1 1998 morgan kaufmann publishers chapter six enhancing performance with pipelining
Post on 19-Dec-2015
219 views
TRANSCRIPT

11998 Morgan Kaufmann Publishers
Chapter Six
Enhancing Performance with Pipelining

21998 Morgan Kaufmann Publishers
Definition
• Pipeline is an implementation technique in which multiple instructions are overlapped in execution.
• We’ll use a laundry analogy for pipelining to explain the main concepts.
• There are four stages in doing the laundry:
– put dirty clothes to the washer (wash)
– placed washed clothes in the dryer (dry)
– place the dry load on the table and fold (fold)
– put clothes away (store)
• What about the MIPS instruction?

31998 Morgan Kaufmann Publishers
Single-Cycle vs Pipelined Performance
• Look at lw, sw, add, sub,and, or, slt and beq.• Operation time for major functional components:
– 200ps for memory access– 200ps for ALU operation– 100ps for register file read or write
• Total execution time for 3 instructions:– 3x800ps=2.4 ns for a single-cycled,non-pipelined processor– 1.4 ns (see Figure in next page) for a pipelined processor
• Total execution time for 1003 instructions:– 1000x800ps + 2400 ps = 802.4 ns for a single-cycled,non-pipelined processor– 1000x200ps + 1400 ps= 201.4 ns for a pipelined processor
• Speedup is less than the number of stages because:– stages may be imperfectly balanced– overhead involved

41998 Morgan Kaufmann Publishers
Pipelining
• Improve performance by increasing instruction throughput
Each instruction still take the same time to execute• Ideal speedup is number of stages in the pipeline. Do we achieve this?
Instructionfetch
Reg ALUData
accessReg
8 nsInstruction
fetchReg ALU
Dataaccess
Reg
8 nsInstruction
fetch
8 ns
Time
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
2 4 6 8 10 12 14 16 18
2 4 6 8 10 12 14
...
Programexecutionorder(in instructions)
Instructionfetch
Reg ALUData
accessReg
Time
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
2 nsInstruction
fetchReg ALU
Dataaccess
Reg
2 nsInstruction
fetchReg ALU
Dataaccess
Reg
2 ns 2 ns 2 ns 2 ns 2 ns
Programexecutionorder(in instructions)

51998 Morgan Kaufmann Publishers
Pipelining in MIPS- What makes it easy
• All instructions are the same length: instruction fetch (1st pipeline stage) and decoding(2nd stage) are much easier
• MIPS has just a few instruction formats, source register field in the same location ==> register file read and instruction decoding can be done at the same time
• Memory operands appear only in loads and stores (as opposed to 80x86, where we could operate on the operands in memory)
• Operands must be aligned in memory: need not worry about a single data transfer instruction requiring two data memory accesses.

61998 Morgan Kaufmann Publishers
Pipelining in MIPS- What makes it hard?
• Structural hazards: suppose we had only one memory
• Control hazards: need to worry about branch instructions
• Data hazards: an instruction depends on a previous instruction

71998 Morgan Kaufmann Publishers
Structural Hazards
• If we have a fourth instruction in the following figure?
• What happens between time 6 and 8 ns?
2 4 6 8 10 12 14
...
P rogramexecutionorder(in instruc tions)
Instructionfetch
Reg ALUData
accessReg
Time
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
2 nsInstruction
fetchReg ALU
Dataaccess
Reg
2 nsInstruction
fetchReg ALU
Dataaccess
Reg
2 ns 2 ns 2 ns 2 ns 2 ns
Programexecutionorder(in instructions)

81998 Morgan Kaufmann Publishers
Control Hazards
• Possible solution:
– stall: to pause before continuing the pipeline, not efficient if we have a long pipeline
– pipeline stall is also known as bubble
Instructionfetch
Reg ALUData
accessReg
Time
beq $1, $2, 40
add $4, $5, $6
lw $3, 300($0)4 ns
Instructionfetch
Reg ALUData
accessReg
2ns
Instructionfetch
Reg ALUData
accessReg
2ns
2 4 6 8 10 12 14 16Programexecutionorder(in instructions)
The above figure assumes that we have extra hardware in place to resolve the branch in the second stage. Otherwise the pause will be
longer than 4ns.

