using simplicity to make hard big data problems easy
TRANSCRIPT

Using simplicity to make hard Big Data
problems easy

Master Master DatasetDataset Batch viewsBatch views
New DataNew Data Realtime Realtime viewsviews
QueryQuery
Lambda Architecture

Master Master DatasetDataset
R/W R/W databasesdatabases
Stream Stream processorprocessor
Proposed alternative
(Problematic)

Easy problem

struct PageView { UserID id, String url, Timestamp timestamp }

Implement:
function NumUniqueVisitors( String url, int startHour, int endHour)

Unique visitors over a range of hours

Notes:
• Not limiting ourselves to current tooling
• Reasonable variations of existing tooling are acceptable
• Interested in what’s fundamentally possible

Traditional Architectures
ApplicationApplication DatabasesDatabases
ApplicationApplication DatabasesDatabasesStream Stream processorprocessorQueueQueue
Synchronous
Asynchronous

Approach #1
• Use Key->Set database
• Key = [URL, hour bucket]
• Value = Set of UserIDs

Approach #1
• Queries:
• Get all sets for all hours in range of query
• Union sets together
• Compute count of merged set

Approach #1
• Lot of database lookups for large ranges
• Potentially a lot of items in sets, so lots of work to merge/count
• Database will use a lot of space

Approach #2
Use HyperLogLog

interface HyperLogLog { boolean add(Object o); long size(); HyperLogLog merge(HyperLogLog... otherSets);}

Approach #2
• Use Key->HyperLogLog database
• Key = [URL, hour bucket]
• Value = HyperLogLog structure

Approach #2
• Queries:
• Get all HyperLogLog structures for all hours in range of query
• Merge structures together
• Retrieve count from merged structure

Approach #2
• Much more efficient use of storage
• Less work at query time
• Mild accuracy tradeoff

Approach #2
• Large ranges still require lots of database lookups / work

Approach #3
• Use Key->HyperLogLog database
• Key = [URL, bucket, granularity]
• Value = HyperLogLog structure

Approach #3
• Queries:
• Compute minimal number of database lookups to satisfy range
• Get all HyperLogLog structures in range
• Merge structures together
• Retrieve count from merged structure

Approach #3
• All benefits of #2
• Minimal number of lookups for any range, so less variation in latency
• Minimal increase in storage
• Requires more work at write time

Hard problem

struct Equiv { UserID id1, UserID id2}
struct PageView { UserID id, String url, Timestamp timestamp }


Person A Person B

Implement:
function NumUniqueVisitors( String url, int startHour, int endHour)

[“foo.com/page1”, 0][“foo.com/page1”, 1] [“foo.com/page1”, 2]
...[“foo.com/page1”, 1002]
{A, B, C}{B}
{A, C, D, E}...
{A, B, C, F, Z}

[“foo.com/page1”, 0][“foo.com/page1”, 1] [“foo.com/page1”, 2]
...[“foo.com/page1”, 1002]
{A, B, C}{B}
{A, C, D, E}...
{A, B, C, F, Z}
A <-> C

Any single equiv could change any bucket

No way to take advantage of HyperLogLog

Approach #1
• [URL, hour] -> Set of PersonIDs
• UserID -> Set of buckets
• Indexes to incrementally normalize UserIDs into PersonIDs

Approach #1
• Getting complicated
• Large indexes
• Operations require a lot of work

Approach #2
• [URL, bucket] -> Set of UserIDs
• Like Approach 1, incrementally normalize UserId’s
• UserID -> PersonID

Approach #2
• Query:
• Retrieve all UserID sets for range
• Merge sets together
• Convert UserIDs -> PersonIDs to produce new set
• Get count of new set

Incremental UserID normalization

Attempt 1:
• Maintain index from UserID -> PersonID
• When receive A <-> B:
• Find what they’re each normalized to, and transitively normalize all reachable IDs to “smallest” val

1 <-> 41 -> 14 -> 1
2 <-> 55 -> 22 -> 2
5 <-> 3 3 -> 2
4 <-> 55 -> 12 -> 1
3 -> 1 never gets produced!

