xjoin: getting fast answers from slow and bursty networks t. urhan m. j. franklin iacs, csd,...
Post on 21-Dec-2015
215 views
TRANSCRIPT

XJoinXJoin: : Getting Fast Answers From Getting Fast Answers From Slow and Bursty NetworksSlow and Bursty Networks
T. UrhanM. J. Franklin
IACS, CSD, University of
Maryland
Presented by: Abdelmounaam
Rezgui
CS-TR-3994

The Problem
How to improve the interactive performance of queries over widely distributed data sources ?
2
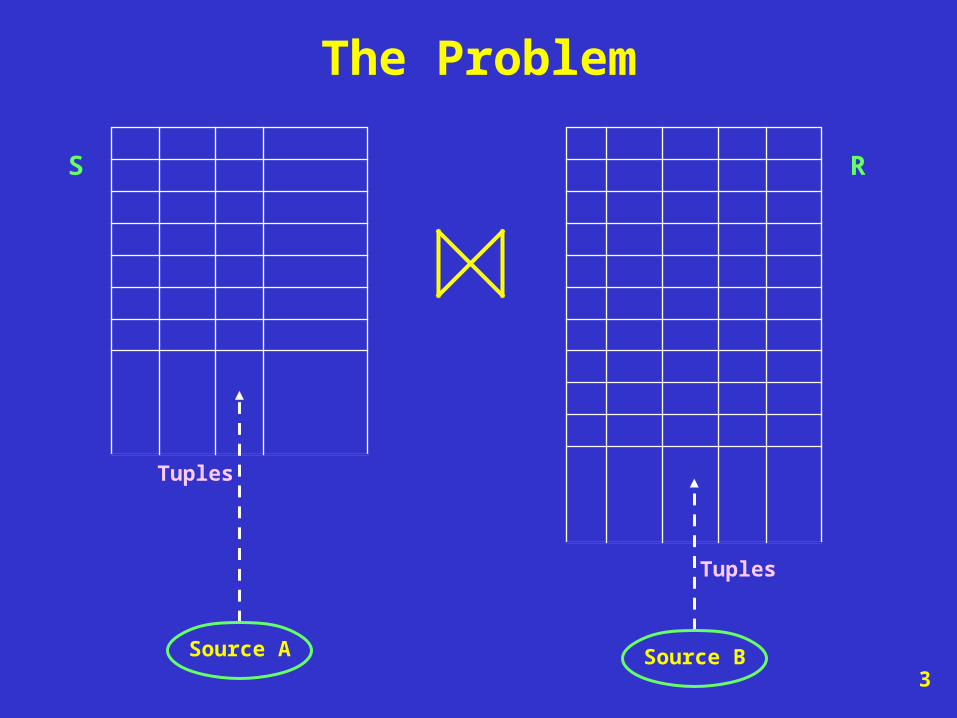
RS
Tuples
Tuples
3
The Problem
Source BSource A

Why is the response-time unpredictable ?
• Remote sources
• Intermediate sites
• Communication links
• Overloading
• Congestion
• Failures
are vulnerable
to {
4
Significant and unpredictable delays
Unresponsive and unusable systems

Different classes of delays
• Initial delay: a longer than expected wait to receive the first tuple.
• Slow delivery: data arrive at a fairly constant but slower than expected rate.
• Bursty arrival: bursts of data followed by long periods of no arrivals.
5

Some Join variants
• Nested Loops Join• Block Nested Loops Join• Index Nested Loops Join• Sort-Merge Join• Classic Hash Join• Simple Hash Join• Grace Hash Join• Hybrid Hash Join (HHJ)• TID Hash Join• Symmetric Hash Join (SHJ)• XJoin
6

Query Scrambling
reacts to data delivery pbs. by on-the-fly rescheduling of query operators and
restructuring of the query execution plan.
7
• improve the response time for the entire query• may slow down the return of some initial results
To be presented on November 22, 1999

Traditional query processing techniques
• Reduce the memory requirements• Reduce Disk I/O
• Delivery of the entire query result (on-line users would like to receive initial results asap.)
• Slow and bursty delivery of data from remote sources can stall query execution.
8

XJoin: Fundamental principles
• improves the interactive performance by producing results incrementally (as they become available)
• allows progress to be made even when one or more sources experience delays (delays are exploited to produce more tuples earlier)
9

XJoin : The key idea
When inputs are delayed
run a background processing on the previously received results
10

• Managing the flow of tuples between memory and secondary storage.
• Controlling the background processing.
• Full answer (all the tuples are produced).
• No duplicate tuples are generated.
XJoin : The challenges
11

SHJoin (Symmetric Hash Join)
Hash table 2
Matching
Hash table 1
Source 2Source 112

SHJoin requires:
13
Hash tables for both of its inputs be memory resident.
Unacceptable for complex queries.

