1 anatomy of a high- performance many-threaded matrix multiplication tyler m. smith, robert a. van...
TRANSCRIPT

Anatomy of a High-Performance Many-Threaded
Matrix Multiplication
Tyler M. Smith, Robert A. van de Geijn, Mikhail Smelyanskiy, Jeff Hammond,
Field G. Van Zee

2
Introduction
Shared memory parallelism for GEMMMany-threaded architectures require more
sophisticated methods of parallelism Explore the opportunities for parallelism to
explain which we will exploitNeed finer grain parallelism

Outline
GotoBLAS approach
Opportunities for Parallelism
Many-threaded Results
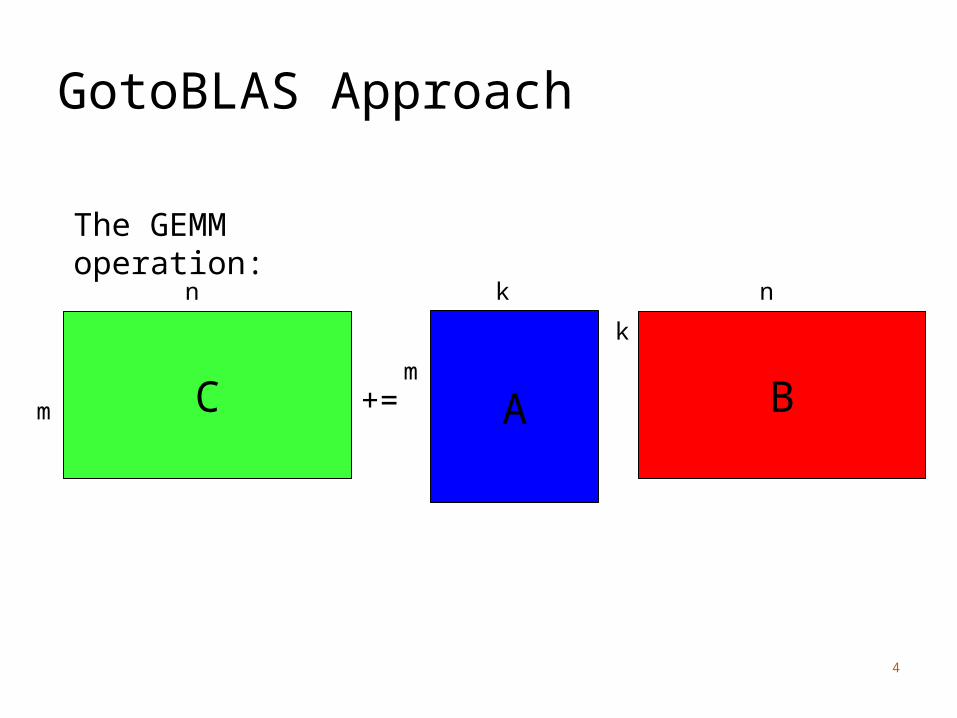
GotoBLAS Approach
+= A BCm
m
n k
k
n
The GEMM operation:
Main Memory
L3 cache
L2 cache
+=
L1 cache
registers
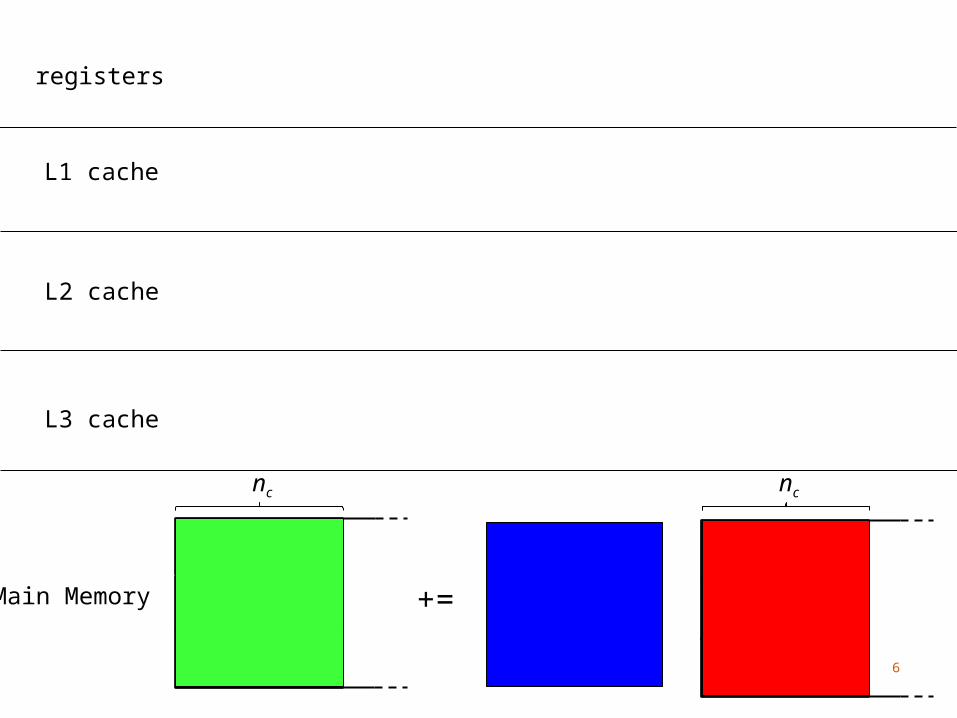
Main Memory
L3 cache
L2 cache
+=
L1 cache
registers
nc nc
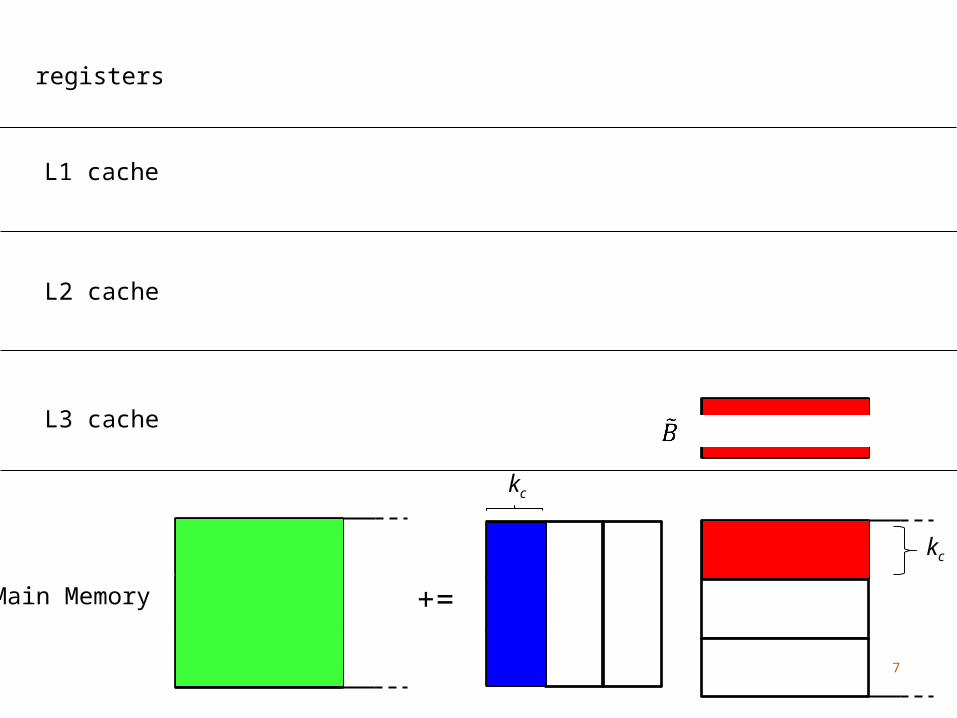
Main Memory
L3 cache
L2 cache
+=
L1 cache
registers
kc
kc
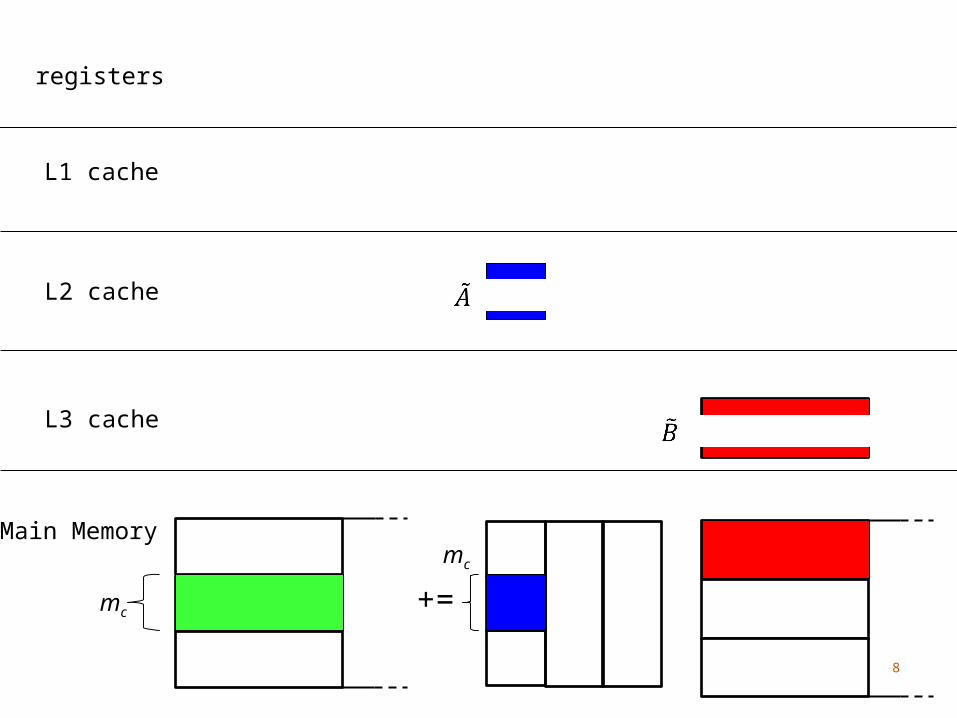
