zookeeper futures
TRANSCRIPT

Thursday, 5 November 2009

ZooKeeper FuturesExpanding the Menagerie
Henry RobinsonSoftware engineer @ ClouderaHadoop meetup - 11/5/2009
Thursday, 5 November 2009

Upcoming features for ZooKeeper
▪Observers
▪Dynamic ensembles
▪ZooKeeper in Cloudera’s Distribution for Hadoop
Thursday, 5 November 2009

Observers▪ZOOKEEPER-368
▪ Problem:
▪ Every node in a ZooKeeper cluster has to vote▪ So increasing the cluster size increases the cost of write operations
▪ But increasing the cluster size is the only way currently to get client scalability
▪ False tension between number of clients and performance▪ Should only increase size of voting cluster to improve reliability
Thursday, 5 November 2009

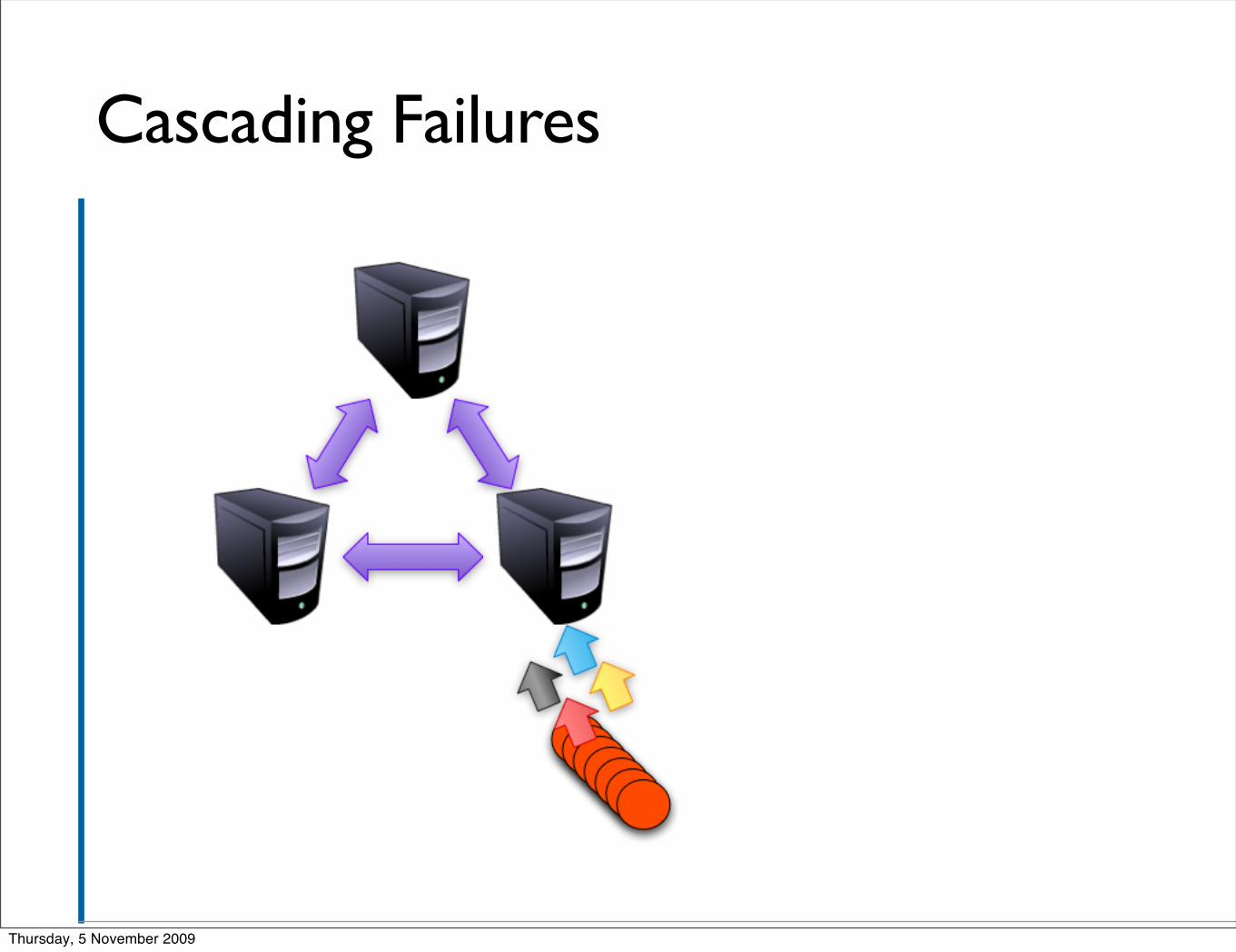
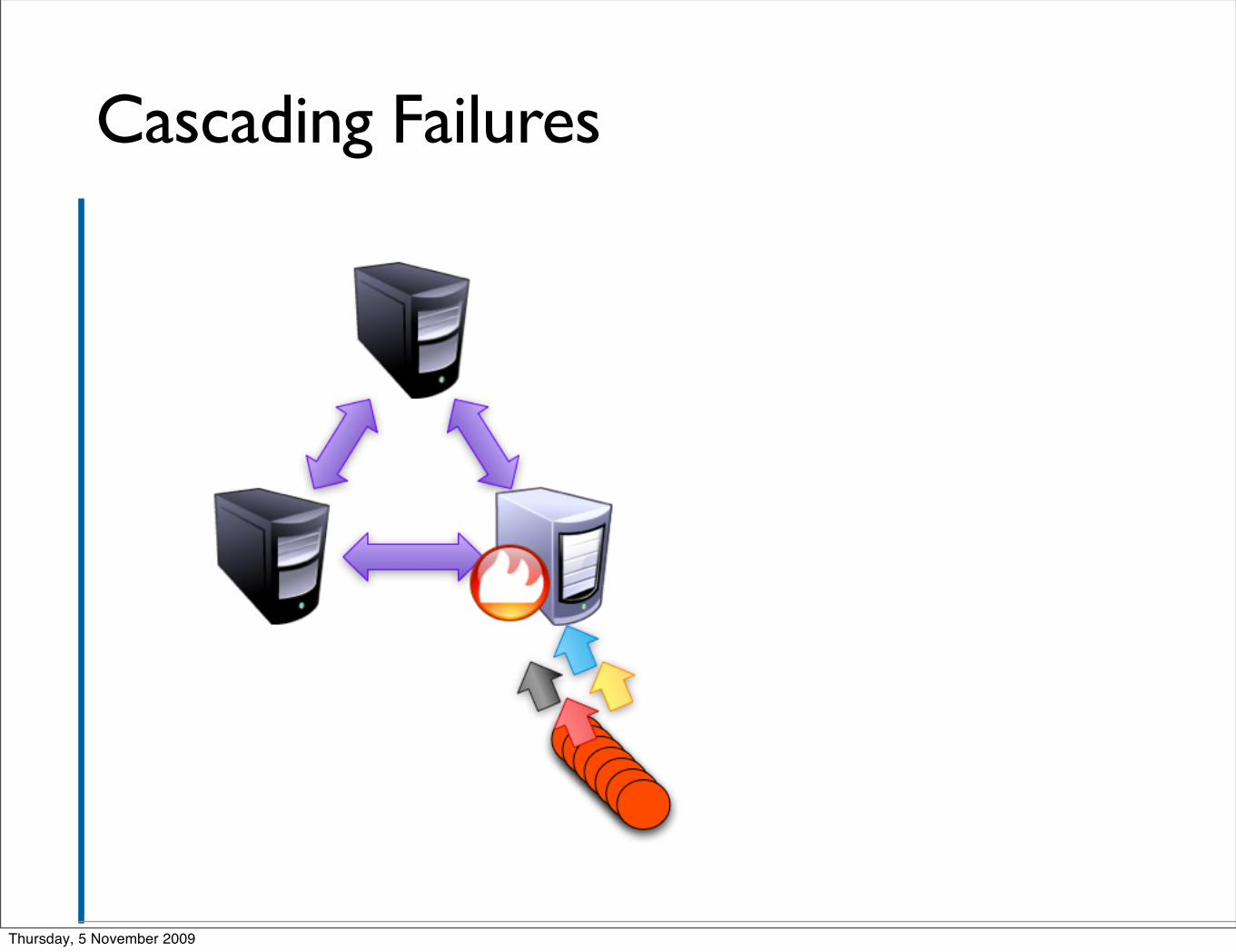
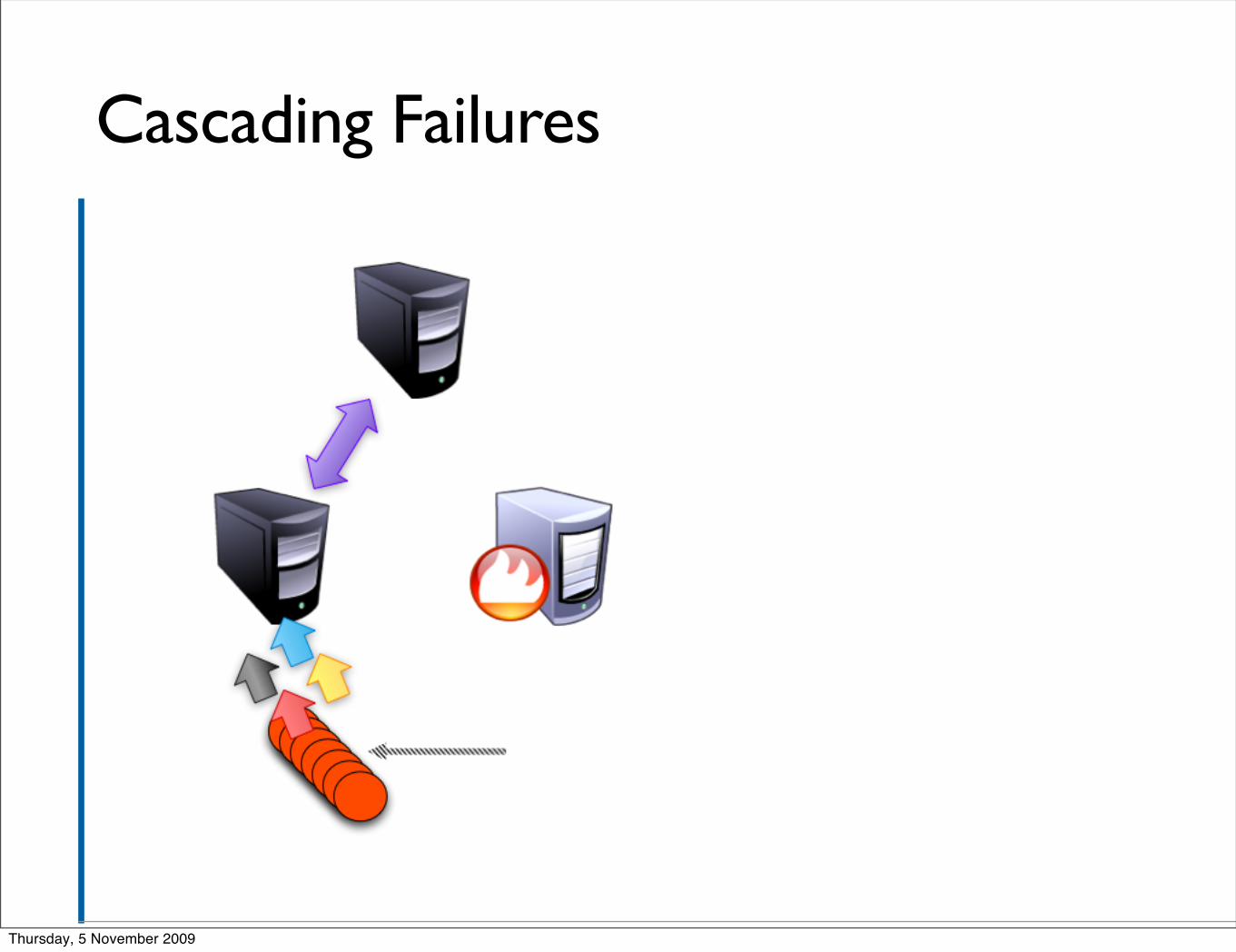
Observers ▪ It’s worse than that
▪ Since clients are given a list of servers in the ensemble to connect to, the cluster is not isolated from swamping due to the number of clients
▪ That is, if a swarm of clients connect to one server and kill it, they’ll move on to another and do the same.
▪ Now we are sharing the same number of clients amongst fewer servers!
▪ So if these were enough clients originally to down a server, the prognosis is not good for those remaining
▪ Only n/2 servers have to die before the cluster is no longer live
Thursday, 5 November 2009
Cascading Failures
Thursday, 5 November 2009
Cascading Failures
Thursday, 5 November 2009
Cascading Failures
Thursday, 5 November 2009