91998 Morgan Kaufmann Publishers
Control Hazards
• Another solution: Predict
Instructionfetch
Reg ALUData
accessReg
Time
beq $1, $2, 40
add $4, $5, $6
lw $3, 300($0)
Instructionfetch
Reg ALUData
accessReg
2 ns
Instructionfetch
Reg ALUData
accessReg
2 ns
Programexecutionorder(in instructions)
Instructionfetch
Reg ALUData
accessReg
Time
beq $1, $2, 40
add $4, $5 ,$6
or $7, $8, $9
Instructionfetch
Reg ALUData
accessReg
2 4 6 8 10 12 14
2 4 6 8 10 12 14
Instructionfetch
Reg ALUData
accessReg
2 ns
4 ns
bubble bubble bubble bubble bubble
Programexecutionorder(in instructions)

101998 Morgan Kaufmann Publishers
Control Hazards
• Delayed branch:
Instructionfetch
Reg ALUData
accessReg
Time
beq $1, $2, 40
add $4, $5, $6
lw $3, 300($0)
Instructionfetch
Reg ALUData
accessReg
2 ns
Instructionfetch
Reg ALUData
accessReg
2 ns
2 4 6 8 10 12 14
2 ns
(Delayed branch slot)
Programexecutionorder(in instructions)

111998 Morgan Kaufmann Publishers
Data Hazards
• Look at the following example:
add $s0, $t0, $t1sub $t2, $s0, $t3
• We need the result $s0 from the add instruction to do the subtraction.
• Is the data ready?
• Compiler cannot handle this issue
• Solution: forwarding or bypassing, i.e., getting the missing item early from the internal resources.

121998 Morgan Kaufmann Publishers
Graphical representation of the instruction pipeline
• IF: instruction fetch
• ID: instruction decode
• EX: execution
• MEM: memory access
• WB: write back
• Shading: element used, White: element not used
• Right-shading: read, Left-Shading: write
Time2 4 6 8 10
add $s0, $t0, $t1 IF ID WBEX MEM

131998 Morgan Kaufmann Publishers
Forwarding
• As soon as ALU add is finished, forward the result
add $s0, $t0, $t1
sub $t2, $s0, $t3
Programexecutionorder(in instructions)
IF ID WBEX
IF ID MEMEX
Time2 4 6 8 10
MEM
WBMEM

141998 Morgan Kaufmann Publishers
Forwarding with stall
• For R-format instruction following a load that tries to use the data, load-use data hazard will occur.
• Need to stall in this case.
Time2 4 6 8 10 12 14
lw $s0, 20($t1)
sub $t2, $s0, $t3
Programexecutionorder(in instructions)
IF ID WBMEMEX
IF ID WBMEMEX
bubble bubble bubble bubble bubble

151998 Morgan Kaufmann Publishers
Reordering Code to Avoid Pipeline Stalls
• Original code:
# register $t1 has the address of v[k]lw $t0, 0($t1) # reg $t0 = v[k]lw $t2, 4($t1) # reg $t1=v[k+1]sw $t2, 0($t1) # v[k] = reg $t2sw $t0, 4($t1) # v[k+1]= reg $t0
• Data hazard occurs on register $t2 between the second lw and the first sw• Modified code removes the hazard
# register $t1 has the address of v[k]lw $t0, 0($t1) # reg $t0 = v[k]lw $t2, 4($t1) # reg $t1=v[k+1]sw $t0, 4($t1) # v[k+1]= reg $t0sw $t2, 0($t1) # v[k] = reg $t2

161998 Morgan Kaufmann Publishers
A Pipelined Datapath
• What do we need to add to actually split the datapath into stages?
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Instruction
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
ReaddataAddress
Datamemory
1
ALUresult
Mux
ALUZero
IF: Instruction fetch ID: Instruction decode/register file read
EX: Execute/address calculation
MEM: Memory access WB: Write back

171998 Morgan Kaufmann Publishers
Pipelined Datapath
Can you find a problem even if there are no dependencies? What instructions can we execute to manifest the problem?
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM MEM/WB
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX
Datamemory
Address

