zerostack reliable openstack
TRANSCRIPT

Reliable Openstack – Designing
for Availability and Enterprise
Readiness
Ajay Gulati, Chaitanya BVK
ZeroStack, Inc.
Tokyo, October 27-30, 2015
1

Talk Outline
• High Availability: Definition and Types
• Platform HA
• Standard Approach
• ZeroStack Approach
• Demo
• VM HA
• Application HA
2

High Availability vs. Fail-Over
• High Availability
• Always on system
• Few seconds downtime in case of failures
• Auto healing with no manual intervention
• Fail Over
• Can tolerate fault temporarily
• Needs manual intervention for healing
3

Goal
• A web-scale private cloud
• Highly available
• Scale-on-demand
VM VM VMV
M VM VMV
M
V
M
V
M V
M
V
MV
M
V
M
V
M
VMV
MVM
VM
4

Standard Approach: Stateless
• Special Controller Nodes
• Multiple instances with HAProxy with VIP
Nova Nova
HAProxy
VIP: 10.10.1.5
Compute/storage nodesControl cluster
5

Problem #1
• Controller nodes don’t scale automatically
• Can become bottleneck when compute scales
Nova Nova
HAProxy
VIP: 10.10.1.5
Compute/storage nodesControl cluster
6
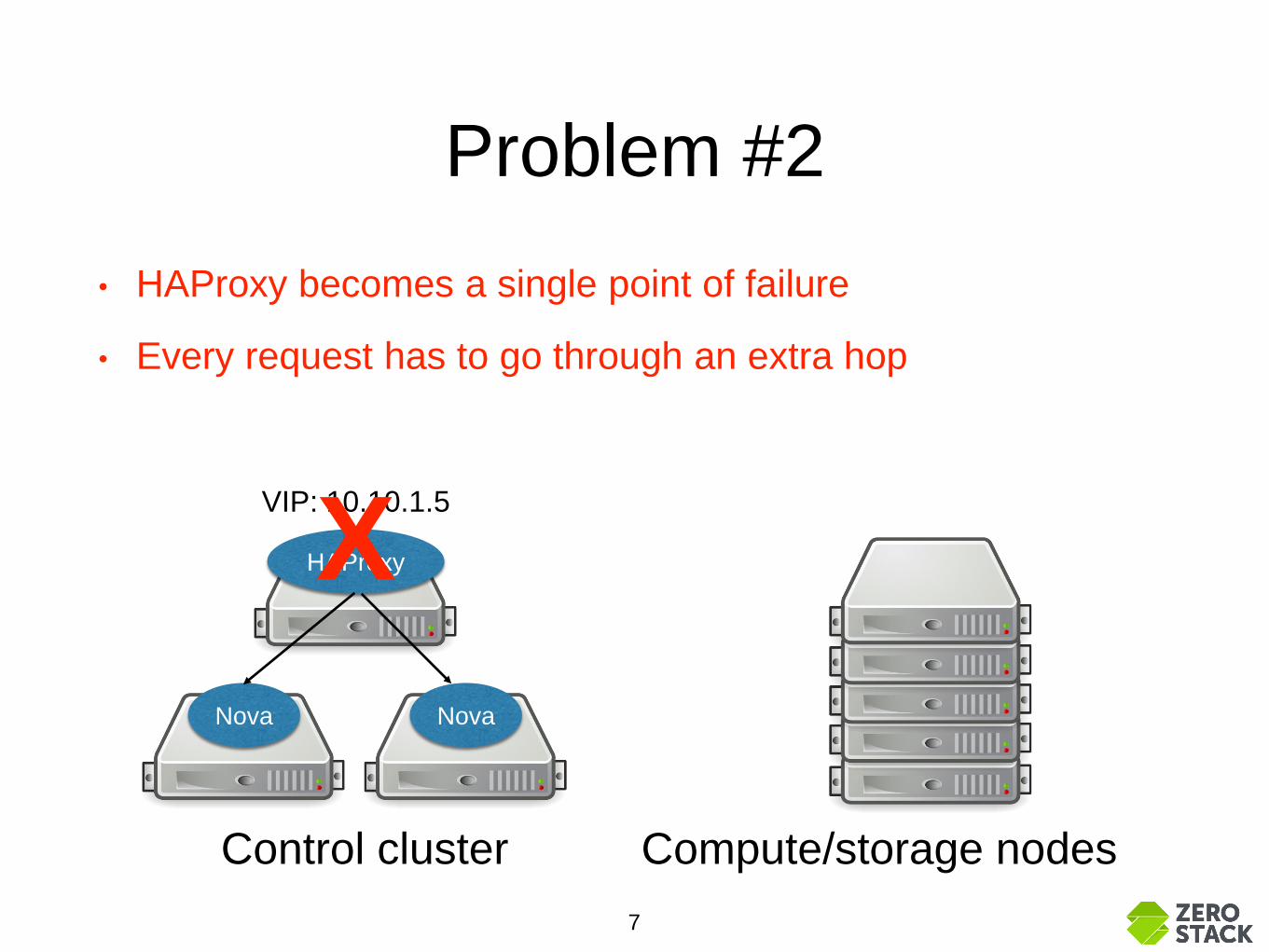
