universidade de lisboa faculdade de...
TRANSCRIPT

UNIVERSIDADE DE LISBOAFaculdade de Ciências
Departamento de Informática
SUBSTRATO DE COORDENAÇÃO E SERVIÇO DEDIRECTORIAS PARA SISTEMAS DE FICHEIROS
SEGUROS PARA CLOUD-OF-CLOUDS
Ricardo Samuel Portinha Mendes
DISSERTAÇÃO
MESTRADO EM ENGENHARIA INFORMÁTICAEspecialização em Arquitectura, Sistemas e Redes de Computadores
2012


UNIVERSIDADE DE LISBOAFaculdade de Ciências
Departamento de Informática
SUBSTRATO DE COORDENAÇÃO E SERVIÇO DEDIRECTORIAS PARA SISTEMAS DE FICHEIROS
SEGUROS PARA CLOUD-OF-CLOUDS
Ricardo Samuel Portinha Mendes
DISSERTAÇÃO
Dissertação orientada pelo Prof. Doutor Alysson Neves Bessanie co-orientada pelo Prof. Doutor Marcelo Pasin
MESTRADO EM ENGENHARIA INFORMÁTICAEspecialização em Arquitectura, Sistemas e Redes de Computadores
2012


Agradecimentos
Em primeiro lugar quero expressar, não só o meu agradecimento, mas também a minhaadmiração para com os meus orientadores, o Prof. Alysson Bessani e o Prof. MarceloPasin pois, para além da enorme quantidade de conhecimento que tive o privilégio dereceber destes, é admirável a relação informal e descontraída que mantiveram duranteeste ano, proporcionando um ambiente perfeito para o debate de ideias. É de louvar ofacto de terem mantido sempre a porta dos seus gabinetes aberta para me receber, a mime às minhas dúvidas. A eles o meu muito obrigado.
Em segundo lugar, quero agradecer também à minha família, nomeadamente aos meuspais e irmãos, por me passarem os valores pelos quais me rejo em todas as minhas de-cisões. Um agradecimento também à família Gomes pelo apoio e carinho com que metêm brindado nestes últimos anos.
Quero agradecer de uma forma muito especial ao Tiago Oliveira, pelas muitas ideiasdiscutidas no processo de desenvolvimento do trabalho apresentado neste documento, epelo companheiro e amigo que tem sido durante todos estes anos.
No meu percurso académico conheci muitas pessoas, algumas delas que, estou certo,ficarão para sempre como bons amigos. Um agradecimento ao Zabibo, Tó Zé, Fernand-inho, Reis, Rui Teixeira, Guns e Panka pelos muitos momentos bem passados que meproporcionaram durante estes anos. Ao João Martins, um grande amigo e parceiro detrabalhos durante a licenciatura e início de mestrado, um muito obrigado por tudo.
Agradeço também aos meus grandes amigos da minha terra natal. Ao Mário, aoCareca, ao “meu gordinho”, ao Chico, ao Varela, ao Fernando e à minha Cristininha,um muito obrigado pelos muitos momentos épicos que temos passado e pela força emmomentos menos bons.
Um agradecimento especial ao Diogo que, como um grande amigo que é, me ajudouno tratamento dos resultados apresentados na secção de avaliação deste documento.
Por fim, mas de maneira nenhuma menos importante, um muito obrigado à minhanamorada Inês que, mesmo com a minha falta de tempo, me congratula sempre com umsorriso e boa disposição. Um muito obrigado pelo apoio incondicional, pelo carinho epelo suporte.
A todos estes e aos demais que de alguma forma possam ter contribuído para o meusucesso, o meu mais sincero obrigado.
iii


À minha Inês e à minha Carolina.


Resumo
O C2FS (Cloud-of-Clouds File System) é um sistema de ficheiros distribuído quefornece aos programadores uma interface POSIX, e que tem por objectivo armazenar osdados numa cloud-of-clouds, utilizando vários provedores de armazenamento nas cloudsao invés de apenas um para aumentar a disponibilidade e privacidade dos dados.
Este projecto visa desenvolver dois dos serviços do C2FS: um serviço de directoriasdistribuído, que ofereça confidencialidade e disponibilidade dos metadados, controlo deacesso aos mesmos por parte de vários utilizadores e fortes garantias de tolerância a faltas;e um serviço de locks para coordenar o acesso aos ficheiros do sistema por parte de váriosprocessos escritores, de forma a garantir a consistência destes ficheiros.
Estes componentes do C2FS usam o DepSpace, um serviço de coordenação tolerantea faltas bizantinas que fornece uma abstracção de espaço de tuplos. Para a sua imple-mentação foi necessário alterar a API e arquitectura deste serviço, adicionando uma novaoperação que permite a substituição de tuplos e uma camada de suporte a Triggers.
Por questões de desempenho foram ainda desenvolvidas duas variações do serviçode directorias: uma que mantém, temporariamente, os metadados utilizados em cache, eoutra para a utilização do sistema sem partilha de ficheiros. Para além disso foi desen-volvido um mecanismo, chamado espaço de nomes pessoal, que permite, para além deaumentar o desempenho do serviço de directorias, diminuir a quantidade de informaçãomantida pelo mesmo.
Neste projecto, foi também desenvolvido um mecanismo que permite ao C2FS fornecergarantias de consistência forte mesmo recorrendo a clouds de armazenamento que fornecemapenas consistência eventual.
Foi ainda feita uma avaliação experimental que permite perceber, em termos de de-sempenho, qual é o custo de utilizar um serviço de coordenação para armazenar os metada-dos do sistema de ficheiros e se esse custo pode ser minimizado através do uso de umacache de metadados.
Palavras-chave: sistema de ficheiros, computação em clouds, armazenamento nasclouds, tolerância a faltas bizantinas.
vii


Abstract
C2FS (Cloud-of-Clouds File System) is a distributed file system that allows develop-ers to take advantage of its POSIX-like interface. It store file system data in a cloud-of-clouds, using several cloud storage providers (instead of only one) to improve the privacyand availability of the data.
The goals of this project are to develop two services to C2FS: a distributed and faulttolerant directory service, which maintain the C2FS’s metadata, ensuring its confiden-tiality, availability, and providing access control to this metadata by various users; and alock service to coordinate the accesses to files by several writers in order to ensure theconsistency of shared files.
This service uses DepSpace, a Byzantine fault tolerant coordination service that pro-vides a tuple space abstraction. To implement these services it was necessary to changethe API and architecture of DepSpace, adding a new operation to replace tuples and sup-port of triggers.
For performance reasons it was developed two directory service variations: one thattemporarily maintains the metadata used in cache, and another that allows users to usethe system without file sharing. Besides this, it was developed a mechanism, called per-sonal namespace, that decrease the amount of data stored by the service, increasing itsperformance for accessing non-shared files.
In this project was also developed a mechanism that allows C2FS to provide strongconsistency guaranties, even if cloud storage providers (used by the system to store itsdata) provide only eventual consistency guaranties.
Finally, it was made an experimental evaluation in order to understand, in terms of per-formance, what is the cost of use a coordination service to store the file system metadataand if that cost can be minimized through the use of a metadata cache.
Keywords: file system, cloud computing, cloud storage, Byzantine fault tolerance.
ix


Conteúdo
Lista de Figuras xv
Lista de Tabelas xvii
1 Introdução 11.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Objectivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Contribuições . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.4 Publicações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.5 Planeamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.6 Estrutura do Documento . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Trabalhos Relacionados 72.1 Serviços de Coordenação . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Chubby . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.1.2 Zookeeper . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.1.3 DepSpace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.1.4 Discussão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2 Sistemas de Ficheiros Distribuídos . . . . . . . . . . . . . . . . . . . . . 122.2.1 Ceph . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.2.2 WheelFS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2.3 Frangipani . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.2.4 Andrew File System . . . . . . . . . . . . . . . . . . . . . . . . 162.2.5 Coda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.2.6 Farsite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.3 Sistemas de Ficheiros para Clouds . . . . . . . . . . . . . . . . . . . . . 212.3.1 Frugal Cloud File System - FCFS . . . . . . . . . . . . . . . . . 222.3.2 BlueSky . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.3.3 S3FS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.3.4 S3QL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.4 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
xi

3 Metadados e Locks no C2FS 273.1 C2FS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.1.1 Arquitectura Geral . . . . . . . . . . . . . . . . . . . . . . . . . 273.1.2 Modelo de Sistema . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2 Metadados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.2.1 DepSpace . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.2.2 Serviço de Directorias . . . . . . . . . . . . . . . . . . . . . . . 333.2.3 Cache no Serviço de Directorias . . . . . . . . . . . . . . . . . . 363.2.4 Espaço de Nomes Pessoal . . . . . . . . . . . . . . . . . . . . . 403.2.5 Serviço de Directorias sem Partilha de Ficheiros . . . . . . . . . 41
3.3 Serviço de Locks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423.4 Consistência no C2FS . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4 Concretização dos Serviços de Directorias e de Locks do C2FS 474.1 Considerações Gerais . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474.2 Trigger de Substituição de Tuplos no DepSpace . . . . . . . . . . . . . . 494.3 Diagramas UML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.3.1 Diagrama de Classes . . . . . . . . . . . . . . . . . . . . . . . . 514.3.2 Diagramas de Sequência . . . . . . . . . . . . . . . . . . . . . . 524.3.3 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . 57
5 Avaliação Experimental 595.1 Metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 595.2 Número de Operações sobre os Metadados . . . . . . . . . . . . . . . . . 605.3 Desempenho dos Serviços de Directorias e Locks . . . . . . . . . . . . . 615.4 Desempenho do Serviço de Directorias sem Partilha de Ficheiros . . . . . 655.5 Desempenho com a utilização do Espaço de Nomes Pessoal . . . . . . . . 665.6 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
6 Conclusão 696.1 Trabalho futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
A Prova Informal do Serviço de Trincos 71
Bibliografia 78
xii


xiv

Lista de Figuras
2.1 Serviço de coordenação e serviço de comunicação em grupo. . . . . . . . 72.2 Arquitectura do Ceph [54]. . . . . . . . . . . . . . . . . . . . . . . . . . 132.3 Arquitectura do Frangipani. . . . . . . . . . . . . . . . . . . . . . . . . . 152.4 Arquitectura do AFS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.5 Arquitectura do BlueSky. . . . . . . . . . . . . . . . . . . . . . . . . . . 232.6 Arquitectura do S3FS. . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.1 Arquitectura do C2FS. . . . . . . . . . . . . . . . . . . . . . . . . . . . 283.2 Cloud-of-clouds. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.1 Diagrama de classes dos serviços de directorias e locks. . . . . . . . . . . 534.2 Diagrama de sequência de uma operação inserção de metadados . . . . . 544.3 Diagrama de sequência de uma operação de obtenção de metadados. . . . 554.4 Diagrama de sequência de uma operação de actualização de metadados. . 56
5.1 Latência das operações do DepSpace. . . . . . . . . . . . . . . . . . . . 625.2 Latência da obtenção de metadados. . . . . . . . . . . . . . . . . . . . . 635.3 Latência das operações do sistema de ficheiros. . . . . . . . . . . . . . . 645.4 Tempo de execução de benchmarks. . . . . . . . . . . . . . . . . . . . . 655.5 Latências de operações sobre o C2FS e tempos de execução dos bench-
marks usando o serviço de directorias sem partilha. . . . . . . . . . . . . 665.6 Latências de operações sobre o C2FS e tempos de execução dos bench-
marks com ficheiros pessoais. . . . . . . . . . . . . . . . . . . . . . . . . 67
xv


Lista de Tabelas
3.1 Interacção do serviço de directorias com o DepSpace. . . . . . . . . . . . 34
4.1 Número de linhas de código dos módulos desenvolvidos. . . . . . . . . . 49
5.1 Número de operações do sistema de ficheiros chamadas pelos benchmarks. 61
xvii


Capítulo 1
Introdução
A popularização dos serviços de armazenamento em clouds tem levado alguns uti-lizadores e empresas a exteriorizar o armazenamento dos seus dados, tirando partido detodas as vantagens que a utilização destes serviços fornece, como por exemplo a facilidadede acesso, o modelo de pagamento consoante o uso e ainda a ausência de investimentoinicial. Exemplos deste tipo de serviços são o DropBox [6], GoogleDrive [12], iCloud [5]e o Amazon S3 [4].
A utilização destes serviços levanta, no entanto, problemas no que diz respeito àdisponibilidade, integridade e privacidade dos dados. Problemas como a indisponibili-dade do provedor usado para armazenar os dados (ou da ligação até ele), o acesso irrestritopor parte do deste aos dados que armazena ou a possibilidade de o mesmo corromper osdados devido a faltas na sua infraestrutura (sejam estas maliciosas ou não), tornam in-viável a utilização destes serviços para armazenar dados sensíveis ou críticos. Há aindaum problema relacionado com o preço do serviço prestado pelos provedores. Estes po-dem aumentar o preço do serviço de tal forma que se torne impossível ao utilizador retirarde lá os seus dados, fenómeno este conhecido por vendor lock-in [21]. Uma outra questãoa ser levantada está relacionada com o modelo de acesso a este serviço por parte dasaplicações. Nos dias de hoje, o modelo mais comummente usado pelos provedores dearmazenamento para permitir às aplicações manusear dados na cloud é a disponibilizaçãode serviços web como o REST, SOAP ou XML-RPC que, embora não obriguem à trocaexplícita de mensagens, são sobretudo orientados ao controlo ao invés de orientados aosdados. Há ainda uma limitação importante relacionada com as garantias de consistên-cia oferecidas por estes serviços. A maioria dos serviços deste género fornece apenasgarantias de consistência eventual [51].
Tal como no caso dos serviços de armazenamento, também a crescente popularidadedos serviços de computação nas clouds tem levado os utilizadores e empresas a migraras suas aplicações para as clouds. A ausência de investimento inicial e de custos demanutenção com as máquinas, a possibilidade de adequar as características das máquinasutilizadas às necessidades da aplicação que estas correm, assim como o facto de não haver
1

Capítulo 1. Introdução 2
preocupação com upgrades nas máquinas que, com o tempo, vão ficando obsoletas, sãobons atractivos para quem deseja correr as suas aplicações de forma eficiente e barata.
Exemplos deste tipo de serviços são o Google App Engine [10], Microsoft WindowsAzure [13] e o Amazon EC2 [2].
No entanto, para que não tenhamos de confiar na segurança e fiabilidade das in-fraestruturas dos provedores do serviço de computação, é necessário que haja uma pre-ocupação extra com segurança e tolerância a faltas na construção das aplicações a sereminstaladas nestes serviços.
1.1 Motivação
A equipa dos Navigators está envolvida num projecto europeu chamado TClouds [17]que tem, entre outros, o objectivo de mitigar todas as limitações descritas na secção ante-rior. Neste âmbito foi recentemente desenvolvido o DepSky [24], um sistema que provaser possível reduzir os referidos problemas através do uso de múltiplos provedores in-dependentes, aliado a técnicas de tolerância a faltas e criptografia. Este sistema per-mite armazenar objectos (blocos opacos de dados associados a uma chave de acesso)numa cloud-of-clouds composta por vários provedores de tal forma que os dados sejamacessíveis e privados mesmo que uma fracção dos provedores estejam sujeitos a fal-tas bizantinas (exibindo um comportamento arbitrário, fora da sua especificação) [36].Porém, o DepSky disponibiliza uma interface de baixo nível que se assemelha a um discovirtual, disco este utilizado para armazenar blocos de dados.
Embora exista um leque muito grande de aplicações que podem tirar partido da inter-face ao nível do bloco disponibilizada pelo DepSky, esta interface é de difícil uso tantopor programadores (que constroem aplicações com armazenamento de dados na cloud-of-clouds) quanto por utilizadores, que apenas querem guardar os seus ficheiros na cloud deforma segura e fiável.
Dado isto, existe a necessidade de fornecer uma abstracção mais amigável que per-mita aos utilizadores e suas aplicações armazenar dados na cloud-of-clouds, minimizandoalterações nas aplicações e o esforço de aprendizagem por parte dos utilizadores. Umaabstracção que mitiga estas necessidades é a abstracção de sistema de ficheiros, na qualos utilizadores tendem a sentir-se confortáveis.
A ideia de armazenar os dados nas clouds já foi concretizada por outros sistemas deficheiros. Alguns exemplos são o S3FS [18], o S3QL [19], o BlueSky [52] e o FCFS [42].No entanto, estes sistemas têm a limitação de usar apenas um provedor de armazenamentona cloud, dependendo do mesmo nos vários aspectos referidos anteriormente (fiabilidade,disponibilidade, politicas de acesso, custos, entre outros).
Neste âmbito, surgiu o desafio de desenvolver um sistema de ficheiros distribuídotolerante a faltas bizantinas, tanto por parte das infraestruturas que armazenam os dados

Capítulo 1. Introdução 3
como das que armazenam os metadados, que permita a partilha de ficheiros controlada,que não exija confiança em nenhuma cloud de armazenamento individualmente e queforneça a garantia de consistência forte. A este sistema de ficheiros foi dado o nome deC2FS (Cloud-of-Clouds File System).
1.2 Objectivos
Os objectivos deste trabalho foram desenvolver um serviço de directorias e um serviçode locks para o C2FS, mostrar que estes serviços têm um desempenho aceitável, e aindadesenvolver um mecanismo que permita ao sistema oferecer a garantia de consistênciaforte mesmo recorrendo a clouds de armazenamento que fornecem apenas consistênciaeventual.
O serviço de directorias é responsável por armazenar os metadados do sistema deficheiros e por efectuar controlo de acesso aos seus recursos, enquanto que o serviço delocks é responsável por gerir escritas concorrentes sobre o mesmo ficheiro por parte dediferentes utilizadores. Para que se possam cumprir os requisitos do C2FS, ambos osserviços devem ser eficientes, seguros e tolerantes a faltas bizantinas.
Desta forma, a abordagem utilizada foi instalar um serviço de coordenação evoluídonas clouds de computação (como a Amazon EC2) e tirar vantagem desse serviço paradesenvolver os serviços de armazenamento e de locks. A utilização desta abordagemjustifica-se com o facto de os serviços de coordenação evoluídos permitirem implementarvárias premissas sobre eles, ao mesmo tempo que fornecem um bom desempenho e boasgarantias de tolerância a faltas.
Dadas as necessidades dos serviços já descritos, o serviço de coordenação escolhidofoi o DepSpace [23], um serviço de coordenação seguro e tolerante a faltas bizantinas quefornece uma abstracção de espaço de tuplos. Assim, um outro objectivo deste trabalhofoi o estudo das limitações, estrutura e desempenho deste serviço de coordenação, assimcomo, caso fosse necessário, a modificação do mesmo de acordo com as necessidades doC2FS.
1.3 Contribuições
As principais contribuições desta dissertação são:
• A modificação do serviço de coordenação DepSpace de forma a este suportar oper-ações de actualização de tuplos guardados no espaço.
• A modificação do DepSpace para que este suporte “Triggers” que executam váriasoperações de actualização de tuplos de uma forma atómica.

Capítulo 1. Introdução 4
• Um serviço de directorias para o C2FS que tem por base o DepSpace. Este serviçoherda todas as garantias do DepSpace logo é seguro, fiável e tolerante a faltasbizantinas. Para além de armazenar os metadados do C2FS, o serviço de direc-torias faz controlo de acesso aos recursos do sistema e permite reduzir o número deoperações feitas ao DepSpace (através do uso de uma cache de metadados).
• Um serviço de locks fiável, também ele desenvolvido tendo o DepSpace como base,que é usado pelo C2FS para coordenar escritas concorrentes de vários utilizadoressobre o mesmo ficheiro.
• A integração destes serviços com outros módulos do C2FS (como o serviço dearmazenamento [40]) em desenvolvimento paralelamente a este trabalho.
• Um mecanismo que permite ao C2FS fornecer uma semântica de consistência forte,mesmo estando assente sobre clouds que fornecem consistência eventual.
• Avaliação experimental dos módulos desenvolvidos com benchmarks utilizados naindústria.
1.4 Publicações
O trabalho descrito neste documento contribuiu para a publicação de um artigo cien-tífico no INForum 2012, na track “Computação Paralela, Distribuída e de Larga Es-cala” [38].
1.5 Planeamento
Inicialmente, o planeamento deste trabalho consistia nas seguintes tarefas:
• Tarefa 1 (Setembro de 2011): Revisão bibliográfica, estudo do DepSpace e famil-iarização com as tecnologias envolvidas na computação em clouds.
• Tarefa 2 (Outubro e Novembro de 2011): Desenho da abstracção de coordenação eserviço de directorias para um sistema de ficheiros e estudo da sua integração numprotótipo. Modificação do DepSpace para que este possa suportar as abstracçõesdesenhadas.
• Tarefa 3 (Dezembro de 2011 e Janeiro de 2012): Concretização dos serviços de co-ordenação e directorias para um sistema de ficheiros para cloud-of-clouds utilizandoa nova versão do DepSpace. Integração do trabalho feito com outros mecanismos,como por exemplo o armazenamento. Concretização do primeiro protótipo do sis-tema de ficheiros para cloud-of-clouds.

Capítulo 1. Introdução 5
• Tarefa 4 (Fevereiro de 2012): Instalação dos servidores do DepSpace nas clouds.Concretização do controlo de acesso no serviço de directorias usando a nova versãodo DepSpace, modificando-o se necessário.
• Tarefa 5 (Março de 2012): Estudo dos modelos de consistência e, caso exista ummodelo melhor, modificação do protótipo para integrar esse modelo.
• Tarefa 6 (Abril de 2012): Avaliação do sistema recorrendo a benchmarks para sis-temas de ficheiros utilizados na indústria.
• Tarefa 7 (Maio de 2012): Escrita da tese e de um artigo científico para um workshopou conferência de médio porte.
Este planeamento foi cumprido sensivelmente como descrito, excepto no caso daTarefa 7. O início desta tarefa foi atrasado devido à necessidade de um esforço extrapara a conclusão da tarefa anterior, pois, para atingir melhores resultados nas mediçõesefectuadas, foram incluídas algumas tarefas de optimização do protótipo. Estas tarefas deoptimização resultaram numa melhoria de desempenho bastante assinalável.
1.6 Estrutura do Documento
Este documento está organizado da seguinte forma:
• Capítulo 2 – Este capítulo descreve o trabalho relacionado com os serviços de-senvolvidos e com o sistema que irá fazer uso destes. Aqui são apresentados sis-temas de ficheiros, serviços de coordenação, sistemas de ficheiros para clouds e umserviço de directorias. Para todos eles são analisadas em especial detalhe todas ascaracterísticas que mais se relacionem com o presente trabalho.
• Capítulo 3 – Aqui é apresentado o C2FS, a sua arquitectura e o seu funcionamento,dando a conhecer o contexto no qual os serviços desenvolvidos são inseridos. Sãotambém descritos detalhadamente os serviços de directorias e de locks, explicando oseu funcionamento e potencialidades. É ainda explicado o mecanismo que permiteao C2FS fornecer consistência forte. Por fim, é introduzido o conceito de Espaçode Nomes Pessoal, a sua motivação e o seu funcionamento.
• Capítulo 4 – Apresentação dos detalhes de concretização do serviço de directoriase de locks.
• Capítulo 5 – Este capítulo contém uma avaliação preliminar feita ao serviço dedirectorias do C2FS. O comportamento deste é avaliado configurando a sua cachede diferentes formas com vista a mostrar as vantagens e desvantagens do uso damesma.

Capítulo 1. Introdução 6
• Capítulo 6 – Neste último capítulo são apresentadas as conclusões retiradas destetrabalho assim como algum trabalho a ser desenvolvido no futuro para melhorar asgarantias de consistência oferecidas pelo C2FS.