181998 Morgan Kaufmann Publishers
IF Stage
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM MEM/WB
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX
Instruction fetch
lw
Address
Datamemory
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Instruction decode
lw
Address
Datamemory

191998 Morgan Kaufmann Publishers
ID Stage
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM MEM/WB
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX
Instruction fetch
lw
Address
Datamemory
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Instruction decode
lw
Address
Datamemory

201998 Morgan Kaufmann Publishers
EX Stage
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Execution
lw
Address
Datamemory

211998 Morgan Kaufmann Publishers
MEM Stage
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
Datamemory
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Memory
lw
Address
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writedata
ReaddataData
memory
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Write back
lw
Writeregister
Address
97108/Patterson Figure 06.15
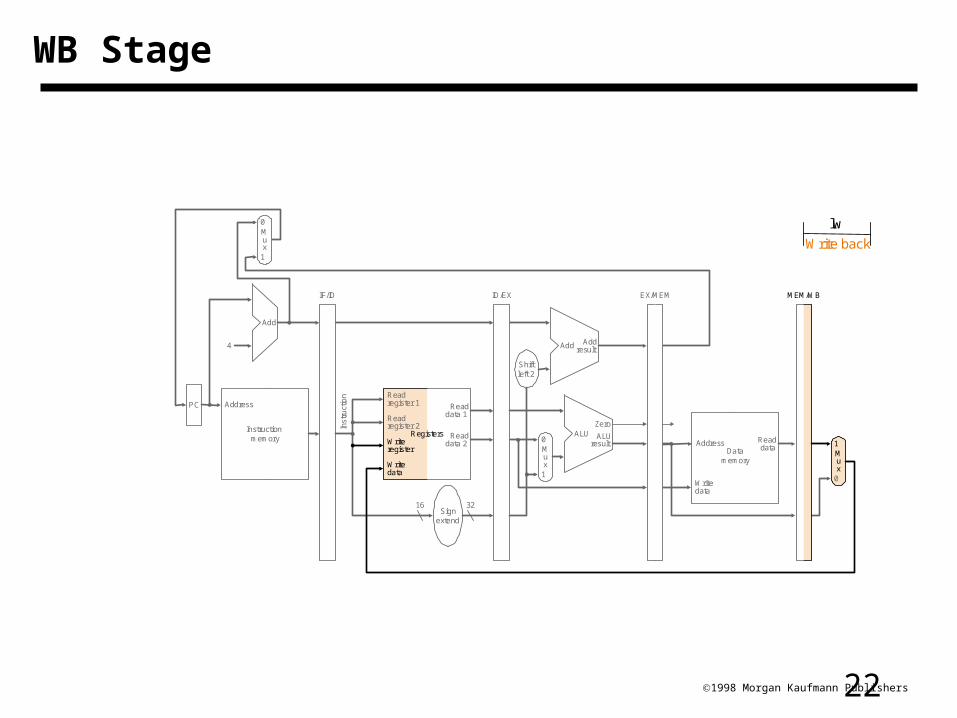
221998 Morgan Kaufmann Publishers
WB Stage
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
Datamemory
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Memory
lw
Address
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writedata
ReaddataData
memory
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Write back
lw
Writeregister
Address
97108/Patterson Figure 06.15