Attempt 2:
• UserID -> PersonID
• PersonID -> Set of UserIDs
• When receive A <-> B
• Find what they’re each normalized to, and choose one for both to be normalized to
• Update all UserID’s in both normalized sets

1 <-> 41 -> 14 -> 1
1 -> {1, 4}
2 <-> 55 -> 22 -> 2
2 -> {2, 5}
5 <-> 3 3 -> 22 -> {2, 3, 5}
4 <-> 55 -> 12 -> 13 -> 1
1 -> {1, 2, 3, 4, 5}

Challenges
• Fault-tolerance / ensuring consistency between indexes
• Concurrency challenges

General challenges with traditional
architectures• Redundant storage of information
(“denormalization”)
• Brittle to human error
• Operational challenges of enormous installations of very complex databases

Master Master DatasetDataset
Indexes for Indexes for uniques over uniques over
timetime
Stream Stream processorprocessor
No fully incremental approach will work!

Let’s take a completely different approach!

Some Rough Definitions
Complicated: lots of parts

Some Rough Definitions
Complex: intertwinement between separate functions

Some Rough Definitions
Simple: the opposite of complex

Real World Example

ID Name Location ID
1 Sally 3
2 George 1
3 Bob 3
Location ID City State Population
1 New York NY 8.2M
2 San Diego CA 1.3M
3 Chicago IL 2.7M
Normalized schema
Normalization vs Denormalization

Join is too expensive, so denormalize...

ID Name Location ID City State
1 Sally 3 Chicago IL
2 George 1 New York NY
3 Bob 3 Chicago IL
Location ID City State Population
1 New York NY 8.2M
2 San Diego CA 1.3M
3 Chicago IL 2.7M
Denormalized schema

Complexity between robust data modeland query performance

Allow queries to be out of date by hours

Store every Equiv and PageView
Master Master DatasetDataset

Master Master DatasetDataset
Continuously recompute indexes
Indexes for Indexes for uniques over uniques over
timetime

Indexes = function(all data)


