1 2004 morgan kaufmann publishers chapter six. 2 2004 morgan kaufmann publishers pipelining the...
Post on 20-Dec-2015
222 views
TRANSCRIPT

12004 Morgan Kaufmann Publishers
Chapter Six

22004 Morgan Kaufmann Publishers
Pipelining
• The laundry analogy

32004 Morgan Kaufmann Publishers
Pipelining
• Improve performance by increasing instruction throughput
Ideal speedup is number of stages in the pipeline. Do we achieve this?
Programexecutionorder(in instructions)
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
Time200 400 600 800 1000 1200 1400 1600 1800
Instructionfetch Reg ALU Data
access Reg
Instructionfetch Reg ALU Data
access Reg
Instructionfetch
800 ps
800 ps
800 ps
Programexecutionorder(in instructions)
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
Time200 400 600 800 1000 1200 1400
Instructionfetch Reg ALU Data
access Reg
Instructionfetch
Instructionfetch
Reg ALU Dataaccess Reg
Reg ALU Dataaccess Reg
200 ps
200 ps
200 ps 200 ps 200 ps 200 ps 200 ps
Note: timing assumptions changedfor this example

42004 Morgan Kaufmann Publishers
Pipelining
• What makes it easy– all instructions are the same length– just a few instruction formats– memory operands appear only in loads and stores
• What makes it hard?– structural hazards: suppose we had only one memory– control hazards: need to worry about branch instructions– data hazards: an instruction depends on a previous instruction
• We’ll build a simple pipeline and look at these issues
• We’ll talk about modern processors and what really makes it hard:– exception handling– trying to improve performance with out-of-order execution, etc.
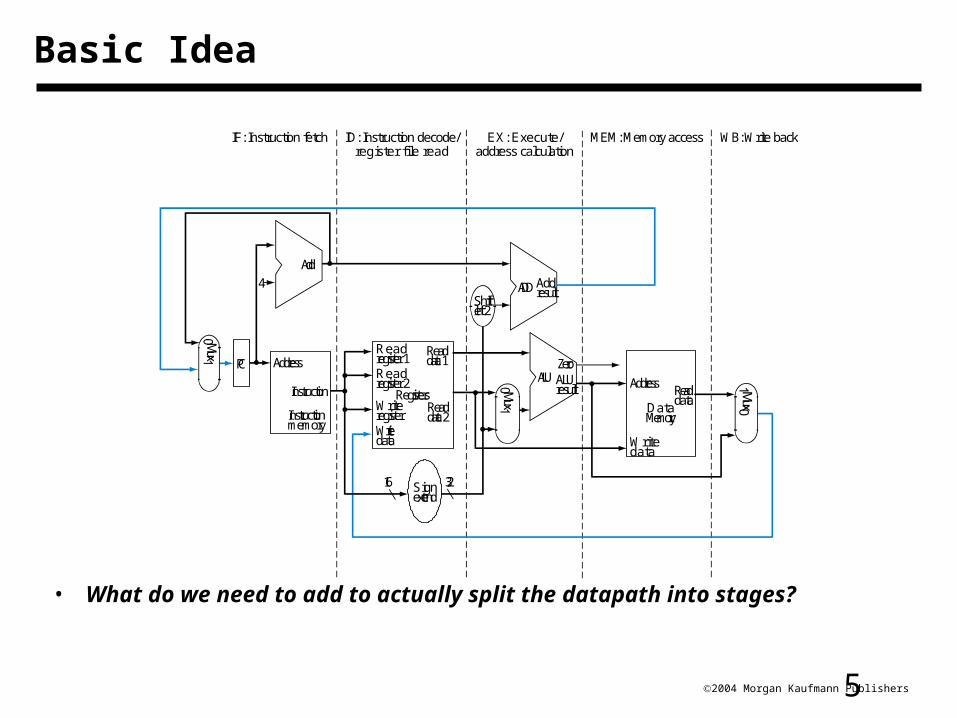
52004 Morgan Kaufmann Publishers
Basic Idea
• What do we need to add to actually split the datapath into stages?
WB: Write backMEM: Memory accessIF: Instruction fetch ID: Instruction decode/register file read
EX: Execute/address calculation
Address
Writedata
Readdata
DataMemory
Readregister 1Readregister 2
WriteregisterWritedata
Registers
Readdata 1
Readdata 2
ALUZeroALUresult
ADDAddresult
Shiftleft 2
Address
Instruction
Instructionmemory
Add
4
PC
Signextend
16 32

