virt1997bu machine learning on vmware vsphere with or ... · machine learning on vmware vsphere...
TRANSCRIPT

VIRT1997BU
#VMworld #VIRT1997BU
Machine Learning on VMware vSphere with NVIDIA GPUs
VMworld 2017 Content: Not fo
r publication or distri
bution

• This presentation may contain product features that are currently under development.
• This overview of new technology represents no commitment from VMware to deliver these features in any generally available product.
• Features are subject to change, and must not be included in contracts, purchase orders, or sales agreements of any kind.
• Technical feasibility and market demand will affect final delivery.
• Pricing and packaging for any new technologies or features discussed or presented have not been determined.
Disclaimer
CONFIDENTIAL 2
VMworld 2017 Content: Not fo
r publication or distri
bution

Uday Kurkure, VMware Performance Engineering Ziv Kalmanovich, VMware vSphere Product Management
VIRT1997BU
#VMworld #SER3052BU
Machine Learning on VMware vSphere with NVIDIA GPUs
VMworld 2017 Content: Not fo
r publication or distri
bution

Overview
• Defining Machine Learning
• Accelerator Infrastructure
• Topologies
• Benchmarks
– DirectPath IO vs Mediated Passthrough
– Scalability
– Mixed Workloads
• VMware Vision for ML/DL Infrastructure on vSphere
CONFIDENTIAL
4
VMworld 2017 Content: Not fo
r publication or distri
bution
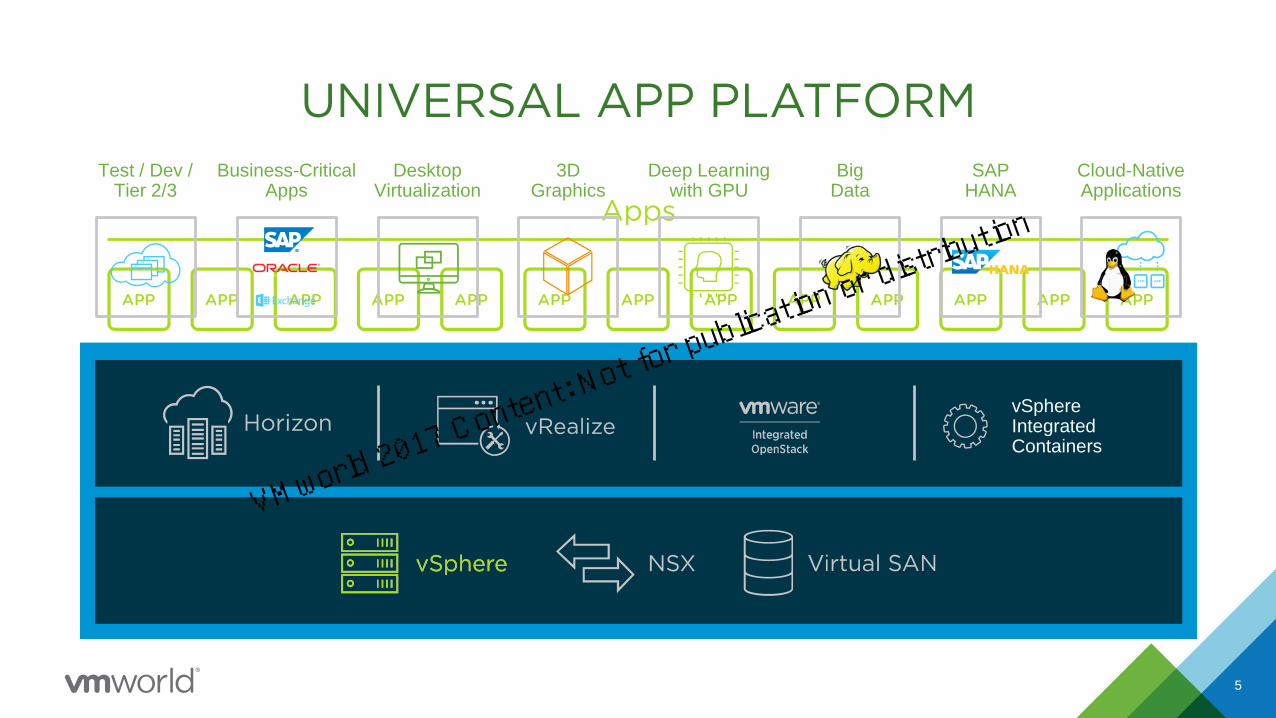
5
Test / Dev /Tier 2/3
Business-CriticalApps
DesktopVirtualization
3DGraphics
BigData
Cloud-NativeApplications
Deep Learningwith GPU
vSphere Integrated Containers
SAPHANA
Universal App Platform
VMworld 2017 Content: Not fo
r publication or distri
bution
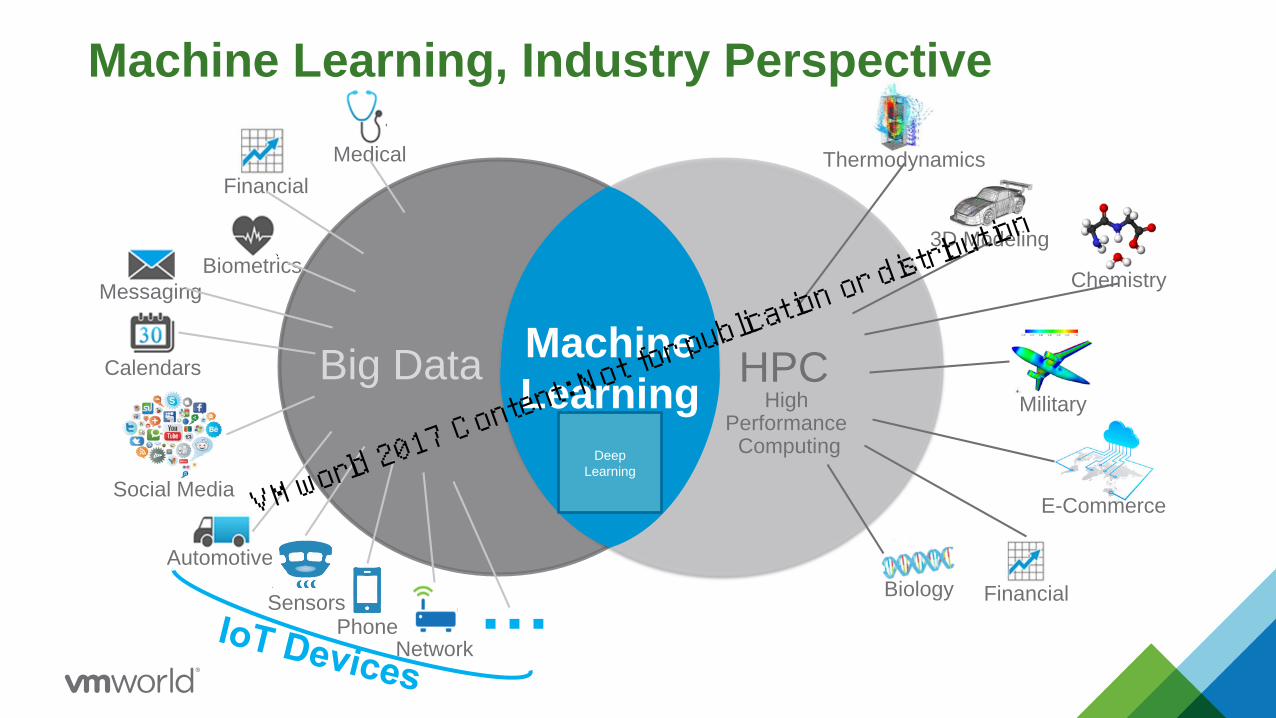
Machine Learning, Industry Perspective
Big Data HPC
Financial
Medical
Biometrics
Automotive
Calendars
Messaging
Network
SensorsPhone
3D Modeling
Chemistry
Military
E-Commerce
FinancialBiology
Thermodynamics
Social Media
…
High Performance
Computing
Machine
Learning
Deep
Learning
VMworld 2017 Content: Not fo
r publication or distri
bution
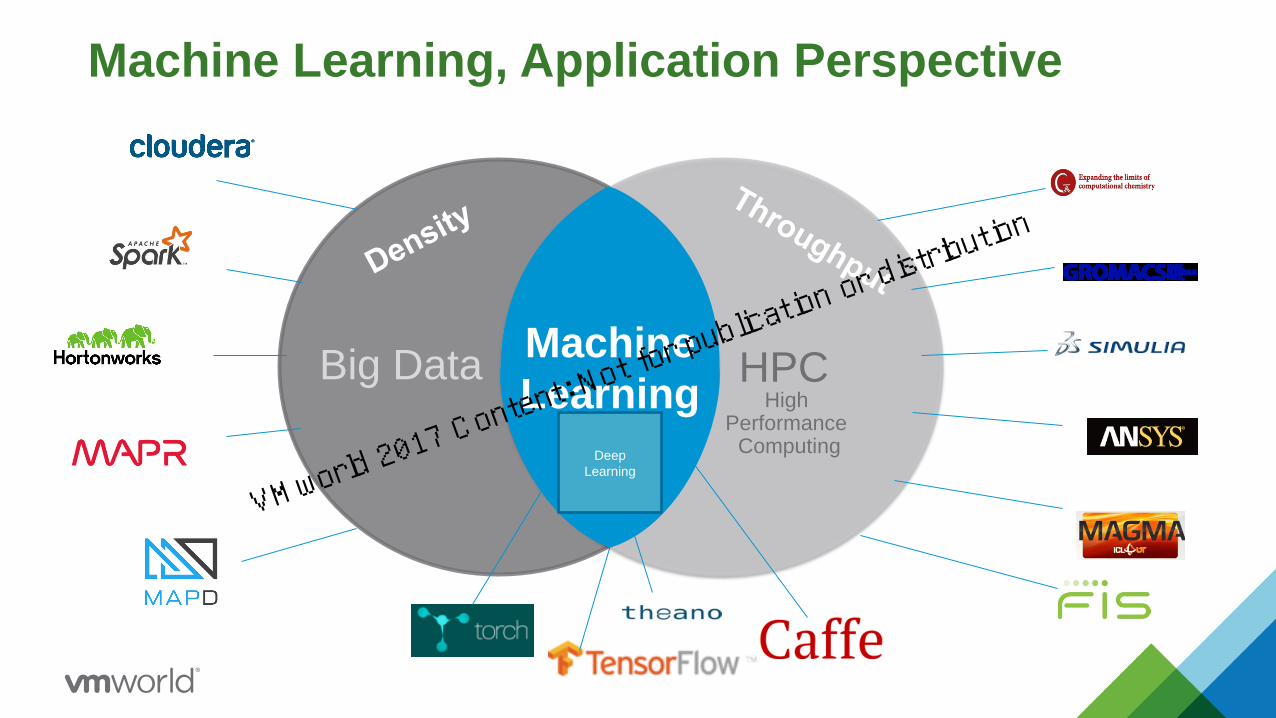
Machine Learning, Application Perspective
Big Data HPCMachine