Main Memory
L3 cache
L2 cache
+=
L1 cache
registers
mc
mc
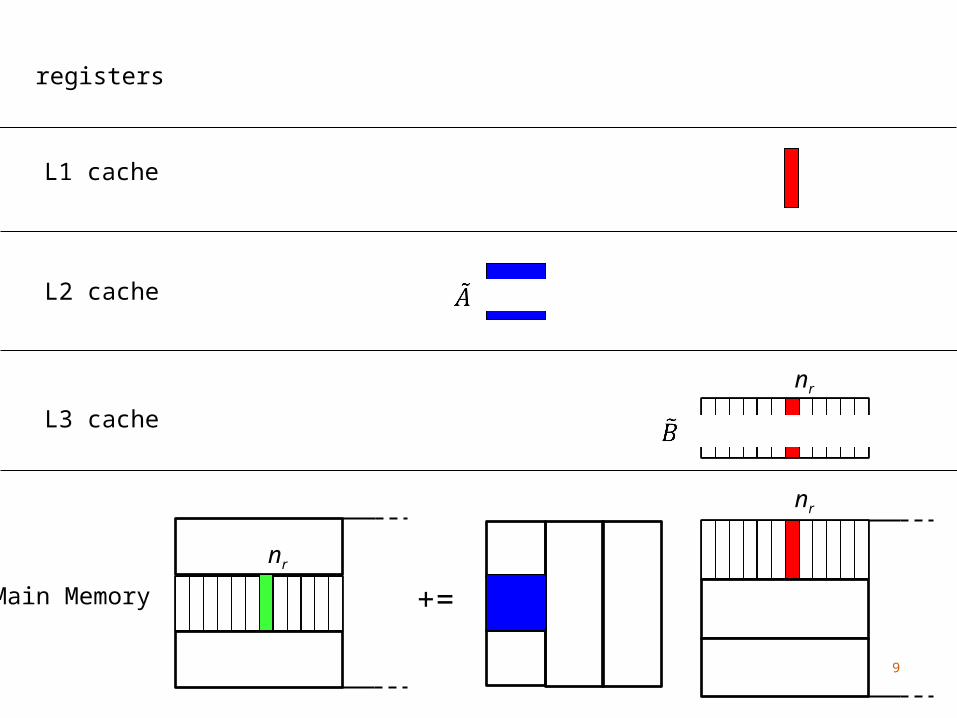
Main Memory
L3 cache
L2 cache
+=
L1 cache
registers
nr
nr
nr
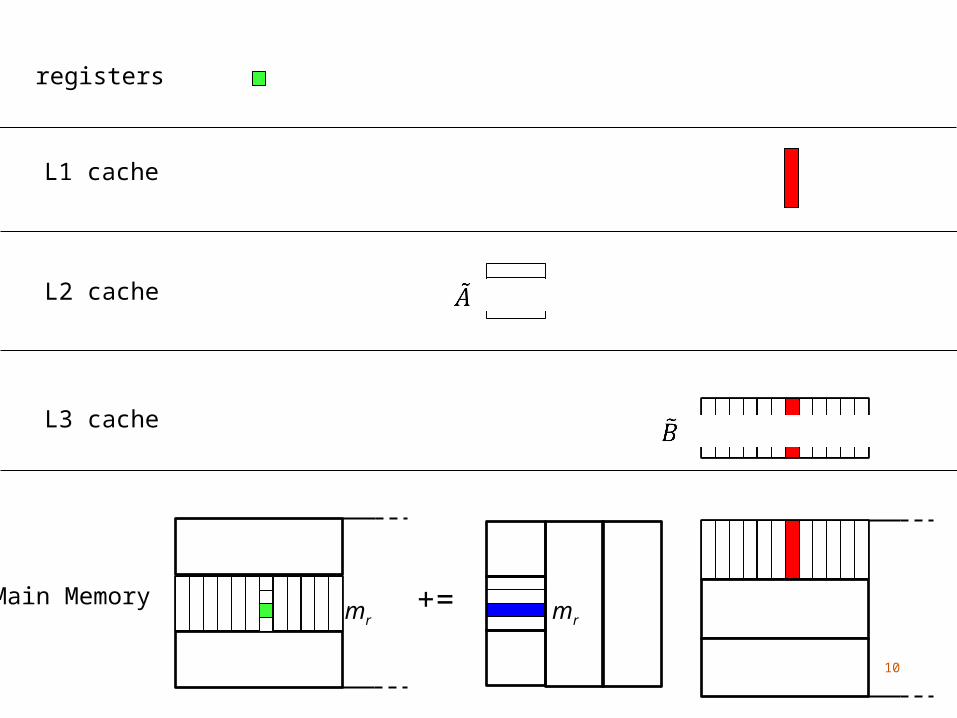
Main Memory
L3 cache
L2 cache
+=
L1 cache
registers
mr mr

11
Outline
GotoBLAS approach
Opportunities for Parallelism
Many-threaded Results
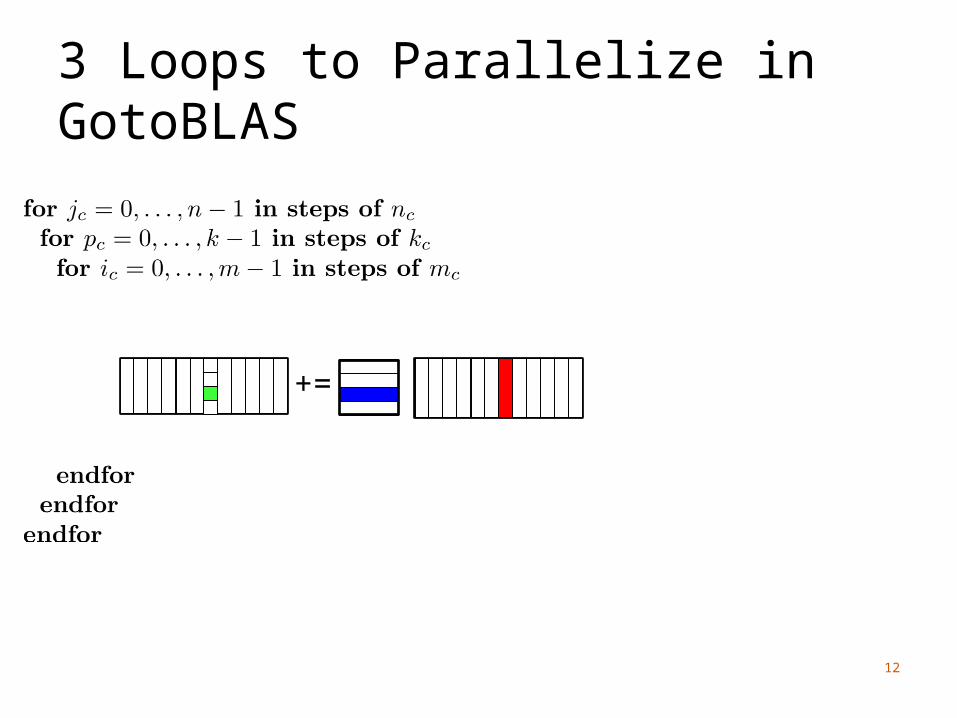
3 Loops to Parallelize in GotoBLAS
+=

5 Opportunities for Parallelism
+=
14
