a dapt ist-2001-37126 middle-r: a middleware for dynamically adaptive database replication r....
Post on 22-Dec-2015
213 views
TRANSCRIPT

ADAPT IST-2001-37126
Middle-R: A Middlewarefor Dynamically Adaptive
Database ReplicationR. Jiménez-Peris, M. Patiño-Martínez, Jesús Milán
Distributed Systems
LaboratoryUniversidad Politécnica de Madrid (UPM)Lsd

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)2 ADAPT
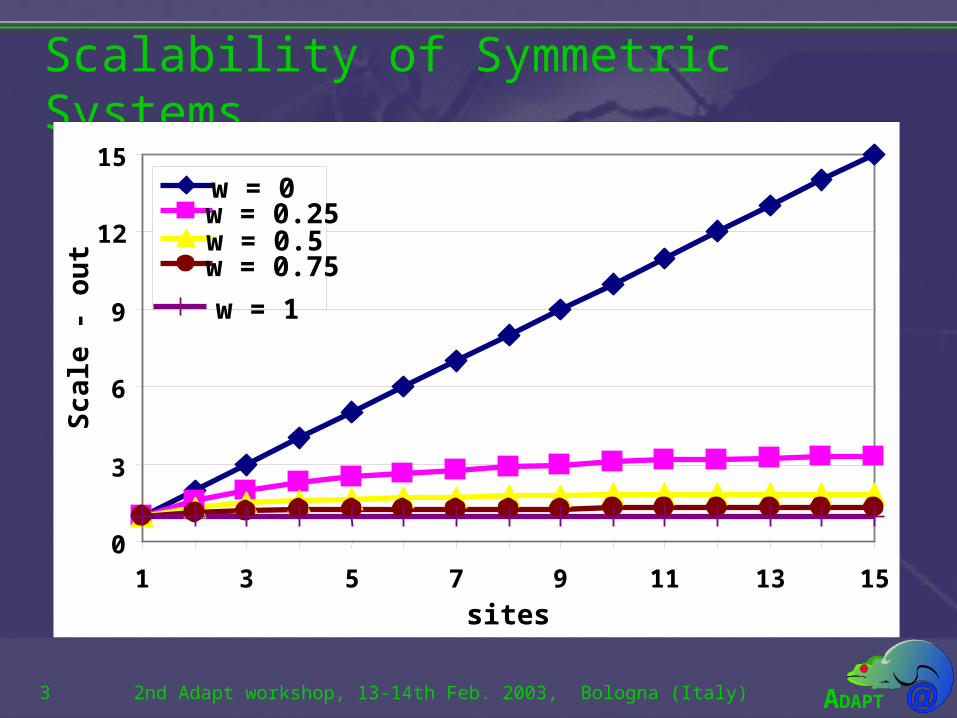
Symmetric vs. Asymmetric Processing
• Transactions in a replicated system can be processed either:– Symmetrically, that means, that all replicas process the
whole transaction.• This approach can only scale by introducing queries in the workload.
– Asymmetrically, that means, that one replica process the transaction and the other replicas just apply the resulting updates.
• This approach can scale depending the ratio between the cost of executing the whole transaction and the cost of just applying the updates.
2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)3 ADAPT
Scalability of Symmetric Systems
0
3
6
9
12
15
1 3 5 7 9 11 13 15
sites
Sca
le -
ou
t
w = 0w = 0.25w = 0.5w = 0.75
w = 1