Cascading Failures
Thursday, 5 November 2009

Observers▪ Simple way to attack this problem: non-voting cluster members
▪Act as a fan-in point for client connections by proxying requests to the inner voting ensemble
▪Doesn’t matter if they die (in the sense that liveness is preserved) - cluster is still available for writes
▪Write throughput stays roughly constant as number of Observers increases
▪ So we can freely scale the number of Observers to meet the requirements of the number of clients
Thursday, 5 November 2009

Observers: More benefits▪Voting ensemble members must meet strict latency contracts in order to not be considered ‘failed’
▪Therefore distributing ZooKeeper across many racks, or even datacenters, is problematic.
▪No such requirements made of Observers
▪ So deploy the voting ensemble for reliability and low latency communicaton, and everywhere you need a client, add an Observer
▪Reads get served locally, so wide distribution isn’t too painful for some workloads
▪ Likelihood of partition increases relative to distribution of ensemble, so availability is increased in some cases
▪Good integration point for publish-subscribe, and for specific optimisations
Thursday, 5 November 2009

Observers: Current state▪This patch required a lot of structural work
▪Hoping to get in to 3.3
▪One major refactor patch committed
▪Core patch up on ZOOKEEPER-368
▪ Check it out and add comments!
▪ Fully functional - you can apply the patch, update your configuration and start using Observers today
▪Benchmarks show expected (and pleasing!) performance improvements
▪To come in future JIRAs - performance tweaking (batching)
Thursday, 5 November 2009

Dynamic Ensembles▪ZOOKEEPER-107
▪ Problem:
▪ What if you really do want to change the membership of your cluster?
▪ Downtime is problematic for a ‘highly-available’ service▪ But failures occur and machines get repurposed or upgraded
Thursday, 5 November 2009

Dynamic Ensembles▪We would like to be able to add or remove machines from the cluster without stopping the world
▪Conceptually, this is reasonably easy - we have a mechanism for updating information on every server synchronously, and in order
▪ (it’s called ZooKeeper)
▪ In practice, this is rather involved:
▪ When is a new cluster ‘live’?▪ Who votes on the cluster membership change?▪ How do we deal with slow members?▪ What happens when the leader changes?▪ How do we find the cluster when it’s completely different?
Thursday, 5 November 2009

Dynamic Ensembles▪Getting all this right is hard
▪ (good!)
▪A fundamental change in how ZooKeeper is designed - much of the code is predicated on a static view of the cluster membership
▪ Ideally, we want to prove that the resulting protocol is correct
▪The key observation is that membership changes must be voted upon by both the old and the new configuration
▪ So this is no magic bullet if the cluster is down
▪Need to keep track of old configurations so that each vote can be tallied with the right quorum
Thursday, 5 November 2009

Dynamic Ensembles▪ Lots of discussion on the JIRA
▪ although no public activity for a couple of months
▪ I have code that pretty much works
▪But waiting until Observers gets committed before I move focus completely to this
▪Current situation not *too* bad; there are upgrade workarounds that are a bit scary theoretically but in practice work ok.
Thursday, 5 November 2009

ZooKeeper Packages in CDH▪We maintain Cloudera’s Distribution for Hadoop
▪ Packages for Mapred, HDFS, HBase, Pig and Hive
▪We see ZooKeeper as increasingly important to that stack, as well as having a wide variety of other applications
▪Therefore, we’ve packaged ZooKeeper 3.2.1 and are making it a first class part of CDH
▪We’ll track the Apache releases, and also backport important patches
▪Wrapped up in the service framework:
▪ /sbin/service zookeeper start
▪RPMs and tarballs are done, DEBs to follow imminently
▪Download RPMs at http://archive.cloudera.com/redhat/cdh/unstable/Thursday, 5 November 2009