231998 Morgan Kaufmann Publishers
Corrected Datapath
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM MEM/WB
Mux
0
1
Add
PC
0
Address
Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
Datamemory
1
ALUresult
Mux
ALUZero
ID/EX
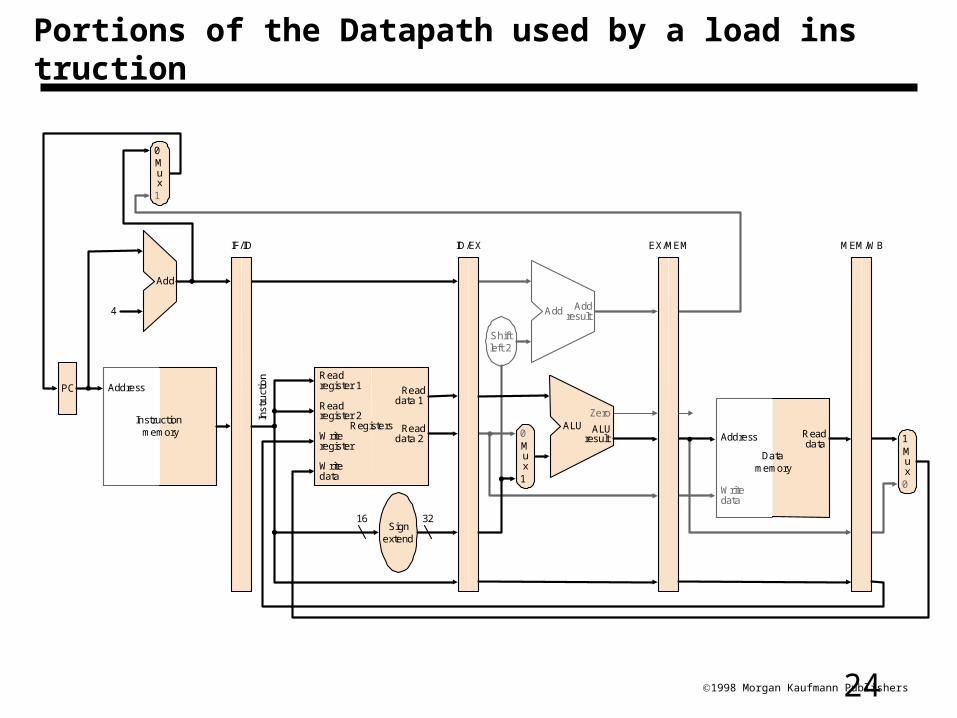
241998 Morgan Kaufmann Publishers
Portions of the Datapath used by a load instruction
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM MEM/WB
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX
Address
Datamemory

251998 Morgan Kaufmann Publishers
Graphically Representing Pipelines
• Can help with answering questions like:
– how many cycles does it take to execute this code?
– what is the ALU doing during cycle 4?
– use this representation to help understand datapaths
IM Reg DM Reg
IM Reg DM Reg
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
lw $10, 20($1)
Programexecutionorder(in instructions)
sub $11, $2, $3
ALU
ALU

261998 Morgan Kaufmann Publishers
Pipeline Control
PC
Instructionmemory
Address
Inst
ruct
ion
Instruction[20– 16]
MemtoReg
ALUOp
Branch
RegDst
ALUSrc
4
16 32Instruction[15– 0]
0
0Registers
Writeregister
Writedata
Readdata 1
Readdata 2
Readregister 1
Readregister 2
Signextend
Mux
1Write
data
Read
data Mux
1
ALUcontrol
RegWrite
MemRead
Instruction[15– 11]
6
IF/ID ID/EX EX/MEM MEM/WB
MemWrite
Address
Datamemory
PCSrc
Zero
AddAdd
result
Shiftleft 2
ALUresult
ALU
Zero
Add
0
1
Mux
0
1
Mux

271998 Morgan Kaufmann Publishers
• We have 5 stages. What needs to be controlled in each stage?– Instruction Fetch and PC Increment– Instruction Decode / Register Fetch– Execution: RegDst, ALUOp, ALUSrc– Memory Stage: Branch, MemRead, MemWrite– Write Back: MemReg, RegWrite
• How would control be handled in an automobile plant?– a fancy control center telling everyone what to do?– should we use a finite state machine?
Pipeline control

281998 Morgan Kaufmann Publishers
• Pass control signals along just like the data
Pipeline Control
Execution/Address Calculation stage control lines
Memory access stage control lines
Write-back stage control
lines
InstructionReg Dst
ALU Op1
ALU Op0
ALU Src Branch
Mem Read
Mem Write
Reg write
Mem to Reg
R-format 1 1 0 0 0 0 0 1 0lw 0 0 0 1 0 1 0 1 1sw X 0 0 1 0 0 1 0 Xbeq X 0 1 0 1 0 0 0 X
Control
EX
M
WB
M
WB
WB
IF/ID ID/EX EX/MEM MEM/WB
Instruction

