accelerating lammps performance
TRANSCRIPT

Sandia National Laboratories is a multimission laboratory managed and operated by National Technology and Engineering Solutions of Sandia, LLC., a wholly owned subsidiary of Honeywell International, Inc., for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-NA-0003525. SAND2017-8029 C
AcceleratingLAMMPSPerformanceStanMoore
2017LAMMPSWorkshopandSymposiumBreakoutsession:AccelerationPackages
Albuquerque,NM

LAMMPSResourcesforPerformanceAcceleration
§ Hardwaresupport§ CPUincludingOpenMP§ GPUviaCuda§ KNLviaOpenMP
§ Website:Benchmarkingpage(discussedinthissession)§ inputfiles,Makefiles,run commands,logfiles,plots&tables
§ Distro§ benchdirectory
§ Manual§ Section5=AcceleratingLAMMPSperformance§ Section5.3.1=GPUpackage§ Section5.3.2=USER-INTELpackage§ Section5.3.3=KOKKOSpackage§ Section5.3.4=USER-OMPpackage§ Section5.3.5=OPTpackage§ Section8=PerformanceandScalability
2

LAMMPSResources(cont.)
§ Packages§ GPU,KOKKOS,OPT,USER-INTEL,USER-OMP
§ Makefiles insrc/MAKE/OPTIONSdir§ Makefile.kokkos,severalvariants:Cuda,KNL,OpenMP§ Makefile.intel,severalvariants:CPUandKNL§ Makefile.omp
§ Commands§ balance,fixbalance,processors,runstyleverlet/split
§ Exampledirs§ balance
3

OutlineofTopics
§ LAMMPSacceleratorpackages§ Overview§ Howandwhentousethem
§ Newbenchmarkingwebsite§ RecentworktoimproveLAMMPSperformance§ Otherperformanceconsiderations§ Discussion
Pleasefeelfreetoaskquestions,givesuggestions,ordiscussduringthepresentation
4

LAMMPSAcceleratorPackages
§ ModernHPCplatformssuchasmulti-coreCPUs,XeonPhis,andGPUsoftenneedtousespecialcode(e.g.OpenMP orCUDA)toallowLAMMPStoperformwell
§ LAMMPShas5acceleratorpackagesthatcontainspecializedcode:§ OPT§ USER-OMP§ USER-INTEL§ GPU§ Kokkos
5

OPTPackage
§ DevelopedbyJamesFischer(HighPerformanceTechnologies),DavidRichie,andVincentNatoli (StoneRidgeTechnologies)
§ MethodsrewritteninC++templatedformtoreducetheoverheadduetoiftests andotherconditionalcode
§ Codealsovectorizes betterthantheregularCPUversion§ Contains9pairstyles:
§ pair_eam_alloy§ pair_eam_fs§ pair_eam§ pair_lj_charmm_coul_long§ pair_lj_cut_coul_long§ pair_lj_cut§ pair_lj_cut_tip4p_long§ pair_lj_long_coul_long§ pair_morse
6

CompilingandRunningOPTPackage
§ Insrc directory,“makeyes-opt”§ CompileLAMMPS§ Runwith8MPI:“mpiexec -np8./lmp_exe -inin.lj -sfopt”§ -sfoptisthesuffix style:automaticallyappends/optonto
anythingitcan§ Forexample,“pair_style lj/cut”becomes“pair_style
lj/cut/opt”
7

USER-OMPPackage
§ DevelopedbyAxelKohlmeyer(TempleU)§ UsesOpenMP toenablemultithreadingonCPUsorXeonPhis§ ExtensiveLAMMPScoverage(108pairstyles,30fixes,moleculartopology
bonds,angles,etc.,PPPM,Verlet &rRESPA)§ Bestforasmallnumberofthreads(2-4)§ MPIparallelizationinLAMMPSisalmostalwaysmoreeffectivethan
OpenMP inUSER-OMPonCPUs§ WhenrunningwithMPIacrossmulti-corenodes,MPIoftensuffersfrom
communicationbottlenecksandusingMPI+OpenMP pernodecanbefaster
§ Themorenodesperjobandthemorecorespernode,themorepronouncedthebottleneckandthelargerthebenefitfromMPI+OpenMP
8