Learning High Performance
ComputingDeep
Learning
VMworld 2017 Content: Not fo
r publication or distri
bution
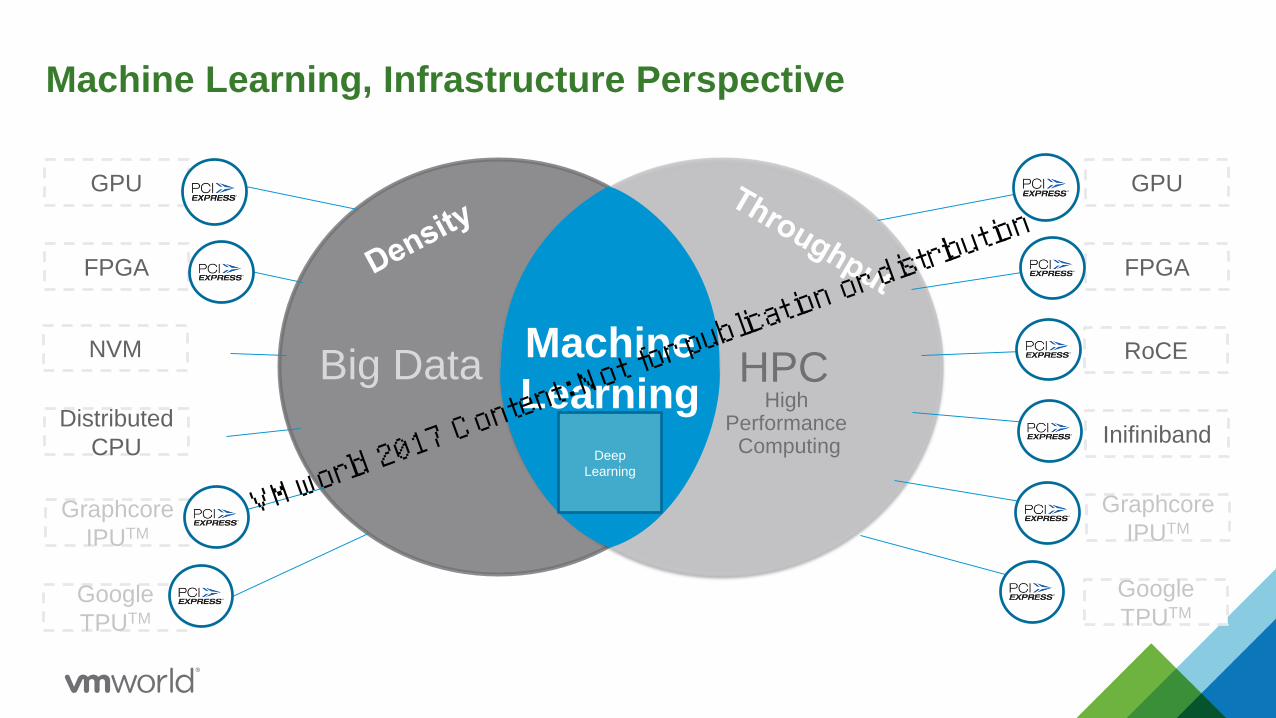
Machine Learning, Infrastructure Perspective
Big Data HPCMachine
Learning High Performance
ComputingDeep
Learning
GPU
FPGA
RoCE
Inifiniband
GPU
FPGA
NVM
Distributed
CPU
Graphcore
IPUTM
TPUTM
Graphcore
IPUTM
TPUTM
VMworld 2017 Content: Not fo
r publication or distri
bution
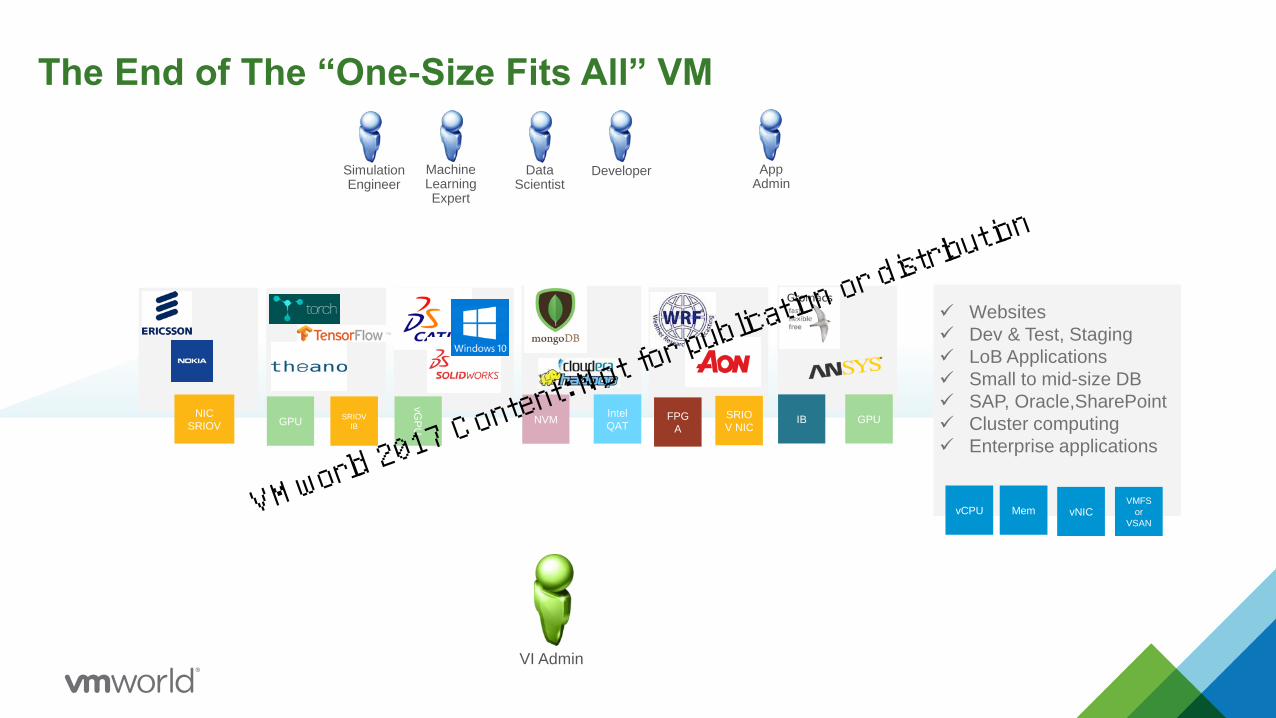
The End of The “One-Size Fits All” VM
✓ Websites
✓ Dev & Test, Staging
✓ LoB Applications
✓ Small to mid-size DB
✓ SAP, Oracle,SharePoint
✓ Cluster computing
✓ Enterprise applications
vCPU Mem vNICVMFS
or
VSAN
NIC
SRIOV GPUSRIOV
IBIB GPUSRIO
V NICFPG
A
vG
PU NVM
VI Admin
App Admin
DeveloperData Scientist
Intel
QAT
Machine Learning Expert
SimulationEngineer
VMworld 2017 Content: Not fo
r publication or distri
bution
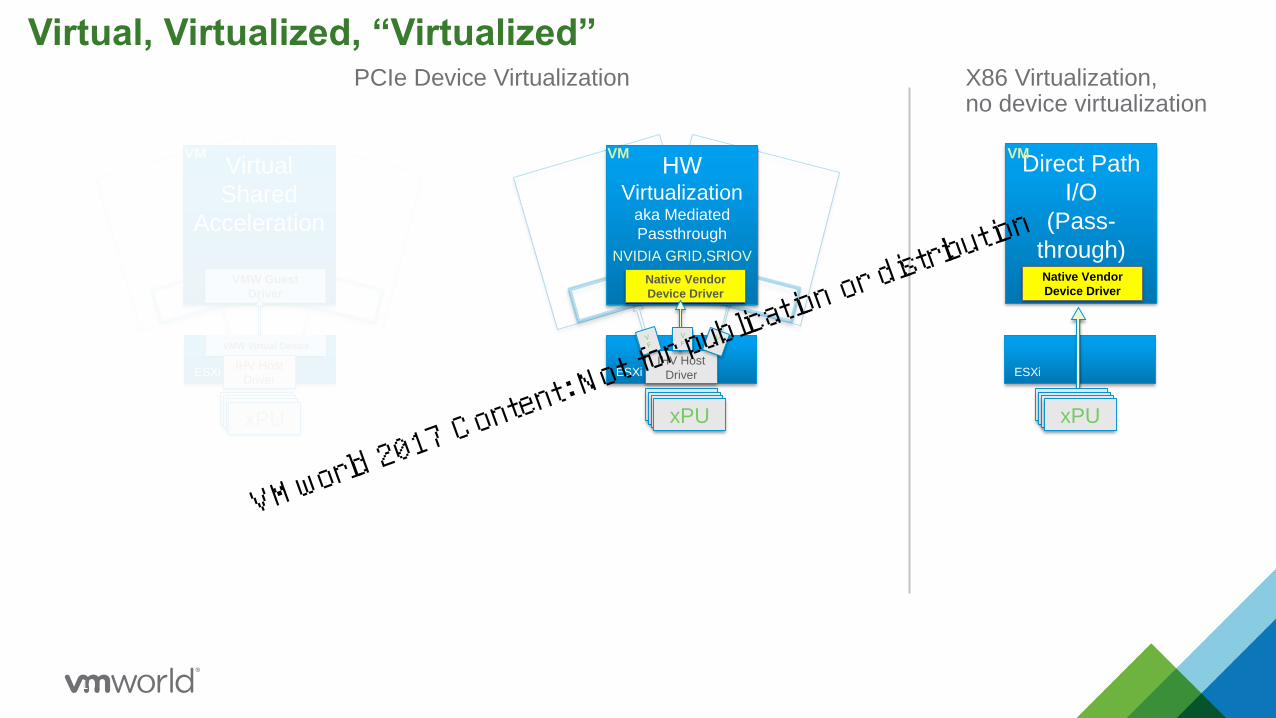
10
Direct Path
I/O
(Pass-
through)
VM
ESXi
Native Vendor
Device Driver
HW Virtualization
aka Mediated
Passthrough
VM
ESXi ESXi
Virtual
Shared
Acceleration
VM
IHV Host
Driver
VMW Virtual Device
IHV Host
Driver
VMW Guest
Driver
Native Vendor
Device Driver
X86 Virtualization, no device virtualization
PCIe Device Virtualization
Virtual, Virtualized, “Virtualized”
NVIDIA GRID,SRIOV
V
F
xPUxPUxPUxPUxPUxPUxPUxPUxPUxPUxPUxPU
VMworld 2017 Content: Not fo
r publication or distri
bution
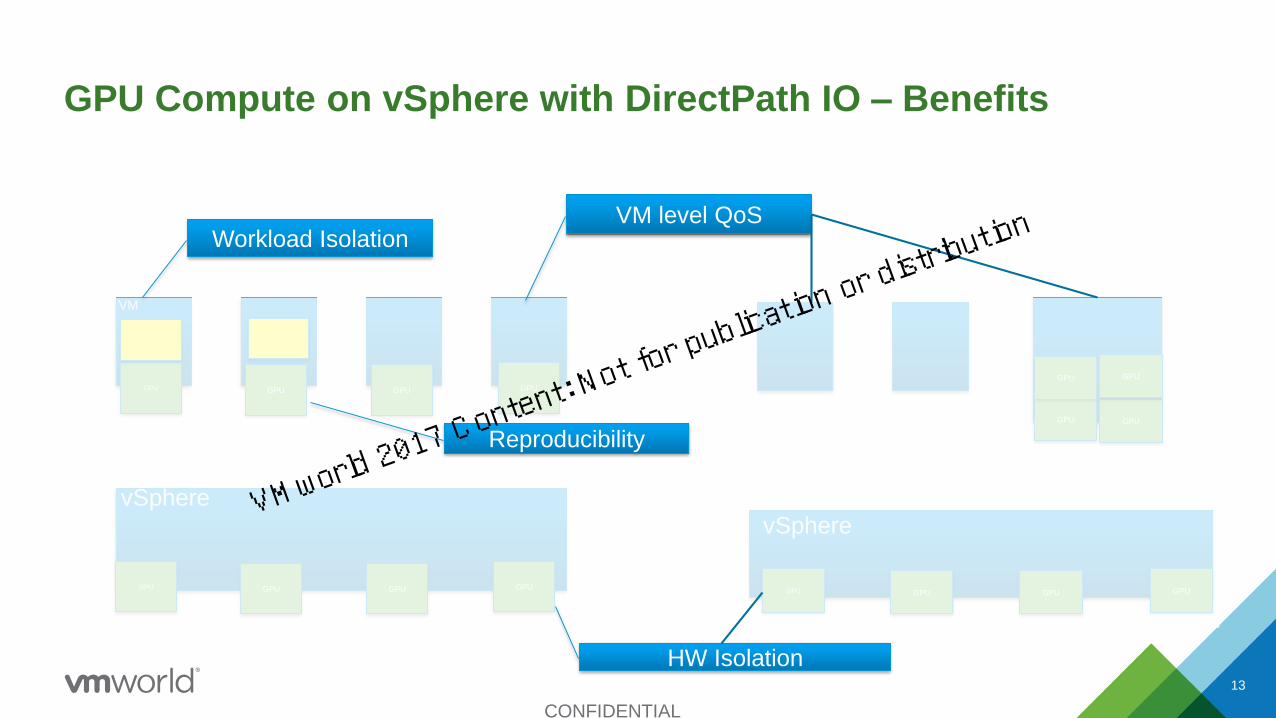
CONFIDENTIAL
13
GPU Compute on vSphere with DirectPath IO – Benefits
GPUGPUGPUGPU
GPU
GPU
GPU
GPU
vSphere
GPUGPUGPUGPU
GPUGPUGPUGPU
vSphere
VM
Workload Isolation
Reproducibility
VM level QoS
HW Isolation
VMworld 2017 Content: Not fo
r publication or distri
bution
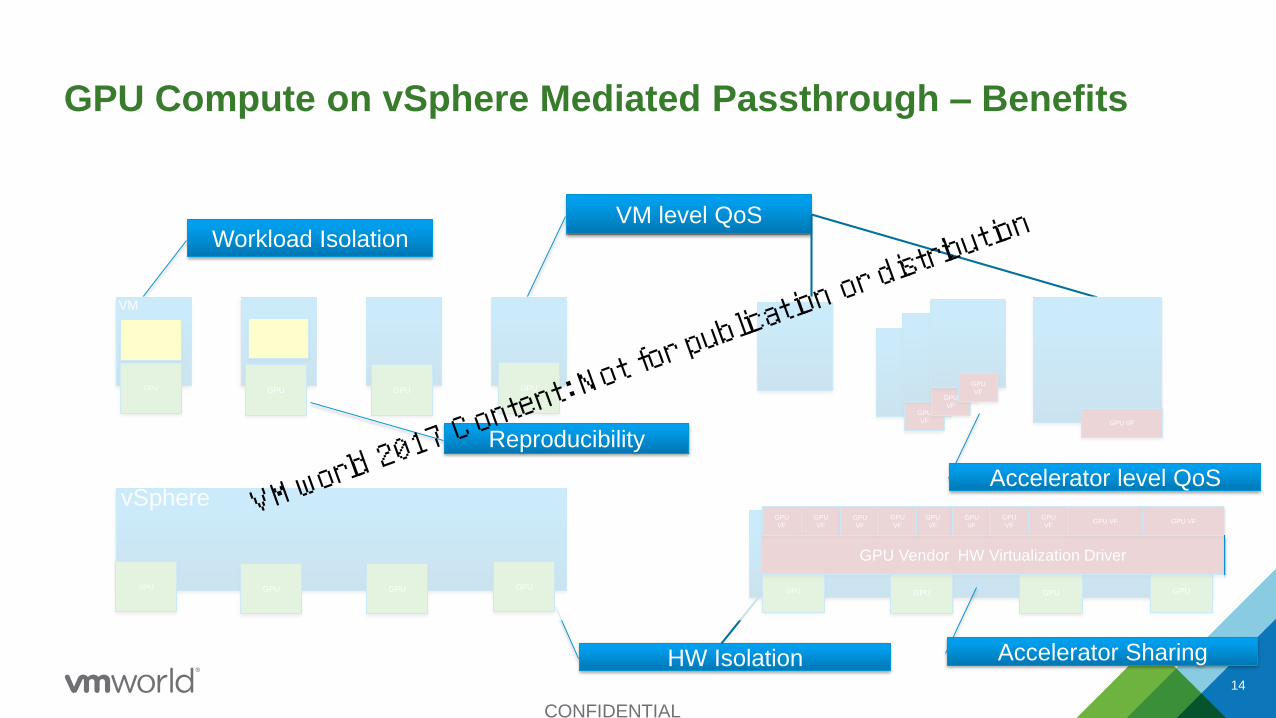
CONFIDENTIAL
14
GPU Compute on vSphere Mediated Passthrough – Benefits
GPUGPUGPUGPU
GPUGPUGPUGPU
GPUGPUGPUGPU
vSphere
VM
Workload IsolationVM level QoS
HW Isolation
GPU Vendor HW Virtualization Driver
GPU
VFGPU
VF
GPU
VF
GPU
VFGPU VF
GPU
VF
GPU
VFGPU
VF
GPU
VFGPU VF
GPU VF
GPU
VF
GPU
VF
GPU
VF
Accelerator level QoS
Accelerator Sharing
Reproducibility
VMworld 2017 Content: Not fo
r publication or distri
bution

