a distributed solver for compressible flows renato …
TRANSCRIPT

TICAM REPORT 96-53November 1996
A Distributed Solver for Compressible Flows
Renato Simoes Silva and Regina C. Almeida

A Distributed Solver for CompressibleFlows
Renata S. Silva1 * Regina C. Ahneicla *
Labora.t6rio Nacional de Computa~ao C:ientfficaRna Lauro Miiller, 4.5.5,:22290-IGO - Rio de .Janeiro, Brazil
I COPPE - UFR.J
Abstract
SupercOlnputers nowadays can be used to solve large-scale prob-lems that come from simulation of industrial or research problems.However. those machines are usually inacessible to most industriesand university laboratories around the world. In this work we presenta. compressible flow solver to be used in a collection of workstationsunder PVM that can overcome t.he use of direct methods on a singleprocessor.
KEY WORDS distributed system; finite element method: com-pressible fows; Petrov-Galerkin formulation.
INTRODUCTION
In the last years, with the advent of successful discretization methodsand powerful computer technologies, computer simulation has been seen asa valuable approach to be combined with experimental methods to solve
'Visiting Scholars from TICAM - Texas Institute of Computational and Applied Math-ematics, The University of Texas at Austin. During the course of this work the authorswere supported by the Brazilian Government fellowship CNPq proc. 201387/93-0 and200289/93-4, respectively.
1

industrial and scient.ihc problerlls. In t.his work we arc interested in thenumerical simulation of compressible flows for which we have to deal withlarge. sparse and Ilon-synunetric systems. For these types of problems thecomputational cost and the accurac.y are the major concerns. Obviously, theaccuracy is related with the appropriate choice of the llulllerical method tosolve these equations.
Ideally, the numerical method to soh'f' the compressible Euler a.nd NavierStokes equations should have good COilvergence properties and should be sta-ble ill the presence of shocks: in those regions of the fluid flow. the variablesin the system vary strongly, making the cOlnput.ation very challenging. Tnthat case, it is well known that the approximate solutioll obtained by us-ing the standard Galerkinhnite element met.hod is completely spoiled byspmious oscillations t.hat are spread all over the conlputatioua.l domain. Inorder to overcome 01'. at. lea.sL t.o minimize those oscillat.ions InaIl} meth-oels have been designed. A good st.ep to this direct.ion was the developmentof t.he Petrov-C:alerkin Finite Element models, \vhich modiry the Ga.lerkill'sweight.ing runctions by adding a perturbation term but. keeping the consis-t.ency property in t.he sense that the exact solution satisfies t.he approximateproblem. lVlor('over. t.he possibility of using discontinuous weighting fllnc-t.iolls, as first proposed with the sure: lVlethod (Streamline Upwind Pet.rovGalerkin Method) [1] to t.he scalar convection dominated problems, openeda fascinating way to cont.rol the instabilities often present in approximate so-lutions with steep gradients. For the systems or equations, t.he perturbationterm in this met.hod acts only in the generalized streamline direct.ion, chosenas the upwind direction [2]. As its scalar counterpart, the result.ing methodhas good stability and accuracy properties if the exact solution is regular[:3]. However, for non-regular solutions, those propert.ies only worth out of aneighborhood containing sharp gradients, where spurious oscillations remain.
Considerable success has been achieved using the concept of generalizedapproximate upwind direction, introduced by the CA LTMethod (ConsistentApproximate Upwind Method) for systems of equations [5, 6]. This ideayields a method that keeps the perturbation term over the generalized stream-line direction and adds, in a consistent way. allOther perturbation whichprovides the control over the derivatives in the direction of t.he genera.lizedapproximate gradienL avoiding completely spurious oscillations. Besides, theaccuracy is kept since the latter perturbation vanishes in the regions wherethe solution is regular. Those good properties lead us to choose this method
2

in this work t.o solve t.he compressible Euler and Navier St.okes equations.However, there still are the necessity of using an f'fficient solver to reduce thecomputational costs when large problems are concerned.
It is well known that iterative methods perform bet.t.er than direct meth-ods for large problems. but to determine the best iterative algorithm t.o solveadaptive Ilonlillear systcms is still an opcn isslle. \Vith the development ofparallel a.nd distributed machines Domain Decomposition Methods have beenrediscovered amI improved to deal wit.h a large class of problems. Amongthem the Overla.pping Schwarz i'vlcthod has becolllc a powcrl'ul tool becauseit. combines high degree or parallelism with simplicity.
A good solvcr means not only a choice of the best method but a combina-t.ion between the method and a fast ilnplelllent.at.ion. H.ecent.ly considerableat.t.ention has been focused in hcterogeneons dist.ribut.ed systems as a so-lution for high performance comput.at.ions. By definit.ion. a heterogeneousdistributed syst.em is a collection of differellt computers loosely connect.ed bya Local Area Net.work (LAN) or/ami a Wide Area Net.work (vVAN). The pop-ularity of these systems can be explained by the increasing performance andlower prices of high speed Iletworks and general-purpose workstations. ThismeallS that. is much chcaper to form and to maint.aiu t.hese systems t.han a.ma.ssively parallel machine (MPr-d) and. in cert.ain cases, their performancescan be similar.
Uillikely MP1Vls, het.erogeneolls distribnted systems call bc formed withdifferent types of proccssors and with different network t..ypes. Besides, theyare composed by general-purpose environments, which means that it. is pos-sible to have difFerent users running t.heir jobs in the machines of the system.As a consequence, the load of each machine and the network traffic can var.yat. each insta.nt and the choice of t.he communication pattern has to 1)(' donecarefully.
Thus. in this work, we present a distributed implementat.ion of an Addi-tive Schwarz Method, a.ccelerated b.y FG~In.ES(k). The experimental resultsof some compressible Euler and N avier Stokes problems show the perfor-mance of this algorithm running on a general purpose collect.ion of 16 IBMR.TSC 6000 workstations: it is possible to get satisfactory efiiciencies with arelative small number of degrees of freedom.
An outline or this paper is as follows. In section 2 the CAU method for thecompressible Euler and Navier Stokes equations employing entropy variahlesis presented. In section :3 the Additive Schwarz method a.nd the restarted