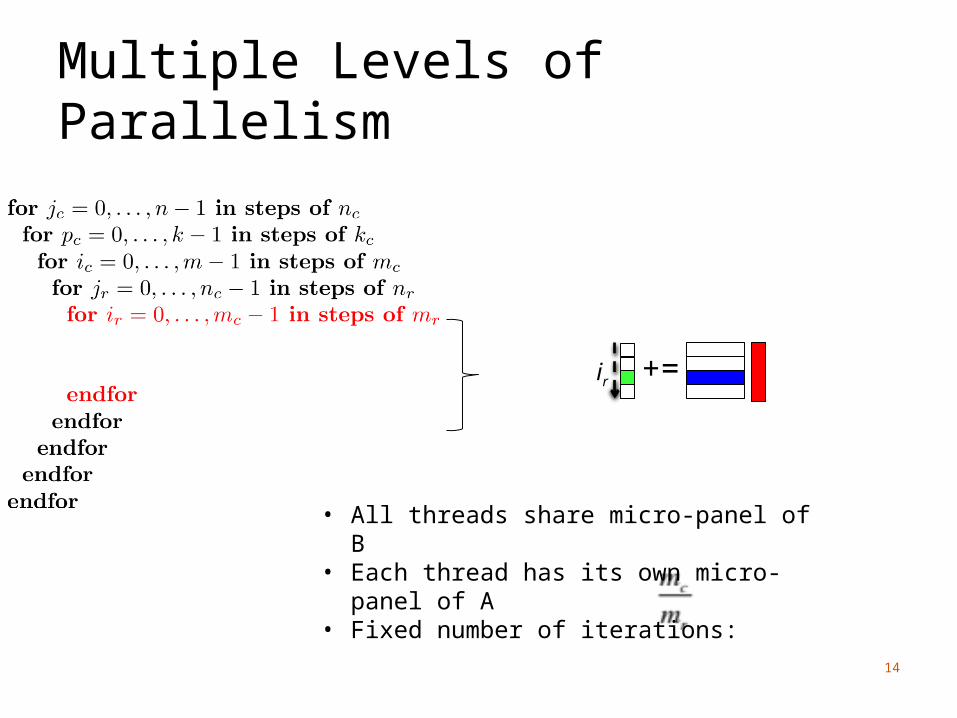
Multiple Levels of Parallelism
ir +=
• All threads share micro-panel of B• Each thread has its own micro-panel of A• Fixed number of iterations:
15
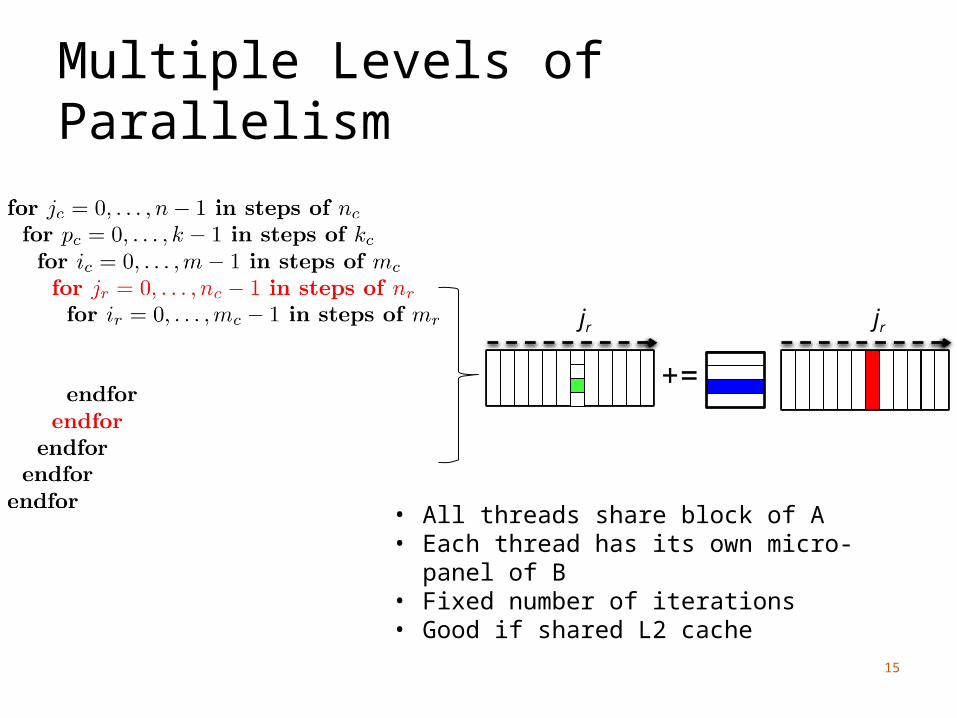
Multiple Levels of Parallelism
+=
jr jr
• All threads share block of A• Each thread has its own micro-panel of B• Fixed number of iterations• Good if shared L2 cache
16
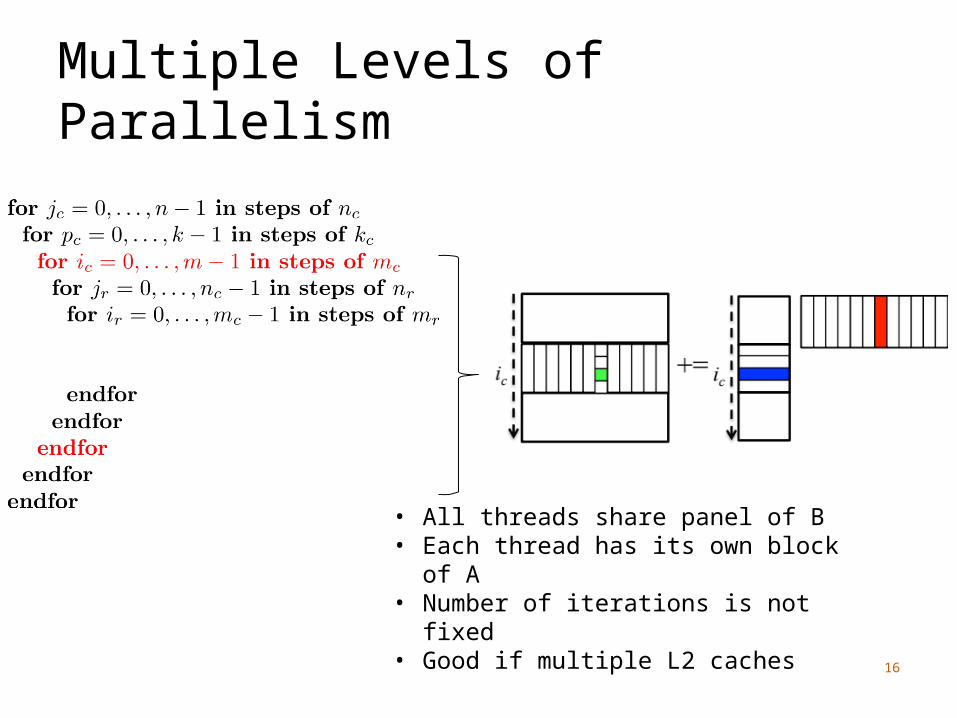
Multiple Levels of Parallelism
