a dynamic level- model in gamesfaculty.haas.berkeley.edu/hoteck/papers/dlk-ho.pdf · a dynamic...
TRANSCRIPT

A Dynamic Level-k Model in Games
Teck Ho and Xuanming SuTeck Ho and Xuanming Su
UC Berkeley
March, 2010 Teck Hua Ho 1
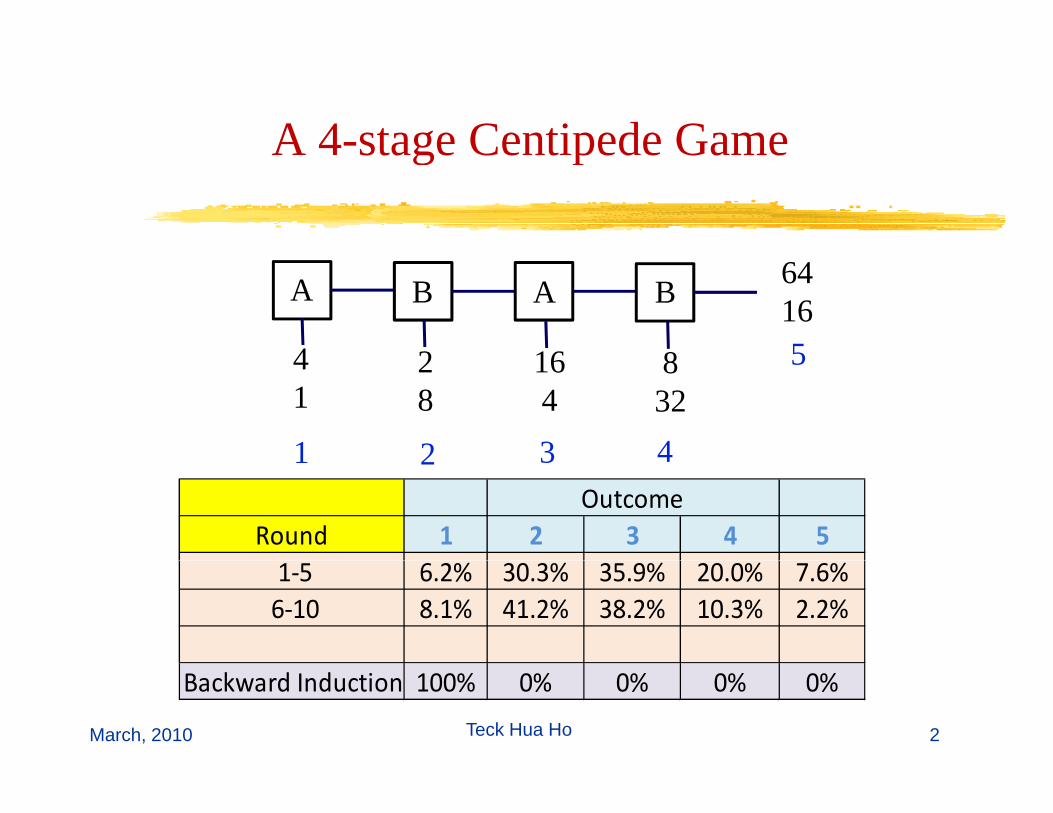
A 4-stage Centipede GameA 4 stage Centipede Game
A AB B
4 2 16 8
641654
128
164
832
1 32 4
5
OutcomeRound 1 2 3 4 5
1 32 4
1‐5 6.2% 30.3% 35.9% 20.0% 7.6% 6‐10 8.1% 41.2% 38.2% 10.3% 2.2%
March, 2010 Teck Hua Ho 2
Backward Induction 100% 0% 0% 0% 0%

A 6-Stage Centipede Gameg p
64 32
25664
A AB B
4 2 16 8
A B
76416
321281 8 4 32
O
1 32 4 65Outcome
Round 1 2 3 4 5 6 7
1‐5 0.0% 5.5% 17.2% 33.1% 33.1% 9.00% 2.10%
6‐10 1.5% 7.4% 22.8% 44.1% 16.9% 6.60% 0.70%
Backward Induction 100% 0% 0% 0% 0% 0% 0%
March, 2010 Teck Hua Ho 3