291998 Morgan Kaufmann Publishers
Datapath with Control
PC
Instructionmemory
Inst
ruct
ion
Add
Instruction[20– 16]
Me
mto
Re
g
ALUOp
Branch
RegDst
ALUSrc
4
16 32Instruction[15– 0]
0
0
Mux
0
1
Add Addresult
RegistersWriteregister
Writedata
Readdata 1
Readdata 2
Readregister 1
Readregister 2
Signextend
Mux
1
ALUresult
Zero
Writedata
Readdata
Mux
1
ALUcontrol
Shiftleft 2
Re
gWrit
e
MemRead
Control
ALU
Instruction[15– 11]
6
EX
M
WB
M
WB
WBIF/ID
PCSrc
ID/EX
EX/MEM
MEM/WB
Mux
0
1
Me
mW
rite
AddressData
memory
Address

301998 Morgan Kaufmann Publishers
• Problem with starting next instruction before first is finished
– dependencies that go backward in time are data hazards
Dependencies
IM Reg
IM Reg
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
sub $2, $1, $3
Programexecutionorder(in instructions)
and $12, $2, $5
IM Reg DM Reg
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9
10 10 10 10 10/– 20 – 20 – 20 – 20 – 20
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)
Value of register $2:
DM Reg
Reg
Reg
Reg
DM

311998 Morgan Kaufmann Publishers
• Type 1.a EX/MEM.RegisterRd= ID/EX.RegisterRs
• Type 1.b EX/MEM.RegisterRd= ID/EX.RegisterRt
• Type 2.a MEM/WB.RegisterRd=ID/EX.RegisterRs
• Type 2.b MEM/WB.RegisterRd=ID/EX.RegisterRt
• Classify the dependencies in the following sequence:
sub $2, $1, $3 # Reg. $2 set by suband $12, $2, $5 # 1st operand ($2)or $13, $6, $2 # 2nd operand ($2)add $14, $2, $2sw $15, 100($2)
• sub-and: Type 1a hazard• sub-or: Type 2b• sub-and: no hazard, sub-sw: no hazard
Hazard Conditions

321998 Morgan Kaufmann Publishers
• Use temporary results, don’t wait for them to be written
– register file forwarding to handle read/write to same register
– ALU forwarding
Forwarding
what if this $2 was $13?
IM Reg
IM Reg
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
sub $2, $1, $3
Programexecution order(in instructions)
and $12, $2, $5
IM Reg DM Reg
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9
10 10 10 10 10/– 20 – 20 – 20 – 20 – 20
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)
Value of register $2 :
DM Reg
Reg
Reg
Reg
X X X – 20 X X X X XValue of EX/MEM :X X X X – 20 X X X XValue of MEM/WB :
DM

