a new approach for classification: visual simulation viewpoint zongben xu deyu meng xi’an jiaotong...
Post on 20-Dec-2015
225 views
TRANSCRIPT

A New Approach for A New Approach for ClassificationClassification::Visual Simulation Visual Simulation
ViewpointViewpointZongben Xu Zongben Xu Deyu MengDeyu Meng
Xi’an Jiaotong Xi’an Jiaotong UniversityUniversity

Introduction The existing approaches Visual sensation principle Visual classification approach Visual learning theory Concluding remarks
OutlineOutline

1. Introduction
Data Mining (DM): the main procedure of KDD, aims at the discovery of useful know-ledge from large collections of data. The knowledge mainly refers to
Clustering Classification Regression
……

Clustering
Partitioning a given dataset with known or un-known distribution into homogeneous subgroups.

Clustering
Object categorization/classification from remote sensed image example

Classification Finding a discriminant rule (a function f(x)) from
the experiential data with k labels generated from an unknown but fixed distribution (normally, k=2 is focused).

Classification
Face recognition example

Classification
Fingerprint recognition example

Regression Finding a relationship (a function f(x))
between the input and output training data generated by an unknown but fixed distribution

Regression
0 100 200 300 400 500-50
0
50
100
150
200
250
300 Measured values Prediction results
RSP
con
cent
rati
on ( g
/m3 )
Data series0 100 200 300 400 500
-100
0
100
200
300 Gaussian kernel Polynomial kernel
Res
idua
l err
or
Data series
Air quality prediction example (the data obtained at the Mong Kok monitory station of Hong Kong based on hourly continuous measurement during the whole year of 2000).

Existing Approaches for Clustering
Hierarchical clustering nested hierarchical clustering nonnested hierarchical clustering
SLINK COMLINK MSTCLUS
Partitional clustering K-means clustering Neural networks Kernel methods Fuzzy methods

Existing Approaches for ClassificationStatistical approach
Parametric methods Bayesian method
Nonparametric methods Density estimation method Nearest-neighbor method
Discriminant function approach Linear discriminant method Generalized linear discriminant method Fisher discriminant method
Nonmetric approach Decision trees method Rule-based method
Computational intelligence approach Fuzzy methods Neural Networks kernel methods: Support Vector Machine

Existing Approaches for Regression
Interpolation methodsStatistical methods
Parameter regression Non-parameter regression
Computational intelligent methods Fuzzy regression methods
-insensitive fuzzy c-regression model Neural Networks kernel methods: Support Vector Regression

Main problems encountered
Validity problem (Clustering): is there real clustering? how many?
Efficiency/Scalability problem: in most cases efficient only for small/ middle sized data set.
Robustness problem: most of the results are sensitive to model parameters, and sample neatness.
Model selection problem: no general rule to specify the model type and parameters.

Research agenda
The essence of DM is modeling from data. It depends not only on how the data are generated, but also on how we sense or perceive the data. The existing DM methods are developed based on the former principle, but less on the latter one.
Our idea is to develop DM methods based on human visual sensation and perception principle (particularly, to treat a data set as an image, and to mine the knowledge from the data in accordance with the way we observe and perceive the image).

