a method for rapid, targeted cnv genotyping identifies rare
TRANSCRIPT

A Method for Rapid, Targeted CNV Genotyping Identifies Rare Variants
Associated with Neurological Disease
Gregory Cooper, Ph.D.Department of Genome Sciences, University of Washington

Genomic Structural VariationFr
eque
ncy
Size
Human Genetic Variation
1 bp 1 chr

Genomic Structural VariationFr
eque
ncy
Size
SNPs
Human Genetic Variation
1 bp 1 chr

Genomic Structural VariationFr
eque
ncy
Size
SNPs
cytogenetic
Human Genetic Variation
1 bp 1 chr

Genomic Structural VariationFr
eque
ncy
Size
SNPs
cytogenetic
structural variation
Human Genetic Variation
1 bp 1 chr

Genomic Structural VariationFr
eque
ncy
Size
SNPs
cytogenetic
structural variation
deletions
insertions
Human Genetic Variation
1 bp 1 chr

Genomic Structural VariationFr
eque
ncy
Size
SNPs
cytogenetic
structural variation
duplications
deletions
insertions
Human Genetic Variation
1 bp 1 chr
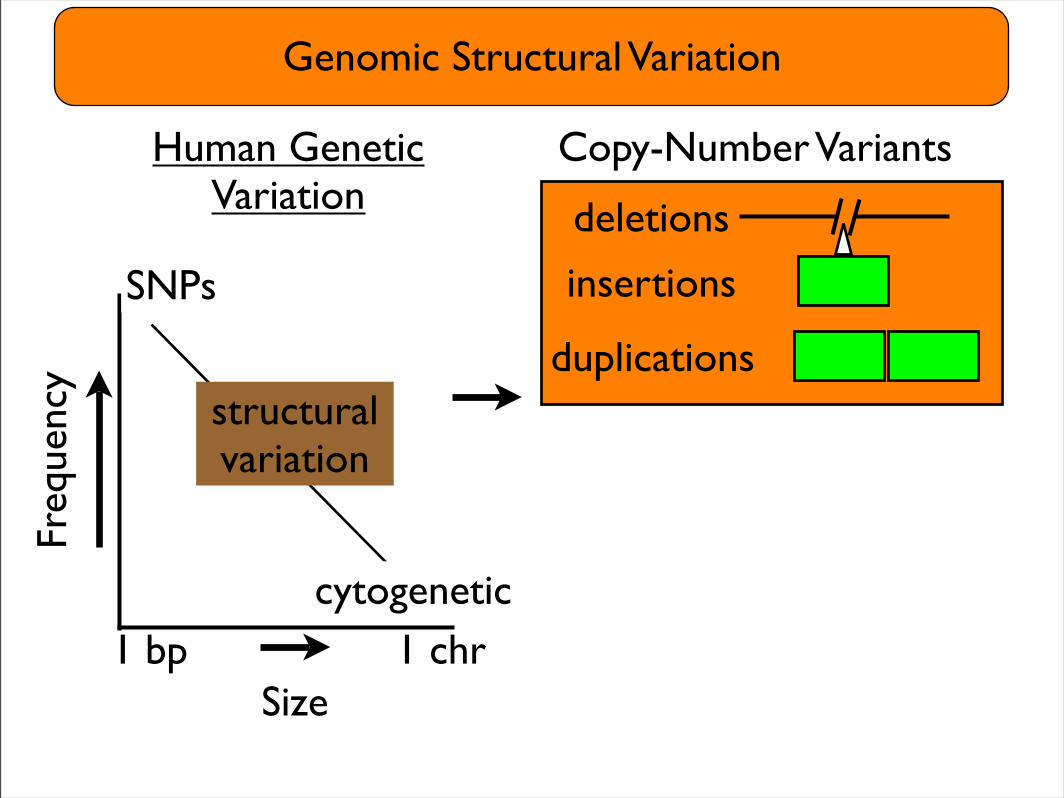
Copy-Number Variants
Genomic Structural VariationFr
eque
ncy
Size
SNPs
cytogenetic
structural variation
duplications
deletions
insertions
Human Genetic Variation
1 bp 1 chr

Copy-Number Variants
Genomic Structural VariationFr
eque
ncy
Size
SNPs
cytogenetic
structural variation
duplications
deletions
insertions
Human Genetic Variation
• Gene-rich, e.g. immune response, drug metabolism
• Abundant: majority of human heterozygosity
• Technological challenges have impeded large-scale analyses
1 bp 1 chr