XJoin
14
Partioning:
• each input is partitioned into a number of partitions based on a hash function.
• each partition i of source A, PiA :
PiA = MPiA DPiA
MPiA DPiA =
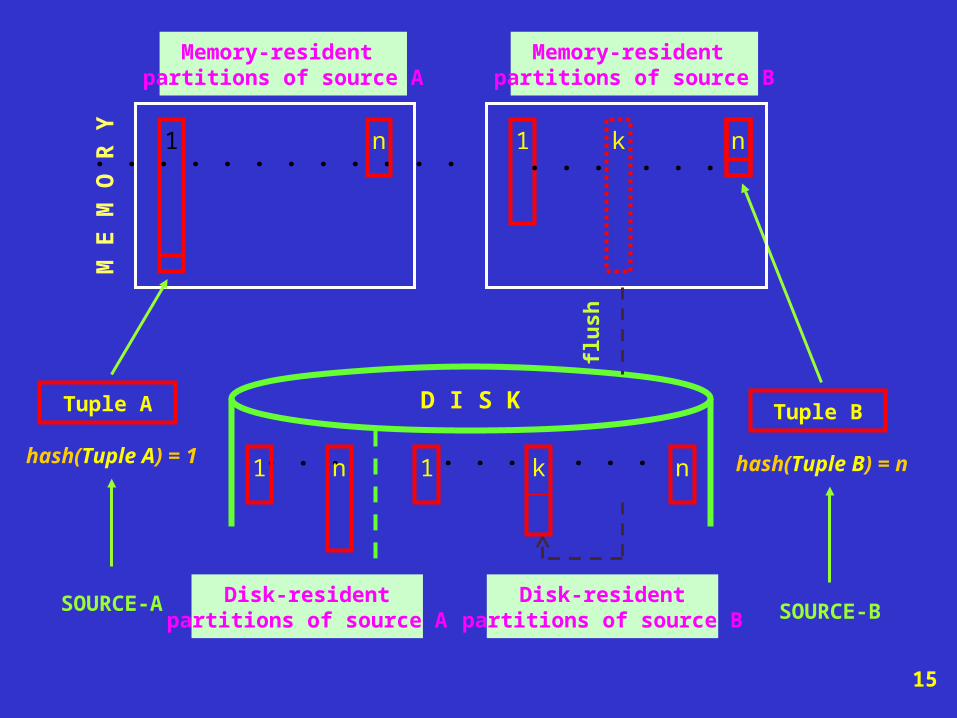
D I S K Tuple B
hash(Tuple B) = n
SOURCE-B
Memory-resident partitions of source B
. . . . . .k1 n
flu
shDisk-resident
partitions of source B
. . . . . .
Disk-residentpartitions of source A
Memory-resident partitions of source A
. . . . . . . . . . . .1
SOURCE-A
M E
M O
R Y
. . .
n
1n1 k n
15
Tuple A
hash(Tuple A) = 1
hash(record B) = j
Partitions of source B
. . . . . . . . .ii
M E
M O
R Y j
16
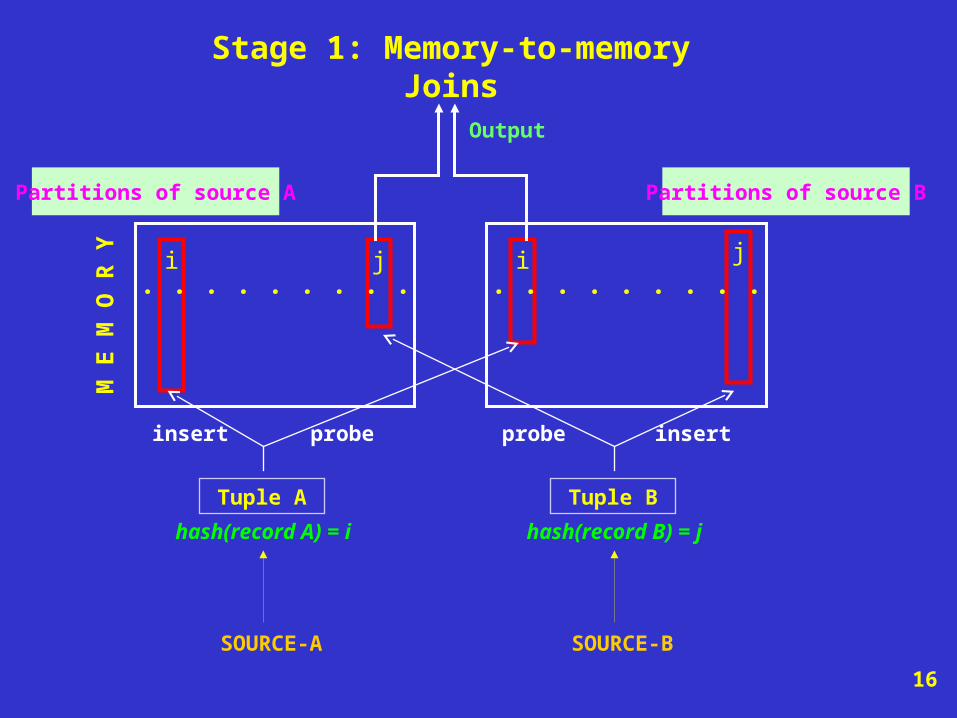
Stage 1: Memory-to-memory Joins
Partitions of source A
j
SOURCE-B
Tuple B
SOURCE-A
Tuple A
hash(record A) = i
. . . . . . . . .
insertinsert probeprobe
Output