CompilingandRunningUSER-OMPPackage
§ Insrc directory,“makeyes-user-omp”§ Add-fopenmp totheMakefile§ CompileLAMMPS§ Runwith2MPIand2OpenMP threads:“mpiexec -np2 -v
OMP_NUM_THREADS=2./lmp_exe -inin.lj -sfomp”
9

USER-INTELPackage
§ DevelopedbyMikeBrown(Intel)§ Allowscodetovectorize andrunwellonbothIntelCPUs(withorwithout
threading)andonXeonPhis§ CanalsobeusedinconjunctionwiththeUSER-OMP package§ Supports11pairstyles,5fixes,somebondedstyles,PPPM§ Supportssingle,double,andmixedprecisionmodes
10

CompilingandRunningUSER-INTELPackage
§ NeedtousearecentversionoftheIntelcompiler§ UseaMakefile in/src/MAKE/OPTIONS/suchas
Makefile.intel_cpu_openmpi§ In/src “makeyes-user-intel”and“makeyes-user-omp”§ CompileLAMMPS§ Torunusing2MPIand2threadsonaIntelCPU:“mpiexec -np
2-vOMP_NUM_THREADS=2./lmp_exe -inin.lj -pk intel0omp 2modemixed-sfintel”
§ -pk isthepackagecommand
11

GPUPackage
§ DevelopedbyMikeBrownandTrung Nguyen(ORNL)§ DesignedforoneormoreGPUscoupledtomanyCPUs§ PairrunsonGPU,fixes/bonds/computesrunonCPU§ Atom-baseddata(e.g.coordinates,forces)movebackandforthbetween
theCPU(s)andGPUeverytimestep§ Supports49pairstyles,PPPM§ Asynchronousforcecomputationscanbeperformedsimultaneouslyon
theCPU(s)andGPU.§ AllowsforGPUcomputationstobeperformedinsingle,doubleprecision,
ormixedprecisionmode§ ProvidesNVIDIAandmoregeneralOpenCLsupport
12

CompilingandRunningGPUPackage
§ FirstcompileGPUlibraryinlib/gpu (make-fMakefile.linux.mixed)
§ Insrc directory,“makeyes-gpu”§ CompileLAMMPS§ Runwith16MPIand4GPUs:“mpiexec -np16./lmp_exe -in
in.lj -sfgpu -pk gpu 4”
13

Kokkos
§ Abstractionlayerbetweenprogrammerandnext-generationplatforms§ AllowsthesameC++codetorunonmultiplehardwares (GPU,XeonPhi,
etc.)§ CoredevelopersareCarterEdwardsandChristianTrott(Sandia)§ Kokkos consistsoftwomainparts:
1. Paralleldispatch—threadedkernelsarelaunchedandmappedontobackendlanguagessuchasCUDAorOpenMP
2. Kokkos views—polymorphicmemorylayoutsthatcanbeoptimizedforaspecifichardware
§ UsedontopofexistingMPIparallelization(MPI+X)§ Open-source,canbedownloadedathttps://github.com/kokkos/kokkos
14

Kokkos Package
§ DevelopedbyChristianTrott,StanMoore,RayShan(Sandia)andothers
§ SupportsOpenMP andGPUs§ ScalestomanyOpenMP threads§ Designedforone-to-oneGPUtoCPUratio§ Designedsothateverything(pair,fixes,computes,etc.)runs
ontheGPU,minimaldatatransferfromGPUtoCPU§ Currentlyonlydoubleprecisionissupported§ SupportsonlynewerNVIDIAGPUs
15