CONFIDENTIAL
15
GPUGPUGPUGPU
GPU
GPU
GPU
GPU
vSphere
GPUGPUGPUGPU
GPUGPUGPUGPU
vSphere
VM
1:1 X:1
CUDA Developer
CUDA Developer
Data Scientist
Data Scientist
GPU Compute on vSphere with DirectPath IO – Machine Learning
VMworld 2017 Content: Not fo
r publication or distri
bution
CONFIDENTIAL
16
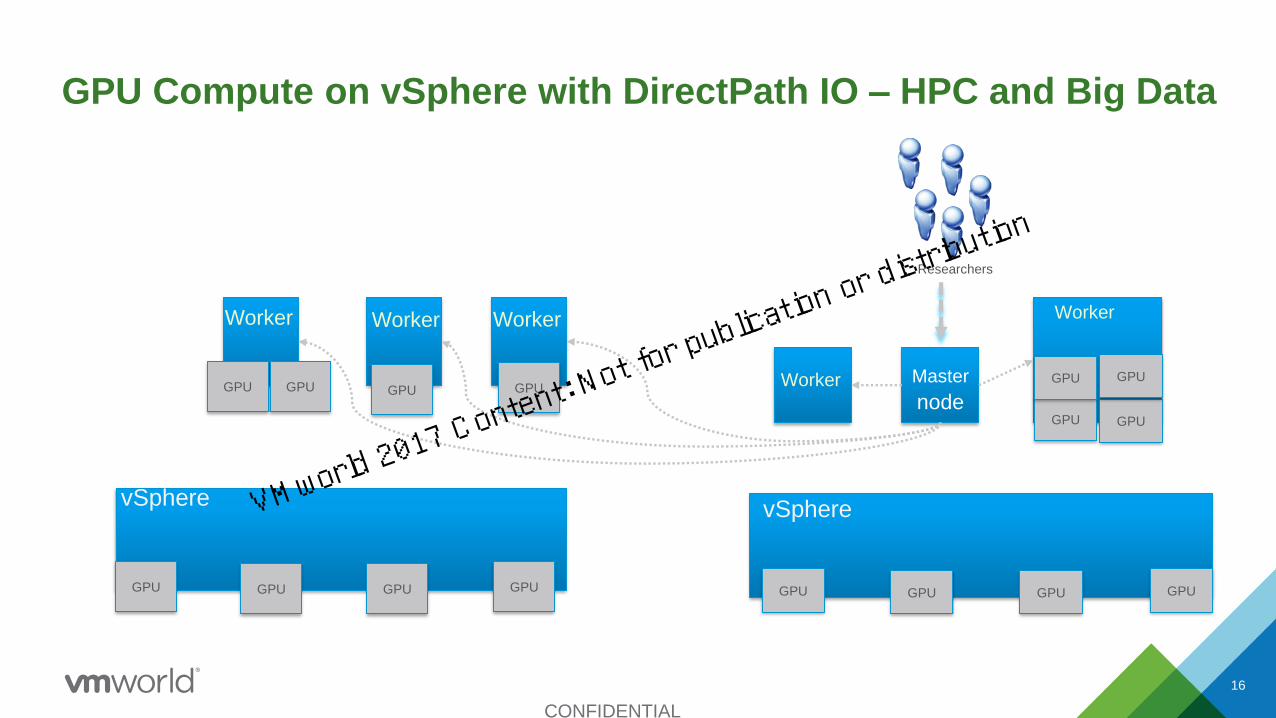
Master
node
GPUGPUGPUGPU
GPU
GPU
GPU
GPU
vSphere
GPUGPUGPUGPU
GPUGPUGPUGPU
vSphere
Researchers
GPU Compute on vSphere with DirectPath IO – HPC and Big Data
Worker
Worker
WorkerWorkerWorker
VMworld 2017 Content: Not fo
r publication or distri
bution
17
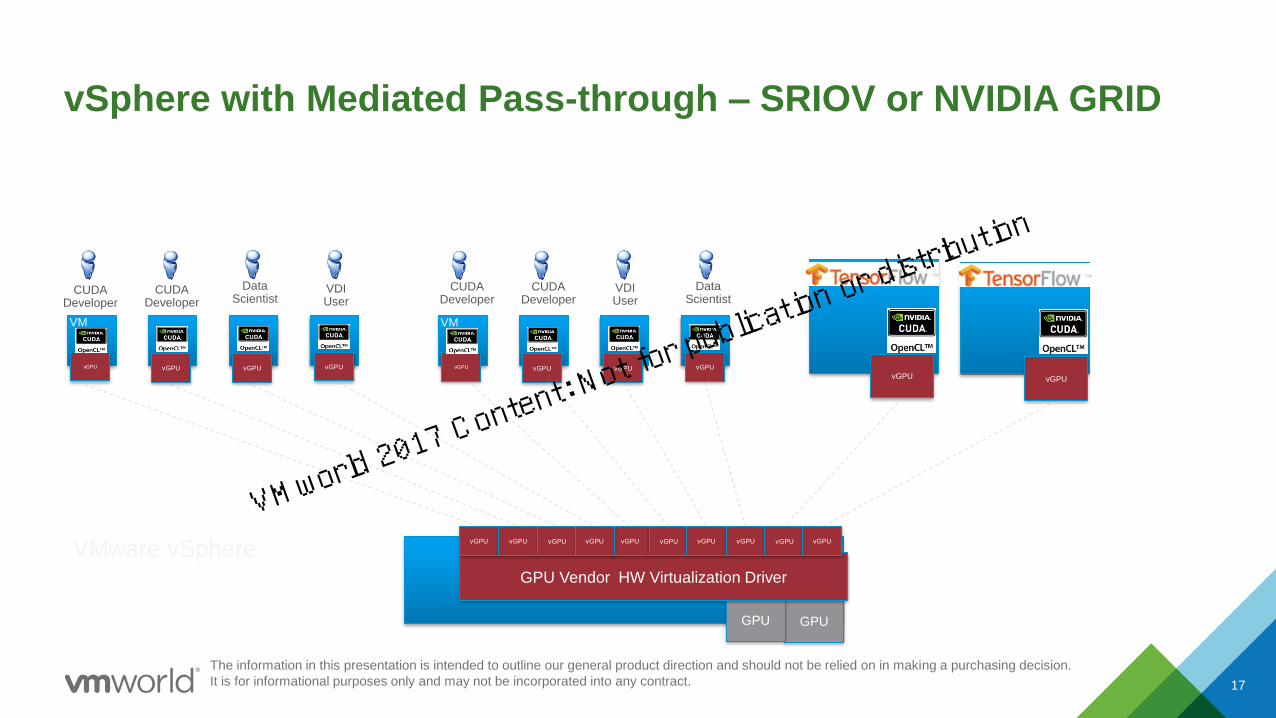
vSphere with Mediated Pass-through – SRIOV or NVIDIA GRID
GPUGPU
VMware vSphere
vGPUvGPUvGPUvGPU
VM
CUDA Developer
CUDA Developer
Data Scientist
vGPUvGPUvGPUvGPU
VM
CUDA Developer
CUDA Developer
Data Scientist
vGPUvGPU
The information in this presentation is intended to outline our general product direction and should not be relied on in making a purchasing decision.
It is for informational purposes only and may not be incorporated into any contract.
GPU Vendor HW Virtualization Driver
vGPU vGPU vGPU vGPU vGPU vGPUvGPU vGPU vGPU vGPU
VDI User
VDI User
VMworld 2017 Content: Not fo
r publication or distri
bution
18
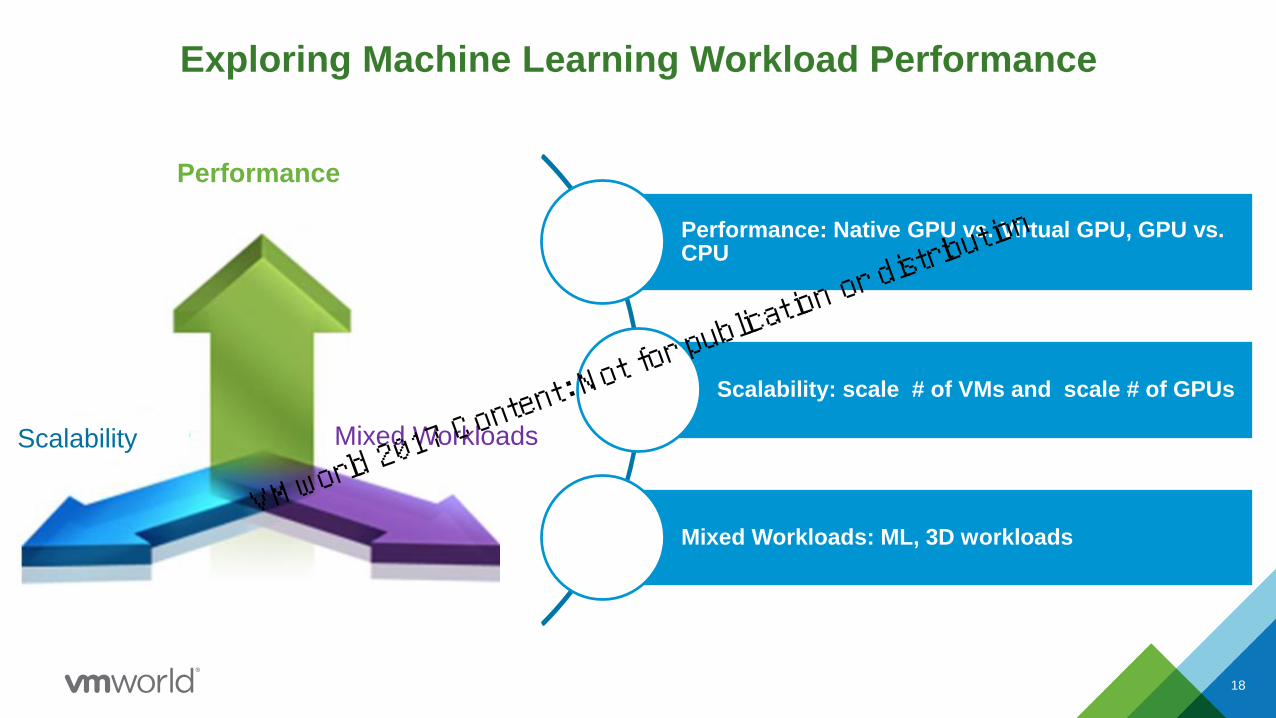
Exploring Machine Learning Workload Performance
Performance: Native GPU vs. Virtual GPU, GPU vs. CPU
Scalability: scale # of VMs and scale # of GPUs
Mixed Workloads: ML, 3D workloads
Performance
Scalability Mixed Workloads
VMworld 2017 Content: Not fo
r publication or distri
bution

19
Workloads, ML FrameworkPerformance
Scalability Mixed WorkloadsVMworld 2017 Content: Not fo
r publication or distri
bution

ML Framework, Workloads and Neural Networks
• ML Framework: Google’s TensorFlow
• Nvidia CUDA 7.5 , Nvidia cuDNN 5.1
• 3 Different Workloads :
– Language Modeling on Penn Tree Bank
– Handwriting Recognition with MNIST
– Image Classifier with CIFAR-10
• 2 Different Neural Network Architectures:
– Convolutional Neural Network
– Recurrent Neural Network
20
VMworld 2017 Content: Not fo
r publication or distri
bution

