Toronto, 2006
How to Extend this Idea?
This is an exciting result … BUT relies on having huge amounts of
text that has been appropriately annotated!

Invited talk: University of Toronto, 2006
How to Avoid Labeling?
“Web as a baseline” (Lapata & Keller 04,05)
Main idea: apply web-determined counts to every problem imaginable.
Example: for t in {<principal> <principle>} Compute f(w1, t, w2) The largest count wins

Invited talk: University of Toronto, 2006
Web as a Baseline
Works very well in some cases machine translation candidate selection article generation noun compound interpretation noun compound bracketing adjective ordering
But lacking in others spelling correction countability detection prepositional phrase attachment
How to push this idea further?
Significantly better than the best supervised algorithm.
Not significantly different from the best supervised.

Invited talk: University of Toronto, 2006
Using Unambiguous Cases
The trick: look for unambiguous cases to start
Use these to improve the results beyond what co-occurrence statistics indicate.
An Early Example: Hindle and Rooth, “Structural Ambiguity and
Lexical Relations”, ACL ’90, Comp Ling’93 Problem: Prepositional Phrase attachment
I eat/v spaghetti/n1 with/p a fork/n2. I eat/v spaghetti/n1 with/p sauce/n2. quadruple: (v, n1, p, n2) Question: does n2 attach to v or to n1?

Invited talk: University of Toronto, 2006
Using Unambiguous Cases
How to do this with unlabeled data? First try:
Parse some text into phrase structure Then compute certain co-occurrences
f(v, n1, p) f(n1, p) f(v, n1) Problem: results not accurate enough
The trick: look for unambiguous cases: Spaghetti with sauce is delicious. (pre-verbal) I eat it with a fork. (object of preposition can’t
attach to a pronoun)
Use these to improve the results beyond what co-occurrence statistics indicate.

Invited talk: University of Toronto, 2006
Unambiguous + Unlimited = Unsupervised Apply the Unambiguous Case Idea to the Very,
Very Large Corpora idea The potential of these approaches are not fully realized
Our work: Semantic Relation Acquisition
Hypernym (ISA) relations
Structural Ambiguity Decisions (work with Preslav Nakov) PP-attachment Noun compound bracketing Coordination grouping

Invited talk: University of Toronto, 2006
Semantic Relation Detection
Goal: automatically augment a lexical database
Many potential relation types: ISA (hypernymy/hyponymy) Part-Of (meronymy)
Idea: find unambiguous contexts which (nearly) always indicate the relation of interest

Invited talk: University of Toronto, 2006
Lexico-Syntactic Patterns

Invited talk: University of Toronto, 2006
Lexico-Syntactic Patterns

Invited talk: University of Toronto, 2006
Adding a New Relation

Invited talk: University of Toronto, 2006
Semantic Relation Detection
Lexico-syntactic Patterns: Should occur frequently in text Should (nearly) always suggest the relation of
interest Should be recognizable with little pre-encoded
knowledge.
These patterns have been used extensively by other researchers.

Invited talk: University of Toronto, 2006
Structural Ambiguity Problems
Apply the U + U = U idea to structural ambiguity
Noun compound bracketing Prepositional Phrase attachment Noun Phrase coordination
Motivation: BioText project
In eukaryotes, the key to transcriptional regulation of the Heat Shock Response is the Heat Shock Transcription Factor (HSF).
Open-labeled long-term study of the subcutaneous sumatriptan efficacy and tolerability in acute migraine treatment.
• BimL protein interact with Bcl-2 or Bcl-XL, or Bcl-w proteins (Immuno-precipitation (anti-Bcl-2 OR Bcl-XL or Bcl-w)) followed by Western blot (anti-EEtag) using extracts human 293T cells co-transfected with EE-tagged BimL and (bcl-2 or bcl-XL or bcl-w) plasmids)

Invited talk: University of Toronto, 2006
Applying U + U = U to Structural Ambiguity
We introduce the use of (nearly) unambiguous features: surface features Paraphrases
Combined with very, very large corpora Achieve state-of-the-art results without
labeled examples. Joint work with Preslav Nakov

Invited talk: University of Toronto, 2006
Noun Compound Bracketing
(a) [ [ liver cell ] antibody ] (left bracketing)(b) [ liver [cell line] ] (right bracketing)
In (a), the antibody targets the liver cell.In (b), the cell line is derived from the liver.