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)4 ADAPT
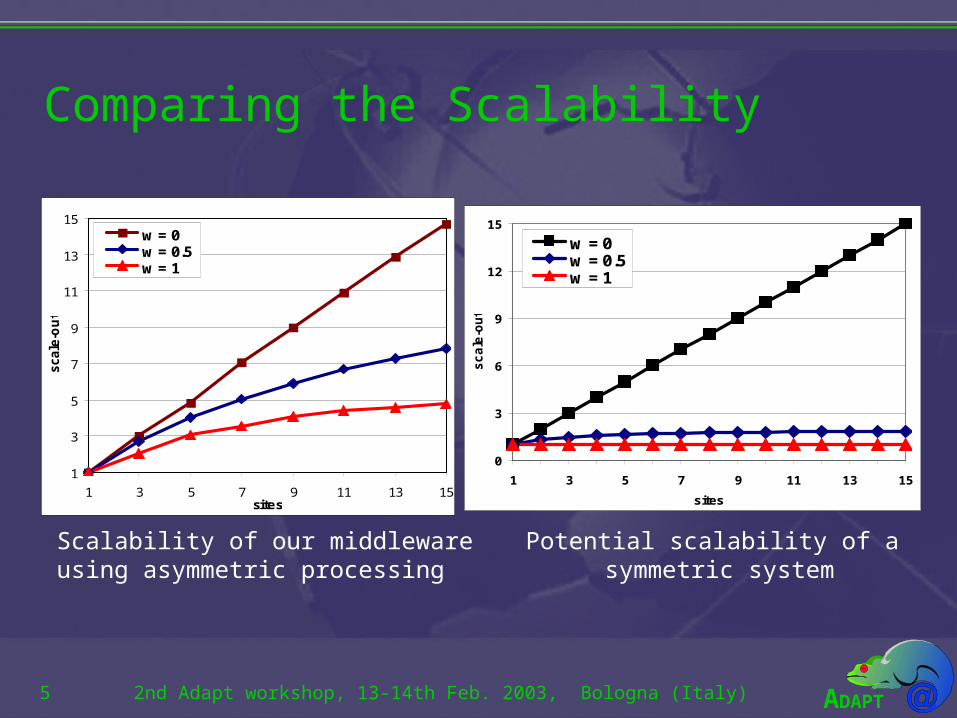
Scalability of Asymmetric Systems
Asymmetric SystemAsymmetric System
• The transaction is fully executed at its master site.• Non-master sites only apply the updates.• This approach leaves some spare computing powerthat enables the scalability
2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)5 ADAPT
Comparing the Scalability
1
3
5
7
9
11
13
15
1 3 5 7 9 11 13 15sites
scale
-ou
t
w = 0w = 0.5w = 1
Scalability of our middlewareusing asymmetric processing
Potential scalability of a symmetric system
0
3
6
9
12
15
1 3 5 7 9 11 13 15
sites
sc
ale
-ou
t
w = 0w = 0.5w = 1

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)6 ADAPT
Taxonomy of Eager Database Replication– White box. Modifying the database engine (Betinna’s
PostgresR [VLDB’00,TODS’00]).• It can use either symmetric or asymmetric processing.
– Black box. At the middleware level without assuming anything from the database (Yair Amir [ICDCS’02]).
• Inherently symmetric approach.
• Transactions are executed sequentially by all replicas.
– Gray box. At the middleware level based on the get/set updates services (our approach [ICDCS’02]).
• It can use symmetric processing.
• It can also use asymmetric processing provided two services from the database to get/set updates of a transaction. This the approach we have taken.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)7 ADAPT
Assumptions in Middle-R• Each site has the entire database (no partial replication).• Read one – write all available.• We work on a LAN.• Virtually synchronous group communication available.• The underlying database provides two basic services (i.e. similar to
the Corba ones):– get state: returns a list of the physical updates performed by a transaction, – set state: applies the physical updates of a transaction at a site.
• Our approach exploits the application semantics; we assume that the database is partitioned in some arbitrary way and that it is known which data partitions are going to be accessed by a transaction.– This allows us to execute transactions from different partitions in parallel.
Transactions spanning several partitions are also considered.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)8 ADAPT
ReplicaReplicamanagermanager
DBDB
Replica 4Replica 4
ReplicaReplicamanagermanager
DBDB
Replica 3Replica 3
ReplicaReplicamanagermanager
DBDB
Replica 2Replica 2
Replica Replica managermanager
DBDB
Replica 1Replica 1
Protocol Overview [Disc’00]
DatabaseDatabaselayerlayer
MiddlewareMiddlewarelayerlayer
GetStateGetState SetStateSetState SetStateSetState SetStateSetState
ClientClient
TransactionTransaction
Update propagationUpdate propagation

