1 computational tools for linguists inderjeet mani georgetown university [email protected]
TRANSCRIPT


2
Topics
Computational tools for
- manual and automatic annotation of linguistic data
- exploration of linguistic hypotheses
Case studies
Demonstrations and training
Inter-annotator reliability
Effectiveness of annotation scheme
Costs and tradeoffs in corpus preparation

3
Outline
Topics
- Concordances
- Data sparseness
- Chomsky’s Critique
- Ngrams
- Mutual Information
- Part-of-speech tagging
- Annotation Issues
- Inter-Annotator Reliability
- Named Entity Tagging
- Relationship Tagging
Case Studies
- metonymy
- adjective ordering
- Discourse markers: then
- TimeML

4
Corpus Linguistics
Use of linguistic data from corpora to test linguistic hypotheses => emphasizes language use
Uses computers to do the searching and counting from on-line material
- Faster than doing it by hand! Check?
Most typical tool is a concordancer, but there are many others!
Tools can analyze a certain amount, rest is left to human!
Corpus Linguistics is also a particular approach to linguistics, namely an empiricist approach
- Sometimes (extreme view) opposed to the rationalist approach, at other times (more moderate view) viewed as complementary to it
- Cf. Theoretical vs. Applied Linguistics

5
Empirical Approaches in Computational Linguistics
Empiricism – the doctrine that knowledge is derived from experience
Rationalism: the doctrine that knowledge is derived from reason
Computational Linguistics is, by necessity, focused on ‘performance’, in that naturally occurring linguistic data has to be processed
- Naturally occurring data is messy! This means we have to process data characterized by false starts, hesitations, elliptical sentences, long and complex sentences, input that is in a complex format, etc.
The methodology used is corpus-based
- linguistic analysis (phonological, morphological, syntactic, semantic, etc.) carried out on a fairly large scale
- rules are derived by humans or machines from looking at phenomena in situ (with statistics playing an important role)

6
Example: metonymy
Metonymy: substituting the name of one referent for another
- George W. Bush invaded Iraq
- A Mercedes rear-ended me
Is metonymy involving institutions as agents more common in print news than in fiction?
- “The X Vreporting”
Let’s start with: “The X said”
- This pattern will provide a “handle” to identify the data

Page 7
Exploring Corpora
Datasetshttp://complingtwo.georgetown.edu/cgi-bin/gwilson/bin/
DataSets.cgi
Metonymy Test using Corporahttp://complingtwo.georgetown.edu/~gwilson/Tools/Metonymy/
TheXSaid_MST.html
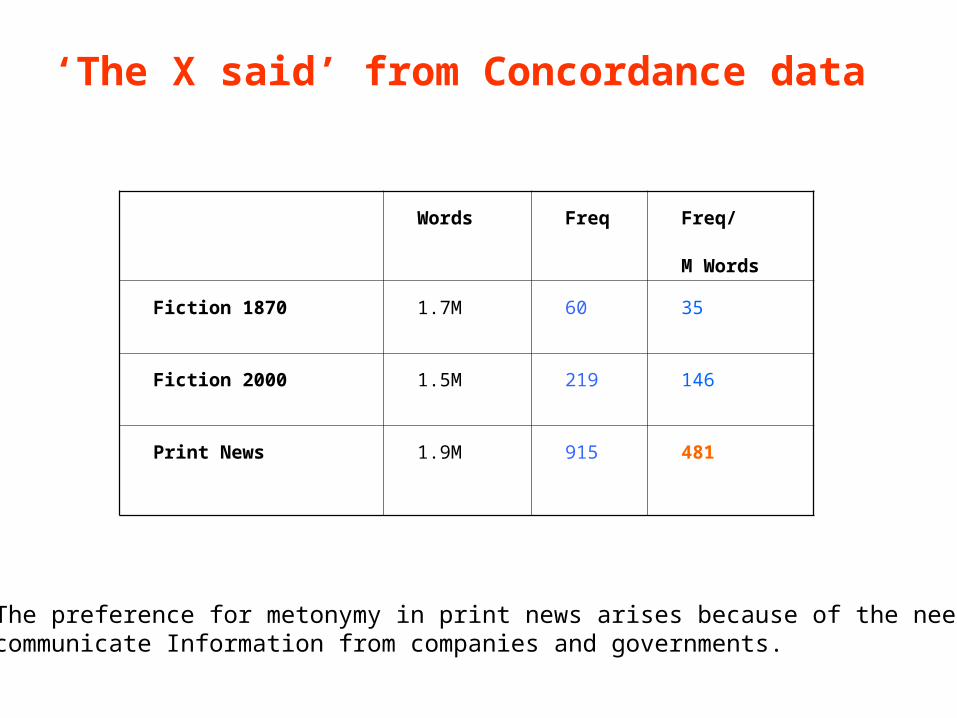
8
‘The X said’ from Concordance data
Words Freq Freq/
M Words
Fiction 1870 1.7M 60 35
Fiction 2000 1.5M 219 146
Print News 1.9M 915 481
The preference for metonymy in print news arises because of the need to communicate Information from companies and governments.

9
Chomsky’s Critique of Corpus-Based Methods
1. Corpora model performance, while linguistics is aimed at the explanation of competence
If you define linguistics that way, linguistic theories will never be able to deal with actual, messy data
Many linguists don’t find the competence-performance distinction to be clear-cut. Sociolinguists have argued that the variability of linguistic performance is systematic, predictable, and meaningful to speakers of a language.
Grammatical theories vary in where they draw the line between competence and performance, with some grammars (such as Halliday’s Systemic Grammar) organized as systems of functionally-oriented choices.

10
Chomsky’s Critique (concluded)
2. Natural language is in principle infinite, whereas corpora are finite, so many examples will be missed
Excellent point, which needs to be understood by anyone working with a corpus.
But does that mean corpora are useless? Introspection is unreliable (prone to performance factors,
cf. only short sentences), and pretty useless with child data.
Also, insights from a corpus might lead to generalization/induction beyond the corpus– if the corpus is a good sample of the “text population”
3. Ungrammatical examples won’t be available in a corpusDepends on the corpus, e.g., spontaneous speech, language
learners, etc.The notion of grammaticality is not that clear
- Who did you see [pictures/?a picture/??his picture/*John’s picture] of?
- ARG/ADJUNCT example
11
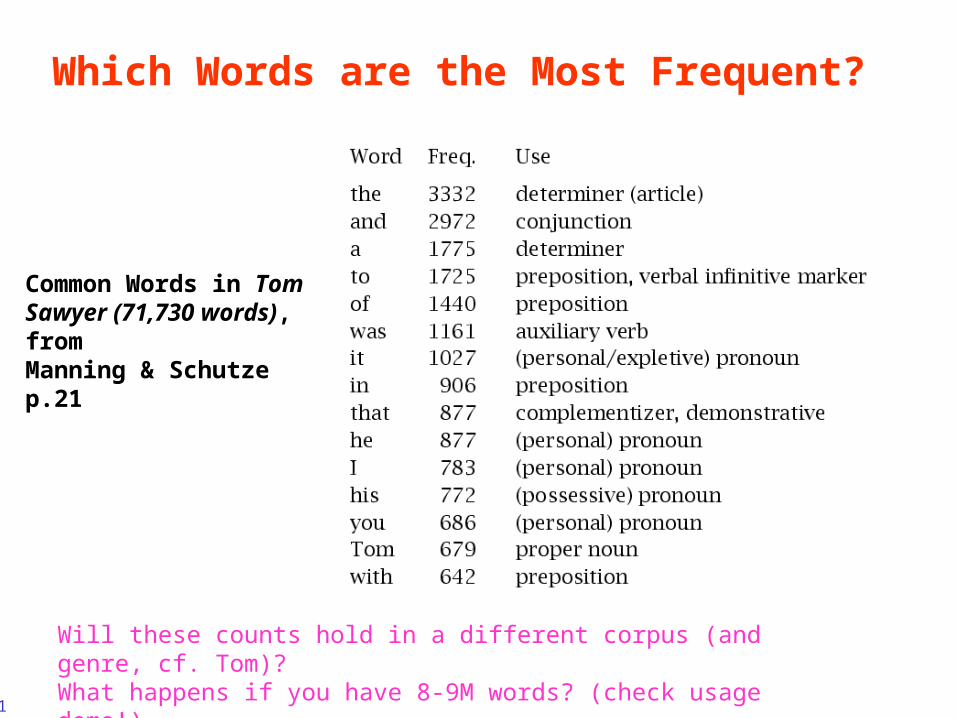
Which Words are the Most Frequent?
Common Words in Tom Sawyer (71,730 words), from Manning & Schutze p.21
Will these counts hold in a different corpus (and genre, cf. Tom)? What happens if you have 8-9M words? (check usage demo!)

12
Data Sparseness
Many low-frequency words
Fewer high-frequency words.
Only a few words will have lots of examples.
About 50% of word types occur only once
Over 90% occur 10 times or less.
So, there is merit to Chomsky’s 2nd objection
Word Frequency Number of words of that frequency
1 3993
2 1292
3 664
4 410
5 243
6 199
7 172
8 131
9 82
10 91
11-50 540
51-100 99
>100 102
Frequency of word types in Tom Sawyer, from M&S 22.