331998 Morgan Kaufmann Publishers
Forwarding
PCInstruction
memory
Registers
Mux
Mux
Control
ALU
EX
M
WB
M
WB
WB
ID/EX
EX/MEM
MEM/WB
Datamemory
Mux
Forwardingunit
IF/ID
Inst
ruct
ion
Mux
RdEX/MEM.RegisterRd
MEM/WB.RegisterRd
Rt
Rt
Rs
IF/ID.RegisterRd
IF/ID.RegisterRt
IF/ID.RegisterRt
IF/ID.RegisterRs
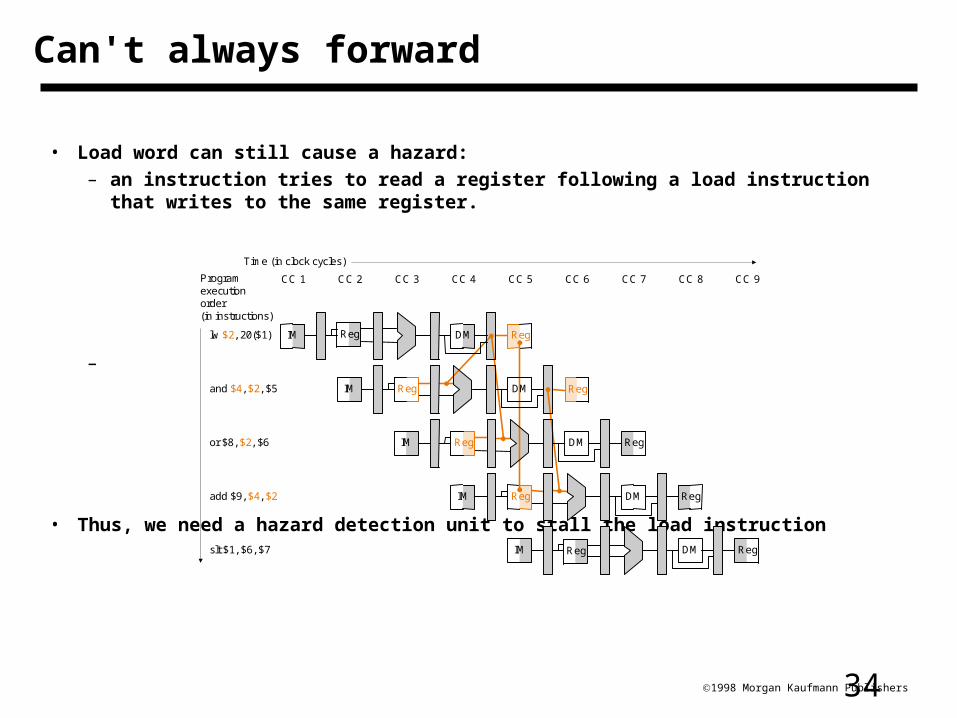
341998 Morgan Kaufmann Publishers
• Load word can still cause a hazard:– an instruction tries to read a register following a load instruction that writes to the
same register.
–
• Thus, we need a hazard detection unit to stall the load instruction
Can't always forward
Reg
IM
Reg
Reg
IM
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
lw $2, 20($1)
Programexecutionorder(in instructions)
and $4, $2, $5
IM Reg DM Reg
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9
or $8, $2, $6
add $9, $4, $2
slt $1, $6, $7
DM Reg
Reg
Reg
DM
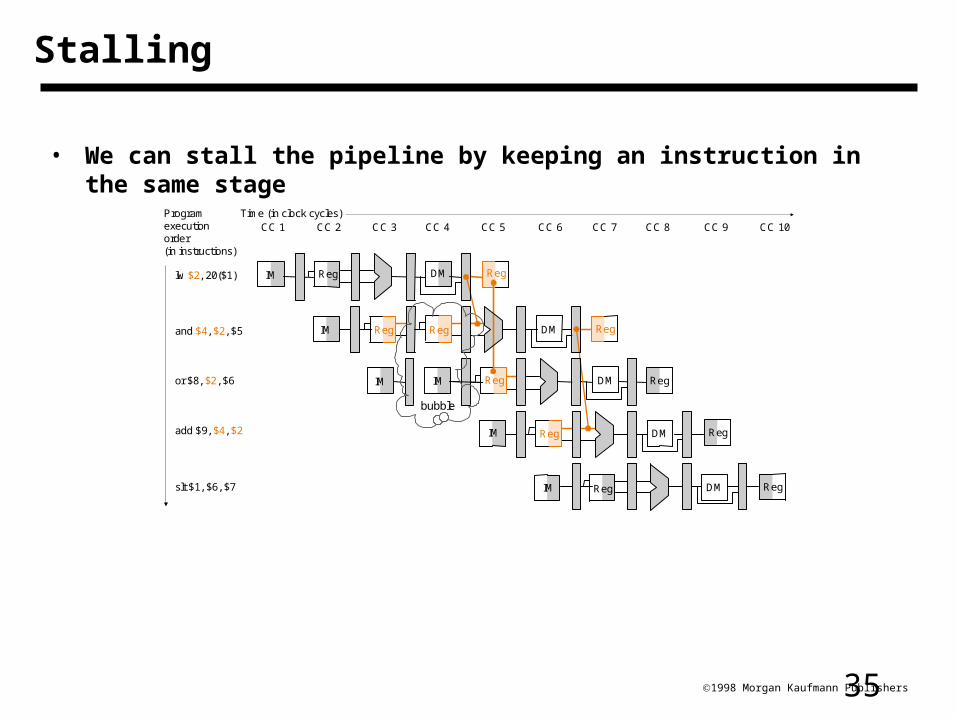
351998 Morgan Kaufmann Publishers
Stalling
• We can stall the pipeline by keeping an instruction in the same stage
lw $2, 20($1)
Programexecutionorder(in instructions)
and $4, $2, $5
or $8, $2, $6
add $9, $4, $2
slt $1, $6, $7
Reg
IM
Reg
Reg
IM DM
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6Time (in clock cycles)
IM Reg DM RegIM
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9 CC 10
DM Reg
RegReg
Reg
bubble

