1 hierarchical classification of documents with error control chun-hung cheng, jian tang, ada...
Post on 20-Dec-2015
220 views
TRANSCRIPT

1
Hierarchical Classification of Documents with Error Control
Chun-Hung Cheng, Jian Tang, Ada Wai-chee Fu, Irwin King

2
Overview
AbstractProblem DescriptionDocument Classification ModelError Control Schemes– Recovery oriented scheme– Error masking scheme
ExperimentsConclusion

3
Abstract
Traditional document classification (flat classification) involves only a single classifier
– Single classifier takes care of everything
– Slow and high overhead

4
Abstract
Hierarchical document classification– Class hierarchy
– Use one classifier at each internal node

5
Abstract
Advantage– Better performance
Disadvantage–Wrong result if misclassified in any
node

6
Abstract
Introduce error control mechanism
Approach 1 (recovery oriented)– Detect and correct misclassification
Approach 2 (error masking)–Mask errors by using multiple
versions of classifiers
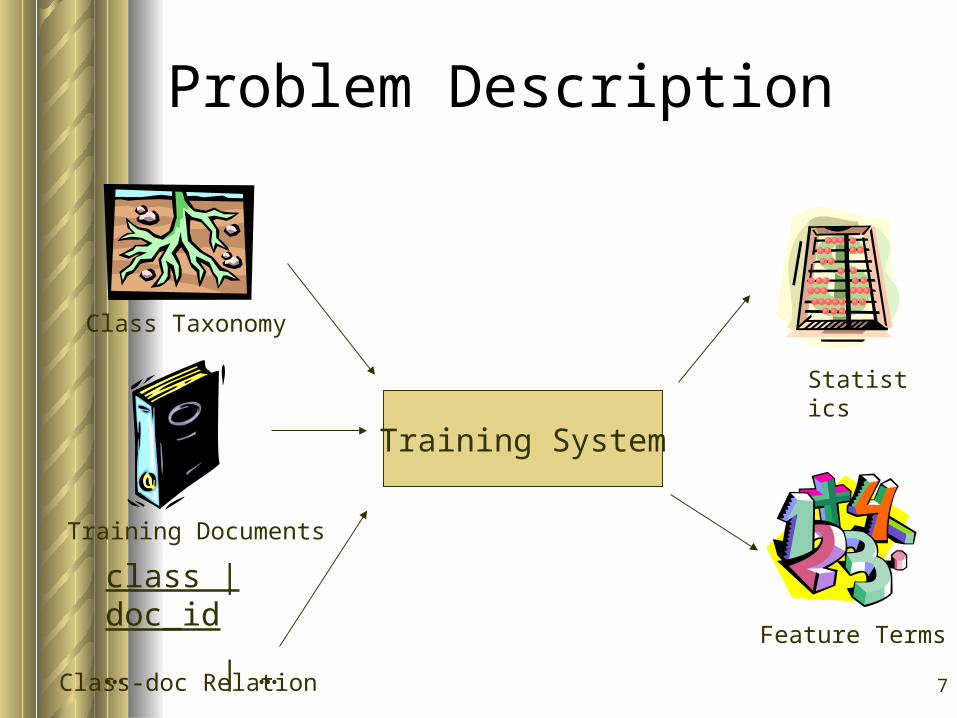
7
Problem Description
class | doc_id
… | …
Class Taxonomy
Training Documents
Class-doc Relation
Training System
Statistics
Feature Terms
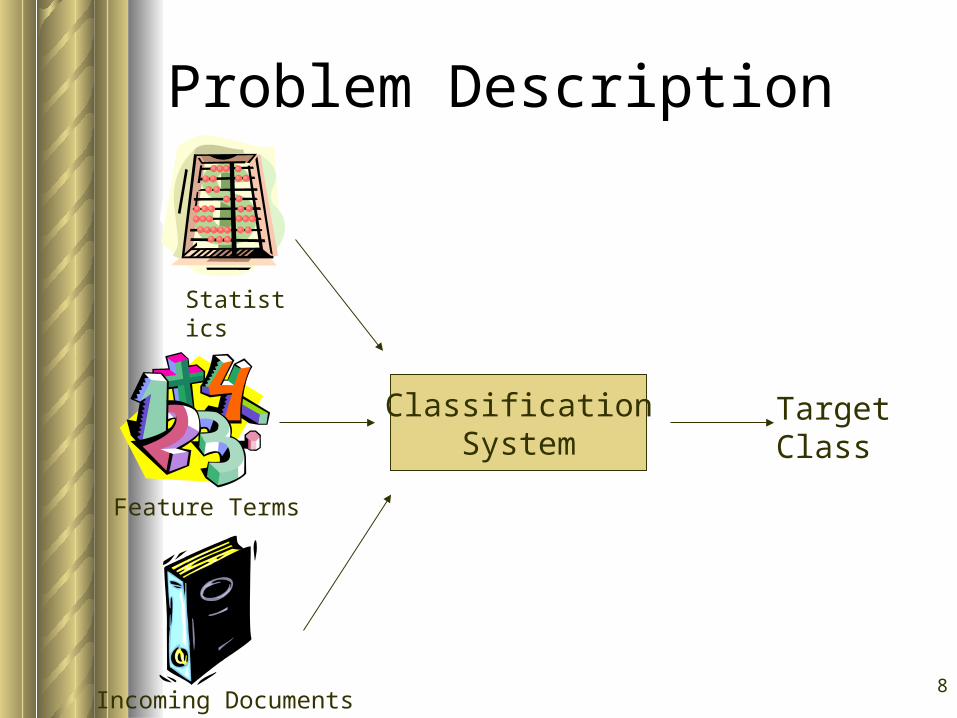
8
Problem Description
ClassificationSystem
Statistics
Feature Terms
TargetClass
Incoming Documents