Partitions of source BPartitions of source A
M E
M O
R Y
i. . . . . . .
ii
D I
S K
i
Output
17
Stage 2: Disk-to-memory Joins
. . . . . . .. . . . . . .. . . . . . .
Partitions of source BPartitions of source A
. . . . .. . . . .. . . . .. . . . .
DPiA MPiB

18
Stage 3: Clean-up
• Stage 1 fails to join tuples that were not in the memory at the same time.
• Stage 2 fails to join two tuples if one of them is not in the memory when the other is brought from the disk.
• Stage 3 joins all the partitions (memory-resident and disk-resident portions) of the two sources.
19
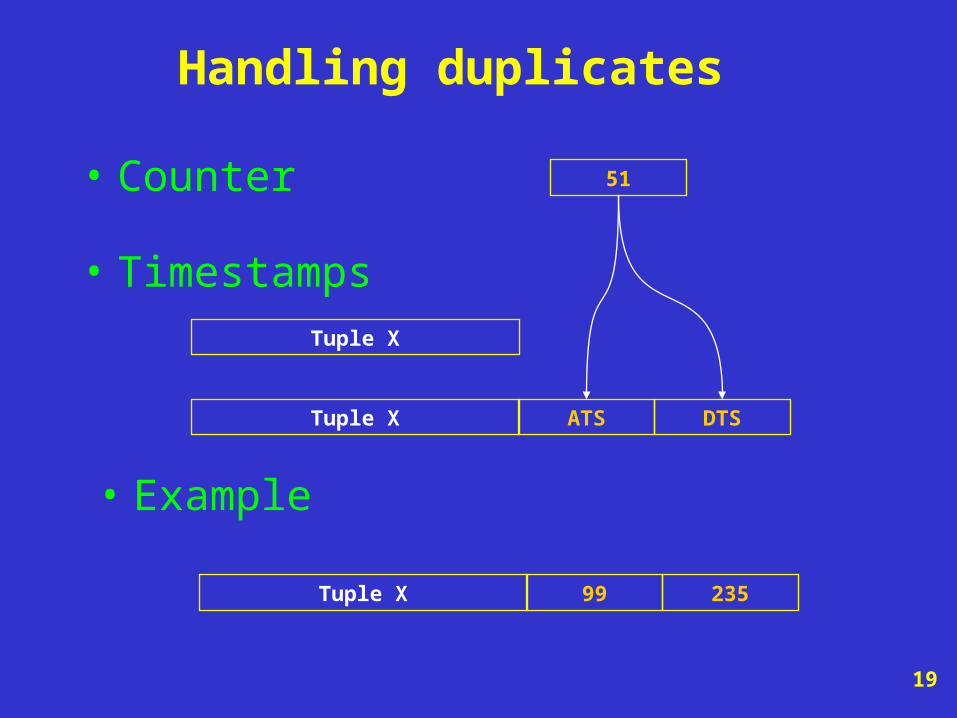
Handling duplicates
• Timestamps
Tuple X
Tuple X ATS DTS
• Example
Tuple X 99 235
• Counter 51
20
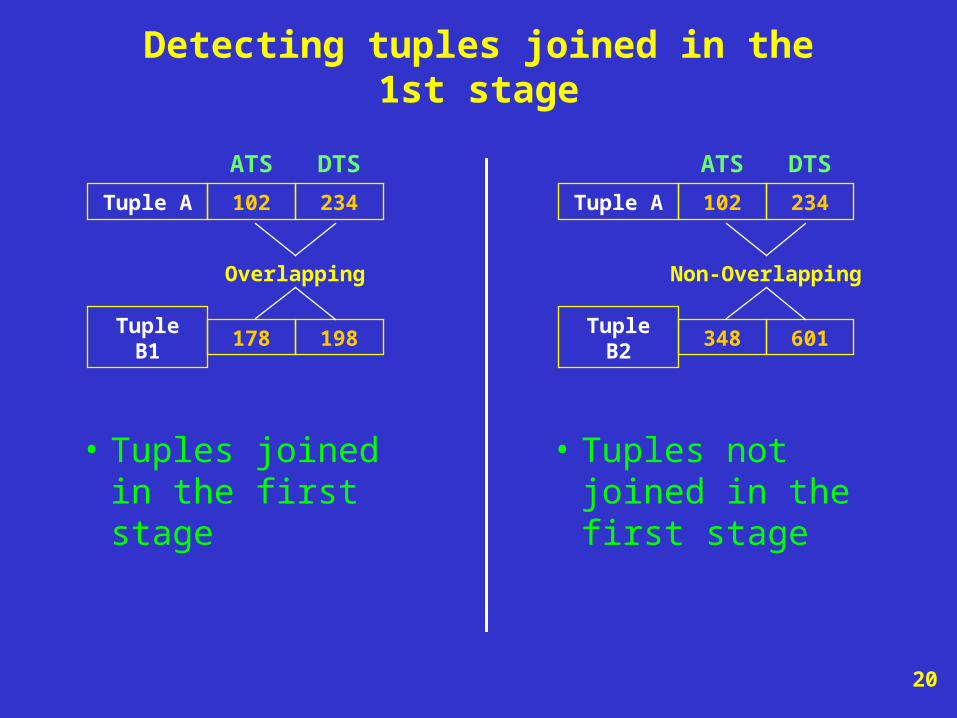
Detecting tuples joined in the 1st stage
Tuple A 102 234
Tuple B1 178 198
• Tuples joined in the first stage
DTSATS
Overlapping
Tuple A 102 234
Tuple B2 348 601
• Tuples not joined in the first stage
DTSATS
Non-Overlapping