SNP-based Deletion Discovery

SNP-based Deletion Discovery
A B B A
B A B B
1 2 3 4
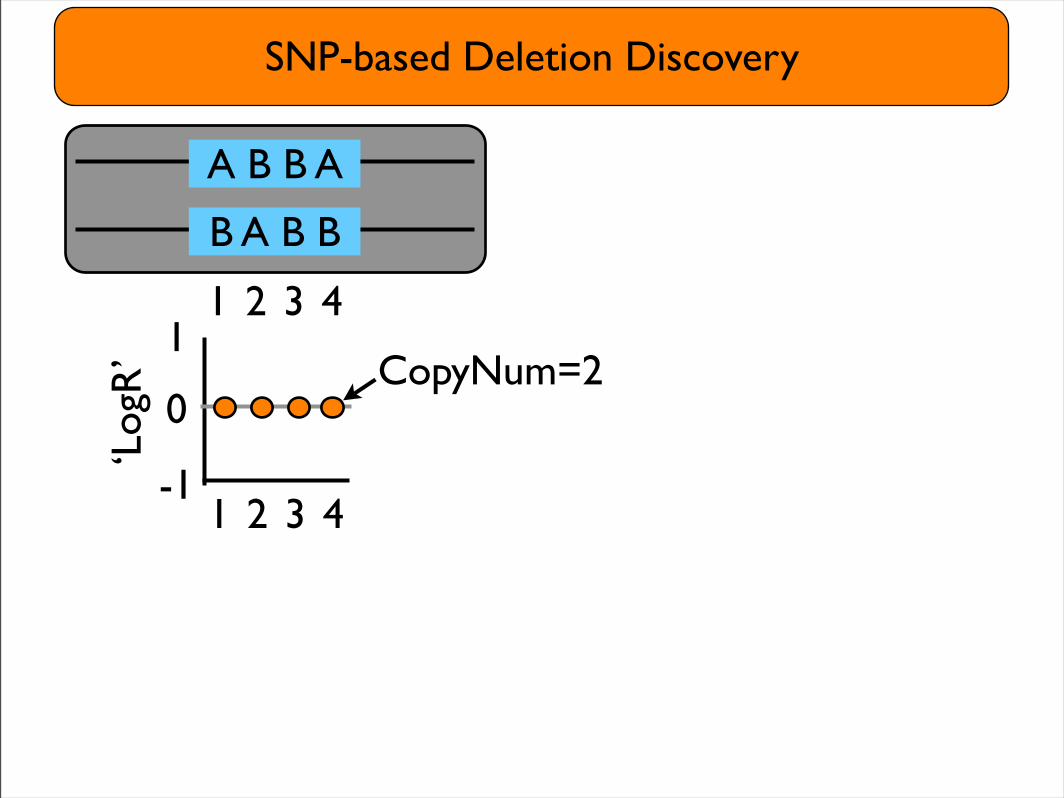
SNP-based Deletion Discovery
A B B A
B A B B
1 2 3 4
0
-1
1
1 2 3 4
‘Log
R’ CopyNum=2

SNP-based Deletion Discovery
A B B A
B A B B
1 2 3 4
‘B-A
llele
Fre
q’
0.5
0
1
1 2 3 4
AB
BB
0
-1
1
1 2 3 4
‘Log
R’ CopyNum=2

SNP-based Deletion Discovery
A B B A
B A B B
1 2 3 4
‘B-A
llele
Fre
q’
0.5
0
1
1 2 3 4
AB
BB
0
-1
1
1 2 3 4
‘Log
R’ CopyNum=2
A-
B-
A B B A
1 2 3 4
B-A
llele
Fre
q0.5
0
1
1 2 3 4
0
-1
1
1 2 3 4
LogR
CopyNum=1

−1.0
−0.5
0.0
0.5
1.0
chr3 coordinates
LogR
and
B−A
llele
Fre
q
46700000 46740000 46770000 46810000 46850000 46890000
●●●
● ●
●
●
●
●●●
●
●
●
●●●●
●
●
●
● ●
●
●●●
●●
●●
● ●● ●
●
●
● ● ● ●●
●
●●
●
●
● ●●● ●●
●
●
●●
● ●
●
●
●●●
●
●
●
●
●●
●
●
● ●
●
LogR
and
B-A
llele
Fre
quen
cy
0
-1
0.5
1
-0.5
Human chromosome 3 position
~55 kbp
fosmid-inferred breakpoints
Illumina 1M Deletion Discovery

−1.0
−0.5
0.0
0.5
1.0
chr3 coordinates
LogR
and
B−A
llele
Fre
q
46700000 46740000 46770000 46810000 46850000 46890000
●●●
● ●
●
●
●
●●●
●
●
●
●●●●
●
●
●
● ●
●
●●●
●●
●●
● ●● ●
●
●
● ● ● ●●
●
●●
●
●
● ●●● ●●
●
●
●●
● ●
●
●
●●●
●
●
●
●
●●
●
●
● ●
●
LogR
and
B-A
llele
Fre
quen
cy
0
-1
0.5
1
-0.5
Human chromosome 3 position
~55 kbp
fosmid-inferred breakpoints
Illumina 1M Deletion Discovery

SNP-based Duplication Discovery
A B B A
B A B B
1 2 3 4
0
-1
1
1 2 3 4
LogR
B-A
llele
Fre
q
0.5
0
1
1 2 3 4
AB
BB
CopyNum=2
A B B A
B A B B
A B B A
1 2 3 4
B-A
llele
Fre
q0.5
0
1
1 2 3 4
AAB
BBB
ABB
0
-1
1
1 2 3 4
LogR
CopyNum=3