9
Problem Description
Objective: Achieve
– Higher accuracy
– Fast performance
Our proposed algorithms provide a good trade-off between accuracy and performance

10
Document Classification Model
Formally, we use a model from [Chakrabarti et al. 1997]
Based on naive Bayesian networkFor simplicity, we study a single
node classifier.
c
c1 c2 … cn

11
zi,d — number of occurrence of term i in the incoming document d
Pj, c — probability that a word in class c is j(estimated using the training data)
c
dj
c
n
j
zcj
dndd
d pzzz
hcdP
1,
,,2,1
,
!!!
!)|(
q
jjj
iii
cdPcP
cdPcPdccP
1
)|()(
)|()(),|(
Probability that an incoming document d belongs to c is

12
Feature Selection
Previous formula involves all the terms
Feature selection reduces cost by using only the terms with good discriminating power
Use the training sets to identify the feature terms

13
Fisher’s Index
Fisher’s Index indicates the discriminating power of a term
Good discriminating power: large interclass distance, small intraclass distance
l
i cdi
i
l
iii
i
ctwdtwc
ctawctawc
ctFisher
1
2
1
2
))),(),((||
1(
)),(),((||
distance Intraclass
distance Interclass
),(
c1 c2 w(t)
Interclass distance
Intraclass distance

14
Document Classification Model
Consider only feature terms in the classification function p(ci|c,d)
Pick the largest probability among all ci
Use one classifier in each internal node
c
c1 c2 … cn

15
Recovery Oriented Scheme
Database system– Failure in DBMS– Restart from a consistent state
Document classification– Error detected– Restart from a correct class (High
Confidence Ancestor, or HCA)

16
Recovery Oriented Scheme
In practice,– Rollback is slow– Identify wrong paths and avoid them
To identify wrong paths,– Define closeness indicator (CI)
– On wrong path, when CI falls below a threshold
HCAi
idPHCAiP
cdPHCAcPHCAdcPHCAcdCI
)|()|(
)|()|(),|()|,(