version of tbe FCMHES(k) method used t.o accek~r<l.t,ed t.he couvergence arediscussed. Section Idescribes 0\11' distributed illlpicillent.atioll of the methodsshown Oil previons sect.ions. Numerical results arc presented ill section.) andt.he conclusiolls arc drawn in section 6.
SIMULATION OF COMPRESSIBLE FLOWS
III this work we are interested in the lIumerical sinllda,t.ion of the st.eadystat.e solution of the two-dimensional compressible I~ulcr a.nd Navier Stokesequations. For such nOli-linear problerns, we get t.he steady state solut.ionfrom t.lle limit. solution of a time dependent. problem. \Ve shall use a st.ablePet.rov-Calerkin formulation. the Cil {T m.d/wrl. in order t.o prevent, inst.a-bilities whell sharp gradients are present.ed in the solut.ion. Here we onlyovcrview the CAU method for the compressible Navier Stokes equations tha.thas been det.ailed pre\'iously in [5, G].
Governing Equations
Using the V-entropy variables [7,8], the compressible Navier-Stokes equa-tions can be writ.ten in the following synunetric form:
(1)
where V = (\'j )~~) is the entropy variables vect.or,m is the lIumber of vari-
ables (In = 4 for the two-dimensional case): Ao = ~;~.~is a (In X In) symmetricand posit.ive-definit.e matrix: Ut = [(I, (I'll). (J'lf,2, (Ie] is the conserva.tion vari-ables vector; (I is the densit.y; 'lli is the velocity in jtil direct.ion, j = 1,2 ande is t.he t.otal energy density. iii = AiAO are symmet.ric, where Ai = ;~/r; ist.he .Jacobian matrix and Fi is the Euler flux defined as:
where bioi is the Kronecker delta, p = h' - 1)(1 [e - t 1'll12] is t.he thermody-namic pressure and I is the ratio of specific rates (, = ~ , where Cp is thespecific heat at constant. pressure and CI' is the specific h~~.t at. constant vol-ume; I = 1.4 for air). 'Vi
(-) = (rm;;~::'Im~~:D is t.he generalized gradient

operator where 1m is the J.!n x 171) ident.ity matrix. I{ is symmetric andpositive semi-definite wit.h [\'ij = KijAO' The matrix I,,' can be decomposedin two parts: [{ = I\'U + I\'h, where Ft = K:jU ..i and F/' = l<:bU,j, i,j = 1,2,are the viscous and heat. fluxes, respectively, given by
andF!' = {O, 0, 0, -qi} .
In those definitions, Tij is the viscolls stress and q is the heat. flux. Finally,,) is the source vect.or. III the following we consider the compressible Eulerequations as a particular case of t.he Navier-St.okes e<iuations when }i' andF/' vanish and there is 110 source term.
Approximate Solution - The CAD Method
We shall formulate the CA lJ method for (1) by usi Ilg the time-discontinuousC:alerkin method as the basis of our formulation. To this end, consider pa.r-titions 0 = to < I, ... < In < In+1 < ... of ~+ and denote by In = (tn, In+l)the nili time interval. The space-t.ime integra.tion dornain is the productOn = 0 X In' 0 C ~d = ~2, with boundary r = r x [no Denote by O~,de flh element. in On, C =1 (Ne)n' where (Ne)n is the total number of ele-ments in On. For 11 = O. 1.2 , let. us first introduce t.he set of kinematicallyad missi ble functions
and the space of admissi ble variations
where I' and p are the nonlinear boundary condition transformation, 9 is apl'escri bed boundary concl ihon and pk is the space of polynomia.ls of degreeless or equal to 1..:.
5

With these definitions. the variat.ional rormulat.ion nsiug the CA U methodconsists or:
Find Vh E S'~ such that. for 11 = O. 1,2 ... ,
(2)
is the approximat.ed solution residual. The terms in this equation CiUJ beidentified in order as the st.andard Galerkill t.enn, the SlJPC: term, t.hediscontilluity-captming t.erm provided by the CAU method allCl the jumpterm by which t.he information is propagat.ed from On to nn+I' The SUPCterm provides the control over the generalized streamline dircct.ioll and Uw(171 x m.) matrix or intrinsic t.ime scale T: is defined as in [9].
To completely overcome spurious oscillations when shocks are present.ed.the CAU term provides an additional contl'Ol over the derivatives in thedirection of the generalized approximate gradient. The auxiliary (nul x nl)matrix jjh is such that
t T·h nh '\7 T'h '\7 [ .., '\7 Tlh <] 0/to I/t + rJ • V 1/ - V • \ V I - It = ,
which together with (:3) yields
As presented in [5, 6], it. is possible to define the rank one tensor C,
C = (/:t - Oh) 0 (11- jjh) AQ" 1
6
(-l )
(5)
(6)