Research agenda (Cont.)
We have successfully developed such an approach for clustering , particularly solved the clustering validity problem. See, Clustering by Scale Space Filtering,IEEE Transaction on PAMI, 22:12(2000), 1396-1410
This report aims at initiating the approach for classification, with an emphasis on solving the Efficiency/ Scalability problem and the Robustness problem.
The model selection problem is under our current research.
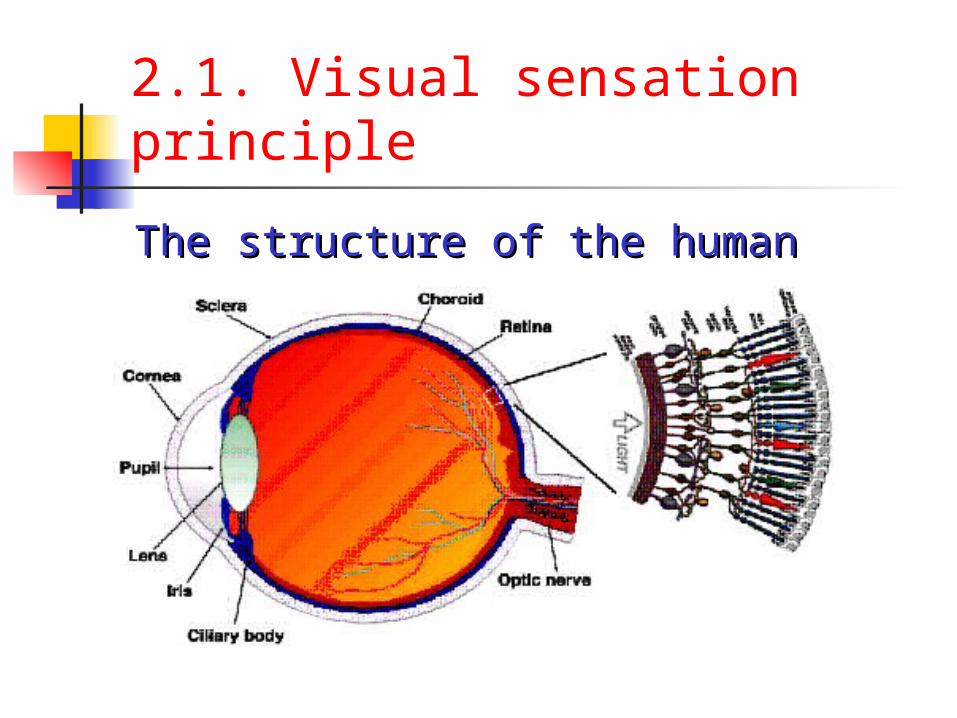
2.1. Visual sensation principle
The structure of the human The structure of the human eyeeye

2.1. Visual sensation principle
Accommodation (focusing) of an image by changing Accommodation (focusing) of an image by changing the the shapeshape of the crystalline lens of the eyes ( of the crystalline lens of the eyes (or or equivalently, by changing theequivalently, by changing the distance distance between between image and eye when the shape of lens is fixedimage and eye when the shape of lens is fixed))

2.1. Visual sensation principle
How How anan image in retinaimage in retina varies with the varies with the distancedistance between object and eye (or between object and eye (or equivalently, with the shape of crystalline equivalently, with the shape of crystalline lens)?lens)?
Scale space theoryScale space theory provides us an provides us an explanation. The theory is supported by explanation. The theory is supported by neurophysiologic findings in animals neurophysiologic findings in animals andand psychophysics in manpsychophysics in man directly. directly.

2.2. Scale Space Theory

2.2. Scale Space Theory

2.2. Scale Space Theory

2.3 Cell responses in retinaOnly change of light can be perceived and only Only change of light can be perceived and only three types of cell responses exist in retina:three types of cell responses exist in retina:
'ON''ON' response: the response response: the response to arrival of a light stimulus to arrival of a light stimulus (the blue region)(the blue region)
'OFF''OFF' response: the response to response: the response to removal of a light stimulus (the removal of a light stimulus (the red region)red region)
'ON-OFF''ON-OFF' response: the response: the response to the hybrids of ‘on’ response to the hybrids of ‘on’ and ‘off’ (because both and ‘off’ (because both presentation and removal of presentation and removal of the stimulus may the stimulus may simultaneously exist) (the simultaneously exist) (the yellow region)yellow region)

2.3. Cell responses in retinaBetween on and off regions, roughly Between on and off regions, roughly at the boundaryat the boundary is is a narrow region where on-off responses occur. Every a narrow region where on-off responses occur. Every cell has its own response strength, roughly, the strength cell has its own response strength, roughly, the strength is Gaussian-like.is Gaussian-like.