21
Detecting tuples joined in the 2nd stage
Tuple A
DTS
20 340 250 550 300 700100 200
ATS ProbeTSDTSlast
Tuple B
DTS
100 300 800 900500 600
ATS
Overlap
History list for the corresponding partitions
22
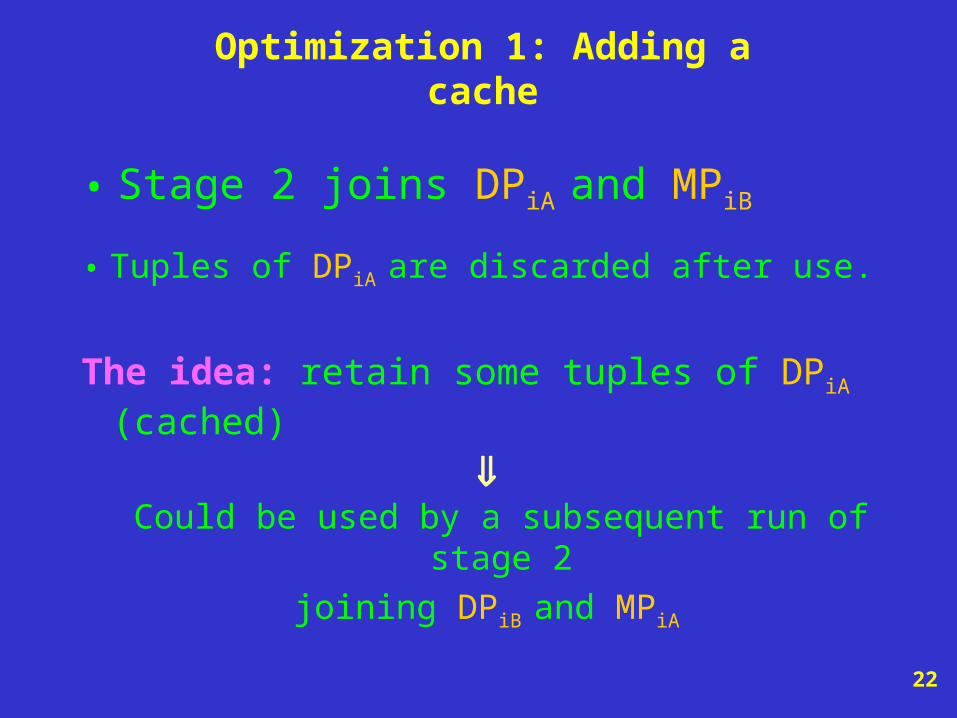
Optimization 1: Adding a cache
• Stage 2 joins DPiA and MPiB
• Tuples of DPiA are discarded after use.
The idea: retain some tuples of DPiA (cached)
Could be used by a subsequent run of stage 2
joining DPiB and MPiA