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)9 ADAPT
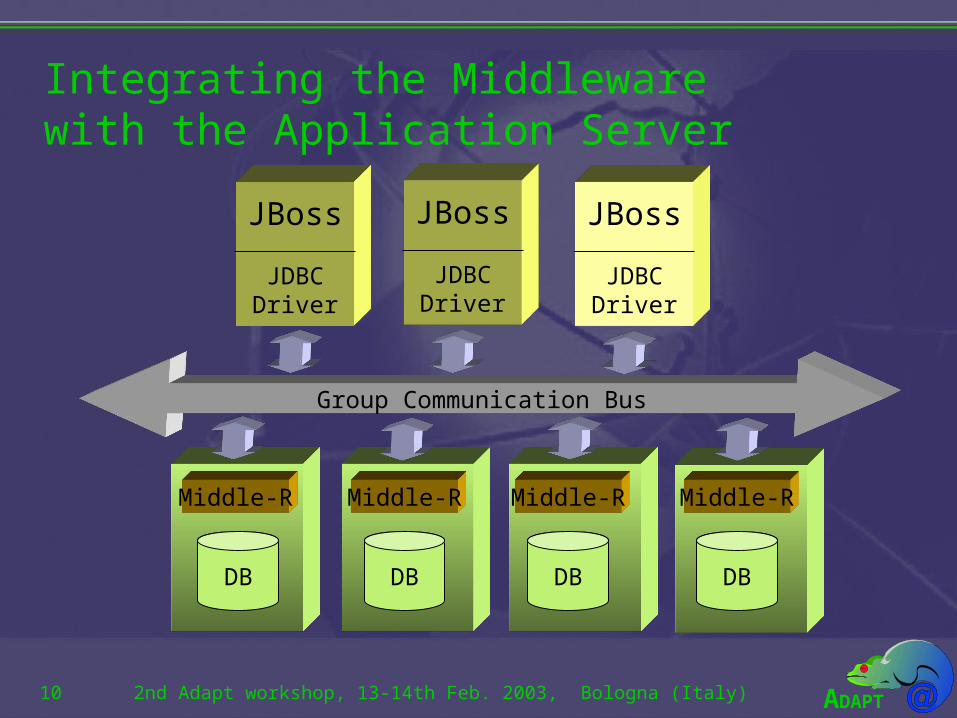
Integrating the Middleware with the Application Server• JBoss accesses databases through JDBC.• In order to integrate the middleware with JBoss it will
be necessary to develop a JDBC driver.• This JDBC driver will access the middleware by
multicasting requests to the middleware instances at each site.
2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)10 ADAPT
Integrating the Middleware with the Application Server
JBoss
JDBCDriver
DB
JBoss
JDBCDriver
JBoss
JDBCDriver
DB DB DB
Group Communication Bus
Middle-R Middle-R Middle-R Middle-R

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)11 ADAPT
Integrating the Middlewarewith the Application Server• If JBoss is replicated, some issues should be tackled with:
– Independently of the kind of replication in JBoss, duplicated requests might reach the replicated database.
• Active replication provokes the duplication of every request.• Other kinds of replication strategies might generate duplicate
requests upon fail-over (i.e., requests done by the failed primary might be resubmitted by the new primary).
– The middleware imposes the requirement to identify duplicate requests identically.
– The middleware, provided the above guarantee, will enforce the removal of duplicate requests.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)12 ADAPT
Automatic DB partitioning
• Middle-R exploits application semantics, that is, it requires to partition the DB in some arbitrary way and know in advance which partitions each transaction is going access.
• In our previous work, these partitioning was performed by the programmer. – For each stored procedure accessing the DB, a function was provided
that taking the parameters of the invocation determined the partitions that would be accessed by the stored procedure invocation.
• This is a limitation of the previous approach that has to be overcome in Adapt.– This DB partitioning should transparent to users and therefore
automatically performed on a partition per table basis (at least).