13
Zipf’s Law: Frequency is inversely proportional to rank
Word Freq f Rank r f.r the 3332 1 3332
and 2972 2 5944
a 1775 3 5325
he 877 10 8770
but 410 20 8200
be 294 30 8820
there 222 40 8880
one 172 50 8600
about 158 60 9480
more 138 70 9660
never 124 80 9920
oh 116 90 10440
two 104 100 10400
turned 51 200 10200
you’ll 30 300 9000
name 21 400 8400
comes 16 500 8000
group 13 600 7800
lead 11 700 7700
friends 10 800 8000
begin 9 900 8100
family 8 1000 8000
brushed 4 2000 8000
sins 2 3000 6000
could 2 4000 8000
applausive 1 8000 8000
Empirical evaluation of Zipf’s Law on Tom Sawyer, from M&S 23.

14
Illustration of Zipf’s Law (Brown Corpus, from M&S p. 30)
logarithmicscale
See also http://www.georgetown.edu/faculty/wilsong/IR/WordDist.html

15
Tokenizing words for corpus analysis
1. Break on - Spaces? 犬に当る男の子は私の兄弟である。
inuo butta otokonokowa otooto da
- Periods? (U.K. Products)- Hyphens? data-base = database = data base- Apostrophes? won’t, couldn’t, O’Riley, car’s
2. should different word forms be counted as distinct?- Lemma: a set of lexical forms having the same stem,
the same pos, and the same word-sense. So, cat and cats are the same lemma.
- Sometimes, words are lemmatized by stemming, other times by morphological analysis, using a dictionary and/or morphological rules
3. fold case or not (usually folded)?- The the THE Mark versus mark- One may need, however, to regenerate the original
case when presenting it to the user

16
Counting: Word Tokens vs Word Types
Word tokens in Tom Sawyer: 71,370
Word types: (i.e., how many different words) 8,018
In newswire text of that number of tokens, you would have 11,000 word types. Perhaps because Tom Sawyer is written in a simple style.

17
Inspecting word frequencies in a corpus
http://complingtwo.georgetown.edu/cgi-bin/gwilson/bin/DataSets.cgi
Usage demo:
- http://complingtwo.georgetown.edu/cgi-bin/gwilson/bin/Usage.cgi

18
Ngrams
Sequences of linguistic items of length n
See count.pl

19
A test for association strength: Mutual Information
1988 AP corpus; N=44.3M
)()(
)(log
)()(
)(
log),(
2
2
YfXf
XYNfNYf
NXf
NXYf
YXMI
Data from (Church et al. 1991)

20
Interpreting Mutual Information
High scores, e.g., strong supporter (8.85) indicates strongly associated in the corpus
MI is a logarithmic score. To convert it, recall that X=2 log2X
so, 28.85 461.44. So this is 461 X chance.
Low scores – powerful support (1.74): this is 3X chance, since 21.74 3
I fxy fx fy x y
1.74 2 1984 13,428 powerful support
I = log2 (2N/1984*13428) = 1.74
So, doesn’t necessarily mean weakly associated – could be due to data sparseness

21
Mutual Information over Grammatical Relations
Parse a corpus
Determine subject-verb-object triples
Identify head nouns of subject and object NPs
Score subj-verb and verb-obj associations using MI

22
Demo of Verb-Subj, Verb-Obj Parses
Who devours or what gets devoured?
Demo: http://www.cs.ualberta.ca/~lindek/demos/depindex.htm

23
MI over verb-obj relations
Data from (Church et al. 1991)

24
A Subj-Verb MI Example: Who does what in news?executive police politician
reprimand 16.36 shoot 17.37 clamor 16.94
conceal 17.46 raid 17.65 jockey 17.53
bank 18.27 arrest 17.96 wrangle 17.59
foresee 18.85 detain 18.04 woo 18.92
conspire 18.91 disperse 18.14 exploit 19.57
convene 19.69 interrogate 18.36 brand 19.65
plead 19.83 swoop 18.44 behave 19.72
sue 19.85 evict 18.46 dare 19.73
answer 20.02 bundle 18.50 sway 19.77
commit 20.04 manhandle 18.59 criticize 19.78
worry 20.04 search 18.60 flank 19.87
accompany 20.11 confiscate 18.63 proclaim 19.91
own 20.22 apprehend 18.71 annul 19.91
witness 20.28 round 18.78 favor 19.92
Data from (Schiffman et al. 2001)

25
‘Famous’ Corpora
Must see: http://www.ldc.upenn.edu/Catalog/ Brown Corpus British National Corpus International Corpus of English Penn Treebank Lancaster-Oslo-Bergen Corpus Canadian Hansard Corpus U.N. Parallel Corpus TREC Corpora MUC Corpora English, Arabic, Chinese Gigawords Chinese, ArabicTreebanks North American News Text Corpus Multext East Corpus – ‘1984’ in multiple Eastern/Central
European langauges

26
Links to Corpora
Corpora:
- Linguistic Data Consortium (LDC) http://www.ldc.upenn.edu/
- Oxford Text Archive http://sable.ox.ac.uk/ota/
- Project Gutenberg http://www.promo.net/pg/
- CORPORA list http://www.hd.uib.no/corpora/archive.html
Other:
- Chris Manning’s Corpora Page
- http://www-nlp.stanford.edu/links/statnlp.html#Corpora
- Michael Barlow’s Corpus Linguistics page http://www.ruf.rice.edu/~barlow/corpus.html
- Cathy Ball’s Corpora tutorial http://www.georgetown.edu/faculty/ballc/corpora/tutorial.html

27
Summary: Introduction
Concordances and corpora are widely used and available, to help one to develop empirically-based linguistic theories and computer implementations
The linguistic items that can be counted are many, but “words” (defined appropriately) are basic items
The frequency distribution of words in any natural language is Zipfian
- Data sparseness is a basic problem when using observations in a corpus sample of language
Sequences of linguistic items (e.g., word sequences – n-grams) can also be counted, but the counts will be very rare for longer items
Associations between items can be easily computed
- e.g., associations between verbs and parser-discovered subjs or objs

28
Outline
Topics
- Concordances
- Data sparseness
- Chomsky’s Critique
- Ngrams
- Mutual Information
- Part-of-speech tagging
- Annotation Issues
- Inter-Annotator Reliability
- Named Entity Tagging
- Relationship Tagging
Case Studies
- metonymy
- adjective ordering
- Discourse markers: then
- TimeML

29
Using POS in Concordances
Words Freq Freq/
Words
Fiction 2000
N
\bdeal_NN
1.5M 115 7.66
Fiction 2000
VB
1.5M 14 9.33
Gigaword
N
10.5M 2857 2.72
Gigaword
VB
10.5M 139 1.32
deal is more often a verbIn Fiction 2000
deal is more often a nounin English Gigaword
deal is more prevalent inFiction 2000 than Gigaword

30
POS Tagging – What is it?
Given a sentence and a tagset of lexical categories, find the most likely tag for each word in the sentence
Tagset – e.g., Penn Treebank (45 tags, derived from the 87-tag Brown corpus tagset)
Note that many of the words may have unambiguous tags
Example
Secretariat/NNP is/VBZ expected/VBN to/TO race/VB tomorrow/NN
People/NNS continue/VBP to/TO inquire/VB the/DT reason/NN for/IN the/DT race/NN for/IN outer/JJ space/NN

31
More details of POS problem
How ambiguous?- Most words in English have only one Brown Corpus tag
Unambiguous (1 tag) 35,340 word types Ambiguous (2- 7 tags) 4,100 word types = 11.5%
- 7 tags: 1 word type “still”- But many of the most common words are ambiguous
Over 40% of Brown corpus tokens are ambiguous Obvious strategies may be suggested based on intuition
to/TO race/VB the/DT race/NN will/MD race/NN
Sentences can also contain unknown words for which tags have to be guessed: Secretariat/NNP is/VBZ

32
Different English Part-of-Speech Tagsets
Brown corpus - 87 tags
- Allows compound tags
“I'm” tagged as PPSS+BEM
- PPSS for "non-3rd person nominative personal pronoun" and BEM for "am, 'm“
Others have derived their work from Brown Corpus
- LOB Corpus: 135 tags
- Lancaster UCREL Group: 165 tags
- London-Lund Corpus: 197 tags.
- BNC – 61 tags (C5)
- PTB – 45 tags
To see comparisons ad mappings of tagsets, go to www.comp.leeds.ac.uk/amalgam/tagsets/tagmenu.html

33
PTB Tagset (36 main tags + 9 punctuation tags)

34
PTB Tagset Development
Several changes were made to Brown Corpus tagset:- Recoverability
Lexical: Same treatment of Be, do, have, whereas BC gave each its own symbol
- Do/VB does/VBZ did/VBD doing/VBG done/VBN Syntactic: Since parse trees were used as part of
Treebank, conflated certain categories under the assumption that they would be recoverable from syntax
- subject vs. object pronouns (both PP)- subordinating conjunctions vs. prepositions on
being informed vs. on the table (both IN)- Preposition “to” vs. infinitive marker (both TO)
- Syntactic Function BC: the/DT one/CD vs. PTB: the/DT one/NN BC: both/ABX vs. PTB: both/PDT the boys, the boys both/RB, both/NNS
of the boys, both/CC boys and girls

35
PTB Tagging Process
Tagset developed
Automatic tagging by rule-based and statistical pos taggers
Human correction using an editor embedded in Gnu Emacs
Takes under a month for humans to learn this (at 15 hours a week), and annotation speeds after a month exceed 3,000 words/hour
Inter-annotator disagreement (4 annotators, eight 2000-word docs) was 7.2% for the tagging task and 4.1% for the correcting task
Manual tagging took about 2X as long as correcting, with about 2X the inter-annotator disagreement rate and an error rate that was about 50% higher.
So, for certain problems, having a linguist correct automatically tagged output is far more efficient and leads to better reliability among linguists compared to having them annotate the text from scratch!

