what is hadoop
TRANSCRIPT

1
Big Data
By: Asis Mohanty CBIP, CDMP

2
The Three V’s of Big Data
Varity
Unstructured and semi-structured data is becoming as strategic as traditional structured data. (Text, Machine logs, clickstream, Social blog..etc)
Volume
Data coming in from new source as well as increased regulation in multiple areas means storing more data for longer period of time.
Velocity
Machine data as well as data coming for new source is being ingested at speeds not even imagined a few years ago.
3
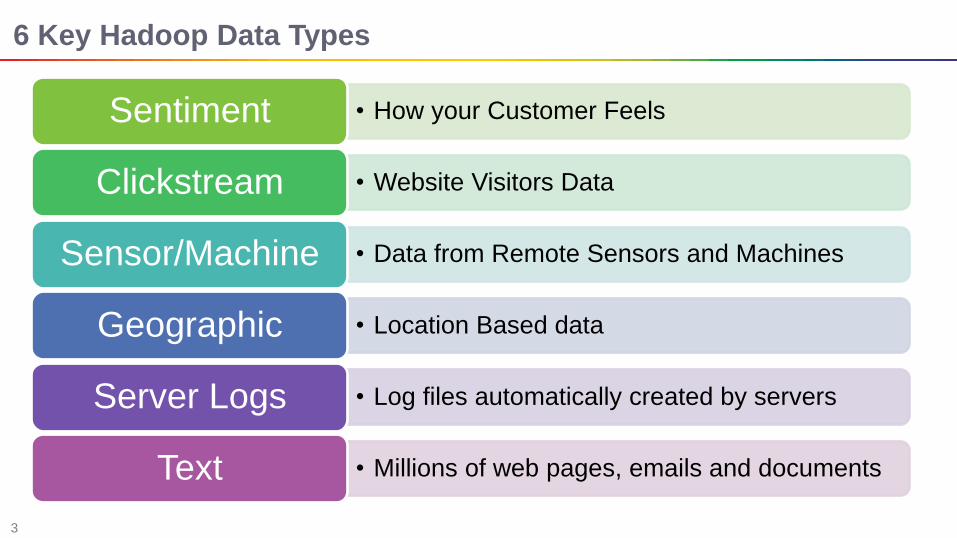
6 Key Hadoop Data Types
• How your Customer Feels Sentiment
• Website Visitors Data Clickstream
• Data from Remote Sensors and Machines Sensor/Machine
• Location Based data Geographic
• Log files automatically created by servers Server Logs
• Millions of web pages, emails and documents Text