23
i . . .. . .i . . .. . .
i . . .. . .i . . .. . . i
CA
CH
E
Partitions of Source B
Partitions of Source A
i . . .. . .i . . .. . .
i . . .. . .i . . .. . . i
CA
CH
E
Partitions of Source B
Partitions of Source A
ME
MO
RY
DIS
K
prob
e
insert
OutputOutputOutput
Partitions of Source B
Partitions of Source A
Second run of stage 2First run of stage 2
prob
eprobe

24
Optimization 2: Controlling Stage 2
• Overhead incured by Stage 2 is hidden only when both inputs experience delays
• Reduce the aggressiveness of Stage 2
• Dynamic activation threshold (e. g., 0.01 0.02)

Experiment Environment
25
PREDATOR, an Object-Relational DBMS
• Xjoin operator added.
• Query optimizer extended to:
• account for XJoin.
• provide some of the statistics and calculations required by XJoin.
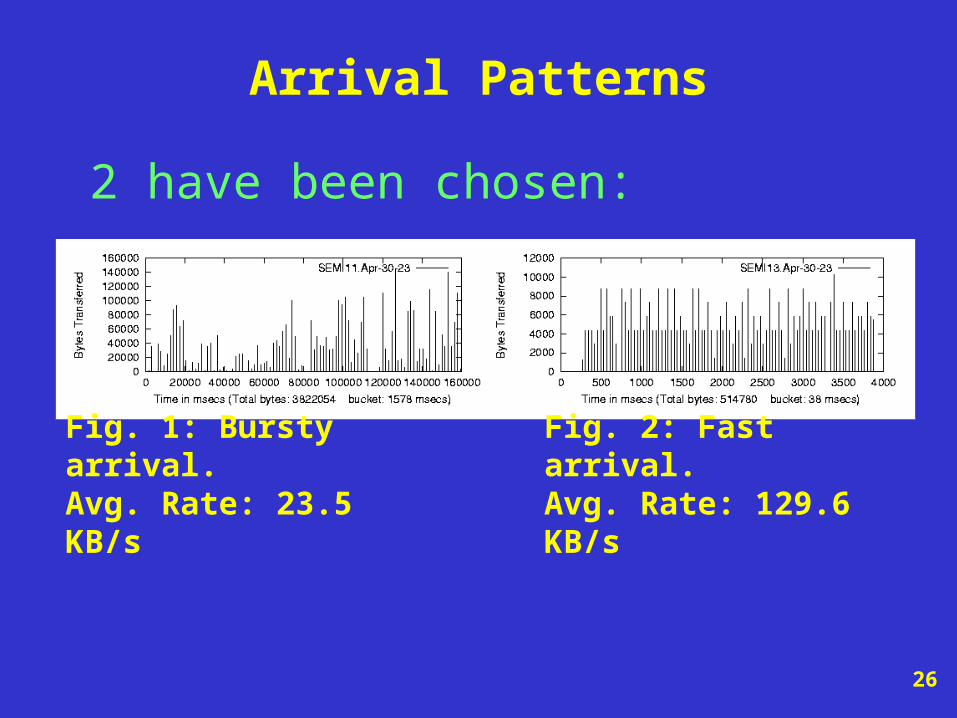
Arrival Patterns
2 have been chosen:
Fig. 1: Bursty arrival.Avg. Rate: 23.5 KB/s
Fig. 2: Fast arrival.Avg. Rate: 129.6 KB/s
26
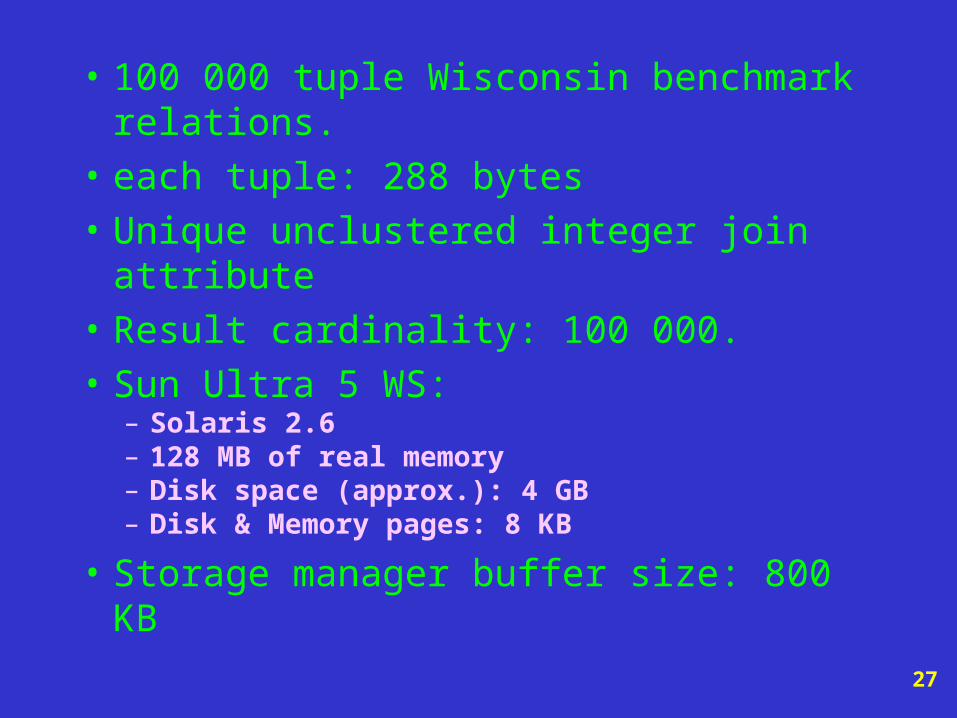
• 100 000 tuple Wisconsin benchmark relations.
• each tuple: 288 bytes
• Unique unclustered integer join attribute
• Result cardinality: 100 000.
• Sun Ultra 5 WS: – Solaris 2.6– 128 MB of real memory– Disk space (approx.): 4 GB– Disk & Memory pages: 8 KB
• Storage manager buffer size: 800 KB
27