OutlineOutline
k d i d i d i i i l iBackward induction and its systematic violations
Dynamic Level-k model and the main theoretical resultsThe centipede game
Resolving well-known paradoxes: o Cooperation in finitely repeated prisoner’s dilemmao Cooperation in finitely repeated prisoner s dilemma
o Chain-store paradox
An empirical application: The centipede gameAlternative explanationso Reputation-based story
S i l fo Social preferences
March, 2010 Teck Hua Ho 4

Backward Induction PrincipleBackward Induction Principle
B k d i d ti i th t id l t d i i l t tBackward induction is the most widely accepted principle to generate prediction in dynamic games of complete information
Extensive-form games (e.g., Centipede)
Finitely repeated games (e.g., Repeated PD and chain-store paradox)
M lti person d namic programmingMulti-person dynamic programming
For the principle to work, every player must be willingness to bet on p p , y p y gothers’ rationality
March, 2010 Teck Hua Ho 5

Violations of Backward InductionViolations of Backward Induction
Well-known violations in economic experiments include: (http://en.wikipedia.org/wiki/Backward_induction ):
Passing in the centipede game
Cooperation in the finitely repeated PD
Chain-store paradox
Likely to be a failure of mutual consistency condition (different people make initial different bets on others’ rationality)
March, 2010 Teck Hua Ho 6

Standard Assumptions in Equilibrium AnalysisEquilibrium Analysis
Assumptions Backward DLk
Induction ModelSolution MethodSolution Method
Strategic Thinking X X
Best Response X X
Mutual Consistency X ?
Instant Equilibration X ?
March, 2010
sta t qu b at o ?
7Teck Hua Ho

NotationsNotations
iIsS
)by (indexed players ofnumber Total : )by (indexed subgamesofnumber Total :
sN s subgameat activeare whoplayersofnumber Total :
64A AB B
4 2 16 8
6416
41
28
164
832
124 ====== NNNNIS
March, 2010 Teck Hua Ho 8
1 ,2 ,4 4321 ====== NNNNIS

Deviation from Backward InductionDeviation from Backward Induction
∑ ∑ ∞ ⎥⎦
⎤⎢⎣
⎡=
S Ni
sI
s
LLDNS
GLL1 ),(11),,...,(δ= = ⎦⎣s isNS 1 1
⎭⎬⎫
⎩⎨⎧ ≠
= ∞∞ otherwise
LaLa,,L(LD
ii
s ,0)()( 1
)
1(.)0 ≤≤ δ
March, 2010 Teck Hua Ho 9
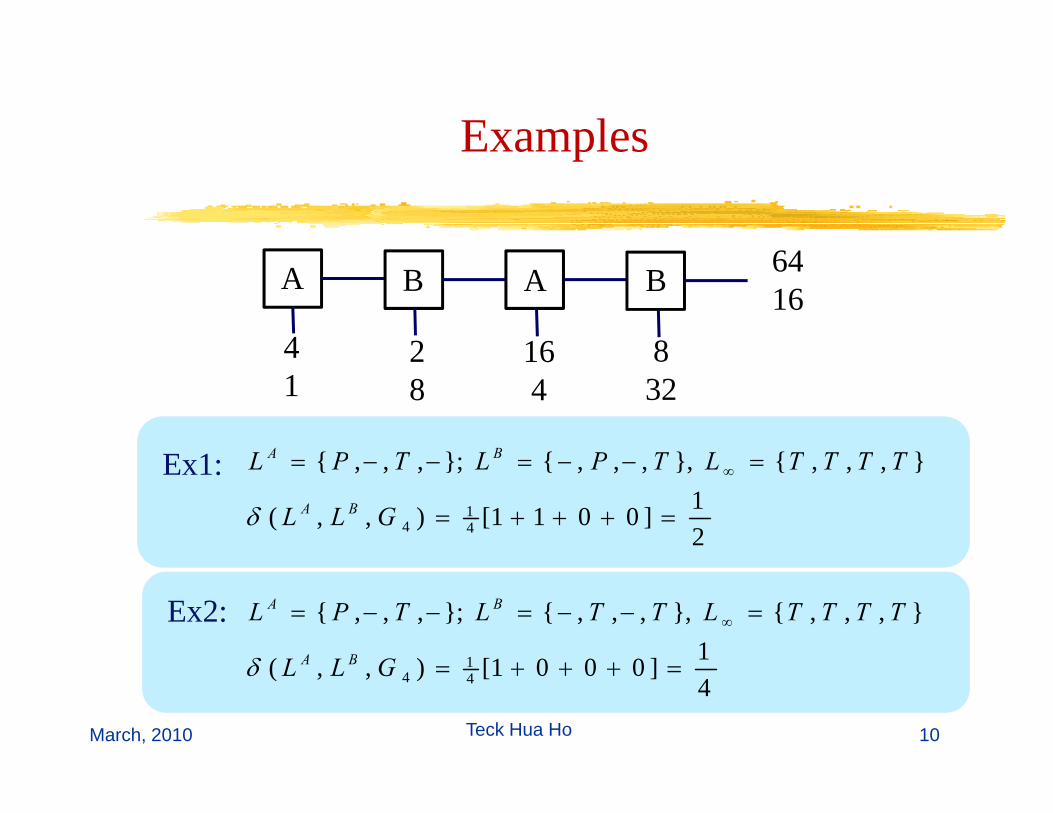
ExamplesExamples
64A AB B
4 2 16 8
6416
41
28
164
832
}{}{};{ TTTTLTPLTPL BAE 1
21]0011[),,(
},,,{},,,,{};,,,{
41
4 =+++=
=−−=−−= ∞
GLL
TTTTLTPLTPL
BAδ
Ex1:
1]0001[)(
},,,{},,,,{};,,,{
1 +++
=−−=−−= ∞
GLL
TTTTLTTLTPL
BA
BA
δ
Ex2:
March, 2010 Teck Hua Ho 10
4]0001[),,( 4
14 =+++=GLL BAδ