Illumina 1M Duplication Discovery−1
.0−0
.50.
00.
51.
0
chr2 coordinates
LogR
and
B−A
llele
Fre
q
75630000 75690000 75750000 75810000 75860000 75920000
●●
● ●● ●●
●
●
●
●
●
●● ●●
●
● ●●
●●●
●●
●
●
●
●●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
● ●●
●●
●●
●
●
●●
●
●
●●●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●
●
●
●●●
● ●●●
●●
●
●
●
● ●
●
●
●●
●
●●●●
●
●● ●
LogR
and
B-A
llele
Fre
quen
cy
0
-1
0.5
1
-0.5
Human chromosome 2 position
~90 kbp

Illumina 1M Duplication Discovery−1
.0−0
.50.
00.
51.
0
chr2 coordinates
LogR
and
B−A
llele
Fre
q
75630000 75690000 75750000 75810000 75860000 75920000
●●
● ●● ●●
●
●
●
●
●
●● ●●
●
● ●●
●●●
●●
●
●
●
●●
●
●
●
●
●
●
●●
● ●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
● ●●
●●
●●
●
●
●●
●
●
●●●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●
●
●
●●●
● ●●●
●●
●
●
●
● ●
●
●
●●
●
●●●●
●
●● ●
LogR
and
B-A
llele
Fre
quen
cy
0
-1
0.5
1
-0.5
Human chromosome 2 position
~90 kbp
fosmids independently
inferred to harbor duplication

• ~1,000 individuals from the PARC project (Illumina 317k SNP arrays)
• Caucasian samples from a statin pharmacogenetics study
• ~1,000 samples from the Human Genome Diversity Panel (Illumina 650Y chips; Li, Absher, et al Science 2008):
• samples collected in diverse regions of the world
• ~800 neurological disease controls (Illumina 550K chips; Andy Singleton; Walsh et al, Science 2008)
• samples screened for symptoms of psychiatric disease
• n = 2,493 samples after QC (600 blood DNA)
Discovering CNVs in Large Cohorts

Study Platform # Samples CNVs Calls/Sample
PARC HH317K 936 (991) 2,664 2.85
Neurological Disease Controls
HH550K 671 (790) 4,641 6.92
HGDP HH650Y 886 (941) 6,538 7.38
Total2,493
(2,722)13,843 5.56
Large CNV Overview

0e+00 2e+05 4e+05 6e+05 8e+05 1e+06
0.01
0.02
0.05
0.10
0.20
0.50
1.00
size_indeces
tenkb.indcounts/sum(study.indcounts)
Coriell
NINDS
cap
prince
stanford
Combined
0 100 200 300 400 500 600 700 800 900 1000
100%
50%
20%
5%
10%
2%
1%
Singleton - Coriell Controls (550K, cells)Singleton - NINDS Controls (550K, cells)PARC (’CAP’) (317K, cells)PARC (’PRINCE’) (317K, blood)HGDP (650Y, cells)Combined
R: 1254x827Fr
acti
on o
f In
div
idu
als
Minimum Size (kb)
Many Individuals Carry Large Events

Collectively Frequent But Individually Rare
1 2 3 4 5 6 7
5e+0
41e
+05
2e+0
55e
+05
1e+0
62e
+06
5e+0
61e
+07
2e+0
7
plot.index + jitter[AssignedState + 1]
Leng
th
0.5 1.0 2.0 5.0 10.0 20.0 50.0 100.0 200.0
5e+0
41e
+05
2e+0
55e
+05
1e+0
62e
+06
5e+0
61e
+07
2e+0
7
Count + jitter[AssignedState + 1]
Leng
th
0.5 1.0 2.0 5.0 10.0 20.0
5e+0
41e
+05
2e+0
55e
+05
1e+0
62e
+06
5e+0
61e
+07
2e+0
7
Count + jitter[AssignedState + 1]
Leng
th
0e+00 2e+05 4e+05 6e+05 8e+05 1e+06
0.01
0.02
0.05
0.10
0.20
0.50
1.00
size_indeceste
nkb.
indc
ount
s/su
m(s
tudy
.indc
ount
s)
CoriellNINDScapprincestanfordCombined
0 100 200 300 400 500 600 700 800 900 1000
100%
50%
20%
5%
10%
2%
1%
Singleton - Coriell Controls (550K, cells)Singleton - NINDS Controls (550K, cells)PARC (’CAP’) (317K, cells)PARC (’PRINCE’) (317K, blood)HGDP (650Y, cells)Combined
R: 1254x827
Frac
tion
of I
nd
ivid
ual
sMinimum Size (kb)
Itsara et al. Figure 5.
2000
50
100
200
500
1000
5000
10000
CN
V S
ize
(kb
)
Number of Individuals
Deletions
Homozygous Deletions
Duplications
R: 1254x865
1 ind 2 inds 3 1005 10
2000
50
100
200
500
1000
5000
10000
CN
V S
ize
(kb
)
Number of Individuals
Deletions
Homozygous Deletions
Duplications
R: 1254x865
20 50 250
0
1
2
5
10
25
Number of Overlapping Genes
0
1
2
5
10
25
# Genes:50
1 2 3 4-5 6-10 10-25 >25