Invited talk: University of Toronto, 2006
Dependency Model
right bracketing: [w1[w2w3] ] w2w3 is a compound (modified by w1)
home health care
w1 and w2 independently modify w3
adult male rat
left bracketing : [ [w1w2 ]w3] only 1 modificational choice possible
law enforcement officer
w1 w2 w3
w1 w2 w3

Invited talk: University of Toronto, 2006
Related Work
Marcus(1980), Pustejosky&al.(1993), Resnik(1993) adjacency model: Pr(w1|w2) vs. Pr(w2|w3)
Lauer (1995) dependency model: Pr(w1|w2) vs. Pr(w1|w3)
Keller & Lapata (2004): use the Web unigrams and bigrams
Girju & al. (2005) supervised model bracketing in context requires WordNet senses to be given
Our approach:• Web as data• 2 , n-grams• paraphrases• surface features

Invited talk: University of Toronto, 2006
Computing Bigram Statistics
Dependency Model, FrequenciesCompare #(w1,w2) to #(w1,w3)
Dependency model, Probabilities
Pr(left) = Pr(w1w2|w2)Pr(w2w3|w3)
Pr(right) = Pr(w1w3|w3)Pr(w2w3|w3)
So we compare Pr(w1w2|w2) to Pr(w1w3|w3)
w1 w2 w3
left
right

Invited talk: University of Toronto, 2006
Probabilities: Estimation
Using page hits as a proxy for n-gram counts
Pr(w1w2|w2) = #(w1,w2) / #(w2) #(w2) word frequency; query for “w2”
#(w1,w2) bigram frequency; query for “w1 w2”
smoothed by 0.5

Invited talk: University of Toronto, 2006
Association Models: 2 (Chi Squared)
A = #(wi,wj)
B = #(wi) – #(wi,wj)
C = #(wj) – #(wi,wj) D = N – (A+B+C) N = 8 trillion (= A+B+C+D)
8 billion Web pages x 1,000 words

Invited talk: University of Toronto, 2006
Web-derived Surface Features
Authors often disambiguate noun compounds using surface markers, e.g.: amino-acid sequence left brain stem’s cell left brain’s stem cell right
The enormous size of the Web makes these frequent enough to be useful.

Invited talk: University of Toronto, 2006
Web-derived Surface Features:Dash (hyphen)
Left dash cell-cycle analysis left
Right dash donor T-cell right fiber optics-system should be left..
Double dash T-cell-depletion unusable…

Invited talk: University of Toronto, 2006
Web-derived Surface Features:Possessive Marker
Attached to the first word brain’s stem cell right
Attached to the second word brain stem’s cell left
Combined features brain’s stem-cell right

Invited talk: University of Toronto, 2006
Web-derived Surface Features:Capitalization
don’t-care – lowercase – uppercase Plasmodium vivax Malaria left plasmodium vivax Malaria left
lowercase – uppercase – don’t-care brain Stem cell right brain Stem Cell right
Disable this on: Roman digits Single-letter words: e.g. vitamin D
deficiency

Invited talk: University of Toronto, 2006
Web-derived Surface Features:Embedded Slash
Left embedded slash leukemia/lymphoma cell right

Invited talk: University of Toronto, 2006
Web-derived Surface Features:Parentheses
Single-word growth factor (beta) left (brain) stem cell right
Two-word (growth factor) beta left brain (stem cell) right

Invited talk: University of Toronto, 2006
Web-derived Surface Features:Comma, dot, semi-colon
Following the first word home. health care right adult, male rat right
Following the second word health care, provider left lung cancer: patients left

Invited talk: University of Toronto, 2006
Web-derived Surface Features:Dash to External Word
External word to the left mouse-brain stem cell right
External word to the right tumor necrosis factor-alpha left

Invited talk: University of Toronto, 2006
Web-derived Surface Features:Problems & Solutions
Problem: search engines ignore punctuation in queries “brain-stem cell” does not work
Solution: query for “brain stem cell” obtain 1,000 document summaries scan for the features in these summaries

Invited talk: University of Toronto, 2006
Other Web-derived Features:Abbreviation
After the second word tumor necrosis factor (NF) right
After the third word tumor necrosis (TN) factor right
We query for, e.g., “tumor necrosis tn factor” Problems:
Roman digits: IV, VI States: CA Short words: me

Invited talk: University of Toronto, 2006
Other Web-derived Features:Concatenation
Consider health care reform healthcare : 79,500,000 carereform : 269 healthreform: 812
Adjacency model healthcare vs. carereform
Dependency model healthcare vs. healthreform
Triples “healthcare reform” vs. “health carereform”