that must sat.isfy the generalized eigenvalue problem
CT = /\2 [/10] T : T _ VVh
IV,,/hl..10
(7)
I
where IVlIhl:\o = (V\/ht [Au] VVh) '1 deflot.es the modulus or vvl1 with
respect to a (nul x /)ul) lnatrix [Ao] = diug [/Iu. Au]. The eigenvalue /\ E ~+and t.he ma.trix Uf - 011) a.re uniquely delined conlbining (G) and (7) with:
zi.·lou = I
(,'1 - Oh) U = /\ [Ao] T ancl (i1 - 011) . VVh = £" . (8)
which yields
l£hl2:1;;-1
IVVhl~\oand
The matrix T,f: is thus defined as
II-I ,,/U=,o'-"
'£hl :\;;-1
if IVV/t,o =I 0:
i I' IVVhl = O . (9)..10
with
( to)
l£hl2 -I IV~VhI2..10 ..10
IV1/hI2 IV1/hI2..10 ..10
if (11 )
I (~ 'I,,)t [r-11 fu I'" .'16] f: I I I I' P' 1w 1erc v ~ = II.; Fix;' I....i Ei.7:i • "i are t 1e oca COOl'( Inates, e rs t IePeelet number and ((Pe) = coth Pe - 1/Pe.
In order to avoid the double eff'ect when t.he generalized approximategradient direction coincides with the generalized SUPe: direction, we should
7

subtract. the projection of the supe operator ill t.his direction (see [10. II]).Calling/Ie t.hc function t.o be designed t.o compensate this effect. it. shouldsat.isfy
Using now UJ). '/e is dct.ermined as
'/Ie (12)
(I,nd the resulting CAU t.el'lll can be writt.en now il.S
(N,)"
L 1. max{ 0e= I 0"
(I:~)
OVERLAPPING SCHWARZ METHOD
Domain deconlPosition algorithnls have been subjected t.o active rcscarcllin the last few years [12, 15, 17. 19, 22] due t.o t.he diffusion of parallel anddistributed machines. In t.his work we focus on the Overlapping Schwarz;Vlethods (OS1\'1). with emphasis on the additive version (ASM).
The main idea of the OSI'\'l is to solve large problems b,y dividing the origi-ua.1 domain n into a number of smaller overlapping subcloma.ins ni. which aresolved by an iterative procedure. It consists of solving the original problemin ea.ch su bdomaiu followed by t he exchange of the boundary condi tions onthe artificial interfaces created by the partition of the original doma.in. Thechoice of how these art.ificial boundary conditions are exchanged will definethe type of OSM used: the Additive 01' tIle Multiplicative versions.
In the Additive version. also called .Jacobi version, a.ll subdomains use thesolution of the last iteration as the boundary conditions. Thus. each sub-cloma.in can be solved independentl.y. On the other hand the Multiplicativeversion, also called C:a.uss-Sidel version. each subdomain uses the solution
8

of t.he others alr('ady eva.luat.ed as houndar.y condit.ions. In essence it. is ..1sC(l'lent.ial method and to oht.ain a pa.rallelism of t.his version is necessary tolise some subclomain coloring schemes, where independent. problems can beirltroduced and the number of sequent.ial st.ep call bc minimil':ed [12, 17,22].Considering t.hese facts. t.he Addit.ive version is nsed in t.his work because itshigh degree of parallelism arid simplicit.y.
Definillg the local matrices Ai by:
( \1)
wherc Hi alld I?: arc t.he restriction and extension matrices defined in [12, 17],A is tlw global stiffness matrix and ;I.n is t.he solution of t he nih it.cration step.til<' ASM can bc writ.ten as:
[tI?; Ail Hi] (b - A:rn)'1=1
( 1 !j)
which is a Preconditioned Hichanlson met.hod with a damped fact.or equalt.o I. for p snbdolllains. where the preconditioner mat.rix is:
P
fv/-I = L H; Ail Hi;=1
(lG)
It is well 1,110wn that. t.he Richardson method presents very slow conver-gence. Thus, in order to accelerate the convergence another method can belIsed. using the matrix A1-1 as a preconditioner.
For general non-symmetric systems of equat.ions t.here are several Conju-gate Gradient like methods in the literature [20. 19.21] that have been widel.yused wi t.h relative success, but. the selection of the best is still an open is-sue. We chose t.he GMRES method, proposed by Saad and Schultz. that.has gained wide acceptance in solving syst.ems coming from Comput.at.ionalFluid Dynamics (CFD) problems [9. 10. 15] because it. never breaks down.unless the exact solution has already been achieved. and t.he convergence ismonotonic [18]. Writing the linear system of equat.ions generated by (2) as:
.4:r = b. ( 17)
the Gl\IRES clerives an approximate solut.ion for :1:.:1: = :/:0+':, where :ro is theinit.ial guess and.: comes from minimizing the residuallih - A(.'w + .:)11 over
!)