Systematic Violation 1: Limited Inductiony
A AB B 6416
41
28
164
832
256
64 32
25664
A AB B
4 2 16 8
A B
16321281 8 4 32
)()( GLLGLL BABA δδ <
March, 2010 Teck Hua Ho 11
),,(),,( 64 GLLGLL δδ <

Limited Induction in Centipede GameLimited Induction in Centipede Game
Figure 1: Deviation in 4 stage versus 6 stage game (1st round)
March, 2010 Teck Hua Ho 12
Figure 1: Deviation in 4-stage versus 6-stage game (1 round)

Systematic Violation 2: Time UnravelingSystematic Violation 2: Time Unraveling
A AB B 6416
41
28
164
832
16
32
∞→→ tGtLtL BA as0)),(),((δ ∞→→ tGtLtL as0)),(),((δ
March, 2010 Teck Hua Ho 13
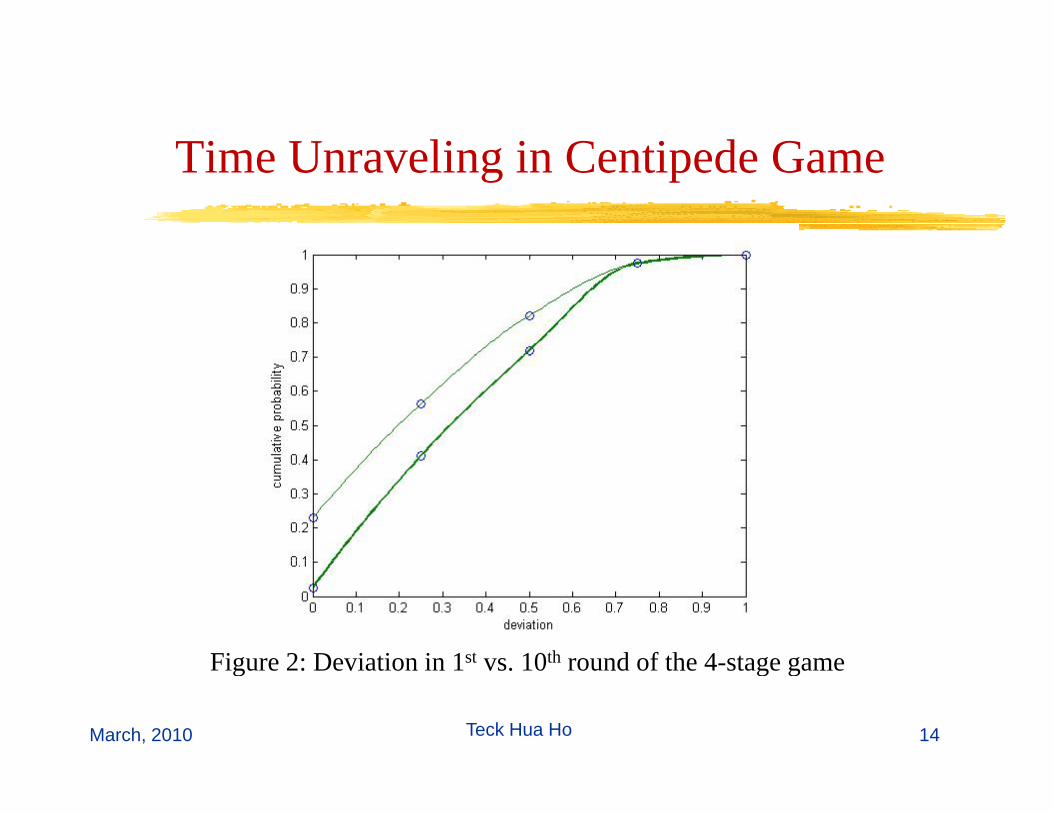
Ti U li i C ti d GTime Unraveling in Centipede Game
Figure 2: Deviation in 1st vs 10th round of the 4 stage game
March, 2010 Teck Hua Ho 14
Figure 2: Deviation in 1 vs. 10 round of the 4-stage game