36
Automatic POS tagging
http://complingone.georgetown.edu/~linguist/

37
A Baseline Strategy
Choose the most likely tag for each ambiguous word, independent of previous words
- i.e., assign each token to the pos-category it occurred in most often in the training set
E.g., race – which pos is more likely in a corpus?
This strategy gives you 90% accuracy in controlled tests
- So, this “unigram baseline” must always be compared against

38
Beyond the Baseline
Hand-coded rules
Sub-symbolic machine learning
Symbolic machine learning

39
Machine Learning
Machines can learn from examples
Learning can be supervised or unsupervised
Given training data, machines analyze the data, and learn rules which generalize to new examples
Can be sub-symbolic (rule may be a mathematical function) –e.g. neural nets
Or it can be symbolic (rules are in a representation that is similar to representation used for hand-coded rules)
In general, machine learning approaches allow for more tuning to the needs of a corpus, and can be reused across corpora

40
A Probabilistic Approach to POS tagging
What you want to do is find the “best sequence” of pos-tags C=C1..Cn for a sentence W=W1..Wn.
- (Here C1 is pos_tag(W1)). In other words, find a
sequence of pos tags Cthat maximizes P(C| W)
Using Bayes’ Rule, we can sayP(C| W) = P(W | C) * P(C) / P(W ) Since we are interested in
finding the value of C which maximizes the RHS, the denominator can be discarded, since it will be the same for every C
So, the problem is: Find C which maximizes
P(W | C) * P(C)
Example: He will race Possible sequences:
- He/PP will/MD race/NN- He/PP will/NN race/NN- He/PP will/MD race/VB- He/PP will/NN race/VB
W = W1 W2 W3 = He will race
C = C1 C2 C3- Choices:
C= PP MD NN C= PP NN NN C = PP MD VB C = PP NN VB

41
Independence Assumptions
P(C1….Cn) i=1, n P(Ci| Ci-1)
- assumes that the event of a pos-tag occurring is independent of the event of any other pos-tag occurring, except for the immediately previous pos tag
From a linguistic standpoint, this seems an unreasonable assumption, due to long-distance dependencies
P(W1….Wn | C1….Cn) i=1, n P(Wi| Ci)
- assumes that the event of a word appearing in a category is independent of the event of any other word appearing in a category
Ditto
However, the proof of the pudding is in the eating!
- N-gram models work well for part-of-speech tagging

42
A Statistical Method for POS Tagging
MD NN VB PRP
he 0 0 0 .3
will .8 .2 0 0
race 0 .4 .6 0
lexical generation probs
he|PP1
will|MD.8
race|NN.4
race|VB.6
will|NN.2
.4
.6.3
.7
.8
.2
<s>| 1lex(B)
C|R MD NN VB PRP
MD .4 .6
NN .3 .7
PP .8 .2
1
pos bigram probs
Find the value of C1..Cn which maximizes:
i=1, n P(Wi| Ci) * P(Ci| Ci-1)
lexical generationprobabilities
Pos bigramprobs

43
Finding the best path through an HMM
Score(I) = Max J pred I [Score(J)* transition(I|J)]* lex(I)
Score(B) = P(PP|)* P(he|PP) =1*.3=.3
Score(C)=Score(B) *P(MD|PP) * P(will|MD) = .3*.8*.8= .19
Score(D)=Score(B) *P(NN|PP) * P(will|NN) = .3*.2*.2= .012
Score(E) = Max [Score(C)*P(NN|MD), Score(D)*P(NN|NN)] *P(race|NN) =
Score(F) = Max [Score(C)*P(VB|MD), Score(D)*P(VB|NN)]*P(race|VB)=
he|PP1
will|MD.8
race|NN.4
race|VB.6
will|NN.2
.4
.6.3
.7
.8
.2
<s>| 1
A
C
B
D
E
Flex(B)
Viterbialgorithm

44
But Data Sparseness Bites Again!
Lexical generation probabilities will lack observations for low-frequency and unknown words
Most systems do one of the following
- Smooth the counts
E.g., add a small number to unseen data (to zero counts). For example, assume a bigram not seen in the data has a very small probability, e.g., .0001.
Backoff bigrams with unigrams, etc.
- Use lots more data (you’ll still lose, thanks to Zipf!)
- Group items into classes, thus increasing class frequency
e.g., group words into ambiguity classes, based on their set of tags. For counting, alll words in an ambiguity class are treated as variants of the same ‘word’

45
A Symbolic Learning Method
HMMs are subsymbolic – they don’t give you rules that you can inspect
A method called Transformational Rule Sequence learning (Brill algorithm) can be used for symbolic learning (among other approaches)
The rules (actually, a sequence of rules) are learnt from an annotated corpus
Performs at least as accurately as other statistical approaches
Has better treatment of context compared to HMMs
- rules which use the next (or previous) pos
HMMs just use P(Ci| Ci-1) or P(Ci| Ci-2Ci-1)
- rules which use the previous (next) word
HMMs just use P(Wi|Ci)

46
Brill Algorithm (Overview)
Assume you are given a training corpus G (for gold standard)
First, create a tag-free version V of it
Notes:
- As the algorithm proceeds, each successive rule becomes narrower (covering fewer examples, i.e., changing fewer tags), but also potentially more accurate
- Some later rules may change tags changed by earlier rules
1. First label every word token in V with most likely tag for that word type from G. If this ‘initial state annotator’ is perfect, you’re done!
2. Then consider every possible transformational rule, selecting the one that leads to the most improvement in V using G to measure the error
3. Retag V based on this rule
4. Go back to 2, until there is no significant improvement in accuracy over previous iteration

47
Brill Algorithm (Detailed)
1. Label every word token with its most likely tag (based on lexical generation probabilities).
2. List the positions of tagging errors and their counts, by comparing with ground-truth (GT)
3. For each error position, consider each instantiation I of X, Y, and Z in Rule template. If Y=GT, increment improvements[I], else increment errors[I].
4. Pick the I which results in the greatest error reduction, and add to outpute.g., VB NN PREV1OR2TAG DT
improves 98 errors, but produces 18 new errors, so net decrease of 80 errors
5. Apply that I to corpus6. Go to 2, unless stopping
criterion is reached
Most likely tag:
P(NN|race) = .98
P(VB|race) = .02
Is/VBZ expected/VBN to/TO race/NN tomorrow/NN
Rule template: Change a word from tag X to tag Y when previous tag is Z
Rule Instantiation to above example: NN VB PREV1OR2TAG TO
Applying this rule yields:
Is/VBZ expected/VBN to/TO race/VB tomorrow/NN

48
Example of Error Reduction
From Eric Brill (1995):Computational Linguistics, 21, 4, p. 7

49
Example of Learnt Rule Sequence
1. NN VB PREVTAG TO- to/TO race/NN->VB
2. VBP VB PREV1OR20R3TAG MD- might/MD vanish/VBP-> VB
3. NN VB PREV1OR2TAG MD- might/MD not/MD reply/NN -> VB
4. VB NN PREV1OR2TAG DT - the/DT great/JJ feast/VB->NN
5. VBD VBN PREV1OR20R3TAG VBZ- He/PP was/VBZ killed/VBD->VBN by/IN Chapman/NNP

50
Handling Unknown Words
Can also use the Brill method
Guess NNP if capitalized, NN otherwise.
Or use the tag most common for words ending in the last 3 letters.
etc.
Example Learnt Rule Sequence for Unknown Words

51
POS Tagging using Unsupervised Methods
Reason: Annotated data isn’t always available!
Example: the can Let’s take unambiguous
words from dictionary, and count their occurrences after the
- the .. elephant- the .. guardian
Conclusion: immediately after the, nouns are more common than verbs or modals
Initial state annotator: for each word, list all tags in dictionary
Transformation template: - Change tag of word to
tag Y if the previous (next) tag (word) is Z, where is a set of 2 or more tags
- Don’t change any other tags

52
Error Reduction in Unsupervised Method
Let a rule to change to Y in context C be represented as Rule(, Y, C).
- Rule1: {VB, MD, NN} NN PREVWORD the- Rule2: {VB, MD, NN} VB PREVWORD the
Idea: - since annotated data isn’t available, score rules so as to
prefer those where Y appears much more frequently in the context C than all others in
frequency is measured by counting unambiguously tagged words
so, prefer {VB, MD, NN} NN PREVWORD the
to {VB, MD, NN} VB PREVWORD the
since dict-unambiguous nouns are more common in a corpus after the than dict-unambiguous verbs

53
Summary: POS tagging
A variety of POS tagging schemes exist, even for a single language
Preparing a POS-tagged corpus requires, for efficiency, a combination of automatic tagging and human correction
Automatic part-of-speech tagging can use
- Hand-crafted rules based on inspecting a corpus
- Machine Learning-based approaches based on corpus statistics
e.g., HMM: lexical generation probability table, pos transition probability table
- Machine Learning-based approaches using rules derived automatically from a corpus
Combinations of different methods often improve performance

54
Outline
Topics
- Concordances
- Data sparseness
- Chomsky’s Critique
- Ngrams
- Mutual Information
- Part-of-speech tagging
- Annotation Issues
- Inter-Annotator Reliability
- Named Entity Tagging
- Relationship Tagging
Case Studies
- metonymy
- adjective ordering
- Discourse markers: then
- TimeML

55
Adjective Ordering
*A political serious problem
*A social extravagant life
*red lovely hair
*old little lady
*green little men
Adjectives have been grouped into various classes to explain ordering phenomena