62004 Morgan Kaufmann Publishers
Pipelined Datapath
Can you find a problem even if there are no dependencies? What instructions can we execute to manifest the problem?
Add
Address
Instructionmemory
Readregister 1
Readregister 2
Writeregister
Writedata
Readdata 1
Readdata 2
RegistersAddress
Writedata
Readdata
Datamemory
Add Addresult
ALU ALUresult
Zero
Shiftleft 2
Signextend
PC
4
ID/EXIF/ID EX/MEM MEM/WB
16 32

72004 Morgan Kaufmann Publishers
Corrected Datapath
Add
Address
Instructionmemory
Readregister 1
Readregister 2
Writeregister
Writedata
Readdata 1
Readdata 2
RegistersAddress
Writedata
Readdata
Datamemory
Add Addresult
ALU ALUresult
Zero
Shiftleft 2
Signextend
PC
4
ID/EXIF/ID EX/MEM MEM/WB
16 32

82004 Morgan Kaufmann Publishers
Inst. Flow in A Pipelined Datapath: IF & ID Stages

92004 Morgan Kaufmann Publishers
Inst. Flow in A Pipelined Datapath: EX Stage

102004 Morgan Kaufmann Publishers
Inst. Flow in A Pipelined Datapath: MEM & WB Stages

112004 Morgan Kaufmann Publishers
Graphically Representing Pipelines
• Can help with answering questions like:
– how many cycles does it take to execute this code?
– what is the ALU doing during cycle 4?
– use this representation to help understand datapaths
Programexecutionorder(in instructions)
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
Time (in clock cycles)
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6 CC7
IM DMReg RegALU
IM DMReg RegALU
IM DMReg RegALU

122004 Morgan Kaufmann Publishers
Pipeline Control
MemWrite
PCSrc
MemtoReg
MemRead
Add
Address
Instructionmemory
Readregister 1
Readregister 2
Writeregister
Writedata
Instruction(15Ð0)
Instruction(20Ð16)
Instruction(15Ð11)
Readdata 1
Readdata 2
RegistersAddress
Writedata
Readdata
Datamemory
Add Addresult
Add ALUresult
Zero
Shiftleft 2
Signextend
PC
4
ID/EXIF/ID EX/MEM MEM/WB
16 32 6ALU
control
RegDst
ALUOp
ALUSrc
RegWrite
Branch

132004 Morgan Kaufmann Publishers
• We have 5 stages. What needs to be controlled in each stage?
– Instruction Fetch and PC Increment
– Instruction Decode / Register Fetch
– Execution
– Memory Stage
– Write Back
• How would control be handled in an automobile plant?
– a fancy control center telling everyone what to do?
– should we use a finite state machine?
Pipeline control

142004 Morgan Kaufmann Publishers
• Pass control signals along just like the data
Pipeline Control
Execution/Address Calculation stage control lines
Memory access stage control lines
Write-back stage control
lines
InstructionReg Dst
ALU Op1
ALU Op0
ALU Src Branch
Mem Read
Mem Write
Reg write
Mem to Reg
R-format 1 1 0 0 0 0 0 1 0lw 0 0 0 1 0 1 0 1 1sw X 0 0 1 0 0 1 0 Xbeq X 0 1 0 1 0 0 0 X
Control
EX
M
WB
M
WB
WB
IF/ID ID/EX EX/MEM MEM/WB
Instruction

152004 Morgan Kaufmann Publishers
Datapath with Control
WB
M
EX
WB
M WB
PCSrc
MemRead
Add
Address
Instructionmemory
Readregister 1
Readregister 2
Instruction[15–0]
Instruction[20–16]
Instruction[15–11]
Writeregister
Writedata
Readdata 1
Readdata 2
RegistersAddress
Writedata
Readdata
Datamemory
Add Addresult
ALU ALUresult
Zero
Shiftleft 2
Signextend
PC
4
ID/EX
IF/ID
EX/MEM
MEM/WB
16 632ALU
control
RegDst
ALUOp
ALUSrc
Branch
Control