Problem #2
• HAProxy becomes a single point of failure
• Every request has to go through an extra hop
Nova Nova
HAProxy
VIP: 10.10.1.5
Compute/storage nodesControl cluster
X
7
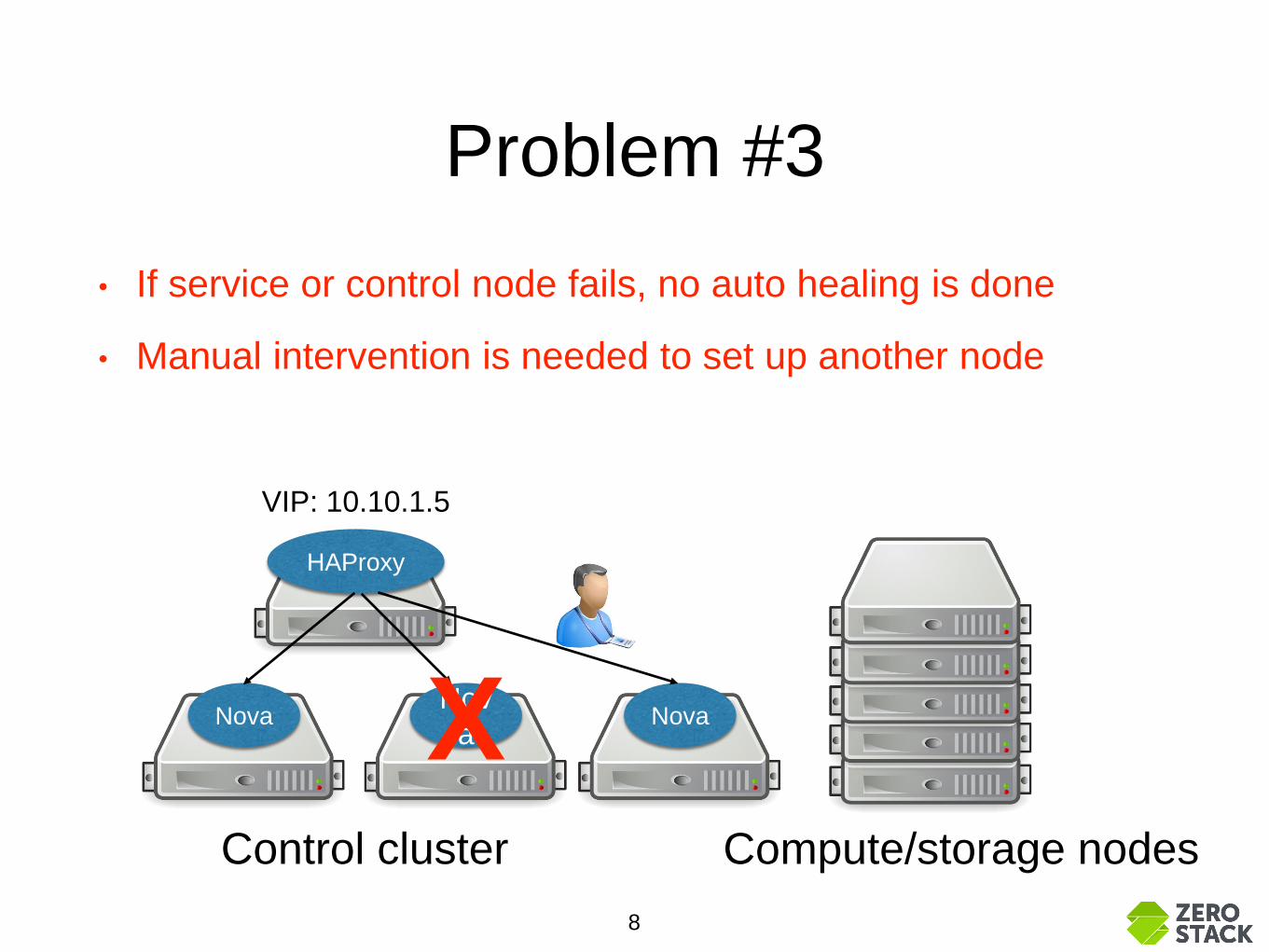
Problem #3
• If service or control node fails, no auto healing is done
• Manual intervention is needed to set up another node
NovaNov
a
HAProxy
VIP: 10.10.1.5
Compute/storage nodesControl cluster
X Nova
8

Standard Approach: Stateful
• Special database or AMQP nodes
• Multiple instances with replication or shared storage
• Active-active or Active-passive
MySql
VIP: 10.10.1.5
Replicated storage
Data replication (DRBD, …)
MySql
Shared reliable storage
9
MySqlMySql

Problem: #1
• Special nodes are needed
• Manual intervention is needed to heal the cluster
MySq
l
VIP: 10.10.1.5
Replicated storage
Data replication (DRBD, …)
XMySql
VIP: 10.10.1.5
10

Problem: #2
• Special nodes are needed
• Expensive shared storage silo needed
• Manual intervention is needed to heal the cluster
MySq
l
Shared reliable storage
XMySql
VIP: 10.10.1.5
11