21
Performance:
Native GPU vs Virtual GPUPerformance
Scalability Mixed WorkloadsVMworld 2017 Content: Not fo
r publication or distri
bution
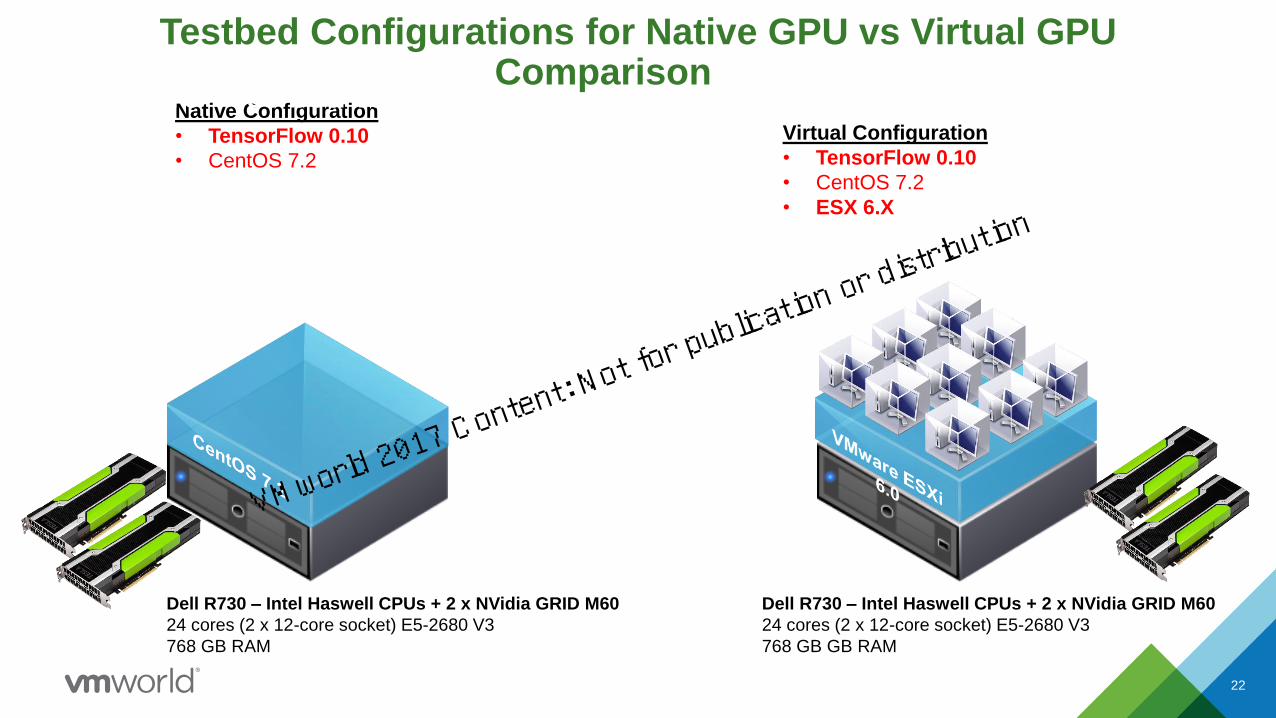
Native Configuration
• TensorFlow 0.10
• CentOS 7.2
Virtual Configuration
• TensorFlow 0.10
• CentOS 7.2
• ESX 6.X
Dell R730 – Intel Haswell CPUs + 2 x NVidia GRID M60
24 cores (2 x 12-core socket) E5-2680 V3
768 GB GB RAM
VMware Test-bed for NVIDIA GRID on Horizon View
Testbed Configurations for Native GPU vs Virtual GPU Comparison
Dell R730 – Intel Haswell CPUs + 2 x NVidia GRID M60
24 cores (2 x 12-core socket) E5-2680 V3
768 GB RAM
22
VMworld 2017 Content: Not fo
r publication or distri
bution

Workload for Native GPU vs Virtualized GPU
• Workload
– Complex Language Modelling
• Given history of words, predicts next word
• Neural Network Type: Recurrent Neural Network
– Large Model
• 1500 LSTM units /layer
– Penn Tree Bank (PTB) Database:
• 929K training words
• 73K validation words
• 82K test words
• 10K vocabulary
23
VMworld 2017 Content: Not fo
r publication or distri
bution

24
Performance: Training Times on native GPU vs virtualized GPU
4% of overhead for both GRID vGPU & DirectPath I/O compared to native GPU
11.04 1.04
0.00
0.20
0.40
0.60
0.80
1.00
1.20
Native GRID vGPU DirectPathIO
No
rma
lize
d T
rain
ing T
imes
Lo
wer
is
bet
ter
Language Modelling with RNN on PTB
VMworld 2017 Content: Not fo
r publication or distri
bution

25
Performance:
GPUs vs CPUs
VMworld 2017 Content: Not fo
r publication or distri
bution

Performance: GPU vs. CPU on a virtualized server
Two VM Configurations:
– 1 VM with 1 vGPU (M60-8q) vs 1 VM without a GPU
– Each VM has 12 vCPUs, 60GB memory, 96GB of SSD storage, CentOS 7.2
• Workload : Handwriting Recognition
Dataset: MNIST database of handwritten digits
Training set: 60,000 examples
Test set: 10,000 examples
Neural Net: CNN
Workload: Language Modelling on PTB dataset using RNN
26
VMworld 2017 Content: Not fo
r publication or distri
bution
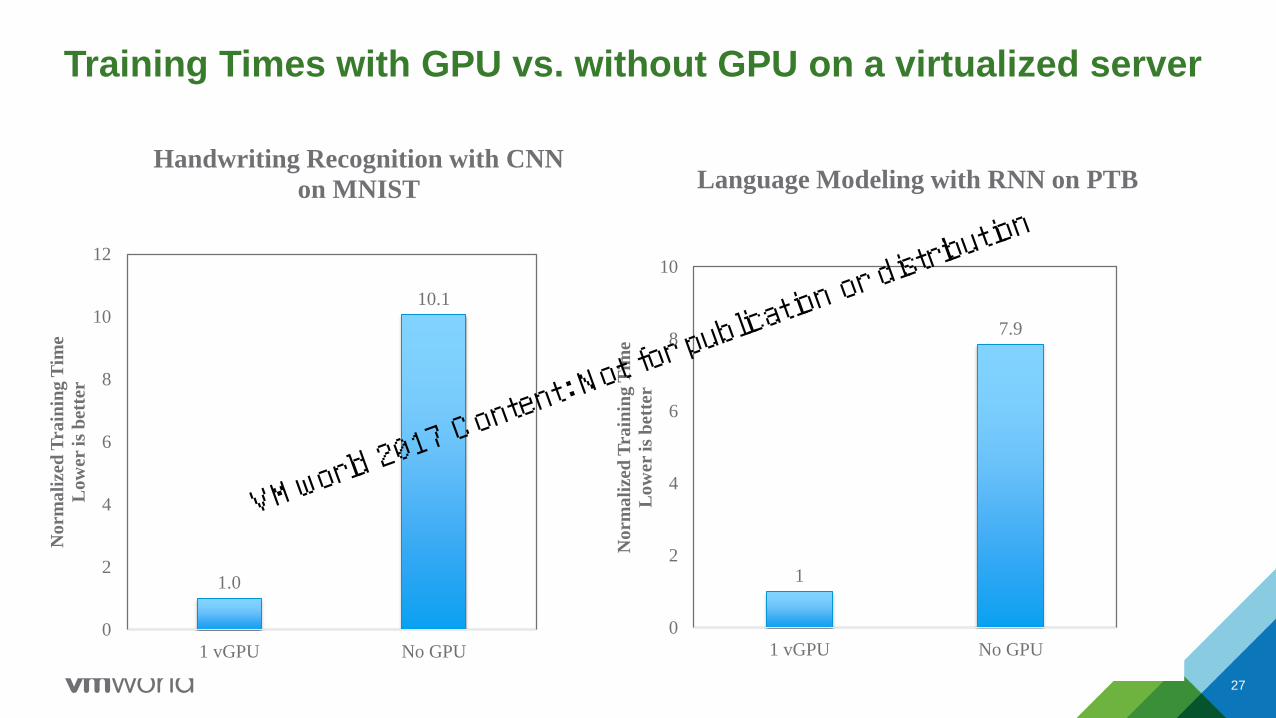
27
Training Times with GPU vs. without GPU on a virtualized server
1.0
10.1
0
2
4
6
8
10
12
1 vGPU No GPU
No
rma
lize
d T
rain
ing
Tim
e
Lo
wer
is
bet
ter
Handwriting Recognition with CNN
on MNIST
1
7.9
0
2
4
6
8
10
1 vGPU No GPU
No
rma
lize
d T
rain
ing
Tim
e
Lo
wer
is
bet
ter
Language Modeling with RNN on PTB
VMworld 2017 Content: Not fo
r publication or distri
bution

28
Performance:
DirectPath IO vs GRID vGPU Performance
Scalability Mixed WorkloadsVMworld 2017 Content: Not fo
r publication or distri
bution
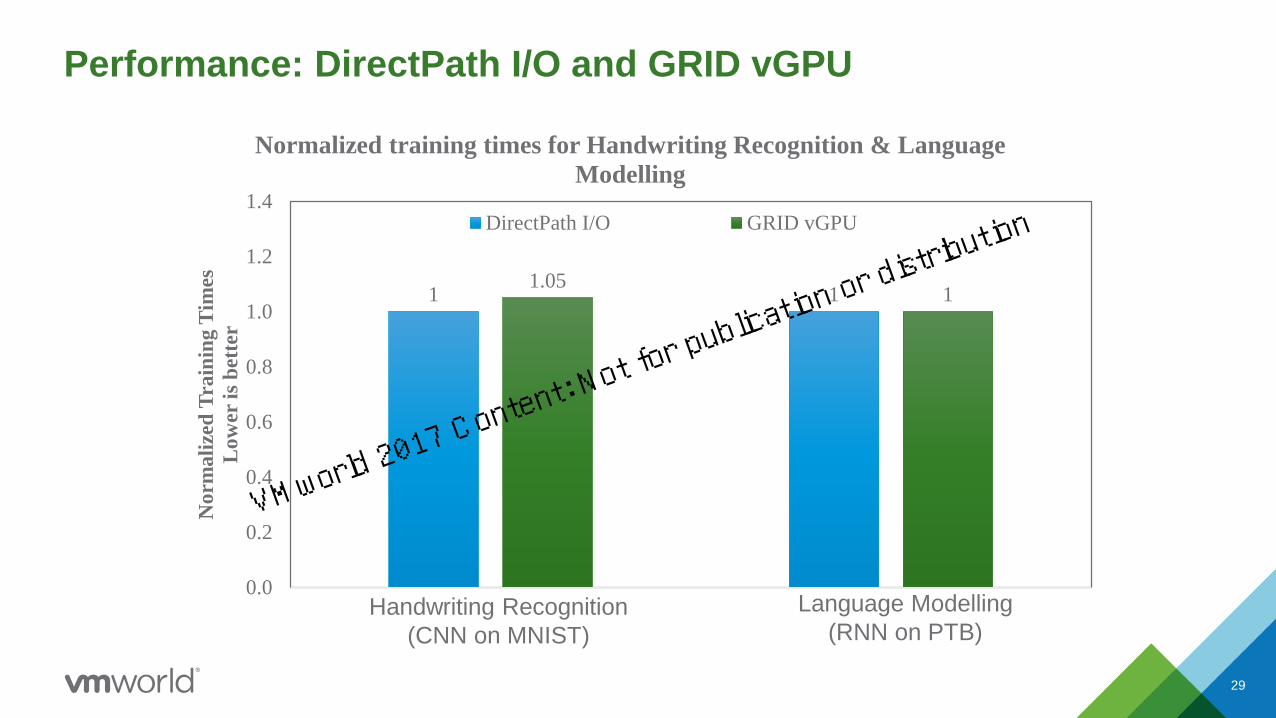
29
Performance: DirectPath I/O and GRID vGPU
1 11.05
1
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
CNN with MNIST RNN with PTB
No
rma
lize
d T
rain
ing
Tim
es
Lo
wer
is
bet
ter
Normalized training times for Handwriting Recognition & Language
Modelling
DirectPath I/O GRID vGPU
Language Modelling
(RNN on PTB)Handwriting Recognition
(CNN on MNIST)
VMworld 2017 Content: Not fo
r publication or distri
bution