LAMMPSKokkos Package§ 6atomstyles:angle,atomic,bond,charge,full,molecular§ 34pairstyles: buck/coul/cut,buck/coul/long,buck,coul/cut,coul/debye,
coul/dsf,coul/long,coul/wolf,eam/alloy,eam/fs,eam,lj/charmm/coul/charmm/implicit,lj/charmm/coul/charmm,lj/charmm/coul/long,lj/class2/coul/cut,lj/class2/coul/long,lj/class2,lj/cut/coul/cut,lj/cut/coul/debye,lj/cut/coul/dsf,lj/cut/coul/long,lj/cut,lj/expand,lj/gromacs/coul/gromacs,lj/gromacs,lj/sdk,morse,sw,reax/c,table,tersoff,tersoff/mod,tersoff/zbl,vashishta
§ 12fixstyles:deform,langevin,momentum,nph,npt,nve,nvt,qeq/reax,reaxc/bonds,reaxc/species,setforce,wall/reflect
§ 1computestyle: temp§ 2bondstyles: fene,harmonic§ 2anglestyles: charmm,harmonic§ 2dihedralstyles:charmm,opls§ 1improperstyle:harmonic§ 1kspace style:pppm
16

Kokkos PackageOptions
§ Usingahalfneighborlistwithnetwon flagonisusuallybetterforCPUsbutrequiresatomicswhenusingmorethanonethread
§ Forpairwisepotentials,usingafullneighborlistdoublesthecomputationbutdoesn’trequirethreadatomicsandcanreducecommunication(oftenbetterforGPUandsometimesXeonPhi)
§ Usingthreadedcommunication(packing/unpackingbuffers)isfasterontheGPUsinceitavoidshost/devicememorytransferbutcanbeslowerontheCPUorXeonPhi
§ ThesedifferencesareimplementedasoptionsintheLAMMPSKokkos package
17

CompilingandRunningKokkos Package
§ Needc++11compiler(gcc 4.7.2orhigher,intel14.0orhigher,CUDA6.5orhigher)
§ In/src directory,“makeyes-kokkos”§ Buildwith/src/MAKE/OPTIONS/Makefile.kokkos_omp or
Makefile.kokkos_cuda_openmpi§ Runwith4MPIand4GPUs:“mpiexec -np4./lmp_exe -inin.lj
-kong4-sfkk”§ Runwith4OpenMP threads:“./lmp_exe -inin.lj -kont4-sf
kk -pk kokkos newtononneighhalfӤ Kokkos packagedocumentationwillbeupdatedsoon
18

ComparisonofKokkos toOtherLAMMPSPackages
§ USER-OMP§ Kokkos usesatomicsorafullneighborlisttoavoidwriteconflicts, whileUSER-
OMPusesmemoryduplication§ USER-OMPistypicallyfasterforafewnumberofthreads,whileKokkos is
morethread-scalable§ GPUpackage
§ GPUpackageonlyrunsthepairstyleandafewothercomputationsontheGPUandworksbestwhencoupledwithmanyCPUs
§ Kokkos packagetriestoruneverything(includingfixes,bonds,etc.)ontheGPU
§ USER-INTEL§ USER-INTELsupportssingle,doubleandmixedprecision,Kokkos currently
onlysupportsdoubleprecision§ USER-INTELvectorizes better
19

AcceleratorPackageRulesofThumb
CPUsandXeonPhis§ UseUSER-INTELifavailable§ Otherwiseifyouareusingafewthreads,useUSER-OMPor
OPT,otherwiseuseKokkos serialorKokkosGPUs§ Ifall/mostofthefixstylesareintheKokkos package,usethe
Kokkos package§ IfmanyfixesarenotyetintheKokkos package,usetheGPU
package§ IfyouwanttousemanymoreCPUsthanGPUs,usetheGPU
package§ Forsingleormixedprecision,usetheGPUpackage
20

