unit 12 correlation and regression mcgraw-hill, bluman, 7th ed., chapter 101
TRANSCRIPT

Unit 12
Correlation and Regression
McGraw-Hill, Bluman, 7th ed., Chapter 10 1

Chapter 12 Overview Introduction Scatter Plots and Correlation
Regression
Coefficient of Determination and Standard Error of the Estimate
Bluman, Chapter 10 2

Unit 12 Objectives1. Draw a scatter plot for a set of ordered pairs.
2. Compute the correlation coefficient.
3. Test the hypothesis H0: ρ = 0.
4. Compute the equation of the regression line.
5. Compute the coefficient of determination.
Bluman, Chapter 10 3

Introduction In addition to hypothesis testing and
confidence intervals, inferential statistics involves determining whether a relationship between two or more numerical or quantitative variables exists.
Bluman, Chapter 10 4

Introduction CorrelationCorrelation is a statistical method used
to determine whether a linear relationship between variables exists.
RegressionRegression is a statistical method used to describe the nature of the relationship between variables—that is, positive or negative, linear or nonlinear.
Bluman, Chapter 10 5

Introduction The purpose of this chapter is to answer
these questions statistically:
1. Are two or more variables related?
2. If so, what is the strength of the relationship?
3. What type of relationship exists?
4. What kind of predictions can be made from the relationship?
Bluman, Chapter 10 6

Introduction
1. Are two or more variables related?
2. If so, what is the strength of the relationship?
To answer these two questions, statisticians use the correlation coefficientcorrelation coefficient, a numerical measure to determine whether two or more variables are related and to determine the strength of the relationship between or among the variables.
Bluman, Chapter 10 7

Introduction
3. What type of relationship exists?
There are two types of relationships: simple and multiple.
In a simple relationship, there are two variables: an independent or input variable independent or input variable (predictor variable) and a dependent or output variable dependent or output variable (response variable).
In a multiple relationship, there are two or more independent variables that are used to predict one dependent variable.
Bluman, Chapter 10 8

Introduction
4. What kind of predictions can be made from the relationship?
Predictions are made in all areas and occur daily. Examples include weather forecasting, stock market analyses, sales predictions, crop predictions, gasoline price predictions, and sports predictions. Some predictions are more accurate than others, due to the strength of the relationship. That is, the stronger the relationship between variables, the more accurate the prediction.
Bluman, Chapter 10 9

Scatter Plots and Correlation A scatter plot scatter plot is a graph of the ordered
pairs (x, y) of numbers consisting of the independent variable x and the dependent variable y.
Bluman, Chapter 10 10

Example 1: Car Rental CompaniesConstruct a scatter plot for the data shown for car rental companies in the United States for a recent year.
Step 1: Draw and label the x and y axes.
Step 2: Plot each point on the graph.
Bluman, Chapter 10 11

Example 1: Car Rental Companies
Bluman, Chapter 10 12
Positive Relationship

Example 2: Absences/Final GradesConstruct a scatter plot for the data obtained in a study on the number of absences and the final grades of seven randomly selected students from a statistics class.
Step 1: Draw and label the x and y axes.
Step 2: Plot each point on the graph.Bluman, Chapter 10 13
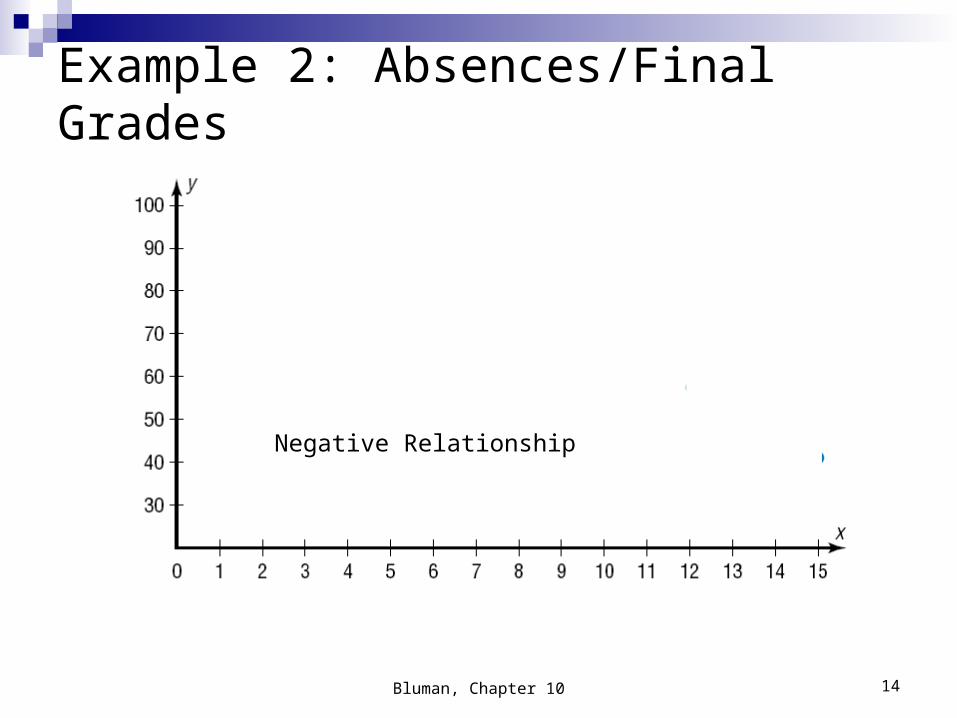
Example 2: Absences/Final Grades
Bluman, Chapter 10 14
Negative Relationship