162004 Morgan Kaufmann Publishers
• Problem with starting next instruction before first is finished
– dependencies that “go backward in time” are data hazards
Dependencies
Programexecutionorder(in instructions)
sub $2, $1, $3
and $12, $2, $5
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)
Time (in clock cycles)CC 1 CC 2 CC 3 CC 4 CC 5 CC 6 CC 7 CC 8 CC 9
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg
10 10 10 10 10/–20 –20 –20 –20 –20Value ofregister $2:
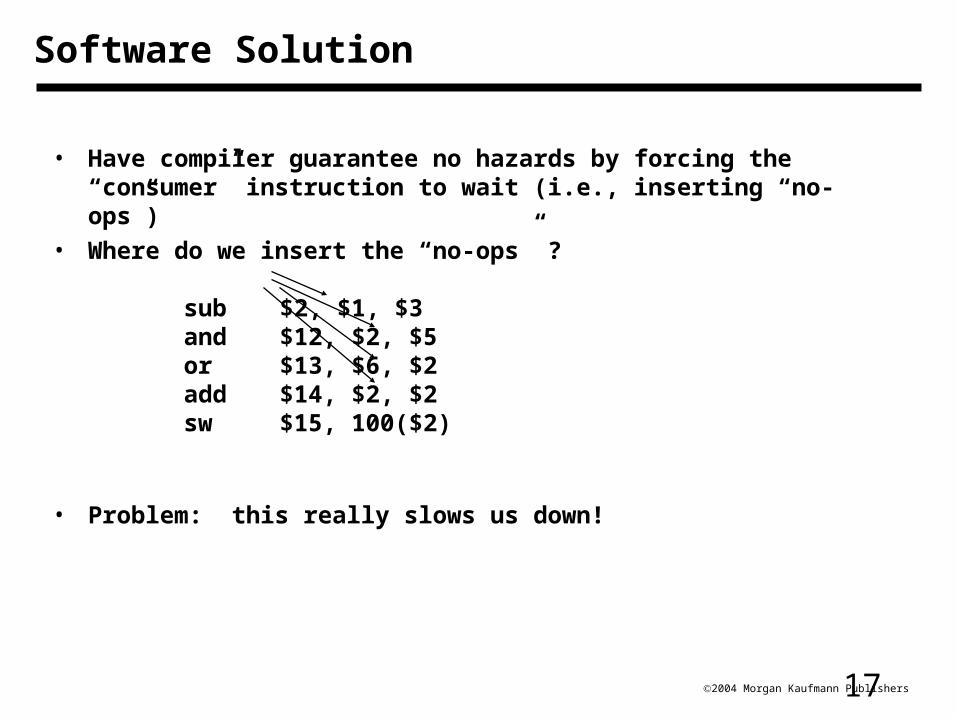
172004 Morgan Kaufmann Publishers
• Have compiler guarantee no hazards by forcing the “consumer” instruction to wait (i.e., inserting “no-ops”)
• Where do we insert the “no-ops” ?
sub $2, $1, $3and $12, $2, $5or $13, $6, $2add $14, $2, $2sw $15, 100($2)
• Problem: this really slows us down!
Software Solution

182004 Morgan Kaufmann Publishers
• Use temporary results, don’t wait for them to be written
– register file forwarding to handle read/write to same register
– ALU forwarding
Forwarding
what if this $2 was $13?
Programexecutionorder(in instructions)
sub $2, $1, $3
and $12, $2, $5
or $13, $6, $2
add $14,$2 , $2
sw $15, 100($2)
Time (in clock cycles)CC 1 CC 2 CC 3 CC 4 CC 5 CC 6 CC 7 CC 8 CC 9
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg
10 10 10 10 10/–20 –20 –20 –20 –20Value of register $2:Value of EX/MEM: X X X –20 X X X X XValue of MEM/WB: X X X X –20 X X X X

192004 Morgan Kaufmann Publishers
Forwarding
• The main idea
1. Detect conditions for
dependencies
(e.g., RdI_earlier =?
RsI_current or RtI_current)
2. If condition true,
select the forward input
of the mux for ALU,
otherwise select the
normal mux input

202004 Morgan Kaufmann Publishers
• Load word can still cause a hazard:– an instruction tries to read a register following a load instruction that writes to the
same register.
• Thus, we need a hazard detection unit to “stall” the load instruction
Can't always forward
Programexecutionorder(in instructions)
lw $2, 20($1)
and $4, $2, $5
or $8, $2, $6
add $9, $4, $2
slt $1, $6, $7
Time (in clock cycles)CC 1 CC 2 CC 3 CC 4 CC 5 CC 6 CC 7 CC 8 CC 9
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg

212004 Morgan Kaufmann Publishers
Stalling
• We can stall the pipeline by keeping an instruction in the same stage
bubble
Programexecutionorder(in instructions)
lw $2, 20($1)
and becomes nop
add $4, $2, $5
or $8, $2, $6
add $9, $4, $2
Time (in clock cycles)CC 1 CC 2 CC 3 CC 4 CC 5 CC 6 CC 7 CC 8 CC 9 CC 10
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg
IM DMReg Reg