Capítulo 2
Trabalhos Relacionados
Nesta secção serão apresentados vários sistemas que de alguma forma relacionamcom o trabalho desenvolvido. Serão apresentados em primeiro lugar alguns serviços decoordenação, seguindo-se a apresentação de alguns sistemas de ficheiros distribuídos, umserviço de directorias e ainda dois sistemas de ficheiros para clouds.
2.1 Serviços de Coordenação
Os serviços de coordenação são serviços com grande utilidade no âmbito dos sistemasdistribuídos pois permitem manter informação de controlo ou de configuração de váriosprocessos num sistema deste tipo. Permitem também fazer sincronização distribuída.Desta forma, estes serviços permitem ao programador de aplicações distribuídas focar-semais no desenvolvimento da aplicação em si e não tanto no mecanismo de coordenaçãoentre os vários processos da sua aplicação, trazendo ganhos tanto no esforço necessáriono desenvolvimento deste tipo de aplicações como na fiabilidade das mesmas.
Figura 2.1: Serviço de coordenação e serviço de comunicação em grupo.
Na figura 2.1 podemos perceber a diferença existente entre um serviço de coorde-nação e um serviço de comunicação em grupo. Um serviço de comunicação em grupo,nos moldes do Appia [39], consiste numa abstracção em que cada participante está apto
7

Capítulo 2. Trabalhos Relacionados 8
a enviar mensagens para todos os outros participantes de um grupo. Por outro lado, umserviço de coordenação permite aos seus clientes, através da disponibilização de um ob-jecto com poder de coordenação, a possibilidade de efectuar eleição de líder, partilharestado, detectar falhas e até trocar mensagens entre vários processos. Nesta secção serãoapresentados alguns destes serviços.
2.1.1 Chubby
O Chubby [26] é um serviço de locks para sistemas distribuídos fracamente acopladosque tem como objectivo sincronizar as actividades de um grande número de clientes, aomesmo tempo que fornece boas garantias de disponibilidade e fiabilidade. Este serviço decoordenação foi desenvolvido pelo Google e é utilizado no Google File System [29] parafazer eleição de líder.
Este serviço de locks usa uma abstracção de sistema de ficheiros que permite aosclientes guardar pequenas quantidades de informação, ou seja, criar pequenos ficheiros,chamados nós. O uso desta abstracção reduz significativamente o esforço de aprendiza-gem dos programadores para a utilização deste serviço. Assim, o Chubby provê um con-junto de operações que podem ser chamadas recorrendo a um handle do Chubby. Estehandle é criado quando o cliente abre um ficheiro do serviço e destruído aquando dofecho do mesmo. O Chubby apenas permite ao cliente ler e escrever o conteúdo deum ficheiro na íntegra. Esta abordagem tem como objectivo desencorajar a criação deficheiros grandes.
Todos os nós do Chubby podem actuar como um lock, fornecendo este serviço doistipos de locks: os exclusivos e os partilhados, sendo que os locks exclusivos podem serusados para reservar recursos para escrita, enquanto que os partilhados para reservar umqualquer recurso para leitura. Os locks são de granularidade elevada (são validos porhoras ou mesmo dias). Segundo os autores, esta abordagem explica-se com a dificuldadede tolerar a falha dos servidores sem perder nenhum lock, aliado com a dificuldade detransferir locks entre clientes.
A arquitectura do Chubby tem dois componentes principais, a biblioteca cliente eos servidores, que comunicam entre si através de chamadas a procedimentos remotos(RPC). Estes servidores são agrupados em células Chubby, sendo usada replicação entreos servidores da célula para tolerar a falha de uma fracção destes. Cada célula Chubbytem um líder responsável por tratar todos os pedidos que a sua célula recebe.
É possível, não só ao cliente perceber quando o servidor Chubby falha, mas tambémao servidor detectar a falha de um cliente detentor de um lock. Para isso, uma sessão tem-porária entre um cliente e uma célula Chubby é mantida através de mensagens KeepAliveperiódicas. Quando o líder falha, um novo líder é eleito, através de um protocolo deconsenso [35].
Para maximizar o desempenho, o serviço permite que clientes do Chubby guardem

Capítulo 2. Trabalhos Relacionados 9
os dados e metadados dos nós numa cache guardada em memória local. Para manter aconsistência das caches, as operações de escrita são bloqueadas pelos servidores até todosos clientes serem notificados, e assim, invalidarem as suas caches.
Os clientes do Chubby podem também subscrever um conjunto de eventos. Quandoisto acontece, o cliente é notificado assincronamente quando a acção correspondente aoseventos subscritos acontece.
O controlo de acesso é feito associando uma ACL (access control list) a cada ficheiro.Esta lista mantém a informação de todos os utilizadores do serviço que estão aptos a ler eescrever no ficheiro, assim como quais estão aptos a modificar as permissões do mesmo.
Por questões de persistência dos dados, com a frequência de poucas horas, o servidorlíder de cada célula faz um backup da base de dados da sua célula para um servidor deficheiros GFS [29].
2.1.2 Zookeeper
O Zookeeper [32] é um serviço de coordenação que fornece um pequeno conjunto deprimitivas simples e gerais para armazenamento e coordenação, permitindo aos clientescriar primitivas de coordenação mais complexas como comunicação e gestão de grupos,registos partilhados e serviços de locks distribuídos. Desta forma, ao invés de implemen-tar primitivas de coordenação específicas, o Zookeeper fornece uma API que manipulaobjectos de dados wait-free, simples e organizados hierarquicamente, permitindo aos pro-gramadores criar as suas próprias primitivas de uma forma eficiente e tolerante a faltas.
No entanto, a propriedade wait-free não é suficiente para fornecer coordenação. Dev-ido a isto, este serviço fornece a possibilidade da utilização dos seus recursos com difer-entes garantias de ordem, nomeadamente, ordem para todas as operações de um cliente(FIFO) e ainda linearização para todos os pedidos que modifiquem o estado do sistema(usando o protocolo Zab [43]).
Este serviço utiliza uma abstracção de espaço de nomes hierárquico “estilo sistemade ficheiros”, onde uma colecção de objectos e dados, chamados znodes, são organizadosnuma árvore. No entanto, os znodes não foram desenhados para guardar um tipo qualquerde dados, mas sim alguma informação que pode ser útil numa computação distribuída,como por exemplo, metadados ou informações de configuração. Os znodes podem ser dedois tipos:
• os regulares, que após a sua criação necessitam ser eliminados explicitamente pelocliente.
• e os efémeros, que são eliminados pelo sistema quando a sessão com o cliente queos criou termina (deliberadamente ou em caso de falha do cliente) ou podem serapagados pelo cliente explicitamente.

Capítulo 2. Trabalhos Relacionados 10
O Zookeeper implementa watches, um mecanismo dirigido a eventos que pode sersubscrito pelos clientes. Este mecanismo permite ao cliente, após subscrição aos eventosde um znode, receber notificações quando esse znode é modificado. Um exemplo dautilidade deste mecanismo é a implementação da primitiva de invalidação de cache.
Para aumentar a disponibilidade, o serviço pode ser replicado entre várias máquinas.Uma das réplicas é o líder, sendo esta responsável por coordenar as escritas, ao passoque qualquer uma das réplicas pode responder de imediato a leituras. Periodicamente sãocriados snapshots do estado do sistema. Estes snapshots são usados para, quando umamáquina recupera após uma falha, recebe o snapshot com o estado do sistema, podendoactualizar os seus dados localmente e, então, começar a atender pedidos dos clientes.Para não ser necessário efectuar um snapshot a cada alteração do estado do sistema, estesnapshot é sempre acompanhado de uma lista das operações efectuadas após a criação dosnapshot mais actual. Note-se que este serviço assume apenas faltas por paragem e queas réplicas podem recuperar.
Para permitir aos servidores perceber quando um cliente falha, este envia mensagenschamadas heartbeats para manter a conexão aberta. Assim, quando o tempo sem rece-ber nenhum heartbeat ou qualquer outra mensagem excede um timeout predefinido, oservidor fecha a conexão, assumindo que o cliente falhou.
Os servidores resolvem todas as leituras usando um espaço de nomes hierárquicoguardado em memória. Este mecanismo ajuda o sistema a atingir um alto desempenhoem ambientes onde as leituras dominam sobre as escritas. Permite ainda que o serviçoseja altamente escalável no que diz respeito às leituras pois, visto cada servidor poderresolver localmente qualquer leitura, a cada réplica adicionada ao serviço, a quantidadede leituras suportadas aumenta. No entanto, por uma questão de durabilidade dos dados,todas as escritas são feitas no disco local dos servidores Zookeeper antes de serem escritasna cópia em memória volátil.
2.1.3 DepSpace
O DepSpace [23] é um serviço de coordenação tolerante a faltas bizantinas que forneceuma abstracção de espaço de tuplos [20] e que suporta comunicação desacoplada notempo e no espaço. Um espaço de tuplos é um objecto de memória partilhada que provêoperações para manipular dados em estruturas, chamadas tuplos, que guardam um con-junto de campos de tipos genéricos. Existem dois tipos de tuplos: entries, que têm todosos campos com valor definido; e templates, que têm alguns campos não definidos (rep-resentados com o wildcard ‘*’). Os templates são importantes porque permitem que ostuplos sejam endereçados pelo seu conteúdo, sem necessariamente saber o valor de todosos campos. Note-se que é ainda suportada a utilização de múltiplos espaços de tuplos.
Este serviço exporta um interface para os clientes que lhes permitindo operar sobreo espaço de tuplos. Esta interface aos clientes ler, escrever e remover tuplos do espaço,

Capítulo 2. Trabalhos Relacionados 11
através da disponibilização das operações RD, OUT e IN respectivamente. As operaçõesde leitura e remoção de tuplos podem ainda ser executadas de forma assíncrona, atravésdas operações RDP e INP. Existe ainda uma operação chamada CAS (conditional atomicswap) cuja semântica consiste em apenas inserir um determinado tuplo no espaço no casode não existir ainda nenhum tuplo que corresponda a um template dado. Esta operaçãoé importante pois fornece uma primitiva de coordenação que permite resolver proble-mas importantes como o consenso. Para isso, basta que cada cliente que tenha um valorpara propor tente inserir um tuplo no espaço com o valor da sua proposta utilizando aoperação CAS, sendo que o valor escolhido é o valor que permanece no espaço após to-dos os clientes terem feito a sua proposta. Esta interface e as garantias asseguradas peloDepSpace são apropriadas para coordenar clientes não confiáveis num sistema distribuído.
O DepSpace é constituído por um conjunto de servidores que, através da utilização devários mecanismos, garante a confidencialidade, disponibilidade e integridade dos tuplosarmazenados, mesmo na presença de servidores faltosos. Desta forma, o número de ré-plicas requeridas pelo DepSpace é de n ≥ 3f + 1, sendo n o número total de réplicas e f
o número de réplicas faltosas toleradas pelo serviço.
No que diz respeito à disponibilidade, é utilizada replicação para garantir que todosos servidores do DepSpace mantêm o mesmo estado. A estratégia de replicação usadaé a replicação de máquina de estados (que garante linearização), juntamente com deter-minismo das réplicas e com o protocolo de difusão com ordem total baseado no Paxosbizantino [47].
Para garantir confidencialidade, este serviço recorre ao PVSS (publicly verifiable se-cret sharing scheme) [46] juntamente com primitivas de criptografia para ter a certezade que apenas partes autorizadas terão acesso a um determinado tuplo em claro. Paraalém disto, todos os canais usados para comunicação entre os clientes e os servidores doDepSpace são canais fiáveis autenticados ponto-a-ponto, através do uso de TCP junta-mente com códigos de autenticação de mensagens.
O DepSpace não necessita de nenhuma suposição de tempo mas, devido ao uso demulticast com ordem total e por razões de liveness, uma sincronia eventual é requerida.
Não há decisões sobre controlo de acesso aos tuplos neste serviço, pois a melhoropção depende da aplicação. Em vez disto, o DepSpace usa uma camada chamada policyenforcement que fornece a possibilidade de definir políticas de acesso refinadas de acordocom as necessidades da aplicação [25]. Este tipo de política permite ao sistema decidirse uma operação é ou não válida baseando-se, não apenas no identificador do cliente queinvoca a operação, mas também, na operação chamada, os seus argumentos e ainda ostuplos actualmente guardados no espaço.
Além disso, o serviço possibilita a criação de tuplos temporários: tuplos que per-manecem no espaço por um tempo definido e, a menos que este seja revalidado (atravésda chamada da operação renew), são automaticamente removidos quando expirados.

Capítulo 2. Trabalhos Relacionados 12
2.1.4 Discussão
Nesta secção foram apresentados os serviços de coordenação estudados. Entre estesserviços, o ZooKeeper destaca-se no que diz respeito ao desempenho. Por outro lado,no que diz respeito à fiabilidade, o serviço estudado que mais se destaca é o DepSpacedevido às suas garantias de confidencialidade, integridade e tolerância a faltas bizantinas.Devido a isto, este foi o serviço de coordenação escolhido para servir de base aos serviçosde directorias e locks.
2.2 Sistemas de Ficheiros Distribuídos
Um sistema de ficheiros tem a função de criar uma estrutura lógica de acesso a dadosarmazenados numa memória secundária (como sendo um disco magnético, um serviço dearmazenamento, ou mesmo as clouds). Estes sistemas organizam os dados em ficheirosque, normalmente, são organizados numa árvore de directorias. A cada ficheiro ou direc-toria de um sistema de ficheiros estão associados um conjunto de informações chamadometadados. Nos metadados são mantidas, entre outras, informações sobre a localizaçãodos dados de cada ficheiro, o seu caminho na árvore de directorias ou o tamanho dos seusdados.
Nesta secção serão apresentados alguns dos sistemas de ficheiros estudados. Todosos sistemas apresentados têm uma natureza distribuída. Um sistema de ficheiros dis-tribuído permite aos utilizadores armazenar os seus dados numa localização remota deforma transparento, podendo estes utilizar este tipo de sistemas da mesma forma queutilizam um sistema de ficheiros local. Estes sistemas de ficheiros utilizam um modelocliente-servidor.
A escolha deste tipo de sistemas de ficheiros para serem descritos nesta secção é jus-tificada com o facto de estes apresentarem mais parecenças com o sistema de ficheirosonde este trabalho foi integrado que os sistemas de ficheiros centralizados.
2.2.1 Ceph
O Ceph [54] é um sistema de ficheiros distribuído que fornece um alto nível de escala-bilidade, fiabilidade e desempenho através do uso da separação entre a gestão de dados edos metadados, aliado com o uso de dispositivos de armazenamento de objectos (OSDs).
Os OSDs substituem a interface ao nível do bloco de dados por uma interface quepermite ao cliente ler e escrever grandes quantidades de dados (muitas vezes de tamanhovariável) sobre um objecto com um determinado nome, sem preocupações com repli-cação, serialização de actualizações, fiabilidade ou tolerância a falhas. Estes componentesfornecem um serviço de locks aos clientes que permite o acesso exclusivo a um determi-nado OSD. Isto é útil, por exemplo, para esconder latência através da aquisição do lock e

Capítulo 2. Trabalhos Relacionados 13
do envio dos dados assincronamente.Na figura 2.2 é apresentada a arquitectura do Ceph. Como podemos ver, o sistema
tem três componentes principais: o cliente, que pode ser um sistema de ficheiros montadono espaço do utilizador (recorrendo ao FUSE [8]) ou pode interagir directamente comos outros componentes; o cluster de OSDs, responsável por armazenar todos os dados emetadados; e o cluster de servidores de metadados (MDS) que faz a gestão do espaço denomes enquanto coordena a segurança, coerência e consistência dos ficheiros do sistema.
Figura 2.2: Arquitectura do Ceph [54].
O cluster de servidores de metadados tem uma arquitectura altamente distribuídabaseada na partição distribuída de sub-árvores, permitindo distribuir a responsabilidadede gestão hierárquica de directorias do sistema de ficheiros pelos MDSs. Esta abordagempermite ao Ceph aumentar a escalabilidade no acesso aos metadados, e assim, a escala-bilidade de todo o sistema.
Os clientes do Ceph fazem I/O sobre os ficheiros directamente com os OSDs. Istoé conseguido recorrendo à função CRUSH [53] que, através do identificador do ficheiro(inode), permite ao cliente saber qual OSD responsável por armazenar o ficheiro sobreo qual pretende operar. O inode é único e é obtido pelo cliente quando este chama aoperação open no MDS. O controlo de acesso aos ficheiros é também feito pelos MDSsaquando da chamada desta operação.
Por questões de eficiência, os MDSs satisfazem a maioria dos pedidos recorrendo àsua cache local, mas as operações de actualização dos metadados têm de ser armazenadasde forma persistente. Para isso, os MDSs usam os OSDs de forma eficiente para ar-mazenar os metadados.
Os clientes do Ceph armazenam em cache dados de ficheiros, sendo esta cache in-validada pelo MDS. Os MDSs invalidam a cache dos dados de um ficheiro em todos osclientes quando mais de um cliente abre um ficheiro para escrita. Quando isso acontece,o cliente detentor do lock é forçado a fazer todas as escritas e leituras sobre esse ficheirode forma síncrona.

Capítulo 2. Trabalhos Relacionados 14
2.2.2 WheelFS
O WheelFS [48] é um sistema de armazenamento distribuído com uma interfacePOSIX [16] desenhado para ser usado por aplicações distribuídas com o propósito departilhar dados e ganhar tolerância a faltas. Foi idealizado para manter quase todos osservidores sempre acessíveis, com falhas ocasionais, não tolerando faltas bizantinas. Emtermos de segurança, garante apenas controlo de acesso aos clientes e validação do con-junto de servidores participantes no sistema.
Este sistema de armazenamento permite aos clientes ajustar algumas configuraçõesdo sistema através do fornecimento de “pistas semânticas”. Estas permitem configurar ocomportamento do sistema no que diz respeito ao tratamento de faltas, localização dosficheiros e das réplicas, política de replicação e garantias de consistência. O facto de estaspistas serem especificadas nos caminhos dos ficheiros permite manter a interface POSIXinalterada, no entanto, pode levantar problemas em algumas aplicações que “partem” ocaminho do ficheiro e assumem que a pista é uma directoria.
O WheelFS armazena objectos do tipo ficheiro ou directoria, replicando cada ob-jecto por um conjunto de servidores, chamado slice, que utilizam replicação do tipo pri-mary/backup1 para gerir cada objecto.
Os metadados são mantidos por um serviço de configuração que é instalado de formaindependente num pequeno conjunto de máquinas que usa replicação de máquina de es-tados e usam Paxos para eleger um líder sempre que necessário. Este serviço mantémuma tabela de slices que guarda, para cada slice, a política de replicação e uma lista dereplicação que mantém o identificador dos servidores que estão a armazenar os objectosdessa slice em cada momento.
O serviço de configuração exporta um serviço de locks estilo Chubby [26] para serusado pelos servidores do sistema. Este serviço de locks permite aos servidores executaroperações de lock sobre uma determinada slice. Um lock sobre uma slice garante aoseu detentor o direito de ser o líder dessa slice, podendo assim especificar os valores deconfiguração durante este período. Os locks das slices são válidos por um período limitadode tempo, após o qual, tem de ser renovado.
Os clientes guardam a tabela de slices em cache de forma periódica, permitindo-lhesdescobrir, dentro de uma slice, quais os servidores que devem contactar para aceder a umdeterminado objecto. Nesta cache são também guardados dados de ficheiros. No entanto,antes de poderem utilizar os valores guardados em cache, os clientes têm que obter dosservidores um lease sobre o objecto. Os servidores revogam todos os leases sobre umficheiro a cada actualização para garantir a consistência de todas as caches.
O WheelFS fornece consistência ao fechar pois é o padrão esperado por muitas apli-cações.
1O servidor primário recebe as operações, propaga-as pelas réplicas de backup, e só depois responde aocliente.

Capítulo 2. Trabalhos Relacionados 15
2.2.3 Frangipani
O Frangipani [50] é um sistema de ficheiros distribuído que fornece várias garantiascomo escalabilidade, facilidade de administração, consistência dos ficheiros e disponibil-idade mesmo na presença de falhas. O Frangipani usa o Petal [37], um sistema de discosvirtuais, para armazenar os seus dados e metadados.
O Petal consiste numa colecção de servidores que, de uma forma cooperativa, geremum conjunto de discos físicos. Este exporta uma abstracção de discos virtuais nos quaisos clientes podem armazenar dados recorrendo a uma interface ao nível do bloco. Estesdiscos virtuais estão disponíveis a todos os clientes do sistema e podem ser criados com otamanho desejado pelo cliente, escondendo a capacidade total dos discos físicos geridospelo Petal. Este sistema de armazenamento apresenta bons valores de escalabilidade, tantono número de servidores que tratam os pedidos como na capacidade de dados suportada,através da adição de mais servidores ao sistema. Tem ainda um desempenho comparávelao de um disco local, ao mesmo tempo que permite tolerar e recuperar de falhas emqualquer componente do sistema, fornecer suporte para backup e recuperação, e fazerbalanceamento de carga de forma uniforme pelos servidores. Visto o Frangipani usar oPetal como o seu sistema de armazenamento, este herda todas as garantias descritas.
Figura 2.3: Arquitectura do Frangipani.
Na figura 2.3 é apresentada a arquitectura do Frangipani. Como podemos ver, osclientes acedem ao sistema usando uma interface de chamadas de sistema padrão fornecidapor servidores de ficheiros do Frangipani, instalados na mesma máquina que o cliente.Abaixo do servidor de ficheiros do Frangipani existem duas camadas: a driver do dis-positivo Petal e um serviço de locks distribuído. Note-se que os servidores do Frangipani

Capítulo 2. Trabalhos Relacionados 16
apenas comunicam com estas duas camadas, nunca havendo comunicação entre si.O driver do dispositivo Petal esconde a natureza distribuída do Petal e é usado pelos
servidores do Frangipani para aceder aos discos virtuais fornecidos pelos servidores doPetal e, assim, guardarem todos os dados e metadados do sistema de ficheiros. O Frangi-pani usa o grande e esparso espaço de disco fornecido pelo Petal para criar estruturas quefacilitam o armazenamento dos seus dados e metadados. Desta forma, o Frangipani utilizadiscos de 264 bytes que são divididos em regiões para armazenar parâmetros partilhados,logs, bitmaps de alocação, inodes e blocos de dados.
O serviço de locks distribuído permite ao Frangipani manter a consistência dos ficheirospartilhados e coordenar o acesso concorrente aos mesmos. Este serviço fornece locksdo tipo um-escritor/múltiplos-leitores sobre os blocos. Na realidade, uma limitação doFrangipani consiste no facto de, visto o petal exportar uma interface ao nível do bloco,apenas permitir reservar ficheiros inteiros ao invés de blocos de dados. Ao invés disto,uma abordagem mais interessante seria permitir reservar blocos de dados individual-mente, sendo possível que diferentes clientes pudessem escrever em blocos de dadosdiferentes do mesmo ficheiro em simultâneo.
Por questões de desempenho, os servidores do Frangipani mantêm uma cache dosdados lidos. Quando estes adquirem o lock para leitura sobre um ficheiro, estão entãoaptos para guardar em cache os dados lidos. Estes dados em cache são válido enquantonenhum servidor adquirir um lock de escrita sobre o mesmo ficheiro. Neste caso, vistoeste acontecimento representar uma possível alteração dos dados do ficheiro, é pedido atodos os servidores com o lock de leitura que libertem o lock e retirem os dados desseficheiro da sua cache.
2.2.4 Andrew File System
O Andrew File System (AFS) [44] é um sistema de ficheiros distribuído cujo desenho éfocado na transparência, suporte à heterogeneidade, escalabilidade e segurança. Este sis-tema de ficheiros foi desenhado nos anos 80 para permitir aos estudantes da Universidadede Carnegie-Mellon partilhar ficheiros entre si. Esta versão do AFS não está apta a supor-tar grandes bases de dados, sendo apenas adequada para suportar a partilha de ficheiroscom poucos megabytes entre relativamente poucos utilizadores (de 5000 a 10000).
A figura 2.4 apresenta a arquitectura do AFS. Como podemos observar, este é com-posto por dois componentes chave: o Vice e a Virtue. O Vice é uma colecção de recur-sos de comunicação e de computação, compostos por um conjunto de servidores semi-autónomos conectados entre si por uma LAN. Este sistema de ficheiros assume que todasas comunicações e computações dentro da Vice são seguros. A Virtue é uma estação detrabalho ligada a um dos servidores do Vice, servidor este responsável por interagir comos restantes servidores. Cada Virtue tem anexada a si uma outra entidade, chamada Venus,que é responsável pela comunicação com o Vice e por gerir a cache local. Dado isto, o sis-