• All threads share panel of B• Each thread has its own block of A• Number of iterations is not fixed• Good if multiple L2 caches
17
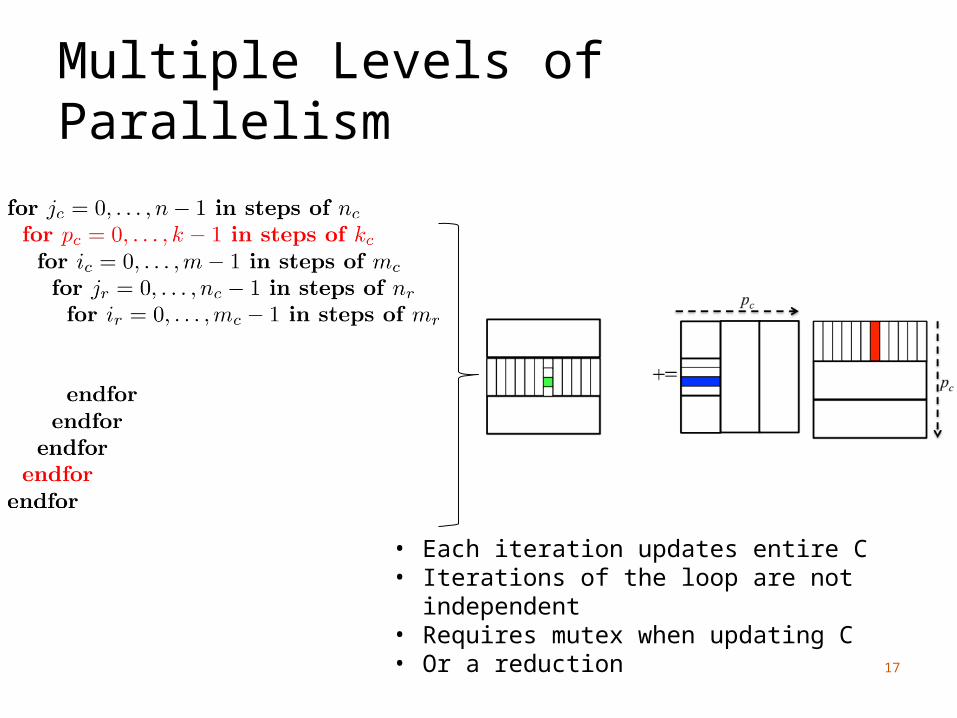
Multiple Levels of Parallelism
• Each iteration updates entire C• Iterations of the loop are not independent• Requires mutex when updating C• Or a reduction
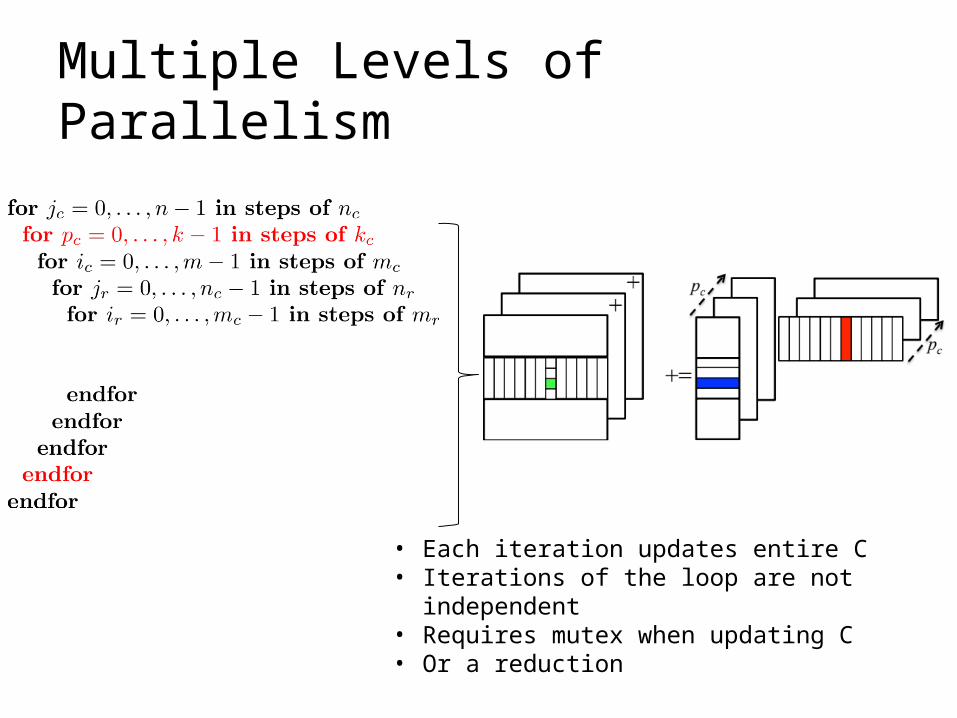
Multiple Levels of Parallelism
• Each iteration updates entire C• Iterations of the loop are not independent• Requires mutex when updating C• Or a reduction