17
Recovery Oriented Scheme
Define distance of HCAand current node = 2
Wrong path
HCA
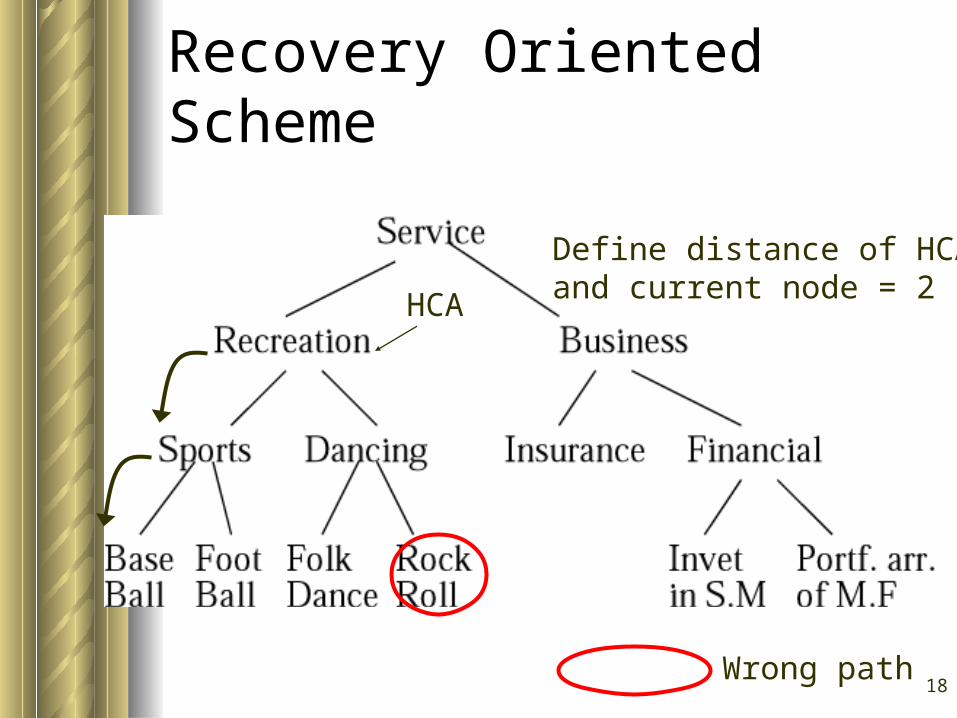
18
Recovery Oriented Scheme
Wrong path
HCA
HCA
Define distance of HCAand current node = 2

19
Error Masking Scheme
Software Fault Tolerance
– Run multiple versions of software
–Majority voting
Document Classification
– Run classifiers of different designs
–Majority voting

20
O-Classifier
Traditional classifier
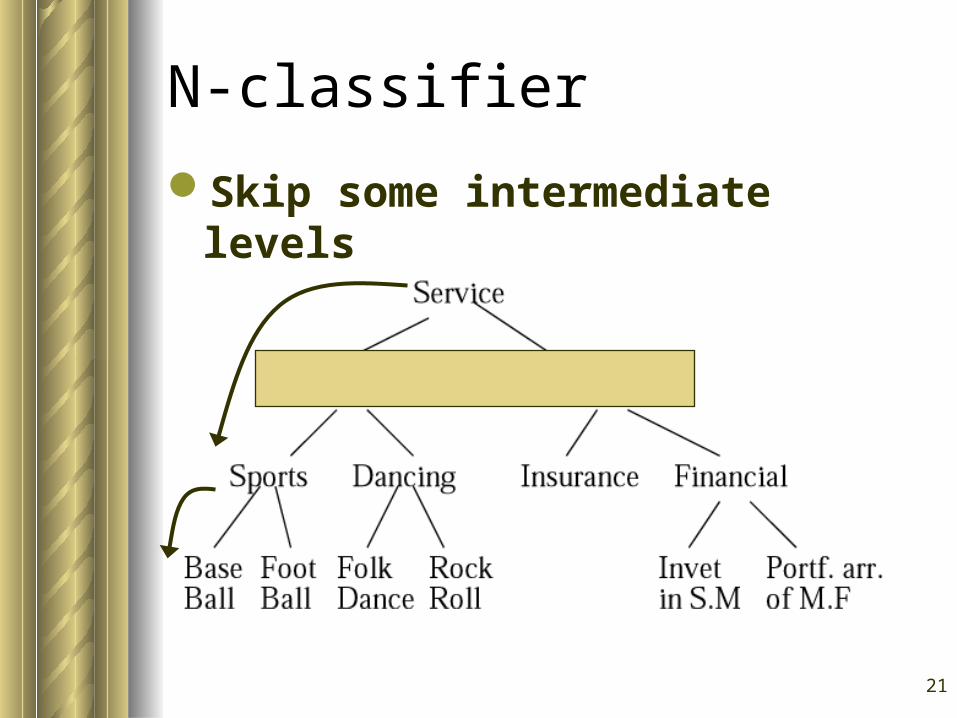
21
N-classifier
Skip some intermediate levels

