wilf2011 - slides
TRANSCRIPT

WILF2011WILF2011Trani 29-31 August 2011Trani 29-31 August 2011
Subtractive Initialization of Nonnegative Matrix
Factorizationsfor Document Clustering
Department of Mathematics Department of Mathematics University of BariUniversity of Bari
Gabriella Casalino
Nicoletta Del Buono Corrado Mencar

Introduction
Several applications store data in huge non-negative matrices Document collections Term-document matrix Image collections image matrix Recommender systems customer-item matrix
Common goals in mining information from non-negative data Cluster similar data into groupsRetrieve items most similar to an user’s query Identify interpretable critical dimensions within the
data collection

Introduction
Low rank approximation is fundamental to process and conceptualise large nonnegative data matricesSingular value decomposition Factor analysis Principal component analysis
Drawbacks
Not able to maintain Not able to maintain the non-negativity of the non-negativity of
the datathe data
Difficulties to provide Difficulties to provide interpretation of the interpretation of the mathematical factorsmathematical factors

Non-negative matrix factorization
Low-rank non-negative matrix factorization (NMF) allows a reduced representation of data by using additive componentsPhysical non-negativity is preserved Learning parts-based representation: parts are
generally combined additively to form a whole

Mathematical formalization of NMF
The mathematical problem Given an initial set of data expressed by a n×m
matrix X each column is an n-dimensional non-negative
vector of the original database (m vectors)NMF consists in approximating X with the product of
two reduced rank matrices
X ≈ WH
n×r basis matrix
r×m encoding variable matrix
Non-Negative Factorization

NMF numerical solutions
A NMF is an approximation problem specified cost function can be defined to qualify this approximation
Use of Euclidean distance: Simple multiplicative update algorithm Lee-Seung algorithm (Euclidean update) Iterative scheme
Use of KL-divergence measure: Another multiplicative updates rule Iterative scheme
Use of general class of distortion measures: Bregman divergences
ij
ijijij
ij ) (UVY- )) (UV
Ylog(
2|||| FUVY

NMF: advantages and drawbacks
AdvantagesStorage
generally W and H are sparse
Interpretability due to additive “parts-basedparts-based” representation of the data
Basis vectors correspond to
conceptual propertiesconceptual properties of the dataX term-document matrix
W concepts or topicsH coefficients for weighing
and combining topics
DisadvantagesLack of
uniqueness robust computation
iterative algorithms Proper initialization
Subtractive Clustering to generate the initial matrices W0 and H0

Subtractive Clustering (SC)
Data matrix X=[X1,X2…Xn] with columns normalized in l2 norm
SC algorithmEach document Xi is a potential cluster centerFor each document, the potential of surrounding
points in a neighborhood ra is computedThe cluster center is selected to be the document
with the higher potential Decrease the potential of most similar documents
(in a neighborhood rb) to the cluster center The process continues until a stopping criteria is
reached

NMF Initialization by SC
# of iteration in SC
# of clusters
€
W0 = X 1,X 2,K , X k[ ]
Hkj0
exp 1
2
X j W*k0 2
2
exp 1
2
X j W*i0 2
2
i1
r
Automatic selection of the subspace dimension r
Basis vector are documents High interpretability
Encoding matrix provides the fuzzy membership value for each document to each
cluster
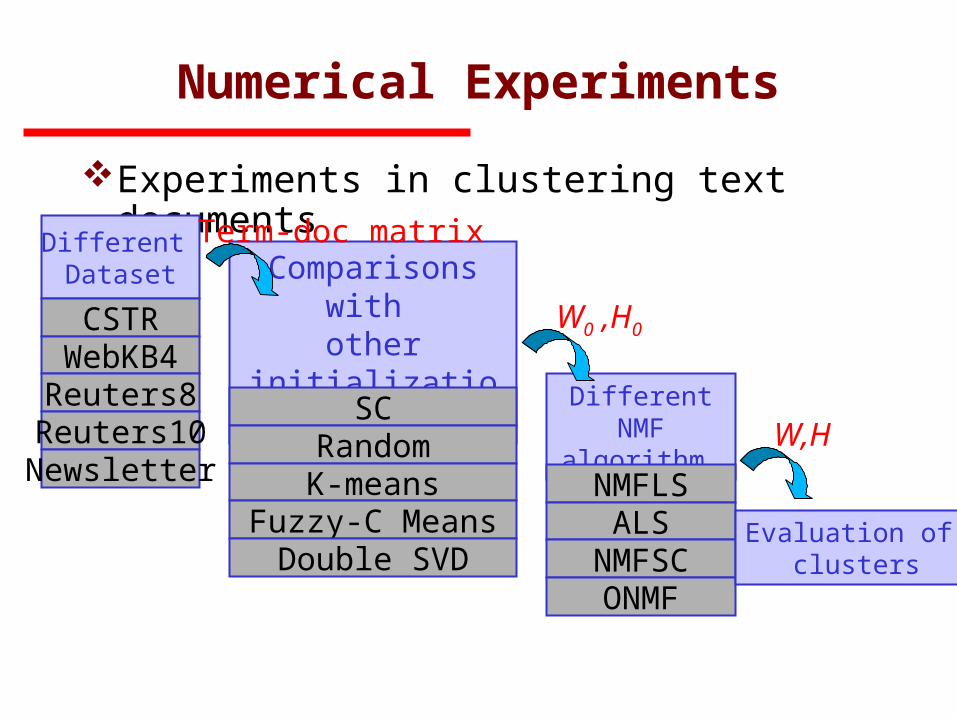
Numerical Experiments
Experiments in clustering text documents
Different Dataset
CSTRWebKB4Reuters8
Reuters10Newsletter
Comparisons with other initialization
SCRandomK-means
Fuzzy-C MeansDouble SVD
Term-doc matrix
Different NMF algorithm
NMFLSALS
NMFSCONMF
W0 ,H0
W,H
Evaluation of clusters

Initial error
Evaluation measures
Initialization algorithms
X W0H0 F
2
X WH F
2
Computational time
Final errorNMF algorithms
# of iterates

Evaluation measures

Cluster evaluation measures
Cluster cohesiveness
Semantic cohesiveness
CC pic log2 pic i1
k
c1
m
SC p jsj1
m
s1
k
log p js

Conclusion and future work
SC has been proposed as initialization scheme for NMFStrength points:
rank factor r automatically discovered when estimation of distance among data is provided
Fast in constructing initial pairs W0 and H0
Encouraging results Future work
Application on different dataset Deeper investigation of the SC capability of
predicting r