access methods for next- generation database systems marcel kornacker uc berkeley
Post on 19-Dec-2015
218 views
TRANSCRIPT

Access Methods for Next-Generation Database
Systems
Marcel KornackerUC Berkeley

Overview and Motivation
• this talk’s topic: access method (AM) extensibility– how to support novel AMs in extensible ORDBMSs– not: yet another point, spatial, metric, ... AM
• outline:– AM extensibility architecture for ORDBMSs– concurrency & recovery– AM performance analysis

Overview and Motivation
• why bother with AMs:– we have B-trees– our customers don’t care
• well...– new apps need ORDBMS support: GIS, multimedia,
genomic sequence databases, etc.– customers do care about fast access to data– B-trees won’t help

Overview and Motivation
• AM extensibility: what has been done– slew of papers about novel AMs– slew of papers about extensible DBMSs (in 80s!)
• what needs to be done:– storage-level techniques for ORDBMSs:
reconciling functionality with performance and reliability
– AMs crucial to performance, deserve special attention

Outline
• Overview and Motivation• High-Performance Extensible Indexing
with Generalized Search Trees– AM Support in Commercial DBMSs– GiST Overview– IUS Implementation Overview
• Concurrency and Recovery• Access Method Performance Analysis

AM Support in Commercial DBMSs • OR modeling and extensibility very
successful in commercial DBMS, but:– AM extensibility has not received same degree of
attention– DBMS vendors now struggling to add/improve novel
(spatial) AMs
• State of art: IUS virtual index interface/Oracle extensible indexing interface:– iterator interface: open(), getnext(), close(), insert(),
delete()– AM handles internally: locking, recovery, page
management, … (same as built-in AMs)

AM Support in Commercial DBMSs (2)
• What’s wrong with this interface
S torage, B uffe r, Log, ...
Q uery P rocessing
R-tre
e
B+-tre
e
He
ap
New AMs stillrequire
custom CC&Rcode
– concurrency and recovery need to be (re-) implemented for each new AM
– difficult to implement: AM developer = domain expert, rarely also DBMS internals expert
– would prefer to deal purely with AM specifics: Generalized Search Tree

Generalized Search Tree Overview• Generalized Search Tree (GiST) = template
index structure– extensible set of data types and queries– customize tree behavior through extension methods– examples: B-trees, R-trees, …– details: Hellerstein, Naughton, Pfeffer, VLDB ‘95
• GiST provides– basic structure: height-balanced tree– template algorithms: search, insert and delete– no assumptions about keys and how they’re arranged– AM developer provides key-specific functions and
particular operational properties

Generalized Search Tree Overview
Internal Nodes
Leaf Nodes
SP1 SPnSP2...
…..
...
GiST AM Parameters
Union( ) updates SPs
Penalty( ) returns insertion cost
Subtree predicate (SP)=User-defined key
Consistent( ) returns true/false
PickSplit( ) splits page items into two groups
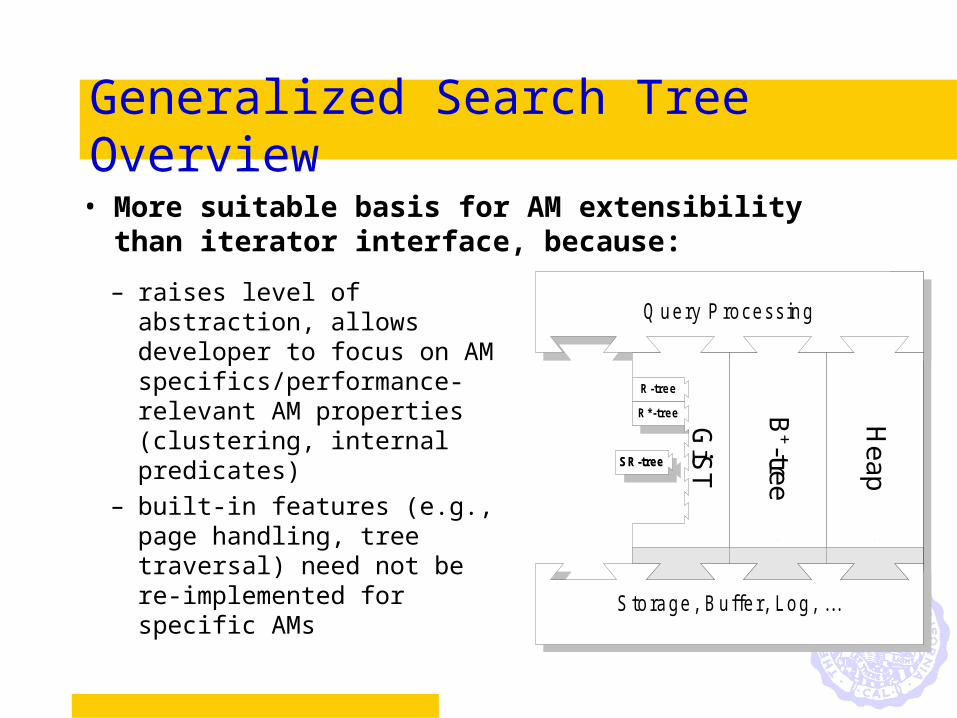
Generalized Search Tree Overview• More suitable basis for AM extensibility
than iterator interface, because:
Q uery P rocessing
S torage, B uffe r, Log, ...
He
ap
B+-tre
e
SR-treeSR-tree
GiS
T
R*-tree
R-tree
– raises level of abstraction, allows developer to focus on AM specifics/performance-relevant AM properties (clustering, internal predicates)
– built-in features (e.g., page handling, tree traversal) need not be re-implemented for specific AMs