NewBenchmarkWebsite
§ Verynon-trivialtogetoptimalperformanceonmodernHPCplatforms
§ CurrentLAMMPSbenchmarkingpageisoutdated§ NewLAMMPSbenchmarkingwebsitewillshowperformance
plotsfordifferentacceleratorpackagesondifferenthardware§ Willalsoincludelinksto:
§ Tablesoftimeforeachrun§ Makefiles usedforcompilingLAMMPS§ Listofmodulesloaded§ ExactMPIruncommandused,alongwithaffinitysettings§ LAMMPSlogfiles foreachrun
21

BenchmarkProblems
§ Lennard-Jones =atomicfluidwithLennard-Jonespotential§ EAM =metallicsolidwithEAMpotential§ Tersoff =semiconductorsolidwithTersoff potential§ Chain =bead-springpolymermeltof100-merchains§ Granular =chuteflowofsphericalgranularparticles§ Stilltobeadded:Rhodopsin (solvatedproteininbilayer),
ReaxFF,GayBerne
22

AcceleratorPackagesusedforBenchmarks
§ ForaccelerationonaCPU/IntelKNL:§ CPU=referenceimplementation,nopackage,noacceleration(CPU)§ OPTpackagewithgenericoptimizationsforCPUs(OPT)§ USER-OMPpackagewithOpenMP support(OMP)§ USER-INTELpackagewithCPUandprecisionoptions(Intel/CPU)§ KOKKOSpackagewithOMPoptionforOpenMP (Kokkos/OMP)§ KOKKOSpackagewithserialoption(Kokkos/serial)
§ ForaccelerationonanNVIDIAGPU:§ GPUpackage,withprecisionoptions(GPU)§ KOKKOSpackagewithCUDAoption(Kokkos/Cuda)
23

BenchmarkMachines
§ chama =IntelSandyBridge CPUs§ 1232nodes§ Onenode=dualSandyBridge:2S:[email protected],16cores,no
hyperthreading§ interconnect=Qlogic Infiniband 4xQDR,fattree
§ serrano =IntelBroadwellCPUs§ 1122nodes§ onenode=dualBroadwell2.1GHzCPUE5-2695,36cores+2x
hyperthreading§ interconnect=Omni-Path
24

BenchmarkMachines
§ mutrino =IntelHaswellCPUsandIntelKNLs§ ~100CPUnodes
§ onenode=dualHaswell2.3GHzCPU,32cores+2xhyperthreading§ ~100KNLnodes
§ node=singleKnight'sLandingprocessor,64cores+4xhyperthreading§ interconnect=CrayAriesDragonfly
25

BenchmarkMachines
§ ride80 =IBMPower8CPUsandNVIDIAK80GPUs§ 11nodes§ onenode=dualPower83.42GHzCPU(Firestone),16cores+8x
hyperthreading§ eachnodehas2TeslaK80GPUs(eachK80is"dual"with2internal
GPUs)§ interconnect=Infiniband
§ ride100 =IBMPower8CPUsandNVIDIAP100GPUs§ 8nodes§ onenode=dualPower83.42GHzCPU(Garrison),16cores+8x
hyperthreading§ eachnodehas4PascalP100GPUs§ interconnect=Infiniband
26

ParameterSweep
§ Don’tknowoptimalnumberofMPItasksvsOpenMP threadsornumberofhyperthreads touseapriori
§ ForGPUpackage,don’tknowoptimalnumberofCPUsperGPU
§ Useaparametersweeptofindoptimalsettingsforthedifferentpackages
§ Onlybestresultsforeachpackageincludedonthewebsite
27

TypesofRuns
§ Fixednumberoftimesteps (i.e.100)§ ForcheappotentialslikeLJ,runmaybetooshort,whichleadstohigh
varianceintheresults§ Forexpensivepotentialsorlargenumberofatoms,runmaytakea
longtime
§ Fixedtime(i.e.30seconds)§ Usefixhalttosetanapproximatetimelimit§ Canusefixednumberoftimesteps forthefirstparametersweepand
thenrefineresultswithfixedtime
28