Example 3: Exercise/Milk IntakeConstruct a scatter plot for the data obtained in a study on the number of hours that nine people exercise each week and the amount of milk (in ounces) each person consumes per week.
Step 1: Draw and label the x and y axes.
Step 2: Plot each point on the graph.
Bluman, Chapter 10 15
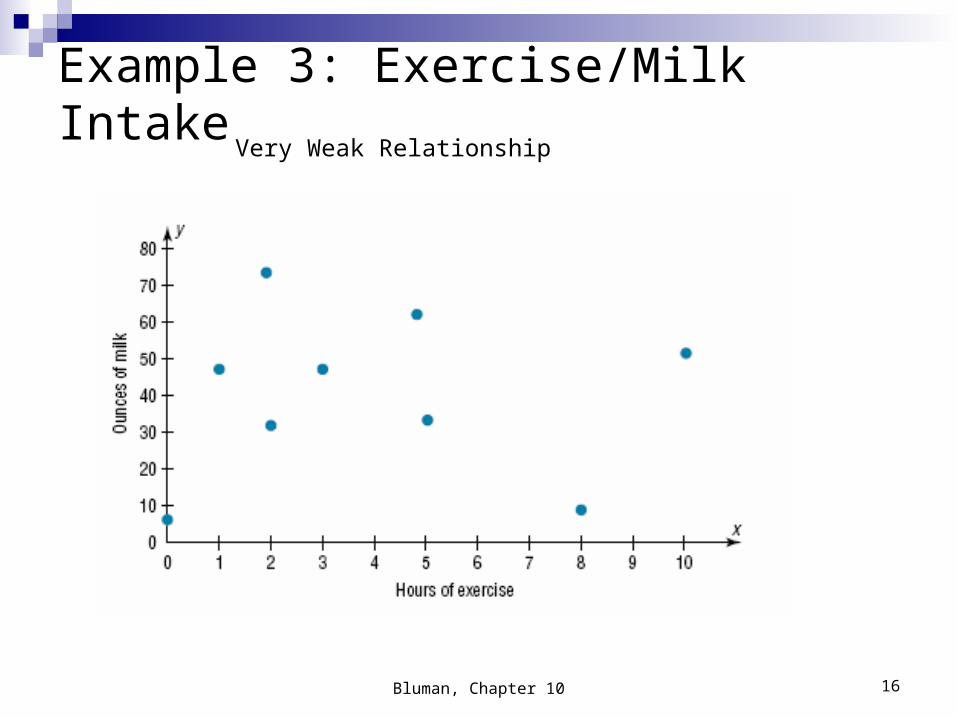
Example 3: Exercise/Milk Intake
Bluman, Chapter 10 16
Very Weak Relationship

Correlation The correlation coefficient correlation coefficient computed from
the sample data measures the strength and direction of a linear relationship between two variables.
There are several types of correlation coefficients. The one explained in this section is called the Pearson product moment Pearson product moment correlation coefficient (PPMC)correlation coefficient (PPMC).
The symbol for the sample correlation coefficient is r. The symbol for the population correlation coefficient is .
Bluman, Chapter 10 17