• Non-Allelic Homologous Recombination (NAHR) between duplicated sequences results in novel CNVs
• Thousands of potential hotspots in the reference assembly (1 kb to Mbps in size)
• de novo hotspot mutations have been implicated as causative for a number of diseases
Genomic CNV ‘HotSpots’
>95% identical
Duplication/Deletion HotSpot

CNVs Enriched Near Segmental Duplications−1
.0−0
.50.
00.
51.
0
chr7 coordinates −− stanford.un.hmm.HGDP00382
LogR
and
B−A
llele
Fre
q
62810000 63420000 64020000 64630000 65240000 65840000
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●●
●●●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●●●
●●●
●
●●
●●
●
●
●
●
●
●●●
●●●●
●
●●
●●
●
●
●
●
●●●●
●●●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
● ●
●
●●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●●
●
●●●
●
●●
●
●
●
●●●●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
● ●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
● ●●
●●
●
●
chr7
LogR
and
B-A
llele
Fre
quen
cy

CNVs Enriched Near Segmental Duplications−1
.0−0
.50.
00.
51.
0
chr7 coordinates −− stanford.un.hmm.HGDP00876
LogR
and
B−A
llele
Fre
q
62810000 63420000 64020000 64630000 65240000 65840000
●
●●
●
●●
●●●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●●
●●
●●●●●
●●
●
●
●
●●
●
●●
●●
●
●
●●●
●●
●
●
●
●
●●●●●●
●●●●●●
●●●●●●
●●●
●●
●●
●●
●
●●
●
●● ●
●
●
●
●●●●
●
●
●●●
●●
●●
●●●
●●
●
●●
●●
●●
●●●●●●●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●●
●
●
●●●
●
●
●●
●●●●●
●
●
●
●
●
●●
●●
●●
●●
●
●●
●
●
●
●
●
●●
●●●
●
●
●●
●
●
●
●
●●●
●●●
●●
●●
●●
●
●
chr7
LogR
and
B-A
llele
Fre
quen
cy

−1.0
−0.5
0.0
0.5
1.0
chr7 coordinates −− stanford.un.hmm.HGDP00876
LogR
and
B−A
llele
Fre
q
62810000 63420000 64020000 64630000 65240000 65840000
●
●●
●
●●
●●●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●●
●●
●●●●●
●●
●
●
●
●●
●
●●
●●
●
●
●●●
●●
●
●
●
●
●●●●●●
●●●●●●
●●●●●●
●●●
●●
●●
●●
●
●●
●
●● ●
●
●
●
●●●●
●
●
●●●
●●
●●
●●●
●●
●
●●
●●
●●
●●●●●●●●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●●
●
●
●●●
●
●
●●
●●●●●
●
●
●
●
●
●●
●●
●●
●●
●
●●
●
●
●
●
●
●●
●●●
●
●
●●
●
●
●
●
●●●
●●●
●●
●●
●●
●
●
CNVs Enriched Near Segmental Duplications−1
.0−0
.50.
00.
51.
0
chr7 coordinates −− stanford.un.hmm.HGDP00382
LogR
and
B−A
llele
Fre
q
62810000 63420000 64020000 64630000 65240000 65840000
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●●
●●
●●●●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●●●
●●●
●
●●
●●
●
●
●
●
●
●●●
●●●●
●
●●
●●
●
●
●
●
●●●●
●●●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
● ●
●
●●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●●
●
●●●
●
●●
●
●
●
●●●●
●●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
● ●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●●
●
● ●●
●●
●
●
25X enrichment for CNVs between homologous duplications in the reference assembly

Hotspots Increase CNV Frequencies
~1%Duplications
increase CNV allele frequency

−1.0
−0.5
0.0
0.5
1.0
chr15 coordinates −− dup
LogR
and
B−A
llele
Fre
q
27720000 28470000 29230000 29990000 30740000 31500000
●●
●●●
●●●
●●● ●
●
●●●●●
●●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●●●●
●
●●
●
●●●
●
●●
●●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●●
●●
●
●●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●●●●
●
●
●●
●
●
●
●●●
●●
●●
●
●
●
●●●● ●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●●
●
●●●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●●●
●●●
●
●●●●●
●
●●
●●●
●
●
●●
●●
●●
●
●●●
●
●●
●
●
●●
●
●
●●●●●●
●
●
●●●
●●●●●
●●
●●●
●
●
●
●
●
●
●●
●●●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●●
●●
●
●●●
●
●●●
●●
●
●
●
●●
●
●
●●●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●●
●●
●
●
●
●
●●
●●●
●
●
●
●●
●●
●●
●
●
LogR
and
B-A
llele
Fre
quen
cy
0
-1
0.5
1
-0.5
chr15q13, near Prader-Willi
Large ‘HotSpot’ Duplication
1.8 Mbp
BP4 BP5