56
Collins COBUILD L2 Grammar
qualitative < color < classifying
Qualitative – expresses a quality that someone or something has, e.g., sad, pretty, small, etc.
- Qualitative adjectives are gradable, i.e., the person or thing can have more or less of the quality
Classifying – used to identify the class something belongs to, i.e.., distinguishing
- financial help, American citizens.
- Classifying adjectives aren’t gradable.
So, the ordering reduces to
- Gradable < color < non-gradable A serious political problem
Lovely red hair
Big rectangular green Chinese carpet

57
Vendler 68
A9 < A8 < …A2 < A1x <A1m < …<A1a
A9: probably, likely, certain
A8: useful, profitable, necessary
A7: possible, impossible
A6: clever, stupid, reasonable, nice, kind, thoughtful, considerate
A5: ready, willing, anxious
A4: easy
A3: slow, fast, good, bad, weak, careful, beautiful
A2: contrastive/polar adjectives: long-short, thick-thin, big-little, wide-narrow
A1j: verb-derivatives: washed
A1i: verb-derivatives: washing
A1h: luminous
A1g: rectangular
A1f: color adjectives
A1a: iron, steel, metal
big rectangular green Chinese carpet

58
Other Adjective Ordering Theories
Goyvaerts 68 quality < size/length/shape < age < color < naturally < style < general < denominal
Quirck &
Greenbaum 73
Intensifying perfect < general-measurable careful wealthy < age young old < color < denominal material woollen scarf < denominal style Parisian dress
Dixon 82 value < dimension < physical property < speed < human propensity < age < color
Frawley 92 value < size < color (English, German, Hungarian, Polish,
Turkish, Hindi, Persian, Indonesian, Basque)
Collins COBUILD: gradable < color < non-gradable Goyvaerts, Q&G, Dixon: size < age < colorGoyvaerts, Q&G: color < denominalGoyvaerts, Dixon: shape < color

59
Testing the Theories on Large Corpora
Selective coverage of a particular language or (small) set of languages
Based on categories that aren’t defined precisely that are computable
Based on small large numbers of examples
Test gradable < color < non-gradable

60
Computable Tests for Gradable Adjectives
Submodifiers expressing gradation
- very|rather|somewhat|extremely A
But what about “very British”?
http://complingtwo.georgetown.edu/~gwilson/Tools/Adj/GW_Grad.txt
Periphrastic comparatives
- “more A than“ | "the most A“
Inflectional comparatives
- -er|-est
http://complingtwo.georgetown.edu/~gwilson/Tools/Adj/BothLists.txt

61
Challenges: Data Sparseness
Data sparseness- Only some pairs will be present in a given
corpus few adjectives on the gradable list may be present
- Even fewer longer sequences will be present in a corpus
Use transitivity?- small < red, red < wooden --> small <
red < wooden?

62
Challenges: Tool Incompleteness
Search pattern will return many non-examples- Collocations
common or marked ones - American “green card”- national Blue Cross
- Adjective Modification bright blue
- POS-tagging errors- May also miss many examples

63
Results from Corpus Analysis
G < C < not G generally holds However, there are exceptions
- Classifying/Non-Gradable < ColorAfter all, the maple leaf replaced the British red
ensign as Canada's flag almost 30 years ago.http://complingtwo.georgetown.edu/~gwilson/Tools/Adj/Color2.html
where he stood on a stage festooned with balloons displaying the Palestinian green, white and red flag
http://complingtwo.georgetown.edu/~gwilson/Tools/Adj/Color4.html
- Color < Shapepaintings in which pink, roundish shapes, enriched
with flocking, gel, lentils and thread, suggest the insides of the female body.
http://complingtwo.georgetown.edu/~gwilson/Tools/Adj/Color4.html

64
Summary: Adjective Ordering
It is possible to test concrete predictions of a linguistic theory in a corpus-based setting
The testing means that the machine searches for examples satisfying patterns that the human specifies
The patterns can pre-suppose a certain/high degree of automatic tagging, with attendant loss of accuracy
The patterns should be chosen so that they provide “handles” to identify the phenomena of interest
The patterns should be restricted enough that the number of examples the human has to judge is not infeasible
This is usually an iterative process

65
Outline
Topics
- Concordances
- Data sparseness
- Chomsky’s Critique
- Ngrams
- Mutual Information
- Part-of-speech tagging
- Annotation Issues
- Named Entity Tagging
- Inter-Annotator Reliability
- Relationship Tagging
Case Studies
- metonymy
- adjective ordering
- Discourse markers: then
- TimeML

66
The Art of Annotation 101
1. Define Goal
2. Eyeball Data (with the help of Computers)
3. Design Annotation Scheme
4. Develop Example-based Guidelines
5. Unless satisfied/exhausted, goto 1
6. WriteTraining Manuals
7. Initiate HumanTraining Sessions
8. Annotate Data / Train Computers
• Computers can also help with the annotation
9. Evaluate Humans and Computers
10. Unless satisfied/exhausted, goto 1

67
Annottation Methodology Picture
RawCorpus
AnnotatedCorpus
InitialTagger
AnnotationEditor
AnnotationGuidelines
MachineLearningProgram
RawCorpus
LearnedRules
AnnotatedCorpus
RuleApply
KnowledgeBase?

68
Goals of an Annotation Scheme
Simplicity – simple enough for a human to carry out
Precision – precise enough to be useful in CLI applications
Text-based – annotation of an item should be based on information conveyed by the text, rather than information conveyed by background information
Human-centered – should be based on what a human can infer from the text, rather than what a machine can currently do or not do
Reproducible – your annotation should be reproducible by other humans (i.e., inter-annotator agreement should be high)
- obviously, these other humans may have to have particular expertise and training

69
What Should An Annotation Contain
Additional Information about the text being annotated – e.g., EAGLES external and internal criteria
Information about the annotator – who, when, what version of tool, etc. (usually in meta-tags associated with the text)
The tagged text itself
Example:
http://www.emille.lancs.ac.uk/spoken.htm

70
External and Internal Criteria (EAGLES)
External: participants, occasion, social setting, communicative function
- origin: Aspects of the origin of the text that are thought to affect its structure or content.
- state: the appearance of the text, its layout and relation to non-textual matter, at the point when it is selected for the corpus.
- aims: the reason for making the text and the intended effect it is expected to have.
Internal: patterns of language use
- Topic (economics, sports, etc.)
- Style (formal/informal, etc.)

71
External Criteria – state (EAGLES)
Mode - spoken
participant awareness: surreptitious/warned/aware venue: studio/on location/telephone
- written Relation to the medium
- written: how it is laid out, the paper, print, etc.- spoken: the acoustic conditions, etc.
Relation to non-linguistic communicative matter - diagrams, illustrations, other media that are coupled with the
language in a communicative event. Appearance
- e.g., advertising leaflets, aspects of presentation that are unique in design and are important enough to have an effect on the language.

72
Examples of annotation schemes (changing the way we do business!)
POS tagging annotationPOS tagging annotation – Penn Treebank Scheme
Named entity annotation – ACE Scheme
Phrase Structure annotation – Penn Treebank scheme
Time Expression annotation – TIMEX2 Scheme
Protein Name Annotation – GU Scheme
Event Annotation – TimeML Scheme
Rhetorical Structure Annotation - RST Scheme
Coreference Annotation, Subjectivity Annotation, Gesture Annotation, Intonation Annotation, Metonymy Annotation, etc., etc.
Etc.
Several hundred schemes exist, for different problems in different languages

73
POS Tag Formats: Non-SGML – to SGML
CLAWS tagger: non-SGML
- What_DTQ can_VM0 CLAWS_NN2 do_VDI to_PRP Inderjeet_NP0 's_POS noonsense_NN1 text_NN1 ?_?
Brill tagger: non-SGML
- What/WP can/MD CLAWS/NNP do/VB to/TO Inderjeet/NNP 's/POS noonsense/NN text/NN ?/.
Alembic POS tagger:
- <s><lex pos=WP>What</lex> <lex pos=MD>can</lex> <lex pos=NNP>CLAWS</lex> <lex pos=VB>do</lex> <lex pos=TO>to</lex> <lex pos=NNP>Inderjeet</lex> <lex pos=POS>'</lex><lex pos=PRP>s</lex> <lex pos=VBP>noonsense</lex> <lex pos=NN>text</lex> <lex pos=".">?</lex></s>
Conversion to SGML is pretty trivial in such cases

74
SGML (Standard Generalized Markup Language)
A general markup language for text
- HTML is an instance of an SGML encoding
Text Encoding Initiative (TEI): defines SGML schemes for marking up humanities text resources as well as dictionaries
Examples:- <p><s>I’m really hungry
right now.</s><s>Oh, yeah?</s>
- <utt speak=“Fred” date=“10-Feb-1998”>That is an ugly couch.</utt>
Note: some elements (e.g., <p>) can consist just of a single tag
Character references: ways of referring to the non-ASCII characters using a numeric code
- å (this is in decimal) å (this is in hexadecimal)
å Entity references: are used to
encode a special character or sequence of characters via a symbolic name
- résumé.;- &docdate;

75
DTDs
A document type definition, or DTD, is used to define a grammar of legal SGML structures for a document
- e.g., para should consist of one or more sentences and nothing else
SGML parser verifies that document is compliant with DTD
DTD’s can therefore be used for XML as well
DTDs can specify what attributes are required, in what order, what their legit values are, etc.
The DTDs are often ignored in practice!
DTD:
<!ENTITY writer SYSTEM "http://www.mysite.com/all-entities.dtd">
<!ATTLIST payment type (check|cash) "cash">
XML:
<author>&writer;</author>
<payment type="check">