Correlation The range of the correlation coefficient is from
1 to 1. If there is a strong positive linear strong positive linear
relationship relationship between the variables, the value of r will be close to 1.
If there is a strong negative linear strong negative linear relationship relationship between the variables, the value of r will be close to 1.
Bluman, Chapter 10 18

Correlation
Bluman, Chapter 10 19

Correlation CoefficientThe formula for the correlation coefficient is
where n is the number of data pairs.
Rounding Rule: Round to three decimal places.
Bluman, Chapter 10 20
2 22 2
n xy x yr
n x x n y y

Example 4: Car Rental CompaniesCompute the correlation coefficient for the data in Example 10–1.
Bluman, Chapter 10 21
CompanyCars x
(in 10,000s)Income y(in billions) xy x2 y2
ABCDEF
63.029.020.819.113.48.5
7.03.92.12.81.41.5
441.00113.1043.6853.4818.762.75
3969.00841.00432.64364.81179.5672.25
49.0015.214.417.841.962.25
Σ x = 153.8
Σ y = 18.7
Σ xy = 682.77
Σ x2 = 5859.26
Σ y2 = 80.67

Example 4: Car Rental CompaniesCompute the correlation coefficient for the data in Example 10–1.
Bluman, Chapter 10 22
Σx = 153.8, Σy = 18.7, Σxy = 682.77, Σx2 = 5859.26, Σy2 = 80.67, n = 6
2 22 2
n xy x yr
n x x n y y
2 2
6 682.77 153.8 18.7
6 5859.26 153.8 6 80.67 18.7
r
0.982 (strong positive relationship)r

Example 5: Absences/Final GradesCompute the correlation coefficient for the data in Example 10–2.
Bluman, Chapter 10 23
StudentNumber of absences, x
Final Grade y (pct.) xy x2 y2
ABCDEF
6 215 9125
828643745890
492 172 645 666 696450
36 4225 8114425
6,7247,3961,8495,4763,3648,100
Σ x = 57
Σ y = 511
Σ xy = 3745
Σ x2 = 579
Σ y2 = 38,993
G 8 78 624 64 6,084

Example 5: Absences/Final GradesCompute the correlation coefficient for the data in Example 10–2.
Bluman, Chapter 10 24
Σx = 57, Σy = 511, Σxy = 3745, Σx2 = 579, Σy2 = 38,993, n = 7
2 22 2
n xy x yr
n x x n y y
2 2
7 3745 57 511
7 579 57 7 38,993 511
r
0.944 (strong negative relationship)r

Example 6: Exercise/Milk IntakeCompute the correlation coefficient for the data in Example 10–3.
Bluman, Chapter 10 25
Subject Hours, x Amount y xy x2 y2
ABCDEF
3 0 2 5 85
48 832641032
144 0 64 320 80160
9 0 4 25 6425
2,304 641,0244,096
1001,024
Σ x = 36
Σ y = 370
Σ xy = 1,520
Σ x2 = 232
Σ y2 = 19,236
G 10 56 560 100 3,136H 2 72 144 4 5,184I 1 48 48 1 2,304

Example 6: Exercise/Milk IntakeCompute the correlation coefficient for the data in Example 10–3.
Bluman, Chapter 10 26
Σx = 36, Σy = 370, Σxy = 1520, Σx2 = 232, Σy2 = 19,236, n = 9
2 22 2
n xy x yr
n x x n y y
2 2
7 1520 36 370
7 232 36 7 19,236 370
r
0.067 (very weak relationship)r

Hypothesis Testing In hypothesis testing, one of the following is
true:
H0: 0 This null hypothesis means that there is no correlation between
the x and y variables in the population.
H1: 0 This alternative hypothesis means that there is a significant correlation between the variables in the population.
Bluman, Chapter 10 27

t Test for the Correlation Coefficient
Bluman, Chapter 10 28
2
2
1
with degrees of freedom equal to 2.
nt r
r
n