Capítulo 2. Trabalhos Relacionados 17
Figura 2.4: Arquitectura do AFS.
tema, num todo, é composto por um conjunto de servidores que armazenam os ficheirosdo sistema, formando o já referido Vice. A cada um destes servidores podem estar lig-adas várias estações de trabalho, cada uma com uma Virtue. A decomposição do Vicenum conjunto de servidores existe para tratar o problema de escalabilidade. Assim, paraaumentar o número de clientes suportados basta adicionar mais servidores.
Por questões de desempenho, cada Virtue deve usar o servidor ao qual se encontraligada sempre que possível, reduzindo assim o tráfego entre servidores e os atrasos nasbridges que conectam os vários servidores, tudo isto ao mesmo tempo que fornece umbom balanceamento de carga.
Devido à natureza não confiável da Virtue, é necessária uma autenticação mutua entrea Virtue e o Vice antes de estabelecer uma conexão. Para isto é usada uma chave de encrip-tação partilhada entre estes de modo a obter uma chave de sessão. Esta chave de sessãoé gerada recorrendo a uma palavra-chave fornecida peço utilizador, e é posteriormenteutilizada para cifrar toda a comunicação entre o Vice e uma Virtue durante uma sessão.
Existem dois espaços de nomes onde os ficheiros podem ser armazenados: o espaçode nomes local, onde o disco local da estação de trabalho é utilizado; e o espaço de nomespartilhado, que recorre ao Vice para armazenar os ficheiros. No espaço de nomes localsão armazenados os ficheiros temporários, os ficheiros privados e os ficheiros usados parainicializar a conexão com o Vice. No espaço de nomes partilhado, visto ser comum atodos os utilizadores, contém todos os ficheiros partilhados por eles.
Para fornecer transparência da localização dos ficheiros, o Vice provê um mecanismopara localizar os ficheiros. Todos os servidores mantêm uma base de dados completa quemapeia cada ficheiro para um conjunto de guardiões. Um guardião de um ficheiro é umservidor pertencente ao Vice responsável por armazenar e por tratar todas as operações

Capítulo 2. Trabalhos Relacionados 18
feitas sobre esse ficheiro.No AFS são usadas transferências dos ficheiros na íntegra ao invés de transferências
de blocos individuais de ficheiros, sendo usado um modelo de consistência ao fechar.Esta abordagem permite, entre outras coisas, reduzir o número de acessos aos guardiõese a sobrecarga da rede. Para atingir melhor desempenho e diminuir o número de acessosfeitos aos servidores é utilizada cache do lado do cliente, neste caso a Virtue. Todas asleituras e escritas são feitas na cópia local do ficheiro, sendo este propagado na íntegrapara o Vice apenas quando o ficheiro é fechado. Nesta versão do AFS, a validação daconsistência da cache é feita quando o ficheiro é aberto (check-on-open).
Para garantir que apenas utilizadores autorizados podem aceder a um determinadoficheiro, o AFS fornece um mecanismo de controlo de acesso. Este replica uma basede dados por todos os servidores com a informação de quais utilizadores e grupos po-dem aceder a cada recurso. Assim, para garantir o acesso a um ficheiro por parte de umdeterminado utilizador é apenas necessário adicioná-lo à lista de acesso. Para facilitara revogação de direitos a um determinado utilizador, o AFS usa o conceito de DireitosNegativos nas listas de acesso. Isto permite adicionar à lista de direitos utilizadores quenão têm direitos de acesso de uma forma fácil e rápida.
O Vice fornece também um mecanismo que provê primitivas de lock do tipo um-escritor/múltiplos-leitores. Os locks obtidos através deste mecanismo têm uma naturezaconsultiva. No entanto, o Vice não requer a reserva de ficheiros antes do seu uso pois esteutiliza mecanismos que mantêm a consistência de um ficheiro mesmo este não estandoreservado.
2.2.5 Coda
O Coda [45] é um sistema de ficheiros distribuído de larga escala para estações detrabalho UNIX. É um descendente do Andrew File System (AFS) [31], mas fornece maisgarantias no que diz respeito aos aspectos de tolerância a faltas. Assim, este sistema deficheiros tem como objectivo manter constante a disponibilidade dos dados, permitindoaos utilizadores continuar a trabalhar sobre os ficheiros mesmo em caso de falha do servi-dor.
Desta forma, o Coda tira vantagem de algumas funcionalidades do AFS que con-tribuem para a sua segurança, fiabilidade e escalabilidade:
• os ficheiros mantidos em cache são transferidos e guardados na integra. O facto detodos os ficheiros serem guardados em cache facilita na tolerância a falhas da redeao mesmo tempo que fornece mobilidade.
• os clientes guardam também em cache alguns metadados, por exemplo, o identifi-cador dos servidores que mantêm os ficheiros guardados.

Capítulo 2. Trabalhos Relacionados 19
• é usada autenticação entre clientes e servidores antes de qualquer comunicação,sendo que todas as mensagens trocadas entre estes são cifradas.
• é usado um modelo onde poucos servidores seguros e confiáveis são acedidos porvários clientes não-confiáveis.
A invalidação da cache usa a mesma estratégia que a versão 2 do AFS [31], onde ummecanismo de callback é usado. Neste mecanismo, o servidor usado pelo cliente paraobter um ficheiro, promete enviar-lhe uma notificação (callback) quando esse ficheiro foralterado.
Para aumentar a disponibilidade e tolerância a faltas, o Coda usa servidores replicadose permite que os seus clientes façam operações mesmo não estando conectados a estes.No entanto, esta abordagem levanta o problema da possibilidade de existência de conflitosde versões em ficheiros partilhados por vários clientes. Neste caso, o sistema tenta emprimeiro lugar, resolver estes conflitos de forma automática e, caso tal não seja possível,este fornece uma ferramenta de reparação que permite aos clientes resolver os conflitosmanualmente.
A unidade da replicação do Coda é o volume, uma sub-árvore parcial do espaço denomes partilhado composto por ficheiros e directorias. Quando um volume é criado, éespecificada a informação sobre o grau de replicação deste e quais os servidores a seremutilizados para o armazenar. Esta informação é armazenada numa base de dados que épartilhada por todos os servidores. O conjunto de servidores que armazenam um volumeé chamado de volume storage group (VSG). Quando um volume é lido, este é guardadonuma cache no disco local do cliente. Por cada volume guardado em cache, o gestor dacache do cliente mantém um subconjunto chamado accessible VSG (AVSG) com todos osVSGs acessíveis a cada instante. Note-se que, para um mesmo volume, diferentes clientespodem ter diferentes AVSGs.
Para abrir um ficheiro, o cliente verifica se tem uma cópia válida desse ficheiro emcache. Caso isto não se verifique, então o ficheiro é obtido do membro do AVSG coma versão mais recente do ficheiro. Este servidor é chamado de “servidor preferido” e ocompromisso da recepção de um callback é estabelecido com ele.
Depois de uma modificação, o ficheiro é fechado e é então transferido em paralelopara todos os membros do AVSG. Devido ao facto de o Coda usar uma estratégia opti-mista, só após a transferência dos dados para os servidores, é feita uma verificação paratentar encontrar conflitos entre versões. Quando um conflito acontece, o Coda tenta, deuma forma automática, resolve-lo. Quando tal não é possível, o Coda marca o ficheirocomo inconsistente em todos os servidores que o armazenam, deixando para o utilizadora responsabilidade de resolver o conflito manualmente. O Coda fornece uma ferramentade reparação de conflitos com uma interface especial que permite operar sobre ficheiros edirectorias com inconsistências.

Capítulo 2. Trabalhos Relacionados 20
Este sistema de ficheiros garante que todos os clientes são informados com um atrasonunca superior a T segundos quando qualquer um dos seguintes eventos acontece:
• A redução do AVSG através da inacessibilidade de um servidor do AVSG.
• A extensão de um AVSG, ou seja, quando algum servidor passa de inacessível paraacessível.
• A perda de um evento callback.
Como vimos acima, as operações desconectadas permitem continuar a trabalhar sobreos ficheiros mesmo em caso de a conexão se ter perdido, aumentando, assim, a disponi-bilidade do sistema. As operações desconectadas começam quando um cliente não temnenhum membro no AVSG. Este modo é idealmente temporário e o cliente volta ao modonormal assim que possível. A mudança entre estes dois modos é transparente ao clienteexcepto no caso de faltar um ficheiro na cache (cache miss) no modo desconectado ou naocorrência de inconsistências no modo conectado.
A ocorrência de eventos de cache miss no modo normal é transparente aos utilizadores,no entanto, estes resultam numa diminuição do desempenho do sistema. Quando estesacontecem no modo de operação desconectado, o sistema bloqueia a computação até queconsiga reestabelecer a conexão e assim obter o ficheiro. Devido a isto é importante man-ter em cache todos os ficheiros sobre os quais o cliente queira operar. Neste contexto, oCoda permite aos utilizadores especificar uma lista de ficheiros (com diferentes níveis deprioridade) que devem ser mantidos em cache.
Em resumo, o Coda é um sistema de ficheiros altamente disponível, pois permiteoperar sobre ficheiros mesmo que não haja conexão com os servidores de forma transpar-ente. Este utiliza uma cache do lado do cliente, não sendo necessária troca de mensagensantes de a utilizar (devido à utilização de callbacks). É utilizada uma abordagem optimistano que diz respeito à existência de ficheiros inconsistentes, sendo fornecidos mecanismospara resolver este problema, tanto de forma automática como manual. O Coda faz ar-mazenamento conjunto dos dados e metadados.
2.2.6 Farsite
O Farsite [22] é um sistema de ficheiros distribuído fiável e fácil de administrar quefunciona como um servidor de ficheiros centralizado mas que é distribuído fisicamenteentre uma rede de máquinas. Este fornece facilidade de administração pois substitui oesforço dos administradores de sistema por processos automáticos. O Farsite protegee preserva os seus dados e metadados recorrendo a técnicas de criptografia e replicação.Para manter a privacidade, integridade e durabilidade dos dados, estes são cifrados e repli-cados pelos vários servidores do sistema, sendo também mantido um hash dos mesmos

Capítulo 2. Trabalhos Relacionados 21
juntamente com os dados e metadados. Por outro lado, os metadados do sistema neces-sitam ter alguns campos em claro. Assim, estes são mantidos por máquinas de estadoreplicadas tolerantes a faltas bizantinas, que garante a disponibilidade e integridade dosdados, e é utilizada criptografia para cifrar os nomes dos ficheiros ou directorias do sis-tema, mantendo estes campos imperceptíveis aos clientes não autorizados.
Para impedir clientes maliciosos de criar ficheiros ou directorias com nomes que, apósserem decifrados, são sintaticamente ilegais é utilizada uma técnica chamada exclusiveencription [27] que garante a decifração de nomes apenas gera nomes legais. Para efectuarcontrolo de acesso, os metadados do sistema mantêm uma ACL com informações sobreas permissões dos clientes sobre cada ficheiro ou directoria.
Em [28] é apresentado um novo serviço de directorias para o Farsite que fornecetodas garantias que o anterior serviço fornecia, fornecendo ainda uma melhoria no quediz respeito à escalabilidade. Isto é conseguido particionando os metadados entre váriosservidores e utilizando mitigação de pontos críticos (hotspots).
Este serviço de directorias divide os metadados pelos vários servidores tendo em contao identificador do ficheiro (imutável e invisível ao utilizador). Esta abordagem simplificao problema da alteração do nome de ficheiros pois cada servidor é responsável por umficheiro (ou conjunto de ficheiros) com um identificador imutável.
Para lidar com actualizações aos metadados são utilizados leases. Estes leases podemser de escrita ou de leitura. Quando um cliente pretende efectuar uma operação sobre osmetadados de um ficheiro, este tem de, não só obter uma cópia dos metadados sobre osquais pretende operar, mas também obter um lease sobre os mesmos. Durante o tempo devalidade do lease, o cliente pode ler ou alterar os valores dos metadados (dependendo seo lease foi apenas para leitura ou se permite também modificações). No caso dos leasesde escrita, o servidor perde a autoridade sobre os metadados enquanto o lease for válido.
Nesta nova versão do serviço de directorias do Farsite, os leases dizem respeito, nãosobre todos os campos dos metadados de um ficheiro, mas apenas sobre um campo dosmesmos. Esta abordagem permite mitigar pontos críticos. Este serviço de directoriaspermite ainda, por questões de desempenho, que os clientes guardem em cache quais osservidores que armazenam os metadados de cada ficheiro.
2.3 Sistemas de Ficheiros para Clouds
Como já foi referido, hoje em dia muitas empresas têm migrado os seus serviços paraas clouds com o objectivo de reduzirem custos no que diz respeito ao investimento emequipamentos e em manutenção dos mesmos. Um dos serviços críticos numa empresa é oseu sistema de ficheiros, utilizado pelos seus colaboradores para manter os seus ficheiros.Visto o trabalho descrito neste relatório ter sido integrado num sistema de ficheiros paraclouds, nesta secção serão descritos dois sistemas de ficheiros deste tipo.

Capítulo 2. Trabalhos Relacionados 22
2.3.1 Frugal Cloud File System - FCFS
O FCFS [42] é um sistema de ficheiros vocacionado a optimizar os custos inerentes àutilização dos serviços de armazenamento das clouds. Este sistema tira partido da utiliza-ção de vários destes serviços para reduzir os custos da sua utilização.
Os serviços de armazenamento apresentam diferentes preços no que diz respeito aoarmazenamento e à transferência dos dados. Os autores do FCFS apresentam como exem-plos os custos de transferência e armazenamento do Amazon S3 [4], Amazon EBS [1] eAmazon ElastiCache [3]. O Amazon S3 tem um custo de armazenamento baixo, mas umcusto de transferência elevado, enquanto que o Amazon EBS tem um custo de armazena-mento relativamente elevado e um custo de transferência relativamente baixo. Por fim, oAmazon ElastiCache tem um custo de armazenamento muito elevado, não havendo custosassociados à transferência de dados. É importante notar que o custo de armazenamentonestes serviços reflecte também a o seu desempenho, nomeadamente, a latência. Assim,quanto menor o custo de armazenamento de um serviço, maior o custo de transferênciados dados por si armazenados e maior a latência de acesso aos mesmos.
Neste âmbito, este sistema reduz os custos de armazenamento dos dados nas cloudsatravés da transferência dos dados entre os vários serviços de armazenamento de acordocom a carga de trabalho do sistema. A abordagem utilizada consiste em utilizar dois níveisde armazenamento dos dados. No início, todos os dados são armazenados no serviçoonde o armazenamento é mais barato (como é o caso do Amazon S3), sendo este nívelde armazenamento denominado de disco. Visto as transferências serem muito caras nesteserviço, quando há muita carga de trabalho sobre um determinado ficheiro, este é trans-ferido para um serviço onde as transferências sejam mais baratas (como o Amazon EBS),sendo este nível de armazenamento chamado de cache. Desta forma, quando há muitosacessos a um ficheiro, este é trazido para a cache onde, para além de oferecer um maiordesempenho, o aumento dos custos inerentes ao seu armazenamento são rentabilizadospelo dinheiro poupado no acesso a ele.
No Amazon EBS, os ficheiros são mantidos em volumes de disco. Estes volumes sãoajustáveis no que diz respeito ao tamanho, sendo importante mantê-los o mais pequenospossível para minimizar os custos. Quando não é rentável aumentar o tamanho do volumepara armazenar mais ficheiros em cache, são usadas políticas de substituição de cache(como o LRU2) para seleccionar os ficheiros a substitui-los na cache por outros que sejammais úteis naquele instante.
Este sistema tem a importante limitação de, para poder usufruir de alguns dos serviçosde armazenamento na cloud de um provedor, nomeadamente o Amazon EBS e o Ama-zon ElastiCache, necessita ter acesso a instâncias de computação fornecidas pelo mesmoprovedor. Esta necessidade acrescenta custos à utilização deste sistema.
Não é apresentado nenhum mecanismo que permita a partilha controlada de ficheiros
2Substitui o objecto em cache que, no instante da substituição, não é utilizado há mais tempo.

Capítulo 2. Trabalhos Relacionados 23
entre vários utilizadores, assim como não é apresentada qualquer informação sobre comosão mantidos os metadados do FCFS. Uma outra limitação a ter em conta é o facto nãohaver nenhuma preocupação com tolerância a faltas do provedor do serviço de armazena-mento nas clouds utilizado pelo sistema.
2.3.2 BlueSky
O BlueSky [52] é um sistema de ficheiros de rede com armazenamento na cloud,desenhado para servir um conjunto de utilizadores num contexto empresarial. Este sis-tema tira partido das garantias de disponibilidade e vasta capacidade de armazenamentofornecidas pelos serviços de armazenamento nas clouds.
A figura 2.5 apresenta a arquitectura do BlueSky. Como podemos ver na figura, osclientes acedem aos dados armazenados através de um proxy que suporta os protocolosNFS (versão 3) e CIFS, dando aos clientes a ilusão de estarem a comunicar com umservidor de ficheiros tradicional. Este componente está situado entre os clientes e osprovedores de armazenamento na cloud. Idealmente, o proxy deve estar instalado namesma rede que os clientes, de forma a reduzir a latência da comunicação entre eles.
Figura 2.5: Arquitectura do BlueSky.
Todas as escritas efectuadas sobre ficheiros do BlueSky são tratas localmente peloproxy. Para isso, ele escreve os novos dados no seu disco local, respondendo ao clientede seguida. Estes novos dados são enviados periodicamente para a cloud de forma assín-crona. No entanto, esta abordagem pode levar a que, em caso de falha do proxy e do seudisco local, algumas escritas não sejam propagadas para a cloud.
Para tratar das leituras localmente, o proxy mantém uma cache que lhe permite trataralguns pedidos. Quando os dados a serem lidos não estão em cache, estes são obtidosda cloud e armazenados na cache local. Visto o proxy ter uma capacidade de disco limi-tada, quando o número de ficheiros em cache atinge um limite pré-definido, é utilizada apolítica LRU para seleccionar o ficheiro a ser substituído.
O proxy permite a partilha controlada de ficheiros entre os clientes a si ligados. Noentanto, em caso de falha deste componente, todos os clientes deixam de ter acesso aosseus ficheiros. Note-se ainda que, na versão do BlueSky apresentada, é apenas permitidaa existência de uma instância deste componente, não podendo os clientes, em caso defalha do proxy, ligar-se a uma outra instância para ter acesso aos seus dados. O BlueSky

Capítulo 2. Trabalhos Relacionados 24
tem também a limitação de usar apenas uma cloud para armazenar os dados, dependendodesta em vários aspectos, nomeadamente no que diz respeito à disponibilidade dos dadosdo sistema.
O BlueSky utiliza um esquema de dados estruturado num log, sendo este log ar-mazenado na cloud. Existem quatro tipos de objectos que representam dados e metadadosneste log: blocos de dados, inodes, mapas de inomes e checkpoints. Os blocos de dadossão utilizados para armazenar os dados dos ficheiros. O BlueSky utiliza blocos fixos de 32KB. Por sua vez, os inodes são utilizados para armazenar os metadados de cada ficheiro,como por exemplo as permissões de acesso, o identificador do seu dono e uma lista deapontadores para os seus blocos de dados. Os mapas de inodes listam a localização daversão mais recente de cada inode no log, ao passo que cada checkpoint mantém a lo-calização no log dos mapas de inodes em uso. Este último objecto é útil para mantera integridade do sistema mesmo em caso de falha do proxy pois, visto este objecto sersempre um dos últimos a ser escrito, basta ao proxy localizar este objecto para estar aptoa obter os metadados dos ficheiros mais recentes.
Por questões de segurança, os objectos armazenados no log são cifrados individual-mente (com AES) e protegidos com códigos de autenticação de mensagens (com HMAC-SHA-256) pelo proxy antes de serem enviados para a cloud, mantendo a integridade econfidencialidade dos dados armazenados. No entanto, é necessário um certo nível deconfiança no provedor de armazenamento, pois este está habilitado a eliminar ou cor-romper os dados, causando a indisponibilidade dos mesmos.
Como qualquer sistema de ficheiros estruturado em log, é necessária a existência deum colector de lixo para apagar dados desactualizados. O BlueSky utiliza um colector delixo que tanto pode estar instalado no proxy como numa cloud de computação fornecidapelo mesmo provedor que armazena os dados. A segunda solução permite que o colectorefectue a sua tarefa mais rápido e com menos custos.
2.3.3 S3FS
O S3FS é um sistema de ficheiros para sistemas operativos UNIX que utiliza o AmazonS3 [4] para armazenar os dados. Como podemos ver na figura 2.6, este sistema é montadona máquina local (utilizando o FUSE [8]) do cliente que acede directamente à cloud. Estesistema tem a limitação de não permitir a partilha controlada de ficheiros entre diferentesutilizadores, i.e., não controla o acesso aos mesmos por parte de diferentes processosescritores. Tal como os anteriores sistemas de ficheiros para clouds apresentados, tambémo S3FS tem a limitação de usar apenas um provedor de armazenamento na cloud, nãotolerando faltas do mesmo.
É possível ao cliente configurar o sistema para utilizar uma cache local, mantida emdisco, para aumentar o desempenho deste. É utilizada uma semântica de consistência aofechar, sendo cada ficheiro obtido da cloud para a cache aquando da sua abertura e escrito

Capítulo 2. Trabalhos Relacionados 25
Figura 2.6: Arquitectura do S3FS.
no seu fecho. Assim, todas as escritas e leituras efectuadas sobre um determinado ficheirosão feitas localmente. Quando a transferência dos dados de um ficheiro para a cloud nãotem sucesso, o sistema volta a tentar duas vezes antes de abortar a transferência e devolverum erro. Note-se que os ficheiros são transferidos na íntegra.
A cache dos dados mantida em disco pode crescer de tal forma que ocupe todo oespaço deste, sendo da responsabilidade do cliente seleccionar os ficheiros a remover dacache para libertar espaço. O S3FS mantém também uma cache em memória principalcom os metadados dos ficheiros.
2.3.4 S3QL
O S3QL é um sistema de ficheiros que armazena os dados na clouds, podendo este serconfigurado para utilizar o Google Storage [11], o Amazon S3 [4] ou o OpenStack CloudFiles [14]. Este sistema pode ser montado em sistemas de ficheiros UNIX.
Tal como o S3FS, também este sistema é montado na máquina local do cliente queacede directamente à cloud, não permitindo partilha controlada de ficheiros entre uti-lizadores e dependendo do provedor de armazenamento em vários aspectos, nomeada-mente na disponibilidade dos dados.
Este sistema utiliza uma base de dados local como cache para armazenar tanto dadoscomo metadados, sendo todas as operações de metadados feitas sobre esta base de dados.Os dados dos ficheiros de sistema são armazenados na cache e na cloud em blocos depequena dimensão. Esta abordagem permite optimizar o desempenho do sistema e aindadiminuir os custos associados ao envio e obtenção de dados da cloud pois apenas sãotransferidos os blocos sobre os quais se pretende operar. Todos os envios feitos para acloud são feitos de forma assíncrona.
Para reduzir a quantidade de informação transferida para garantir a confidencialidadedos dados, antes de enviar os dados para a cloud, o sistema comprime os dados (utilizandoos mecanismos de compressão LZMA ou bzip2) e cifra os mesmos (utilizando a técnicaAES com chave de 256 bits). Para garantir a integridade dos dados, o S3QL mantémlocalmente um resumo criptográfico de cada bloco armazenado na cloud. Assim, quandoobtém os dados, o sistema compara o resumo criptográfico dos dados lidos com o resumoguardado localmente podendo, desta forma, perceber se estes dados foram corrompidos.
O S3QL fornece ainda um mecanismo que permite efectuar backup de directorias.