Generalized Search Trees Overview• Goal of thesis work: making idea
industrial strength:– efficiency: Informix Universal Server impl (VLDB ’99)– concurrency & recovery (SIGMOD ’97)– analysis framework (demo SIGMOD ’98)

IUS GiST
• Datatype extensibility:– IUS allows UDTs to be indexed by built-in AMs– require same degree of datatype extensibility for GiST
• Good performance:– operations on UDTs implemented via UDFs, which are
orders of magnitude slower than regular function calls– GiST needs to avoid large number of UDF calls
• Intra-page storage format:– original GiST design assumed R-tree-like page layout– IUS GiST needs to allow customized formats (e.g., B-
tree, hB-tree) to support compression or simplified access

IUS GiST - Summary
• Extensibility architecture:– GiST core in server– AM extension in DataBlade, implements GiST API
• Improved GiST API– page-based, not entry-based: few UDF calls– leave page format to AM extension: very flexible

IUS GiST - Performance
• Comparison of GiST-based and built-in R-trees in IUS:– built-in R-tree: datatype extensible– software engineering: 1,400 lines of C for GiST R-tree
vs. 10,000 lines of C for built-in R-tree (GiST core: about 10,000 lines of C)
– performance: identical # of I/OS, GiST uses 14 to 40% less CPU time
• Reasons for GiST performance advantage:– far fewer UDF calls for GiST R-tree: on average 1 per
page (built-in: 1 per page entry)– but: higher set-up cost for GiST: needs to set up
descriptors for 11 interface UDFs (built-in: only needs 7 UDFs)

Outline
• Overview and Motivation• High-Performance Extensible Indexing
with Generalized Search Trees• Concurrency and Recovery
– Physical CC - concurrent index operations – Logical CC - transaction isolation – Recovery and how it affects concurrency
• Access Method Performance Analysis

Concurrent Index Ops• Problem: concurrent structure modifications
(example: B-tree)
4
7641
4
641 87
7
D:7
I:8 D:7
• Lock-coupling strategy with repositioning (ARIES/IM): requires key ordering
• B-link tree strategy: compensation during traversal

Concurrent Index Ops
• Navigating linked nodes:– how to detect node split?– when to stop going right?
• Structural GiST extensions– global sequence counter – sequence number (NSN) for each node

Concurrency Extensions
• Remember and compare global counter with NSNs
• NSNs allow split compensation independently of key properties
• Can be implemented very efficiently in typical WAL environments
2
D:
I: D:
1
3
12
3
6
5 6
counter: counter:

A Word on Latch-Coupling
• Popular technique for B-trees (ARIES/IM):– hold parent latched while going to child– avoid invalid pointers after node deletion
• Won’t work for GiST:– GiST search might traverse multiple subtrees– either: keep parent latched while traversing all
children (low conc.)– or: reposition in parent after traversing each child– but: repositioning requires partitioning