19
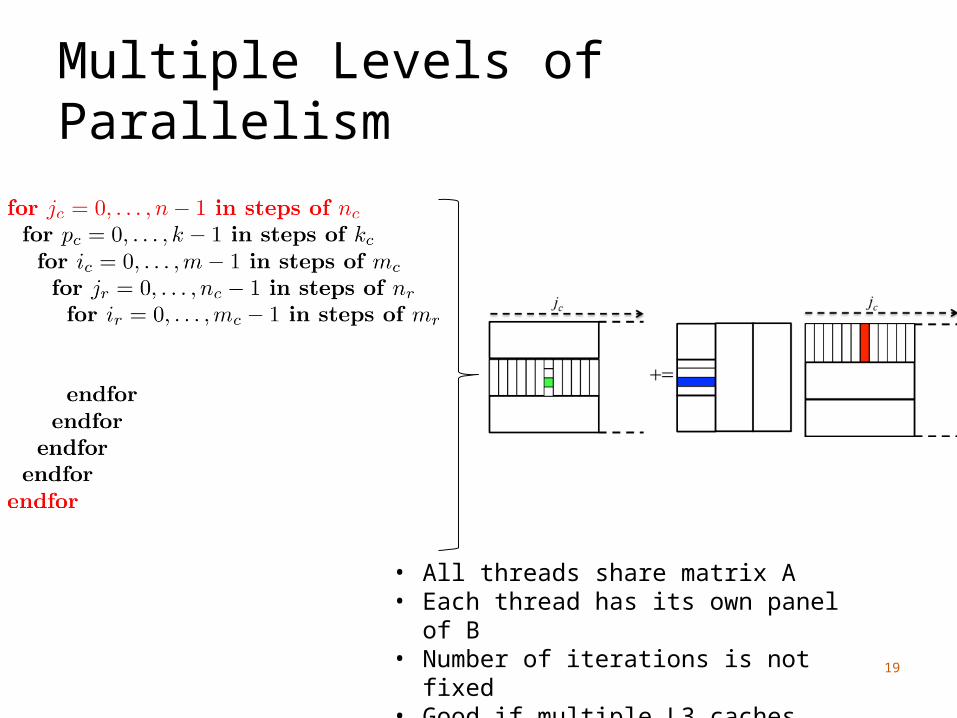
Multiple Levels of Parallelism
• All threads share matrix A• Each thread has its own panel of B• Number of iterations is not fixed• Good if multiple L3 caches• Good for NUMA reasons

20
Outline
GotoBLAS approach
Opportunities for Parallelism
Many-threaded Results

Intel Xeon Phi
Many Threads60 cores, 4 threads per coreNeed to use > 2 threads per core to utilize FPU