76
XML
“Extensible Markup Language (XML) is a simple, very flexible text format derived from SGML.
Originally designed to meet the challenges of large-scale electronic publishing, XML is also playing an increasingly important role in the exchange of a wide variety of data on the Web and elsewhere.” www.w3.org/XML/
Defines a simplified subset of SGML, designed especially for Web applications
Unlike HTML, separates out display (e.g., XSL) from content (XML)
Example
<p/><s><lex pos=“WP”>What</lex> <lex pos=“MD”>can</lex></s>
Makes use of DTDs, but also RDF Schemas

77
RDF Schemas
Example of Real RDF Schema:
http://www.cs.brandeis.edu/~jamesp/arda/time/documentation/TimeML.xsd (see EVENT tag and attributes)

78
Inline versus Standoff Annotation
Usually, when tags are added, an annotation tool is used, to avoid spurious insertions or deletions
The annotation tool may use inline or standoff annotation
Inline – tags are stored internally in (a copy of) the source text.
- Tagged text can be substantially larger than original text
- Web pages are a good example – i.e., HTML tags
Standoff – tags are stored internally in separate files, with information as to what positions in the source text the tags occupy
- e.g., PERSON 335 337
- However, the annotation tool displays the text as if the tags were in-line

79
Summary: Annotation Issues
A ‘best-practices’ methodology is widely used for annotating corpora
The annotation process involves computational tools at all stages
Standard guidelines are available for use
To share annotated corpora (and to ensure their survivability), it is crucial that the data be represented in a standard rather than ad hoc format
XML provides a well-established, Web-compliant standard for markup languages
DTDs and RDF provide mechanisms for checking well-formedness of annotation

80
Outline
Topics
- Concordances
- Data sparseness
- Chomsky’s Critique
- Ngrams
- Mutual Information
- Part-of-speech tagging
- Annotation Issues
- Inter-Annotator Reliability
- Named Entity Tagging
- Relationship Tagging
Case Studies
- metonymy
- adjective ordering
- Discourse markers: then
- TimeML

81
Background
Deborah Schiffrin. Anaphoric then: aspectual, textual, and epistemic meaning. Linguistics 30 (1992), 753-792
Schiffrin xamines uses of then in data elicited via 20 sociolinguistic interviews, each an hour long
Distinguishes two anaphoric temporal senses, showing that they are differentiated by clause position
Shows that they have systematic effects on aspectual interpretation
A parallel argument is made for two epistemic temporal senses

82
Schiffrin: Temporal and Non-Temporal Senses
Anaphoric Senses- ‘Narrative’ temporal sense (shifts reference time)
And then I uh lived there until I was sixteen- Continuing Temporal sense (continues a previous
reference time) I was only a little boy then.
Epistemic senses- Conditional ‘sentences’ (rare, but often have temporal
antecedents in her data) But if I think about it for a few days -- well, then I
seem to remember a great deal …if I’m still in the situation where I am now….I’m, not
gonna have no more then- Initiation-response-evaluation sequences (‘in that
case’?) Freda: Do y’ still need the light? Debby: Um. Freda” W’ll have t’ go in then. Because the bugs are
out.

83
Schiffrin’s Argument (Simplified) and Its Test
Shifting RT thens (call these Narrative) & then in if-then conditionals
- similar semantic function
- mainly clause-initial
Continuing RT thens (call these Temporal) & IRE thens
- similar semantic function
- mainly clause final
- stative verb more likely (since RT overlaps, verbs conveying duration are expected)
Call the rest Other
- isn’t differentiated into if-then versus IRE
- So, only part of her claims tested

84
So, What do we do Then?
Define environments of interest, each one defined by a pattern
For each environment
1. Find examples matching the pattern
2. If classifying the examples is manageable, carry it out and stop
3. Otherwise restrict the environment by adding new elements to the pattern, and go back to 1
So, for each final environment, we claim that X% of the examples in that environment are of a particular class
Initial ‘then’ Pattern: (^|_CC|_RB)\s*then\w+\s+\w
Final ‘then’ Pattern: [^\,]\s+then[\.\?\'\;\!\:]

85
Exceptions
Non-Narrative Initial ‘then’
then there [be]
then come
then again
then and now
only then
even then
so then
Non-Temporal Final ‘then’
What then?
All right/OK [,] then
And then?

86
Results
Written Fiction 2000 Spoken Broadcast News Written Gigaword News
T N O T N O T N O
Clause Initial 1.73
(23/13
22)
96.67
(1276/
1322)
1.58
(21/13
22)
.73
(6/81
8)
93.88(
768/81
8)
5.3
(44/81
8)
3.64
(27/740
)
75.94
(562/74
0)
20.40
(151/74
0)
Clause Final 71.81
(79/11
0)
2.72
(3/110)
25.45
(28/11
0)
72.61
(61/8
4)
5.95
(5/84)
21.42
(18/84)
93.23
(179/19
2)
0 6.77
(13/192
)
Other is a presence in final position in fiction and broadcast news, and in initial position in print news. Is this real or artifact of catch-all class?
Conclusion: only part of her claims tested. But those claims are borne out across three different genres and much more data!

87
Outline
Topics
- Concordances
- Data sparseness
- Chomsky’s Critique
- Ngrams
- Mutual Information
- Part-of-speech tagging
- Annotation Issues
- Inter-Annotator Reliability
- Named Entity Tagging
- Relationship Tagging
Case Studies
- metonymy
- adjective ordering
- Discourse markers: then
- TimeML

88
Considerations in Inter-Annotator Agreement
Size of tagset
Structure of tagset
Clarity of Guidelines
Number of raters
Experience of raters
Training of raters
- Independent ratings (preferred)
- Consensus (not preferred)
Exact, partial, and equivalent matches
Metrics
Lessons Learned: Disagreement patterns suggest guideline revisions

89
Protein Names
Considerable variability in the forms of the names
Multiple naming conventions
Researchers may name a newly discovered protein based on
- function
- sequence features
- gene name
- cellular location
- molecular weight
- discoverer
- or other properties
Prolific use of abbreviations and acronyms
fushi tarazu 1 factor homolog
Fushi tarazu factor (Drosophila) homolog 1
FTZ-F1 homolog ELP
steroid/thyroid/retinoic nuclear hormone receptor homolog nhr-35
V-INT 2 murine mammary tumor virus integration site oncogene homolog
fibroblast growth factor 1 (acidic) isoform 1 precursor
nuclear hormone receptor subfamily 5, Group A, member 1

90
Guidelines v1 TOC

91
Agreement Metrics
Reference Candidate
Yes No
Yes TP FN
No FP TN
Measure Definition
Percentage Agreement
100*(TP+TN)/(TP+FP+TN+FN)
Precision TP/(TP+FP)
Recall TP/(TP+FN)
(Balanced) F-Measure
2*Precision*Recall/(Precision+Recall)

92
Example for F-measure: Scorer Output (Protein Name Tagging)
REFERENCE CANDIDATE
CORR FTZ-F1 homolog ELP | FTZ-F1 homolog ELP INCO M2-LHX3 | M2SPUR | -SPUR | LHX3
Precision = ¼ = 0.25
Recall = ½ = 0.5
F-measure = 2 * ¼ * ½ / ( ¼ + ½ ) = 0.33

93
The importance of disagreement
Measuring inter-annotator agreement is very useful in “debugging” the annotation scheme
Disagreement can lead to improvements in the annotation scheme
Extreme disagreement can lead to abandonment of the scheme

94
V2 Assessment (ABS2)
Old Guidelines
- protein 0.71 F
- acronym 0.85 F
- array-protein 0.15
F
New Guidelines
- protein 0.86 F
- long-form 0.71 F
these are only
~4% of tags
Coders
Correct
Precision
Recall
F-mea-
sure
<protein>
A1-A3 4497 0.874
0.852
0.863
A1-A4 4769 0.884
0.904
0.894
A3-A4 4476 0.830
0.870
0.849
Average
0.862 0.875 0.868
<long-form>
A1-A3 172 0.720
0.599
0.654
A1-A4 241 0.837
0.840
0.838
A3-A4 175 0.608
0.732
0.664
Average
0.721 0.723 0.718

95
TIMEX2 Annotation Scheme
Time Points <TIMEX2 VAL="2000-W42">the third week of October</TIMEX2>
Durations <TIMEX2 VAL=“PT30M”>half an hour long</TIMEX2>
Indexicality <TIMEX2 VAL=“2000-10-04”>tomorrow</TIMEX2>
Sets <TIMEX2 VAL=”XXXX-WXX-2" SET="YES” PERIODICITY="F1W" GRANULARITY=“G1D”>every Tuesday</TIMEX2>
Fuzziness <TIMEX2 VAL=“1990-SU”>Summer of 1990 </TIMEX2>
<TIMEX2 VAL=“1999-07-15TMO”>This morning</TIMEX2>
Non-specificity <TIMEX2 VAL="XXXX-04" NON_SPECIFIC=”YES”>April</TIMEX2> is usually wet.
For guidelines, tools, and corpora, please see timex2.mitre.org

