1 distributed nuclear norm minimization for matrix completion morteza mardani, gonzalo mateos and...
TRANSCRIPT

1
Distributed Nuclear Norm Minimization for Matrix Completion
Morteza Mardani, Gonzalo Mateos and Georgios Giannakis
ECE Department, University of Minnesota
Acknowledgments: MURI (AFOSR FA9550-10-1-0567) grant
Cesme, TurkeyJune 19, 2012

2
Learning from “Big Data” `Data are widely available, what is scarce is the ability to extract wisdom from them’
Hal Varian, Google’s chief economist
BIG Fast
Productive
Revealing
Ubiquitous
Smart
K. Cukier, ``Harnessing the data deluge,'' Nov. 2011.
Messy
33
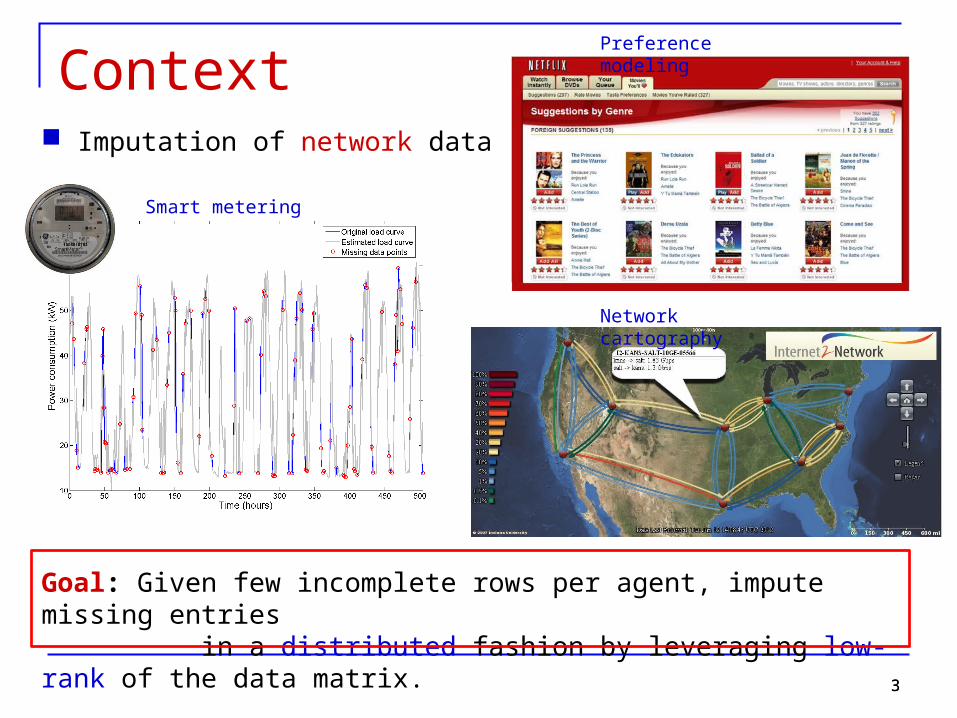
Context Imputation of network data
Goal: Given few incomplete rows per agent, impute missing entries in a distributed fashion by leveraging low-rank of the data matrix.
Preference modeling
Network cartography
Smart metering

(as) has low rank Goal: denoise observed entries, impute missing ones
44
Low-rank matrix completion Consider matrix , set
Given incomplete (noisy) data
Nuclear-norm minimization [Fazel’02],[Candes-Recht’09]
Sampling operator
Noisy Noise-free
s.t.
?
?
??
??
? ??
?
?
?

55
Problem statement
Goal: Given per node and single-hop exchanges, find
n
Network: undirected, connected graph
(P1)
?
?
??
?
?
?
?
?
?
Challenges Nuclear norm is not separable Global optimization variable

66
Separable regularization Key result [Recht et al’11]
New formulation equivalent to (P1)
(P2)
Proposition 1. If stationary pt. of (P2) and ,
then is a global optimum of (P1).
Nonconvex; reduces complexity:
Lxρ≥rank[X]

77
Distributed estimator
Network connectivity (P2) (P3)
(P3)
Consensus with neighboring nodes
Alternating-directions method of multipliers (ADMM) solver Method [Glowinski-Marrocco’75], [Gabay-Mercier’76] Learning over networks [Schizas et al’07]
Primal variables per agent :
Message passing:n

88
Distributed iterations

99
Highly parallelizable with simple recursions Unconstrained QPs per agent No SVD per iteration
Low overhead for message exchanges is and is small Comm. cost independent of network size
Recap:(P1) (P2) (P3)
CentralizedConvex
Sep. regul.Nonconvex
ConsensusNonconvex
Stationary (P3) Stationary (P2) Global (P1)
Attractive features

1010
Optimality
Proposition 2. If converges to
and , then:
i)
ii) is the global optimum of (P1).
ADMM can converge even for non-convex problems [Boyd et al’11]
Simple distributed algorithm for optimal matrix imputation Centralized performance guarantees e.g., [Candes-Recht’09] carry over

1111
Synthetic data Random network topology
N=20, L=66, T=66
0 0.2 0.4 0.6 0.8 1
0
0.2
0.4
0.6
0.8
1
Data , ,

1212
Real data
Abilene network data (Aug 18-22,2011) End-to-end latency matrix N=9, L=T=N 80% missing data
Network distance prediction [Liau et al’12]
Data: http://internet2.edu/observatory/archive/data-collections.html
Relative error: 10%