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)13 ADAPT
Automatic DB Partitioning
• The second issue is how to know in advance which partitions a particular transaction is going to access.
• Our new approach will analyze on-the-fly the submitted SQL statements to determine which partitions it will access.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)14 ADAPT
DB Interaction Model
• Our previous work assumed that each transaction was submitted in a single message to the middleware.– This model was suitable for working for stored procedures.
• However, this interaction model does not match with the one adopted by JDBC.– Under JDBC a transaction might span an arbitrary number of
requests.– Under JDBC a transaction might be distributed, so the XA
interface should be supported for distributed atomic commit.
• For this reason, we are extending the underlying replication protocol to deal with transactions spanning multiple messages.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)15 ADAPT
Dynamic Adaptability
• The following dynamic adaptability properties are considered:– Online recovery. Whilst a new (or failed) replica is being
recovered, the system continues its regular processing without disruption ([SRDS’02] approach that extend ideas from [DSN’01] to the middleware context).
– Load balancing. The masters of the different partitions are reassigned to balance the load dynamically.
– Admission control. Depending on the workload the optimal number of transactions active in the system changes. A limit of active transactions is dynamically adapted to reach the maximum throughput for each workload.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)16 ADAPT
Dynamic Adaptability: Online Recovery [SRDS’02]
• Recovery is performed on a per-partition basis.• Recovery is not performed during the state transfer associated to
the view change to prevent the blocking of regular requests.• Once a partition is recovered at a recovering replica, it can start
processing requests on that partition although the other partitions are not recovered yet.
• Recovery is flexible to enable load balancing policies to take into account the load of recovery:– The recovery can use one or more recoverers.– Each recoverer can recover one or more partitions.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)17 ADAPT
Dynamic Adaptability: Online Recovery• Replicas might recover in a cascading fashion.• The online recovery protocol deals efficiently with
cascading recoveries.• Basically, it prevent redundancies in the recovery process
as follows:– A replica that starts recovery, whilst the recovery of another
replica is underway, is not delayed till the whole recovery completes.
– Neither a new recovery is started in parallel (yielding redundant recoveries).
– Instead, this replica joins the recovery process with the next partition to be recovered.
– In this way, cascading recovering replicas share the recovery of common partitions.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)18 ADAPT
Dynamic Adaptability: Load Balancing
• The middleware approach has the advantage that every replica knows without any additional information the load of each other replica.
• This allows to achieve load balancing with very little overhead.• One of the main difficulties of load balancing is to determine
the current load of each replica.• We are currently modeling the behavior of the DB to be able to
determine dynamically the current load of each replica.• These models will enable the middleware to determine which
replicas become saturated, so its load can be redistributed.• The load is redistributed by reducing the number of partitions
that are mastered by an overloaded replica.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)19 ADAPT
Dynamic Adaptability:Load Balancing during Online Recovery• The load balancing will also control the online recovery
to adapt it to the load conditions.• When the system load is low it will increase the resources
devoted to recovery to accelerate it taking advantage of the spare computing resources.
• When the system load increases it will dynamically decrease the resources devoted to recovery to cope with the new load.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)20 ADAPT
Dynamic Adaptability: Admission Control
• The maximum throughput for a workload is reached with a given number of concurrent transactions in the system.
• Once this threshold is exceeded the DB begins to thrash.• This threshold is different for each workload so it needs to be
dynamically adapted to achieve the maximum throughput for the changing workload.
• The middleware has a pool of connections with the DB, and it can control the transaction admission to attain the optimal degree of concurrency.
• We are developing behavior models that will enable us to find dynamically the thrashing point and adapt dynamically the threshold in the admission control.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)21 ADAPT
Wide Area Replication
• The underlying protocols in the middleware are amenable to be used in a WAN.
• We are currently studying which new requirements are needed in a WAN to find problems that might require changes in the protocols.
• Replication across a WAN help to survive catastrophic failures and it is also needed by many multinational companies with branches spanning different countries.– For the former scenario we contemplate a replica at each geographic
location.– For the latter scenario we contemplate a cluster at each geographic
location.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)22 ADAPT
Partial Replication• Scalability in the middleware, although good, is
limited due to the overhead induced by propagating the updates to all the replicas (see [SRDS’01] for an analytical model determining the precise scalability of the approach).
• This limitation can be overcome by means of partial replication.
• In this way, each partition can be dynamically replicated to the optimal level.
• However, partial replication introduces new complications such as queries spanning multiple partitions that cannot be performed on a replica that do not hold a copy of all the accessed partitions.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)23 ADAPT
Conclusions
• Extensions to our previous work and the JDBC driver will enable the use of our middleware approach to provide dynamically adaptable DB replication for JBoss.
• The flexibility of the middleware approach enable us to contribute on different issues regarding dynamic adaptability such as online recovery, dynamic admission control, dynamic load balancing, changing dynamically the degree of partial replication, etc.
2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)24 ADAPT
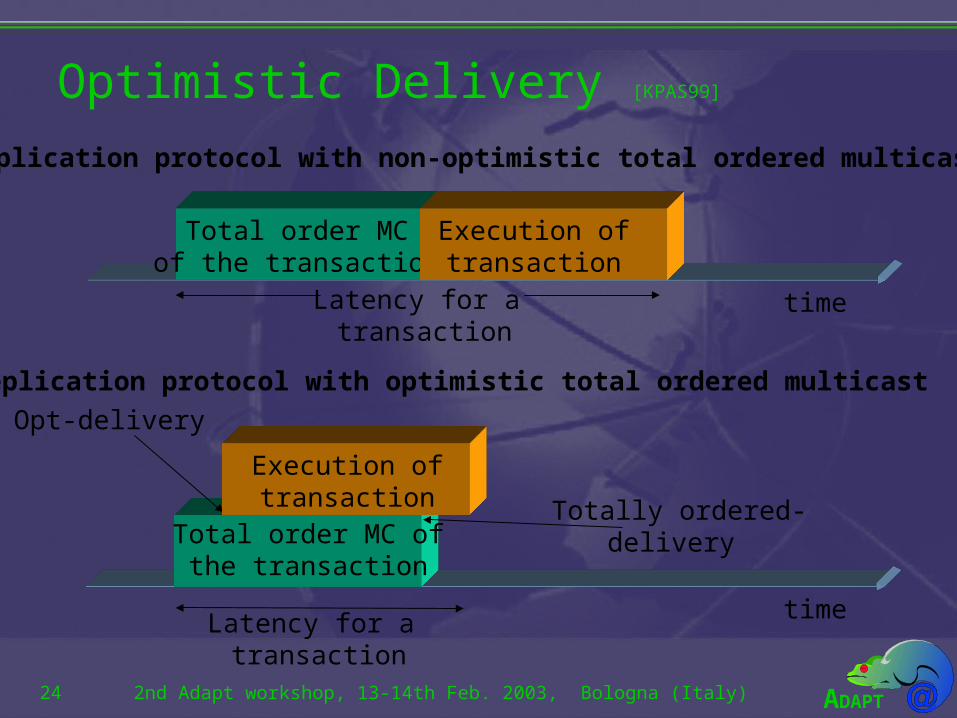
Optimistic Delivery [KPAS99]
Total order MCof the transaction
timeLatency for a transaction
Execution of transaction
a) Replication protocol with non-optimistic total ordered multicast
Opt-delivery
time
Total order MC ofthe transaction
Totally ordered-delivery
Execution oftransaction
Latency for a transaction
b) Replication protocol with optimistic total ordered multicast