3. Visual Classification Approach: our philosophy

3. VCA: Our philosophy (Cont.)

3. VCA: A method to choose scale
An observationAn observation

3. VCA: A method to choose scale

3. VCA: Method to choose scale

3. VCA: Procedure

3. VCA: DemonstrationsLinearly separable data without noiseLinearly separable data without noise

3. VCA: DemonstrationsLinearly separable data with 5% noiseLinearly separable data with 5% noise

3. VCA: DemonstrationsCircularly separable data without noiseCircularly separable data without noise

3. VCA: DemonstrationsCircularly separable data with 5% noiseCircularly separable data with 5% noise

3. VCA: Demonstrations
Spirally separable data without Spirally separable data without noisenoise

3. VCA: Demonstrationsspirally separable data with 5% noisespirally separable data with 5% noise
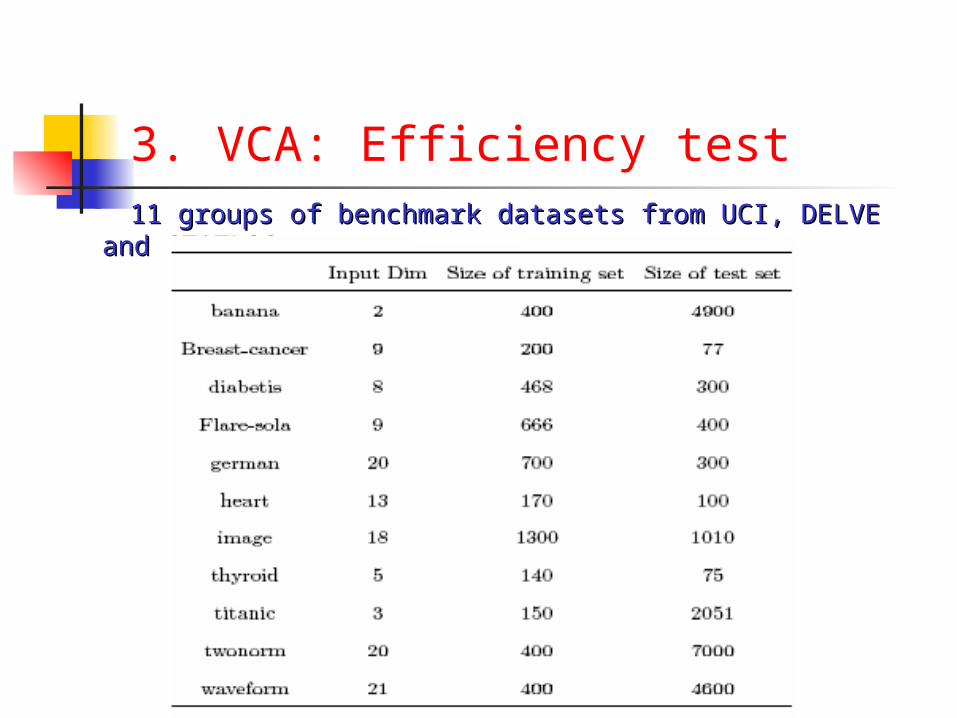
3. VCA: Efficiency test 11 groups of benchmark datasets from UCI, DELVE and 11 groups of benchmark datasets from UCI, DELVE and
STATLOGSTATLOG

3. VCA: Efficiency testPerformance comparison between VCA Performance comparison between VCA
& SVM& SVM

3. VCA: Scalability test
Time complexity of VCA with increase of size of training Time complexity of VCA with increase of size of training data is quadratic (a), with increase of dimension of data is quadratic (a), with increase of dimension of data is linear (b). data is linear (b).
(a): fixed 10-D but varying (a): fixed 10-D but varying size size data sets are used.data sets are used.
(b): Fixed 5000 size but varying (b): Fixed 5000 size but varying dimension datasets are dimension datasets are used.used.

3. VCA: conclusion
1.1. Without increase of misclassification rate (namely, loss of Without increase of misclassification rate (namely, loss of generalization capability), much less computation effort is paid, generalization capability), much less computation effort is paid,
as as compared with SVM (approximately 0.7% times of SVM is requircompared with SVM (approximately 0.7% times of SVM is required, ed, increasing 142 times computation efficiency). That is, increasing 142 times computation efficiency). That is, VCA has vVCA has very ery high computation efficiency.high computation efficiency.
2.2. The VCA ‘s training time increases linearly with dimension The VCA ‘s training time increases linearly with dimension and quadtratically with size of training data. This shows that and quadtratically with size of training data. This shows that VCVCA A has a very good scalabityhas a very good scalabity. .