t.he I\.rylov subspace (span [1'0' .4-1'0, ;12'1'0 ..... , AA:I'o], where I.: is the dirnensiollof t.he space and 1'0 = h - ;\:/:0)' The major drawback of GMRES is thatincreasing I.: t.he amount of memory required per iterat.ion increases linear1.\·and the computational work increases quadrat.ically. In order to control theamount. or work and memory requirements a rest.arted version (GMHES(k))is used. This means t.hat aft.er I.: orthogonaliza.t.ion steps all variables will becleaned up and the obt.ained solutioll will be t.aken as the initia.l solution forthe next k steps. ]'he crucial element for a successful use of this version isbased on the choice of the parameter k. If it. is t.oo smalL the convergencemay slow down or the method can not converge. while large values wouldturn this method useless because of the work and memory requirements.
[n t.his work we used a variation of t.he GMRES(k) called FG.l\'1RES(k)introduced by Saad [lcl]. Although t.his version increases t.he amount ofmemory required by a factor I.:, since the preconditioned vectors are stored,it has the advantage over the resta.rted version because it allows the use of aniterative method for solving the preconclitioner ancl reduces the CPU timeto comput.e tire approximate solution. The FG.l\IHES(k) a.lgorithm is therollowi ng:
I. Start: Choose :1.:0 and a dimension I.: of the I\.rylov subspaces.2. Arnoldi process:
(a) Comput.e 1'0 = b - 1'1:1:0, (J = 111'011 ancl/)I = I'o/fl·(h) For .i = 1, ... ,I.: do
("1 '\ f I.,ompute :::.i := J' .i 'O.i
{I" ' .- ('II' 'I")...... '.' "1.1·- :., 1.
• h>r 'I = I, ... ,J. do " Iw :=w - 'i.,i'Oi
• Comput.e hi+l,.i = Ilmil il.lld Vi+1 = w/h.i+I,J .(c) Define Z/.; := [,:I, .... :::A] (\.lId Fh = {hi";}I~i~.i+I;l~.i<:::k'
:1. Form the approximate solution: Corllpute :1.:/.; = ;/:0 + ZA: ~/k,
where y/.; = ol'gm·i.n,/II!1C1 - Fh yll and (:1 = [1,0, .... or·4. Restart: If satisfied stop. else set. ;':0 f--- ;t:/.; a.nd go to 2.
TIle FGJVIRES(I.:) algorithm
There arc t.wo forms to solvc the local problems Ail: a dircct solvcr or anit.erative solver, like multigrid. At this time we decided t.o use a direct solve,
10

the LIT decorllposit.ioll method from t.he La.pacl, pa.ckagc[:2:~]. More eflicieutways will 1)(' dealt in fntnre works.
DISTRIBUTED SYSTEM
I{ecently t.hcre lias bcell Illuch interest. ill using workst.ations 1.0 forlll dis-t.ributed syst.ems. \Vit.11 t.he quick evolution of desktop workstatiolls, t.he,y canofF-load .iobs from saturated vect.or comIHlt.ers. often prO\'iding comparablet.ertll around t.ime at a fradioll of t.he cost.. \Vith high-speed networks theworkstations call also serve as a.1l inexpensive parallel cornpllt.er. Anotherfador ill favor of distributed computing is t.he availability of many lightlyloaded workst.ations. These ot.herwise \Vast.cd idle cycles call be used by dis-tributed COlllput.atiolls t.o provide speedups alld/or to solve large problemst.hat otherwise could not. be tackled.
Distributed FGMRES(k)
Similar to ot.her Con.iugate Cradient like iterative IllCtllOds, tile mostexpensive parts of the FCl'vIHES algoritllTll arc:
• tile preconditioner:• the matrix-vcctor products:
• the vedor-vector prodict.s.
To reduce the computational cost they shonld be done in parallel. To thisend, it. is necessary t.o determine how to split the data among the processors.Thus, t.wo factors have to be taken into account. The first. one is that, aswe are using the ASM, the preconditioller step is reduced to a series of localproblems that can be solved in parallel. Each subdomain should be assign at.least to each processor. The second one is that, for this type of system, thecommon networks used (Ethernet and FDDI) allow all processors to logicallycommunicate directly with any other processor but physicaUy support onlyone; send' at a. time. For these rea.sons we chose one-dimensional partitionof the domain reducing the overhead on 'starhl]Js' in the network and thenumber of neighbors.
It. is important to remark that this type of partition can be exchangeddepending on the network types or machines, not implying in a limitation in
11