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)25 ADAPT
Advantages of optimistic delivery
• For the optimism to create problems two things must happen at the same time:– Messages get out of order (unlikely in a LAN).– The corresponding transactions conflict.
• The resulting probability is very low and we can make it even lower (transaction reordering at the primary).
• Cost of group communication minimized.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)26 ADAPT
Experimental set up
• Database: PostgreSQL.
• Group communication Ensemble.
• Network: 100 Mbit Ethernet.
• 15 database sites (each SUN Ultra 5, Solaris).
• Two kinds of transactions were used in the workload:– Queries (only reads).
– Pure updates (only writes).

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)27 ADAPT
Experiments
• #1: using replication does not make the system worse.• #2: adding more replicas increases the throughput of
the system.• #3: the increase in throughput does not affect the
response time.• #4: acceptable overhead in worst case scenarios.
The dangers of replication:none of these statements
is true in conventionaleager replication protocols.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)28 ADAPT
1. Comparison with Distributed Locking
Standard Distributed Locking vs. Scalable Replication
0100200300400500600700800
1 3 5 7 9 11 13 15
Sites
Re
sp
on
se
Tim
e
(ms
)
Standard Distributed Locking (5 upd)
Scalable replication (5 upd)
Distributed lockingdegrades very fastwith an increasing number of replicas
Our middleware response time is
stableLoad 5 tps