4. Theory: Visual classification machine
Formalization (Learning theory)Formalization (Learning theory)
Let Let be sample space ( be pattern space be sample space ( be pattern space
and and label space), and assume that label space), and assume that
there exists a fixed but unknown relationship there exists a fixed but unknown relationship FF (or (or
equivalently, there is a fixed but unknown distribution equivalently, there is a fixed but unknown distribution
on ). on ).
Given a family of functionsGiven a family of functions
and a finite number of samplesand a finite number of samples
which is drawn independently identically according to .which is drawn independently identically according to .
{ ( , ), }H f x
{ 1,1}Y
1{ , }ll i i iD x y Z
~
( , ) ( ) ( / )F x y F x F y x
~
F
Z X Y
Z
X

4. Theory: Visual classification machine
We are asked to find a function in We are asked to find a function in which ap which approximates proximates FF in , that is, find a a function in in , that is, find a a function in , for , for a certain type of measurea certain type of measure Q Q between machine’s outbetween machine’s output and actual output , so that put and actual output , so that
(Learning problem)
where ~
( ( , )) ( , ( , )) ( , ).ZR f x Q y f x d F x y
* arg inf ( ( ))f H
f R f
(risk or generalization error)(risk or generalization error)
*f
* *( , )f f x
( , )f x
Formalization (cont.)Formalization (cont.)
H
Z H
y

4. Theory: Visual classification machine Learning algorithm (Convergence)
A learning algorithm L is a mapping from to H with the following property:
For any , there is an integer such that whenever ,
where .
In this case, we say that L(Z) is a -solution of the learning problem. Given an implementation scheme of a learning problem, we say it is convergent if it is a learning algorithm.
0, (0,1) ( , )l
{ ( ( )) ( ) } 1l FP R L D OPT H ( ) inf ( )F
f HOPT H R f
( , )
lD
( , )l l

4. Theory: Visual classification machine
Visual classification machine (VCM)
The function set
The generalization error
The learning implementation scheme (the procedure of finding ) (Is it a learning algorithm?)
, ,1
1{ ( ), 0,}, sgn( ( , ))
l l
l
D D i ii
H f x f y g x xl
~
, ,( ) | ( )) | ( , ).l lD Z DR f y f x d F x y
*
*
,1
1sgn( ( , ))
E l
l
i i EDi
f y g x xl
*
E

4. Theory: Visual classification machine
Learning theory of VCM
• How can the generalization performance of VCM be controlled (what is the learning principle)?
• If is it convergent? (If it is a learning algorithm?)
Key is to develop a rigorous upper bound Key is to develop a rigorous upper bound estimation on estimation on
and estimateand estimate ( ( )) ( ) .l FP R L D OPT H
,( ) ( )lD FP R f OPT H

4. Theory: Visual classification machine
This theorem shows that to maximize the This theorem shows that to maximize the generalization of the machine is equivalently to generalization of the machine is equivalently to minimize . minimize .

4. Theory: Visual classification machine
VCA is just designed to approximate here. This VCA is just designed to approximate here. This reveals the learning principle behind VCA and explain reveals the learning principle behind VCA and explain why VCA has strong generalization capability.why VCA has strong generalization capability.
*, ,l

4. Theory: Visual classification machine
This theorem shows that the VCA is a learning This theorem shows that the VCA is a learning algorithm. Consequently, a learning theory of VCM is algorithm. Consequently, a learning theory of VCM is established.established.

5. Concluding remarks The existing approaches for classification has mainly been aimed t
o exploring the intrinsic structure of dataset, less or no emphasis paid on simulating human sensation and perception. We have initiated an approach for classification based on human visual sensation and perception principle (The core idea is to model the blurring effect of lateral retinal interconnections based on scale space theory). The preliminary simulations have demonstrated that the new approach potentially is encouraging and very useful.
The main advantages of the new approach are its very high efficiency and excellent scalibility. It very often brings a significant reduction of computation effort without loss of prediction capability, especially compared with the prevalently adopted SVM approach.
The theoretical foundations of VCA, Visual learning theory, have been developed, which reveals that (1) VCA attains its high generalization performance via minimizing the upper error bound between actual and optimal risks (learning principle); (2) VCA is a learning algorithm.

5. Concluding remarks
Many problems deserve further research:Many problems deserve further research:
To apply nonlinear scale space theory for To apply nonlinear scale space theory for further efficiency speed-up;further efficiency speed-up;
to utilize VCA to practical engineering to utilize VCA to practical engineering problems (e.g., DNA sequence analysis);problems (e.g., DNA sequence analysis);
to develop visual learning theory for to develop visual learning theory for regression problem, etc. regression problem, etc.

Thanks !!