this implementation. Other partitions only reqnire COll1nlllllication reorderill order to avoid ba.lldwit,h competition on the Iletwork. Besides. t.Il<' mostimportant part. of t.he algorit.hm is the procedure used ill t.he ort.ogona.lizatiollprocess that. will be explained next.
Independent of t.he type of part.ition, each processor has the matrix Ai andparts of the init.ial residual vector 'l'lJ and tire initial solution :rlJ. To evaluatethe lllat.rix-vector products, each processor lias to execute a series of localcOlllmunicat.ions with it.s lIeighbors, usually callednearst.-neillbors communi-cat.ions. to obtaill the contribution of t.he interface degrees of freedom. Atthe end, each processor lias 'pin with 111 = 0, ... , P, where P is t.he 1ll1111berofprocessors. Thus, the orthogonaliza.tioll step is performed in parallel. wherethe part.ial result.s (1II'oll,lluill, fJi+I ..;) are exchanged among the processors tocornp1cte the process. Obviously this procedure requires a great nlllnber ofcOlllmllnications. 1I0wever this is the bett.er choice to solve large problemswit.h adaptive procedures because ont.v a fixed nlllnber of scalar variables.equal to the l--:r.\'lov dilllellsion. is exchallged in a global form.
Two types of communicat.ion are used on t.his implementat.ion: the nearest-neighbor and one global communicat.ioll. For t.he first silllple 'send:::: and'receivcs' between neighbors are used inform of bi -d ired i011<11 ri ng. In theglobal COlllllluuicat.iollS we will use the Bucket Collect, algorithms and t.heRecursive Doubling Collect [16] are used.
Message Passing Library
The typical methodology for parallel processing in net.worked environ-ments is based on a software framework that executes on part.icipant.inghosts on a network and emulates a "virt.ual machine". This can be providedby many software systems like PVrvL Linda. P4. PARMACS, Chamelon,Zipcode, TCGIvISGG, Express and, more recently. following the MPI stan-dard, the l\'lPICH, LAN, CHAI\IMP and others [1:3. 2-!]. Applications accessthe virtual machine via system-provided libraries that. typically support. pro-cess ma.nagement, message exchange. group mana.gement and other facilit.ies.iVlost of the ellvironments use the message passing model. In this model. theprogrammer can have !nare control of the clata locality, the management ofthe caches and memory what can lead to a performance improvement.
In this work the PVM (Parallel Virtual i\lachine) is used. It has beenan ongoing project at Emoroy University, University of Tennessee and Oak

Ridge National Laborat.ory since H)89 and has been distributed freely sinceI~)91. This is an integrated set of softwa,re tools and libraries that emulates ageneral- purpose, flexi b Ie, heterogeneos concunen t COlli pu ti ng framework oninterconnected COlllput.ers of many architecture's. 'l'he purpose of PVM is t.oenable such collect.ion of computers t.o be llsed cooperatively for concurrelltor parallel computatious.
[>V1\[ is cOlllposed by 1.\vo parts. The first. olle is a daemoll that is ex-ecuted in each machine of t.he syst.em and allows the communication andsynchronization among machines. Thc second part, is a library containinglISeI' callable subrout.ines t.hat are the user's link to the PVtvl daenlmons.\Vhit t.hese subroutines the user call execute comlllunications, create audmanage group of ta,sks.
NUMERICAL RESULTS
In this section some nUluerical results obtained hy applying t.he proposedmethodology 011 the solut.ioll of a variet.y of scalar transport problems as wellas cOlllpressible Euler and Navier Stokes flow problems arc conveyed. Allcomput.ations were donc using piecewise liuear elements in space and con-st.allt in time. This leads t.o a time-marching scheme which IlCls low order ofaccuracy in time but. good stahilit.y properties, heing appropriate for solviugsteady problems.
The result.s are obtained using a collection of seventeen 1131\1 RISC GOOOworkstations, model :~BT, connected by FDDI network at the Texas Instituteof Computational and Applied Mathematics (TICA]\'I) Laboratory of TIleUniversity of Texas at Aust.in.
The PV1\o1 version :3.:1.7 was used. The PvmDaln]nPlace option is used inall examples t.o save on packing costs. All t.he measured times are Elapsedt.imes ( !Vall ck:0ck: lim,e). given by the C routine gdlim,colday. The algorithmuses BLAS-1 and BLAS-2 rout.ines when it is possible.
Convection-Diffusion Problem
In this section, we are going to solve the stationary convection-dominatedconvection-diffusion problems of the form
In n.