30
Scalability- VMs Performance
Scalability Mixed WorkloadsVMworld 2017 Content: Not fo
r publication or distri
bution
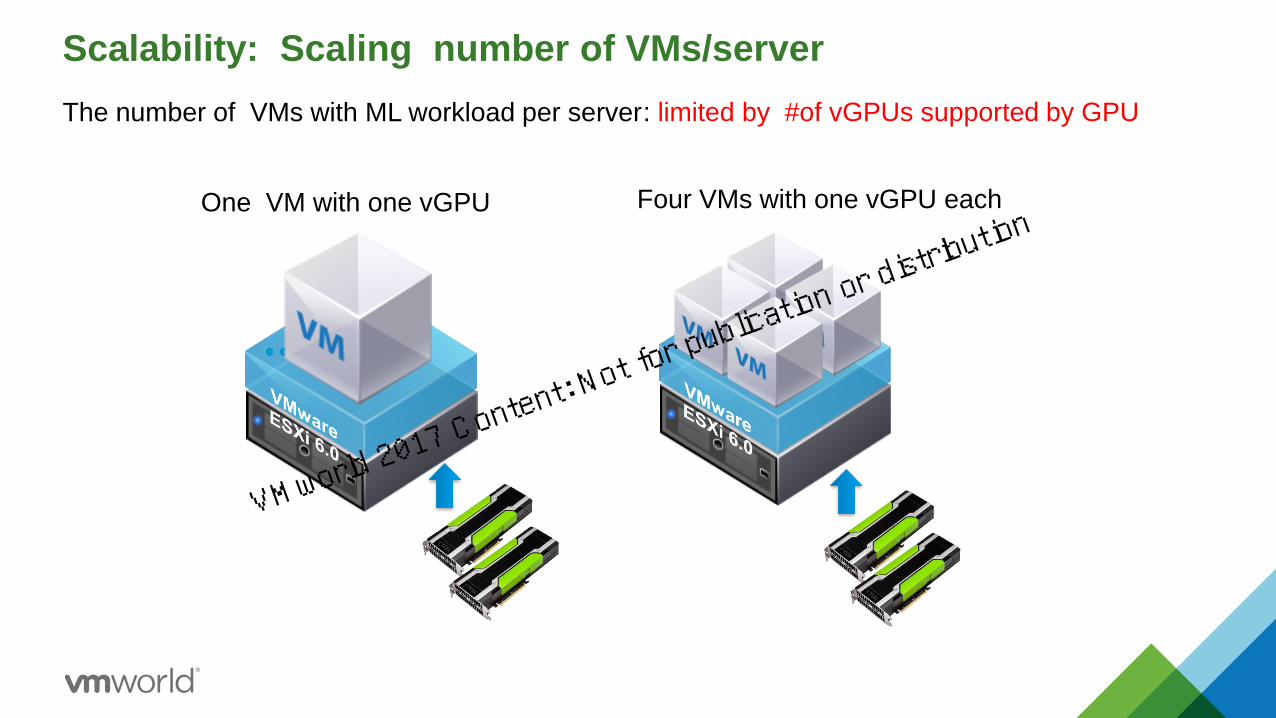
Scalability: Scaling number of VMs/server
The number of VMs with ML workload per server
Four VMs with one vGPU each One VM with one vGPU
: limited by #of vGPUs supported by GPU
VMworld 2017 Content: Not fo
r publication or distri
bution

Scalability: Image Classifier(CIFAR-10) Workload
• Workload:
• Image Classifier(CIFAR-10): 10 classes
• 60K images
– 50K training and 10K Test images
• Convolutional Neural Network
– ~ One Million learning parameters
– ~19 million multiply-add to compute inference on a
single image
32
VMworld 2017 Content: Not fo
r publication or distri
bution
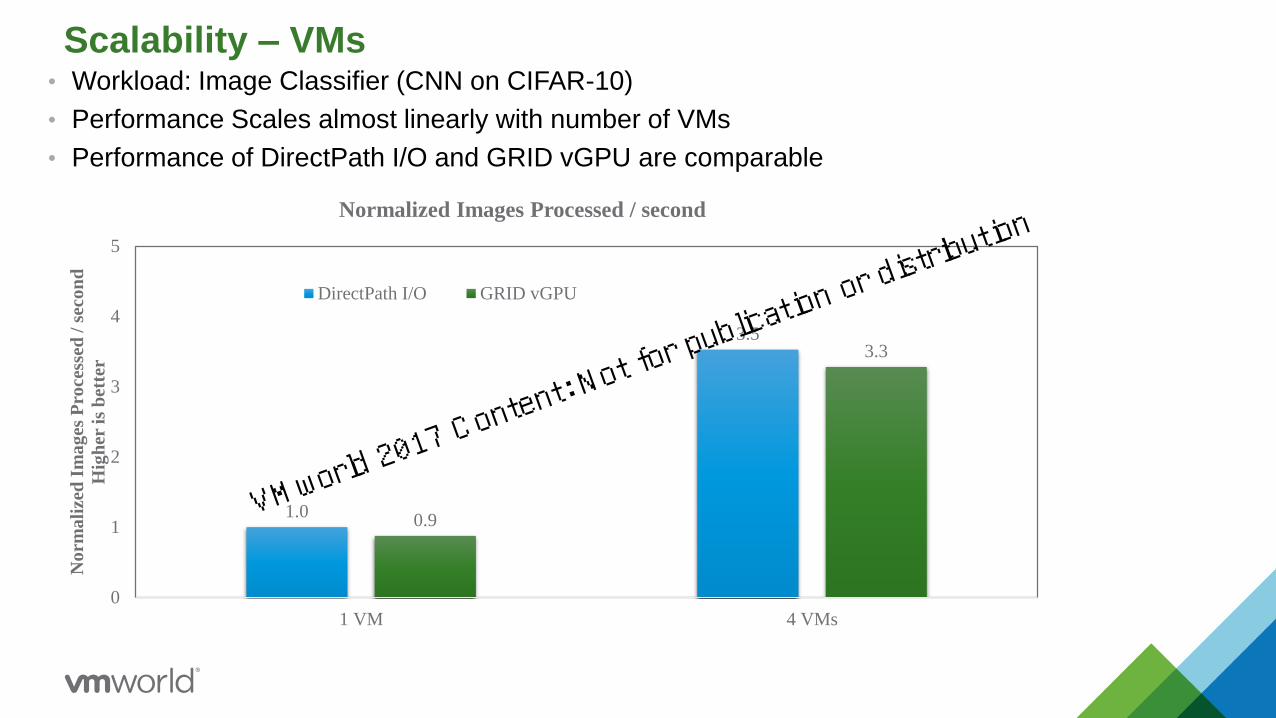
Scalability – VMs
1.0
3.5
0.9
3.3
0
1
2
3
4
5
1 VM 4 VMs
No
rma
lize
d I
ma
ges
Pro
cess
ed /
sec
on
d
Hig
her
is
bet
ter
Normalized Images Processed / second
DirectPath I/O GRID vGPU
• Workload: Image Classifier (CNN on CIFAR-10)
• Performance Scales almost linearly with number of VMs
• Performance of DirectPath I/O and GRID vGPU are comparable
VMworld 2017 Content: Not fo
r publication or distri
bution

34
Scalability - GPUsPerformance
Scalability Mixed WorkloadsVMworld 2017 Content: Not fo
r publication or distri
bution
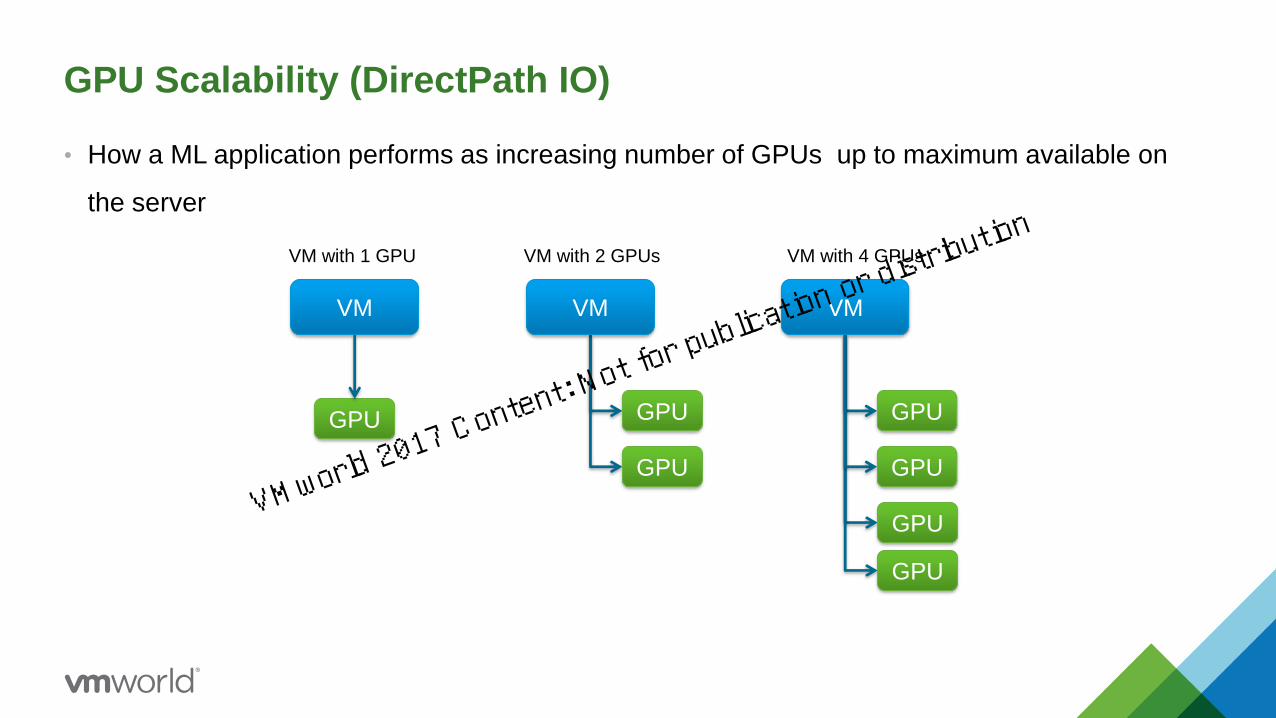
GPU Scalability (DirectPath IO)
• How a ML application performs as increasing number of GPUs up to maximum available on
the server
VM
GPU
VM with 1 GPU
35
VM
GPU
GPU
VM with 2 GPUs
VM
GPU
GPU
GPU
GPU
VM with 4 GPUs
VMworld 2017 Content: Not fo
r publication or distri
bution
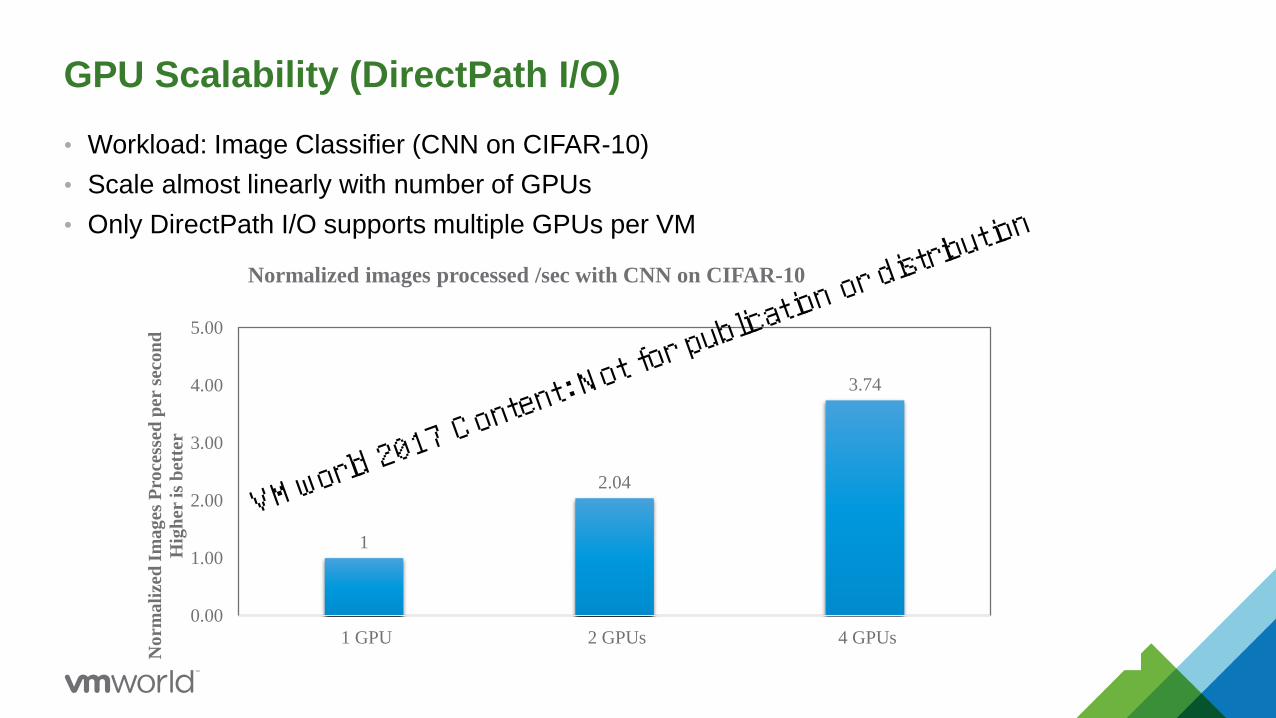
GPU Scalability (DirectPath I/O)
• Workload: Image Classifier (CNN on CIFAR-10)
• Scale almost linearly with number of GPUs
• Only DirectPath I/O supports multiple GPUs per VM
1
2.04
3.74
0.00
1.00
2.00
3.00
4.00
5.00
1 GPU 2 GPUs 4 GPUs
No
rma
lize
d I
ma
ges
Pro
cess
ed p
er s
eco
nd
Hig
her
is
bet
ter
Normalized images processed /sec with CNN on CIFAR-10
VMworld 2017 Content: Not fo
r publication or distri
bution