Invited talk: University of Toronto, 2006
Other Web-derived Features:Reorder
Reorders for “health care reform” “care reform health” right “reform health care” left

Invited talk: University of Toronto, 2006
Other Web-derived Features:Internal Inflection Variability
Vary inflection of second word tyrosine kinase activation tyrosine kinases activation

Invited talk: University of Toronto, 2006
Other Web-derived Features:Switch The First Two Words
Predict right, if we can reorder adult male rat as male adult rat

Invited talk: University of Toronto, 2006
Paraphrases
The semantics of a noun compound is often made overt by a paraphrase (Warren,1978) Prepositional
stem cells in the brain right cells from the brain stem right
Verbal virus causing human immunodeficiency left pain associated with arthritis migraine right
Copula office building that is a skyscraper right

Invited talk: University of Toronto, 2006
Paraphrases
prepositional paraphrases: We use: ~150 prepositions
verbal paraphrases: We use: associated with, caused by, contained in,
derived from, focusing on, found in, involved in, located at/in, made of, performed by, preventing, related to and used by/in/for.
copula paraphrases: We use: is/was and that/which/who
optional elements: articles: a, an, the quantifiers: some, every, etc. pronouns: this, these, etc.

Invited talk: University of Toronto, 2006
Evaluation: Datasets
Lauer Set 244 noun compounds (NCs)
from Grolier’s encyclopedia inter-annotator agreement: 81.5%
Biomedical Set 430 NCs
from MEDLINE inter-annotator agreement: 88% ( =.606)

Invited talk: University of Toronto, 2006
Evaluation: Experiments
Exact phrase queries Limited to English
Inflections: Lauer Set: Carroll’s morphological tools Biomedical Set: UMLS Specialist
Lexicon

Invited talk: University of Toronto, 2006
Co-occurrence Statistics
Lauer set
Bio set
Invited talk: University of Toronto, 2006
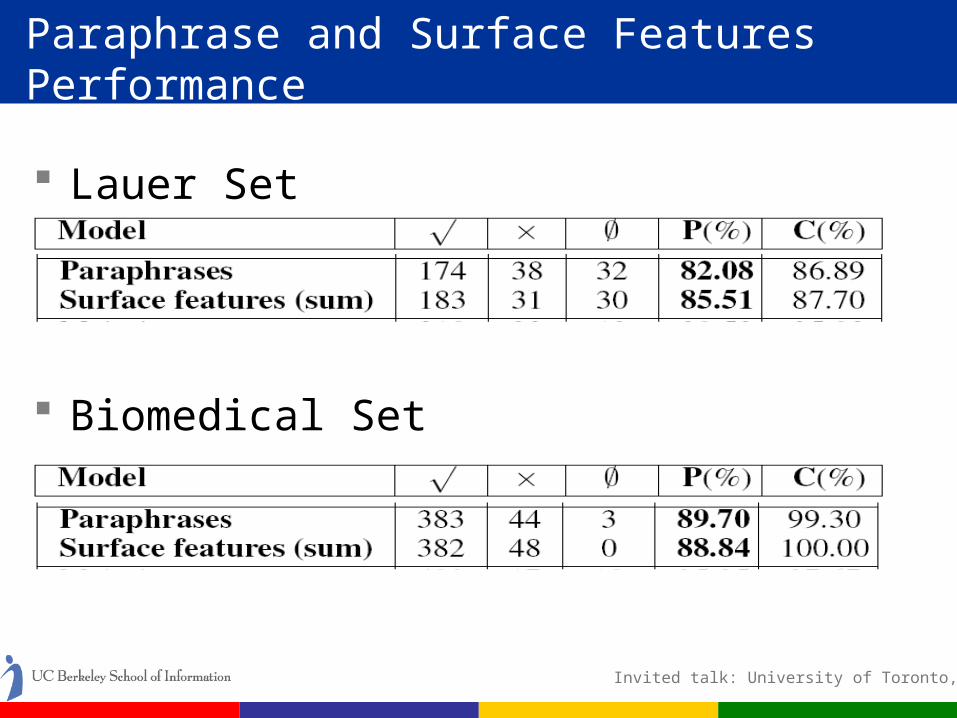
Paraphrase and Surface Features Performance
Lauer Set
Biomedical Set

Invited talk: University of Toronto, 2006
Individual Surface Features Performance: Bio

Invited talk: University of Toronto, 2006
Individual Surface Features Performance: Bio

