unsupervised feature selection for linked social media data
DESCRIPTION
Unsupervised Feature Selection for Linked Social Media Data. Jiliang Tang and Huan Liu Computer Science and Engineering Arizona State University August 12-16, 2012 KDD2012. Social Media. The expansive use of social media generates massive data in an unprecedented rate - PowerPoint PPT PresentationTRANSCRIPT

Data Mining and Machine Learning Lab
Unsupervised Feature Selection for Linked Social Media Data
Jiliang Tang and Huan LiuComputer Science and Engineering
Arizona State University
August 12-16, 2012 KDD2012

Social Media
• The expansive use of social media generates massive data in an unprecedented rate
- 250 million tweets per day
- 3,000 photos in Flickr per minute
-153 million blogs posted per year

High-dimensional Social Media Data
• Social Media Data can be high-dimensional– Photos– Video stream– Tweets
• Presenting new challenges– Massive and noisy data– Curse of dimensionality

Feature Selection
• Feature selection is an effective way of preparing high-dimensional data for efficient data mining.
• What is new for feature selection of social media
data?
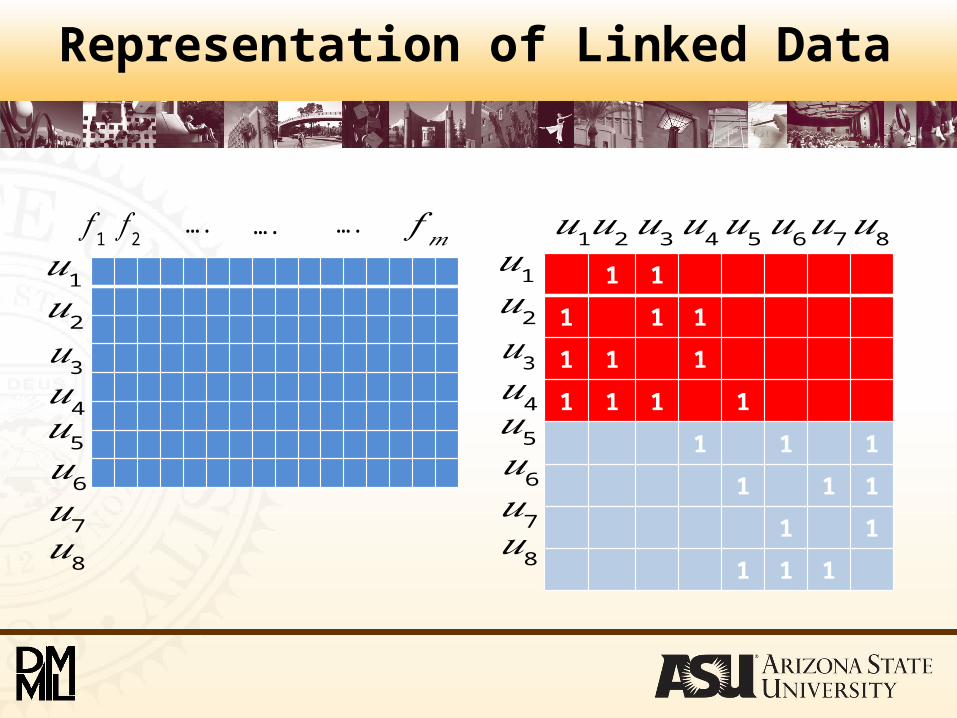
Representation of Linked Data
𝑢1𝑢2𝑢3
𝑢5𝑢6
𝑢4
𝑢7𝑢8
𝑓 1𝑓 2 𝑓 𝑚…. …. ….
1 1
1 1 1
1 1 1
1 1 1 11 1 1
1 1 11 1
1 1 1
𝑢1𝑢2𝑢3
𝑢5𝑢6
𝑢4
𝑢7𝑢8
𝑢1𝑢2𝑢3𝑢4𝑢5𝑢6𝑢7𝑢8

Challenges for Feature Selection
• Unlabeled data - No explicit definition of feature relevancy
- Without additional constraints, many subsets of features could be equally good
• Linked data - Not independent and identically distributed

Opportunities for Feature Selection
• Social media data provides link information - Correlation between data instances
• Social media data provides extra constraints
- Enabling us to exploring the use of social theories

Problem Statement
• Given n linked data instances, its attribute-value representation X, its link representation R, we want to select a subset of features by exploiting both X and R for these n data instances in an unsupervised scenario.

Supervised and Unsupervised Feature Selection
• A unified view– Selecting features that are consistent with some
constraints for either supervised or unsupervised feature selection
– Class labels are sort of targets as a constraint
• Two problems for unsupervised feature selection
- What are the targets?
- Where can we find constraints?

Our Framework: LUFS

The Target for LUFS

The Constraints for LUFS

Pseudo-class Label
• s is a selection vector
- s(j) = 1 if j-th feature is selected, s(j)=0 otherwise
- , X = diag(s)X
• Y is the pseudo-class label indicator matrix
- Y =
- ||Y(:,i) =

Social Dimension for Link Information
• Social Dimension captures group behaviors of linked Instances– Instances in different social dimensions are disimilar– Instances within a social dimension are similar
• Example:

Social Dimension Regularization
• Within, between, and total social dimension scatter matrices,
• Instances are similar within social dimensions while dissimilar between social dimensions.

Constraint from Attribute-Value Data
• Similar instances in terms of their contents are more likely to share similar topics,

An Optimization Problem for LUFS

The Optimization Problem for LUFS

The Optimization Problem for LUFS

The Optimization Problem for LUFS

LUFS after Two Relaxations
• Spectral Relaxation on Y - Social Dimension Regularization:
• W = diag(s)W, and adding 2,1-norm on W
)YTr(YFFYYTrmin TTT )(

Evaluating LUFS
• Datasets and experiment setting
• What is the performance of LUFS comparing to state-of-the art baseline methods?
• Why does LUFS work?

Evaluating LUFS
• Datasets and experiment setting
• What is the performance of LUFS comparing to state-of-the art baseline methods?
• Why does LUFS work?

Data and Characteristics
• BlogCatalog
• Flickr

http://dmml.asu.edu/users/xufei/datasets.html

Experiment Settings
• Metrics - Clustering: Accuracy and NMI
- K-Means
• Baseline methods - UDFS
- SPEC
- Laplacian Score

Evaluating LUFS
• Datasets and experiment setting
• What is the performance of LUFS comparing to state-of-the art baseline methods?
• Why does LUFS work?

Results on Flickr

Results on Flickr

Results on BlogCatalog

Evaluating LUFS
• Datasets and experiment setting
• What is the performance of LUFS comparing to state-of-the art baseline methods?
• Why does LUFS work?

Probing Further: Why Social Dimensions Work
Social Dimensions Random Groups
…….
…….
Link Information
Social Dimension Extraction
Random Assignment

Results in Flickr

Future Work
• Further exploration of link information
• Noise and incomplete social media data
• Other sources: multi-view sources
• The strength of social ties ( strong and weak ties mixed)

http://www.public.asu.edu/~huanliu/projects/NSF12/
More Information?

Questions
Acknowledgments: This work is, in part, sponsored by National Science Foundation via a grant (#0812551). Comments and suggestions from DMML members and reviewers are greatly appreciated.