Example 7: Car Rental CompaniesTest the significance of the correlation coefficient found in Example 10–4. Use α = 0.05 and r = 0.982.
Step 1: State the hypotheses.
H0: ρ = 0 and H1: ρ 0
Step 2: Find the critical value.
Since α = 0.05 and there are 6 – 2 = 4 degrees of freedom, the critical values obtained from Table F are ±2.776.
Bluman, Chapter 10 29

Step 3: Compute the test value.
Step 4: Make the decision. Reject the null hypothesis.
Step 5: Summarize the results. There is a significant relationship between the number of cars a rental agency owns and its annual income.
Example 7: Car Rental Companies
Bluman, Chapter 10 30
2
2
1
n
t rr 2
6 20.982 10.4
1 0.982

Example 8: Car Rental CompaniesUsing Table I, test the significance of the correlation coefficient r = 0.067, from Example 10–6, at α = 0.01.
Step 1: State the hypotheses.
H0: ρ = 0 and H1: ρ 0
There are 9 – 2 = 7 degrees of freedom. The value in Table I when α = 0.01 is 0.798.
For a significant relationship, r must be greater than 0.798 or less than -0.798. Since r = 0.067, do not reject the null.
Hence, there is not enough evidence to say that there is a significant linear relationship between the variables.
Bluman, Chapter 10 31

Possible Relationships Between Variables
When the null hypothesis has been rejected for a specific a value, any of the following five possibilities can exist.
1.There is a direct cause-and-effect relationship between the variables. That is, x causes y.
2.There is a reverse cause-and-effect relationship between the variables. That is, y causes x.
3.The relationship between the variables may be caused by a third variable.
4.There may be a complexity of interrelationships among many variables.
5.The relationship may be coincidental.
Bluman, Chapter 10 32

Possible Relationships Between Variables
1. There is a reverse cause-and-effect relationship between the variables. That is, y causes x.
For example, water causes plants to grow poison causes death heat causes ice to melt
Bluman, Chapter 10 33

Possible Relationships Between Variables
2. There is a reverse cause-and-effect relationship between the variables. That is, y causes x.
For example, Suppose a researcher believes excessive coffee
consumption causes nervousness, but the researcher fails to consider that the reverse situation may occur. That is, it may be that an extremely nervous person craves coffee to calm his or her nerves.
Bluman, Chapter 10 34

Possible Relationships Between Variables
3. The relationship between the variables may be caused by a third variable.
For example, If a statistician correlated the number of deaths
due to drowning and the number of cans of soft drink consumed daily during the summer, he or she would probably find a significant relationship. However, the soft drink is not necessarily responsible for the deaths, since both variables may be related to heat and humidity.
Bluman, Chapter 10 35

Possible Relationships Between Variables
4. There may be a complexity of interrelationships among many variables.
For example, A researcher may find a significant relationship
between students’ high school grades and college grades. But there probably are many other variables involved, such as IQ, hours of study, influence of parents, motivation, age, and instructors.
Bluman, Chapter 10 36

Possible Relationships Between Variables
5. The relationship may be coincidental.
For example, A researcher may be able to find a significant
relationship between the increase in the number of people who are exercising and the increase in the number of people who are committing crimes. But common sense dictates that any relationship between these two values must be due to coincidence.
Bluman, Chapter 10 37

Regression If the value of the correlation coefficient is
significant, the next step is to determine the equation of the regression line regression line which is the data’s line of best fit.
Bluman, Chapter 10 38

Regression
Bluman, Chapter 10 39
Best fit Best fit means that the sum of the squares of the vertical distance from each point to the line is at a minimum.

Regression Line
Bluman, Chapter 10 40
y a bx
2
22
22
where
= intercept
= the slope of the line.
y x x xya
n x x
n xy x yb
n x x
a y
b

Example 9: Car Rental CompaniesFind the equation of the regression line for the data in Example 10–4, and graph the line on the scatter plot.
Bluman, Chapter 10 41
Σx = 153.8, Σy = 18.7, Σxy = 682.77, Σx2 = 5859.26, Σy2 = 80.67, n = 6
2
22
y x x xya
n x x
22
n xy x yb
n x x
2
18.7 5859.26 153.8 682.77
6 5859.26 153.8
0.396
2
6 682.77 153.8 18.7
6 5859.26 153.8
0.106
0.396 0.106 y a bx y x