222004 Morgan Kaufmann Publishers
Hazard Detection Unit
• Stall by letting an instruction that won’t write anything (i.e. “nop”) go forward
0 M
WB
WB
Datamemory
Instructionmemory
Mux
Mux
Mux
Mux
ALU
ID/EX
EX/MEM
MEM/WB
Forwardingunit
PC
Control
EX
M
WB
IF/ID
Mux
Hazarddetection
unit
ID/EX.MemRead
IF/ID.RegisterRs
IF/ID.RegisterRt
IF/ID.RegisterRt
IF/ID.RegisterRd
ID/EX.RegisterRt
Registers
Rt
Rd
Rs
Rt

232004 Morgan Kaufmann Publishers
• When we decide to branch, other instructions are in the pipeline!
• We are predicting “branch not taken”– need to add hardware for flushing the three instructions already in the
pipeline if we are wrong– Mis-prediction penalty = 3 cycles
Branch Hazards
Reg
Programexecutionorder(in instructions)
40 beq $1, $3, 28
44 and $12, $2, $5
48 or $13, $6, $2
52 add $14, $2, $2
72 lw $4, 50($7)
Time (in clock cycles)CC 1 CC 2 CC 3 CC 4 CC 5 CC 6 CC 7 CC 8 CC 9
IM DMReg Reg
IM DMReg Reg
IM DM Reg
IM DMReg Reg
IM DMReg Reg

242004 Morgan Kaufmann Publishers
Flushing Instructions
Control
Hazarddetection
unit
+
4
PCInstructionmemory
Signextend
Registers=
+
Fowardingunit
ALU
ID/EX
EX/MEM
EX/MEM
WB
M
EX
Shiftleft 2
IF.Flush
IF/ID
Mux
Mux
Mux
Mux
Mux
Mux
Datamemory
WB
WBM
0
Note: we’ve also moved branch decision to ID stage to reduceBranch penalty (from 3 to 1)

252004 Morgan Kaufmann Publishers
Branches
• If the branch is taken, we have a penalty of one cycle• For our simple design, this is reasonable• With deeper pipelines, penalty increases and static branch prediction
drastically hurts performance• Solution: dynamic branch prediction
Predict taken Predict taken
Predict not taken Predict not taken
Not taken
Not taken
Not taken
Not taken
Taken
Taken
Taken
Taken
A 2-bit prediction scheme

262004 Morgan Kaufmann Publishers
Branch Prediction
• Sophisticated Techniques:
– A “branch target buffer” to help us look up the destination
– Correlating predictors that base prediction on global behaviorand recently executed branches (e.g., prediction for a specific
branch instruction based on what happened in previous branches)
– Tournament predictors that use different types of prediction strategies and keep track of which one is performing best.
– A “branch delay slot” which the compiler tries to fill with a useful instruction (make the one cycle delay part of the ISA)
• Branch prediction is especially important because it enables other more advanced pipelining techniques to be effective!
• Modern processors predict correctly 95% of the time!

272004 Morgan Kaufmann Publishers
Improving Performance
• Try and avoid stalls! E.g., reorder these instructions:
lw $t0, 0($t1)lw $t2, 4($t1)sw $t2, 0($t1)sw $t0, 4($t1)
• Dynamic Pipeline Scheduling
– Hardware chooses which instructions to execute next
– Will execute instructions out of order (e.g., doesn’t wait for a dependency to be resolved, but rather keeps going!)
– Speculates on branches and keeps the pipeline full (may need to rollback if prediction incorrect)
• Trying to exploit instruction-level parallelism

282004 Morgan Kaufmann Publishers
Advanced Pipelining
• Increase the depth of the pipeline
• Start more than one instruction each cycle (multiple issue)
• Loop unrolling to expose more ILP (better scheduling)
• “Superscalar” processors
– DEC Alpha 21264: 9 stage pipeline, 6 instruction issue
• All modern processors are superscalar and issue multiple instructions usually with some limitations (e.g., different “pipes”)
• VLIW: very long instruction word, static multiple issue (relies more on compiler technology)
• This class has given you the background you need to learn more!

292004 Morgan Kaufmann Publishers
Chapter 6 Summary
• Pipelining does not improve latency, but does improve throughput
Slower Faster
Instructions per clock (IPC = 1/CPI)
Multicycle(Section 5.5)
Single-cycle(Section 5.4)
Deeplypipelined
Pipelined
Multiple issuewith deep pipeline
(Section 6.10)
Multiple-issuepipelined
(Section 6.9)
1 Several
Use latency in instructions
Multicycle(Section 5.5)
Single-cycle(Section 5.4)
Deeplypipelined
Pipelined
Multiple issuewith deep pipeline
(Section 6.10)
Multiple-issuepipelined
(Section 6.9)