Invited talk: University of Toronto, 2006
Results Lauer

Invited talk: University of Toronto, 2006
Results: Comparing with Others

Invited talk: University of Toronto, 2006
Results Bio

Invited talk: University of Toronto, 2006
Results for Noun Compound Bracketing
Introduced search engine statistics that go beyond the n-gram (applicable to other tasks) surface features paraphrases
Obtained new state-of-the-art results on NC bracketing more robust than Lauer (1995) more accurate than Keller&Lapata (2004)

Invited talk: University of Toronto, 2006
Prepositional Phrase Attachment
(a) Peter spent millions of dollars. (noun attach)
(b) Peter spent time with his family. (verb attach)
quadruple: (v, n1, p, n2)(a) (spent, millions, of, dollars)(b) (spent, time, with, family)

Invited talk: University of Toronto, 2006
Related Work
Supervised (Brill & Resnik, 94):
transformation-based learning, WordNet classes, P=82%
(Ratnaparkhi & al., 94): ME, word classes (MI),
P=81.6% (Collins & Brooks, 95): back-off, P=84.5% (Stetina & Makoto, 97):
decision trees, WordNet, P=88.1%
(Toutanova & al., 04): morphology, syntax, WordNet, P=87.5%
Unsupervised (Hindle & Rooth, 93):
partially parsed corpus, lexical associations over subsets of (v,n1,p), P=80%,R=80%
(Ratnaparkhi, 98): POS tagged corpus, unambiguous cases for (v,n1,p), (n1,p,n2), classifier: P=81.9%
(Pantel & Lin,00): collocation database, dependency parser, large corpus (125M words), P=84.3%
Unsup. state-of-the-art

Invited talk: University of Toronto, 2006
PP-attachment: Our Approach
Unsupervised (v,n1,p,n2) quadruples, Ratnaparkhi test set Google and MSN Search Exact phrase queries Inflections: WordNet 2.0 Adding determiners where appropriate Models:
n-gram association models Web-derived surface features paraphrases

Invited talk: University of Toronto, 2006
Web-derived Surface Features
Example features open the door / with a key verb (100.00%, 0.13%) open the door (with a key) verb (73.58%, 2.44%) open the door – with a key verb (68.18%, 2.03%) open the door , with a key verb (58.44%, 7.09%)
eat Spaghetti with sauce noun (100.00%, 0.14%) eat ? spaghetti with sauce noun (83.33%, 0.55%) eat , spaghetti with sauce noun (65.77%, 5.11%) eat : spaghetti with sauce noun (64.71%, 1.57%)
Summing achieves high precision, low recall.
P R
su
ms
um
compare

Invited talk: University of Toronto, 2006
Paraphrases
v n1 p n2
v n2 n1 (noun) v p n2 n1 (verb) p n2 * v n1 (verb) n1 p n2 v (noun) v PRONOUN p n2 (verb) BE n1 p n2 (noun)

Invited talk: University of Toronto, 2006
Evaluation
Ratnaparkhi dataset 3097 test examples, e.g.
prepare dinner for family Vshipped crabs from province V
n1 or n2 is a bare determiner: 149 examples problem for unsupervised methodsleft chairmanship of the Nis the of kind Nacquire securities for an N
special symbols: %, /, & etc.: 230 examples problem for Web queriesbuy % for 10 Vbeat S&P-down from % Vis 43%-owned by firm N

Invited talk: University of Toronto, 2006
Results
Simpler but not significantlydifferent from 84.3%(Pantel&Lin,00).
For prepositions other then OF.(of noun attachment)
Models in bold are combined in a majority vote.

Invited talk: University of Toronto, 2006
Noun Phrase Coordination
(Modified) real sentence: The Department of Chronic Diseases and Health Promotion
leads and strengthens global efforts to prevent and control chronic diseases or disabilities and to promote health and quality of life.

Invited talk: University of Toronto, 2006
NC coordination: ellipsis
Ellipsis car and truck production means car production and truck production
No ellipsis president and chief executive
All-way coordination Securities and Exchange Commission

Invited talk: University of Toronto, 2006
NC Coordination: ellipsis
Quadruple (n1,c,n2,h) Penn Treebank annotations
ellipsis:(NP car/NN and/CC truck/NN production/NN).
no ellipsis:(NP (NP president/NN) and/CC (NP chief/NN
executive/NN)) all-way: can be annotated either way
This is a problem a parser must deal with.
Collins’ parser always predicts ellipsis,but other parsers (e.g. Charniak’s) try to solve it.