OutlineOu e
k d i d i d i i i l iBackward induction and its systematic violations
Level-k model and the main theoretical resultsThe centipede game
Resolving well-known paradoxes: o Cooperation in finitely repeated prisoner’s dilemmao Cooperation in finitely repeated prisoner s dilemma
o Chain-store paradox
An empirical application: The centipede gameAlternative explanationso Reputation-based story
S i l fo Social preferences
March, 2010 Teck Hua Ho 15

Research questionResearch question
To develop a good descriptive model to predict the probability of player i (i=1,…,I) choosing strategy j at subgame s (s=1,.., S) in any dynamic game of complete informationany dynamic game of complete information
)(sPij
March, 2010 16Teck Hua Ho

Criteria of a “Good” Model
Nests backward induction as a special case
Behavioral plausibleHeterogeneous in their bets on others’ rationality
Captures limited induction and time unraveling
Fit d t llFits data well
Simple (with as few parameters as the data would allow)
March, 2010 Teck Hua Ho 17

Standard Assumptions in Equilibrium AnalysisEquilibrium Analysis
Assumptions Backward HierarchicalInduction Strategizing
Solution MethodSolution Method
Strategic Thinking X X
Best Response X X
Mutual Consistency X HeterogenousBets
Instant Equilibration X Learning
March, 2010 18Teck Hua Ho

Dynamic Level-k Model: SummaryDynamic Level k Model: Summary
Pl h l f l hi hPlayers choose rule from a rule hierarchy
Players make differential initial bets on others’ chosen rules
After each game play, players observe others’ rules (e.g., strategy method)
Pl d t th i b li f l h b thPlayers update their beliefs on rules chosen by others
Players always choose a rule to maximize their subjective expected utility in each roundexpected utility in each round
March, 2010 Teck Hua Ho 19

Dynamic Level-k Model: Rule Hierarchyy y
l h l f l hi h d b bPlayers choose rule from a rule hierarchy generated by best-responses
Rule hierarchy: LLLRule hierarchy:
R t i t L t f ll b h i d i th i ti
,....,, 210 LLL)( 1−= kk LBRL
Restrict L0 to follow behavior proposed in the existing literature
BIL = BIL =∞
March, 2010 Teck Hua Ho 20

Dynamic Level-k Model: Poisson Initial Beliefy
Diff l k diff i i i l b h ’ h lDifferent people make different initial bets on others’ chosen rules
Poisson distributed initial beliefs:
K
!)(
KeKf
Kλτ−=
λ : average belief of rules used by opponents
f(k) fraction of players think that their opponents use Lk-1 rule.
March, 2010 Teck Hua Ho 21

Dynamic Level-k model:Belief Updating at the End of Round tBelief Updating at the End of Round t
Initial belief strength: N (0) = βInitial belief strength: Nk(0) = βUpdate after observing which rule opponent chose
+ )(ii I(k t)tΝtN 11)(
=
⋅+ )−(=
iki
kk
tNtB
I(k,t)tΝtN
)()(
11)(
I(k ) 1 if h L d 0 h i
∑=
= S
k
ik
k
tNtB
0')(
)(
I(k, t) = 1 if opponent chose Lk and 0 otherwiseBayesian updating involving a multi-nomial distribution with a Dirichlet prior (Fudenberg and Levine, 1998; Camerer and Ho,
March, 2010
Dirichlet prior (Fudenberg and Levine, 1998; Camerer and Ho, 1999)
22Teck Hua Ho