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)29 ADAPT
Throughput Scale-out
1
3
5
7
9
11
13
15
1 3 5 7 9 11 13 15
sites
scal
e-o
ut
0% upd
50% upd
100% upd
2. Throughput Scalability
Scalability of 1/2 the nominal capacity
Scalability of 2/3 the nominal capacity
15 tps
225 tps
2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)30 ADAPT
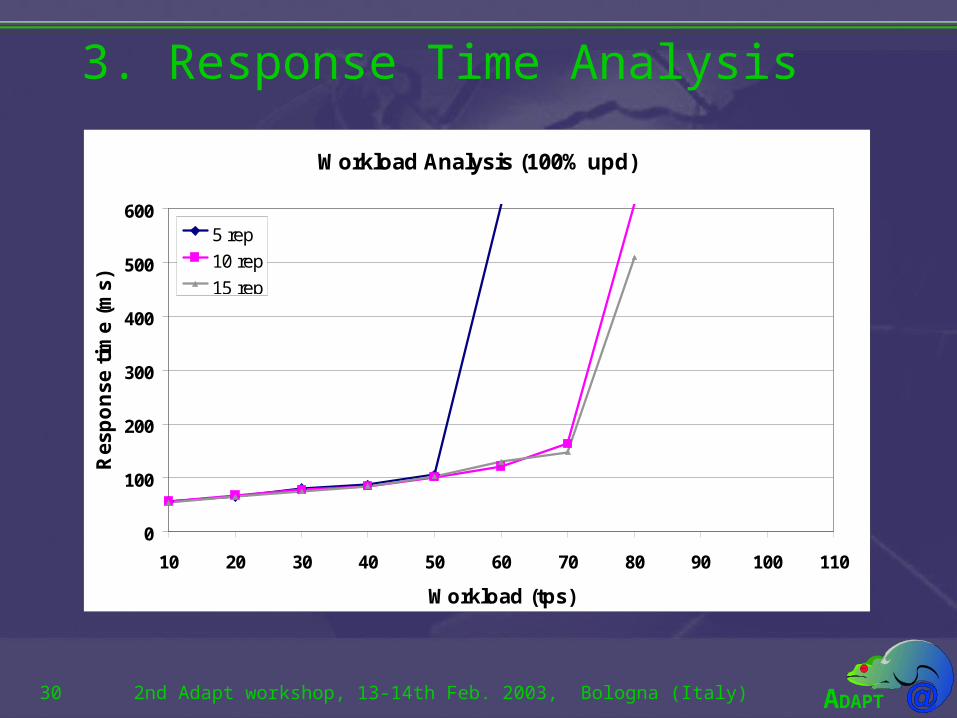
3. Response Time Analysis
Workload Analysis (100% upd)
0
100
200
300
400
500
600
10 20 30 40 50 60 70 80 90 100 110
Workload (tps)
Res
po
nse
tim
e (m
s)
5 rep
10 rep
15 rep
2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)31 ADAPT
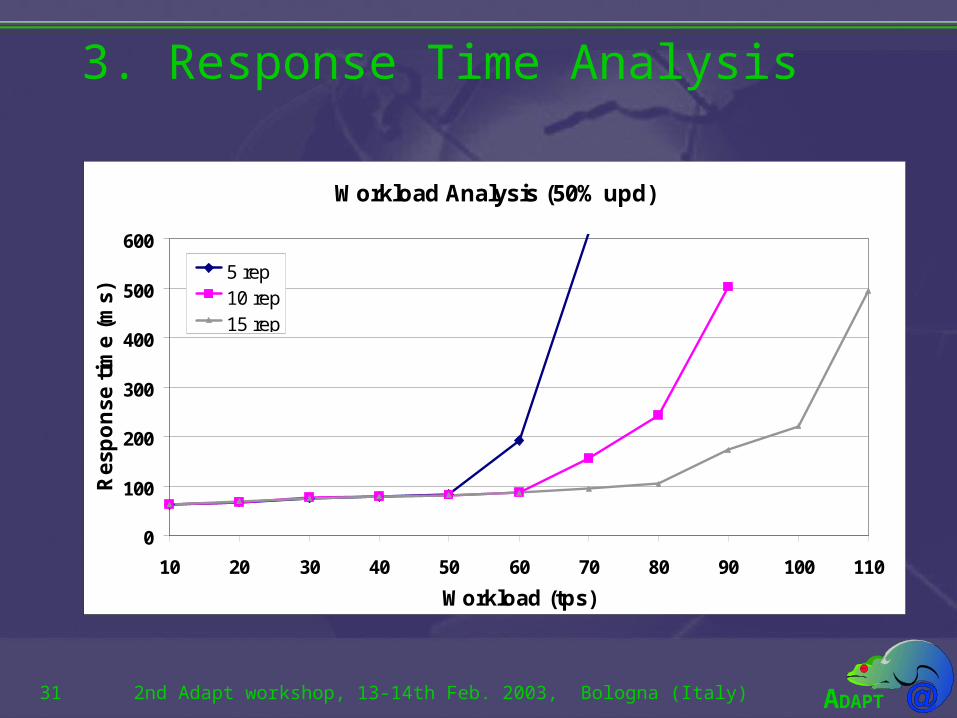
3. Response Time Analysis
Workload Analysis (50% upd)
0
100
200
300
400
500
600
10 20 30 40 50 60 70 80 90 100 110
Workload (tps)
Res
po
nse
tim
e (m
s)
5 rep10 rep15 rep