22
Error Masking Scheme
Run three classifiers in parallel– O-classifier– N-classifier– O-classifier using new feature length
This selection minimizes the time wasted on waiting the slowest classifiers

23
Experiments
Data Sets– US Patents• Preclassified• Rich text content• Highly hierarchical
3 Sets Collected– 3 levels/large no of docs– 4 levels/large no of docs– 7 levels/small no of docs

24
Experiments
Algorithm compared– Simple hierarchical– TAPER– Flat– Recovery oriented– Error masking
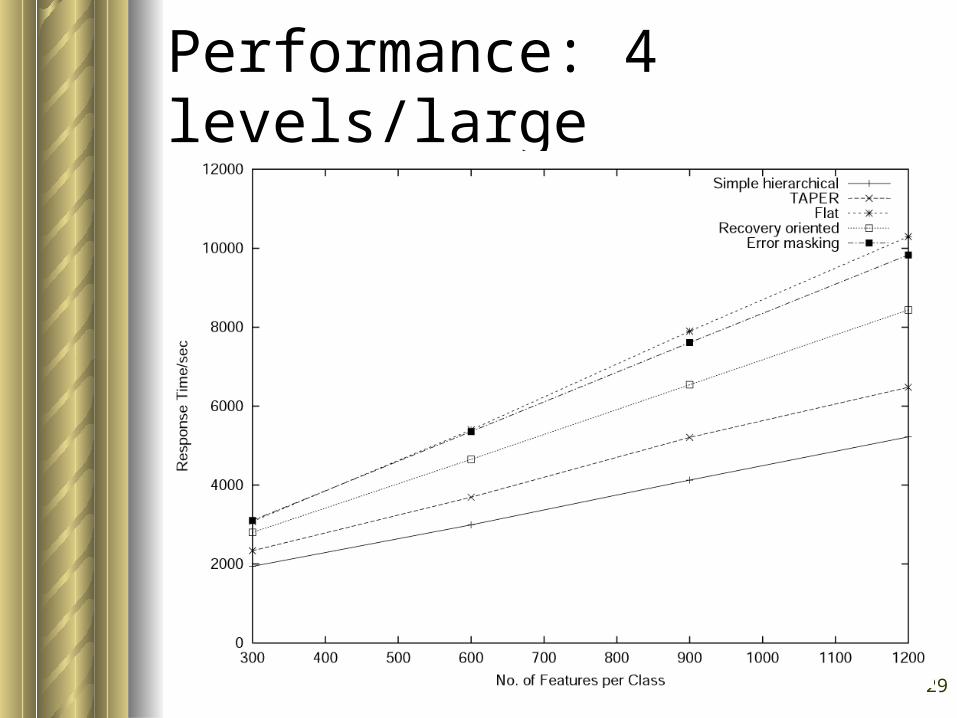
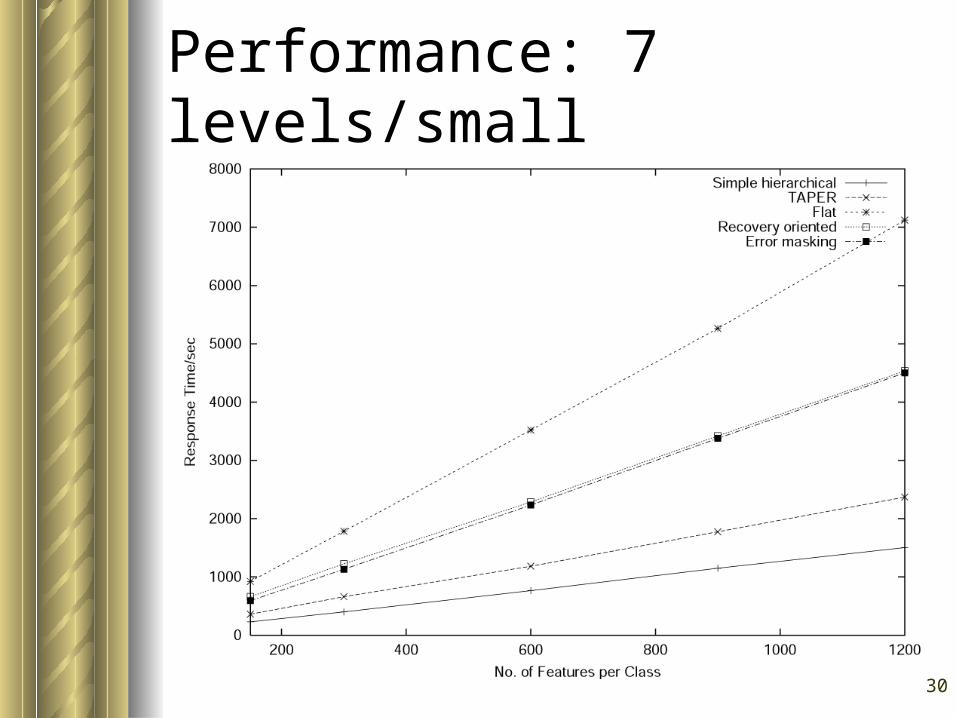
Generally, – flat is the slowest and the most accurate– simple hierarchical is the fastest and the