Capítulo 2. Trabalhos Relacionados 26
2.4 Considerações Finais
Neste capítulo foram apresentados vários sistemas que, de alguma forma, estão rela-cionados com o trabalho desenvolvido neste projecto. No próximo capítulo será apresen-tado esse trabalho, sendo em primeiro lugar descrito o contexto no qual este foi integrado,através da apresentação do C2FS como um todo, sendo em seguida dada ênfase à de-scrição detalhada do substrato de coordenação (concretizado num serviço de locks) e doserviço de directorias.

Capítulo 3
Metadados e Locks no C2FS
Neste capítulo são apresentados o mecanismo utilizado para gerir os metadados noC2FS, assim como é garantida a consistência dos seus ficheiros. Em primeiro lugar é ap-resentado o C2FS como um todo para fornecer o contexto do ambiente no qual o trabalhodesenvolvido foi integrado. Em seguida são apresentadas várias versões do serviço de di-rectorias utilizado para armazenar os dados, assim como o serviço de locks desenvolvido.Para o desenvolvimento destes serviços, foi necessário adicionar algumas funcionalidadesnovas ao DepSpace [23], sendo estas também explicadas em detalhe neste capítulo.
3.1 C2FS
O C2FS é um sistema de ficheiros com interface POSIX [16] que armazena os dadosnuma cloud-of-clouds, recorrendo ao DepSky [24]. Este sistema garante a privacidade,integridade e disponibilidade dos dados, admitindo que uma fracção dos provedores de ar-mazenamento utilizados falhe de forma Bizantina. Os metadados são armazenados recor-rendo ao um serviço de coordenação também tolerante a faltas bizantinas [23], que garanteque os metadados são armazenados de forma segura.
3.1.1 Arquitectura Geral
A figura 3.1 apresenta a arquitectura do C2FS e a estrutura dos seus serviços. Como sepode observar, na base da arquitectura temos o módulo FUSE [8]. Este módulo é respon-sável por interceptar as chamadas ao sistema operativo referentes a recursos do C2FS.Estas chamadas são entregues ao agente C2FS. Neste sistema é usada uma concretizaçãodo FUSE em Java, chamada FUSE-J [9].
O agente C2FS é responsável por interagir com os serviços de armazenamento, lockse directorias de acordo com a chamada recebida do módulo FUSE. Uma das tarefas destetrabalho era a integração dos serviços de directorias e de locks com o serviço de armazena-mento. Esta tarefa foi concretizada neste componente.
27
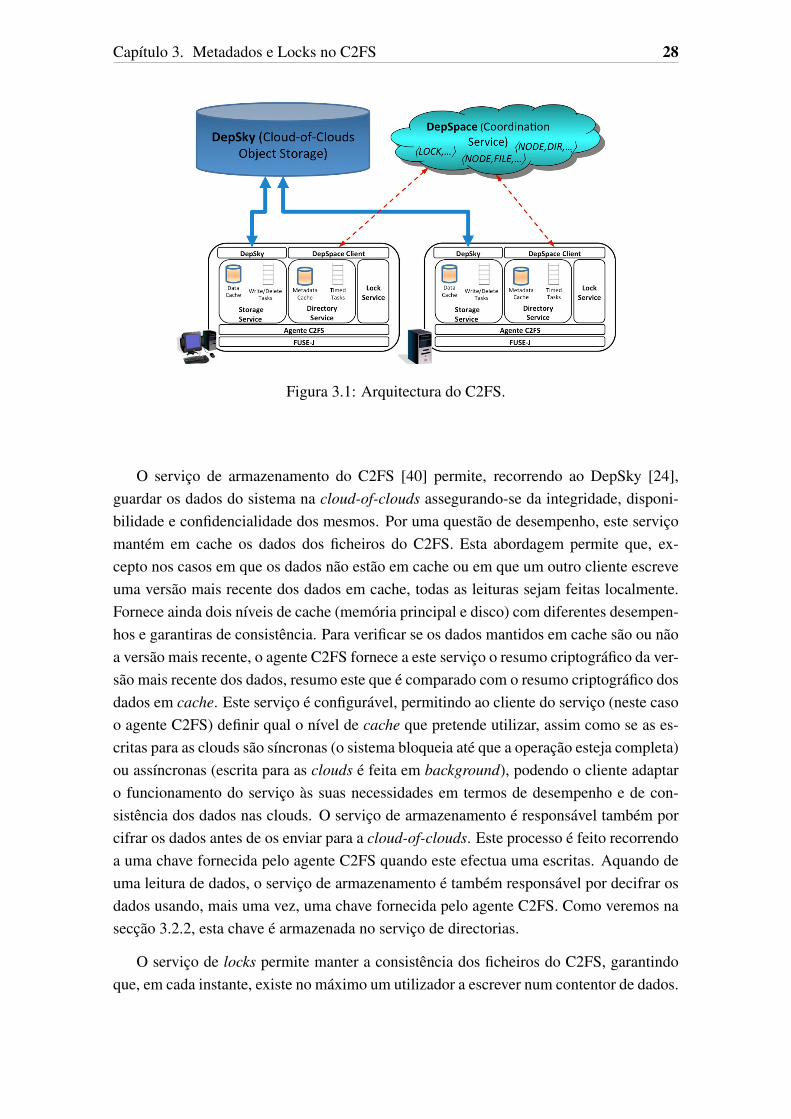
Capítulo 3. Metadados e Locks no C2FS 28
Figura 3.1: Arquitectura do C2FS.
O serviço de armazenamento do C2FS [40] permite, recorrendo ao DepSky [24],guardar os dados do sistema na cloud-of-clouds assegurando-se da integridade, disponi-bilidade e confidencialidade dos mesmos. Por uma questão de desempenho, este serviçomantém em cache os dados dos ficheiros do C2FS. Esta abordagem permite que, ex-cepto nos casos em que os dados não estão em cache ou em que um outro cliente escreveuma versão mais recente dos dados em cache, todas as leituras sejam feitas localmente.Fornece ainda dois níveis de cache (memória principal e disco) com diferentes desempen-hos e garantiras de consistência. Para verificar se os dados mantidos em cache são ou nãoa versão mais recente, o agente C2FS fornece a este serviço o resumo criptográfico da ver-são mais recente dos dados, resumo este que é comparado com o resumo criptográfico dosdados em cache. Este serviço é configurável, permitindo ao cliente do serviço (neste casoo agente C2FS) definir qual o nível de cache que pretende utilizar, assim como se as es-critas para as clouds são síncronas (o sistema bloqueia até que a operação esteja completa)ou assíncronas (escrita para as clouds é feita em background), podendo o cliente adaptaro funcionamento do serviço às suas necessidades em termos de desempenho e de con-sistência dos dados nas clouds. O serviço de armazenamento é responsável também porcifrar os dados antes de os enviar para a cloud-of-clouds. Este processo é feito recorrendoa uma chave fornecida pelo agente C2FS quando este efectua uma escritas. Aquando deuma leitura de dados, o serviço de armazenamento é também responsável por decifrar osdados usando, mais uma vez, uma chave fornecida pelo agente C2FS. Como veremos nasecção 3.2.2, esta chave é armazenada no serviço de directorias.
O serviço de locks permite manter a consistência dos ficheiros do C2FS, garantindoque, em cada instante, existe no máximo um utilizador a escrever num contentor de dados.

Capítulo 3. Metadados e Locks no C2FS 29
O serviço de directorias utiliza o DepSpace [23]1 para armazenar os metadados e efectuaro controlo de acesso aos ficheiros do C2FS. Como podemos verificar na figura 3.1, esteserviço mantém uma cache de metadados que permite diminuir o número de chamadas aoDepSpace, diminuindo os custos inerentes à utilização do sistema e aumentar o desem-penho do sistema. Estes dois serviços vão ser descritos em maior detalhe nas secções 3.2.2e 3.3.
Tanto o serviço de armazenamento como o serviço de directorias mantêm uma fila detarefas que correm em background. Estas tarefas permitem propagar alterações de dados emetadados de forma assíncrona no sistema, representando um incremento do desempenhodo mesmo.
Figura 3.2: Cloud-of-clouds.
Na figura 3.2 é apresentada uma visão geral do C2FS, onde um conjunto de uti-lizadores acede a ficheiros cujos dados e metadados estão armazenados em diferentesprovedores de armazenamento e computação nas clouds. Exemplos de serviços destegénero são o Amazon S3 [4] e o Amazon EC2 [2], respectivamente. Como podemosperceber, foi decidido separar os dados dos metadados. Outros sistemas de ficheiros [54,48] optaram também por esta abordagem. As razões que levaram à utilização de umserviço de coordenação instalado nas clouds de computação para o armazenamento dosmetadados ao invés de os armazenar nas clouds de armazenamento são essencialmente asseguintes:
• Um serviço de coordenação fornece primitivas eficientes para a implementação deum serviço de locks.
• O desempenho é superior para operações com pouca transferência de dados (comoé o caso do acesso aos metadados), conforme será mostrado na secção 5.
1Assume-se implicitamente que as réplicas do DepSpace vão estar a correr em diferentes provedores decomputação em cloud, fazendo também uso do paradigma cloud-of-clouds.

Capítulo 3. Metadados e Locks no C2FS 30
• Ter um serviço de metadados consistente permite ter um sistema de ficheiros con-sistente. Esta afirmação será explicada em pormenor no capítulo 3.4.
O serviço de coordenação utilizado, como já foi referido anteriormente, é o DepSpace [23].Esta escolha deve-se ao facto de este ser o serviço de coordenação disponível que maisgarantias de segurança e fiabilidade oferece entre os serviços estudados (ver secção 2.1).
3.1.2 Modelo de Sistema
O sistema suporta um conjunto ilimitado de clientes que correm os serviços de ar-mazenamento, directorias e locks. Assume-se que cada um destes clientes tem um identi-ficador único (clientId).
Os serviços de directorias e locks recorrem ao DepSpace [23] para exercer a suafunção. Toda a comunicação entre estes serviços e o DepSpace é feita utilizando canaisfiáveis autenticados ponto-a-ponto através do uso de sockets TCP, códigos de autenti-cação de mensagens (MAC) e de chaves de sessão. É também assumido que a rede podedescartar, corromper ou atrasar mensagens, mas não pode interromper indefinidamente acomunicação entre processos correctos. Não é necessária nenhuma garantia de tempo ex-plícita, sendo no entanto, por uma questão de liveness, necessário um modelo de sistemaeventualmente síncrono. Esta necessidade deve-se ao uso da primitiva de difusão comordem total, baseada no protocolo de consenso bizantino Paxos, para garantir que todosos servidores do DepSpace executam as mesmas operações pela mesma ordem [47].
O serviço de armazenamento, por sua vez, recorre ao DepSky [24] para armazenaros seus dados na cloud-of-clouds. Cada cloud utilizada para armazenar dados representaum servidor passivo (não executando nenhum código específico para o protocolo) comuma semântica de consistência regular, ou seja, para operações de leitura que ocorremconcorrentemente com operações de escrita, o valor lido é sempre, ou o valor antigo, ou ovalor a ser escrito, nunca um valor intermédio. O sistema tolera faltas bizantinas por partedos servidores do DepSpace, do serviço de directorias, do serviço de locks, dos provedoresde armazenamento nas clouds e do serviço de armazenamento (enquanto processo leitorde dados no DepSky).
Embora o C2FS garanta que, a cada instante, não existe mais que um processo escritorpara um mesmo contentor no DepSky, não são considerados escritores maliciosos pois,tendo acesso ao ficheiro, um cliente malicioso poderia escrever dados sem sentido para aaplicação de qualquer forma. Todos os serviços de armazenamento que efectuam leituras(recorrendo ao DepSky) têm acesso à chave pública dos escritores, permitindo efectuarverificação e validação dos dados lidos (previamente assinados).
Tanto no caso dos servidores DepSpace como das clouds usadas pelo DepSky, devidoao uso de quóruns bizantinos, o sistema requer n ≥ 3f+1 servidores (ou clouds) para tol-erar f faltas, assumindo, no entanto, que as falhas dos servidores não são correlacionadas.No entanto, o sistema tolera um número ilimitado de clientes faltosos.

Capítulo 3. Metadados e Locks no C2FS 31
3.2 Metadados
Os metadados no contexto de um sistema de ficheiros, tem a função de guardar in-formações referentes a cada ficheiro, tais como a localização dos seus dados na memóriasecundária, o seu dono, as permissões de acesso por parte de diferentes utilizadores, entreoutros. Tal como todos os sistemas de ficheiros, também o C2FS necessita de um mecan-ismo que lhe permita armazenar e manusear os metadados do sistema. Neste contexto,foram desenvolvidas algumas versões de um serviço de directorias para efectuar estastarefas. Todas as versões deste serviço de directorias que permitem a partilha de ficheirosutilizam o DepSpace [23] para armazenar os metadados. Abaixo, serão descritas as alter-ações necessárias neste serviço de coordenação, assim como o modo de funcionamentodos vários mecanismos desenvolvidos para armazenar e manusear os metadados do C2FS.
3.2.1 DepSpace
Como referido na secção 2.1.3, o DepSpace é um serviço de coordenação seguroe tolerante a faltas bizantinas. Este serviço utiliza uma abstracção de espaço de tup-los, fornecendo aos clientes a possibilidade de armazenar estruturas de dados genéricas(chamadas tuplos).
Além de simplesmente armazenar tuplos, este serviço possibilita definir políticas deacesso aos tuplos contidos no espaço, nomeadamente definir quais os clientes que estãohabilitados a ler ou modificar o conteúdo de um determinado tuplo contido no espaço.Possibilita ainda a criação de tuplos temporários, ou seja, tuplos que permanecem no es-paço de tuplos durante um espaço de tempo previamente definido, sendo estes, a menosque sejam revalidados (através da chamada da operação renew), removidos automatica-mente quando expirados.
Para a implementação de um serviço de directorias eficiente para o C2FS, foi necessárioadicionar duas novas funcionalidades ao DepSpace.
Operação replace. Uma das limitações do modelo de espaço de tuplos é a impossi-bilidade de modificar um tuplo no espaço. Esta limitação aparece para um serviço dedirectorias quando, por exemplo, é necessário renomear um nó da árvore de directorias,que é representado por um tuplo no DepSpace. A forma usual de se alterar tuplos é re-mover a versão antiga e adicionar uma nova. No entanto, esta solução levanta problemastanto de desempenho (pelo menos duas operações no espaço) como de consistência (asduas operações não são atómicas). A solução encontrada para este problema foi adi-cionar uma nova operação à interface exportada pelo DepSpace, operação esta chamadareplace(t̄,t). Esta nova operação substitui o tuplo mais antigo no espaço que satisfaça t̄
por t, retornando true no caso de ter sido modificado algum tuplo e false caso contrário.

Capítulo 3. Metadados e Locks no C2FS 32
Suporte a triggers. Um segundo problema, mais grave, ocorre quando renomeamosuma directoria. Quando isso acontece, é necessário actualizar o campo “nó pai” de todosos nós dentro dessa directoria. Como veremos mais à frente (secção 3.2.2), o identificadorguardado no tuplo que permite ao sistema saber qual “nó pai” de um determinado nó é ocaminho (path) deste. À primeira vista, este problema poderia ser resolvido substituindoeste identificador por um identificador imutável (como o container_id), o qual não neces-sitaria ser alterado quando o nó é renomeado. Na verdade, esta abordagem seria aindamais problemática pois, visto o sistema operativo executar as chamadas sobre o sistemade ficheiros utilizando o path dos nós sobre os quais pretende operar, teriam de ser feitasvárias chamadas sobre o serviço de directorias até se obter os metadados do nó pretendido,e só então, operar sobre os mesmos. Por exemplo, supondo que existem os ficheiros/m/foo/file e /m/fuu/file com os container_ids 3 e 4, e que as directorias /m/foo e /m/fuutêm os container_ids 1 e 2 respectivamente, os tuplos guardados, segundo esta abordagemalternativa, seriam (numa versão simplificada): 〈FILE, 1, file, 3〉, 〈FILE, 2, file, 4〉,〈DIR, 0, foo, 1〉 e 〈DIR, 0, foo, 2〉. Numa operação de stat2 sobre o ficheiro /m/foo/file,visto termos mais que um tuplo com o nome file, ao pesquisarmos por esse nome atravésdo template 〈∗, ∗, file, ∗〉, obteríamos os tuplos 〈FILE, 1, file, 3〉 e 〈FILE, 2, file, 4〉.Em seguida, teríamos ainda de perceber, através de nova chamada ao DepSpace, qualdos dois é referente à directoria /m/foo. Para isso seria usado o template 〈∗, ∗, foo, ∗〉,obtendo então os metadados da directoria procurada, e assim o seu container_id. Nestecaso, bastariam estas duas chamadas, pois bastava comparar os container_ids dos cam-pos “nó pai” dos tuplos obtidos da primeira chamada com o container_id do nó obtidona segunda para perceber qual o tuplo com os metadados do ficheiro /m/foo/file. Note-seno entanto que poderiam ser necessárias mais chamadas caso existissem mais nós no sis-tema com o nome foo. Como podemos perceber, esta abordagem levantaria problemas deatomicidade e de desempenho da operação.
A abordagem utilizada para resolver este problema de forma eficiente, i.e., evitar a ex-ecução de um replace por cada nó filho do nó renomeado, foi adicionar uma nova camadapara suporte a Triggers. Quando é executada uma operação de replace no DepSpace éactivado um gatilho que, de forma recursiva, executa um conjunto de outras operaçõesreplace nos servidores, actualizando o campo “nó pai” de todos os nós abaixo do nórenomeado na árvore de directorias.
Uma outra função desta camada é permitir a substituição de tuplos quando um nóé renomeado. Por exemplo, existindo os ficheiros /A e /B, se pretendermos renomear oficheiro /A para /B, o comportamento esperado é que o ficheiro /A deixe de existir, pas-sando o ficheiro /B a conter os dados de /A. Neste contexto, se simplesmente modificarmoso nome de /A para /B, passariam a existir dois nós com o mesmo nome. Neste sentido,sempre que já exista no espaço um tuplo cujo caminho seja igual ao novo caminho de
2Operação do sistema de ficheiros utilizada para obter os metadados de um dado nó.

Capítulo 3. Metadados e Locks no C2FS 33
um nó renomeado, este tuplo é apagado do espaço. Uma outra potencialidade desta ca-mada é permitir utilizar valores dos metadados dos nós substituídos, ou seja, caso existamcampos no novo tuplo que não estejam definidos (tenham o valor ’*’), quando este tuplosubstitui o antigo, estes campos são preenchidos com o valor dos campos correspondentesno antigo tuplo.
Todas as operações já referidas que são efectuadas por um trigger são executadas deforma atómica. Note-se também que os Triggers só são requeridos quando há necessidadede renomear um nó.
3.2.2 Serviço de Directorias
O C2FS usa um serviço de directorias que tem por base o DepSpace. Esta abordagemfaz com que os metadados possam ser guardados utilizando a abstracção de espaço detuplos ao mesmo tempo que permite que o serviço herde todas as garantias fornecidaspelo serviço subjacente. Cada serviço de directorias é então cliente do DepSpace e temum identificador único que o identifica.
Formato dos Metadados
Os metadados de todos os ficheiros, directorias e ligações simbólicas são representadoscomo tuplos no espaço. Para o caso dos ficheiros e directorias, esses tuplos têm o seguinteformato:
〈NODE , parent_folder , node_name, node_type, node_metadata, container_id〉
O campo parent_folder guarda o caminho do “nó pai” do nó em questão, enquantoque o campo node_name é o nome do nó. Para obter o caminho de um determinado nóbasta, portanto, concatenar o valor do campo parent_folder com o carácter ‘\’ seguido dovalor do campo node_name. O campo node_type pode tomar o valor de FILE, DIR con-soante os metadados sejam de um ficheiro ou uma directoria, respectivamente. O camponode_metadata contém toda a informação dos metadados de um determinado nó, taiscomo as permissões sobre ele por parte dos vários utilizadores do sistema, o identificadordo dono do ficheiro, o tamanho do ficheiro, o resumo criptográfico (hash) dos dados aque este se refere e a chave simétrica utilizada para cifrar estes dados. A importânciade manter o resumo criptográfico e a chave neste serviço será explicada em detalhe maisà frente. O campo container_id é o identificador único do contentor onde os dados deum determinado ficheiro são armazenados. No caso das directorias, este identificador éignorado pelo sistema. Este identificador é criado pelo cliente do serviço de directoriasque cria o contentor. Para garantir que dois clientes não criam dois contentores com omesmo identificador, este é gerado concatenando o identificador do cliente no serviço dedirectorias (que o serviço garante ser único) com um timestamp local.

