web archiving and access mike smorul joseph jaja adapt group university of maryland, college park
TRANSCRIPT

Web Archiving and AccessWeb Archiving and Access
Mike SmorulJoseph JaJa
ADAPT GroupUniversity of Maryland, College
Park

Web Archive Storage and Web Archive Storage and SearchSearch
• Management tools
• Storage infrastructure
• Indexing, searching, compression experiments
7/21/2010 NDIIPP Partners Meeting 2

Webarc ManagerWebarc Manager
• Develop a tool to help manage webarc collections
• Show statistics of a series of crawls
• Open API to easily query collection– List all copies of a page, etc
7/21/2010 NDIIPP Partners Meeting 3

Manager ComponentsManager Components
• WarcManager (server)– REST-based access to index– Index of DAT/ARC entries– URL Searching, ARC browsing,
• Javascript Client• Simple Web-Accessible Preservation
(SWAP)– Web-accessible distributed storage– ARC page retrieval– 1Gbps, 2200requests/s
7/21/2010 NDIIPP Partners Meeting 4

Manager DesignManager Design
7/21/2010 NDIIPP Partners Meeting 5
Javascript Client
Webarc Manager
MySQL
Storage Server
Storage Server
RESTJSON
Page Request
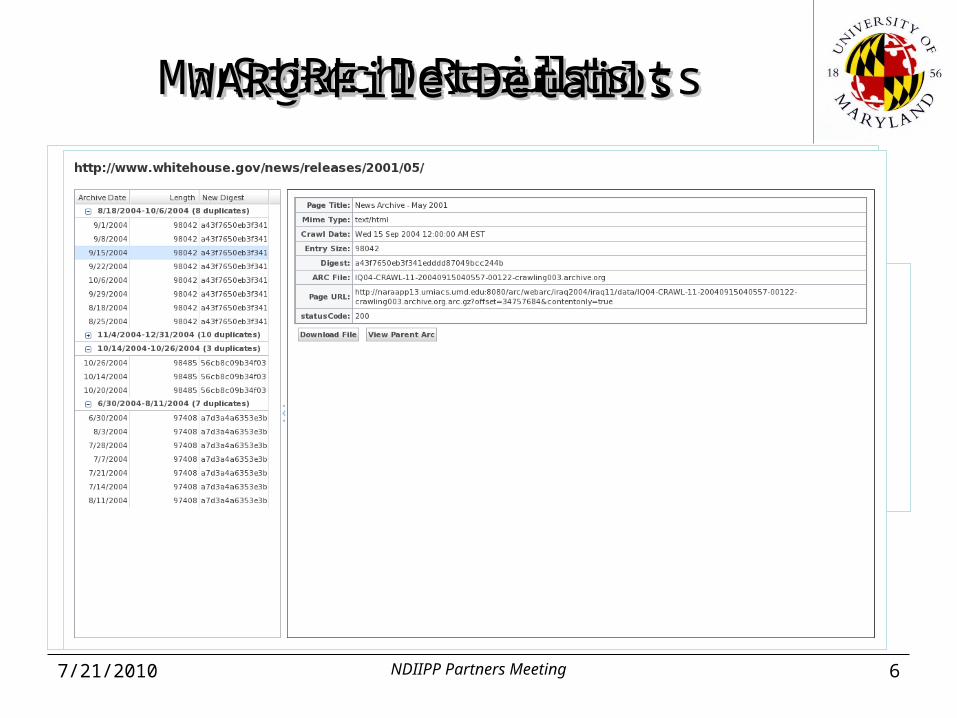
Manager ScreenshotsManager Screenshots
7/21/2010 NDIIPP Partners Meeting 6
Search ResultsSearch ResultsURL DetailsURL DetailsWARC File DetailsWARC File Details

Storage DesignStorage Design
• SWAP – Simple, Web-Accessible Preservation• Intelligent placement of files across multiple
servers and disk partitions• Simple HTTP access, PUT, GET, DELETE• Use redirects to provide a uniform namespace• Files organized into file groups
– Each group resides on multiple partitions (slices)– Hash(file_path) % slices = partition
• No centralized catalog
7/21/2010 NDIIPP Partners Meeting 7