Dynamic Level-k model: :O ti l R l i R d t+1Optimal Rule in Round t+1
Optimal rule k*:
∑ ∑= =
=⎭⎬⎫
⎩⎨⎧
⋅=S
s
S
kskks
ikSk aatBk
1 1'',',..,1
* )()(maxarg π
Let the specified action of rule Lk at subgame s be akLet the specified action of rule Lk at subgame s be aks
March, 2010 23Teck Hua Ho
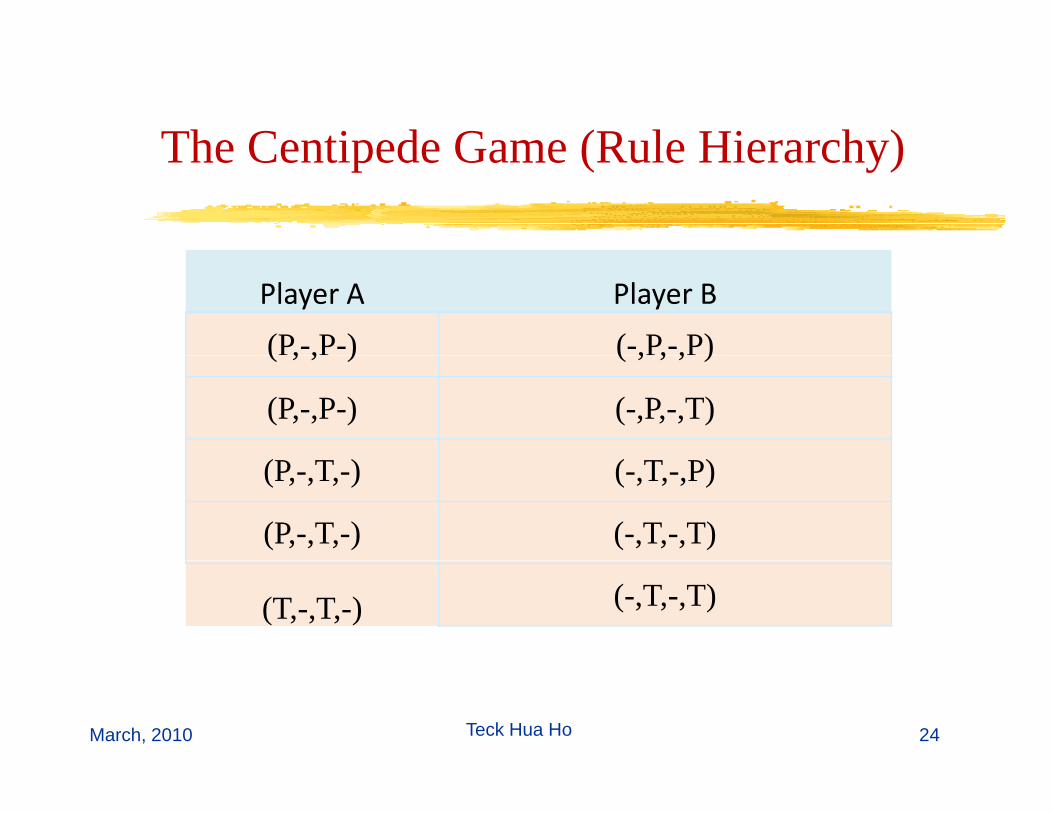
The Centipede Game (Rule Hierarchy)The Centipede Game (Rule Hierarchy)
Player A Player B
(P,-,P-) (-,P,-,P)( , , ) ( , , , )
(P,-,P-) (-,P,-,T)
(P,-,T,-) (-,T,-,P)
(P,-,T,-) (-,T,-,T)
(T,-,T,-) (-,T,-,T)
March, 2010 24Teck Hua Ho

Player A in 4-Stage Centipede Gamey g p
Nik(t) β=0.5
Round (t) L L L L L Rule Used by Opponent Optimal Rule (Player A)Round (t) L 0 L 1 L 2 L 3 L 4 Rule Used by Opponent Optimal Rule (Player A)
0 β L 2
1 β 1 L 3 L 2
β2 β 2 L 3 L 2
3 β 3 L 3 L 4
March, 2010 Teck Hua Ho 25
3 β 3 L 3 L 4