Results
Experiment 1 Basic performance of XJoin
• Memory space allocated to the join operators: 3 MB.
• Input relations: 28.8 MB each
• Activation threshold (of stage 2): 0.01
• 4 delay scenarios
28
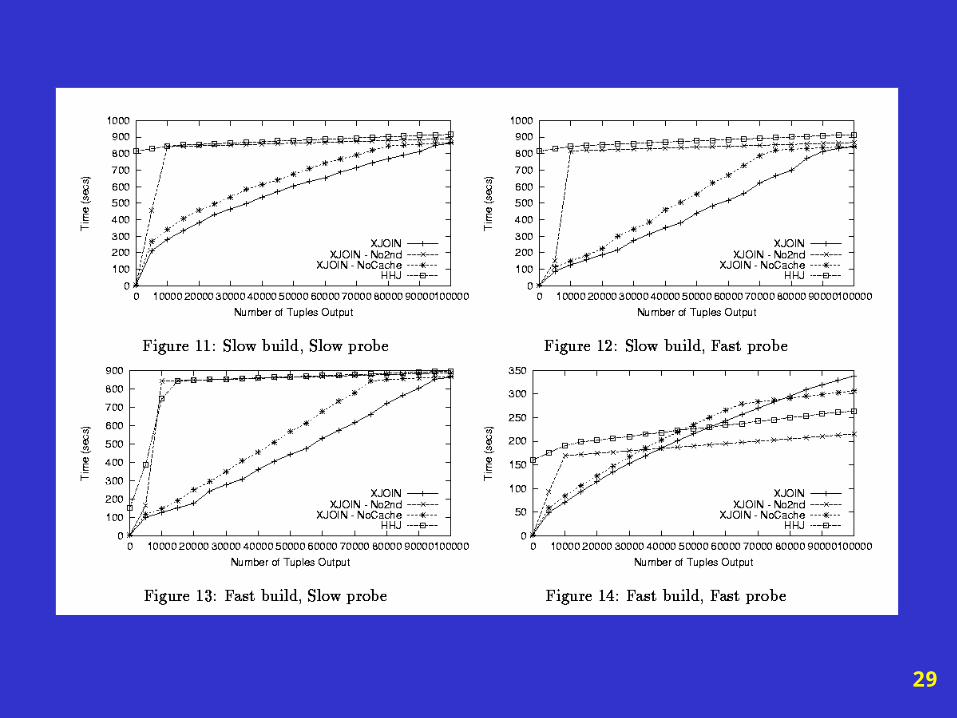
29