Capítulo 3. Metadados e Locks no C2FS 34
Op. do Serviço de Directorias Op. do DepSpace
getMetadata(path) rdp(〈NODE, parent(path), name(path), *, *, *, *〉);
putMetadata(mdata) cas(〈NODE, parent(mdata), name(mdata), *, *, *, *〉,
〈NODE, parent(mdata), name(mdata), nodeType(mdata), mdata, contId(mdata)〉);
removeMetadata(path) inp(〈NODE, parent(path), name(path), *, *, *, *〉);
updateMetadata(path, mdata) replace(〈NODE, parent(path), name(path), *, *, *, *〉,
〈NODE, parent(mdata), name(mdata), nodeType(mdata), mdata, contId(mdata)〉);
getChildren(parent) rdAll(〈NODE, parent, *, *, *, *, *〉);
getLinks(contId) rdAll(〈NODE, *, *, *, *, *, contId〉);
updateLocalMetadata(contId, hash, size) -commitLocalMetadata(contId) replace(〈NODE, parent, name, *, *, *, *〉,
〈NODE, parent, name, nodeType, mdata, contId〉);
putPrivateNamespace(namespaceStats) cas(〈PRIVATE_NAMESPACE, *, *, *〉,
〈PRIVATE_NAMESPACE, contID, key, hash〉);
getPrivateNamespace() rdp(〈PRIVATE_NAMESPACE, contID, *, *〉);
Tabela 3.1: Interacção do serviço de directorias com o DepSpace.
No caso das ligações simbólicas, visto este tipo de nós consistirem num apontadorpara um outro nó, alguns dos campos deste formato são utilizados para armazenar difer-entes informações. Assim, no campo container_id, ao invés do identificador do contentorde dados do nó, é guardado o caminho do nó para o qual esta ligação aponta. Os cam-pos parent_folder e node_name são utilizados para armazenar o caminho do “nó pai”da ligação e o seu nome, respectivamente. Os restantes campos do formato apresentadomantêm a função anteriormente descrita, sendo que neste caso, como é fácil de perceber,o campo node_type tem o valor SYMLINK.
Operações do Serviço de Directorias
O serviço de directorias exporta uma API que permite efectuar todas as operações necessáriaspara manipular os metadados do sistema. Assim, estão disponíveis operações para adi-cionar, remover, alterar e obter os metadados de um nó do sistema de ficheiros. Atabela 3.1 apresenta uma lista dessas operações e a sua interacção com o DepSpace.
Como podemos perceber, para armazenar os metadados dos nós do sistema de ficheiros,o serviço de directorias insere tuplos no espaço. A operação usada para inserir estes tu-plos é a operação cas pois permite, de uma forma atómica, inserir um tuplo no espaçoapenas no caso de não existir nenhum outro que corresponda ao mesmo nó do sistema deficheiros. Para obter os metadados de um dado nó, o serviço faz uma leitura ao espaço,com a operação rdp que devolve o tuplo mais antigo no espaço que satisfaça um templatedado. Para remover tuplos do espaço é usada a operação inp do DepSpace, enquanto quepara as operações do serviço que necessitam obter os metadados de mais que um nó éutilizada a operação rdAll. A operação inp permite remover os metadados de um nó, en-

Capítulo 3. Metadados e Locks no C2FS 35
quanto que a operação rdAll permite obter uma colecção com os tuplos que correspondamcom o template fornecido pelo serviço de directorias.
Para lidar com actualizações de metadados em consequência de actualizações de da-dos, o serviço permite modificar os valores do tamanho e resumo criptográfico dos da-dos localmente, mantendo estas alterações por tempo indeterminado até que o cliente doserviço decida efectuar essas alterações de forma definitiva no DepSpace. Isto é usado,e.g., quando o cliente tem de fazer escritas demoradas de dados. Neste caso o sistemaprimeiro efectua a escrita dos dados numa cache em disco local, depois altera os metada-dos localmente e retorna ao sistema operativo, fazendo a alteração no DepSpace ape-nas quando a escrita dos dados terminar. No caso concreto do C2FS, este mecanismo éútil quando o serviço de armazenamento faz as escritas para as clouds de forma assín-crona. Nesta configuração, este mecanismo permite que durante a execução das escritasem background, geridas pelo serviço de armazenamento, o cliente possa efectuar leiturasaos dados com os metadados correctos, ao mesmo tempo que previne outros clientes dosistema, que correm uma outra instância do serviço de directorias, de obter metadadoserrados para o mesmo nó. Esta potencialidade é implementada através das operações up-dateLocalMetadata(contId, hash, size) e commitLocalMetadata(contId), sendo a primeirapara actualizar os valores do tamanho e resumo criptográfico dos dados localmente e a se-gunda para propagar estas actualizações para o DepSpace, ficando então disponíveis atodos os clientes do sistema. Como podemos perceber na definição das operações natabela 3.1, a operação updateLocalMetadata(contId, hash, size) não faz qualquer oper-ação no DepSpace. Nesta operação, os valores alterados são armazenados numa estruturade dados mantida na memória principal e ainda em disco local. A utilização do disco localpara armazenar estes valores é imprescindível pois, em caso de falha do serviço de direc-torias durante o envio dos em dados em background para a cloud-of-clouds, é possívelrecuperar os metadados referentes à escrita em curso. Assim, na operação commitLocal-Metadata(contId), os metadados guardados localmente são actualizados no DepSpace eapagados tanto da estrutura de dados em memória como do disco local. Na verdade, osúnicos campos actualizados por esta operação são o tamanho e o resumo criptográfico dosdados. Esta abordagem permite que o cliente do serviço possa fazer alterações a outroscampos dos metadados enquanto os metadados estão guardados localmente, i.e., enquantoa escrita do ficheiro está a decorrer.
As operações putPrivateNamespace e getPrivateNamespace têm por função inserire obter as informações referentes ao espaço de nomes pessoal de cada cliente. Estasoperações serão descritas em pormenor na secção 3.2.4.
Controlo de Acesso aos Ficheiros
O serviço de directorias fornece um mecanismo que permite controlar o acesso aosmetadados. Este permite aos clientes definir, a qualquer instante, quais os clientes do

Capítulo 3. Metadados e Locks no C2FS 36
sistema de ficheiros que podem ler ou modificar os metadados. Este mecanismo estáassente sobre as políticas de controlo de acesso aos tuplos do DepSpace [23].
O que é feito pelo serviço de directorias é definir quais os identificadores dos clientescom permissões de leitura e escrita sobre cada tuplo. Desta forma, um outro cliente dosistema de ficheiros (que corre um serviço de directorias próprio com um identificadorúnico no DepSpace) apenas consegue obter ou alterar os metadados de nós cujos tuplostenham o seu identificador na lista de clientes aptos para ler ou escrever.
É com o mecanismo de controlo de acesso aos metadados descrito, aliado com o factode o serviço de armazenamento [40] cifrar os dados com a chave simétrica armazenadajuntamente com os metadados, que o C2FS faz controlo de acesso aos ficheiros. Paraum cliente ler os dados de um determinado ficheiro este tem que, em primeiro lugar, teracesso à chave usada para cifrar os mesmos. Caso este seja um cliente não autorizado,este não conseguirá obter os metadados do ficheiro e, assim sendo, não conseguirá obter achave para decifrar os dados. Desta forma, mesmo que um cliente consiga obter os dadosdirectamente das clouds sem usar o serviço de armazenamento, este não consegue acederos dados em claro.
3.2.3 Cache no Serviço de Directorias
Conforme já descrito, o serviço de directorias pode realizar caching de metadados emmemória local de forma a minimizar tanto a latência de acesso aos metadados3, quantoo número de chamadas feitas ao DepSpace (permitindo a este atender mais clientes ereduzir os custos da utilização deste serviço).
A cache de metadados do C2FS é concretizada utilizando tarefas temporizadas, re-sponsáveis pela actualização dos metadados no DepSpace após a expiração de um tem-porizador, sendo que cada tarefa é responsável por actualizar os metadados de um úniconó. Estas tarefas são criadas com o objectivo de efectuar actualizações nos metadadosde um determinado nó no DepSpace de forma assíncrona ao sistema e com um atrasoesperado de no máximo ∆ ms, sendo ∆ um parâmetro do serviço. Este mecanismo per-mite também que todas as actualizações feitas aos metadados de um nó em cache duranteum intervalo de ∆ ms sejam executadas de uma única vez no DepSpace. O valor de ∆
define também por quanto tempo os metadados de um determinado nó estão em cache noserviço de directorias. Assim, a definição deste parâmetro deve ter em conta que, quantomaior seu valor, menor o número de chamadas feitas ao DepSpace, e maior o atraso depropagação de alterações de metadados, o que pode ter efeitos negativos na consistênciado sistema. Para além das operações descritas na tabela 3.1, esta versão do serviço dedirectorias fornece uma operação extra, chamada removeFromCache(path), responsávelpor limpar da cache toda a informação referente aos metadados do nó com o caminho
3Acedidos através das chamada stat, identificada em muitos estudos como a operação mais comumenteinvocada pelos sistemas de ficheiros (como é mostrado na secção 5.2).

Capítulo 3. Metadados e Locks no C2FS 37
dado.Os algoritmos 1, 2 e 3 descrevem em detalhe o comportamento das operações put-
Metada, getMetadata e updateMetadata do serviço de directorias com cache activada.
Variáveis utilizadas. Nestes algoritmos o objecto noCacheDiS representa um objectodo serviço de directorias sem cache que disponibiliza as operações e comportamento de-scritos na tabela 3.1. Os objectos cache e localMetadata representam a cache de metada-dos e a estrutura de dados em memória principal que mantém as actualizações de metada-dos localmente, respectivamente. Os objectos UpdaterTask representam as tarefas tem-porizadas responsáveis por actualizar os metadados no DepSpace de forma assíncrona,enquanto que o objecto scheduler representa um objecto que mantém as tarefas de actu-alização, e as executa com um atraso pré-definido. No algoritmo 4 há ainda os objectosstopped e cacheDiS. O primeiro é um booleano que indica se a tarefa foi ou não cancelada,enquanto que o segundo é um objecto do serviço de directorias com cache.
Algoritmos. No algoritmo 1 podemos ver que o nó é criado no sistema através da in-serção dos seus metadados no DepSpace (linha 2). Estes metadados são também guarda-dos em cache (linha 4), permitindo que as operações feitas sobre eles nos ∆ ms seguintespossam ser feitas numa só chamada ao DepSpace.
Algorithm 1: putMetadata(m)Map 〈 String, MetadataCacheEntry 〉 cache;
Entrada: m - metadados a inseririnício1
noCacheDiS.putMetadata(m);2
entry ←−MetadataCacheEntry(m, currentT ime);3
cache.put(m.path, entry);4
fim
A operação referente à obtenção de dados (algoritmo 2) é um pouco mais complexa.Em primeiro lugar o serviço verifica se os metadados referentes ao nó pedido estão emcache, caso isto não se verifique, os metadados são obtidos recorrendo ao serviço de direc-torias sem cache e guardados em cache, como podemos ver nas linhas 4 e 6 do algoritmo.Caso os metadados se encontrem em cache, é necessário verificar se estes ainda se en-contram válidos, ou seja, estão guardados em cache há menos de ∆ ms (linha 7). Se osmetadados guardados em cache forem inválidos, são então obtidos do DepSpace recor-rendo ao serviço de directorias sem cache, como se pode observar na linha 10. Caso exis-tam metadados guardados na estrutura localMetadata, os campos referentes ao tamanhodos dados e resumo criptográfico guardados nos metadados desta estrutura são substituí-dos nos metadados a retornar por esta operação (linhas 15 e 16).

Capítulo 3. Metadados e Locks no C2FS 38
Algorithm 2: getMetadata(path)Map 〈 String, MetadataCacheEntry 〉 cache;Map 〈 String, NodeMetadata 〉 localMetadata;
Entrada: path - caminho do ficheiro a obterSaída: metadados de pathinício1
entry ←− cache.get(path);2
se (entry =⊥) então3
mdata←− noCacheDiS.getMetadata(path);4
entry ←−MetadataCacheEntry(mdata, currentT ime);5
cache.put(path, entry);6
senãose (currentT ime ≤ (entry.time + ∆)) então7
mdata←− entry.metadata;8
senãocache.remove(path);9
mdata←− noCacheDiS.getMetadata(path);10
entry ←−MetadataCacheEntry(m, currentT ime);11
cache.put(path, entry);12
mdata′ ←− localMetadata.get(mdata.containerId);13
se (mdata′ 6=⊥) então14
mdata.dataSize←− mdata′.dataSize;15
mdata.dataHash←− mdata′.dataHash;16
retorna mdata;17
fim
Na operação updateMetadata apresentada no algoritmo 3, o primeiro procedimentoefectuado no caso em que os metadados do nó referente ao caminho dado não estejam emcache (ou estejam inválidos) é obtê-los. Este procedimento é feito através da chamada daoperação getMetadata. Em seguida, caso não exista ainda nenhuma tarefa de actualizaçãopara o nó referente ao caminho dado, essa tarefa tem de ser lançada. Esta tarefa, comopodemos ver na linha 7 do algoritmo em descrição, é agendada para ∆ ms após a execuçãoda tarefa menos a quantidade de tempo em que os metadados a actualizar estão em cache.Isto acontece para garantir que não são feitas actualizações sobre metadados inválidos emcache. Após isso basta alterar o valor dos metadados em cache pois, após (quanto muito)∆ ms, é esse o valor enviado pela tarefa de actualização. Há, no entanto, o problema dea operação ter por objectivo renomear um nó da árvore de directorias. Neste caso, nãobasta modificar o caminho do nó e esperar que a tarefa de actualização propague essamodificação para o DepSpace. Esta abordagem tem o problema de poder já existir um nócujo caminho é igual ao novo caminho do nó renomeado. Neste caso, poderia acontecerque esse nó estivesse em cache, logo, pudesse ter uma tarefa de actualização para alterar

Capítulo 3. Metadados e Locks no C2FS 39
Algorithm 3: updateMetadata(path, m)Map 〈 String, NodeMetadata 〉 cache;Map 〈 String, NodeMetadata 〉 localMetadata;
Entrada: path - caminho dos metadados, m - nova versão dos metadadosinício1
oldMDataEntry ←− cache.get(path);2
se ((oldMDataEntry =⊥) ∨ (currentT ime ≥ oldMDataEntry .time)) então3
getMetadata(path) ; // metadados ficam em cache4
se (!scheduler.contains(path)) então5
updaterTask ←− UpdaterTask(path,m,NoCacheDiS, this);6
t←− (∆− (currentT ime− entry.time));7
scheduler.schedule(m.path, updaterTask, t);8
se (path 6= m.path) então9
schedule.cancel(path);10
cache.remove(path);11
replacedMData ←− getMetadata(m.path);12
se (replacedMData 6=⊥) então13
se (replacedMData.numContainerLinks ≤ 1) então14
localMetadata.remove(replacedMData.containerId);15
se (cache.get(m.path) 6=⊥) então16
schedule.cancel(m.path);17
cache.remove(m.path);18
noCacheDiS.updateMetadata(path,m);19
senãocache.remove(path);20
entry ←− MetadataCacheEntry(m, currentT ime);21
cache.put(path, entry);22
fim
os seus metadados. Assim, a tarefa de actualização deste segundo nó poderia alterar osmetadados do nó renomeado. Para solucionar este problema, sempre que esta operaçãotenha por objectivo renomear um nó, o serviço verifica se existem tarefas de actualizaçãopara o nó renomeado. Caso exista, essa tarefa é abortada (linha 10). Em seguida, o serviçoverifica se existe um nó cujo caminho corresponda ao novo caminho do nó renomeado.Caso isto se verifique, a tarefa de actualização referente a este nó, caso exista, é abortada(linha 17).
Nas linhas 14 e 15 do algoritmo em descrição, podemos perceber que, na existênciade um nó que irá ser substituído por um nó renomeado, caso o número de ligações aoseu contentor seja menor ou igual a um, os seus metadados são apagados da estrutura dedados que mantém as actualizações de metadados feitas localmente. Isto acontece pois,dada a substituição do nó em questão, o seu contentor de dados irá perder uma ligação,

Capítulo 3. Metadados e Locks no C2FS 40
logo, esta informação deixa de ser útil.
Algorithm 4: UpdaterTask.run()NodeMetadata initialMData;NodeMetadata mData;Boolean stoped;
Entrada: m - metadados a inseririnício1
se (!stopped ∧ (initialMData 6= mData)) então2
noCacheDiS.updateMetadata(initialMData.path,mData);3
cacheDiS.removeFromCache(initialMData.path);4
fim
O comportamento das tarefas de actualização, que são executadas após ∆ ms peloScheduler, resume-se a, caso hajam, propagar as actualizações feitas ao seu nó para oDepSpace. Na linha 2 do algoritmo 4 são comparados os metadados iniciais com osmetadados actuais, sem a actualização efectuada apenas no caso de estes dois objectos nãocoincidirem. Note-se que o objecto initialMData é obtido através da chamada do métodoclone sobre o objecto mData aquando da construção da tarefa, enquanto que o objectomData referência o objecto de metadados mantido em cache pelo serviço de directorias.Após as rotinas descritas acima, é chamada a operação removerFromCache(path) (linha4), que permite ao serviço de directorias remover os metadados da estrutura cache.
3.2.4 Espaço de Nomes Pessoal
O facto de o DepSpace guardar todos os tuplos na memória principal é uma limitaçãodeste serviço. Desta forma, também o serviço de directorias herda esta limitação pois, oespaço de memória das réplicas onde o DepSpace está instalado oferece um limite quantoà quantidade de metadados que o serviço de directorias pode armazenar.
Para minimizar esta limitação introduzimos o conceito de espaço de nomes pessoal:um objecto que guarda uma série de metadados referentes a nós que são privados ao seudono, ou seja, que não são partilhados. Com a utilização destes objectos, os metadados,ao invés de serem guardados no DepSpace, são guardados numa estrutura de dados serial-izável. Esta estrutura é guardada juntamente com os dados do sistema de ficheiros (nestecaso, no serviço de armazenamento), sendo apenas guardado no serviço de directorias umtipo de metadados especial que tem as informações necessárias para o utilizador poderobter a referida estrutura de dados. O espaço de nomes pessoal é enviado para escrita noserviço de armazenamento sempre que é feita uma modificação na estrutura de dados quemantém os metadados.
O serviço de directorias, através das operações putPrivateNamespace e getPrivate-Namespace, permite armazenar e obter a informação relativa ao armazenamento do es-

Capítulo 3. Metadados e Locks no C2FS 41
paço de nomes pessoal na cloud-of-clouds. Esta informação, tal como os metadados dosficheiros partilhados, é armazenada no DepSpace, sendo as permissões de escrita e leiturado tuplo onde a esta informação é armazenada atribuídas unicamente ao dono do espaçode nomes pessoal. Esta abordagem garante que apenas o dono do espaço de nomes pessoalconsiga obter e modificar o tuplo que armazena as informações de acesso a este objecto.O referido tuplo tem o seguinte formato:
〈PNS , container_id , key , hash〉
O valor do campo container_id diz respeito ao contentor onde o espaço de nomespessoal é armazenado. Este identificador é único e é baseado no identificador do clientejunto do DepSpace, podendo ser calculado pelo serviço de directorias. O campo key éa chave simétrica que é utilizada pelo serviço de armazenamento para cifrar o espaçode nomes pessoal, impossibilitando outros clientes de obter os metadados dos ficheirospessoais de um determinado cliente. Note-se que, caso não fosse utilizado este processo,um cliente poderia obter os metadados dos ficheiros pessoais de um outro cliente, e assim,obter as chaves usadas para encriptar os dados dos seus ficheiros. Desta forma, caso esteconseguisse obter os dados dos ficheiros referentes aos metadados obtidos, conseguiria lê-los em claro. No campo hash é armazenado o resumo criptográfico do espaço de nomesprivado. A utilidade deste é permitir ao serviço de armazenamento verificar a validadedo objecto mantido em cache. Caso o hash do objecto mantido em cache não coincidacom o hash mantido pelo serviço de directorias, uma nova versão do objecto tem de serlida da cloud-of-clouds. Embora este acontecimento seja invulgar (dado nenhum outrocliente conseguir alterar este objecto), esta verificação necessita ser feita pois, visto osdados em cache serem guardados no disco local, pode acontecer que esta informaçãotenha sido apagada pelo utilizador ou que o sistema a tenha substituído por motivos defalta de espaço livre em disco.
Na prática, um espaço de nomes pessoal fornece sensivelmente as mesmas operaçõesque o serviço de directorias, no entanto, todas as operações são executadas localmente. Autilização desta técnica permite então, não só minimizar a limitação do DepSpace rela-cionada com o armazenamento dos tuplos na memória principal, mas também, aumentaro desempenho do manuseamento dos metadados de nós privados.
Cada utilizador do sistema de ficheiros tem apenas um espaço de nomes pessoal, sendoeste obtido do serviço de armazenamento sempre que o sistema de ficheiros é montado.
3.2.5 Serviço de Directorias sem Partilha de Ficheiros
Para utilizadores que têm como objectivo utilizar o C2FS para armazenar ficheirosna cloud-of-clouds sem a necessidade de os partilhar com outros utilizadores, foi desen-volvido um serviço de directorias sem partilha de ficheiros. Este serviço de directorias é

Capítulo 3. Metadados e Locks no C2FS 42
concretizado localmente e, à semelhança do espaço de nomes privado, é concretizado uti-lizando um objecto serializável que mantém várias estruturas de dados onde são guarda-dos os metadados de todos os nós do sistema, objecto este que é armazenado nas cloudsrecorrendo ao serviço de armazenamento.
Este serviço de directorias, à excepção das operações relacionados com o espaço denomes pessoal, fornece as mesmas operações que o serviço de directorias com partilhade ficheiros, tendo um comportamento similar ao mesmo. Nesta versão do serviço dedirectorias, as operações relacionadas com o espaço de nomes pessoal deixam de fazersentido pois, não havendo partilha de ficheiros, todos os ficheiros passam a ser pessoais.À imagem do objecto de espaço de nomes pessoal, também o objecto que mantém todosos metadados deste serviço é serializado e armazenado nas clouds sempre que existe umaalteração de metadados em algum nó deste serviço de directorias.
Este serviço, para além de aumentar o desempenho do sistema, visto todos os metada-dos serem manuseados localmente, permite também diminuir os custos de utilização doC2FS pois, ao contrário do serviço de directorias apresentado anteriormente, não neces-sita ter nenhum serviço instalado em instâncias fornecidas por provedores de computaçãonas clouds, não havendo custos com a manutenção das mesmas.
3.3 Serviço de Locks
Para coordenar o acesso concorrente por parte de processos escritores aos ficheiros doC2FS com o objectivo de manter a consistência dos mesmos, foi desenvolvido um serviçode locks. Como referido anteriormente, também este serviço foi desenvolvido tendo oDepSpace como base.
No C2FS, antes de efectuar uma escrita num ficheiro, um cliente têm de reservar ocontentor de dados desse ficheiro através da aquisição de um lock. Este lock é efectuadosobre o contentor de dados pois, devido ao facto do C2FS suportar ligações fortes (hardlinks) entre ficheiros, caso os locks fossem feitos sobre ficheiros, poderiam existir doisclientes com locks sobre diferentes ficheiros a escrever para o mesmo contentor de dados,o que poderia levar a escritas inconsistentes.
Para isto, o serviço de locks exporta uma interface que permite aos clientes do serviçoadquirir e libertar um lock sobre um dado contentor de dados através da disponibiliza-ção de três operações: tryAcquire, release e renew. No algoritmo 5 são apresentadasestas operações, assim como as chamadas feitas ao DepSpace aquando da sua execução.Relembro que é assumido que o DepSpace implementa políticas de controlo de acessoque protegem o espaço de tuplos [25]
A primeira operação do algoritmo permite ao cliente tentar reservar um contentor paraescrita, retornando true em caso de sucesso e false caso contrário. Assim, quando umcliente tenta adquirir o lock sobre um contentor de dados o serviço tenta inserir um tuplo

Capítulo 3. Metadados e Locks no C2FS 43
Algorithm 5: Operações do serviço de locks.procedimento tryAquire(contId, time)1
início2
retorna cas(〈LOCK, contId〉, 〈LOCK, contId〉, time);3
fim
procedimento release(contId)4
início5
inp(〈LOCK, contId〉);6
fim
procedimento renew(contId, time)7
início8
renew(〈LOCK, contId〉, time);9
fim
de lock sobre o mesmo contentor no DepSpace. Esta aquisição, assim como a operaçãofeita pelo cliente, só tem sucesso no caso de o serviço de locks obter true da operação casefectuada no DepSpace.
Para prevenir que outros clientes C2FS libertem locks que não lhes pertencem, atravésda remoção dos tuplos que representam locks, o serviço de locks configura o tuplo de lockinserido no espaço com permissões de escrita apenas para o seu criador. Desta forma,apenas quem cria o tuplo de lock pode removê-lo.
Quando um cliente deste serviço, neste caso, o agente C2FS, não consegue obter olock, espera um intervalo de tempo (de aproximadamente um segundo) e só depois voltaa tentar reservar o mesmo contentor.
A operação release permite ao cliente libertar um contentor de dados, caso este estejareservado. Nesta operação o serviço, através da operação inp do DepSpace, remove otuplo de lock do espaço. Assim, quando um outro utilizador tentar reservar o mesmocontentor de dados, o serviço de locks a correr na sua máquina irá obter sucesso quandoefectua a chamada cas da operação tryAquire.
Para tolerar a falha de um cliente detentor de um lock, são usados tuplos de lock comtempos de expiração (que desaparecem do espaço após um intervalo de tempo [41]), quegarantem que os locks acabam por ser libertados se os seus detentores falharem. Estagarantia é indispensável pois, caso contrário, a falha de um cliente detentor de um lockpoderia resultar na indisponibilidade permanente do contentor reservado. Assim, quandoo cliente tenta adquirir um lock sobre um ficheiro, este tem de fornecer a quantidadede tempo na qual deseja que este lock se encontre válido (a variável time dada comoargumento na operação de aquisição do lock). Note-se que o serviço de locks deixa parao cliente a responsabilidade de renovar este lock, através da chamada da operação renew.Esta operação executa a operação renew do DepSpace para aumentar o tempo de validadedo tuplo por mais uma quantidade de tempo, sendo essa quantidade de tempo dada por