Dynamic Level-k Model: SummaryDynamic Level k Model: Summary
Pl h l f l hi hPlayers choose rule from a rule hierarchy
Players make differential initial bets on others’ chosen rules
After each game play, players observe others’ rules (e.g., strategy method)
Pl d t th i b li f l h b thPlayers update their beliefs on rules chosen by others
Players always choose a rule to maximize their subjective expected utility in each roundexpected utility in each round
A 2-paramter extension of backward induction (λ and β)
March, 2010 Teck Hua Ho 26

Main Theoretical Results: Limited InductionMain Theoretical Results: Limited Induction
)()( GLLGLL BABA δδ < ),,(),,( 64 GLLGLL δδ <
March, 2010 27Teck Hua Ho

Main Theoretical Results: Time UnravelingMain Theoretical Results: Time Unraveling
∞→→ tGtLtL BA as0)),(),((δ ∞→→ tGtLtL as0)),(),((δ
March, 2010 28Teck Hua Ho

Iterated Prisoner’s Dilemma (Rule Hierarchy)Iterated Prisoner s Dilemma (Rule Hierarchy)
3 3 0 5Level Strategy
0 TFT*3,3 0,5
5,0 1,1
0 TFT*
1 TFT,D
2 TFT,D,D
* K l (1982)
3 TFT,D,D,D
K TFT,D1…,Dk
* Kreps et al (1982)
March, 2010 Teck Hua Ho 29

Main Theoretical ResultsMain Theoretical Results
TT'GLLGLL TBA
TBA >< );,,(),,( 'δδ
March, 2010 30Teck Hua Ho

Main Theoretical ResultsMain Theoretical Results
∞→→ tGtLtL BA as 0)),(),((δ
March, 2010 31Teck Hua Ho

Properties of Level-0 RuleProperties of Level 0 Rule
Maximize group payoff: A level-0 player always chooses a decision that if others do the same will lead to the largest total
ff f th ( TFT i RPD)payoff for the group (e.g., TFT in RPD)
P i di id l ff Whil i i i ffProtect individual payoff: While maximizing group payoff, a level-0 player also ensures that the chosen decision rule is robust against continued exploitation by others (e.g., TFT in RPD)g p y ( g , )
March, 2010 Teck Hua Ho 32

Chain-Store Paradox (Rule Hierarchy)Chain Store Paradox (Rule Hierarchy)
E
51
E
CS
OUT IN
1
0 2
CS
FIGHT SHARE
0 2Level Chain Store (CS) Entrant
0 FIGHT(F)G O l CS i b d h ( h
1F,F,F,..,F,F,S GTR: OUT unless CS is observed to share (then
ENTER(E)2 F,F,F,..,F,S,S GRE, E
3 F F F S S S GTR E E
March, 2010 Teck Hua Ho 33
3 F,F,,..F,S,S,S GTR,E,E
K F,..,F,S1,..,SkGTR,E1,..,Ek-1

Main Theoretical ResultsMain Theoretical Results
March, 2010 34Teck Hua Ho

OutlineOu e
k d i d i d i i i l iBackward induction and its systematic violations
Level-k model and the main theoretical resultsThe centipede game
Resolving well-known paradoxes: o Cooperation in finitely repeated prisoner’s dilemmao Cooperation in finitely repeated prisoner s dilemma
o Chain-store paradox
An empirical application: The centipede gameAlternative explanationso Reputation-based story
S i l fo Social preferences
March, 2010 Teck Hua Ho 35

4-Stage versus 6-Stage Centipede Gamesg g p
A AB B 6416
41
28
164
832
256
64 32
25664
A AB B
4 2 16 8
A B
6416
321281 8 4 32
March, 2010 Teck Hua Ho 36

Empirical Regularitiesp g
Outcome
Round 1 2 3 4 5
1 5 6 2% 30 3% 35 9% 20 0% 7 6%1‐5 6.2% 30.3% 35.9% 20.0% 7.6%
6‐10 8.1% 41.2% 38.2% 10.3% 2.2%
Outcome
Round 1 2 3 4 5 6 7
1‐5 0.0% 5.5% 17.2% 33.1% 33.1% 9.00% 2.10%
6‐10 1.5% 7.4% 22.8% 44.1% 16.9% 6.60% 0.70%
March, 2010 Teck Hua Ho 37