37
Resource Utilization
VMworld 2017 Content: Not fo
r publication or distri
bution

CPU Utilization for Machine Learning Workloads with GPUs
38
8%
43%
0%
10%
20%
30%
40%
50%
1 vGPU No GPUC
PU
Uti
liza
tion
(%
)
Lo
wer
is
bet
ter
Language Modelling with RNN on
PTB
3%
78%
0%
20%
40%
60%
80%
100%
1 vGPU No GPU
CP
U U
tili
zati
on
(%
)
Lo
wer
is
bet
ter
Handwriting Recognition with CNN
on MNIST
Off-loading Compute to GPU: CPU Resources become available
VMworld 2017 Content: Not fo
r publication or distri
bution

Benefits of Off-loading Compute to GPUs
• More CPU resources are available
– Mix GPU and non-gpu workloads on the same server
– Have more users / VMs per server
VMworld 2017 Content: Not fo
r publication or distri
bution

40
Mixed Workloads (Graphics+ML)Performance
Scalability Mixed WorkloadsVMworld 2017 Content: Not fo
r publication or distri
bution
41
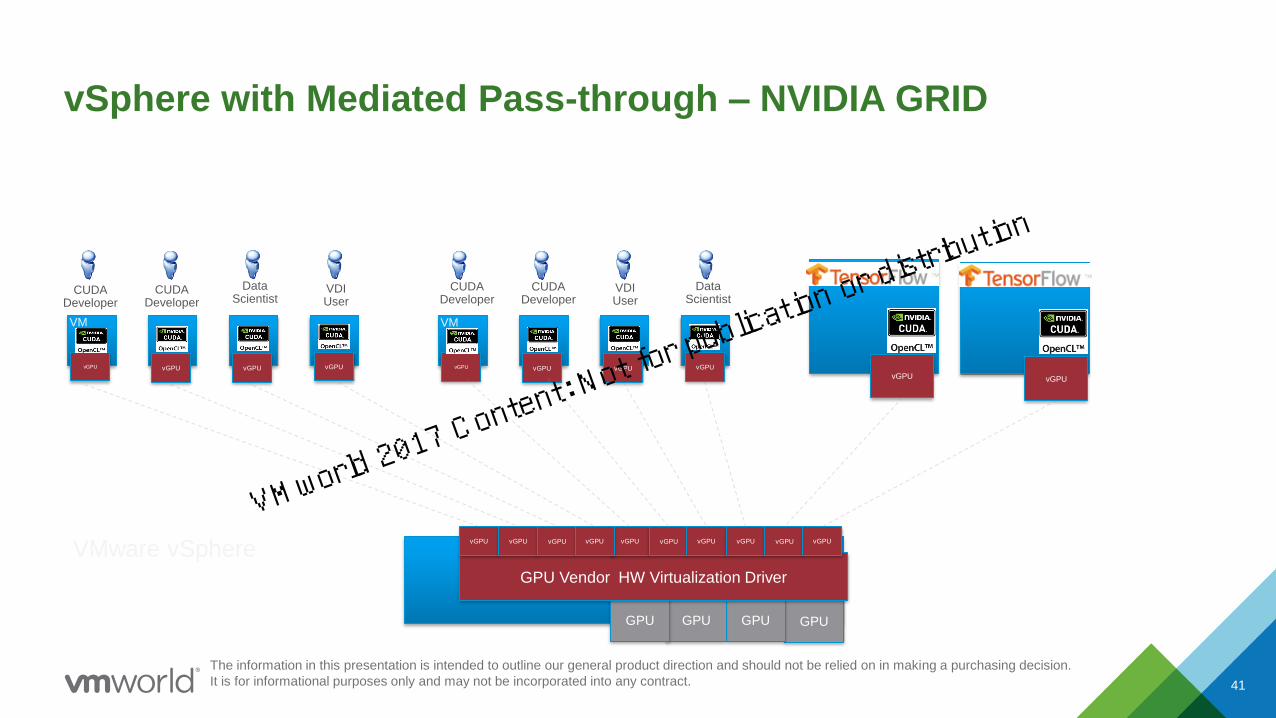
vSphere with Mediated Pass-through – NVIDIA GRID
GPUGPUGPUGPU
VMware vSphere
vGPUvGPUvGPUvGPU
VM
CUDA Developer
CUDA Developer
Data Scientist
vGPUvGPUvGPUvGPU
VM
CUDA Developer
CUDA Developer
Data Scientist
vGPUvGPU
The information in this presentation is intended to outline our general product direction and should not be relied on in making a purchasing decision.
It is for informational purposes only and may not be incorporated into any contract.
GPU Vendor HW Virtualization Driver
vGPU vGPU vGPU vGPU vGPU vGPUvGPU vGPU vGPU vGPU
VDI User
VDI User
VMworld 2017 Content: Not fo
r publication or distri
bution
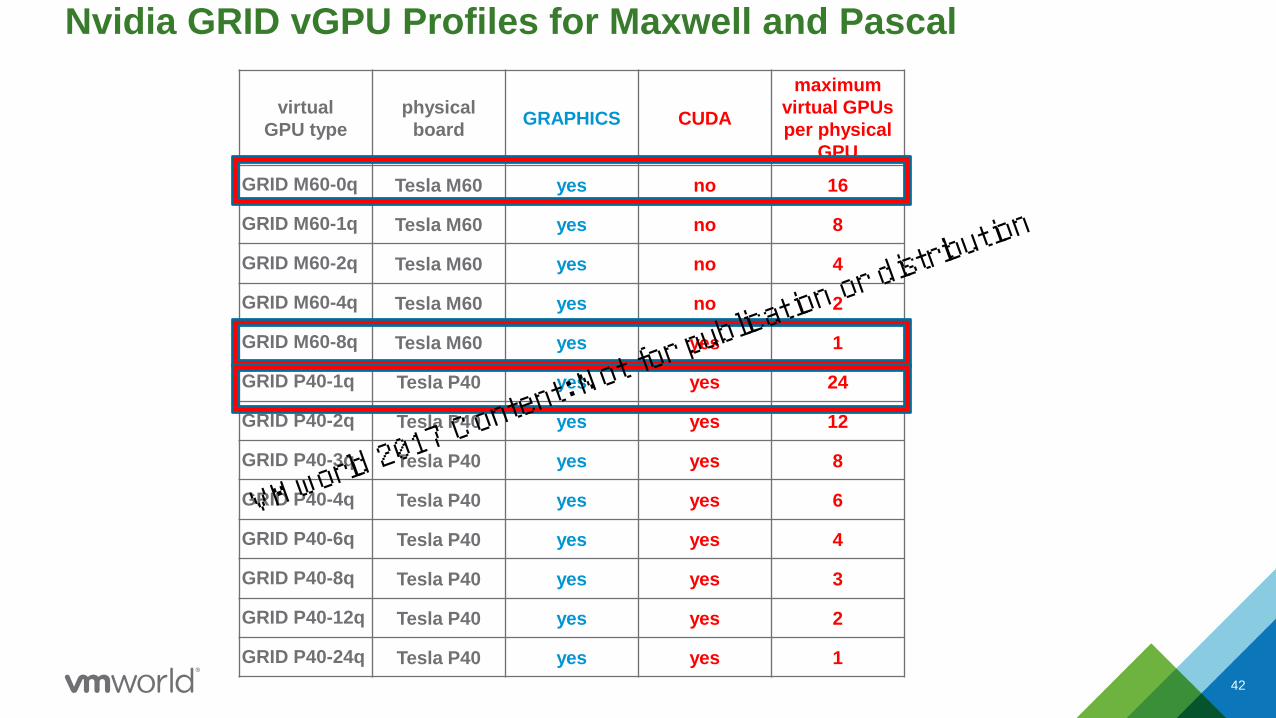
Nvidia GRID vGPU Profiles for Maxwell and Pascal
42
virtual
GPU type
physical
boardGRAPHICS CUDA
maximum
virtual GPUs
per physical
GPU
GRID M60-0q Tesla M60 yes no 16
GRID M60-1q Tesla M60 yes no 8
GRID M60-2q Tesla M60 yes no 4
GRID M60-4q Tesla M60 yes no 2
GRID M60-8q Tesla M60 yes yes 1
GRID P40-1q Tesla P40 yes yes 24
GRID P40-2q Tesla P40 yes yes 12
GRID P40-3q Tesla P40 yes yes 8
GRID P40-4q Tesla P40 yes yes 6
GRID P40-6q Tesla P40 yes yes 4
GRID P40-8q Tesla P40 yes yes 3
GRID P40-12q Tesla P40 yes yes 2
GRID P40-24q Tesla P40 yes yes 1
VMworld 2017 Content: Not fo
r publication or distri
bution
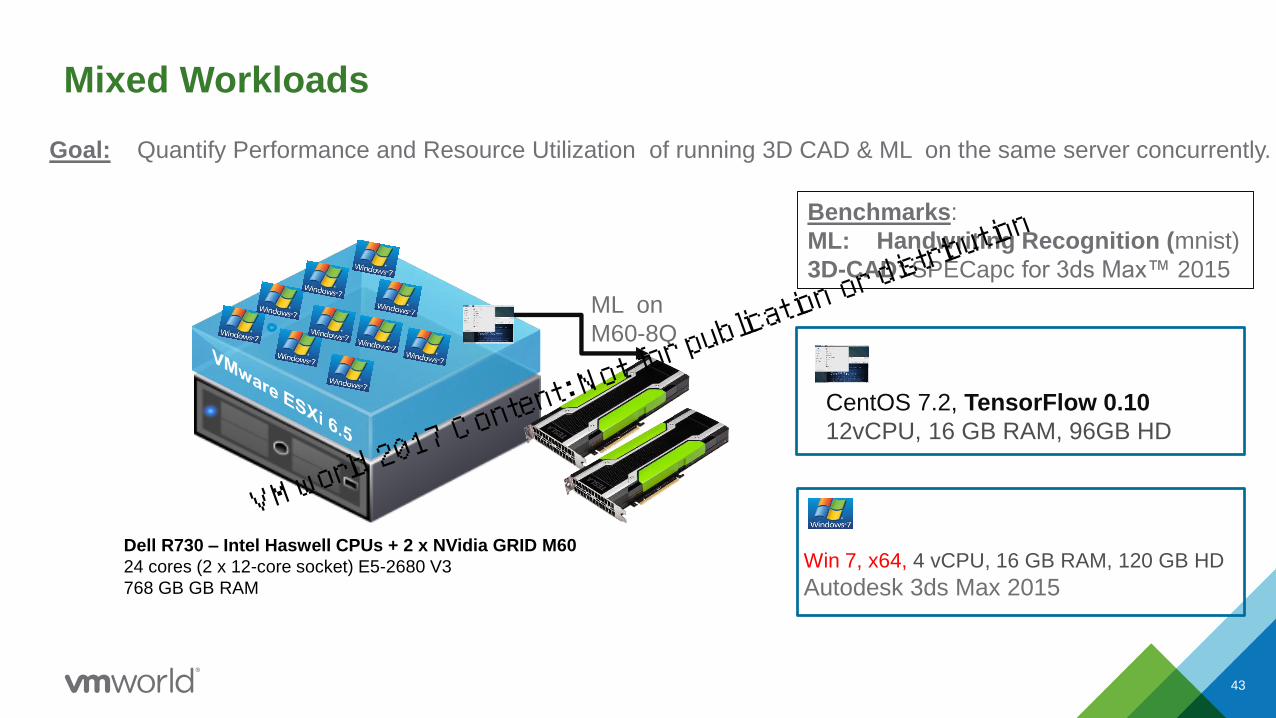
Mixed Workloads
Goal: Quantify Performance and Resource Utilization of running 3D CAD & ML on the same server concurrently.
Dell R730 – Intel Haswell CPUs + 2 x NVidia GRID M60
24 cores (2 x 12-core socket) E5-2680 V3
768 GB GB RAM
ML on
M60-8Q
Benchmarks:
ML: Handwriting Recognition (mnist)
3D-CAD: SPECapc for 3ds Max™ 2015
Win 7, x64, 4 vCPU, 16 GB RAM, 120 GB HD
Autodesk 3ds Max 2015
CentOS 7.2, TensorFlow 0.10
12vCPU, 16 GB RAM, 96GB HD
43
VMworld 2017 Content: Not fo
r publication or distri
bution