Transaction Isolation
• SQL Isolation Levels:– most of it: locks on base table items (unrelated to
index)– hard part: “serializable” isolation level (i.e.,
preventing phantoms)
• Phantom Problem:– SELECT specifies logical range– need to prevent insertions into that range– can’t lock non-existing items

Transaction Isolation: B-Trees
• B-Trees: Example of Key-Range Locking– partition data space into intervals– each leaf item corresponds to interval– scan from 5 to 9: lock data in range, lock next key– insert 9: check interval 8-10 (check item 10)
3 1110987654

Transaction Isolation: GiSTs
• But: this doesn’t work for GiSTs!• Example:
– 2-dim point keysand search rectangle
– what are next keys?where do we findthem in tree?
x
y

Predicate Locking
• Idea:– readers register shared predicate (search qual.),
check exclusive predicates– updaters register exclusive predicate (updated item),
check shared predicates
• Compared to key-range locking– perfectly accurate, maximal concurrency– expensive: evaluate lots of predicates– no gradual expansion:
(1) lock entire range, even when cursor stops early (2) nearest-neighbor search locks entire tree

Hybrid Locking
• Instead: novel hybrid mechanism– 2-phase locking of retrieved, inserted and deleted
data records– restricted pred locking for phantom avoidance
(‘‘covering the holes’’)
• Restricted predicate locking– search predicate attached to every visited node
during traversal– structure mods replicate predicate attachments– no insert/delete predicates– insert only checks target leaf’s predicates

Hybrid Locking
• Example
8
121084 6
I:9S:5-9
5-9
5-9

Hybrid Locking
• In comparison to predicate locking:– retains perfect accuracy– fewer predicates to check (only those on leaf)– search and delete don’t check predicates– almost gradual expansion
• In comparison to key-range locking:– structure mods more expensive (replicating
predicate attachments)– high implementation complexity (replicating ...):
difficult/expensive to implement

Node Locking
• Simplified hybrid locking:– replace pred. attachments with node locks– block structure mods that would need to replicate
node locks
• Comparison to hybrid locking:– diminished accuracy/concurrency– structure mods cheap– higher implementation complexity

AM Recovery
• Purpose:– bring AM structure into working condition– restore AM contents to reflect committed xacts
• Reminder: WAL recovery– every update writes log record with redo and undo
info– rollback: apply undo portion in reverse chronological
order– restart, phase 1: apply redo portion in chronological
order– restart, phase 2: undo all uncommitted xacts

GiST Recovery
• Keys to high concurrency:– separate updates into contents change and structure
modification (operation, SMO)– “commit” SMOs separately and immediately– “logical” undo of contents change:
re-locate leaf, compensate update, only lock data, not structure
• Logical undo:– cannot re-traverse tree structure, but can follow
rightlinks– in Aries/IM, need tree-global latch to avoid this
situation

Summary & Conclusion
• GiST concurrency and recovery techniques:– Concurrency: adaption of link technique – Isolation: hybrid predicate/2-phase locking– Recovery: WAL-based a la ARIES– invisible to AM developer:
can write industrial-strength AMs without knowledge of server internals

Outline
• Overview and Motivation• High-Performance Extensible Indexing
with Generalized Search Trees• Concurrency and Recovery• Access Method Performance Analysis
– Motivation– Goals of Framework– Analysis Framework with Examples– amdb– Conclusion

Motivation
• Access method (AM) design and tuning is a black art– Which AM do I use to index my non-traditional data type?– What are contributions of individual design ideas?– How to explain performance differences between AMs?– How to assess AMs on their own?
• Current practice of performance analysis little help:– aggregate runtime or I/Os numbers provide no
explanations– measuring semantic properties (e.g., spatial overlap) is
domain-specific, not useful for general analysis framework

Goals of Analysis Framework (1)
• Measure performance in context of specific workload (data and queries)– recognize workload as part of analysis input– compare workloads by running against same AM– allows tuning of AM for specific workload
• Performance metrics characterize observed performance (I/Os)– independent of data or query semantics– reflects purpose of performance tuning

Goals of Analysis Framework (2)
• Metrics express performance loss– loss = difference between observed and optimal
performance– shows potential for performance improvement– optimal performance obtained by executing workload in
optimal tree– fixed point of reference allows AM to be assessed on its
own
• Loss metrics for each query, node of input tree and structure-shaping aspects of implementation– breakdown allows performance flaws to be traced back,
facilitates assessment of individual design aspects