361998 Morgan Kaufmann Publishers
Hazard Detection Unit
• Stall by letting an instruction that won’t write anything go forward
PCInstruction
memory
Registers
Mux
Mux
Mux
Control
ALU
EX
M
WB
M
WB
WB
ID/EX
EX/MEM
MEM/WB
Datamemory
Mux
Hazarddetection
unit
Forwardingunit
0
Mux
IF/ID
Inst
ruct
ion
ID/EX.MemReadIF
/ID
Wri
te
PC
Wri
te
ID/EX.RegisterRt
IF/ID.RegisterRd
IF/ID.RegisterRt
IF/ID.RegisterRt
IF/ID.RegisterRs
RtRs
Rd
Rt EX/MEM.RegisterRd
MEM/WB.RegisterRd

371998 Morgan Kaufmann Publishers
• When we decide to branch, other instructions are in the pipeline!
• We are predicting branch not taken– need to add hardware for flushing instructions if we are wrong
Branch Hazards
Reg
Reg
CC 1
Time (in clock cycles)
40 beq $1, $3, 7
Programexecutionorder(in instructions)
IM Reg
IM DM
IM DM
IM DM
DM
DM Reg
Reg Reg
Reg
Reg
RegIM
44 and $12, $2, $5
48 or $13, $6, $2
52 add $14, $2, $2
72 lw $4, 50($7)
CC 2 CC 3 CC 4 CC 5 CC 6 CC 7 CC 8 CC 9
Reg

381998 Morgan Kaufmann Publishers
Flushing Instructions
PCInstruction
memory
4
Registers
Mux
Mux
Mux
ALU
EX
M
WB
M
WB
WB
ID/EX
0
EX/MEM
MEM/WB
Datamemory
Mux
Hazarddetection
unit
Forwardingunit
IF.Flush
IF/ID
Signextend
Control
Mux
=
Shiftleft 2
Mux

391998 Morgan Kaufmann Publishers
Improving Performance
• Try and avoid stalls! E.g., reorder these instructions:
lw $t0, 0($t1)lw $t2, 4($t1)sw $t2, 0($t1)sw $t0, 4($t1)
• Add a branch delay slot
– the next instruction after a branch is always executed
– rely on compiler to fill the slot with something useful

401998 Morgan Kaufmann Publishers
More on improving performances
• Superpipelining: decompose the stage further (not always practical)• Superscalar: start more than one instruction in the same cycle (extra coordination r
equired)– CPI can be less than 1– IPC: instruction per clock cycle
• Dynamic pipelining:
lw $t0, 20($s2)
addu $t1, $t0, $t2
sub $s4, $s4, $t3
slti $t5, $s4, 20
– Combine extra hardware resources so later instructions can proceed in parallel.– More complicated pipeline control– More complicated instruction execution model

411998 Morgan Kaufmann Publishers
Superscalar MIPS
• Assume two instructions are issued per clock cycle, say one integer ALU operation or branch, the other load or store.
• Need to fetch and decode 64 bits of instruction
• Extra resources are required.

421998 Morgan Kaufmann Publishers
Dynamic Scheduling
• The hardware performs the scheduling?
– hardware tries to find instructions to execute
– out of order execution is possible
– speculative execution and dynamic branch prediction
Commitunit
Instruction fetchand decode unit
…
In-order issue
In-order commit
Load/Store
Floatingpoint
IntegerInteger …Functionalunits
Out-of-order execute
Reservationstation
Reservationstation
Reservationstation
Reservationstation

431998 Morgan Kaufmann Publishers
Real Stuff
• All modern processors are very complicated
– DEC Alpha 21264: 9 stage pipeline, 6 instruction issue
– PowerPC and Pentium: branch history table
– Compiler technology important