Iterative graph algorithm
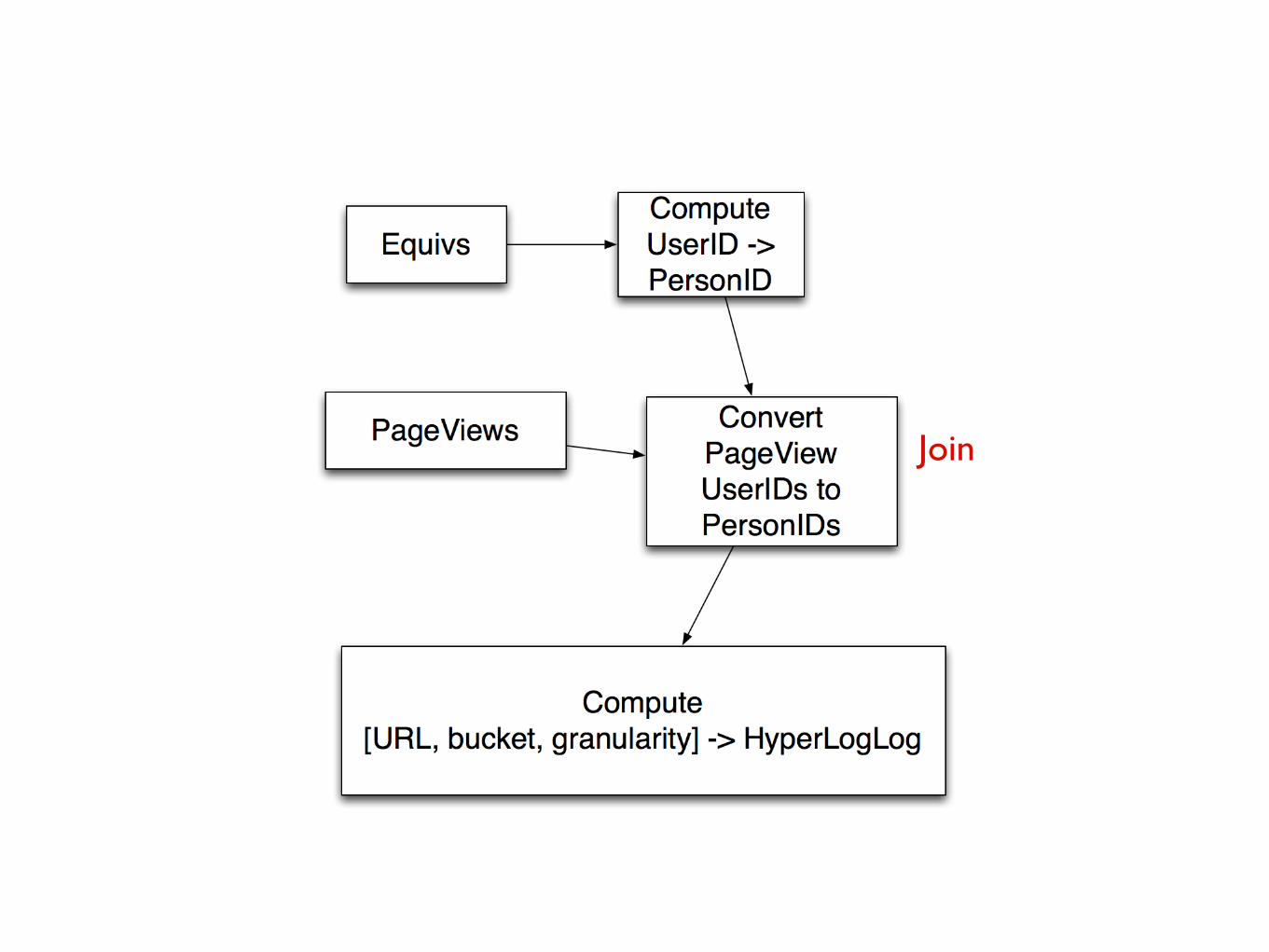
Join

Basic aggregation

Sidenote on tooling
• Batch processing systems are tools to implement function(all data) scalably
• Implementing this is easy

Person 1 Person 6
UserID normalization

UserID normalization




Conclusions
• Easy to understand and implement
• Scalable
• Concurrency / fault-tolerance easily abstracted away from you
• Great query performance

Conclusions
• But... always out of date

Absorbed into batch viewsAbsorbed into batch views Not Not absorbedabsorbed
NowTime
Just a small percentageof data!

Master Master DatasetDataset Batch viewsBatch views
New DataNew Data Realtime Realtime viewsviews
QueryQuery

Get historical buckets from batch viewsand recent buckets from realtime views

Implementing realtime layer
• Isn’t this the exact same problem we faced before we went down the path of batch computation?

Approach #1
• Use the exact same approach as we did in fully incremental implementation
• Query performance only degraded for recent buckets
• e.g., “last month” range computes vast majority of query from efficient batch indexes

Approach #1
• Relatively small number of buckets in realtime layer
• So not that much effect on storage costs

Approach #1
• Complexity of realtime layer is softened by existence of batch layer
• Batch layer continuously overrides realtime layer, so mistakes are auto-fixed

Approach #1
• Still going to be a lot of work to implement this realtime layer
• Recent buckets with lots of uniques will still cause bad query performance
• No way to apply recent equivs to batch views without restructuring batch views

Approach #2
• Approximate!
• Ignore realtime equivs

UserID -> UserID -> PersonIDPersonID
(from batch)
Approach #2
PageviewPageview Convert UserID Convert UserID to PersonIDto PersonID
[URL, bucket][URL, bucket]->->
HyperLogLogHyperLogLog

Approach #2
• Highly efficient
• Great performance
• Easy to implement

Approach #2
• Only inaccurate for recent equivs
• Intuitively, shouldn’t be that much inaccuracy
• Should quantify additional error

Approach #2
• Extra inaccuracy is automatically weeded out over time
• “Eventual accuracy”

Simplicity

Input:Normalize/denormalize
Output:Data model robustness
Query performance

Master Master DatasetDataset Batch viewsBatch views
NormalizedRobust data model
DenormalizedOptimized for queries

Normalization problem solved
• Maintaining consistency in views easy because defined as function(all data)
• Can recompute if anything ever goes wrong

Human fault-tolerance

Complexity of Read/Write Databases

Black box fallacyBlack box fallacy

Incremental compaction
• Databases write to write-ahead log before modifying disk and memory indexes
• Need to occasionally compact the log and indexes