96
TIMEX2 Inter-Annotator Agreement
tag pos act corr prec rec f f-TempEx
extent 6421 6369 5064 0.795101 0.788662 0.791882 0.762098val 5324 5296 4578 0.864426 0.85988 0.862153 0.829071granularity 289 312 165 0.535168 0.486111 0.51064 0.440212mod 494 451 363 0.813776 0.723356 0.768566 0.778878non_specific 143 92 28 0.304348 0.195804 0.250076 0periodicity 244 253 208 0.822134 0.852459 0.837297 0.811268set 300 316 232 0.734177 0.773333 0.753755 0.81465
193 NYT news docs5 annotators10 pairs of annotators
Human annotation quality is ‘acceptable’ on EXTENT and VAL Poor performance on Granularity and Non-Specific
But only a small number of instances of these (200 ~ 6000)
Annotators deviate from guidelines, and produce systematic errors (fatigue?) several years ago: PXY instead of PAST_REF
all day: P1D instead of YYYY-MM-DD

97
TempEx in Qanda

98
Summary: Inter-Annotator Reliability
There’s no point going on with an annotation scheme if it can’t be reproduced
There are standard methods for measuring inter-annotator reliability
An analysis of inter-annotator disagreements is critical for “debugging” an annotation scheme

99
Outline
Topics
- Concordances
- Data sparseness
- Chomsky’s Critique
- Ngrams
- Mutual Information
- Part-of-speech tagging
- Annotation Issues
- Inter-Annotator Reliability
- Named Entity Tagging
- Relationship Tagging
Case Studies
- metonymy
- adjective ordering
- Discourse markers: then
- TimeML

100
Information Extraction
Types
- Flag names of people, organizations, places,…
- Flag and normalize time expressions, phrases such as time expressions, measure phrases, currency expressions, etc.
- Group coreferring expressions together
- Find relations between named entities (works for, located at, etc.)
- Find events mentioned in the text
- Find relations between events and entities
- A hot commercial technology!
Example patterns:
- Mr. ---,
- , Ill.

101
Message Understanding Conferences (MUCs)
Idea: precise tasks to measure success, rather than test suite of input and logical forms.
MUC-1 1987 and MUC-2 1989 - messages about navy operations
MUC-3 1991 and MIC-4 1992 - news articles and transcripts of radio broadcasts about terrorist activity
MUC-5 1993 - news articles about joint ventures and microelectronics
MUC-6 1995 - news articles about management changes, + additional tasks of named entity recognition, coreference, and template element
MUC-7 1998 – mostly multilingual information extraction
Has also been applied to hundreds of other domains - scientific articles, etc., etc.

102
Historical Perspective
Until MUC-3 (1993), many IE systems used a Knowledge Engineering
approach
- They did something like full chart parsing with a unification-based
grammar with full logical forms, a rich lexicon and KB
- E.g., SRI’s Tacitus
Then, they discovered that things could work much faster using finite-state
methods and partial parsing
And that using domain-specific rather than general purpose lexicons
simplified parsing (less ambiguity due to fewer irrelevant senses)
And that these methods worked even better for the IE tasks
- E.g., SRI’s Fastus, SRA’s Nametag
Meanwhile, people also started using statistical learning methods from
annotated corpora
- Including CFG parsing

103
An instantiated scenario template
Wall Street Journal, 06/15/88
MAXICARE HEALTH PLANS INC and UNIVERSAL HEALTH SERVICES INC have dissolved a joint venture which provided health services.
<TEMPLATE-8806150049-1> := DOC NR: 8806150049 CONTENT: <TIE_UP_RELATIONSHIP-8806150049-1> DATE TEMPLATE COMPLETED: 311292 EXTRACTION TIME: 0
Source

104
Templates Can get Complex! (MUC-5)
<TEMPLATE-8806150049-1> := DOC NR: 8806150049 CONTENT: <TIE_UP_RELATIONSHIP-8806150049-1> DATE TEMPLATE COMPLETED: 311292 EXTRACTION TIME: 0<TIE_UP_RELATIONSHIP-8806150049-1> := TIE-UP STATUS: DISSOLVED ENTITY: <ENTITY-8806150049-1> <ENTITY-8806150049-2> JOINT VENTURE CO: <ENTITY-8806150049-3> OWNERSHIP: <OWNERSHIP-8806150049-1> <OWNERSHIP-8806150049-2> ACTIVITY: <ACTIVITY-8806150049-1><ENTITY-8806150049-1> := NAME: Maxicare Health Plans INC ALIASES: "Maxicare" LOCATION: Los Angeles (CITY 4) California (PROVINCE 1) United States (COUNTRY) TYPE: COMPANY ENTITY RELATIONSHIP: <ENTITY_RELATIONSHIP-8806150049-1><ENTITY-8806150049-2> := NAME: Universal Health Services INC ALIASES: "Universal Health" LOCATION: King of Prussia (CITY) Pennsylvania (PROVINCE 1) United States (COUNTRY) TYPE: COMPANY ENTITY RELATIONSHIP: <ENTITY_RELATIONSHIP-8806150049-1><ACTIVITY-8806150049-1> := INDUSTRY: <INDUSTRY-8806150049-1> ACTIVITY-SITE: (<FACILITY-8806150049-1> <ENTITY-8806150049-3>)<INDUSTRY-8806150049-1> := INDUSTRY-TYPE: SERVICE PRODUCT/SERVICE: (80 "a joint venture Nevada health maintenance [organization]")

105
2002 Automatic Content Extraction (ACE) Program: Entity Types
Person
Organization
(Place)
- Location – e.g., geographical areas, landmasses, bodies of water, geological formations
- Geo-Political Entity – e.g., nations, states, cities
Created due to metonymies involving this class of places
The riots in Miami
Miami imposed a curfew
Miami railed against a curfew
Facility – buildings, streets, airports, etc.

106
ACE Entity Attributes and Relations
Attributes
- Name: An entity mentioned by name
- Pronoun
- Nominal
Relations
- AT: based-in, located, residence
- NEAR: relative-location
- PART: part-of, subsidiary, other
- ROLE: affiliate-partner, citizen-of, client, founder, general-staff, manager, member, owner, other
- SOCIAL: associate, grandparent, parent, sibling, spouse, other-relative, other-personal, other-professional

107
Designing an Information Extraction Task
Define the overall task
Collect a corpus
Design an Annotation Scheme
- linguistic theories help
Use Annotation Tools
- - authoring tools
- -automatic extraction tools
Apply to annotation to corpus, assessing reliability
Use training portion of corpus to train information extraction (IE) systems
Use test portion to test IE systems, using a scoring program

108
Annotation Tools
Specialized authoring tools used for marking up text without damaging it
Some tools are tied to particular annotation schemes

109
Annotation Tool Example: Alembic Workbench

110
Callisto (Java successor to Alembic Workbench)

Page 111
Relationship Annotation: Callisto

112
Steps in Information Extraction
Tokenization- Language Identification- Document Zoning- Sentence and Word Tokenization
Morphological and Lexical Processing - Tagging entities of interest- Specific trigger lexicons- Dealing with unknown words- Part-of-Speech Tagging- Word-Sense Tagging- Morphological Analysis
Parsing- Finite-State Parsing (usually just chunking)
Domain Semantics- Coreference- Merging Partial Results

113
Morphological Analysis
Inflectional morphology, mostly
For simple languages (English, Japanese) – simple inflectional module suffices
For more complex languages (Spanish) – a finite-state transducer is used
For morphologically very complex languages (Arabic, Hebrew) – complex finite state transducer architectures
For languages with productive noun compounding (German) – specialized module needed

114
Finite-State Parsing for IE
A.C. Nielesen CO. NG said VG George Garrick NG, 40 years old, president NG of
information Resources Inc. NG's London-based European
Information Services operationNG, will becomeVG presidentNG and chief operating officerNG of Nielsen Marketing Research USANG, a unit NG of Dun & Bradstree Corp. NG
First find NG, VG, particles; ignore PP attachment; ignore clause boundaries; maybe ignore modifiers that aren’t domain-relevant
Later transducers handle more complex phenomena:
- relative clauses (e.g., look for second verb for marking end of rc; subject relatives: associate subject with first and second verb; object relatives: associate object with head noun before rel mod)
- general clause segmentation
- coordination
- appositives
- PP argument attachment (only for verbs important in domain whose subcat info is provided – rest are adverbial adjuncts)

115
Example Text Processing
KEY:
Trigger word tagging
Named Entity tagging
Chunk parsing: NGs, VGs, preps, conjunctions
Bridgestone Sports Co. said Friday it has set up a joint venture in Taiwan with a local concern and a Japanese trading house to produce golf clubs to be shipped to Japan.
CompanyNG Set-UPVG Joint-VentureNG with CompanyNG
ProduceVG ProductNG
The joint venture, Bridgestone Sports Taiwan Cp., capitalized at 20 million new Taiwan dollars, will start production in January 1990 with production of 20,000 iron and “metal wood” clubs a month.

116
Merging Structures
Activity:
Type: PRODUCTION
Company:
Product: golf clubs
Start-date:
Bridgestone Sports Co. said Friday it has set up a joint venture in Taiwan with a local concern and a Japanese trading house to produce golf clubs to be shipped to Japan.
Activity:
Type: PRODUCTION
Company: Bridgestone Sports Taiwan Co
Product: iron and “metal wood” clubs
Start-date: DURING 1990
The joint venture, Bridgestone Sports Taiwan Cp., capitalized at 20 million new Taiwan dollars, will start production in January 1990 with production of 20,000 iron and “metal wood” clubs a month.