Capítulo 3. Metadados e Locks no C2FS 44
time.No caso do C2FS, o responsável por revalidar os locks sobre os contentores de dados é
o agente C2FS. Este módulo mantém uma lista de tarefas responsáveis por manter válidostodos os locks sobre os contentores de dados de todos os ficheiros abertos a cada instante.Aquando do fecho de um ficheiro, o agente C2FS acaba a execução da tarefa responsávelpor fazer as revalidações do lock sobre o contentor de dados desse ficheiro e liberta esselock. Desta forma, o contentor de dados fica então livre para ser reservado por outroprocesso.
O agente C2FS é também responsável por, aquando da abertura de um ficheiro, decidirse é ou não necessário reservar o respectivo contentor de dados. Sempre que o ficheiro aser aberto é pessoal, não é necessário obter o lock sobre ele. Um ficheiro é consideradopessoal caso este pertença ao espaço de nomes pessoal ou caso o serviço de directorias emuso pelo sistema de ficheiros não permita a partilha de ficheiros. Como é fácil de perce-ber, se um ficheiro é pessoal, nenhum outro utilizador irá ter acesso a ele e, assim, nãoprecisa ser considerado como escritor concorrente. No entanto, para controlar o acessoconcorrente a um ficheiro pessoal por parte de diferentes processos escritores na mesmamáquina, o agente C2FS mantém, a cada instante, uma lista dos contentores de dados dosficheiros abertos para escrita, não permitindo a abertura de nenhum outro ficheiro com omesmo contentor por parte de outro processo.
A prova de que este algoritmo satisfaz as propriedades de um algoritmo de locks estáno apêndice A.
3.4 Consistência no C2FS
Visto os provedores de armazenamento nas clouds fornecerem apenas garantia de con-sistência eventual [51], um dos objectivos do C2FS é aumentar estas garantias, fornecendoaos seus clientes uma garantia de consistência forte. Neste contexto, um dos problemasé fornecer um serviço de armazenamento consistente a partir de clouds de armazena-mento eventualmente consistentes. Para isso, é necessária a utilização de uma âncorade consistência, um serviço consistente que permite armazenar pequenas quantidades deinformação. No C2FS, o serviço utilizado como âncora de consistência é o serviço dedirectorias. Note-se que as versões do serviço de directorias com partilha de ficheirostiram partido do DepSpace [23] para tal.
Em termos gerais, o mecanismo utilizado consiste em, aquando de uma escrita numficheiro, o cliente actualiza em primeiro lugar os dados no serviço de armazenamento, esó depois os metadados no serviço de directorias. Assim, quando um outro cliente obtémos metadados com a nova versão dos metadados, este vai saber que, eventualmente, osdados irão estar disponíveis.
Para a implementação deste mecanismo, foi necessário adicionar uma nova operação

Capítulo 3. Metadados e Locks no C2FS 45
ao DepSky [24] chamada readMatching que, dado o identificador do contentor de dadose um resumo criptográfico referente aos dados que o cliente pretende obter, devolve osdados mais actualizados que correspondam ao resumo criptográfico fornecido [40]. Estaoperação permite, caso o resumo criptográfico não corresponda à versão mais recentedos dados, obter uma versão antiga dos dados que corresponda ao mesmo. Esta últimafuncionalidade permite obter dados consistentes mesmo que, aquando de uma leitura con-corrente com uma escrita e após a obtenção dos metadados (e assim, do resumo criptográ-fico), os dados a ler das clouds sejam mais recentes que os metadados obtidos. Isto podeacontecer pois, no processo de escrita, os dados são escritos antes de actualizar os metada-dos, ao passo que, no processo de leitura, os metadados são obtidos em primeiro lugar.Com esta abordagem temos a possibilidade de obter metadados referentes a uma versãoantiga dos dados, problema este resolvido pela operação readMatching.
Quando o resumo criptográfico fornecido a esta operação não diz respeito a nenhumadas versões dos dados armazenadas nas clouds significa que, devido às limitações de con-sistência dos provedores de armazenamento nas clouds, estes ainda não estão disponíveis,sabendo nós que, eventualmente o estarão. Neste caso, a operação readMatching do Dep-Sky retorna um erro. Para tentar obter a nova versão dos dados, quando o serviço dearmazenamento obtém um erro desta operação, este volta a tentar obter os dados após umtempo (normalmente 5 segundos), fazendo este processo três vezes. Caso após as trêstentativas não consiga obter os dados referentes à versão pedida, é retornado um erro. Nocaso do C2FS, quando o agente C2FS obtém erro de uma leitura no serviço de armazena-mento, também a operação de leitura do sistema de ficheiros retorna um erro.
Neste contexto, a operação de escrita no C2FS segue os seguintes passos:
1. Escrever os dados com o resumo criptográfico h no DepSky, recorrendo ao serviço de ar-
mazenamento.
2. Escrever os metadados com o novo valor h no serviço de directorias.
A operação de leitura, por sua vez, requer os seguintes passos:
1. Ler os metadados do ficheiro com o resumo criptográfico h, através do serviço de directo-
rias.
2. Utilizar o serviço de armazenamento para ler a versão dos dados correspondentes a h através
da operação readMatching do DepSky.
Devido à utilização deste mecanismo, aliada com o facto do serviço de locks nãopermitir escritas concorrentes sobre o mesmo contentor de dados, o C2FS garante umasemântica de consistência regular [34] para o armazenamento de ficheiros assegurandoque, aquando de uma operação de leitura concorrente a uma operação de escrita sobre osdados de um ficheiro, ou os dados obtidos são o valor anterior à escrita, ou são o valorque está a ser escrito.

Capítulo 3. Metadados e Locks no C2FS 46
3.5 Considerações Finais
Neste capítulo foi apresentado o C2FS em termos gerais, assim como os serviços dedirectorias e locks. Foram apresentadas várias versões do serviço de directorias, sendodescrito em cada uma o mecanismo utilizado para armazenar e manusear os metadadosdo C2FS. Sobre o serviço de locks, para além do modo de funcionamento, foram aindaapresentadas as garantias fornecidas pelo serviço. Foram também descritas as alteraçõesnecessárias no DepSpace para que fosse possível implementar os referidos serviços.
Descrevemos ainda um mecanismo que permite melhorar as propriedades de con-sistência oferecidas pelas clouds de armazenamento utilizadas pelo C2FS.
No próximo capítulo irá ser descrita a forma como estas ideias foram concretizadas.

Capítulo 4
Concretização dos Serviços deDirectorias e de Locks do C2FS
Neste capítulo serão apresentados os detalhes de concretização do trabalho desen-volvido. Em primeiro lugar serão descritas as tecnologias utilizadas para a implemen-tação dos módulos desenvolvidos. Em seguida será descrito o algoritmo utilizado paraimplementação da camada de suporte a triggers do DepSpace. Serão também apresen-tados alguns diagramas UML, nomeadamente o diagrama de classes e os diagramas desequência das operações mais relevantes do serviço de directorias.
4.1 Considerações Gerais
Todos os componentes dos serviços de directorias e de locks foram implementados nalinguagem de programação JAVA. Esta escolha justifica-se com o facto de o DepSpaceter sido concretizado nesta linguagem de programação. Há ainda o facto de o serviço dearmazenamento fazer uso do DepSky, também ele implementado em JAVA. Assim, estaescolha vai ao encontro de facilitar a integração de todos estes componentes.
O primeiro serviço a ser concretizado foi o de locks. Após um estudo para encon-trar um mecanismo que garantisse o acesso exclusivo a uma hipotética zona crítica porparte de vários processos concorrentes utilizando unicamente o DepSpace, foi então im-plementado este serviço já com a preocupação de fornecer uma interface que permitisseaos seus clientes reservar diferentes contentores de dados, sendo que um mesmo processopode reservar mais que um contentor. Na prática, bastou apenas generalizar o mecanismoinicialmente estudado para este fornecer uma interface que permitisse o acesso exclusivoa várias zonas críticas (a reserva de vários contentores de dados).
O segundo passo foi desenvolver o serviço de directorias sem cache. Aqui houve apreocupação de desenvolver uma interface genérica o suficiente para este serviço de talforma que este pudesse ser utilizado para armazenar os metadados de outros sistemas deficheiros que não o C2FS.
47

Capítulo 4. Concretização dos Serviços de Directorias e de Locks do C2FS 48
Por questões de desempenho e de redução de custos, o passo seguinte foi desenvolvero serviço de directorias com cache. Para garantir eficiência no que diz respeito ao acessoaos metadados em cache, este serviço utiliza instâncias da classe HashMap do pacotejava.util do JAVA para guardar estes metadados. No que diz respeito às tarefas de ac-tualização, foi utilizado um objecto do tipo java.util.Timer que permite, de forma fácil,agendar a execução de cada tarefa de actualização para um momento no futuro.
Por fim foram desenvolvidos o espaço de nomes pessoal e o serviço de directorias sempartilha de ficheiros.
Tendo isto, podemos perceber que o serviço de directorias pode assumir vários modosde funcionamento, sendo eles:
• NoCacheDirectoryService: O serviço de directorias não mantém metadados emcache permitindo, no entanto a partilha de ficheiros entre vários utilizadores. Nestecaso, os metadados dos ficheiros pessoais de cada utilizador são mantidos no seuespaço de nomes pessoal.
• DirectoryServiceWTempCache: O serviço mantém em cache os metadados re-centemente utilizados, sendo possível configurar o tempo de validade dos mesmos(através do parâmetro ∆). Tal como no modo de funcionamento anterior, tam-bém neste caso é possível a partilha de ficheiros, sendo também os metadados dosficheiros privados de cada cliente mantidos no espaço de nomes pessoal. Este modode funcionamento tem um desempenho superior ao anterior.
• NoShareDirectoryService: Neste caso, todos os metadados são mantidos em es-truturas de dados locais, não fazendo uso do DepSpace [23], e assim, não per-mitindo a partilha de ficheiros. No entanto, este modo de funcionamento tem umdesempenho significativamente superior quando comparado com os restantes.
No que diz respeito à concretização, o serviço de directorias sem partilha de ficheirose o espaço de nomes pessoal são muito similares. Ambos guardam todos os metadadosem instâncias da classe HashMap, visto esta ser serializável e eficiente no que diz respeitoao tempo de acesso aos metadados, e disponibilizam sensivelmente os mesmos métodos(sendo que o serviço de directorias sem partilha de ficheiros respeita a interface do serviçode directorias). Na prática, a diferença essencial entre eles reside no facto de, enquantoque o armazenamento do espaço de nomes pessoal nas clouds é da responsabilidade doagente C2FS, no caso dos metadados do serviço de directorias sem partilha de ficheiros éo próprio serviço que serializa as suas estruturas e as armazena na cloud-of-clouds. Estaabordagem aparece com a necessidade de generalizar o código do agente C2FS pois, deacordo com a configuração do sistema de ficheiros, aquando da montagem do sistema deficheiros é criada apenas uma instância de serviço de directorias, sendo apenas necessáriogarantir que não é usado o espaço de nomes pessoal quando não há partilha de ficheiros.
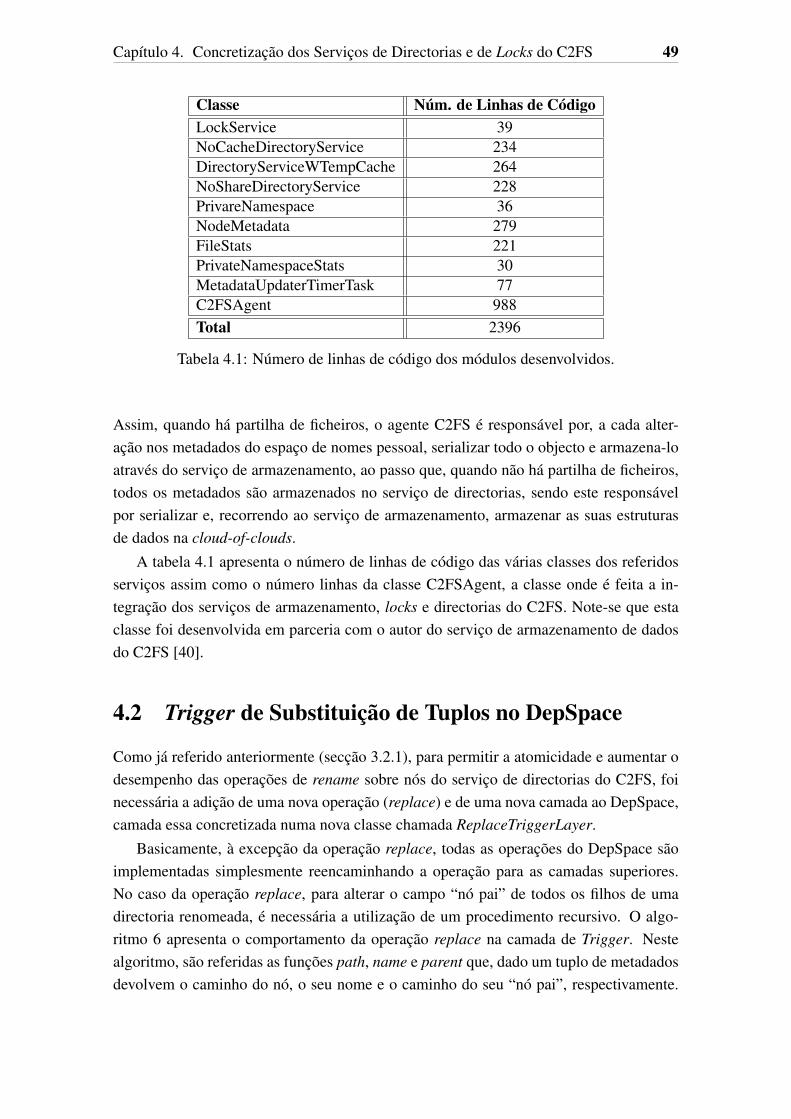
Capítulo 4. Concretização dos Serviços de Directorias e de Locks do C2FS 49
Classe Núm. de Linhas de CódigoLockService 39NoCacheDirectoryService 234DirectoryServiceWTempCache 264NoShareDirectoryService 228PrivareNamespace 36NodeMetadata 279FileStats 221PrivateNamespaceStats 30MetadataUpdaterTimerTask 77C2FSAgent 988Total 2396
Tabela 4.1: Número de linhas de código dos módulos desenvolvidos.
Assim, quando há partilha de ficheiros, o agente C2FS é responsável por, a cada alter-ação nos metadados do espaço de nomes pessoal, serializar todo o objecto e armazena-loatravés do serviço de armazenamento, ao passo que, quando não há partilha de ficheiros,todos os metadados são armazenados no serviço de directorias, sendo este responsávelpor serializar e, recorrendo ao serviço de armazenamento, armazenar as suas estruturasde dados na cloud-of-clouds.
A tabela 4.1 apresenta o número de linhas de código das várias classes dos referidosserviços assim como o número linhas da classe C2FSAgent, a classe onde é feita a in-tegração dos serviços de armazenamento, locks e directorias do C2FS. Note-se que estaclasse foi desenvolvida em parceria com o autor do serviço de armazenamento de dadosdo C2FS [40].
4.2 Trigger de Substituição de Tuplos no DepSpace
Como já referido anteriormente (secção 3.2.1), para permitir a atomicidade e aumentar odesempenho das operações de rename sobre nós do serviço de directorias do C2FS, foinecessária a adição de uma nova operação (replace) e de uma nova camada ao DepSpace,camada essa concretizada numa nova classe chamada ReplaceTriggerLayer.
Basicamente, à excepção da operação replace, todas as operações do DepSpace sãoimplementadas simplesmente reencaminhando a operação para as camadas superiores.No caso da operação replace, para alterar o campo “nó pai” de todos os filhos de umadirectoria renomeada, é necessária a utilização de um procedimento recursivo. O algo-ritmo 6 apresenta o comportamento da operação replace na camada de Trigger. Nestealgoritmo, são referidas as funções path, name e parent que, dado um tuplo de metadadosdevolvem o caminho do nó, o seu nome e o caminho do seu “nó pai”, respectivamente.

Capítulo 4. Concretização dos Serviços de Directorias e de Locks do C2FS 50
Há ainda a função setParent que permite alterar o valor do campo referente ao caminhodo “nó pai” num tuplo de metadados.
Algorithm 6: Concretização da operação replace na camada de triggerprocedimento replace(template, tuple)início1
se (path(template) 6= path(tuple)) então2
tupleTemplate←− 〈NODE, parent(tuple), name(tuple), ∗, ∗, ∗〉;3
inp(tupleTemplate);4
retorna replaceNodeAndChildren(template, tuple);5
retorna upperLayer.replace(template, tuple);6
fim
procedimento replaceNodeAndChildren(template, tuple)início7
result←− upperLayer.replace(template, tuple);8
parent←− path(template);9
childrenList←− rdAll(〈NODE, parent, ∗, ∗, ∗, ∗〉);10
para cada (child ∈ childrenList) faça11
templateNew ←− 〈NODE, parent, name(child), ∗, ∗, ∗〉;12
parentNew ←− parent(child);13
tupleNew ←− child;14
tupleNew.setParent(parentNew);15
replaceNodeAndChildren(templateNew, tupleNew);16
retorna result;17
fim
Como já referido, esta camada tem a função de permitir que, quando uma directoriaé renomeada, o campo “nó pai” dos seus filhos seja actualizado com o seu novo caminhode forma atómica e eficiente. Para além disso, esta camada tem a função de, caso ex-ista um nó no serviço de directorias com o mesmo caminho que o futuro caminho do nórenomeado, eliminar o seu tuplo de metadados do espaço de tuplos. Esta última particu-laridade pode ser vista nas linhas 3 e 4 do algoritmo.
O procedimento replaceNodeAndChildren é responsável por actualizar os metadadosdos “nós filhos” do nó renomeado. Em primeiro lugar, na linha 8 do algoritmo em de-scrição, é feita a substituição dos tuplos (através da chamada à operação replace da ca-mada superior à ReplaceTriggerLayer no DepSpace). As seguintes linhas do algoritmofazem a recursão deste procedimento, permitindo a actualização dos nós abaixo do nórenomeado na árvore de directorias. Para isso, são obtidos todos os nós filhos do nórenomeado (linha 10) através da chamada rdAll, e para cada um destes nós é construídoum novo tuplo no qual o valor do campo “nó pai” é actualizado (linhas 14 e 15), sendofeita posteriormente a substituição destes tuplos e dos seus filhos através da chamada docorrente procedimento (linha 16).

Capítulo 4. Concretização dos Serviços de Directorias e de Locks do C2FS 51
4.3 Diagramas UML
Nesta secção são apresentados alguns diagramas UML referentes ao trabalho desen-volvido. Serão apresentados um diagrama de classes dos componentes desenvolvidose diagramas de sequência referentes às operações de obtenção, alteração e inserção demetadados no serviço de directorias com cache.
4.3.1 Diagrama de Classes
A figura 4.1 apresenta o modelo de classes dos serviços de directorias e de locks. Nestediagrama podemos analisar em detalhe as várias ligações entre os componentes.
A classe C2FSAgente concretiza o agente C2FS. Como podemos perceber, esta classemantém uma instância de cada um dos seguintes componentes: DirectoryService, Lock-Service, PrivateNamespace e PrivateNamespaceStats. No desenvolvimento deste com-ponente houve a preocupação de permitir que, caso seja necessário desenvolver um novoserviço de directorias com um comportamento diferente, não seja necessário alterar todoo código do componente, bastando adequar o objecto instanciado no objecto do tipo Di-rectoryService de acordo com a configuração do sistema. Actualmente, como se podeperceber no diagrama, os objectos que podem ser instanciados são objectos do tipo No-CacheDirectoryService, DirectoryServiceWTempCache e NoShareDirectoryService.
No caso do serviço de directorias com cache, concretizado na classe DirectorySer-viceWTempCache, são mantidas duas Maps, uma com objectos do tipo MetadataCacheEn-try, e outra com as tarefas de actualização a correr a cada instante, e ainda um objecto dotipo NoCacheDirectoryService. Na classe MetadataCacheEntry é mantido um objectodo tipo NodeMetadata e ainda um inteiro que indica o instante em que os metadadosforam inseridos na cache. É na classe NodeMetadata que são mantidas todas as infor-mações dos metadados de cada nó. Esta classe mantém um objecto do tipo FileStats comtodos os valores dos metadados a ser utilizados localmente, ao passo que os restantescampos do objecto NodeMetadata são vocacionados a manter as informações relativasà partilha de ficheiros. A classe NodeMetadata fornece também o método getAsTupleque transforma o objecto de metadados num tuplo a guardar no DepSpace, respeitando oformato apresentado na secção 3.2.2. O campo node_metadata apresentado no referidoformato é, na prática, uma instância da classe FileStats apresentada anteriormente. Ofacto de esta versão do serviço de directorias manter um objecto do serviço de directo-rias sem cache prende-se com o objectivo de delegar a responsabilidade da interacçãocom o DepSpace. Com esta decisão de desenho, a classe DirectoryServiceWTempCacheé responsável apenas por gerir os metadados em cache, utilizando a classe NoCacheDi-rectoryService, para interagir com o DepSpace, manuseando os metadados no DepSpace.Uma outra coisa que se pode observar no diagrama é o facto de cada tarefa de actualiza-ção (classe MetadataUpdaterTimerTask) manter objectos do serviço de directorias com e

Capítulo 4. Concretização dos Serviços de Directorias e de Locks do C2FS 52
sem cache. Isto permite que a actualização dos metadados seja feita no DepSpace atravésda classe NoCacheDirectoryService e que, após isto, os metadados sejam removidos dacache na classe DirectoryServiceWTempCache (através da chamada do método remove-FromCache desta classe).
As classes PrivateNamespace e PrivateNamespaceStats concretizam o mecanismo deespaço de nomes pessoal. A classe PrivateNamespace é responsável de armazenar osmetadados do espaço de nomes pessoal, enquanto que a classe PrivateNamespaceStatscontém as informações relativas ao contentor de dados e resumo criptográfico do objectoPrivateNamespace armazenado na cloud-of-clouds.
4.3.2 Diagramas de Sequência
As figuras 4.2, 4.3 e 4.4 representam diagramas de sequência que ilustram o fluxode execução das operações de obtenção, inserção e alteração de metadados no serviço dedirectorias com cache. Nestes diagramas foi ignorado o lançamento de excepções comvista a simplificar a percepção da informação por eles representada. As excepções sãolançadas sempre que, aquando de uma chamada ao DepSpace por parte do serviço dedirectorias sem cache, ocorre um problema de conexão com os servidores. Para alémdisto, é também lançada uma excepção quando o resultado obtido da execução de umachamada ao DepSpace não cumpre a semântica dessa operação. Exemplos disso são atentativa de inserir um tuplo de metadados referente um novo nó que não tem sucesso, oque significa que o nó já existe no serviço, ou no caso de não obter sucesso nas operaçõesde busca e actualização de tuplos de metadados, o que significa que o nó não existe nosistema de ficheiros. Em seguida, serão descritos os referidos diagramas de sequência.
Inserção de metadados. A figura 4.2 apresenta o diagrama de sequência da operaçãode inserção de metadados no serviço de directorias com cache.
Nesta operação, o cliente é responsável por criar o objecto do tipo NodeMetada comos metadados a guardar. Em primeiro lugar, é utilizado o objecto do serviço de directoriassem cache para inserir os metadados no DepSpace. Embora o diagrama referido nãoapresente este nível de detalhe, para obter o tuplo de metadados referente ao objectoNodeMetadata a inserir, basta utilizar o método getAsTuple desta classe.
Em seguida, o objecto NodeMetadata referente aos metadados inseridos, é guardadono Map de metadados em cache. É também criada e guardada no respectivo Map a tarefade actualização referente aos metadados do nó inserido no serviço.
Obtenção de metadados. Para obter os metadados de um nó, o agente C2FS chama aoperação getMetadata do serviço de directorias fornecendo o caminho do nó desejado. Afigura 4.3 ilustra o fluxo de execução desta operação.
O primeiro passo a fazer é perceber se os metadados desse nó estão guardados emcache. Caso isto se verifique, os metadados em cache são utilizados, caso contrário, os

Capítulo 4. Concretização dos Serviços de Directorias e de Locks do C2FS 53
Figura 4.1: Diagrama de classes dos serviços de directorias e locks.