The aim here is to verify the communication patt.c\'lls. The CAU methodapplied to this equation has already been described in [II]. In the first one-dimensional eX(lI11plc (x ([(L Ln, the velocit.y field u is const.ant (lui = I) and1.tle IIwdia is isotropic so that t.he dif['usivity tellsor !\' is constant and equal1,0 Io-t;. The SOIll'CC term is cons tall t allover the dom ain U = I) and theboulldary conditiolls arc
<,&(0) = () and ¢Y( I) = I .
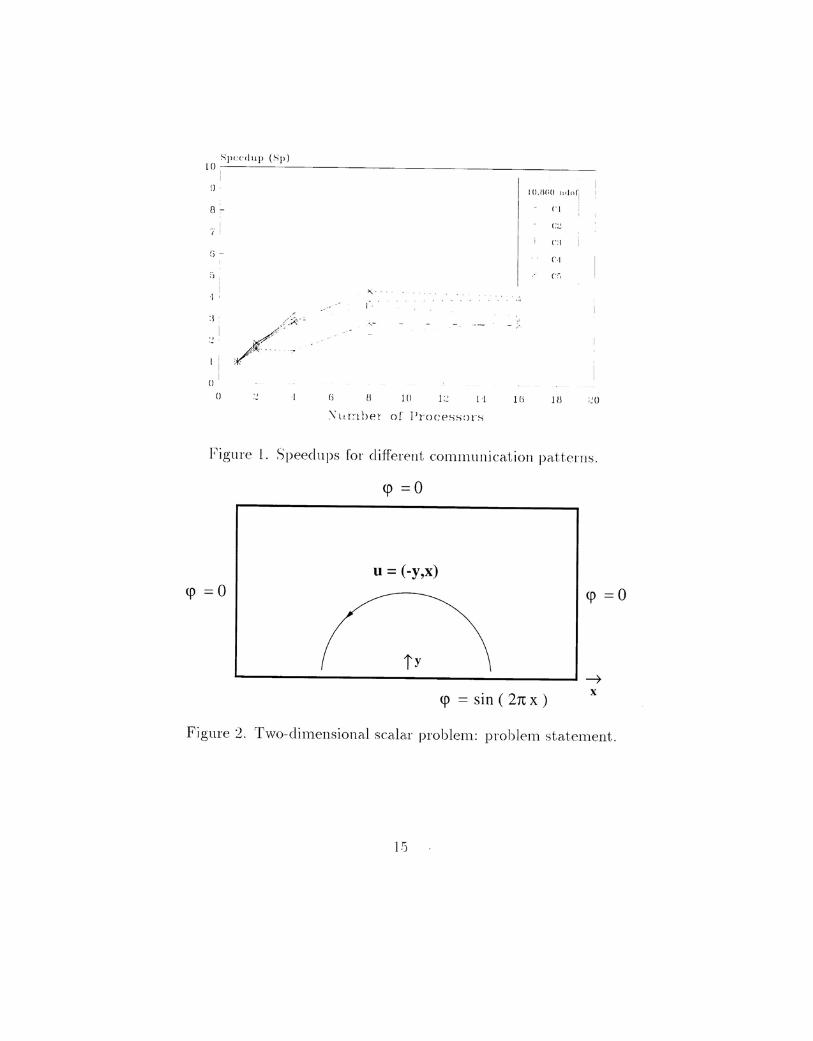
so t.hat. t.he exact. solut.ion is a linear function.'1'0 study the communication behavior witlr large number of iterations
we tmned off the preconditioner. The Figure I shows the speed up for thisproblelll with lO.8GO degrees of freedolll (ndof) for two different algorithmsat. difrcrent times of the day. Like syst.ems or t.his type. the performanceduring the day ca.1l vary denpending Oil the load of the system caused tryt,11<'extcrnalusers allel/or traffic. This behavior call be noticed ill the curves(:2 (wei C~L with eight anel four processors respectively. 'rhe cllI'ves Cl rInd(:2 were obt.ai ned using the !{,ecmsi vc c: loba.l Collect algori thill, d uri ng anormal day ((:1) and at. night ((:2), which is suposed to have t.he smallerinHnence of (,he traffic caused by other users. IlowcveL in t.hat, particularIlight. one machine was running a big job and the performance with 8 alldIG processors suffered with it.. The cllI'ves C:L (\1 anel CG were obtained byusing t.he Bucket (ring) a.lgorithm in t.hree successive mns during the day.
The PV11 allows two \Nays to perform the COllllllunica.tions: one usesthe daemons that is based on the UDP method and the second one is thed.ynarllic TCP sockets that permits a direct link among the processors. TheIa.tter is faster than the former a.lthough suffering limit.ations in t.he numberof links that can be established. The curves C:3 and CL~ were obtained usingthe PVM r!acm,on.s and C!) using the dynamic TCP sockets. Not.ice thatthe Bucket Algorithm running in a normal day is fast.er than t.he RecursiveGlobal Coiled running during the night. This is caused by the competitionfor t.he ba.ndwith on t.he FDDI net.work.
The second scalar example is t.he two-dimensional problem depicted inFigure :3. From now on, the preconditioner wi]] be turned on and it.s effectson t.he performance can be seen in Figure :3. The 1\SM increases the granu-larat.y of the partitions. Thus the elapsed t.ime decreases when t.he numberof processors increases even for the small problem considered.
14
Speed"p (Sp)10
II
Ill,nliO Ildn
('1
I... I( ,
G -I
,I'
:1
I
I!II
() ,
() (;
I,
1\ 10 11 11;
('"
11\
\\lr::rber of l'nJCess:>I's
Figure l. Speedups for difFerelJt, communicatioll patterns.
<p = 0
<p = 0u=(-y,x)
jy
<p = sin ( 2n x )
<p = 0
Figure 2. Two-dimensional scalar problem: problem statement.
)!j

200
180
160
_ 140.'!!-
~ 120i='0ffi 1000-mW 80
60
40
20
5,265 Ndofs
--------- No Preconditioner-----A---- with Precotlditioner
oo 2 4 6 8 10 12 14 16 18
Nunber of Processors
Pigll1'e ;{. Influence of the preconclitioner over t.he Elapsed time.
Flow over a wedge
This problem deals with all inviscid supersonic now (Mach number M=2)over a wedge at. all angle with respect to the mesh. It is illustrated in F'igll1'e ,,1where the dashed lillc shows the position of the slwck that can be det.erminedc\.llalytically.
The Figme!) shows the elapsed time for different problem sizes. For smalldegrees of freedom (dol') tlw performance is not satisfactory when a slllallnumber of processors is used. However. t.he performa.llce illlprovrs whell thenumber of degrees of freedom increases.
It. is well known that t.he execution time can be reduced by running t.hecodes ill fastest. and more expensive machines. '1'0 show that. the performancecan be increased by \Ising an exist.illg collection of workstations, in Table 1wc compare the present sol vcr with a widel.y \lsed direct. solver. t.he front.alsolver. running on a IBr..J RISe model !)qO. It. can be seen that the present.solver is 1.8 times faster. It is important to remark that. a problem with
16