4
Changes in Analyzing Data
Big Data is fundamentally changing the way we analyze information.
Ability to analyze vast amounts of data rather than evaluating sample sets. Historically we have had to look at causes. Now we can look at patterns and correlate in data that give us much better prospective.
5
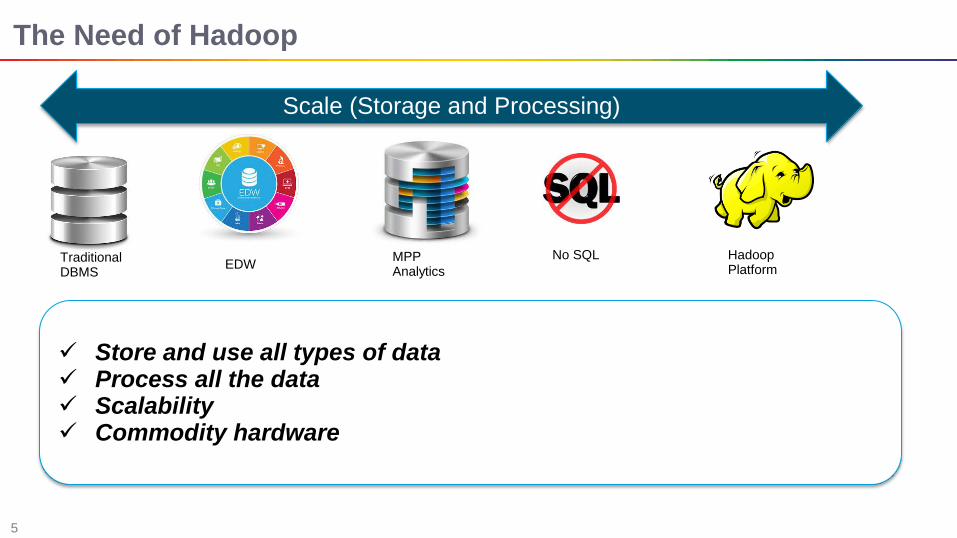
The Need of Hadoop
Store and use all types of data Process all the data Scalability Commodity hardware
Scale (Storage and Processing)
Traditional DBMS
EDW MPP Analytics
No SQL Hadoop Platform
6
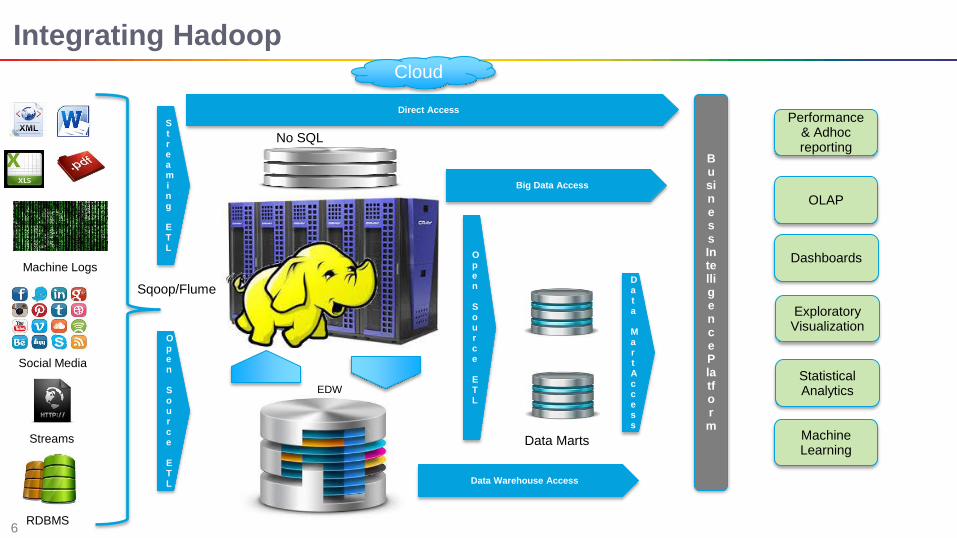
Integrating Hadoop
RDBMS
Streams
Social Media
Data Marts
Machine Logs
Sqoop/Flume
Open Source ETL
Streaming ETL
Direct Access
No SQL
Open Source ETL
Data Warehouse Access
EDW
Data Mart Access
Big Data Access
Business Intelligence Platform
Cloud
Performance & Adhoc reporting
OLAP
Dashboards
Exploratory Visualization
Statistical Analytics
Machine Learning

7
What is Hadoop ?
o Framework for solving data intensive processes o Designed to scale massively o Processes all the contents of a file (instead of attempting to read
portion of a file) o Hadoop is very fast for very large jobs o Hadoop is not fast for small jobs o It does not provide caching or indexing (tools like HBase can
provide these features if needed) o Designed for hardware and software failures

8
What is Hadoop 2.0?
The Apache Hadoop 2.0 project consists of the following modules o Hadoop Common: the utilities that provide support for the other
Hadoop modules o HDFS: the Hadoop Distributed File System o YARN: a framework for job scheduling and cluster resource
management. o MapReduce: for processing large data sets in a scalable and
parallel fashion

9
What is Yarn?
YARN is a sub-project of Hadoop at the Apache Software Foundation that takes Hadoop beyond batch processing to enable broader data-processing
It extends the Hadoop platform by supporting non-MapReduce workloads associated with other programming models
The core concept of YARN was born out of a need to have Hadoop work for more real-time and streaming capabilities
As more and more data landed in Hadoop, enterprises have demanded that Hadoop extend its capabilities
As part of Hadoop 2.0, YARN takes the resource management capabilities that were in MapReduce and packages them so they can be used by new engines
Streamlines MapReduce to do what it does best - process data Run multiple applications in Hadoop, all sharing a common resource
management Many organization are already building application on YARN in order to bring
them IN to Hadoop With Hadoop 2.0 and YARN, organizations can use Hadoop for streaming,
interactive and a world of other Hadoop-based applications