Mixed Workloads – Experiment Design
1) First set of runs : Run 3D-CAD Workload ONLY (SPECapc)
2) Second set of runs: Run ML workload ONLY (MNIST)
44
Perf. Metrics:
3D-CAD (SPECapc): Geo. Mean of run-times
ML (Handwriting Recognition): Training Times
3) Third set of runs: Run 3D-CAD and ML Concurrently
Note:
3D-CAD (SPECapc) runs on all vGPU profiles
ML runs only on M60-8Q profile
VMworld 2017 Content: Not fo
r publication or distri
bution
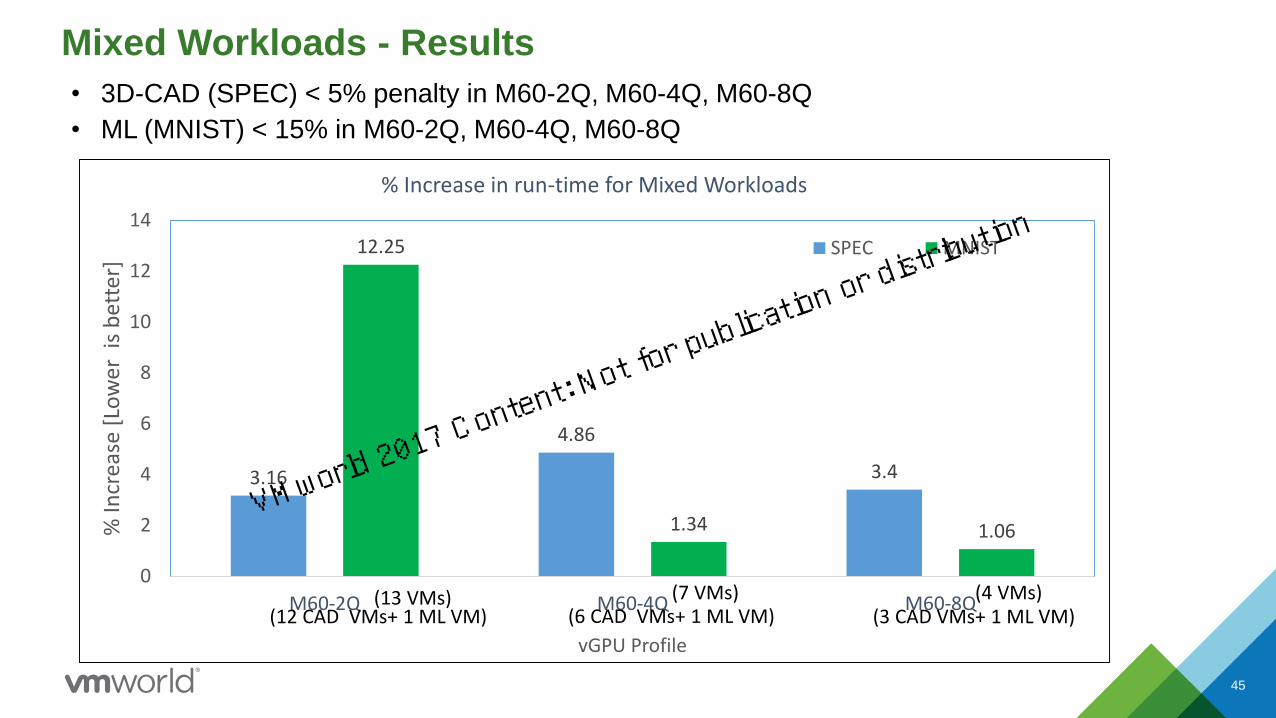
Mixed Workloads - Results
• 3D-CAD (SPEC) < 5% penalty in M60-2Q, M60-4Q, M60-8Q
• ML (MNIST) < 15% in M60-2Q, M60-4Q, M60-8Q
45
3.16
4.86
3.4
12.25
1.34 1.06
0
2
4
6
8
10
12
14
M60-2Q M60-4Q M60-8Q
% In
crea
se [
Low
er i
s b
ette
r]
vGPU Profile
% Increase in run-time for Mixed Workloads
SPEC MNIST
(12 CAD VMs+ 1 ML VM) (6 CAD VMs+ 1 ML VM) (3 CAD VMs+ 1 ML VM)(4 VMs)(7 VMs)(13 VMs)
VMworld 2017 Content: Not fo
r publication or distri
bution
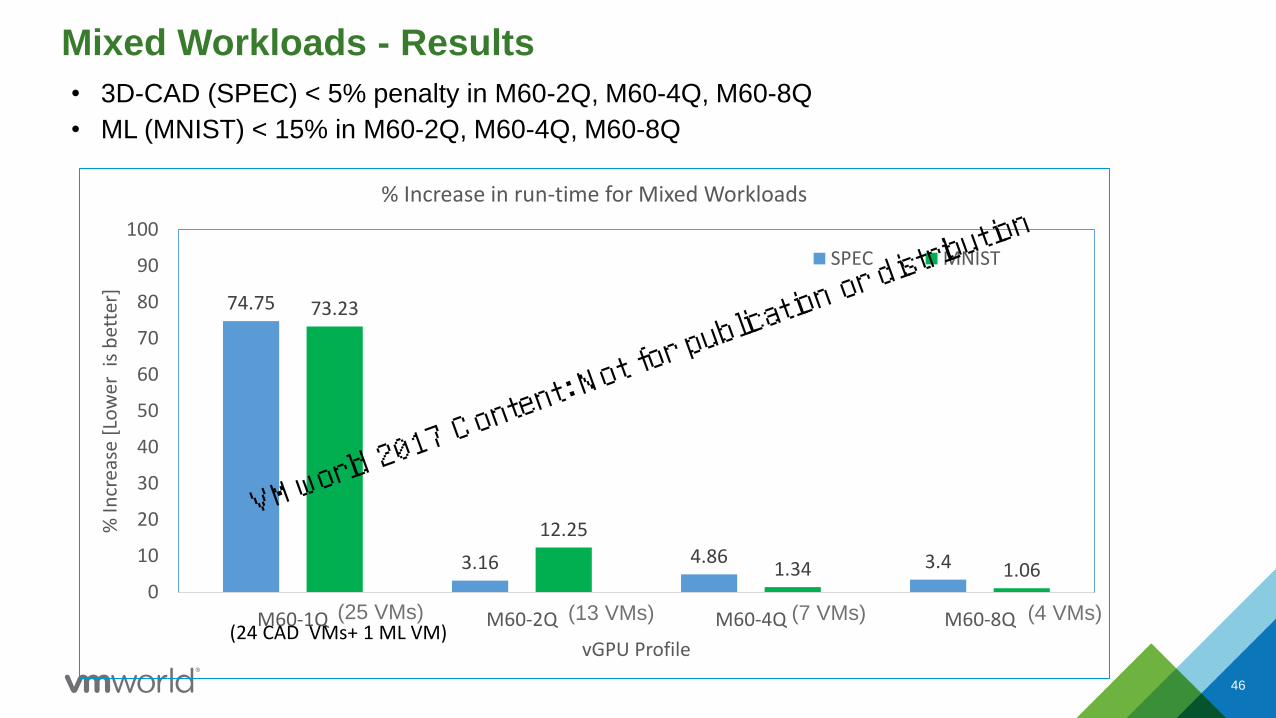
Mixed Workloads - Results
• 3D-CAD (SPEC) < 5% penalty in M60-2Q, M60-4Q, M60-8Q
• ML (MNIST) < 15% in M60-2Q, M60-4Q, M60-8Q
46
74.75
3.16 4.86 3.4
73.23
12.25
1.34 1.060
10
20
30
40
50
60
70
80
90
100
M60-1Q M60-2Q M60-4Q M60-8Q
% In
crea
se [
Low
er i
s b
ette
r]
vGPU Profile
% Increase in run-time for Mixed Workloads
SPEC MNIST
(24 CAD VMs+ 1 ML VM)(13 VMs) (7 VMs) (4 VMs)(25 VMs)
VMworld 2017 Content: Not fo
r publication or distri
bution
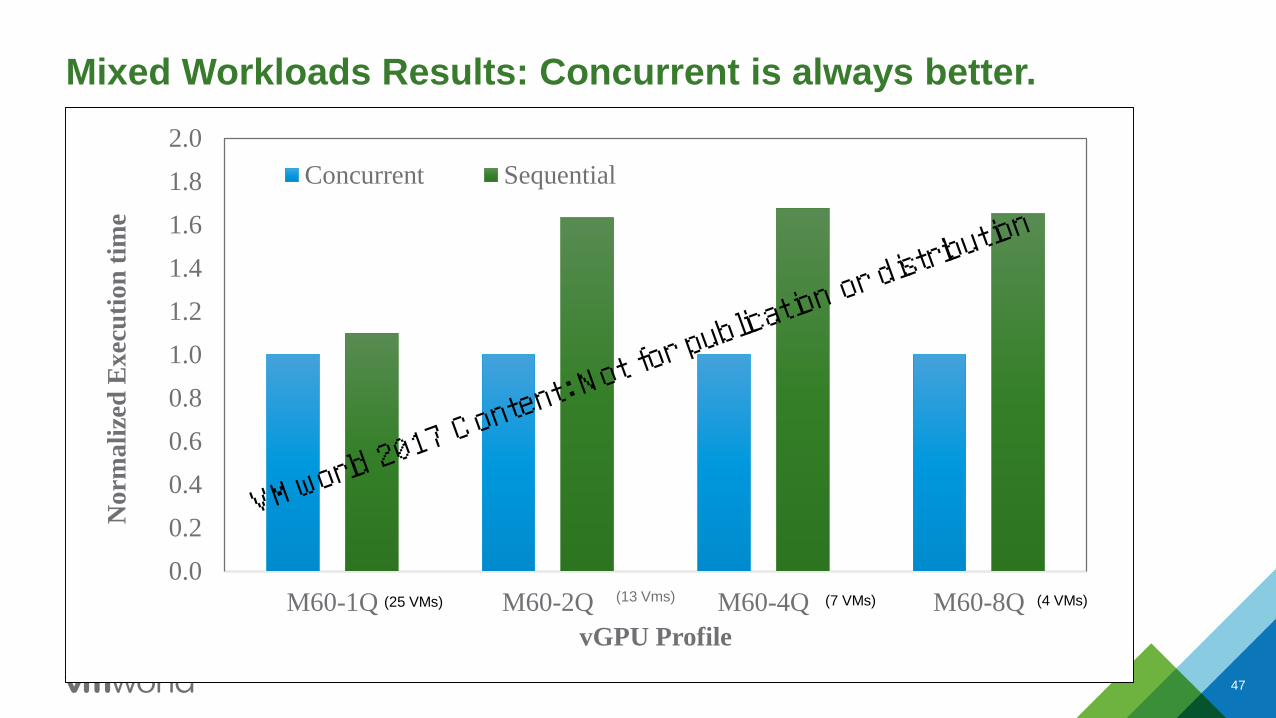
Mixed Workloads Results: Concurrent is always better.
47
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
1.8
2.0
M60-1Q M60-2Q M60-4Q M60-8Q
No
rma
lize
d E
xec
uti
on
tim
e
vGPU Profile
Concurrent Sequential
(25 VMs) (7 VMs) (4 VMs)(13 Vms)
VMworld 2017 Content: Not fo
r publication or distri
bution

Advantages of Running Mixed Workloads
• Concurrent Running times are always shorter than sequential times.
• Better Resource Utilization
• Higher Consolidation Ratios
VMworld 2017 Content: Not fo
r publication or distri
bution