~.58() dol's is still (,ollsidered a small problem as far as it.erative met.llOds areCOli ('e\'lwd.
p = 1,0
11I1= 1,0
p = 0,17857
M=2
jY
p = 1.45843
M = 1.64 1I, = 0,8873 I
1I2=O,P = 0,30475
Figure 4. Flow over a. wedge: problem stat.ement.
Elapsed Time (s)4000
3500
3000
2500
2000
1500
1000
500
Oblique Shock- T1.A--- T2
+-- T3e--- T4,
00 2 4 6 8 10 12 14 16 18 20Number of Processors
Figure rio Flow over a wedge: elapsed t.ilne(s)('1'1 =2.21"lnc10fs. '1'2 = "L420 dol'. T:~ = G.:,)96 ndof. '1'4 = 8,580 ndof).
17

Tahle I. COlllparison bet.ween the Direct. ami the Distributed Solvers.
8,580 dofSerial (!)~)O) Distributed (p = 16)Frontal :\SM - FCMHES(!»:ll.:~ min 17.:~ mi 11
Shock-Reflection Problem
This inviscid steady problem, consisting of thrce flow rcgions sep<\,ratedhy an ohliquc shock and its reflection from a wall, is depicted in Figure 6.
M =2,9
•p = 1.0
P = 0,714286111=2,911,=0,0
29:
M = 2378\
- -p = 1.7
P = 1.52819III = 2,61933411,=·().50632
2128"
4,1
M = 268728
•p = 2,68728p = 2,9340711
1=2.4014
II,=(),O
Figure 6. Shock-Reflection: problem statement..
The t.iming results for this problem are very silllilar to the previous exam-ple. In Ta.ble 2 the comparison with the fronta.l solver shows tha.t the presentalgorithm is 1.7 t.imes faster.
Table 2. Comparison bet.ween the Direct. and the Distributed Solvers.
12,740 dofSerial (590) Distribut.ed (p = 16)Frontal ASI\l - FGMRES(!))68.:~ min :38.4 min
18

Flow over a flat plate
Tllis classical example, call(~d Cart.er's problelJl, consists of a two-dimensionalMach :~viscous flow over a semi-infinite flat. platc~ at. zero angle of att.ack. Thecomputa.t.iona,1 domain and the boundary couditions arc shown in Figure 7.Again t.he timming results are very similar to t.he example S.LI In this ex-ample we compa,red the dist.ributed solver with t.hc frontal solver runuing 011
(]. lin", model :313'1', wit.hout ext.ernaillsers Oil t.he machine. The result.s (),reshO\vn in Table:L Herc the distributed solver isl.S timcs faster.
Yip = p : 1I1= U : 1I, = O. : 8 = 800 00 _ 00
M =3.000
R = 1.00000
sIwek
p = Poo1I =UI 00
1I,= O.
8 =800
1I,=O,
q 2= O.L12= O.
0.2
bOllI/dar\' layer
1.2
x~
O.X
Figure 7. Flow over a flat pla.te: problem st.atement.
Ta.ble :3. Comparison between the Direct and the Distribut.ed Solvers .
.5.580 dof ,
Serial (:mT) Distributed (p = 16)Frontal ASM - FG1'vIRES(S):~9.:3 min 8.1 min
19

CONCLUSIONS
III t.his paper we have shown a dist.ributed solver for solving C1"]) prob-lems nsing a stable Pctrov Calerkin method written in entropy variables.The nnmerical results showed that this solver is appropriate for distributedsystenls like a collection of workstations COll1lccted by a token-ring or bnsbased Il<'twork. Vie have shown that. this type of approach can Iw efficientfwd with a small a.monnt of efrort., it can be superior or fast.(~r t.ltan t.he usualsolvers f'ither for t.he small size problems considered in this paper.
References
[I] 1\. N. Brooks and T . .J. H. Hughes: 'Streamline Upwind Petrov-CalerkinFormulations for Convection-Dominated Flows with Particular Elllplw.-sis on the Incompressible Na\'ier-Stokes Eqnatiolls'. COn/put, Me/hods
\./1\;.1,/ I;'· . 32 I ()()')r:()(I()"'))j j)j). J r.;C I. ~lIfJ'.'J. . . -~.l. " o~ .
[2] T. .J. n,. Hughes alld M. IVlallct.. '1\ New Finite Element Fonnulat.ionfor Computational Fluid DYllamics: III. The Generalized StreamlineOperator for Multidimensional Advcctive-Diff'usivc Systems', Compul.Nlethods Appl. l\1(;ch. Eng/g. 58 :305-:328 (1986).
[:~] C . .Johnson. U. N~l.vcrt and .J. Pitkaranta, Finit.e Element Methods forLinear Hyperbolic Problems, Comp'llt. Methods Appl. Alech.. Eng/g. 45(] 984) 285-:312.
[et] A. C. Galeao and E. G. do Carmo. '1\ Consistent Approximate UpwindPctrov-Galerkin l\Iethod for Convection-Dominated Problems'. Comput.Methods Appl. Mech.. En.grg. 68 8:1-95 (] 988).
[5] R. C. Almeida (lnd A. C. Ga,leao. 'The Ceneralized CA U Operatorfor the Compressible Euler and Na.vier-Stokes Equations', 8th Inter-national Confe'I'cnce (J'n .rVu.merical J\;[ elhods in Lam.inar and Turb ulentF'lows (19~J:3).
[6] R. C. Almeida and A. C. Galeao. ;An Adaptive Petrov-Calerkin Formu-lation for the C:ompressi ble Euler and N avier-Stokcs Equations': Com-jJut. Aletlwds Appl. Mech.. Eng/g. 129 157-176 (1996).
20