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)32 ADAPT
3. Response Time Analysis
Workload Analysis (0% upd)
0
100
200
300
400
500
600
10 20 30 40 50 60 70 80 90 100 110
Workload (tps)
Resp
on
se t
ime (
ms)
5 rep10 rep15 rep

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)33 ADAPT
4. Coordination overhead
Small Transactions
0
100
200
300
400
500
600
20 50 80 110 140 170 200 230 260
Workload (tps)
Re
sp
on
se
Tim
e (
ms
)
5 rep
10 rep
15 rep

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)34 ADAPT
Conclusions
• Consistent replication can be implemented at the middleware level.
• Achieving efficiency requires to understand the dangers of replication:– Only one message per transaction
– Asymmetric system
– Reduce communication latency
– Reduce abort rates
• Our system demonstrates different ways to address all of these problems.
2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)35 ADAPT
Ongoing work
• We are using the middleware to implement replication in object containers (e.g. J2EE, Corba).
• Tests are underway to use the system to implement replication across the Internet.
• Porting system to Spread [Amir et al.].• Load balancing for web servers based on replicated databases.• Online recovery and dynamic system reconfiguration:
– DSN 2001 [Kemme, Bartoli, Babaoglu].– SRDS 2002 [Jimenez, Patiño, Alonso].
2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)36 ADAPT
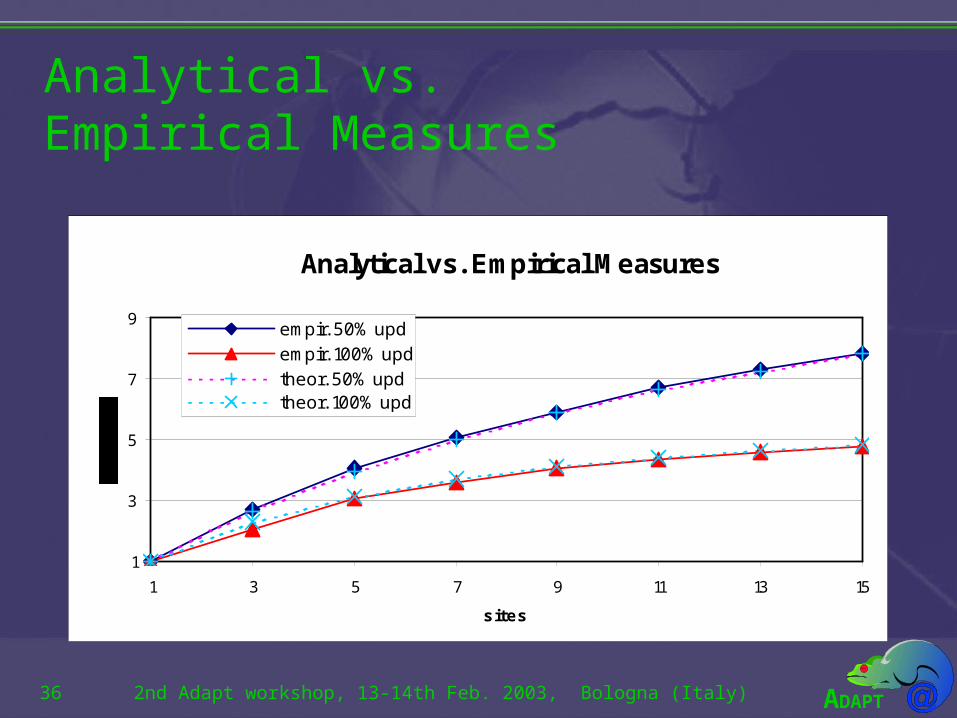
Analytical vs. Empirical Measures
Analytical vs. Empirical Measures
1
3
5
7
9
1 3 5 7 9 11 13 15
sites
empir. 50% updempir. 100% updtheor. 50% updtheor. 100% upd

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)37 ADAPT
How can the middleware performwith faster databases?
• The 1 upd transaction took 10 ms to be executed, whilst an 8 upd transaction took 55 ms.
• This means that in a faster database for transactions lasting within these ranges we can obtain similar scalabilities (till some bottleneck is reached, most likely group communication).
• The determinant factor of scalability is the ratio of the cost of executing a full transaction and applying its updates, but this factor, although can be reduced, will be always significant (in Postgres for 8 upd transactions it was 0.16 and for 1 upd transactions it was 0.2).