Memory Disk
Write-ahead log
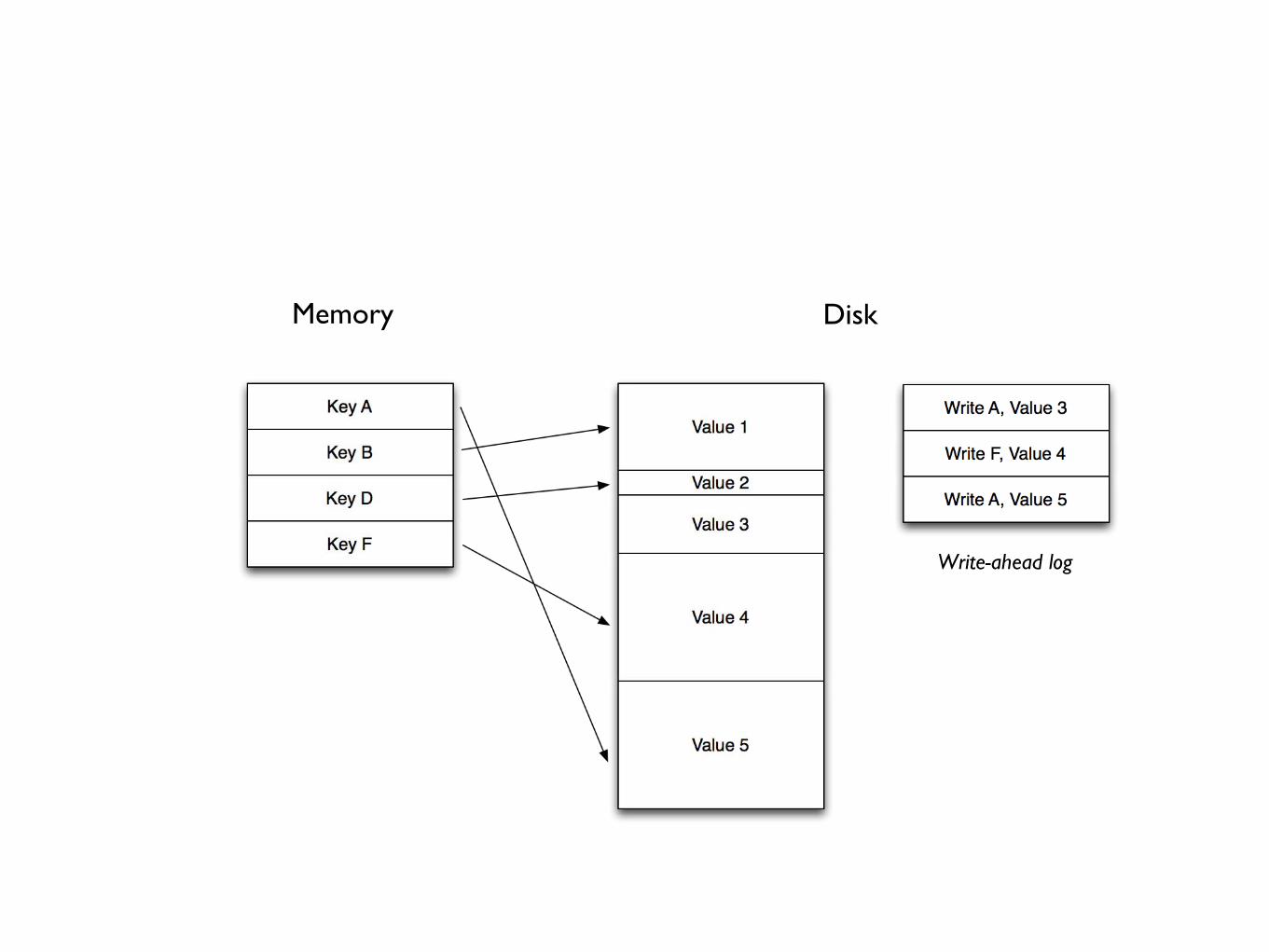
Memory Disk
Write-ahead log

Memory Disk
Write-ahead log
Compaction

Incremental compaction
• Notorious for causing huge, sudden changes in performance
• Machines can seem locked up
• Necessitated by random writes
• Extremely complex to deal with

More Complexity
• Dealing with CAP / eventual consistency
• “Call Me Maybe” blog posts found data loss problems in many popular databases
• Redis
• Cassandra
• ElasticSearch

Master Master DatasetDataset Batch viewsBatch views
New DataNew Data Realtime Realtime viewsviews
QueryQuery

Master Master DatasetDataset Batch viewsBatch views
New DataNew Data Realtime Realtime viewsviews
QueryQuery
No random writes!

Master Master DatasetDataset
R/W R/W databasesdatabases
Stream Stream processorprocessor

Master Master DatasetDataset
ApplicationApplication R/W R/W databasesdatabases
(Synchronous version)

Master Master DatasetDataset Batch viewsBatch views
New DataNew Data Realtime Realtime viewsviews
QueryQuery
Lambda Architecture

Lambda = Function
Query = Function(All Data)

Lambda Architecture
• This is most basic form of it
• Many variants of it incorporating more and/or different kinds of layers