10
Yarn taking Hadoop Beyond Batch
With YARN, Applications run natively in Hadoop
Applications Run Natively IN Hadoop
HDFS2 (Redundant, Reliable Storage)
YARN (Cluster Resource Management)
BATCH (MapReduce)
INTERACTIVE (Tez)
STREAMING (Storm, S4,…)
GRAPH (Giraph)
IN-MEMORY (Spark)
HPC MPI (OpenMPI)
ONLINE (HBase)
OTHER (Search)
(Weave…)
11
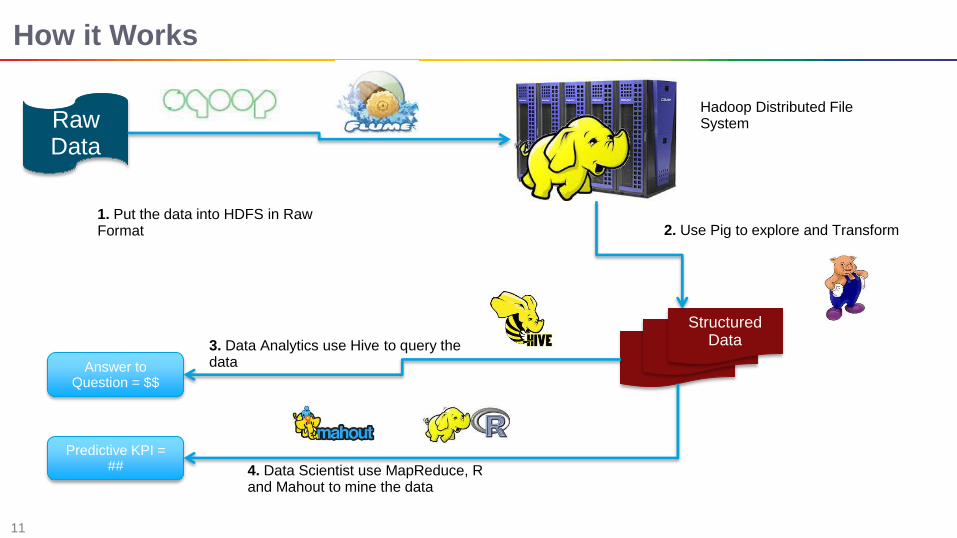
How it Works
Raw Data
1. Put the data into HDFS in Raw Format 2. Use Pig to explore and Transform
3. Data Analytics use Hive to query the data
4. Data Scientist use MapReduce, R and Mahout to mine the data
Hadoop Distributed File System
Structured Data
Answer to Question = $$
Predictive KPI = ##

12
Getting Relational Data & Raw Data in to Hadoop
Raw Data
Hadoop Distributed File System
Table in RDBMS
Sqoop Job Sqoop is a tool to transfer data between RDBMS to Hadoop
Flume Agent
Flume is a tool to streaming data in to
Hadoop

13
What is Pig?
Pig is an extension of Hadoop that simplifies the ability to query large HDFS datasets
Pig is made up of two main components: • A data processing language called Pig Latin • A compiler that compiles and runs Pig Latin scripts
Pig was created at Yahoo! to make it easier to analyze the data in HDFS without the complexities of writing a traditional MapReduce program
With Pig, you can develop MapReduce jobs with a few lines of Pig Latin