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)38 ADAPT
Background
• Replication has been used for two different and exclusive purposes in transactional systems:– To increase availability (eager replication) by providing redundancy at
the cost of throughput and scalability.– To increase throughput and scalability by distributing the work among
replicas (lazy replication) at the cost of consistency.• We want both availability and performance.• However, Gray in “The Dangers of replication” SIGMOD’96
stated that eager replication could not scale.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)39 ADAPT
Motivation
• Postgres-R [KA00] showed how to combine database replication with group communication to implement a scalable solution within a database.
• We extended this work [PJKA00] by exploring how to implement replication outside the database:– Protocol is provably correct.– Could be implemented as middleware.– It scales (e.g. adding more sites increases the capacity).
• In this talk we discuss the performance of such protocol as implemented on a cluster of computers connected through a LAN and show that it can be used in a wide range of applications.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)40 ADAPT
Eager Data Replication
• There is a copy of the database at each site.• Every replica can perform update transactions
(update everywhere).• Transaction updates must be propagated to the rest
of the replicas.• Queries (read only transactions) are executed at a
single replica.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)41 ADAPT
Understanding the Scalabilityof Data Replication
Each transaction executed by a site induces a load of one Each transaction executed by a site induces a load of one transaction on each other sitetransaction on each other site
Assume sites with a processing capacity of 4 tpsAssume sites with a processing capacity of 4 tps
Symmetric SystemSymmetric System
The capacity of the system is at most the capacity of a single site: 4 tpsThe capacity of the system is at most the capacity of a single site: 4 tps

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)42 ADAPT
Asymmetric Systems
• In an asymmetric system the work performed by a replica consists of:– Local transactions, i.e., transactions submitted to the
replica.
– Remote transactions, i.e., update transactions submitted to other replicas.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)43 ADAPT
A Middleware Replication Layer
Group CommunicationGroup Communication
PostgreSQLPostgreSQL
QueueQueueManagerManager
Client AClient A Client BClient B
CommunicationCommunicationManagerManager
ConnectionConnectionManagerManager
ReplicaReplicaManager XManager X
PostgreSQLPostgreSQL
QueueQueueManagerManager
Client CClient C Client DClient D
CommunicationCommunicationManagerManager
ConnectionConnectionManagerManager
ReplicaReplicaManager YManager Y

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)44 ADAPT
A Middleware Replication Layer
• The replication system has been implemented as a middleware layer that runs on top of off-the-shelf non-distributed databases or other data stores (e.g., an object container like Corba).
• This layer only requires two simple services from the underlying data repository:– get state: returns a list of the physical updates performed by a
transaction,
– set state: applies the physical updates of a transaction at a replica.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)45 ADAPT
Exp. 1: Comparison with Distributed Locking• In this experiment we compared our system with a commercial
database using distributed locking and eager replication to guarantee full consistency of the replicas.
• A small load of 5 transactions per second was used for this experiment.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)46 ADAPT
Response Time Analysis
• The goal of this experiment is to show that transaction latency keeps stable with loads within the scalability interval.
• For each configuration and update rate, the load is increased until the response time degenerates.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)47 ADAPT
Exp. 2: Throughput Scalability
• This experiment tested how the throughput of the system varies for an increasing number of replicas.
• In particular, we wanted to know the power of the cluster relative to a single site.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)48 ADAPT
Measuring the Overhead
• The latency of short transactions is extremely sensitive to any overhead.
• The goal of this experiment is to measure how the response time was affected by the overhead introduced by the middleware layer.
• In this experiment the shortest update transaction was used: a transaction with a single update.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)49 ADAPT
Motivation and background
• Eager replication is the text book approach to achieve availability …
• Yet, very few database products provide consistent replication.
• The reasons were explained by Gray in “The Dangers of replication” SIGMOD’96.
• Postgres-R [KA00] showed how to avoid these dangers and implement eager replication within a DB.– Combines transaction
processing and group communication.
– Uses asymmetric processing
– Showed how to embed these techniques in a real database engine.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)50 ADAPT
Motivation and Background
• A subsequent approach explored scalable eager DB replication outside the DB, at the middleware level [Disc00,ICDCS’02].
• Experiments showed that it was possible to achieve replication at the middleware level with a scalability close to the one achieved within the database.

2nd Adapt workshop, 13-14th Feb. 2003, Bologna (Italy)51 ADAPT
Two Crucial Issues
• Processing should be asymmetric– Otherwise it does not scale …
– … but difficult to do outside the database
• Avoid the latency introduced by group communication (especially for large groups)– Otherwise the response time suffers …
– … but we need the group communication semantics