Capítulo 4. Concretização dos Serviços de Directorias e de Locks do C2FS 54
Figura 4.2: Diagrama de sequência de uma operação inserção de metadados
metadados são obtidos do DepSpace recorrendo ao objecto NoCacheDirectoryService. Éneste ponto que é verificada a existência do nó cujos metadados são para obter. Caso aoperação rdp feita ao DepSpace não retorne nenhum resultado, é lançada uma excepção.Caso o nó exista, é então construído o objecto NodeMetadata que representa os metadadosobtidos. Os metadados obtidos são então guardados em cache através da inserção dosmesmos num Map que mantém todos os objectos NodeMetadata em cache.
Por fim, é necessário verificar se existem modificações nos metadados guardados lo-calmente (à espera de serem propagados para o DepSpace) referentes ao contentor dedados do nó em questão. Os valores do resumo criptográfico (hash) e o tamanho dos da-dos são então actualizados no objecto FileStats dos metadados a devolver com os valoresguardados localmente.
Actualização de metadados. O fluxo de execução aquando de uma operação de actual-ização de metadados é apresentado na figura 4.4. Nesta operação, o primeiro passo a serfeito pelo serviço de directorias com cache é certificar-se de que os metadados a seremalterados são mantidos em cache. A chamada da operação getMetadata (descrita acima)garante isso.
Após a obtenção dos metadados, caso não exista ainda nenhuma tarefa de actualiza-ção para estes, é necessário lançar uma tarefa deste tipo. É então construída uma novatarefa que é inserida na Map de tarefas em execução, sendo depois agendada para ex-ecução através do objecto do tipo Timer. Para facilitar a compreensão deste diagrama,este objecto foi ignorado, sendo o agendamento da tarefa representada com a chamadarun(DELTA) sobre a instância upTask da classe UpdaterTask.
Após isto, é necessário perceber se a operação em curso tem como objectivo renomearum nó. Caso isto se verifique, são feitas uma sequência de operações (já descritas nasecção 3.2.3), nomeadamente a gestão das tarefas de actualização em curso e das actu-alizações dos metadados locais, para garantir o correcto funcionamento desta operação.Caso a operação em curso não tenha por objectivo a alteração do caminho de um nó, osmetadados são alterados apenas na cache através da remoção dos antigos metadados einserção dos novos no Map que mantém os metadados em cache.

Capítulo 4. Concretização dos Serviços de Directorias e de Locks do C2FS 55
Figura 4.3: Diagrama de sequência de uma operação de obtenção de metadados.

Capítulo 4. Concretização dos Serviços de Directorias e de Locks do C2FS 56
Figura 4.4: Diagrama de sequência de uma operação de actualização de metadados.

Capítulo 4. Concretização dos Serviços de Directorias e de Locks do C2FS 57
4.3.3 Considerações Finais
Nesta secção foram descritos os detalhes de concretização dos serviços de directorias ede locks. Foram explicadas as decisões de desenho para a implementação destes serviços,tal como a interacção entre os vários componentes dos mesmos.
Na próxima secção será apresentada uma avaliação experimental dos mesmos serviços,sendo avaliado desempenho de cada operação fornecida por estes.

Capítulo 4. Concretização dos Serviços de Directorias e de Locks do C2FS 58

Capítulo 5
Avaliação Experimental
Neste capítulo é apresentada uma avaliação do desempenho do serviço de locks e dediferentes versões do serviço de directorias, com e sem partilha de ficheiros. Em primeirolugar será apresentado um estudo sobre o número de operações de metadados feitas pe-los vários benchmarks. Em seguida serão mostradas medições feitas sobre as operaçõesdo DepSpace usadas pelos serviços desenvolvidos, de forma a perceber de que forma éque a latência destas operações condiciona o seu desempenho. É também feita uma com-paração entre a latência média da operação de obtenção de metadados (getMetadata) e aoperação rdp do DepSpace, utilizando o serviço de directoria com diferentes valores parao parâmetro ∆.
Serão apresentados também o tempo de execução de alguns benchmarks aplicados aoC2FS e ainda o tempo de execução de algumas chamadas feitas ao sistema de ficheiros poresses benchmarks, tendo estes experimentos sido efectuados, novamente, com diferentesvalores para o parâmetro ∆.
Será por fim apresentado um estudo ao desempenho do sistema na presença de difer-entes percentagens de ficheiros pessoais.
5.1 Metodologia
As medições apresentadas neste capítulo foram obtidas através da execução de algunsbenchmarks sobre o sistema de ficheiros. Os benchmarks utilizados foram: o Post-Mark [33], que simula um servidor de e-mail; e o Filebench [7], que permite exercitarvários workloads sobre um sistema de ficheiros. A escolha destes dois benchmarks deve-se ao facto de ambos serem adequados para testar o desempenho dos metadados de umsistema de ficheiros [49].
Na utilização do Filebench, foram utilizados três workloads para testar os metadadosdo sistema: o file server, o create files e o copy files. O file server simula um servidorde ficheiros, criando, eliminando e operando sobre vários ficheiros. Os workloads createfiles e copy files têm como função a criação de ficheiros no sistema de ficheiros. A escolha
59

Capítulo 5. Avaliação Experimental 60
destes workloads deve-se ao facto de as aplicações desktop dos dias de hoje fazerem umuso assinalável de ficheiros temporários [30], sendo, portanto, importante o desempenhodo sistema de ficheiros na criação, cópia e eliminação de ficheiros.
Os benchmarks utilizados foram configurados da seguinte forma:
• O PostMark foi configurado para operar sobre 500 ficheiros, com tamanhos com-preendidos entre os 500 bytes e os 9.77KB.
• O workload file server, por sua vez, foi configurado para manter três tarefas a operarsobre 1000 ficheiros, com tamanho de aproximadamente 128KB, aleatoriamenteorganizados numa árvore de directorias com uma profundidade média de cinco nós.
• No workload create files são utilizadas duas tarefas para criar 1000 ficheiros deaproximadamente 16KB cada, organizados numa árvores de directorias com umaprofundidade de aproximadamente cinco nós. Por fim, o workload copy files criauma cópia de uma árvore de directorias com uma profundidade aproximada de 20nós, com 1000 ficheiros de aproximadamente 16KB no sistema de ficheiros.
A utilização de ficheiros de tamanho tão baixo prende-se com o facto de o foco destetrabalho ser o desempenho do sistema para diferentes configurações do serviço utilizadopara armazenar os seus metadados. Desta forma, foram utilizados ficheiros de pequenasdimensões de forma a minimizar o tempo gasto na execução dos benchmarks.
Na execução destas experiências, as réplicas do DepSpace utilizadas pelo serviçode directorias estavam instaladas no Amazon EC2 em máquinas virtuais de configu-ração standard, instaladas na zona de disponibilidade da Europa (Irlanda). O sistemade ficheiros estava montado num computador portátil com aproximadamente 2 anos lo-calizado em Lisboa, utilizando um serviço de internet com ligação de 24.66 Mbps dedownload e 5.16 Mbps de upload1.
Todos os resultados apresentados resultam da média dos valores obtidos de aproxi-madamente dez execuções dos experimentos.
5.2 Número de Operações sobre os Metadados
A tabela 5.1 mostra o número de chamadas de sistema, que resultam na leitura, escritaou actualização de metadados efectuadas por cada um dos benchmarks anteriormentedescritos. Note-se que visto que os benchmarks utilizados simulam o comportamentode aplicações reais, podemos perceber que as chamadas feitas por estas serão da mesmaordem que as apresentadas.
1Valores obtidos do site www.speedtest.net, medindo o débito da ligação entre a localização do cliente(Lisboa) e um servidor na Irlanda (localização onde as réplicas do DepSpace estavam instaladas)

Capítulo 5. Avaliação Experimental 61
Operação PostMark FileServer CreateFiles CopyFiles Total Percent.stat 2896 50240 3804 8790 65730 67.6%flush 1264 15433 1000 3001 20698 21.3%mknod 764 5683 1000 2000 9447 9.7%unlink 764 0 0 0 764 0.8%mkdir 0 226 226 113 565 0.6%Total 5688 71582 6030 13904 97204 100%
Tabela 5.1: Número de operações do sistema de ficheiros chamadas pelos benchmarks.
Como podemos ver na tabela, a operação do sistema de ficheiros stat é a operação quemais vezes é chamada (com 67.6% da totalidade de operações). Como podemos percebertambém, nos benchmarks executados, a operação flush é também uma operação muitochamada.
Tal como anteriormente referido, é importante perceber qual o desempenho do sistemano que diz respeito à criação de ficheiros, visto esta ser uma operação muito comum nasaplicações desktop dos dias de hoje [30]. Como podemos ver na tabela 5.1, a operaçãomknod (operação que cria um novo ficheiro) é uma das operações mais chamadas pelosnossos benchmarks.
5.3 Desempenho dos Serviços de Directorias e Locks
Na figura 5.1 são apresentadas as latências médias observadas para as várias oper-ações do DepSpace utilizadas pelos serviços mencionados. Os dados apresentados foramobtidos a partir da medição do tempo de execução de cada uma das operações aquandoda execução dos benchmarks ou, visto haver operações que são menos exercitadas queoutras, as operações rdAll e replace foram também exercitadas explicitamente. No total,cada uma das operações foi executada aproximadamente 30000 vezes.
Como podemos ver na figura, a latência mais baixa é a das operações rdp sendo estasda ordem dos 63 ms. As operações de inp e cas, utilizadas para remover e inserir tuplosde metadados, apresentam latências na ordem dos 66ms. Por sua vez a operação rdAlltem uma latência média de 75 ms enquanto que a operação replace demora em média 87ms. Com isto podemos perceber que em média, as operações de leitura de metadados,mesmo não usando cache são as mais rápidas, enquanto que as operações de actualizaçãode metadados, embora com uma diferença pouco assinalável, são as que mais tempodemoram.
Note-se também que as operações cas e inp são utilizadas pelo serviço de lockspara inserir e remover tuplos de lock, respectivamente. Segundo estes experimentos, aobtenção e destruição de um lock demora então, em média, 66 ms por operação.
A razão que leva a operação rdp a ser a que menos latência apresenta prende-se com
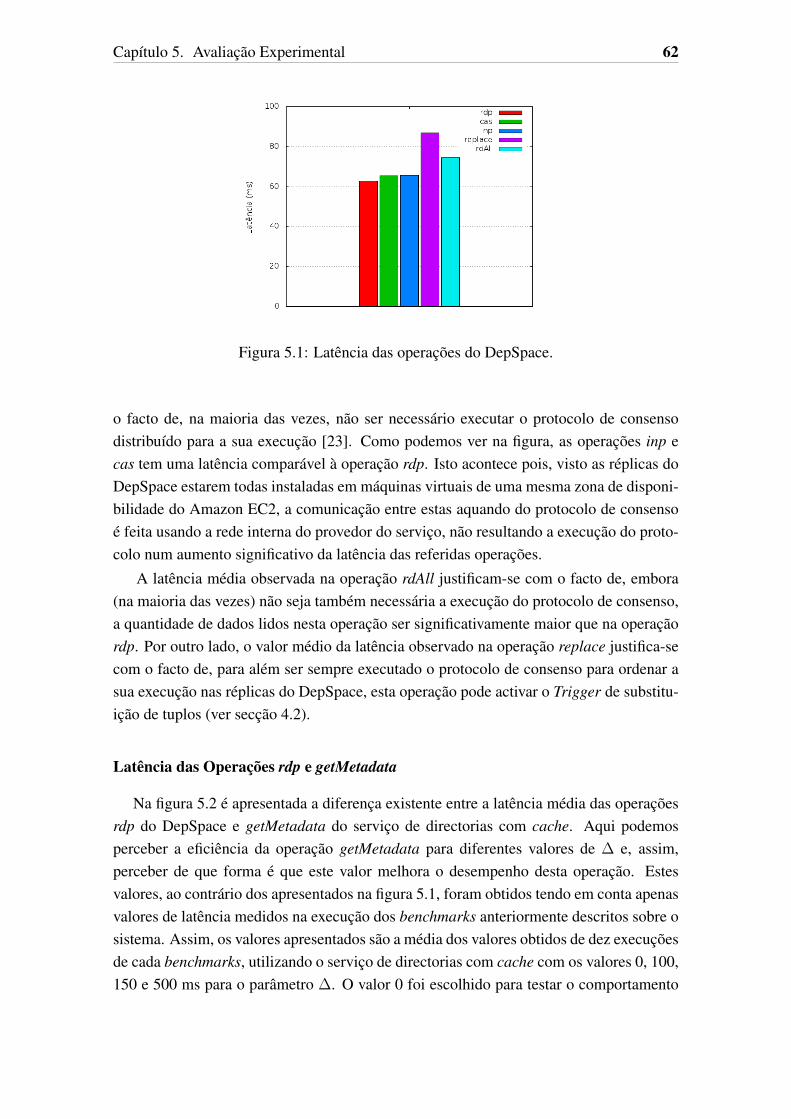
Capítulo 5. Avaliação Experimental 62
Figura 5.1: Latência das operações do DepSpace.
o facto de, na maioria das vezes, não ser necessário executar o protocolo de consensodistribuído para a sua execução [23]. Como podemos ver na figura, as operações inp ecas tem uma latência comparável à operação rdp. Isto acontece pois, visto as réplicas doDepSpace estarem todas instaladas em máquinas virtuais de uma mesma zona de disponi-bilidade do Amazon EC2, a comunicação entre estas aquando do protocolo de consensoé feita usando a rede interna do provedor do serviço, não resultando a execução do proto-colo num aumento significativo da latência das referidas operações.
A latência média observada na operação rdAll justificam-se com o facto de, embora(na maioria das vezes) não seja também necessária a execução do protocolo de consenso,a quantidade de dados lidos nesta operação ser significativamente maior que na operaçãordp. Por outro lado, o valor médio da latência observado na operação replace justifica-secom o facto de, para além ser sempre executado o protocolo de consenso para ordenar asua execução nas réplicas do DepSpace, esta operação pode activar o Trigger de substitu-ição de tuplos (ver secção 4.2).
Latência das Operações rdp e getMetadata
Na figura 5.2 é apresentada a diferença existente entre a latência média das operaçõesrdp do DepSpace e getMetadata do serviço de directorias com cache. Aqui podemosperceber a eficiência da operação getMetadata para diferentes valores de ∆ e, assim,perceber de que forma é que este valor melhora o desempenho desta operação. Estesvalores, ao contrário dos apresentados na figura 5.1, foram obtidos tendo em conta apenasvalores de latência medidos na execução dos benchmarks anteriormente descritos sobre osistema. Assim, os valores apresentados são a média dos valores obtidos de dez execuçõesde cada benchmarks, utilizando o serviço de directorias com cache com os valores 0, 100,150 e 500 ms para o parâmetro ∆. O valor 0 foi escolhido para testar o comportamento

Capítulo 5. Avaliação Experimental 63
do serviço sem a utilização de cache. A escolha dos valores 100 e 150 pretende testar ocomportamento do serviço quando os metadados são mantidos em cache por um tempoaproximado à latência das operações do DepSpace no pior caso. O valor 500 foi escolhidocom o objectivo de perceber até que ponto a subida de ∆ influencia o desempenho doserviço.
Figura 5.2: Latência da obtenção de metadados.
Como podemos observar na figura 5.2, quando o valor de ∆ é 0, não existem ganhosde latência da utilização do serviço, sendo a latência média das operações getMetadataigual à das operações rdp no DepSpace. Por outro lado, sempre que é utilizada cacheno serviço de directorias, a latência na obtenção de metadados passa a cerca de metadeda latência das operações rdp. Observa-se também que, com o aumento do valor de ∆
(e assim o aumento do tempo em que os metadados permanecem válidos em cache),existem pequenas melhorias no valor da latência média da operação getMetadata quandocomparado com o mesmo valor para a operação de leitura do DepSpace.
Através da análise da figura podemos também perceber que os ganhos de desempenhoda operação getMetadata não são proporcionais à subida do valor de ∆. Isto é facilmenteperceptível, por exemplo, verificando as latências médias desta operação com ∆ = 100 e∆ = 500. Neste caso, sendo o valor de ∆ cinco vezes superior, enquanto que a latênciamédia para ∆ = 100 é aproximadamente 50% menor que latência média da operação rdp,para ∆ = 500 existe um ganho de apenas 56.5%. Assim podemos concluir que, para obterimportantes ganhos de desempenho, o valor do parâmetro ∆ deve ser maior que zero, masnão demasiado grande. Embora com a subida deste valor sejam observadas melhorias nodesempenho da operação getMetadata, este aumento leva também a uma diminuição dacoerência dos metadados mantidos no DepSpace. É então importante que este factor sejatido em conta na escolha do valor deste parâmetro.
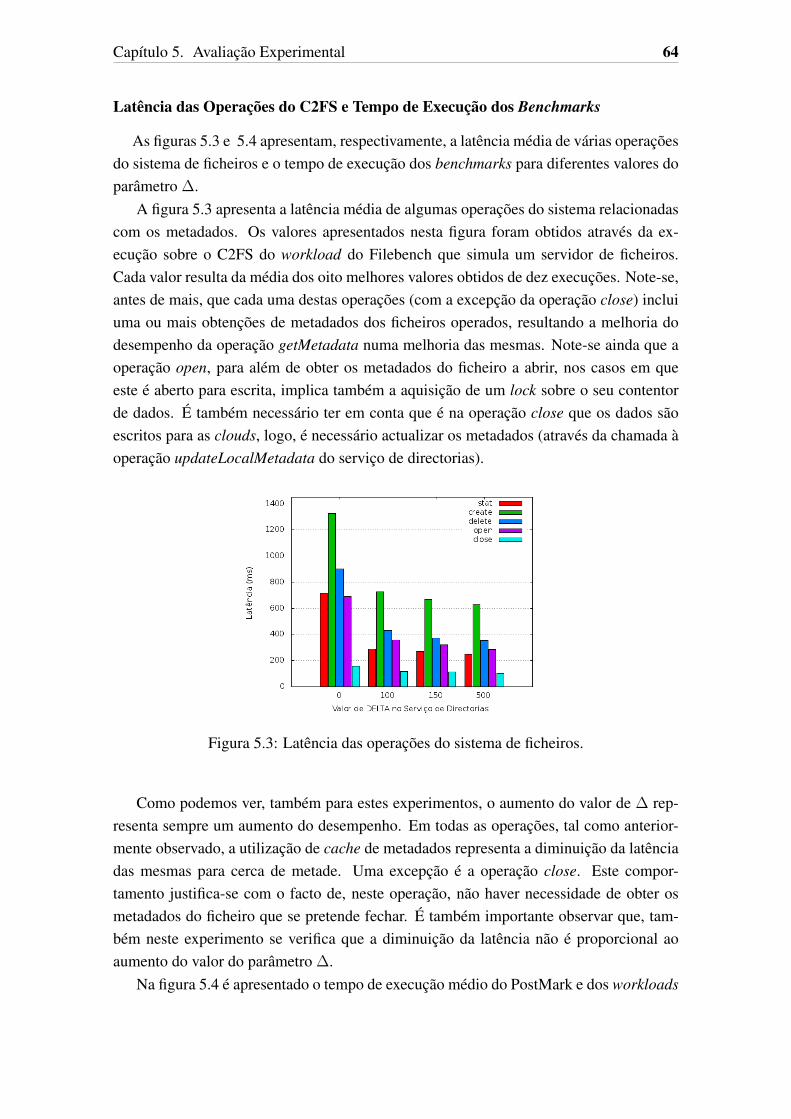
Capítulo 5. Avaliação Experimental 64
Latência das Operações do C2FS e Tempo de Execução dos Benchmarks
As figuras 5.3 e 5.4 apresentam, respectivamente, a latência média de várias operaçõesdo sistema de ficheiros e o tempo de execução dos benchmarks para diferentes valores doparâmetro ∆.
A figura 5.3 apresenta a latência média de algumas operações do sistema relacionadascom os metadados. Os valores apresentados nesta figura foram obtidos através da ex-ecução sobre o C2FS do workload do Filebench que simula um servidor de ficheiros.Cada valor resulta da média dos oito melhores valores obtidos de dez execuções. Note-se,antes de mais, que cada uma destas operações (com a excepção da operação close) incluiuma ou mais obtenções de metadados dos ficheiros operados, resultando a melhoria dodesempenho da operação getMetadata numa melhoria das mesmas. Note-se ainda que aoperação open, para além de obter os metadados do ficheiro a abrir, nos casos em queeste é aberto para escrita, implica também a aquisição de um lock sobre o seu contentorde dados. É também necessário ter em conta que é na operação close que os dados sãoescritos para as clouds, logo, é necessário actualizar os metadados (através da chamada àoperação updateLocalMetadata do serviço de directorias).
Figura 5.3: Latência das operações do sistema de ficheiros.
Como podemos ver, também para estes experimentos, o aumento do valor de ∆ rep-resenta sempre um aumento do desempenho. Em todas as operações, tal como anterior-mente observado, a utilização de cache de metadados representa a diminuição da latênciadas mesmas para cerca de metade. Uma excepção é a operação close. Este compor-tamento justifica-se com o facto de, neste operação, não haver necessidade de obter osmetadados do ficheiro que se pretende fechar. É também importante observar que, tam-bém neste experimento se verifica que a diminuição da latência não é proporcional aoaumento do valor do parâmetro ∆.
Na figura 5.4 é apresentado o tempo de execução médio do PostMark e dos workloads

Capítulo 5. Avaliação Experimental 65
copy files e create files do Filebench para diferentes valores de ∆. Tal como no casoda figura anterior, os resultado aqui apresentados resultam da média dos oito melhoresvalores obtidos de dez execuções.
Figura 5.4: Tempo de execução de benchmarks.
Tal como anteriormente, também nesta figura podemos verificar que a utilização decache de metadados representa um aumento do desempenho do serviço de directorias, eassim, o desempenho global do C2FS. Em todas as execuções, o desempenho aumentacom o crescimento do valor do parâmetro ∆. Podemos ver que, com ∆ = 100, temostempos de execução aproximadamente 50% menores que para ∆ = 0 (48% para o Post-Mark, 43% e 52% para os workloads create files e copy files, respectivamente). Como aumento do valor de ∆ continuam a existir ganhos no desempenho do sistema, sendoestes, no entanto, mais modestos. As melhorias com o aumento do tempo de validade dosmetadados em cache de 100 para 500, no caso dos tempos de execução do PostMark e doworkload copy files são de apenas 10.1% e 13.2%, respectivamente. No caso do workloadcreate files, para os mesmos valores de ∆, temos ganhos bastante nos tempos médios deexecução (na ordem dos 25%).
5.4 Desempenho do Serviço de Directorias sem Partilhade Ficheiros
A utilização do C2FS sem partilha de ficheiros permite aos utilizadores tirar partido dafiabilidade de armazenamento fornecida pelo DepSky [24] com uma interface de sistemade ficheiros, não prejudicando o desempenho do sistema com a necessidade de utilizar oDepSpace [23] para armazenar os metadados. Esta configuração assemelha-se ao modode funcionamento do BlueSky [52] ou do S3QL [19], tendo no entanto melhores garantiasde tolerância a faltas.