−1.0
−0.5
0.0
0.5
1.0
chr15 coordinates −− dup
LogR
and
B−A
llele
Fre
q
27720000 28470000 29230000 29990000 30740000 31500000
●●
●●●
●●●
●●● ●
●
●●●●●
●●
●
●●●
●
●
●
●●
●
●
●
●
●
●
●●
●●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●●●●
●
●●
●
●●●
●
●●
●●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●●
●●
●
●●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●●●●
●
●
●●
●
●
●
●●●
●●
●●
●
●
●
●●●● ●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●●
●
●●●
●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●●●
●●●
●
●●●●●
●
●●
●●●
●
●
●●
●●
●●
●
●●●
●
●●
●
●
●●
●
●
●●●●●●
●
●
●●●
●●●●●
●●
●●●
●
●
●
●
●
●
●●
●●●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●●
●●
●
●●●
●
●●●
●●
●
●
●
●●
●
●
●●●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●●
●●
●
●
●
●
●●
●●●
●
●
●
●●
●●
●●
●
●
LogR
and
B-A
llele
Fre
quen
cy
0
-1
0.5
1
-0.5
chr15q13, near Prader-Willi
Large ‘HotSpot’ Duplication
1.8 MbpReciprocal Deletion Associates with ID (Sharp et
al. 2008) and Epilepsy (Helbig et al. 2009)
BP4 BP5

Neurological Disease Meta-Analysis
• Combined our ~2,500 samples with published CNV calls from ~3,000 controls analyzed using Affymetrix arrays (ISC Nature 2008)
• Combined genome-wide CNV annotations from 9 disease studies:
• schizophrenia: ~3,500 individuals
• autism: ~2,500 individuals
• intellectual disability: ~500 individuals
• mixture of Affy, Illumina, and CGH
• only analyzed CNVs > 500 kb

Neurological Disease Meta-Analysis
1 Mb 1 Mb
DeletionsDuplications
Disease
Controls Controls
Disease

Neurological Disease Meta-Analysis
1 Mb 1 Mb
22q11-12 (VCFS) Prader Willi,15q13DeletionsDuplications
Disease
Controls Controls
Disease
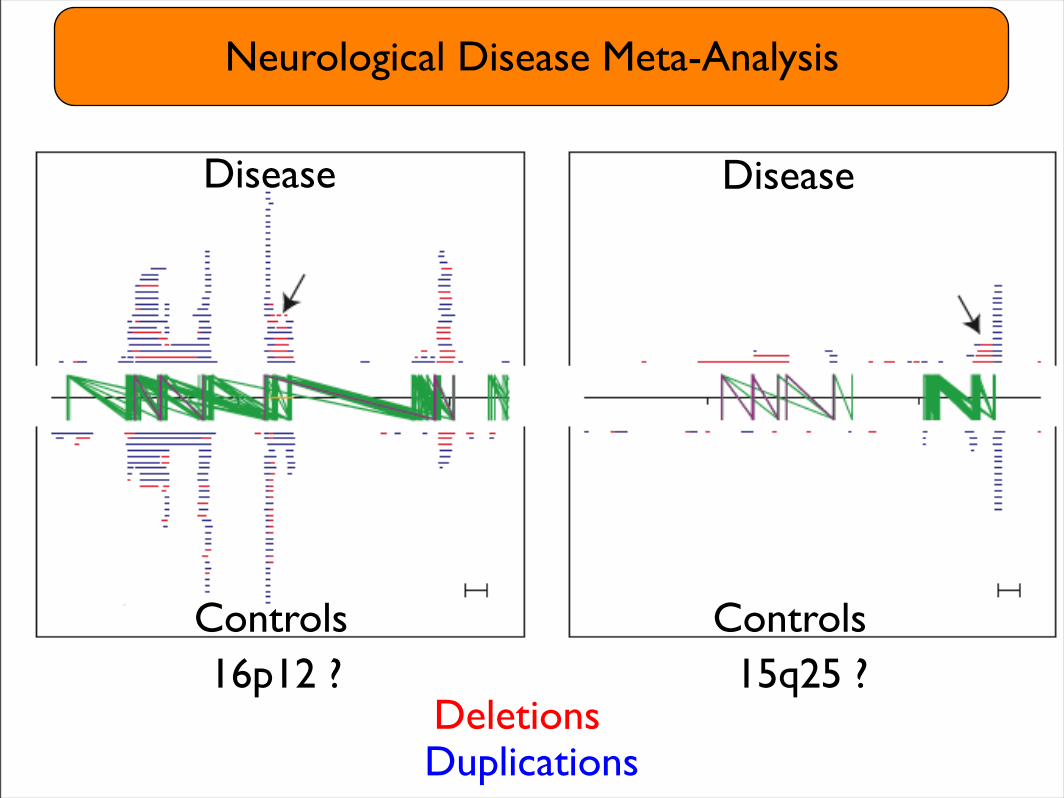
Neurological Disease Meta-Analysis
1 Mb 1 Mb
DeletionsDuplications
16p12 ? 15q25 ?
Disease
Controls Controls
Disease