14
What is Hive?
Hive is a subproject of the Apache Hadoop project that provides a data warehousing layer built on top of Hadoop
Hive allows you to define a structure for your unstructured big data, simplifying the process of performing analysis and queries by introducing a familiar, SQL-like language called HiveQL
Hive is for data analysts familiar with SQL who need to do ad-hoc queries, summarization and data analysis on their HDFS data
Hive is not a relational database Hive uses a database to store metadata, but the data that Hive
processes is stored in HDFS Hive is not designed for on-line transaction processing and does not
offer real-time queries and row level updates
15
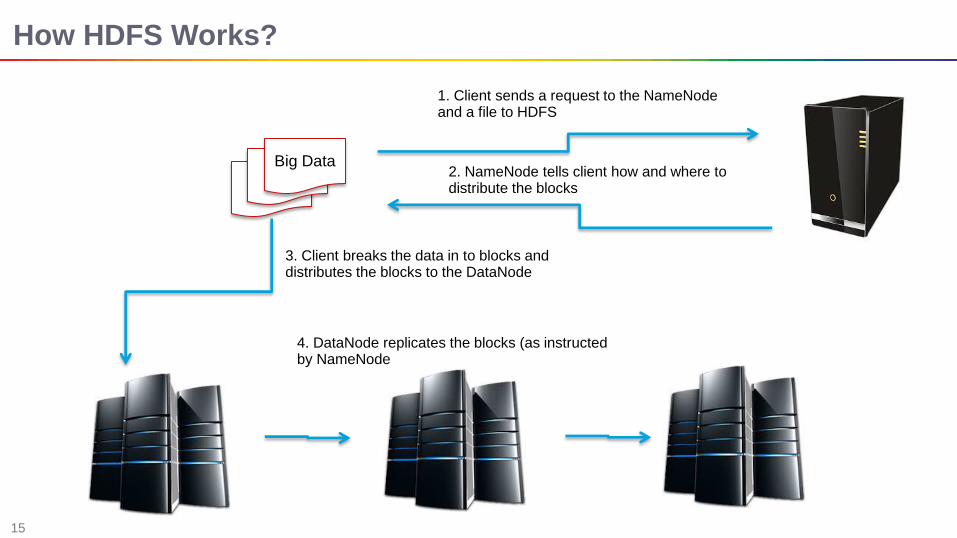
1. Client sends a request to the NameNode and a file to HDFS
2. NameNode tells client how and where to distribute the blocks
Big Data