49
Key Performance Takeaways
Virtualized GPUs deliver near bare metal Performance for ML workloads
GPUs can be used in two modes on vSphere: Direct Path IO and NVidia GRID vGPU
For CUDA/ML workloads, GRID VGPU requires 1 vGPU per VM
For Multi-GPU ML workloads, use Direct Path IO mode
For more consolidation of GPU-based workloads, use GRID vGPU
GRID vGPU combines performance of GPUs and datacenter management benefits of VMware vSphere
VMworld 2017 Content: Not fo
r publication or distri
bution
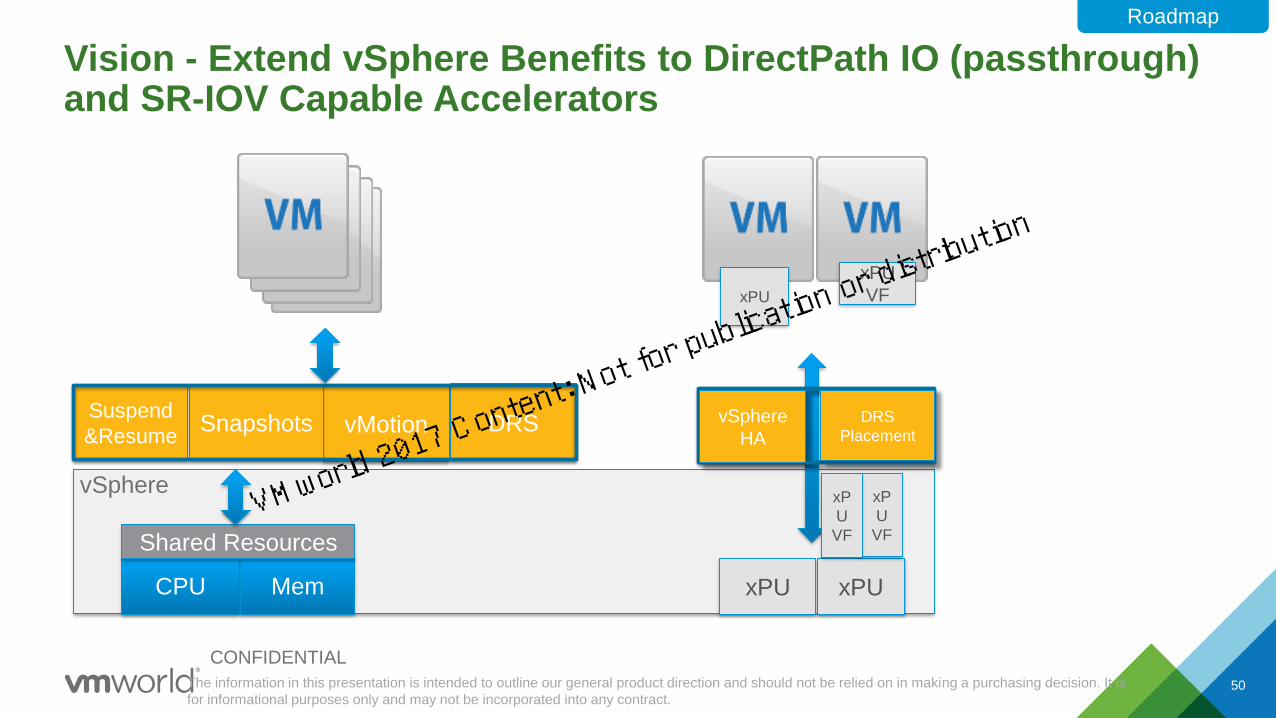
Vision - Extend vSphere Benefits to DirectPath IO (passthrough) and SR-IOV Capable Accelerators
CONFIDENTIAL
50
DRSvMotionSnapshotsSuspend
&Resume
CPU Mem xPU
Shared Resources
xPU
xPU
vSphere
DRS
Placement
vSphere
HA
Roadmap
The information in this presentation is intended to outline our general product direction and should not be relied on in making a purchasing decision. It is
for informational purposes only and may not be incorporated into any contract.
xP
U
VF
xP
U
VF
xPU
VF
VMworld 2017 Content: Not fo
r publication or distri
bution
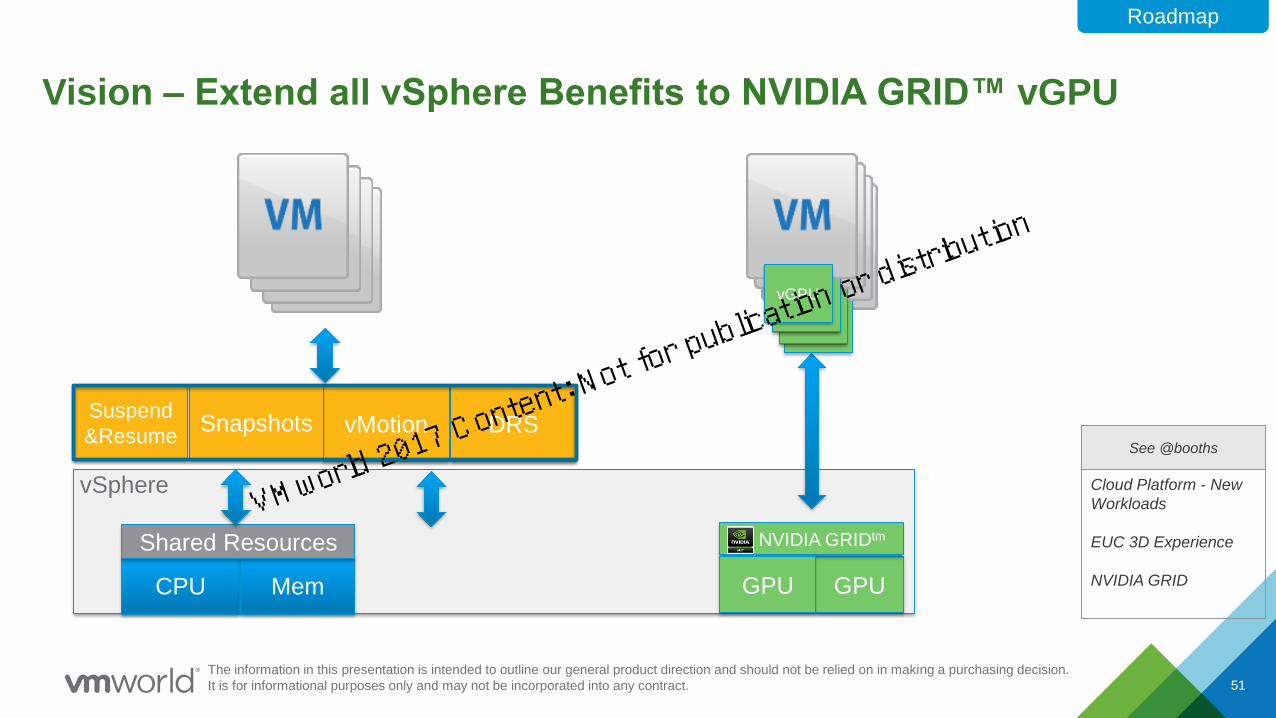
Vision – Extend all vSphere Benefits to NVIDIA GRID™ vGPU
51
DRSvMotionSnapshotsSuspend
&Resume
CPU Mem
Shared Resources
vGPUvGPU
vGPUvGPU
vSphere
Roadmap
GPU
NVIDIA GRIDtm
GPU
See @booths
Cloud Platform - New
Workloads
EUC 3D Experience
NVIDIA GRID
The information in this presentation is intended to outline our general product direction and should not be relied on in making a purchasing decision.
It is for informational purposes only and may not be incorporated into any contract.
VMworld 2017 Content: Not fo
r publication or distri
bution
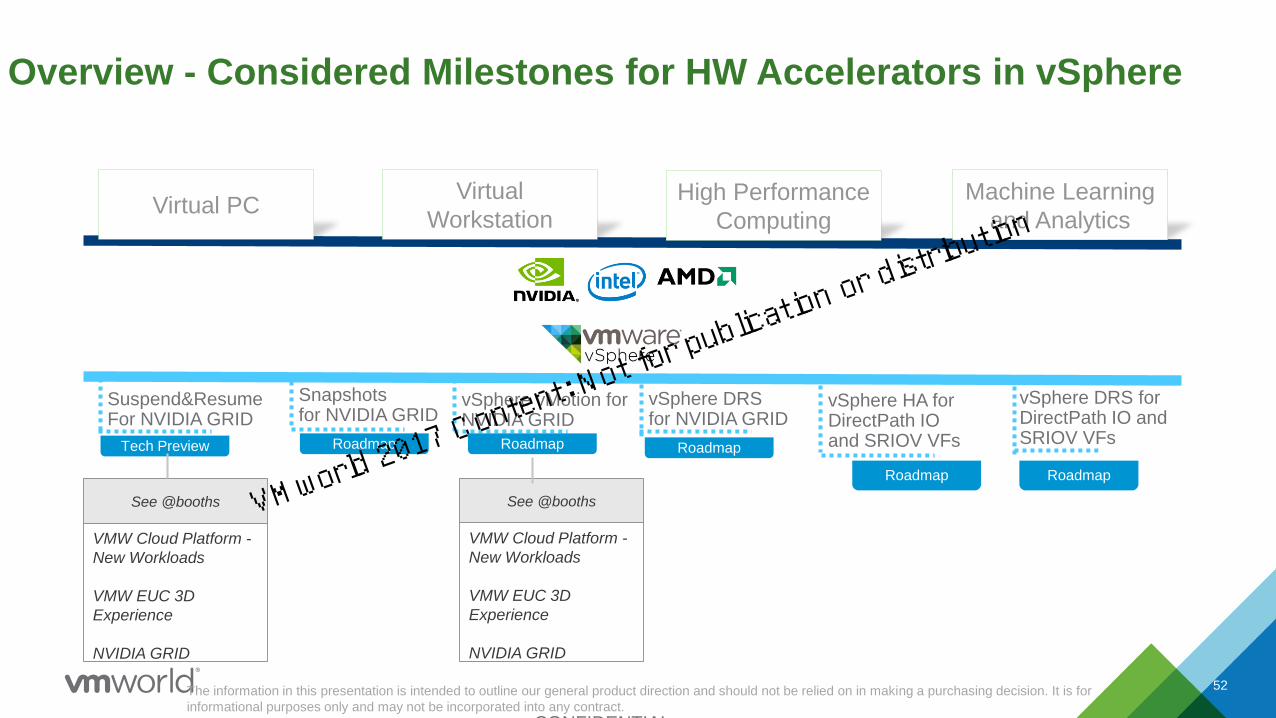
Overview - Considered Milestones for HW Accelerators in vSphere
CONFIDENTIAL
52
Suspend&ResumeFor NVIDIA GRID
vSphere vMotion for NVIDIA GRID
Snapshots for NVIDIA GRID
RoadmapTech Preview
See @booths
VMW Cloud Platform -
New Workloads
VMW EUC 3D
Experience
NVIDIA GRID
vSphere DRS for NVIDIA GRID
Roadmap
vSphere DRS for DirectPath IO and SRIOV VFs
Roadmap
vSphere HA for DirectPath IOand SRIOV VFs
Roadmap
The information in this presentation is intended to outline our general product direction and should not be relied on in making a purchasing decision. It is for
informational purposes only and may not be incorporated into any contract.
Roadmap
Virtual PC
See @booths
VMW Cloud Platform -
New Workloads
VMW EUC 3D
Experience
NVIDIA GRID
Virtual
WorkstationHigh Performance
Computing
Machine Learning
and Analytics
VMworld 2017 Content: Not fo
r publication or distri
bution

Introducing vSphere Scale-Out for Big Data and HPC Workloads
53
• Hypervisor, vMotion, vShield Endpoint, Storage vMotion, Storage APIs, Distributed Switch, I/O Controls & SR-IOV, Host Profiles / Auto Deploy and more
Features
• Sold in Packs of 8 CPU at a cost-effective price pointPackaging
• EULA enforced for use w/ Big Data/HPC/ML workloads onlyLicensing
New package that provides all the core features required for scale-out workloads at an attractive price point
VMworld 2017 Content: Not fo
r publication or distri
bution

Value of vSphere Scale-Out for Big Data and HPC
54
Flexibility & Agility
• Infrastructure on demand
• Iterate faster
• Scale out more rapidly
• Multi-tenancy enables different multiple distros on the same set of server
Operational Efficiency
• CapEx and OpExSaving
• Cluster Consolidation
• Increase Server Utilization
Reduced Complexity
• Simple operations using tools that IT is familiar with
• Live workload mobility for Master nodes
• Reference architecture and best practices
Data Governance and Control of Sensitive Data
• Host and VM security for your customer data
• Security isolation
• Hypervisor Guests have low privileges by default
Faster time to results and insights at a lower cost
VMworld 2017 Content: Not fo
r publication or distri
bution

Key Takeaways
• Gain vSphere’s operational benefits with near bare-metal performance (95%) for GPU accelerated HPC,
Big Data and Machine Learning
• VMware's vision is seamless integration of GPU’s and other HW accelerators as native resources of VM
infrastructure
• New vSphere Scale-Out SKU; new package with attractive price point for Big Data/HPC/ML dedicated
infrastructure virtualization. http://blogs.vmware.com/vsphere/2017/09/vsphere-scale-now-available.html
• Using DirectPath IO for GPU compute doesn’t require device specific certification, more here
http://tinyurl.com/VMWKB2142307 and http://tinyurl.com/VMWOCTO
VMworld 2017 Content: Not fo
r publication or distri
bution

Extreme Performance Series – Las Vegas
• SER2724BU Performance Best Practices
• SER2723BU Benchmarking 101
• SER2343BU vSphere Compute & Memory Schedulers
• SER1504BU vCenter Performance Deep Dive
• SER2734BU Byte Addressable Non-Volatile Memory in vSphere
• SER2849BU Predictive DRS – Performance & Best Practices
• SER1494BU Encrypted vMotion Architecture, Performance, & Futures
• STO1515BU vSAN Performance Troubleshooting
• VIRT1445BU Fast Virtualized Hadoop and Spark on All-Flash Disks
• VIRT1397BU Optimize & Increase Performance Using VMware NSX
• VIRT2550BU Reducing Latency in Enterprise Applications with VMware NSX
• VIRT1052BU Monster VM Database Performance
• VIRT1983BU Cycle Stealing from the VDI Estate for Financial Modeling
• VIRT1997BU Machine Learning and Deep Learning on VMware vSphere
• FUT2020BU Wringing Max Perf from vSphere for Extremely Demanding Workloads
• FUT2761BU Sharing High Performance Interconnects across Multiple VMs
CONFIDENTIAL56
VMworld 2017 Content: Not fo
r publication or distri
bution

Extreme Performance Series – Barcelona
• SER2724BE Performance Best Practices
• SER2343BE vSphere Compute & Memory Schedulers
• SER1504BE vCenter Performance Deep Dive
• SER2849BE Predictive DRS – Performance & Best Practices
• VIRT1445BE Fast Virtualized Hadoop and Spark on All-Flash Disks
• VIRT1397BE Optimize & Increase Performance Using VMware NSX
• VIRT1052BE Monster VM Database Performance
• FUT2020BE Wringing Max Perf from vSphere for Extremely Demanding Workloads
CONFIDENTIAL57
VMworld 2017 Content: Not fo
r publication or distri
bution

Extreme Performance Series - Hand on Labs
Don’t miss these popular Extreme Performance labs:
• HOL-1804-01-SDC: vSphere 6.5 Performance Diagnostics & Benchmarking
– Each module dives deep into vSphere performance best practices, diagnostics, and optimizations using various interfaces and benchmarking tools.
• HOL-1804-02-CHG: vSphere Challenge Lab
– Each module places you in a different fictional scenario to fix common vSphere operational and performance problems.
CONFIDENTIAL58
VMworld 2017 Content: Not fo
r publication or distri
bution

Performance Survey
CONFIDENTIAL59
The VMware Performance Engineeringteam is always looking for feedback about your experience with theperformance of our products, ourvarious tools, interfaces and wherewe can improve.
Scan this QR code to access ashort survey and provide us directfeedback.
Alternatively: www.vmware.com/go/perf
Thank you!
VMworld 2017 Content: Not fo
r publication or distri
bution

VMworld 2017 Content: Not fo
r publication or distri
bution

VMworld 2017 Content: Not fo
r publication or distri
bution