Chr Start Stop Type Note NAHR? Disease CNVs
Control CNVs
Diseases
chr22chr15chr1chr15chr1chr16chr22chr16chr15chr16chr16chr17chr22chr11chr2chr9chr3chr16chr17
17,014,90027,015,263142,540,00018,376,200142,800,58021,693,73945,144,02760,141,70082,573,42180,737,83929,474,81014,000,00047,572,87578,120,000184,270,000
206456197,179,15629,470,95112,650,000
19,993,12730,650,000146,059,43330,756,771146,009,43622,611,36349,509,15361,581,60083,631,69782,208,45130,235,81815,421,83548,323,41785,610,000186,892,000
1599250198,842,29930,252,47315,540,000
losslosslossgaingainlosslosslosslossgaingainlossgainlossgaingainlosslossgain
VCFS15q131q21.1
PW/15q131q21.116p12
Term 2216q2115q25
16q23.316p11.2HNPP
Term 2211q142q329p243q29
16p11.2CMT1A
yesyesyesyesyesyesnonoyesnoyesyesnonononoyesyesyes
311924451254444665333384
00313300000111000031
A,S,IDS
A,S,CA,S,ID,CA,S,ID,C
A,SAA
A,SA,S
A,S,CA,S,CA,S,CS,IDA
A,SS
A,CA,S,ID,C
Neurological Disease CNVs

Chr Start Stop Type Note NAHR? Disease CNVs
Control CNVs
Diseases
chr22chr15chr1chr15chr1chr16chr22chr16chr15chr16chr16chr17chr22chr11chr2chr9chr3chr16chr17
17,014,90027,015,263142,540,00018,376,200142,800,58021,693,73945,144,02760,141,70082,573,42180,737,83929,474,81014,000,00047,572,87578,120,000184,270,000
206456197,179,15629,470,95112,650,000
19,993,12730,650,000146,059,43330,756,771146,009,43622,611,36349,509,15361,581,60083,631,69782,208,45130,235,81815,421,83548,323,41785,610,000186,892,000
1599250198,842,29930,252,47315,540,000
losslosslossgaingainlosslosslosslossgaingainlossgainlossgaingainlosslossgain
VCFS15q131q21.1
PW/15q131q21.116p12
Term 2216q2115q25
16q23.316p11.2HNPP
Term 2211q142q329p243q29
16p11.2CMT1A
yesyesyesyesyesyesnonoyesnoyesyesnonononoyesyesyes
311924451254444665333384
00313300000111000031
A,S,IDS
A,S,CA,S,ID,CA,S,ID,C
A,SAA
A,SA,S
A,S,CA,S,CA,S,CS,IDA
A,SS
A,CA,S,ID,C
Neurological Disease CNVs

Chr Start Stop Type Note NAHR? Disease CNVs
Control CNVs
Diseases
chr22chr15chr1chr15chr1chr16chr22chr16chr15chr16chr16chr17chr22chr11chr2chr9chr3chr16chr17
17,014,90027,015,263142,540,00018,376,200142,800,58021,693,73945,144,02760,141,70082,573,42180,737,83929,474,81014,000,00047,572,87578,120,000184,270,000
206456197,179,15629,470,95112,650,000
19,993,12730,650,000146,059,43330,756,771146,009,43622,611,36349,509,15361,581,60083,631,69782,208,45130,235,81815,421,83548,323,41785,610,000186,892,000
1599250198,842,29930,252,47315,540,000
losslosslossgaingainlosslosslosslossgaingainlossgainlossgaingainlosslossgain
VCFS15q131q21.1
PW/15q131q21.116p12
Term 2216q2115q25
16q23.316p11.2HNPP
Term 2211q142q329p243q29
16p11.2CMT1A
yesyesyesyesyesyesnonoyesnoyesyesnonononoyesyesyes
311924451254444665333384
00313300000111000031
A,S,IDS
A,S,CA,S,ID,CA,S,ID,C
A,SAA
A,SA,S
A,S,CA,S,CA,S,CS,IDA
A,SS
A,CA,S,ID,C
Neurological Disease CNVs

Chr Start Stop Type Note NAHR? Disease CNVs
Control CNVs
Diseases
chr22chr15chr1chr15chr1chr16chr22chr16chr15chr16chr16chr17chr22chr11chr2chr9chr3chr16chr17
17,014,90027,015,263142,540,00018,376,200142,800,58021,693,73945,144,02760,141,70082,573,42180,737,83929,474,81014,000,00047,572,87578,120,000184,270,000
206456197,179,15629,470,95112,650,000
19,993,12730,650,000146,059,43330,756,771146,009,43622,611,36349,509,15361,581,60083,631,69782,208,45130,235,81815,421,83548,323,41785,610,000186,892,000
1599250198,842,29930,252,47315,540,000
losslosslossgaingainlosslosslosslossgaingainlossgainlossgaingainlosslossgain
VCFS15q131q21.1
PW/15q131q21.116p12
Term 2216q2115q25
16q23.316p11.2HNPP
Term 2211q142q329p243q29
16p11.2CMT1A
yesyesyesyesyesyesnonoyesnoyesyesnonononoyesyesyes
311924451254444665333384
00313300000111000031
A,S,IDS
A,S,CA,S,ID,CA,S,ID,C
A,SAA
A,SA,S
A,S,CA,S,CA,S,CS,IDA
A,SS
A,CA,S,ID,C
Neurological Disease CNVs
•3q29 independently reported as an ID syndrome•16p12 deletion present in:
• a schizophrenia/ID affected family (from Mary-Claire King)• 3 schizophrenic and 2 control samples (from Jonathan Sebat)• 12 out of ~10,000 children with various cognitive deficits (Lisa Shaffer and Signature Genomics)