[7] A. ILuten, 'On thc Symmetric Form of Systems of Conserva.tion Lawswith Entropj·· . .J. (:{)fllp. Physics 49 15]-]GI (19~:n.
[8] T . .J. It Hughes. L. P. Franca and 1\1. IVlallet, '1\ New Fillite Elcmelltformula.tion for Computational Fluid DYllamics: I. Symmetric Formsof the Compressible euler and Navier-Stokes Equations a.nd the SccondLa.w of Thermodynilll1ics'. c.'Oll1pu/. Mclhods !I/JP/. Mu:h. 1'.-"/If//'9. 54 2:t~~2:J1(198G).
[!l] F. Shakib, Tinite Element Analysis of the Compressible Euler andNavier-St.okes Equat.iolls·, Ph. D. Thes1s. ,'/Ia/lfon/ (Tnilwrsily (]988).
[10] J\l1. l'dallet., '}\ Finit.e Elemcnt Met.hod for Computational Fluid DYJlalll-ics', Ph. n. Thesis. Sianfon/ Unh,cr:;ily (198:)).
[11] R. C. Almeida alld It Silva. '1\ St.able Pet.rov-(;alerkin fvIethod forCOllvcction-Domin<lted Problellls'. (to appear ill C.'OfllpU./.Methods ilpIJ/.Mech. Eng/g.)
[12] Patrick Lc Tallec. 'Dornain Decomposition ;\Iethods ill ComputationalMechallics', COfllpulrliional Mec/wnics Aduanccs I (UHH).
[!:~]A. Geist. A. 13eguelin, J. Dongarra, \N. Jiang. n. Manc1wk a.nd V. Sun-dcr<lm, PVM: Parallel Virtual Machine. A ITsers' C:uide and 'rutorial forNetworked Parallel Computing. The MIT Pnss.
[14] Y. Saacl, A flexible Inner-Outer Preconclitioner Gl\IRES Algorithm,Universdy of i\linnuwta S'lIpercomputCl' In::<tihdc Resea/'ch Report91/279 (1991).
[15] 'vV. D. Gropp and D. E. Ke.yes. 'Domain Decomposition Methods inComputational Fluid Dyna.mics', II/ter. Journal for NUlnCl'ical !Helhodsin Fluids 14 147-165 (1992).
[16] M. Barnett, R. Littlefield, D. G. Payne and R. A. van del' Geijn, 'Oil theEfficiency of Global Combine Algorithms for 2-D j\Ieshes With Worm-hole Routing', TR-9:J-05. Departm.ent of Computer Sciences. The Uni-'/)crsily of Tt:ws, 19~):3.
21

[17] T. F. Chan and T.P. Mathew. 'Domain decomposit.ion algorithms', ;\daNl/.lIIrriw GI- I L(:l (I DDl).
[IS] It D. da Cliltll<l a,nd T. Ilopkins, 'A Parallel IllIplcment.ation or t.heHcstarted CiVIRES Iterat.ive Method for Nonsymmetric Syst.ems or Lin-ear Eq uatioJ IS'. {saInI/dIed 10 A (!-i.'a;l1cesin C:om)Julal iOl1al M alhc"/I7.ati(8).
[ID] Y. Cai and 1.1-1. Navon, 'Parallel Block Preconditioning Techniques forN lImerical Simulat.ion of the Shallow Wa.ter Flow Using Finite ElementMethods', (:;'//bm,illed 10 Journal of Compulational Physics).
[:W] R. Barrett, 1\11. Berr,,>,.T. Chan . .I. Demmel, OJ. Donato, .I. Dongarra, V.EijkhouL R. Pozo, C. Romine and II. van del' Vorst, TEMPLATES fmthe solution of Linear Systems: Building Blocks for Iterative Methods.SII\1\1 (199:3).
[21] .I.W. Demmel. 1\1.'1'. Heath and II. vall del' \forsL 'Parallel numericallinear algebra', Acta Num.erica 111-197 (19~):)).
[22] Xiao-Chuan Cai. William D. Cropp and David Keyes .. A Comparisomof Some Domain Decomposit.ion Algorithms for Nonsymmetric EllipticProblems', Fifth Inlernational Sym.poshlln on Dom.ain Decom.positionMclhods for Pa,,.lial DifTen:nlial EqlUltion8, SIAM, 224-n5 (1992).
[2:1] E. Anderson. Z. Bai. C. 13ischoL .J. DClIlllledl,.J. Dongarra,.J. f)u Croz,A. CrcenbaullL S. Ilammarling, A. 1\'lckcnncy, S. Ostrollchov and D.Soresen, LAP/\C:/\' Uscrs' (iI/ide, 2nd Edit.ion, SIAM (1~)95).
[2,1] \V. Gropp, E. Lusk and A. Skjellum, Using MPI - Portable ParallelProgramming with the lVlessage-Passing Interface, JIlT p,.ess (1994).
22