Capítulo 5. Avaliação Experimental 66
A figura 5.5 apresenta o tempo de execução dos benchmarks já apresentados nas fig-uras anteriores e a latências das operações stat, create, delete, open e close sobre o sistemade ficheiros. Os valores apresentados resultam da média dos oito melhores resultados dedez execuções.
(a) Tempo de execução de benchmarks sem partilha. (b) Latência das operações do C2FS sem partilha.
Figura 5.5: Latências de operações sobre o C2FS e tempos de execução dos benchmarksusando o serviço de directorias sem partilha.
Como podemos ver na figura 5.5(a), os tempos de execução dos benchmarks no C2FSutilizando o serviço de directorias são em muito inferiores ao melhor tempo observado noC2FS com partilha de ficheiros (figura 5.4). O tempo de execução do PostMark diminuide 242 para 9 segundos, enquanto que nos workloads create files e copy files diminui de299 para 20 segundos e de 446 para 29 segundos, respectivamente.
No que diz respeito à latência das operações do sistema de ficheiros, também sãoobservadas melhorias de desempenho muito assinaláveis, diminuindo a latência médiadas operações stat, create, delete, open e close de 249, 629, 354, 286 e 100 ms/operação(no melhor caso) para 9, 26, 37, 17 e 8 ms/operação.
5.5 Desempenho com a utilização do Espaço de NomesPessoal
A utilização de um espaço de nomes pessoal, armazenado na cloud-of-clouds, ondesão mantidos os metadados de todos os ficheiros privados de cada cliente, para além depermitir a diminuição da quantidade de informação armazenada no DepSpace, permitetambém um aumento do desempenho do sistema.
A figura 5.6 apresenta a latência de algumas operações do sistema e o tempo de ex-ecução do PostMark e dos workloads de criação e cópia de um conjunto de ficheiros,sendo efectuados experimentos com diferentes percentagens de ficheiros pessoais. Para
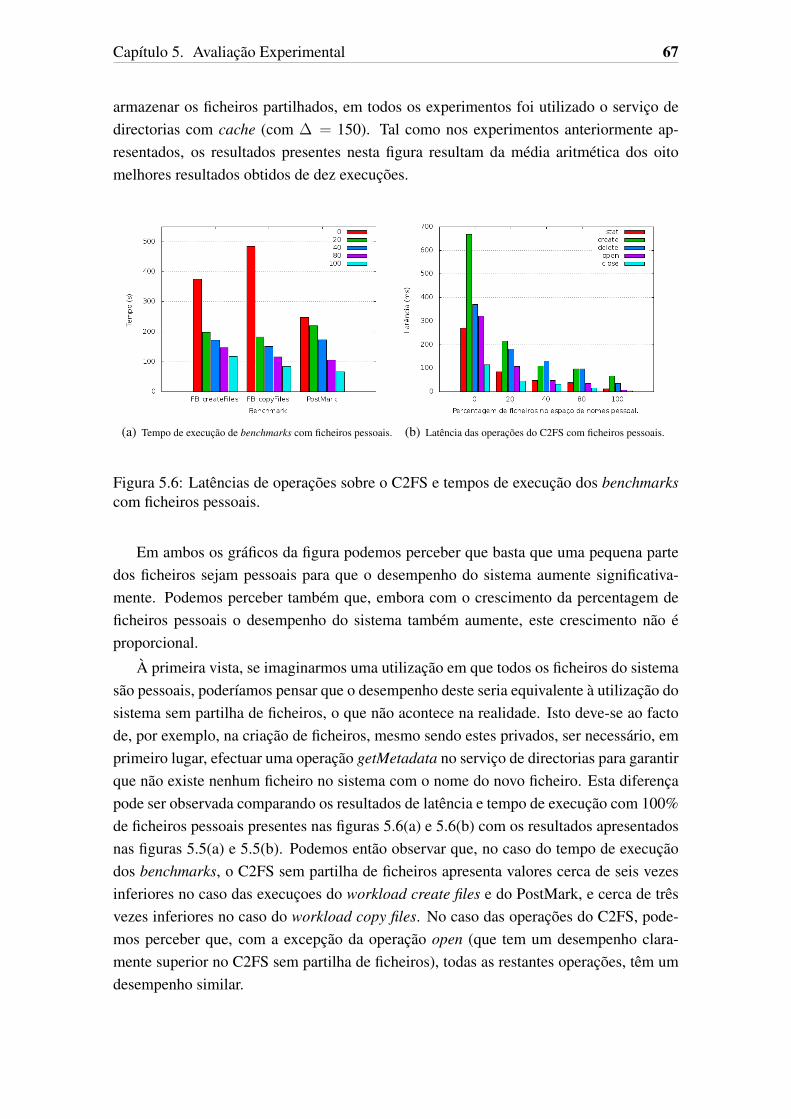
Capítulo 5. Avaliação Experimental 67
armazenar os ficheiros partilhados, em todos os experimentos foi utilizado o serviço dedirectorias com cache (com ∆ = 150). Tal como nos experimentos anteriormente ap-resentados, os resultados presentes nesta figura resultam da média aritmética dos oitomelhores resultados obtidos de dez execuções.
(a) Tempo de execução de benchmarks com ficheiros pessoais. (b) Latência das operações do C2FS com ficheiros pessoais.
Figura 5.6: Latências de operações sobre o C2FS e tempos de execução dos benchmarkscom ficheiros pessoais.
Em ambos os gráficos da figura podemos perceber que basta que uma pequena partedos ficheiros sejam pessoais para que o desempenho do sistema aumente significativa-mente. Podemos perceber também que, embora com o crescimento da percentagem deficheiros pessoais o desempenho do sistema também aumente, este crescimento não éproporcional.
À primeira vista, se imaginarmos uma utilização em que todos os ficheiros do sistemasão pessoais, poderíamos pensar que o desempenho deste seria equivalente à utilização dosistema sem partilha de ficheiros, o que não acontece na realidade. Isto deve-se ao factode, por exemplo, na criação de ficheiros, mesmo sendo estes privados, ser necessário, emprimeiro lugar, efectuar uma operação getMetadata no serviço de directorias para garantirque não existe nenhum ficheiro no sistema com o nome do novo ficheiro. Esta diferençapode ser observada comparando os resultados de latência e tempo de execução com 100%de ficheiros pessoais presentes nas figuras 5.6(a) e 5.6(b) com os resultados apresentadosnas figuras 5.5(a) e 5.5(b). Podemos então observar que, no caso do tempo de execuçãodos benchmarks, o C2FS sem partilha de ficheiros apresenta valores cerca de seis vezesinferiores no caso das execuçoes do workload create files e do PostMark, e cerca de trêsvezes inferiores no caso do workload copy files. No caso das operações do C2FS, pode-mos perceber que, com a excepção da operação open (que tem um desempenho clara-mente superior no C2FS sem partilha de ficheiros), todas as restantes operações, têm umdesempenho similar.

Capítulo 5. Avaliação Experimental 68
5.6 Considerações Finais
Neste capítulo foi apresentada a avaliação experimental feita às versões com e sempartilha de ficheiros do serviço de directorias e à utilização do espaço de nomes pessoal.Aqui, foram estudadas as latências médias das várias operações do DepSpace utilizadaspelos serviços de directorias e de locks, o desempenho de algumas operações do sistemade ficheiros que operam sobre os metadados e ainda o tempo de execução de algunsbenchmarks, para diferentes configurações do sistema.
Neste capítulo demonstrou-se que a utilização de uma cache de metadados temporáriapermite obter ganhos bastante assinaláveis de desempenho, não sendo o aumento do de-sempenho proporcional ao aumento do tempo de validade dos metadados em cache.
Verificou-se também que, para além de diminuir a quantidade de informação ar-mazenada no DepSpace, a utilização do espaço de nomes pessoal permite ainda grandesganhos de desempenho.

Capítulo 6
Conclusão
O C2FS é um sistema de ficheiros multi-utilizador com uma interface estilo-POSIX,que permite o armazenamento de dados em várias clouds, e ainda tolera falhas por partedos clientes e provedores de armazenamento nas clouds.
Neste trabalho, para além da arquitectura geral do C2FS, foram apresentadas em de-talhe as várias versões do serviço de directorias, utilizadas para gerir os metadados eefectuar controlo de acesso aos ficheiros. A primeira versão apresentada permite a par-tilha de ficheiros entre vários utilizadores, não fazendo, no entanto, uso de cache paraaumentar o desempenho do serviço. Em seguida foi apresentado o serviço de directoriasque, para além de permitir a partilha de ficheiros, faz uso da cache para aumentar o desem-penho do serviço (em especial das leituras de metadados). Foi também descrito o serviçode directorias sem partilha de ficheiros, uma versão que permite tirar partido das vanta-gens inerentes ao armazenamento dos dados na cloud-of-clouds sem que o desempenhodo serviço de directorias seja prejudicado com a latência da rede. Para aumentar o de-sempenho das versões do serviço de directorias com partilha de ficheiros, foi apresentadoo conceito de espaço de nomes pessoal, um mecanismo que permite, ao mesmo tempo,aumentar o desempenho do manuseamento de metadados de ficheiros não partilhados ereduzir a quantidade de informação armazenada pelo serviço.
Todas as versões do serviço de directorias descritas acima fornecem garantias de in-tegridade e confidencialidade para os metadados. As versões deste serviço que permitema partilha de ficheiros, para além das garantias já referidas, garantem ainda a disponibil-idade dos metadados armazenados, através da utilização de um serviço de coordenaçãotolerante a faltas bizantinas [23].
Foi ainda apresentado um serviço de trincos, utilizado para coordenar o acesso concor-rente aos contentores de dados dos ficheiros por parte de diferentes processos escritores.Por fim, foi apresentado um mecanismo que, através da interacção entre os serviços dedirectorias e armazenamento [40] do C2FS, permite ao sistema garantir consistência fortedos dados armazenados na cloud-of-clouds.
Os resultados reportados numa avaliação experimental aos serviços de directorias e
69

Capítulo 6. Conclusão 70
trincos do C2FS mostram que os referidos serviços têm um desempenho aceitável paracertos workloads comuns como servidores de ficheiros ou servidores de e-mail.
6.1 Trabalho futuro
Actualmente, todos os utilizadores do C2FS têm de partilhar as contas de utilizadordos provedores de armazenamento utilizados para armazenar os dados dos ficheiros dosistema. Neste cenário, cada utilizador do sistema está apto a obter qualquer contentorde dados a partir do DepSky, sendo da responsabilidade do serviço de directorias manterprivada aos utilizadores não autorizados a chave necessária para decifrar os dados. Estaabordagem é apenas útil, e.g., num modelo empresarial no qual a organização fica encar-regue dos encargos relacionados com o armazenamento dos dados partilhados entre osseus colaboradores. No entanto, esta abordagem deixa de fazer sentido quando o sistemaé utilizado por vários utilizadores comuns pois, neste caso, os custos inerentes à utiliza-ção dos vários provedores de armazenamento nas clouds por parte dos vários utilizadoresficariam ao encargo de apenas uma pessoa. Para resolver este problema, uma das tarefasfuturas é desenvolver uma nova versão do serviço de directorias que permita a partilha deficheiros armazenados em diferentes contas de utilizador nas clouds de armazenamento,desenvolvendo também um novo mecanismo de controlo de acesso aos ficheiros para estaversão.
Há ainda a necessidade de avaliar o desempenho do sistema na presença de faltasou ainda o desempenho do mecanismo que permite ao C2FS fornecer uma semântica deconsistência forte, aquando da presença de dados inconsistentes nas clouds.

Apêndice A
Prova Informal do Serviço de Trincos
O serviço de trinco apresentado deve garantir certas propriedades de correcção. Destaforma, as seguintes garantias devem ser fornecidas:
Safety 1 (S1) Existe no máximo um processo com um trinco sobre um contentor de da-dos.
Safety 2 (S2) A menos que o detentor de um trinco o queira, nenhum trinco fica inválidoantes do seu tempo de validade expirar.
Liveness 1 (L1) Quando nenhum processo detém o trinco sobre um contentor, se umprocesso tentar adquirir esse trinco, este consegue.
Liveness 2 (L2) Quando um processo detentor de um trinco falha, eventualmente, o con-tentor reservado por esse trinco é libertado.
A propriedade S1 tem por objectivo garantir que o serviço faz uma correcta gestãodas reservas de contentores de dados. Por outro lado, sem a propriedade L1, uma formade garantir que nunca existem dois processos com o trinco sobre o mesmo contentorseria, por exemplo, não permitir que nenhum processo obtivesse trincos sobre quaisquercontentores, deixando o serviço de ter qualquer utilidade. Estas duas propriedades são aspropriedades fundamentais de um serviço de trincos.
A segunda propriedade de safety permite garantir que, após a obtenção de um trincopor parte de um cliente e antes do seu tempo de validade expirar, o cliente mantém acessoexclusivo de escrita a um contentor. Por outro lado, a segunda propriedade de liveness tempor objectivo garantir que, na presença de faltas por parte dos clientes, nunca existirãocontentores reservados eternamente, impossíveis de usar por clientes correctos.
Assumindo um conjunto de processos que falham apenas por paragem (ver secção 3.1.2),pretende-se então provar de forma informal que o serviço de trinco do C2FS cumpre estaspropriedades de correcção:
71

Apêndice A. Prova Informal do Serviço de Trincos 72
S1. Como já referido anteriormente, a operação do serviço de trinco que permite aosclientes adquirir um trinco sobre um dado contentor de dados é a operação tryAquire,representando o sucesso desta operação a obtenção de um trinco por parte do clienteinvocador da operação. Esta operação tenta inserir um tuplo no espaço de tuplos através dachamada cas do DepSpace. Como podemos ver no algoritmo 5, o template fornecido nestachamada é igual ao tuplo a inserir, contendo ambos um identificador estático referente aotipo de tuplo (LOCK) e o identificador do contentor a reservar. Tendo em conta que aoperação de aquisição de um trinco só tem sucesso se o serviço conseguir inserir o tuplode trinco no espaço, aliado com o facto de a semântica da operação cas do DepSpace sóinserir o tuplo caso não haja nenhum tuplo no espaço que faça correspondência com otemplate dado, podemos comprovar que a operação só tem sucesso se não existir nenhumoutro tuplo no espaço com os mesmos campos, ou seja, com o mesmo identificador docontentor de dados. Assim, prova-se que, caso um cliente queira adquirir um trinco sobreum contentor de dados já reservado por um outro cliente (que conseguiu inserir o tuplode trinco referente a esse contentor), a operação não irá ter sucesso, pois o seu tuplo nãoconseguirá ser inserido, garantindo que nunca existirão dois processos com um trincosobre o mesmo contentor.
S2. O tuplo de trinco que é inserido no DepSpace, e que é utilizado para reservar umcontentor de dados, é um tuplo temporário. Aquando da chamada da operação tryAquirepor parte de um cliente, é fornecido o parâmetro time, que específica a quantidade detempo que o tuplo de trinco deve permanecer no espaço. Este tuplo é também configuradocom permissões de escrita apenas para o seu dono, ou seja, para o serviço de trinco que oinsere. Tendo em conta que o DepSpace garante que este tuplo não desaparece do espaçode tuplos antes do seu tempo de validade (time) expirar, aliado com o facto de nenhumcliente malicioso estar apto a remover o mesmo tuplo, podemos garantir que, enquanto otuplo for válido, ele é mantido no espaço. Assim, estando um determinado trinco válidoapenas se o seu tuplo de trinco se encontra no espaço de tuplos, podemos provar queum trinco nunca fica inválido antes do seu tempo de validade expirar, a menos que o serdetentor o queira.
L1. Como explicado na prova anterior, os tuplos de trinco inseridos no DepSpace sãotuplos temporários. Assim, em caso de falha no cliente que detém o trinco (não permitindoque este possa renovar o tempo de validade deste tuplo), o tuplo irá desaparecer do espaçode tuplos após time ms. Desta forma, prova-se que, caso o cliente detentor de um trincofalhe, o contentor de dados associado a este trinco acaba por ser libertado pois o tuplo detrinco utilizado para reservar esse contentor desaparece do espaço após um determinadotempo, deixando o contentor livre para ser acedido por outro cliente.

Apêndice A. Prova Informal do Serviço de Trincos 73
L2. Como anteriormente explicado, para um cliente obter um trinco sobre um determi-nado contentor de dados basta ter sucesso na execução da operação tryAquire do serviçode trinco, dando como argumento o identificador desse contentor. Assim, visto que osucesso desta operação depende da inserção do tuplo de trinco no espaço, caso não existaum tuplo de trinco para o referido contentor (o que significa que este pode ser acedido),a inserção deste tuplo tem sucesso. Prova-se portanto que, se for feita uma operação deaquisição de trinco sobre um dado contentor não reservado por parte de um cliente, estetem sucesso na operação cas e, consequentemente, na obtenção do trinco.


Bibliografia
[1] Amazon Elastic Block Store. http://aws.amazon.com/ebs/.
[2] Amazon Elastic Compute Cloud. http://aws.amazon.com/pt/ec2/.
[3] Amazon ElastiCache. http://aws.amazon.com/elasticache/.
[4] Amazon Simple Storage Service. http://aws.amazon.com/s3/.
[5] Apple iCloud. http://www.apple.com/icloud/.
[6] DropBox. https://dropbox.com.
[7] Filebench. http://sourceforge.net/apps/mediawiki/filebench.
[8] FUSE. http://fuse.sourceforge.net/.
[9] FUSE-J. http://fuse-j.sourceforge.net/.
[10] Google App Engine. https://appengine.google.com.
[11] Google Cloud Storage. https://developers.google.com/storage/.
[12] GoogleDrive. https://drive.google.com/.
[13] Microsoft Windows Azure. http://www.windowsazure.com/.
[14] OpenStack Storage. http://www.openstack.org/software/openstack-storage/.
[15] PlanetLab Europe web site. http://www.planet-lab.eu/.
[16] POSIX. http://en.wikipedia.org/wiki/POSIX.
[17] Project TCLOUDS - trustworthy clouds - privacy and resilience for internet-scalecritical infrastructure. http://www.tclouds-project.eu/.
[18] S3FS. http://code.google.com/p/s3fs/.
[19] S3QL. http://code.google.com/p/s3ql/.
[20] Tuple space. http://en.wikipedia.org/wiki/Tuple_space.
75

Bibliografia 76
[21] Hussam Abu-Libdeh, Lonnie Princehouse, and Hakim Weatherspoon. RACS: Re-dundant Array of Cloud Storage. In ACM Symposium on Cloud Computing (SOCC),June 2010.
[22] A. Adya, W. J. Bolosky, M. Castro, R. Chaiken, G. Cermak, J. R. Douceur, J. How-ell, J. R. Lorch, M. Theimer, and R. P. Warrenhofer. Farsite: Federated, available,and reliable storage for an incompletely trusted environment. In 5th OSDI. Dec2002.
[23] Alysson N. Bessani, Eduardo P. Alchieri, Miguel Correia, and Joni S. Fraga.DepSpace: a Byzantine fault-tolerant coordination service. In Proc. of the 3rd ACMEuropean Systems Conference – EuroSys’08, pages 163–176, April 2008.
[24] Alysson N. Bessani, Miguel Correia, Bruno Quaresma, Fernando Andre, and PauloSousa. DepSky: Dependable and Secure Storage in cloud-of-clouds. In Proc. of the3rd ACM European Systems Conference – EuroSys’11, April 2011.
[25] Alysson Neves Bessani, Miguel Correia, Joni da Silva Fraga, and Lau Cheuk Lung.Sharing Memory between Byzantine Processes using Policy-Enforced Tuple Spaces.In IEEE Transactions on Parallel and Distributed Systems. Vol. 20 no. 3. pages 419-43, IEEE Computer Society, March 2009.
[26] Mike Burrows. The Chubby Lock Service. In Proceedings of 7th Symposium onOperating Systems Design and Implementation – OSDI 2006, November 2006.
[27] John R. Douceur, Atul Adya, Josh Benaloh, William J. Bolosky, and Gideon Yuval.A Secure Directory Service based on Exclusive Encryption. In Proceedings of the18th Annual Computer Security Applications Conference (ACSAC), December 2002.
[28] Jonh R. Douceur and Jon Howell. Distributed directory service in farsite file system.In Proceedings of the 7th USENIX Symposium on Operating Systems Design andImplementation. OSDI’06, pages 321-333, 2006. USENIX Association.
[29] S. Ghemawat, H. Gobioff, and S. Leung. The Google file system. In 19th SOSP.pages 29-43, December, 2003.
[30] Tyler Harter, Chris Dragga, Michael Vaughn, Andrea C. Arpaci-Dusseau, andRemzi H. Arpaci-Dusseau. A File is Not a File: Understanding the I/O Behav-ior of apple desktop applications. In Proceedings of the 23rd ACM Symposium onOperating Systems Principles – SOSP’11, October 2011.
[31] J. H. Howard, M. L. Kazar, Menees S. G., D. N. Nichols, M. Satyanarayanan, R. N.Sidebotham, and M. J. West. Scale and performance in a distributed file system. InACM Trans. Comput. Syst. vol. 6, no. I, February 1988.

Bibliografia 77
[32] Patrick Hunt, Mahadev Konar, Flavio Junqueira, and Benjamin Reed. Zookeeper:Wait-free Coordination for Internet-scale Services. In Proc. of the USENIX AnnualTechnical Conference – ATC 2010, pages 145–158, June 2010.
[33] Jeffrey Katcher. PostMark: A New File System Benchmark. Technical report,August 1997.
[34] Leslie Lamport. On interprocess communication (part II). Distributed Computing,1(1):203–213, January 1986.
[35] Leslie Lamport. The part-time parliament. ACM Transactions Computer Systems,16(2):133–169, May 1998.
[36] Leslie Lamport, Robert Shostak, and Marshall Pease. The Byzantine generals prob-lem. ACM Transactions on Programing Languages and Systems, 4(3):382–401, July1982.
[37] Edward L. Lee and Chandramohan A. Thekkath. Petal: Distributed Virtual Disks. InIn the Proceedings of the 7th Intl. Conf. on Architectural Support for ProgrammingLangauges and Operating Systems. pages 84-92, October 1996.
[38] Ricardo Mendes, Tiago Oliveira, Alysson Bessani, and Marcelo Pasin. C2FS: umSistema de Ficheiros Seguro e Fiável para Cloud-of-clouds. In INForum12, Septem-ber 2012.
[39] Hugo Miranda, Alexandre Pinto, and Luís Rodrigues. Appia communication frame-work. http://appia.di.fc.ul.pt/.
[40] T. Oliveira. Substrato de Armazenamento para Sistemas de Ficheiros para cloud-of-clouds. Relatório do Projecto de Engenharia Informática. DI/FCUL, September2012.
[41] R. Posse. Serviço de Coordenação para Bases de Dados Replicadas. Relatório doProjecto de Engenharia Informática. DI/FCUL, Setembro 2011.
[42] Krishna P. N. Puttaswamy, Thyaga Nandagopal, and Murali Kodialam. Frugal Stor-age for Cloud File Systems. In Proc. of the 3rd ACM European Systems Conference– EuroSys’12, April 2012.
[43] B. Reed and F. P. Junqueira. A simple totally ordered broadcast protocol. In LADIS’08: Proceedings of the 2nd Workshop on Large-Scale Distributed Systems and Mid-dleware. pages 1–6, New York, NY, USA, 2008. ACM.

Bibliografia 78
[44] M. Satyanarayanan, J. H. Howard, D. N. Nichols, R. N. Sidebotham, A. Z. Spector,and M. J. West. The ITC distributed file system: principles and design. In Proceed-ings of the 10th ACM Symposium Oper. Syst. Principles. Orcas Island, December1985.
[45] M. Satyanarayanan, P. Kumar, M. Okasaki, E. Siegel, and D. Steere. Coda: A highlyavailable file system for a distributed workstation environment. In IEEE Trans. onComp. 4. 39 (Apr 1990), 447-459.
[46] B. Schoenmakers. A simple publicly verifiable secret sharing scheme and its ap-plication to electronic voting. In Proceedings of the 19th International CryptologyConference on Advances in Cryptology - CRYPTO’99. Aug. 1999.
[47] J. Sousa and A. Bessani. From byzantine consensus to bft state machine replication:A latency-optimal transformation. In In the Proc. of the 9th European DependableComputing Conference, 2012.
[48] Jeremy Stribling, Yair Sovran, Irene Zhang, Xavid Pretzer, Jinyang Li, M.FransKaashoek, and Robert Morris. Flexible, Wide-Area Storage for Distributed Systemwith WheelFS. In In the Proceedings of the 6th USENIX Symposium on NetworkedSystems Design and Implementation (NSDI ’09). Boston, MA, April 2009.
[49] Vasily Tarasov, Saumitra Bhanage, Erez Zadok, and Margo Seltzer. BenchmarkingFile System Benchmarking: It *IS* Rocket Science. In 13th USENIX Workshop inHot Topics in Operating Systems (HotOS XIII). May 2011.
[50] C. Thekkath and E. L. T. Mann. Frangipani: A scalable distributed file system. InIn the Proceedings of the 16th SOSP.
[51] W. Vogels. Eventually Consistent. In Communications of the ACM, October 2008.
[52] Michael Vrable, Stefan Savage, and Geoffrey M. Voelker. BlueSky: A cloud-backedfile system for the enterprise. In Proc. of the 10th USENIX Conference on File andStorage Technologies – FAST’12, 2012.
[53] S. A. Weil, S. A. Brandt, E. L. Miller, and C. Maltzahn. CRUSH: Controlled,scalable, decentralized placement of replicated data. In Proceedings of the 2006ACM/IEEE Conference on Superomputing (SC ’04). Tampa, FL, Nov, 2006, ACM.
[54] Sage A. Weil, Scott A. Brandt, Ethan L. Miller, Darrell D. E. Long, and CarlosMaltzahn. Ceph: A Scalable, High-Performance Distributed File System. In Proc.of the 7th USENIX Symposium on Operating Systems Design and Implementation –OSDI 2006, pages 307–320, 2006.