Large CNVs in Human Populations
• Large CNVs are collectively frequent (most individuals carry one or more large CNVs)
• Large CNVs are individually rare (usually <1% frequency)
• NAHR contributes to both common and rare variants:
• many CNVs will not be ‘taggable’ via SNPs
• ascertaining variation in/near duplications critical
• Highly penetrant CNVs, each explaining <1% of disease, may collectively make large disease contributions
• Accurate genotyping of rare CNVs in large numbers will be required to identify these

• Discovery is done per-sample, genome-wide, and without assumptions about breakpoints
• consequently, sensitivity is compromised to facilitate tolerable FDR
• Genotyping is targeted to known loci and applies to all samples simultaneously
• good sensitivity and specificity are required
• knowledge that a CNV is likely to exist and borrowing information across samples reduces the number of probes needed
CNV Genotyping vs Discovery

0.0 0.2 0.4 0.6 0.8 1.0 1.2
0.0
0.2
0.4
0.6
0.8
1.0
A/BA/AB/BA/ -B/ -- / -
A allele fluorescence (normalized units)
B al
lele
fluo
resc
ence
(nor
mal
ized
uni
ts)
SNP-based Common CNV Genotyping

SNP-Conditional Mixture Modeling (SCIMM) for Deletion Genotyping Input: SNP calls and quantitative data from multiple probes
Uses the EM algorithm to generate putative copy number calls (0, 1, 2) for each sample and a score for the probe set0.0 0.2 0.4 0.6 0.8 1.0 1.2
0.0
0.2
0.4
0.6
0.8
1.0
A/BA/AB/BA/ -B/ -- / -
A allele fluorescence (normalized units)
B al
lele
fluo
resc
ence
(nor
mal
ized
uni
ts)
SNP-based Common CNV Genotyping

SNP-Conditional Mixture Modeling (SCIMM) for Deletion Genotyping Input: SNP calls and quantitative data from multiple probes
Uses the EM algorithm to generate putative copy number calls (0, 1, 2) for each sample and a score for the probe set0.0 0.2 0.4 0.6 0.8 1.0 1.2
0.0
0.2
0.4
0.6
0.8
1.0
A/BA/AB/BA/ -B/ -- / -
A allele fluorescence (normalized units)
B al
lele
fluo
resc
ence
(nor
mal
ized
uni
ts)
SNP-based Common CNV Genotyping
SCIMM used to genotype hundreds of common deletions, replicate concordance and Mendelian consistency > 99%

Scaling Up CNV Genotyping
•Identification of pathogenic variants seen in 0.1% - 1% of affected people requires sample sizes in excess of 10,000
•Genome-wide platforms are better for coverage, but expensive
•NAHR hotspots define breakpoints and enrich for copy-number variation
•We developed a custom ‘BeadXpress’ assay to genotype rare CNVs in children affected by idiopathic intellectual disability

BeadXpress CNV Detection
• 384-plex Illumina ‘GoldenGate’ SNP genotyping (PCR-based) assay performed in 96-well plates
• 69 known and putative disease hotspots targeted, ~5 probes each
• 2 common CNVs and 1 X-linked site
• Analyzed 1,105 affected children and 39 control samples
•Follow-up validation with targeted array-CGH

●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●● ●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
● ●● ●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
● ●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
● ●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
0.0 0.1 0.2 0.3 0.4 0.5 0.6
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
rs$V4
rs$V5
Snp-Conditional OUTlier (SCOUT) Detection
A-allele Intensity
B-al
lele
Inte
nsity
SNP inside chr16 hotspot

●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●● ●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
● ●● ●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
● ●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
● ●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
0.0 0.1 0.2 0.3 0.4 0.5 0.6
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
rs$V4
rs$V5
Snp-Conditional OUTlier (SCOUT) Detection
A-allele Intensity
B-al
lele
Inte
nsity
SNP inside chr16 hotspot
‘ABB’
‘BBB’
‘AAB’
‘AAA’
‘B-’
‘A-’

●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●● ●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
● ●● ●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
● ●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
● ●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
0.0 0.1 0.2 0.3 0.4 0.5 0.6
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
rs$V4
rs$V5
Snp-Conditional OUTlier (SCOUT) Detection
A-allele Intensity
B-al
lele
Inte
nsity
SNP inside chr16 hotspot
‘ABB’
‘BBB’
‘AAB’
‘AAA’
‘B-’
‘A-’

●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●● ●●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
● ●● ●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
● ●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
● ●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
● ●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
● ●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
0.0 0.1 0.2 0.3 0.4 0.5 0.6
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
rs$V4
rs$V5
Snp-Conditional OUTlier (SCOUT) Detection
A-allele Intensity
B-al
lele
Inte
nsity
SNP inside chr16 hotspot
‘ABB’
‘BBB’
‘AAB’
‘AAA’
‘B-’
‘A-’