We do not block for the L1 cacheDifficult to amortize the cost of updating C with
4 threads sharing an L1 cacheWe consider part of the L2 cache as a virtual L1
Each core has its own L2 cache
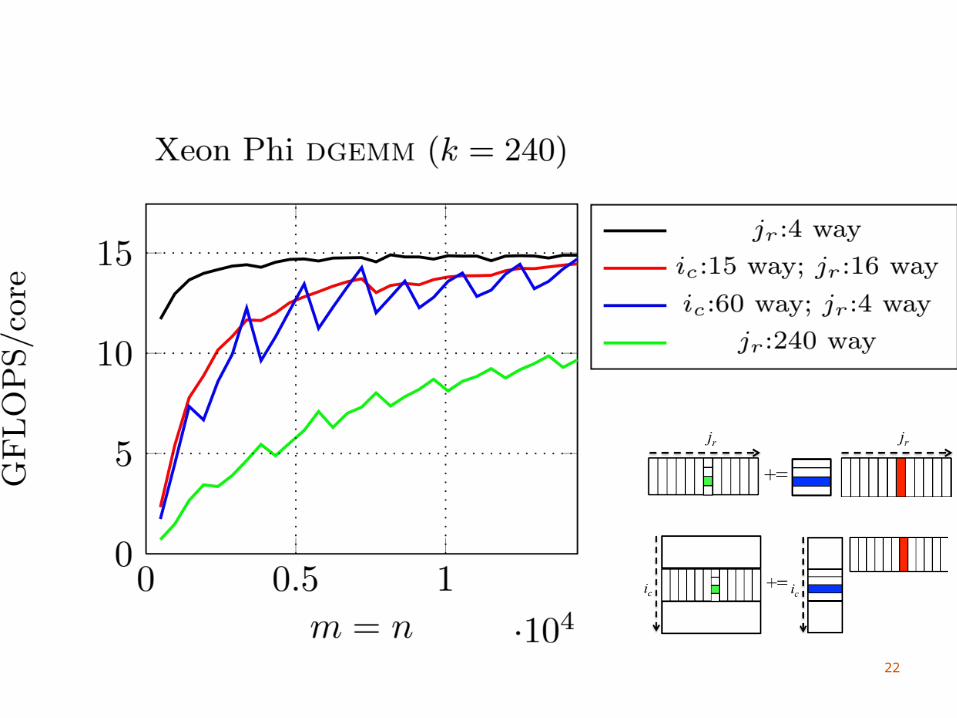
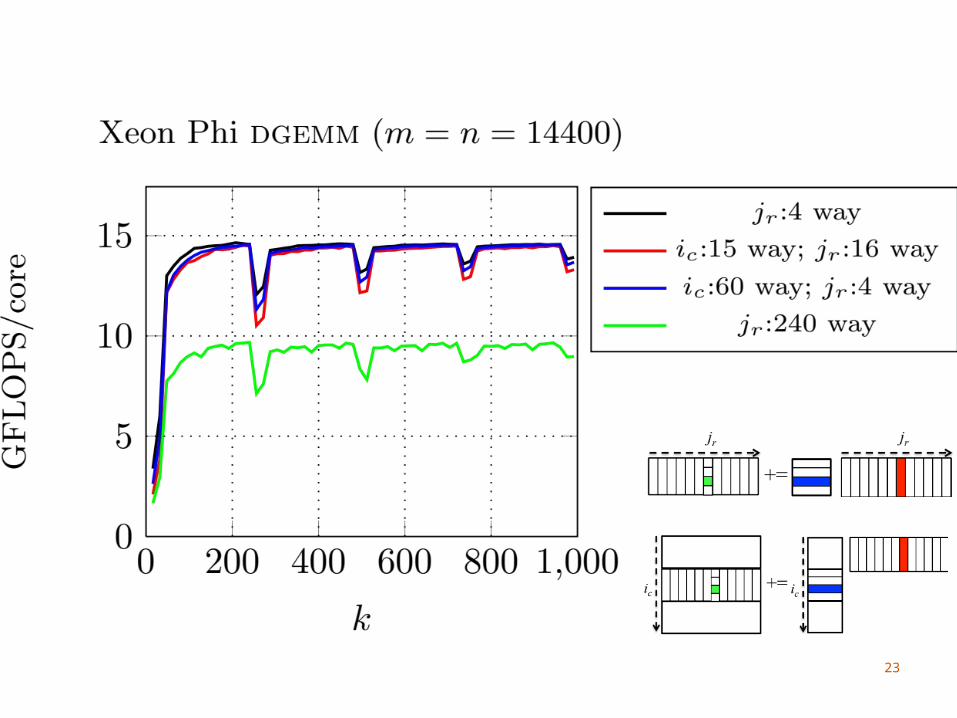
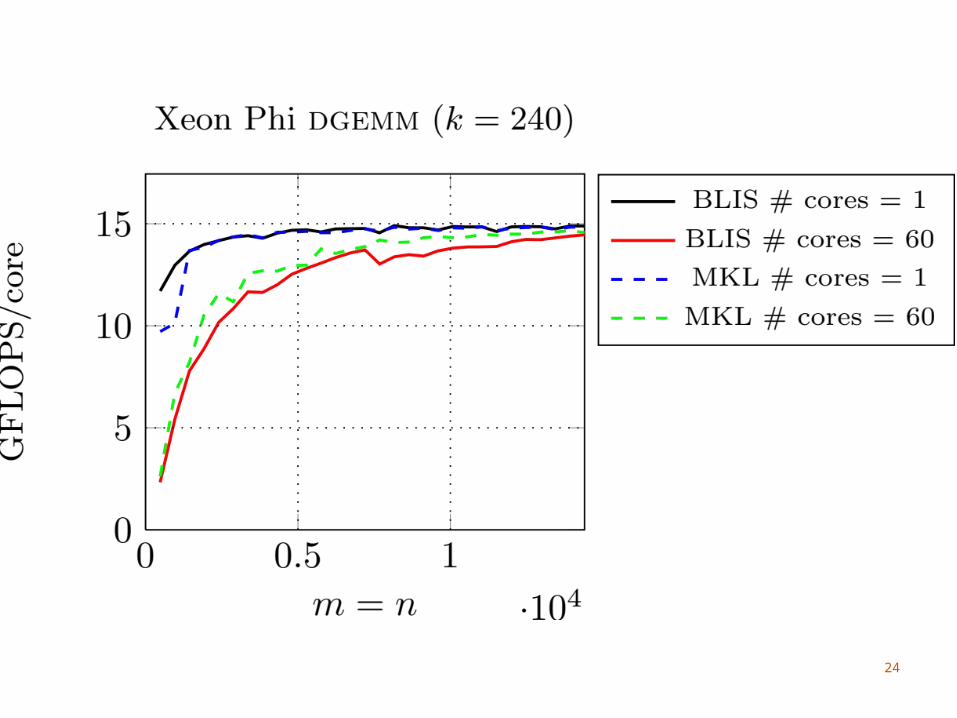
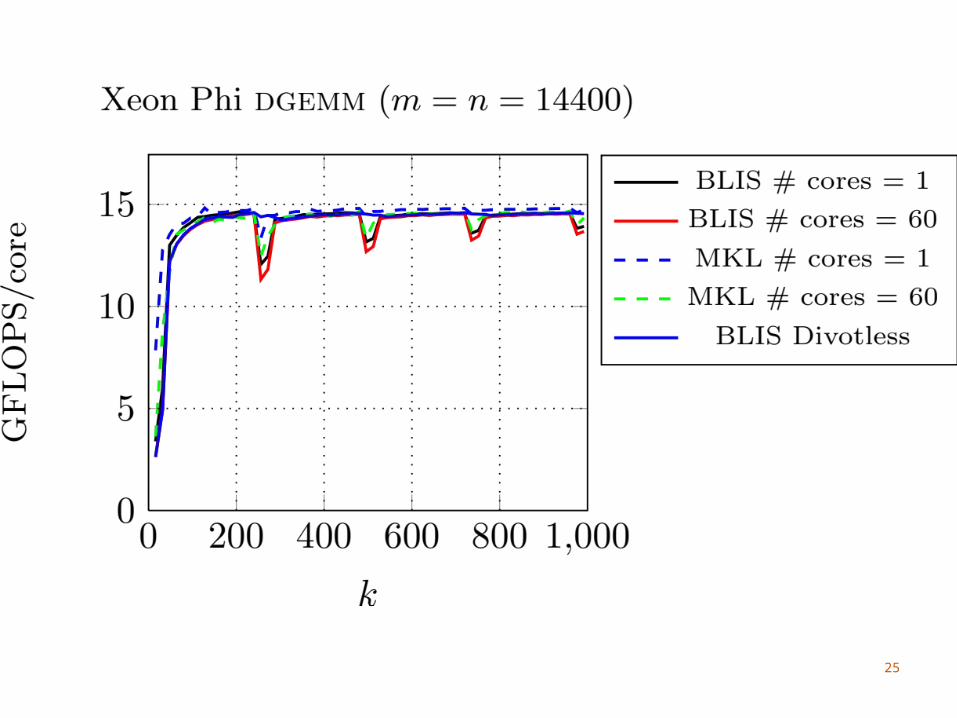

26
IBM Blue Gene/Q
(Not quite as) Many Threads16 cores, 4 threads per coreNeed to use > 2 threads per core to utilize FPU