least accurate
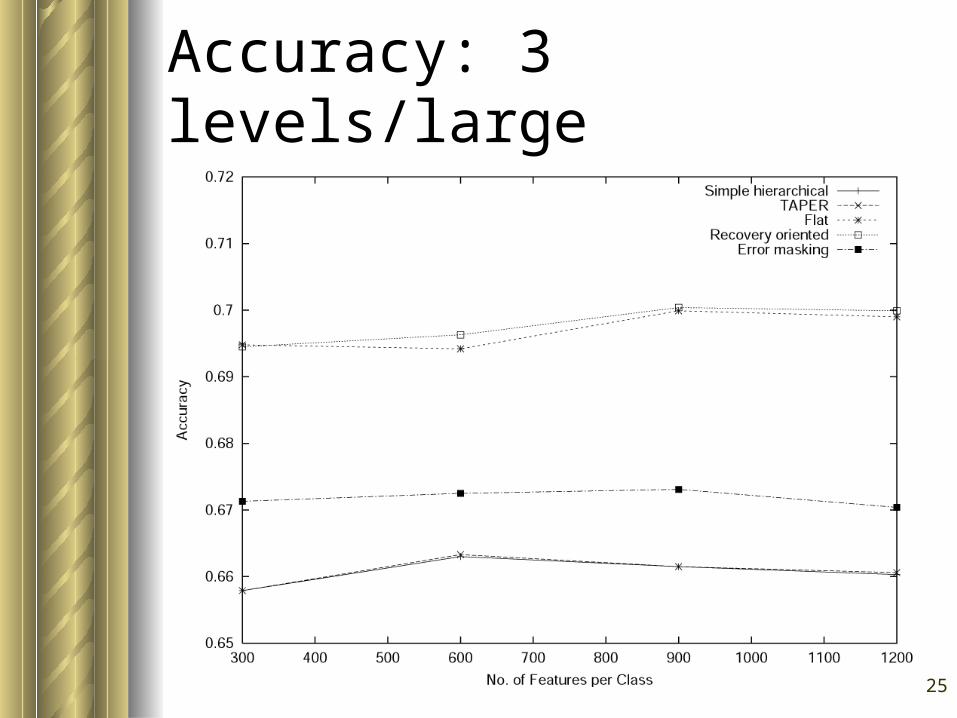
25
Accuracy: 3 levels/large
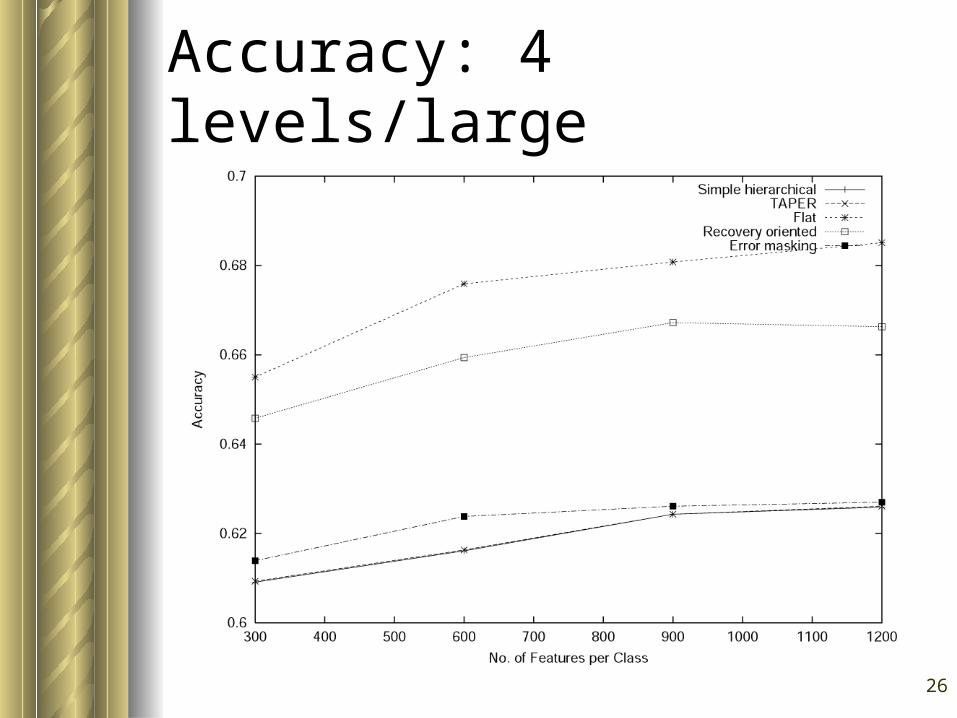
26
Accuracy: 4 levels/large
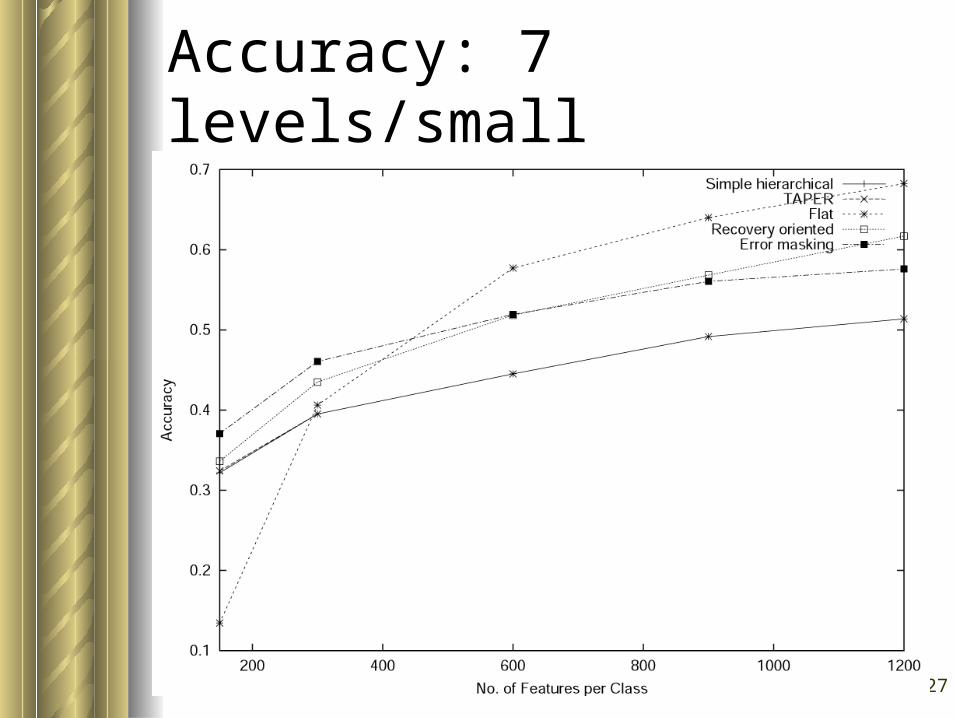
27
Accuracy: 7 levels/small
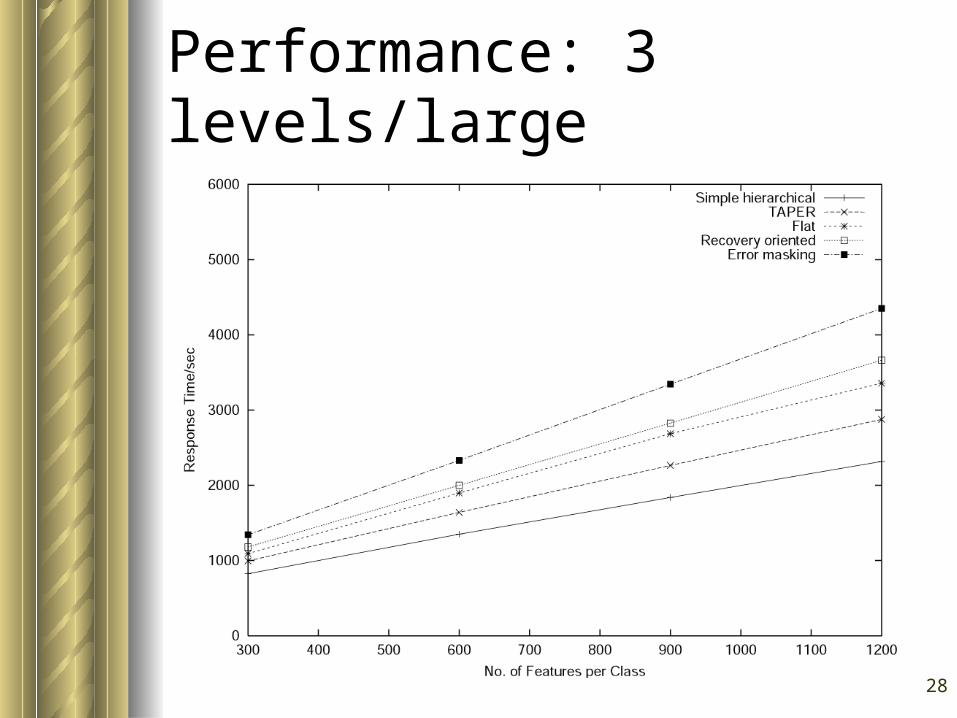
28
Performance: 3 levels/large
29
Performance: 4 levels/large
30
Performance: 7 levels/small

31
Conclusion
Real-life application– Large taxonomy– Flat classification is too slow
Our algorithm is faster than flat classification at as low as 4 levels
Performance gain widens as the number of levels increases
A good trade-off between accuracy and performance for most applications

32
Thank You
The End