Case 1: Slow NetworkBoth sources are slow
• XJoin improves the delivery time of initial answers.
• The reactive background processing is an effective solution to exploit delays.
• The use of cache can further improve performance.
30
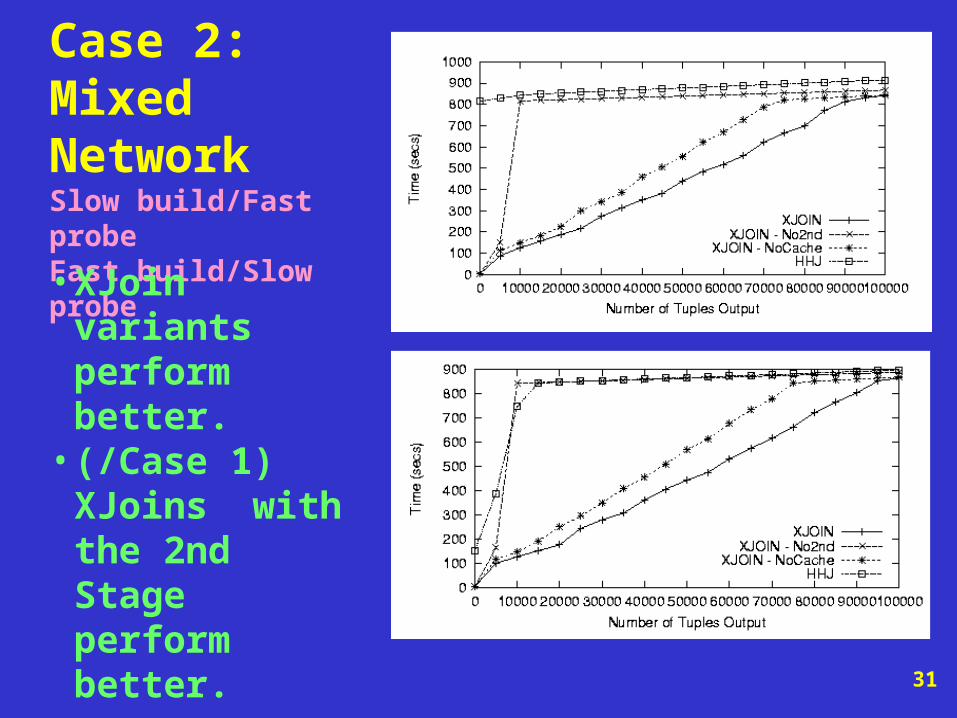
Case 2: Mixed Network Slow build/Fast probeFast build/Slow probe
• XJoin variants perform better.
• (/Case 1) XJoins with the 2nd Stage perform better.
31
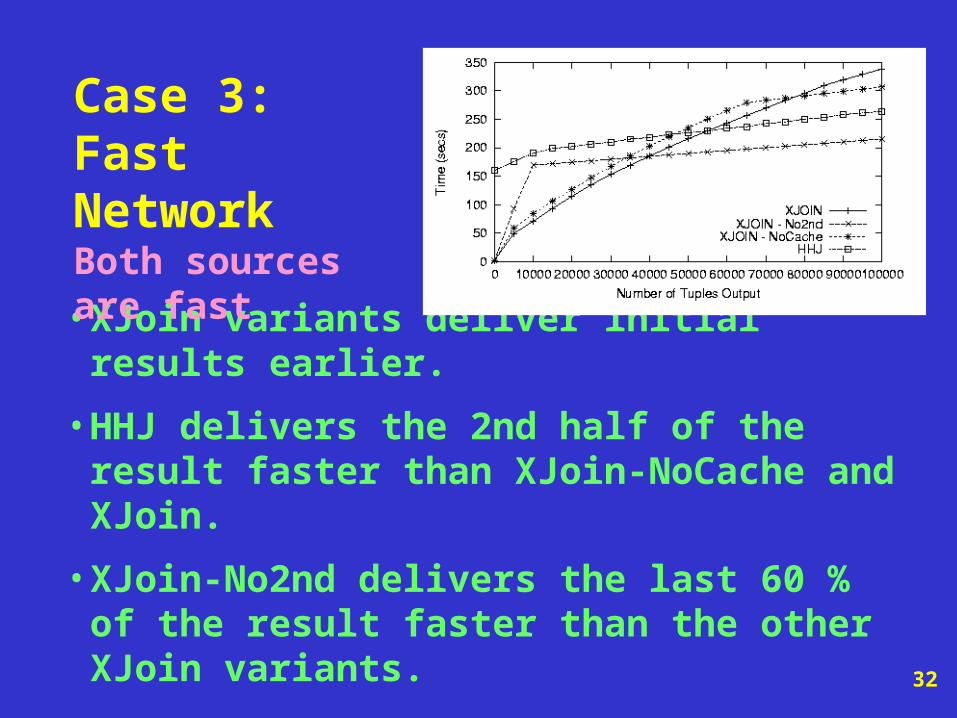
• XJoin variants deliver initial results earlier.
• HHJ delivers the 2nd half of the result faster than XJoin-NoCache and XJoin.
• XJoin-No2nd delivers the last 60 % of the result faster than the other XJoin variants.
32
Case 3: Fast NetworkBoth sources are fast
33
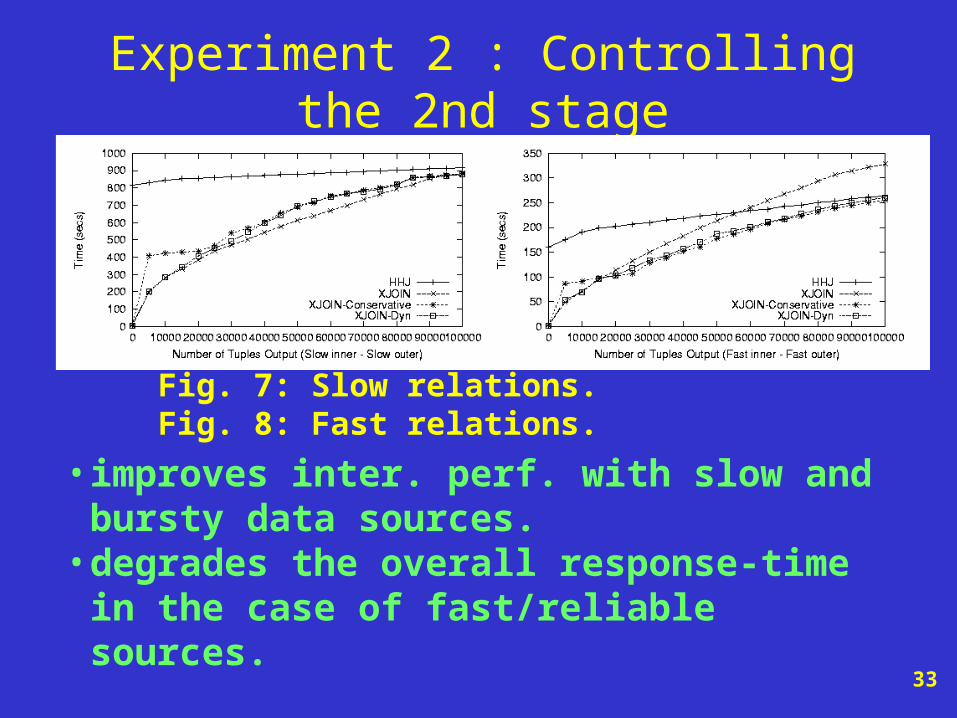
Experiment 2 : Controlling the 2nd stage
• improves inter. perf. with slow and bursty data sources.
• degrades the overall response-time in the case of fast/reliable sources.
Fig. 7: Slow relations. Fig. 8: Fast relations.