TypesofScaling
§ Singlecore§ Singlenode§ Multi-nodestrongscalingupto64nodes(fixedproblemsize)§ Multi-nodeweakscalingupto64nodes(fixedproblemsize
pernode)§ AlsohavesomedataforKNLscalingupto8192nodes
29

Automation
§ Pythonscriptiscreatedforeverymachineandeverymodel§ Pythonscriptsworktogethertogeneratebatchscriptsfor
eachacceleratorpackageandmodel§ Batchscriptsaresubmittedtothejobqueueoneachmachine§ Pythonscriptpost-processlogfiles togeneratetablesof
timings,finds“best”timeinsweepofparameters§ Pythonscriptsgenerateplotsfromtablesandthengenerates
webpage§ LAMMPSisconstantlybeingimproved;easytorerunthe
benchmarksandregeneratethewebpagewithupdatedresults
30

InformationHierarchy
§ Foreachmodelandscalingtype(node,weaketc.),show§ Overallbestperformanceforeachmachineusinganyaccelerator
package
§ Resultsinthispresentationarepreliminaryandmaybeimproved 31
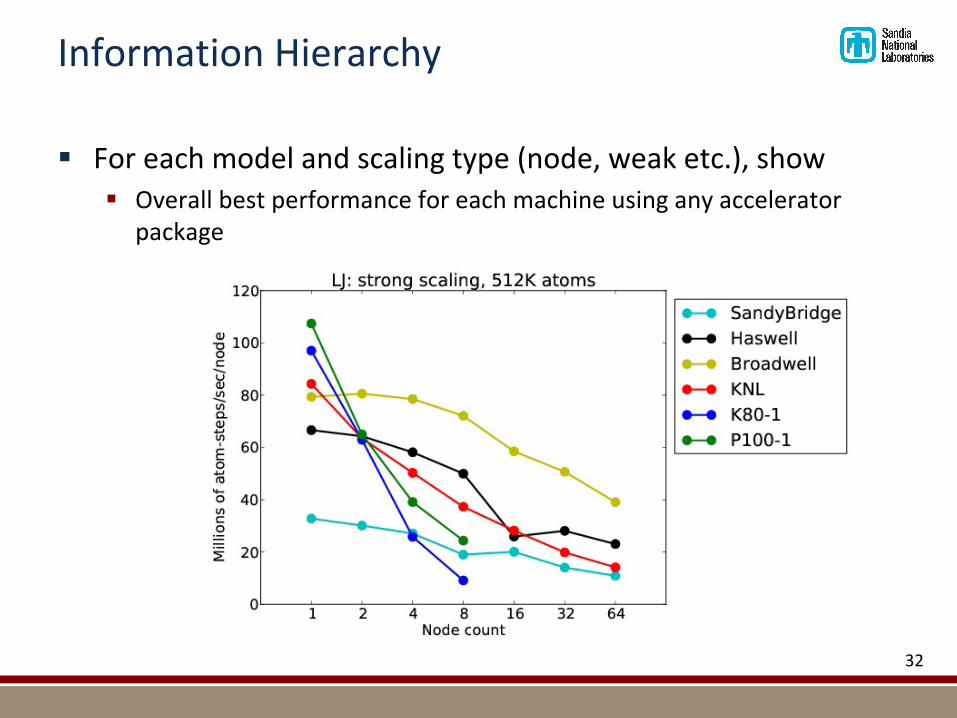
InformationHierarchy
§ Foreachmodelandscalingtype(node,weaketc.),show§ Overallbestperformanceforeachmachineusinganyaccelerator
package
32

InformationHierarchy
§ Foreachmodelandscalingtype(node,weaketc.),show§ Overallbestperformanceforeachmachineusinganyaccelerator
package
33

InformationHierarchy
§ Foreachmodelandscalingtype(node,weaketc.),show§ Overallbestperformanceforeachmachineusinganyaccelerator
package
34