3. Client breaks the data in to blocks and distributes the blocks to the DataNode
4. DataNode replicates the blocks (as instructed by NameNode
How HDFS Works?
16
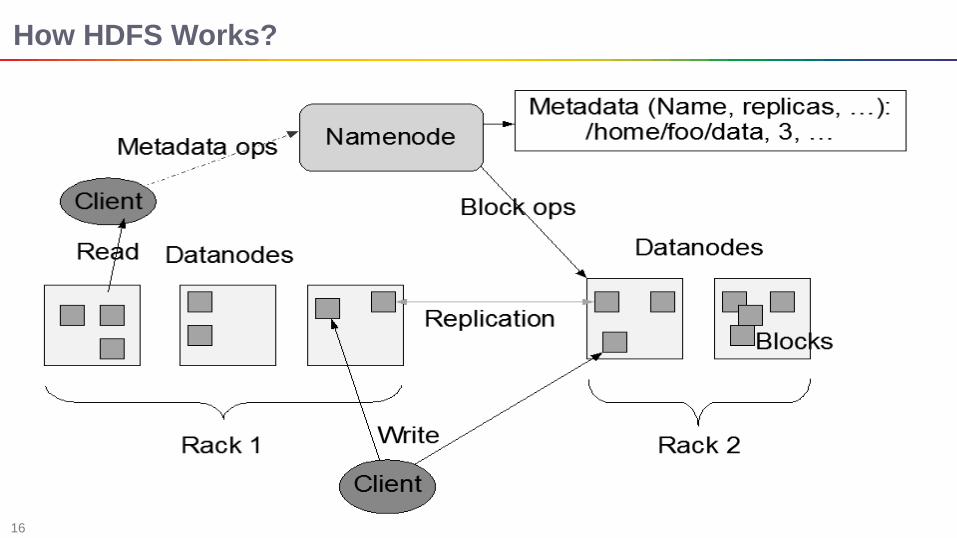
How HDFS Works?
17
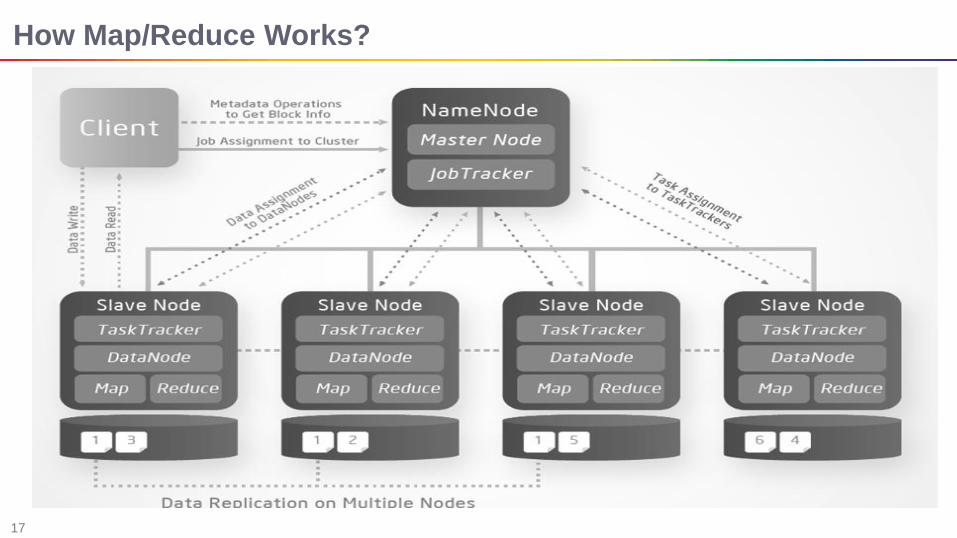
How Map/Reduce Works?
18
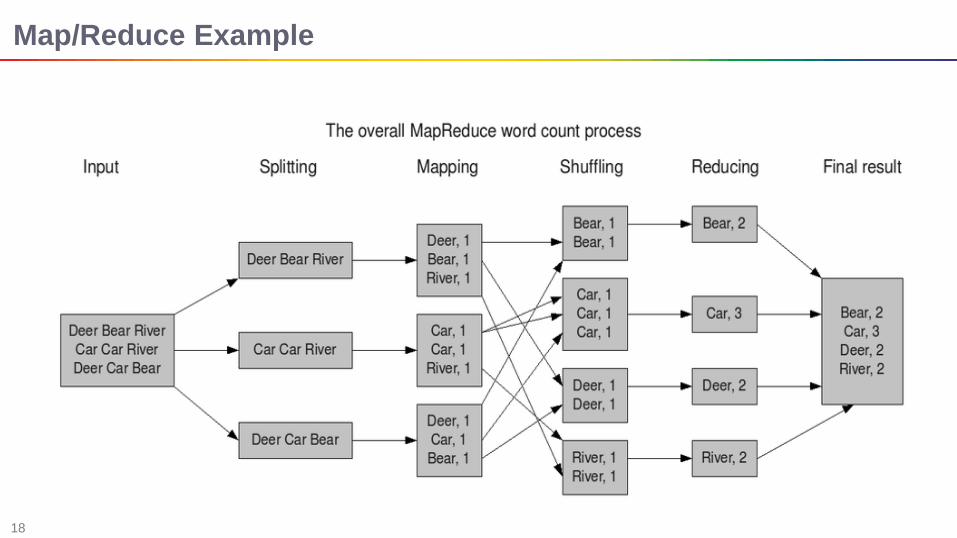
Map/Reduce Example
19
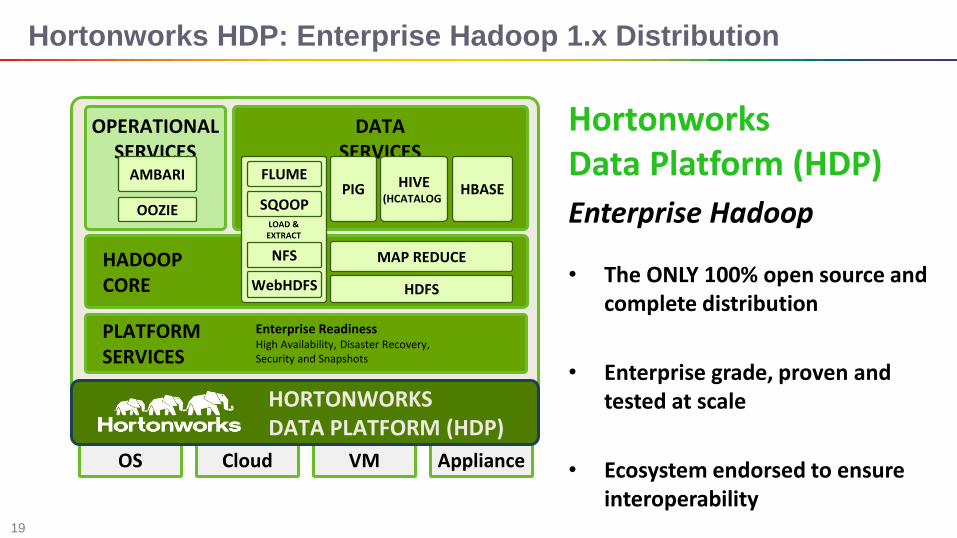
Hortonworks HDP: Enterprise Hadoop 1.x Distribution
OS Cloud VM Appliance
PLATFORM SERVICES
HADOOP CORE
Enterprise Readiness High Availability, Disaster Recovery, Security and Snapshots
HORTONWORKS DATA PLATFORM (HDP)
OPERATIONAL SERVICES
DATA SERVICES
HIVE (HCATALOG)
PIG HBASE
OOZIE
AMBARI
HDFS
MAP REDUCE
Hortonworks Data Platform (HDP)
Enterprise Hadoop
• The ONLY 100% open source and complete distribution
• Enterprise grade, proven and tested at scale
• Ecosystem endorsed to ensure interoperability
SQOOP
FLUME
NFS
LOAD & EXTRACT
WebHDFS