117
Coreference
Coreference means establishing referential relations between expressions.
- Pronouns ..Mr. Gates …he, the testimony….it- Definite NPs Microsoft….the company- Indefinite NPs the building…an apartment- Proper Names Bill Gates…William Gates…. Mr. Gates- Temporal Expressions today, three weeks from Monday- Headless Determiners all, the one, five- Prenominals aluminum siding …the price of aluminum- Events they attacked at dawn…the attack
Types of relationships:- Identity, Part-whole- Set-subset the jurors…five ….- Set-member the jurors…on

118
Statistical Named Entity Tagging
Typically, treat it as a word-level tagging problem
- To get phrase-level tags, one could greedily concatenate adjacent tags
this will fail to separate ‘like’ tags
Approaches can separately model words at start, end, or middle of name
- BBN Identifinder does that
P(C|W) = P(W, C)/P(W)
argmaxCP(W, C)
P(Ci|Ci-1, wi-1) first word in a name
* P(<w, f>i=first|Ci, Ci-1) first word in a name
* P(<w,f>i|<w,f>i-1, Ci) all but the first word in a name
Word features f includes information about capitalization, initials, etc.

119
Information Extraction Metrics
Precision: Correct Answers/Answers Produced
Recall: Correct Answers /Total Possible Correct
F-measure - uses a parameter to weight precision versus recall (=1 for balance)
F = (B2+1) PR / B2(P+R)
F =.6 for the relationship/event extraction task (ceiling) in MUC
F = .95+ for named entity task in MUC
= .8 or so for coreference task

120
40
50
60
70
80
90
100
% C
OR
RE
CT
IE and QA Evaluations
Current status for various information extraction and question-answering components
Current status for various information extraction and question-answering components
Event extractionEvent extraction
Names in English
Names in EnglishNames in
Japanese Names in Chinese
Names in Japanese Names
in Chinese
Question AnsweringQuestion Answering
RelationsRelations
Names from audio @ 0%
15% word error
Names from audio @ 0%
15% word error

121
Summary: Information Extraction
A variety of IE tasks and methods are available
Named entities, relations, and event templates can be filled, as well as coreference relations
Linguistic information used can be hand-crafted or corpus-based
Domain knowledge, where needed, is hand-crafted
Performance on names is better than on relations, while “deep” templates have shown a 60% ceiling effect

122
Outline
Topics
- Concordances
- Data sparseness
- Chomsky’s Critique
- Ngrams
- Mutual Information
- Part-of-speech tagging
- Annotation Issues
- Inter-Annotator Reliability
- Named Entity Tagging
- Relationship Tagging
Case Studies
- metonymy
- adjective ordering
- Discourse markers: then
- TimeML

123
Motivation for Temporal Information Extraction
Story Understanding
- Question-answering
- Summarization
Focus on temporal aspects of narrative

124
Chronology of ‘The Marathon’ (mini-story)
Yesterday Holly was running a marathon when she twisted her ankle. David had pushed her.
02172004 02182004
run
twist ankle
du
rin
gfi
nis
hes
or
du
rin
g
before
push befo
re
du
rin
g
1. When did the running occur?Yesterday.2. When did the twisting occur?Yesterday, during the running.3. Did the pushing occur before the twisting?Yes.4. Did Holly keep running after twisting her ankle?5. Maybe not????

125
Factors influencing Event Ordering(1) Max entered the room. He had drunk a lot of wine.
TENSE: Past perfect indicates drinking precedes entering.
(2) Max entered the room. Mary was seated behind the desk.
ASPECT: State of ‘being seated’ overlaps with ‘entering’.
(3) He had borrowed some shirts from local villagers after his backpack went down.
TEMPORAL MODIFIER: Going down precedes borrowing, based on temporal adverbial after
(4) Iraq was defeated during the Gulf War. In ancient times it was the cradle of civilization.
TIMEX: Being the cradle precedes being defeated, based on explicit time expression.
(5) Max stood up. John greeted him.
NARR_CONVENTION: Narrative convention applies, with ‘standing up’ preceding ‘greeting’
(6) Max fell. John pushed him.
DISCOURSE_REL: Narrative convention overridden, based on Explanation relation
(7) A drunken man died in the central Philippines when he put a firecracker under his armpit.
DISCOURSE_REL: dying after putting, with temporal modifier used to instantiate Explanation relation
(8) U.N. Secretary- General Boutros Boutros-Ghali Sunday opened a meeting of .... Boutros-Ghali arrived in Nairobi from South Africa, accompanied by Michel...
WORLD KNOWLEDGE: arrival at the place of a meeting precedes opening a meeting
126
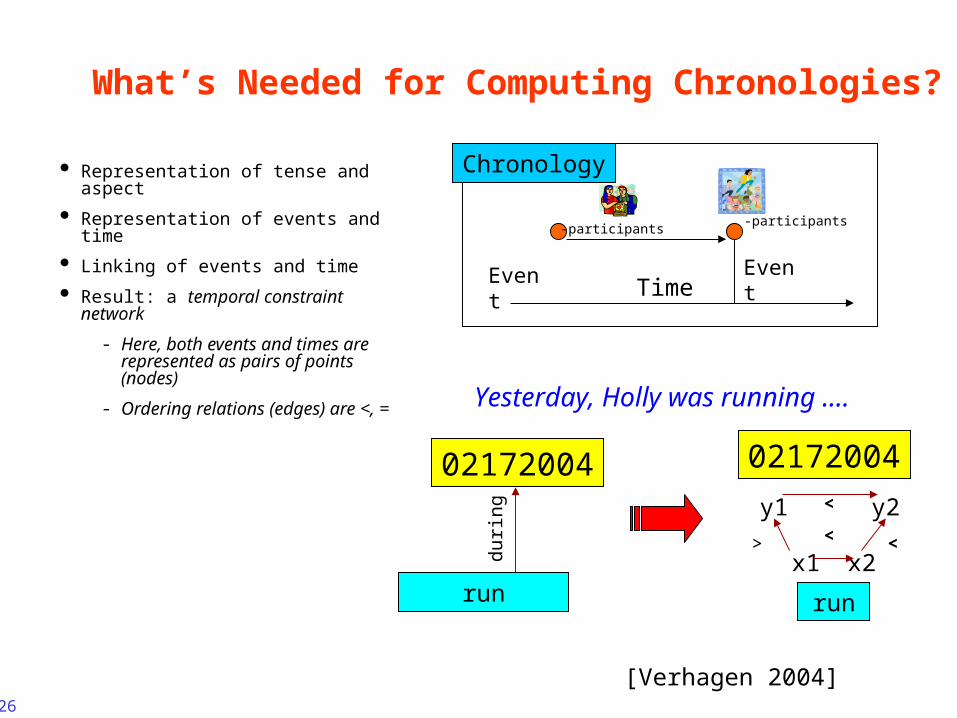
What’s Needed for Computing Chronologies?
Representation of tense and aspect
Representation of events and time
Linking of events and time
Result: a temporal constraint network
- Here, both events and times are represented as pairs of points (nodes)
- Ordering relations (edges) are <, =
Chronology
Time
Event Event-participants
-participants
02172004
run
du
rin
g
02172004
run
<x1 x2
y1 y2
>
Yesterday, Holly was running ….
<
<
[Verhagen 2004]

127
TimeML Annotation
TimeML is a proposed metadata standard for markup of events and their temporal anchoring and ordering
Consists of EVENT tags, TIMEX3 tags, and LINK tags
- EVENTS are grouped into classes and have tense and aspect features
- LINKS include overt and covert links
Can be within or across sentences

128
How TimeML Differs from Previous Markups
Extends TIMEX2 annotation to TIMEX3- Temporal Functions: three years ago- Anchors to events and other temporal expressions: three
years after the Gulf War- Addresses problem with Granularity/Periodicity: three days
every month- Inserts start/end points for Durations: two weeks from June
7 Identifies signals determining interpretation of temporal expressions;
- Temporal Prepositions: for, during, on, at;- Temporal Connectives: before, after, while.
Identifies event expressions; - tensed verbs; has left, was captured, will resign;- stative adjectives; sunken, stalled, on board;- event nominals; merger, Military Operation, Gulf War;
Creates dependencies between events and times:- Anchoring; John left on Monday.- Orderings; The party happened after graduation.- Embedding; John said Mary left.

129
TLINKTLINK or Temporal Link represents the temporal relationship
holding between events or between an event and a time, and establishes a link between the involved entities, making explicit if they are:
• Simultaneous (happening at the same time)• Identical: (referring to the same event)• John drove to Boston. During his drive he ate a
donut. • One before the other:
• The police looked into the slayings of 14 women.In six of the cases suspects have already been arrested.
• One immediately before the other: • All passengers died when the plane crashed
into the mountain. • One including the other: • John arrived in Boston last Thursday.• One holding during the duration of the other: • One being the beginning of the other: • John was in the gym between 6:00 p.m. and
7:00 p.m.• One being the ending of the other: • John was in the gym between 6:00 p.m. and
7:00 p.m.

130
SLINKSLINK or Subordination Link is used for contexts introducing relations between two events, or an event and a signal, of the following sort: Modal: Relation introduced mostly by modal verbs (should, could, would, etc.) and events that introduce a reference to a possible world --mainly I_STATEs:
John should have bought some wine. Mary wanted John to buy some wine.
Factive: Certain verbs introduce an entailment (or presupposition) of the argument's veracity. They include forget in the tensed complement, regret, manage:
John forgot that he was in Boston last year. Mary regrets that she didn't marry John.
Counterfactive: The event introduces a presupposition about the non-veracity of its argument: forget (to), unable to (in past tense), prevent, cancel, avoid, decline, etc.
John forgot to buy some wine. John prevented the divorce.
Evidential: Evidential relations are introduced by REPORTING or PERCEPTION: John said he bought some wine. Mary saw John carrying only beer.
Negative evidential: Introduced by REPORTING (and PERCEPTION?) events conveying negative polarity:
John denied he bought only beer. Negative: Introduced only by negative particles (not, nor, neither, etc.), which will be marked as SIGNALs, with respect to the events they are modifying:
John didn't forget to buy some wine. John did not want to marry Mary.