InformationHierarchy
§ Foreachmodelandscalingtype,alsoshow§ Tableofperformanceforeachmachineusinganyacceleratorpackage§ LinkstoLAMMPSlogfiles
35

InformationHierarchy
§ Foreachmachine,model,andscalingtype,show§ Performanceforeachacceleratorpackage(bestoutofparameter
sweep)
36

InformationHierarchy
§ Foreachmachine,model,andscalingtype,show§ Performanceforeachacceleratorpackage(bestoutofparameter
sweep)
37

InformationHierarchy
§ Foreachmachine,model,andscalingtype,show§ Performanceforeachacceleratorpackage(bestoutofparameter
sweep)
38

InformationHierarchy
§ Foreachmachine,model,andscalingtype,show§ Performanceforeachacceleratorpackage(bestoutofparameter
sweep)
39

InformationHierarchy
§ Foreachmachine,model,andscalingtype,show§ Performanceforeachacceleratorpackage(bestoutofparameter
sweep)
40

InformationHierarchy
§ Foreachmachine,model,andscalingtype,show§ Performanceforeachacceleratorpackage(bestoutofparameter
sweep)
41

InformationHierarchy(cont.)
§ Foreachmachine,model,andscalingtype,alsoshow§ Tableofperformanceforeachacceleratorpackage(bestoutof
parametersweep)
42

RecentPerformanceWork
§ USER-INTELaddedfullneighborlistwithnewtonoff,canbebetterforsimplepair-wisepotentialsonXeonPhi
§ Added“short”neighborlisttoCPU,OpenMP,Kokkos andGPU(notyetreleased)many-bodypotentials(sw,tersoff,andvashishta)
§ KOKKOSpackageimprovedEAMandReaxFF performanceonGPUs
§ USER-OMPaddedmultithreadedReaxFF
43

ReaxFF
§ 4versionsinLAMMPS:§ USER-REAXC§ Fortran§ KOKKOS§ USER-OMP
§ KOKKOSversionmorememoryrobust,shouldbeusedwithGCMC
§ KOKKOSserialversionfasterthanUSER-REAXC,atleastinsomecases
§ KOKKOSversioncanrunonNVIDIAGPUs§ USER-OMPversionbrandnew,probablybetterforOpenMP
onXeonPhi/CPU(needtobenchmarkperformance)44

PerformanceRegressionTesting
§ Currentlyhaveautomated“codecorrectness”regressiontestingforLAMMPS
§ Butnoperformanceregressiontests§ Changestothecodecouldslowdownperformancewithout
developersknowledge§ Couldaddautomatedperformanceregressiontests
45

Long-RangeElectrostatics
§ Truncationdoesn’tworkwellforchargedsystemsduetolong-rangednatureofCoulombicinteractions
§ UseKspace styletoaddlong-rangeelectrostatics:§ PPPM—usuallyfastest,usesFFTs§ Ewald—potentiallymostaccurate,butslowforlargesystems§ MSM—multigridmethodthatalsoworksfornon-periodicsystems
§ Usuallyspecifyarelativeaccuracy(1e-4or1e-5typicallyused)
§ Examplesyntax(forperiodicsystems):kspace_style pppm1.0e-4
§ Usepair_style *coul/longsuchaslj/cut/coul/long
46

AcceleratingLRE
§ 2-FFTPPPM(kspace_modify diffad)§ StaggeredPPPM§ SinglevsdoubleprecisionPPPM§ PartialchargePPPM§ Verlet/splitrunstyle--canoverlappaircomputationwith
Kspace
47

OtherPerformanceConsiderations
§ ProcessorcommandforMPIgridlayout,canmaptonumaregions
§ Load-balancing§ balancecommand§ fixbalance
§ Affinityisimportantandcomplicated,seeexamplesonnewbenchmarkwebsite
48

Questions?Discussion/Suggestions?
49