20
Hadoop 2.0… The Enterprise Generation
Business Value
Big Data Transactions, Interactions, Observations
Single Platform Multiple Use
BATCH
INTERACTIVE
ONLINE
1.0 Architected for the Large Web Properties
2.0 Architected for the Broad Enterprise
Enterprise Requirements Hadoop 2.0 Features
Mixed workloads YARN
Interactive Query Hive on Tez
Reliability Full Stack HA
Point in time Recovery Snapshots
Multi Data Center Disaster Recovery
ZERO downtime Rolling Upgrades
Security Knox Gateway

21
HDP: Enterprise Hadoop 2.0 Distribution
OS/VM Cloud Appliance
PLATFORM SERVICES
HADOOP CORE
Enterprise Readiness High Availability, Disaster Recovery, Rolling Upgrades, Security and Snapshots
HORTONWORKS DATA PLATFORM (HDP)
OPERATIONAL SERVICES
DATA SERVICES
HIVE & HCATALOG
PIG HBASE
HDFS
MAP
Hortonworks Data Platform (HDP)
Enterprise Hadoop
• The ONLY 100% open source and complete distribution
• Enterprise grade, proven and tested at scale
• Ecosystem endorsed to ensure interoperability
SQOOP
FLUME
NFS
LOAD & EXTRACT
WebHDFS
KNOX*
OOZIE
AMBARI
FALCON*
YARN*
TEZ* OTHER REDUCE
22
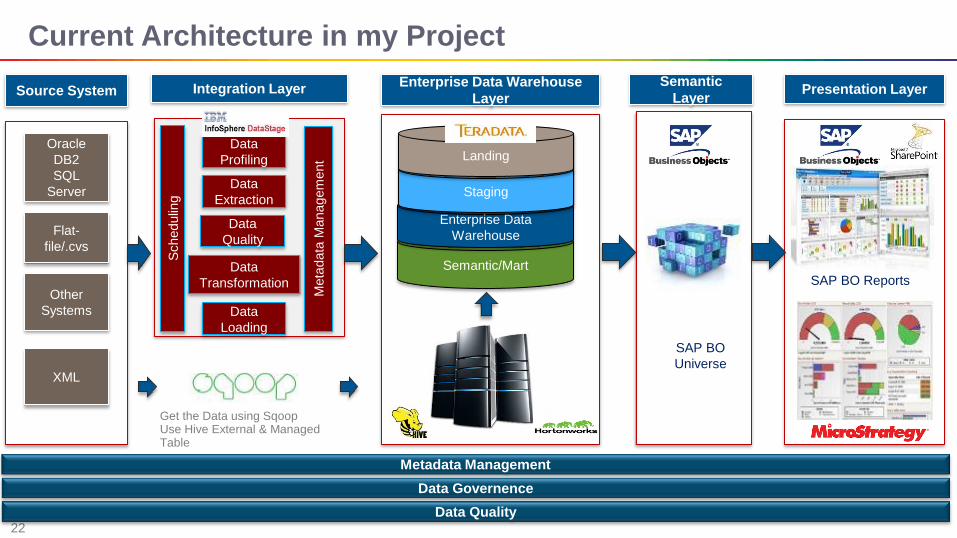
Current Architecture in my Project
Source System Integration Layer Enterprise Data Warehouse
Layer
Semantic
Layer Presentation Layer
Oracle
DB2
SQL
Server
Data
Profiling
Data
Extraction
Data
Quality
Data
Transformation
Data
Loading M
eta
data
Managem
ent
Schedulin
g
Semantic/Mart
Enterprise Data
Warehouse
Staging
Flat-
file/.cvs
XML
Metadata Management
Data Governence
Data Quality
SAP BO
Universe
SAP BO Reports
Landing
Other
Systems
Get the Data using Sqoop Use Hive External & Managed Table

23
Lambda Architecture
The Lambda-Architecture aims to satisfy the needs for a robust system that is fault-tolerant, both against hardware failures and human mistakes, being able to serve a wide range of workloads and use cases, and in which low-latency reads and updates are required. The resulting system should be linearly scalable, and it should scale out rather than up.
1. All data entering the system is dispatched to both the batch layer and the speed layer for processing. 2. The batch layer has two functions: (i) managing the master dataset (an immutable, append-only set of raw data), and (ii) to pre-compute the batch views. 3. The serving layer indexes the batch views so that they can be queried in low-latency, ad-hoc way. 4. The speed layer compensates for the high latency of updates to the serving layer and deals with recent data only. 5. Any incoming query can be answered by merging results from batch views and real-time views.