• Stage 2 should be employed less aggressively (less often).
• A dynamic activation threshold.
34

XJoin-Dyn
• aggressive in the early stages of the query.
• becomes less aggressive as more of the results are produced.
• starts with a low activation treshold (0.01) and then linearly increases it to 0.02.
35

36
Experiment 3 : the effect of memory size
• Recall ! The prime motivation for designing XJoin was the huge memory requirements of the symmetric hash join.
• XJoin reduces the memory requirements but adds overhead (disk I/O & duplicate detection).

• Size of the input relations: 8.6 MB.• 3 different memory allocations:
- 3 MB (neither of the inputs fit into the memory)- 10 MB (one input fits into the memory)- 20 MB (both inputs fit into the memory)
Fig. 9: Slow Network, Varying memory
Fig. 10: Fast Network, Varying memory
37

• XJoin performs better both in:
- interactive performance
- completion time.
38

Experiment 4 : impact of query complexity
• 2 to 6 relations (1 to 5 joins)• 3 MB to each join operator
Fig. 11. Tuple production rates of XJoin and HHJ (secs)- Slow Network
39

Experiment 4 : impact of query complexity
Fig. 12. Tuple production rates of XJoin and HHJ (secs)
- Fast Network
40
XJoin delivers the initial results faster

XJoin
An effective query processing technique for providing fast query responses to
users in the presence of slow and bursty remote sources.
41
Conclusions

• lowers the memory requirements (partitioning)
• improves the interactive performance.
• reacts to delays and takes advantage of silent periods to produce more tuples faster.
42

What de you think about
PJoin A Multithreaded Parallel XJoin Using
the Cilk Language
?43
Perspectives