131
Role of the machine in human annotation
In cases of dense annotation (events, pos tags, word-sense tags, etc.), it can be too tedious for a human to annotate everything
In such cases, it’s helpful to have a computer program pre-annotate the data that the human then corrects
The machine can also interact to flag invalid entries
The machine can also provide visualization
The machine can also augment the annotation with information that can be inferred

132
Annotating Chronology in The Marathon

133
Pre-Closure

134
Post-Closure
135
Automatic TIMEX2 tagging
http://complingone.georgetown.edu/~linguist/

136
TimeML Annotation Issues
Problems Weaknesses in guidelines
- Links between subordinate clause and main clause of same/diff sentence
- Difficulties in annotating states
Granularity of temporal relations (72% agreement on temporal relations on common links)
Density of links. Number of links is quadratic in the number of events, but less than half the eventualities are linked.
So, inter-annotator agreement on links likely to be low.
Solutions Adding more annotation
conventions Lightening the annotation. Expanding annotation
using temporal reasoning. Using heavily mixed-
initiative approach Providing user with
visualization tools during annotation.
Note: such problems are characteristic of semantic and discourse-level annotations!

137
TimeBank Browser and TimeML tools
http://corpora.dutchboy.net/timebank/
http://complingone.georgetown.edu/~linguist/

Page 138
Strategy for Automatically Inferring Linguistic Information
Develop a corpus of TimeML annotated documents
- TimeML represents temporal adverbials, tense, grammatical aspect, temporal relations
- Takes into account subordination and (to an extent) vagueness
- Work on metric constraints for durations of states is ongoing (Hobbs)
Develop initial computer taggers to tag Events, Times, and Links in the corpus
Correct the corpus using a human
Ensure that the annotations can be reproduced accurately
- Inter-annotator reliability
Use the corpus to train improved computer taggers

At the Florist’s (mini-story)
• a. John went into the florist shop.
• b. He had promised Mary some flowers.
• c. She said she wouldn’t forgive him if he forgot.
• d. So he picked out three red roses.
• From (Webber 1988)

Chronology of At the Florist’s

At the Florist’s: A Rhetorical Structure Theory account
• Assumes abstract nodes which are Rhetorical Relations
• Rhetorical relation annotations are not easily reproduced– question of inter-
annotator reliability
Narration
Explanation Ed
Ea Elaboration
Narration
Eb Ec

Temporal Relations as Surrogates for Rhetorical Relations
• When E1 is left-sibling of E2 and E1 < E2, then typically, Narration(E1, E2)
• When E1 is right-sibling of E2 and E1 < E2, then typically Explanation(E2, E1)
• When E2 is a child node of E1, then typically Elaboration(E1, E2)
constraints: {Eb < Ec, Ec < Ea, Ea < Ed}
a. John went into the florist shop. b. He had promised Mary some flowers. c. She said she wouldn’t forgive him if he forgot. d. So he picked out three red roses.
Narr
Elab
Expl

Temporal Discourse Model Annotation Conventions
1. Each tree is rooted in an abstract node. 2. In the absence of any temporal adverbials or discourse
markers, a tense shift will license the creation of an abstract node, with the tense shifted event being the leftmost daughter of the abstract node. The abstract node will then be inserted as the child of the immediately preceding text node.
3. In the absence of temporal adverbials and discourse markers, a stative event will always be placed as a child of the immediately preceding text event when the latter is non-stative, and as a sibling of the previous event when the latter is stative (as in a scene-setting fragment of discourse).

Representing States
• Approach: Minimality– A tensed stative predicate
is represented as a node in the tree (progressives are treated as stative).
John walked home. He was feeling great.
– We represent the state of feeling great as being minimally a part of the event of walking, without committing to whether it extends before or after the event
– A constraint is added to C indicating that this inclusion is minimal.
• Problem: IncompletenessMax entered the room. He
was wearing a black shirt The system will not know
whether the shirt was worn after he entered the room.

TDMs and DRT
EaEbEcxyzt1t2t3 [enter(Ea, x, theWhiteHart) & man (x) & PROG(wear(Eb, x, y) & black-jacket(y) &serve(Ec, Bill, x, z) & beer(z) & t1 < n & Ea t1 & t2 < n & Eb o t2 & Eb Ea & t3 < n & Ec t3 & Ea < Ec]

What’s Needed for Computing TDMs?
• A Corpus of TDMs, annotated with high inter-annotator reliability
• ‘Syntactic’ parsers for TDMs, trained on the corpus

147
Conclusion
There are lots of computational tools for manual and automatic annotation of linguistic data and exploration of linguistic hypotheses
The automatic tools aren’t perfect, but neither are humans!
An annotation scheme must be tested using guidelines and inter-annotator reliability
Annotations must be prepared and used within standard XML-based frameworks
There are many costs and tradeoffs in corpus preparation
The yields can considerably speed up the pace of linguistic research

148
Desiderata for Indian Language Work
The data needs to be encoded using standard character encoding schemes – UNICODE, or else ISCII
Annotation needs to follow the best-practices methodology, including proof of replicability, and XML representation
Experience has shown that linguists and computer scientists can work in synergy on this
Once corpora are prepared according to these guidelines, automatic tools can be developed in India and abroad and used to improve linguistic processing of Indian languages
- Morphological analyzers, stemmers, etc.
- Part-of-speech taggers
- Syntactic Parsers
- Word-Sense Disambiguators
- Temporal Taggers
- Information Extraction Systems
- Text Summarizers
- Statistical MT Systems
- etc.

Free Resources (contact me)
• TIMEX2 corpora and tools: timex2.mitre.org (English, Korean, Spanish)
• TimeML and annotation tools: www.timeml.org• AQUAINT corpus, and TimeML software: watch this
space• PRONTO and iprolink corpora, guidelines, tagsets• (see my web site)

The Changing Environment
• If statistical rules induced from examples perform just as well as rules derived from intuition, then this suggests that probabilistic statistical linguistic rules might help explain or model human linguistic behavior.
• It also suggests that humans might learn from experience by means of induction using statistical regularities.
• For many years, corpus linguistic research rarely examined statistics above the level of words, due to the lack of availability of broad-coverage parsers and statistical models that could handle syntax and other levels of ‘hidden structure’ (Manning 2003).
• The present climate with plenty of tools and statistical models, should allow corpus linguistics to extend its descriptive and explanatory scope dramatically.

151
Ngrams Details
Consider a sequence of words W1…Wn, “I saw a rabbit”. What’s P(W1…Wn)? Note that we can’t find sequences of
length n, and count them - there won’t be enough data. Chain Rule of probability:
P(W1, .. ,Wn ) = P(W1)P(W2|W1) P(W3|W1,W2)..P(Wn|W1,W2, ..,Wn-1 )
- But you still have the problem of lacking enough data Bigram model
- Approximates P(Wn|W1…Wn-1) by P(Wn|Wn-1)- Assumes the probability of a word depends just on the
previous word. This means, that you don’t have to look back more than one word.
- P(I saw a rabbit) = P(I|<s>)*P(saw|I)*P(a|saw)*P(rabbit|a)- More generally: P(W1….Wn) i=1, n P(Wi| Wi-1)
A trigram model, would look 2 words back into the past- P(I saw a rabbit) =P(saw|<s> I)*P(a| I saw)*P(rabbit|saw a)

152
POS Tagging Based on N-grams
Problem: Find C which maximizes P(W | C) * P(C)
Here W=W1..Wn and C=C1..Cn (these were sequences, remember?)
P(W1, .. ,Wn ) = P(W1)P(W2|W1) P(W3|W1,W2)..P(Wn|W1,W2, ..,Wn-1 )
- Using the bigram model, we get:
P(W1….Wn | C1….Cn) i=1, n P(Wi| Ci)
P(C1….Cn) i=1, n P(Ci| Ci-1)
So, we want to find the value of C1..Cn which maximizes:
i=1, n P(Wi| Ci) * P(Ci| Ci-1)
lexical generationprobabilities, estimatedfrom training data
posbigramprobs, estimatedfrom training data

153
Problems in Event Anchoring
States
- John walked home. He was feeling great.
How long does “feeling great” last?
- => We need a “minimal” duration for states- a. Mary entered the President’s Office.b. A copy of the budget was on the
president’s desk. c. The president’s financial advisor stood beside it. d. The president sat regarding both admiringly. e. The advisor spoke. (Dowty 1986)
Was the budget on the desk before she entered the office?
- => “perceived scene” presents an imperfective view of states, not indicating their true onsets
Vagueness
The attack lasted 2-3 weeks.
Recently, Holly turned 16.
Next summer, Holly may run
Three days later, David pushed her
- => temporal reasoning has to deal with vagueness

154
Problems in Event Anchoring (contd)
Vagueness (contd)
- John hurried to Mary’s house after work. But Mary had already left for dinner.
- => we need to track ‘reference time’ and decide when reference times coincide
Modality
- John should have brought some wine.
Did he bring wine? No.
- John prevented the divorce.
Did the divorce happen? No.
=> we need to know about subordination Implicit Information
Yesterday, Holly fell. (implicit “on”)
Holly fell. David pushed her. (implicit “because”)
=> we need discourse modeling