10
0.0
0.1
0.2
0.3
0.4
SCOUT Score Bin
0
10
20
-15 5-10 -5
Perc
ent
0
30
40Positive Control DelsNovel Validated Dels
Positive Control DupsNovel Validated Dups
Diploid Sites
Accurate Detection of Rare Variants

10
0.0
0.1
0.2
0.3
0.4
SCOUT Score Bin
0
10
20
-15 5-10 -5
Perc
ent
0
30
40Positive Control DelsNovel Validated Dels
Positive Control DupsNovel Validated Dups
Diploid Sites
Specificity of ~99.99% (< 1 FP per plate)
with sensitivity to all known CNVs
Accurate Detection of Rare Variants

Disease-Relevant CNVs
LocusSize (MB)
Confirmed by array-CGH
Predicted> |6|
Combined frequency (n = 1,010)
1q21.1 dup 1.4 1 2 0.30%
15q11 BP1-BP3 del 5.7 1 0 0.10%
15q11 BP2-BP3 del 5.3 1 0 0.10%
15q24 del 2.2 0 1 0.10%
16p11.2 del 0.9 6 1 0.69%
16p11.2 dup 0.9 1 0 0.10%
16p12.2-p11.2 del 8.1 0 1 0.10%
16p13 BP1-BP2 del 1.2 1 1 0.20%
16p13 BP1-BP3 del 3.2 1 0 0.10%
17p11.2 del (SMS) 3.5 2 0 0.20%
17p12 del (HNPP) 1.4 1 0 0.10%
17p12 dup (CMT1A) 1.4 0 1 0.10%
17q12 del 1.6 1 0 0.10%
22q11.21 3-Mb del (VCFS) 2.9 2 1 0.30%
22q11.21 3-Mb dup 2.9 2 0 0.20%
22q11.21-q11.22 distal del 1.4 2 1 0.30%
TOTAL 22 9 3.08%

Disease-Relevant CNVs
LocusSize (MB)
Confirmed by array-CGH
Predicted> |6|
Combined frequency (n = 1,010)
1q21.1 dup 1.4 1 2 0.30%
15q11 BP1-BP3 del 5.7 1 0 0.10%
15q11 BP2-BP3 del 5.3 1 0 0.10%
15q24 del 2.2 0 1 0.10%
16p11.2 del 0.9 6 1 0.69%
16p11.2 dup 0.9 1 0 0.10%
16p12.2-p11.2 del 8.1 0 1 0.10%
16p13 BP1-BP2 del 1.2 1 1 0.20%
16p13 BP1-BP3 del 3.2 1 0 0.10%
17p11.2 del (SMS) 3.5 2 0 0.20%
17p12 del (HNPP) 1.4 1 0 0.10%
17p12 dup (CMT1A) 1.4 0 1 0.10%
17q12 del 1.6 1 0 0.10%
22q11.21 3-Mb del (VCFS) 2.9 2 1 0.30%
22q11.21 3-Mb dup 2.9 2 0 0.20%
22q11.21-q11.22 distal del 1.4 2 1 0.30%
TOTAL 22 9 3.08%
16p11.2 previously associated with autism, but most of the individuals here have intellectual
disability without autism

CNVs of Uncertain Pathogenicity
•Duplications at 16p13 seen in 11 (1.1%) of samples
•only seen in 2/2,493 controls (p = 4.7 x 10-5)
•deletion is known to be pathogenic
•duplication also enriched in schizophrenia
•Deletions at 15q11.2 seen in 8 (0.8%) of samples
•only seen in 3/2,493 controls (p = 0.003)
•near Prader-Willi critical region
•also enriched in schizophrenia

BeadXpress Pilot Results
• High-confidence diagnosis of 31 (3.1%) children carrying pathogenic variants (e.g. 1q21.1, 16p11.2, VCFS, SMS, etc)
•16p11.2 associates with intellectual disability and is not an autism allele per se
•Evidence for disease relevance of 16p13 dups and 15q11.2 deletions collectively seen in 19 (1.9%) affected children
•1,105 samples processed in < 1 month with costs 5-20X less than CGH or genome-wide SNP platforms
• New assay being designed for a larger batch of samples (5,000 - 10,000) and with probe selection optimizations

• Copy-number variation is an influential source of genomic variation in human populations
• Duplication architecture is a major contributor to both common and rare variation via NAHR
• Rare variants are contributors to substantial amounts of disease heritability
• Tools are now available to dramatically scale the the size and accuracy of CNV-disease association studies
General Conclusions

University of WashingtonEvan Eichler and Debbie NickersonAndy Itsara, Troy Zerr, Heather Mefford, Jeff Kidd, Josh Smith, Mark RiederEichler and Nickerson labsIllumina Human 1M HapMap Data: Dan Peiffer (Illumina)PARC Project: Ron Krauss (CHORI), Jerry Rotter (Cedar-Sinai)Neurological Disease Controls: Andy Singleton (NINDS)HGDP Samples: Devin Absher, Jun Li, and Rick Myers (HudsonAlpha)Funding: NHGRI/NHLBI; Merck, Jane Coffin Childs Foundation
Acknowledgments