Invited talk: University of Toronto, 2006
Results428 examples from Penn TB

Invited talk: University of Toronto, 2006
Conclusions
Tapping the potential of very large corpora for unsupervised algorithms Go beyond n-grams
Surface features Paraphrases
Results competitive with best unsupervised Results can rival supervised algorithms’
Future Work Unambiguous + Unlimited = Unsupervised How to extend to other problems?

Thank you!
http://biotext.berkeley.eduSupported in part by NSF DBI-0317510

Invited talk: University of Toronto, 2006
Using n-grams to make predictions
Say trying to distinguish: [home health] care home [health care]
Main idea: compare these co-occurrence probabilities “home health” vs “health care”

Invited talk: University of Toronto, 2006
Using n-grams to make predictions
Use search engines page hits as a proxy for n-gram counts compare Pr(w1w2|w2) to Pr(w1w3|w3)
Pr(w1 w2|w2 ) = #(w1,w2) / #(w2) #(w2) word frequency; query for “w2”
#(w1,w2) bigram frequency; query for “w1 w2”

Invited talk: University of Toronto, 2006
Probabilities: Why? (1)
Why should we use: (a) Pr(w1w2|w2), rather than (b) Pr(w2w1|w1)?
Keller&Lapata (2004) calculate: AltaVista queries:
(a): 70.49% (b): 68.85%
British National Corpus: (a): 63.11% (b): 65.57%

Invited talk: University of Toronto, 2006
Probabilities: Why? (2)
Why should we use: (a) Pr(w1w2|w2), rather than
(b) Pr(w2w1|w1)?
Maybe to introduce a bracketing prior. Just like Lauer (1995) did.
But otherwise, no reason to prefer either one. Do we need probabilities? (association is OK) Do we need a directed model? (symmetry is
OK)

Invited talk: University of Toronto, 2006
Adjacency & Dependency (2)
right bracketing: [w1[w2w3] ] w2w3 is a compound (modified by w1)
w1 and w2 independently modify w3
adjacency model Is w2w3 a compound?
(vs. w1w2 being a compound)
dependency model Does w1 modify w3?
(vs. w1 modifying w2)
w1 w2 w3
w1 w2 w3
w1 w2 w3

Invited talk: University of Toronto, 2006
Paraphrases: pattern (1)
(1)v n1 p n2 v n2 n1 (noun)
Can we turn “n1 p n2” into a noun compound “n2 n1”? meet/v demands/n1 from/p customers/n2 meet/v the customer/n2 demands/n1
Problem: ditransitive verbs like give gave/v an apple/n1 to/p him/n2 gave/v him/n2 an apple/n1
Solution: no determiner before n1 determiner before n2 is required the preposition cannot be to

Invited talk: University of Toronto, 2006
Paraphrases: pattern (2)
(2)v n1 p n2 v p n2 n1 (verb)
If “p n2” is an indirect object of v, then it could be switched with the direct object n1. had/v a program/n1 in/p place/n2 had/v in/p place/n2 a program/n1
Determiner before n1 is required to prevent
“n2 n1” from forming a noun compound.

Invited talk: University of Toronto, 2006
Paraphrases: pattern (3)
(3)v n1 p n2 p n2 * v n1(verb)
“*” indicates a wildcard position (up to three intervening words are allowed)
Looks for appositions, where the PP has moved in front of the verb, e.g. I gave/v an apple/n1 to/p him/n2 to/p him/n2 I gave/v an apple/n1

Invited talk: University of Toronto, 2006
Paraphrases: pattern (4)
(4)v n1 p n2 n1 p n2 v(noun)
Looks for appositions, where “n1 p n2” has moved in front of v shaken/v confidence/n1 in/p markets/n2 confidence/n1 in/p markets/n2 shaken/v

Invited talk: University of Toronto, 2006
Paraphrases: pattern (5)
(5)v n1 p n2 v PRONOUN p n2 (verb)
n1 is a pronoun verb (Hindle&Rooth, 93)
Pattern (5) substitutes n1 with a dative pronoun (him or her), e.g. put/v a client/n1 at/p odds/n2 put/v him at/p odds/n2
pronoun

Invited talk: University of Toronto, 2006
Paraphrases: pattern (6)
(6)v n1 p n2 BE n1 p n2 (noun)
BE is typically used with a noun attachment
Pattern (6) substitutes v with a form of to be (is or are), e.g. eat/v spaghetti/n1 with/p sauce/n2 is spaghetti/n1 with/p sauce/n2
to be