Standard Approach: Summary
• These methods don’t scale well
• Manual intervention needed, can be error prone
• Too many special nodes or silos
We need a more scalable approach to High
availability
12

Distributed Control Plane
• A distributed service that manages OpenStack services
• Can use any available node for fail-over
• Supports up to 97 failures in a 100 node cluster.
• Initiates auto-healing on failures (eg: fix under-replication, etc)
• Allows us to support more failures after healing
Glance MySqlRabbitMQ
KeystoneNeutron Heat
Distributed control plane
13
Cinder
Nova

Leader Election
• A fault-tolerant Leader Election algorithm picks one node as the Leader
• Multiple leader elections may be used for different responsibilities (eg: load balancing)
• Leader brings up OpenStack services on the cluster
• Monitors health of all services continuously
• Migrates services across nodes as necessary
Glance MySqlRabbitMQ
KeystoneNeutron Heat
continuous status checks
leader
14
Cinder
Nova

Service & Node Failures
• Leader detects node and service failures
• Leader computes a new service mapping
• Migrates services to match the new service map
• Initiate service specific healing if necessary
Cinder Glance
Nova
MySql
RabbitMQ
KeystoneNeutron
Heat
node failedleader
15
MySql
Heat
X

Leader Failures
• All nodes participate in leader election
• Non-leader nodes watch for leader’s health
• Initiate re-election when leader becomes unavailable
• Leader state (eg: service mapping, etc.) is stored in a Distributed WAL
• New leader restores the previous leader’s state from the Distributed WAL
Cinder
Glance
Nova
MySql
RabbitMQ
KeystoneNeutron
Heat
new leaderXleader
16
Cinder
Nova

Detecting Node Failures
How to differentiate failed vs. disconnected node? You cannot!
• Leader issues service specific leases to each node
• An agent on each node stops service when lease is expired
• Leader refreshes the leases periodically
• Waits for previous lease to expire before starting a service
Glance
MySql
RabbitMQ
KeystoneNeutron
HeatCinder
Nova
leaderperiodic lease refresh
17

Some Implementation Notes
• Use a distributed key-value store for fault-tolerance and Distributed WAL
• Zookeeper, etcd, custom raft based…
• Use service specific Virtual IPs so that host node doesn’t matter
• Expire ARP cache entries
• Use configurable timeouts to adjust responsive-ness
Glance
MySql
RabbitMQ
KeystoneNeutron
Heat
distributed key-value store
Cinder
Nova
18

Key Benefits
• No single point of failure
• High fault tolerance
• No special controller nodes
• Automatic healing
• No manual intervention required
19

Platform HA Summary
High
Availability
Fail-over
manual healing
Leader-based
self-healing
Distributed
control-planeReliable storage
Active-passive
with HAProxy
Replicated
storage
Not suited for Web-scale
Easier to do manually
Designed for Web-scale
Hard to debug manually
20

Demo: HA in Action
• Create a scale-out cloud
• Do some operations
• Kill a node with live services
• Do more operations
21
Users Admins

VM Level HA
Goal: Restart VM with same disks in case of failure
• Key problem: how do you identify a dead VM?
• Network disconnect?
• Not a reliable signal
• VM may still be doing IOs on its disks
• Storage IO disconnect is necessary
• Avoids data corruption in case of two VMs
22

VM Level HA: Solution
• Run agent on host for connectivity check
• Within cluster or to Internet
• In case of disconnection: kill VMs, stop IO access
• In case of host failure: do IPMI shutdown
• Restart the VMs on other hosts in priority order, specified by user
VMV
M
V
M
V
M
V
M V
M
V
MV
M
VM
VMVM VM
host-agent XX
23
VM
VM VM

Application Level HA
• Two kinds of failures
• Infrastructure failures (our focus here)
• Application bugs, hangs
24

Standard Approach
• Run application across multiple availability zones
• Run a load-balancer in front
25
VM VM
VM VM VM
VM VM VM
tier 1
tier 2
tier 3
AZ-east AZ-west
tier 1
tier 2
tier 3
LB
VM VM
VM VM VM
VM VM VM

Problem #1
• No locality within AZ
• Higher latency for inter-tier or inter-VM requests
26
VMVM
VM
VMVM
VM VM
VM
AZ-east
Rack 1 Rack N

Problem #2
• No failure tolerance against within AZ failure
• Rack, power or host failures can take down the app
27
VMVM
VM
VM VM
VM
VM
VM
AZ-east
Rack 1 Rack N
X
X

Solution
• Control on placement
• Use affinity rules within VMs across tiers
• Use anti-affinity rules for VMs within a tier
28
VM VM
VM VM VM
VM VM VM
tier 1
tier 2
tier 3
AZ-east
Affinity within a group
Anti-affinity across
groups

Conclusions
• Current techniques are not sufficient for web-scale
infrastructure
• Key ideas for scalable, automated HA:
• No special nodes, symmetric design
• Automatic healing
• Distributed consensus needed for taking decisions
• VM level HA requires stronger failure detection & isolation
• Use application level HA for better performance and higher
reliability
29