We do not block for the L1 cacheDifficult to amortize the cost of updating C with
4 threads sharing an L1 cacheWe consider part of the L2 cache as a virtual L1
Single large, shared L2 cache
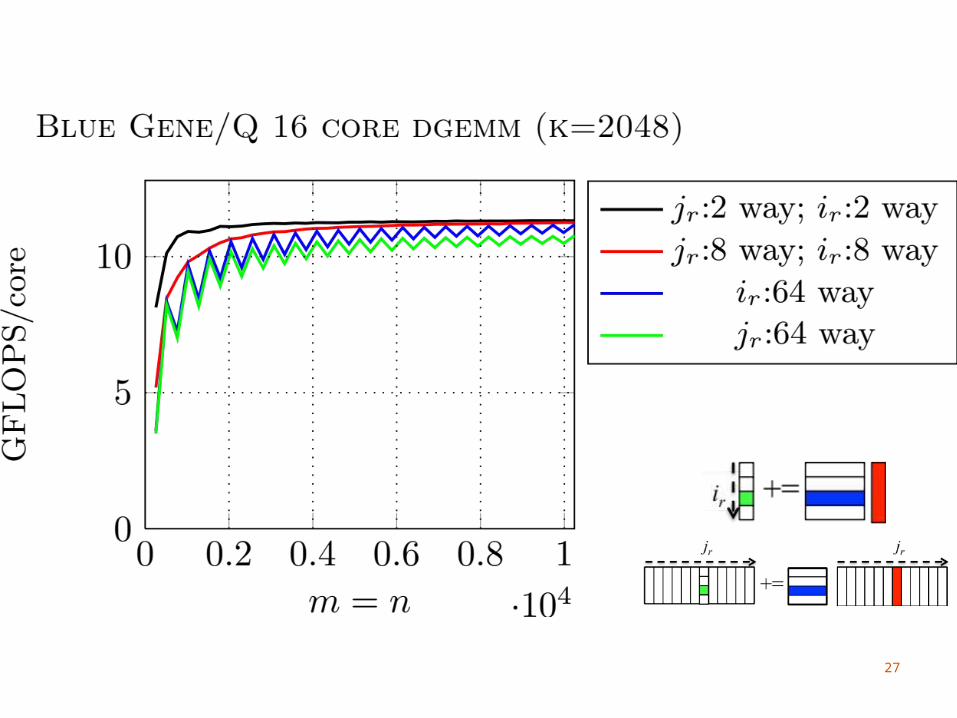
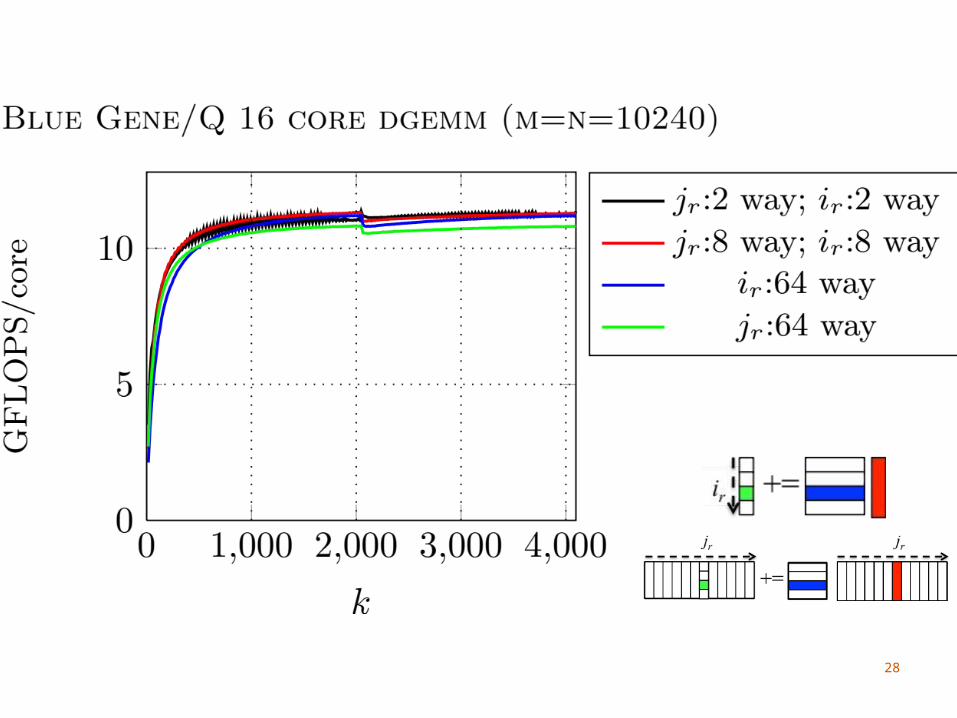
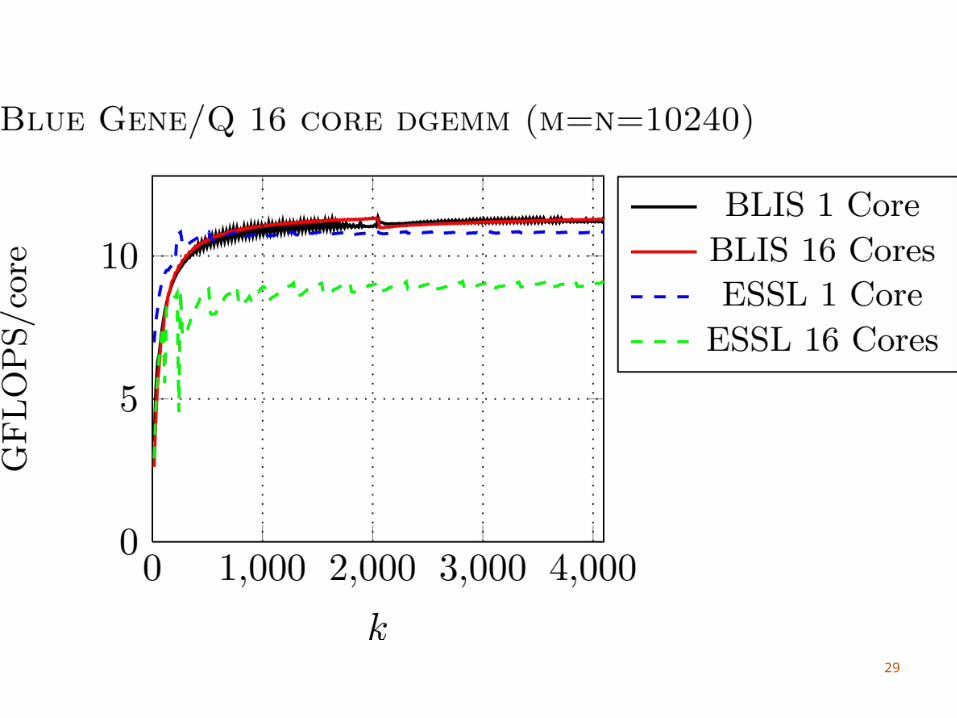
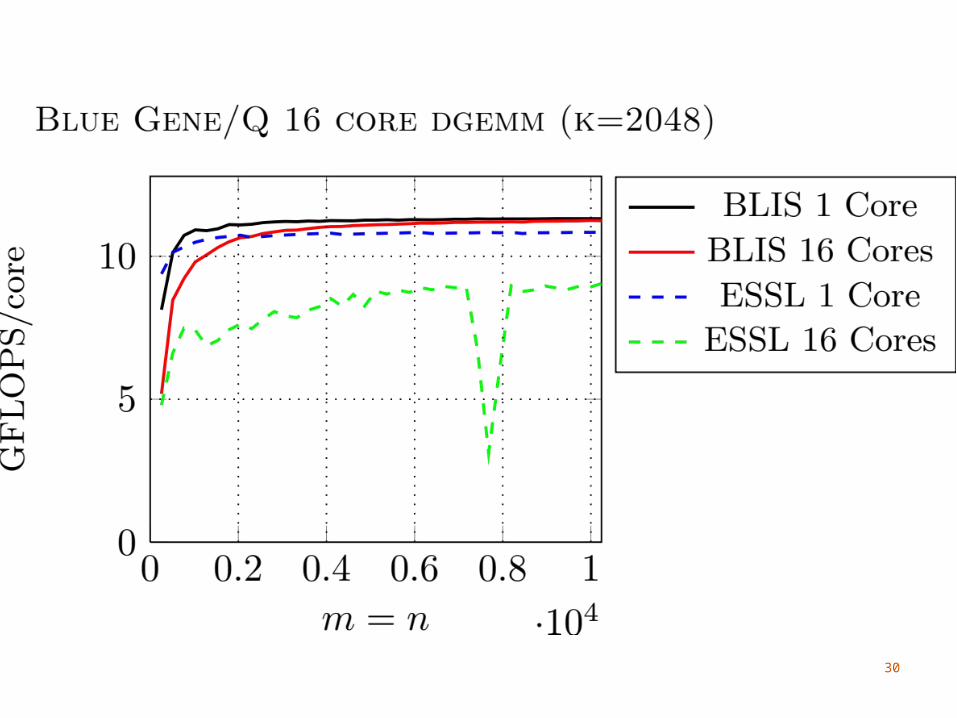
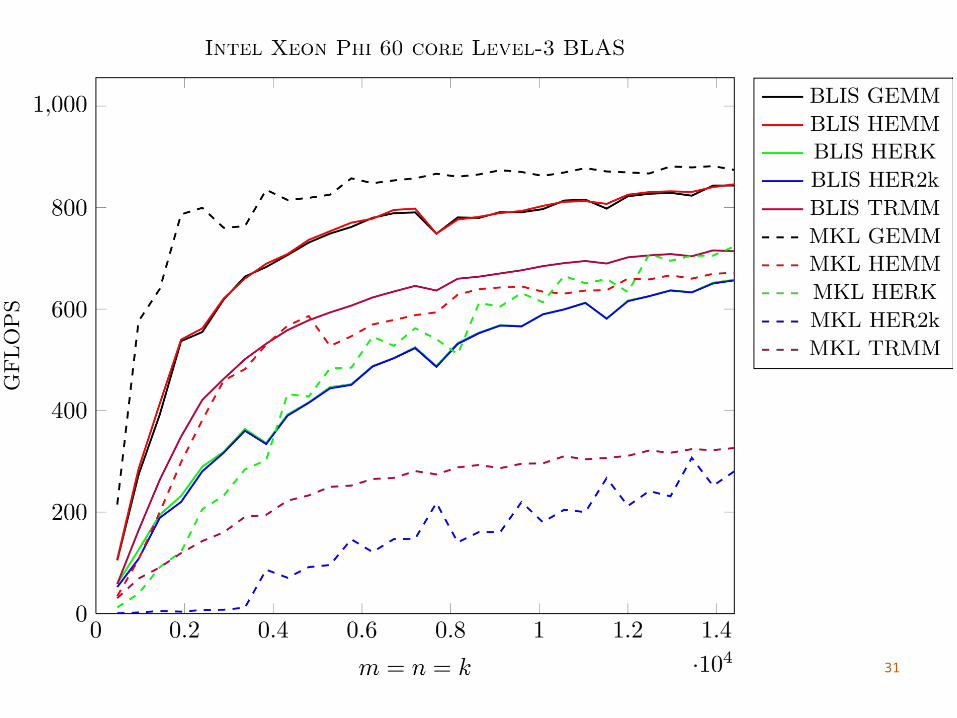
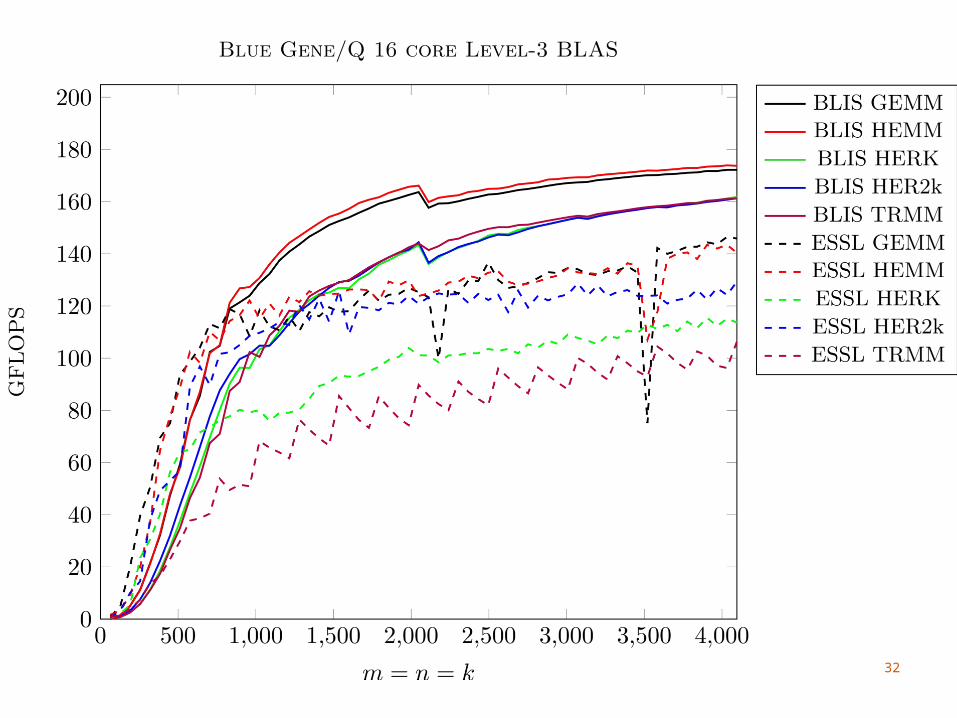

33
Thank You
Questions?Source code available at:
code.google.com/p/blis/