How it worksHow it works
7/21/2010 NDIIPP Partners Meeting 8
Client
Server 1 Server 2
P1 P2 P4P3
GET ‘bag1/warc55.gz’
Calculate hash(bag1/warc55.gz) % 4 = 3
Return 302: Server 2 GET ‘bag1/warc55.gz’Return warc55.gz
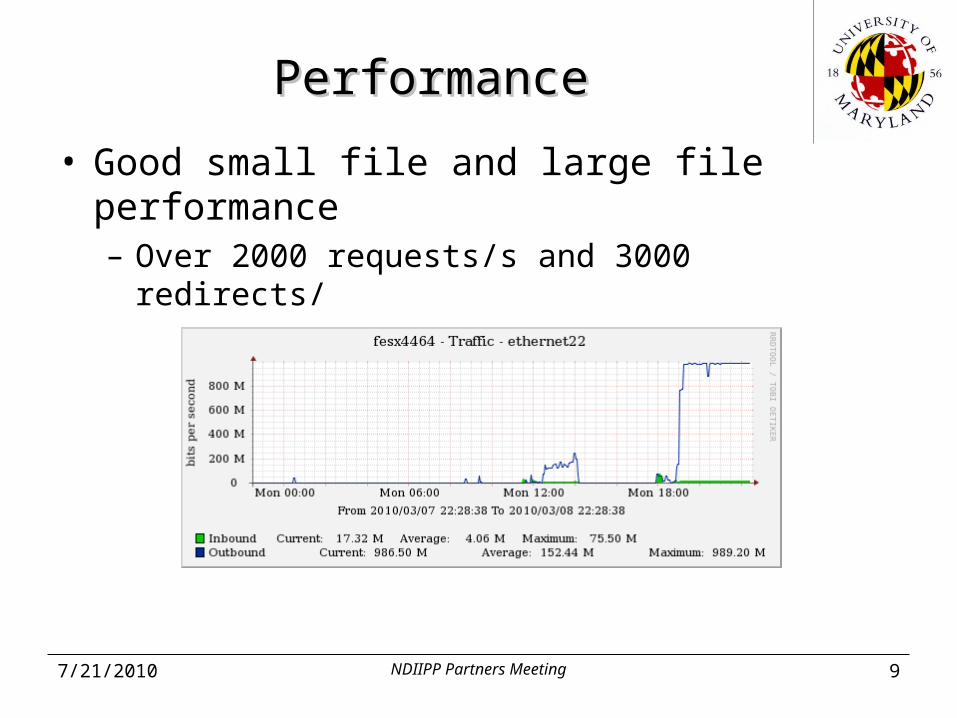
PerformancePerformance
• Good small file and large file performance– Over 2000 requests/s and 3000 redirects/
7/21/2010 NDIIPP Partners Meeting 9

Time Machine for the Web
• Fast parallel indexer to handle large scale crawled web contents, coupled with a new compression scheme.
• Fast search of contents based on unstructured queries involving temporal specifications.
• Presentation of pertinent summary information in ranked order according to the temporal context.
7/21/2010 NDIIPP Partners Meeting 10

Parallel Index ConstructionParallel Index Construction
• A parallel and hybrid strategy of multi-core CPU and multi-GPU
• Processing Speed with a single node: 80MB/s
7/21/2010 NDIIPP Partners Meeting 11
DiskDisk
ARC File
CPU ParserCPU Parser
CPU ParserCPU Parser
CPU ParserCPU Parser
CPU ParserCPU Parser
CPU ParserCPU Parser
CPU ParserCPU Parser
DiskDisk
Dictionary &Postings Lists
Parallel CPU Parser
CPU IndexerCPU Indexer
CPU IndexerCPU Indexer
GPU IndexerGPU Indexer
GPU IndexerGPU Indexer
Parallel CPU/GPU Indexer

Index CompressionIndex Compression
• A combination of – integer compression scheme and– multi-versioned document posting w/
temporal information included• Potential space savings of temporal
information for frequent terms compared to full temporal information: 50%.
• Potential space saving from integer compression: 4B vs 1B for small integers
7/21/2010 NDIIPP Partners Meeting 12

Temporally Anchored Temporally Anchored Information RetrievalInformation Retrieval
• Given a temporally anchored query, return a ranked set of pages within a temporal context.
• A new approach that:– Substantially limits the search space– Generates efficiently temporally
ranked pages
• Extensive experimental results.7/21/2010 NDIIPP Partners Meeting 13

Additional InformationAdditional Information
• http://adapt.umiacs.umd.edu– Papers, results, etc..
• E-mail: [email protected]
7/21/2010 NDIIPP Partners Meeting 14