Dynamic Level-k Model’sPrediction in 4 stage gamePrediction in 4-stage game
March, 2010 Teck Hua Ho 38

Dynamic Level-k Model’sPrediction in 6 stage gamePrediction in 6-stage game
March, 2010 Teck Hua Ho 39

MLE Model Estimates
1 11.1
Special cases are rejectedSpecial cases are rejected
Both heterogeneity and learning are important
March, 2010 Teck Hua Ho 40

Model PredictionsModel Predictions
March, 2010 Teck Hua Ho 41

Alternative 1:Gang of Four’s Story (Kreps, et al, 1982)g y ( p , , )
large
θ = proportion of altruistic players (level 0 players)
March, 2010 Teck Hua Ho 42
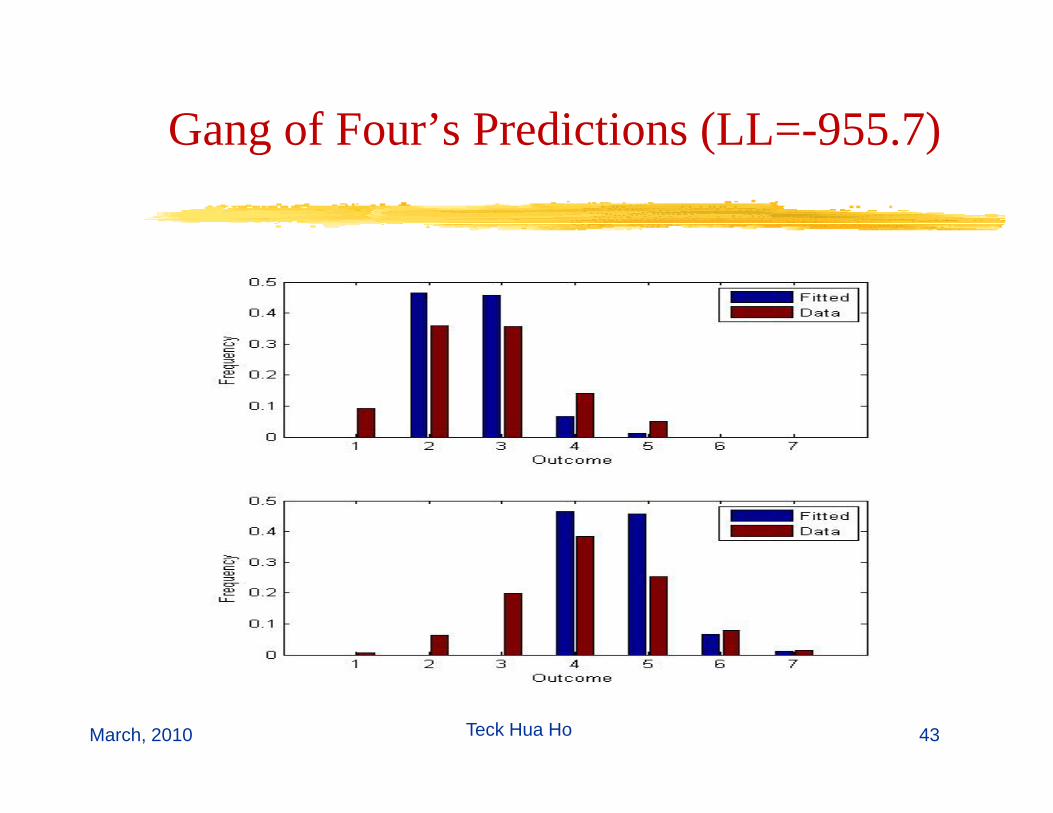
Gang of Four’s Predictions (LL=-955.7)g ( )
March, 2010 Teck Hua Ho 43

Alternative 2: Social Preferences
March, 2010 Teck Hua Ho 44

ConclusionsConclusions
i l l k d l i i i l l iDynamic level-k model is an empirical alternative to BI
Captures limited induction and time unraveling
Explains violations of BI in centipede game
Explains paradoxical behaviors in 2 well-known games ( ti fi it l t d PD h i t d )(cooperation finitely repeated PD, chain-store paradox)
Dynamic level-k model can be considered a tracing procedure for backward induction (since the former converges to thefor backward induction (since the former converges to the latter as time goes to infinity)
March, 2010 Teck Hua Ho 45