1 improved speaker adaptation using speaker dependent feature projections spyros matsoukas and...
TRANSCRIPT

1
Improved Speaker Adaptation Using Speaker Dependent Feature
Projections
Spyros Matsoukas and Richard Schwartz
Sep. 5, 2003
Martigny, Switzerland

2
Overview
Baseline system
Technical background– Heteroscedastic Linear Discriminant Analysis (HLDA)– Constrained Maximum Likelihood Linear Regression (CMLLR)– Speaker Adaptive Training using CMLLR (CMLLR-SAT)
HLDA adaptation
SAT using HLDA adaptation (HLDA-SAT)
Results
Conclusions

3
Baseline SI system description
PLP front-end, speaker turn based cepstral mean normalization
HLDA used to find ‘optimal’ feature space– Original space consists of 14 cepstral coefficients and energy,
plus their first, second and third derivatives (60 total dimensions)
– Reduced space has 46 dimensions
Trained three gender independent (GI) HMMs:– Phonetically tied mixture (PTM), within-word triphone model– State Clustered Tied mixture (SCTM) within-word quinphone
model– SCTM cross-word quinphone model
Estimated separate HLDA transforms for each model

4
HLDA
HLDA is being adopted by many state of the art systems– Like LDA, its goal is to find a feature subspace where it is
easier to discriminate among a given set of classes– Unlike LDA, it does not assume that the class Gaussian
distributions have equal covariance matrix– Formulated within the ML framework
Many choices available for the definition of the classes– Phonemes, tied states, mixture components
Used the SCTM codebook clusters (HMM tied-states) as the classes in this work

5
CMLLR adaptation
Widely used adaptation method– Estimates a constrained linear transformation to adapt both
means and covariances of a set of Gaussians– Equivalent to transforming the input features using the inverse
transformation matrix– Reliable row-iterative estimation method is available when the
model to be adapted consists of diagonal covariance Gaussians
Formulation can be extended to handle full covariance Gaussians– Easy to compute objective function and first derivative– Used standard gradient descent methods to estimate the ML
transformation

6
Speaker Adaptive Training (SAT)
SAT brings speaker awareness to acoustic model reestimation– Extends set of model parameters by including speaker
dependent transformations– Reduces inter-speaker variability, resulting in more compact
acoustic models– Improves performance on test data, after speaker adaptation
Multiple flavors of SAT– MLLR-based, with transforms applied to model parameters
• Complicated update equations, hard to integrate with MMI– CMLLR-based, with transforms applied to features
• Transparently integrates with regular SI reestimation methods (ML, MMI, etc.)

7
CMLLR-SAT
Estimate HLDAfeature projection,
y = L x
SCTM xwordtraining using
features y
CMLLR adaptationz = As y
Train final PTM,SCTM models using
features z
Estimate HLDAmodel on features x

8
HLDA adaptation
Possible mismatch between training and testing acoustic conditions might reduce the effectiveness of HLDA
HLDA adaptation alleviates this problem by transforming the test features such that their statistics look more similar to training– Uses CMLLR in the full space, based on the single Gaussian
per tied state HMM– The CMLLR transform is then combined with the global HLDA
matrix in order to form speaker dependent projections– Most effective when applied to both training and testing

9
HLDA-SAT
Estimate HLDAmodel on features x
CMLLR adaptationw = Bs
xUpdate HLDA model
using features w
Estimate HLDAfeature projection,
y = L w
SCTM xwordtraining using
features y
CMLLR adaptationz = As y
Train final PTM,SCTM models using
features z

10
Experimental Setup
Trained gender-independent (GI), band-independent (BI) models on 145 hours of Broadcast News (BN) data, using ML– 6,300 tied states– 25.6 Gaussians per state
Trigram language model (LM), trained on 600M words– 13 M bigrams, 43M trigrams
Tested on h4e97 and h4d03 test sets– Automatic segmentation and speaker clustering– Two decoding passes
• Unadapted pass, generating hypotheses for adaptation• Adapted pass, using SI or SAT adapted models