Find two points to sketch the graph of the regression line.
Use any x values between 10 and 60. For example, let x equal 15 and 40. Substitute in the equation and find the corresponding y value.
Plot (15,1.986) and (40,4.636), and sketch the resulting line.
Example 9: Car Rental Companies
Bluman, Chapter 10 42
0.396 0.106
0.396 0.106 15
1.986
y x
0.396 0.106
0.396 0.106 40
4.636
y x

Example 9: Car Rental CompaniesFind the equation of the regression line for the data in Example 10–4, and graph the line on the scatter plot.
Bluman, Chapter 10 43
0.396 0.106 y x
15, 1.986
40, 4.636

Use the equation of the regression line to predict the income of a car rental agency that has 200,000 automobiles.
x = 20 corresponds to 200,000 automobiles.
Hence, when a rental agency has 200,000 automobiles, its revenue will be approximately $2.516 billion.
Example 11: Car Rental Companies
Bluman, Chapter 10 44
0.396 0.106
0.396 0.106 20
2.516
y x

Regression The magnitude of the change in one variable
when the other variable changes exactly 1 unit is called a marginal changemarginal change. The value of slope b of the regression line equation represents the marginal change.
For valid predictions, the value of the correlation coefficient must be significant.
When r is not significantly different from 0, the best predictor of y is the mean of the data values of y.
Bluman, Chapter 10 45

Assumptions for Valid Predictions1. For any specific value of the independent
variable x, the value of the dependent variable y must be normally distributed about the regression line. See Figure 10–16(a).
2. The standard deviation of each of the dependent variables must be the same for each value of the independent variable. See Figure 10–16(b).
Bluman, Chapter 10 46

Extrapolations (Future Predictions) ExtrapolationExtrapolation, or making predictions beyond
the bounds of the data, must be interpreted cautiously.
Remember that when predictions are made, they are based on present conditions or on the premise that present trends will continue. This assumption may or may not prove true in the future.
Bluman, Chapter 10 47

Procedure TableStep 1: Make a table with subject, x, y, xy, x2, and
y2 columns.
Step 2: Find the values of xy, x2, and y2. Place them in the appropriate columns and sum each column.
Step 3: Substitute in the formula to find the value of r.
Step 4: When r is significant, substitute in the formulas to find the values of a and b for the regression line equation y = a + bx.
Bluman, Chapter 10 48

Coefficient of Determiation The coefficient of determination coefficient of determination is the
ratio of the explained variation to the total variation.
The symbol for the coefficient of determination is r 2.
Another way to arrive at the value for r 2 is to square the correlation coefficient.
Bluman, Chapter 10 49
2 explained variation
total variationr

Coefficient of Determination Coefficient of Determination The coefficient of determination is the ratio of the explained variation
to the total variation and is denoted by R2. That is, For the example, R2 =78.4/92.8 = 0.845. The term R2 is usually expressed as a percentage. So in this case, 84.5% of the total variation is explained by the regression line using the independent variable.
Another way to arrive at the value for R2 is to square the correlation coefficient. In this case, r = 0.919 and R2 =0.845, which is the same value found by using the variation ratio.
Bluman, Chapter 10 50

Coefficient of Determination
It is usually easier to find the coefficient of determination by squaring r and converting it to a percentage. Therefore, if r = 0.90, then R2 =0.81, which is equivalent to 81%. This result means that 81% of the variation in the dependent variable is accounted for by the variations in the independent variable. The rest of the variation, 0.19, or 19%, is unexplained. This value is called the coefficient of nondetermination and is found by subtracting the coefficient of determination from 1. As the value of r approaches 0, R2
decreases more rapidly. For example, if r 0.6, then R2 = 0.36, which means that only 36% of the variation in the dependent variable can be attributed to the variation in the independent variable.
Bluman, Chapter 10 51
Definition: The coefficient of determination is a measure of the variation of the dependent variable that is explained by the regression line and the independent variable. The symbol for the coefficient of determination is R2

Coefficient of Determination
Another definition: If R2 = 87%, for example, then 87% of the behavior of the regression is due to the input variable. A sometimes used definition: 87% of the prediction reliability of the regression equation is likely caused by the input variable. The remaining 13% is due to random interaction between the input and output variables.
Bluman, Chapter 10 52