11
Results-I
Effect of HLDA adaptation using SI models
HLDA adaptation
CMLLR MLLR h4e97 h4d03
17.6 18.6
15.6 16.5
15.4 15.7
14.4 15.3
Significant gain from HLDA adaptation, even on top of CMLLR and MLLR
12
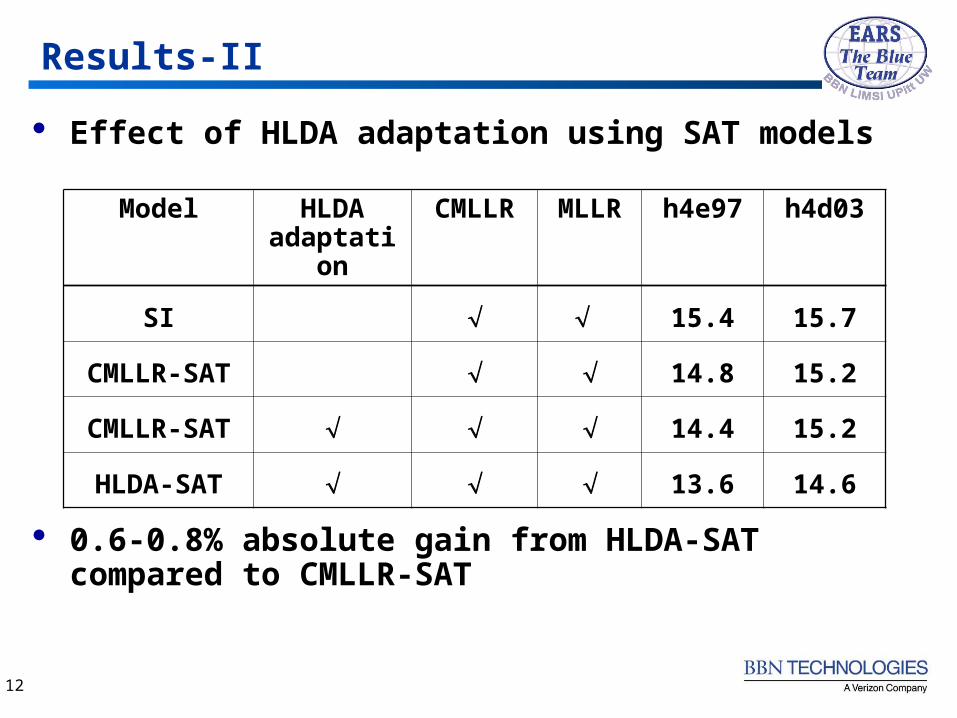
Results-II
Effect of HLDA adaptation using SAT models
Model HLDA adaptation
CMLLR MLLR h4e97 h4d03
SI 15.4 15.7
CMLLR-SAT 14.8 15.2
CMLLR-SAT 14.4 15.2
HLDA-SAT 13.6 14.6
0.6-0.8% absolute gain from HLDA-SAT compared to CMLLR-SAT

13
Understanding the improvements
HLDA-SAT extends CMLLR-SAT in two ways– Uses a single Gaussian per state (1gps) model to estimate
transforms in full space– Updates HLDA in transformed space
Which of the two has the largest effect in recognition accuracy?– 1gps model allows to estimate CMLLR transforms that move
the speakers closer to the canonical model– Reestimating HLDA in the transformed space results in
significantly higher objective function value
Tried two variations of HLDA-SAT, in which the SI HLDA is used– HLDA-SAT1: using 1gps-based CMLLR in reduced space– HLDA-SAT2: using 1gps-based CMLLR in full space

14
Results-III
Effects of HLDA update and full space transforms
Model h4e97 h4d03
CMLLR-SAT 14.4 15.2
HLDA-SAT1 14.1 14.6
HLDA-SAT2 14.0 14.9
HLDA-SAT 13.6 14.6
Most of the improvement from HLDA-SAT is due to using a 1gps model. The rest is due to updating the HLDA projection in the transformed space

15
HLDA-SAT on CTS data
Applied HLDA-SAT to English and Mandarin CTS with mixed results– 0.7% gain on Mandarin CTS– 0.1% gain on English CTS
Suspect problem with English CTS run, need more debugging to determine the cause of the poor performance

16
Conclusions
Significant gain from HLDA adaptation
Additional improvement from HLDA-SAT
Future work:– Find out why there is no gain from HLDA-SAT on English CTS – Extend method to use non-linear transformations