Analysis Framework: Overview (1)
• Performance-relevant aspects of tree:– Clustering: determines amount of data that query
accesses beyond result set– Page Utilization: determines number of pages that
data occupy– SPs: excess coverage (covers more data space than
is present in subtree) leads to extra traversals
• subdivide loss along those factors– break-down provides more detailed clues about
cause of performance loss

Analysis Framework: Overview (2)• Query Metrics:
– run each query in actual and optimal tree to obtain performance loss
– workload metrics: sum over all queries
• Node metrics: – node’s contribution to aggregate loss– obtained by computing per-node metrics for each
query and aggregating over workload
• Implementation metrics: – measure how much pickSplit() and penalty()
deteriorate tree– obtained by running sample splits and insertions

amdb
• Analysis, visualization and debugging tool that implements analysis framework
• Accepts AMs written for libgist• Available at http://gist.cs.berkeley.edu

amdb Features
• Tracing of insertions, deletions, and searches
• Debugging operations: breakpoints on node splits, updates, traversals, and other events
• Global and structural views of tree allow navigation and provide visual summary of statistics
• Graphical and textual view of node contents
• Analysis of workloads and tree structure
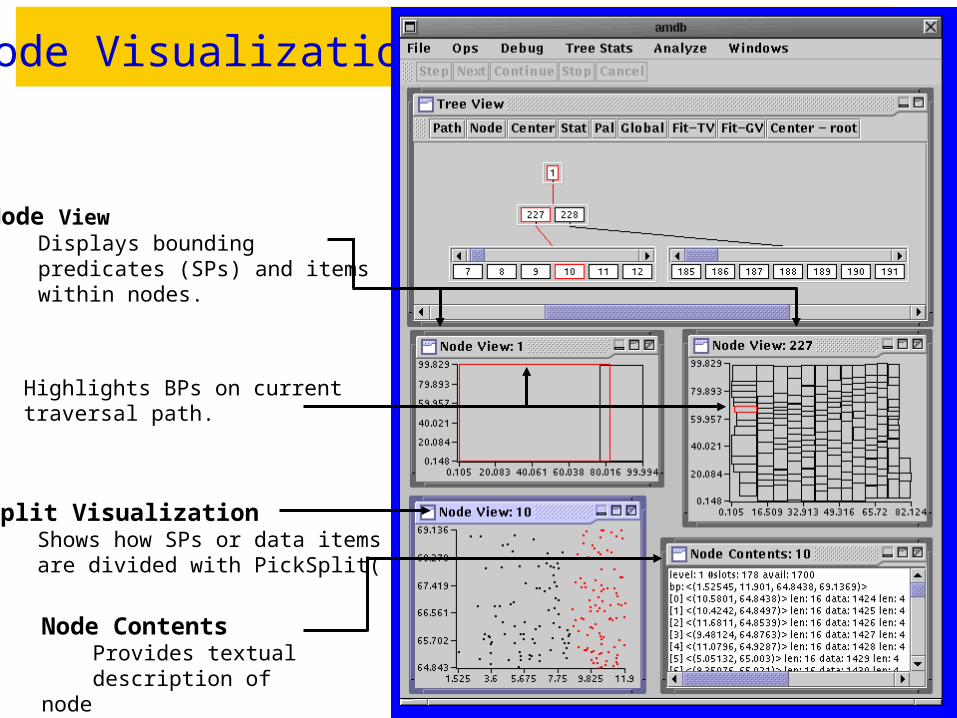
Node Visualization
Node View Displays bounding predicates (SPs) and items within nodes.
Node Contents Provides textual description of node
Split Visualization Shows how SPs or data items are divided with PickSplit( )
Highlights BPs on currenttraversal path.

Leaf-Level Statistics
I/O counts and corresponding overheads under various scenarios
{Breakdown of lossesagainst optimal clustering {
Total or per query breakdown
Global View Provides summary of node statistics for entire tree
Tree View Also displays node stats

Construction of Optimal Tree
• Optimal tree: optimal clustering, optimal page utilization, no excess coverage
• Optimal leaf level:– partition items to minimize number of page accesses– partition size = target page utilization– workload can be modeled as hypergraph,
approximate clustering with hypergraph partitioning algorithm
• Optimal internal levels:– cannot be constructed analogously– but: we assume target page utilization and no excess
coverage
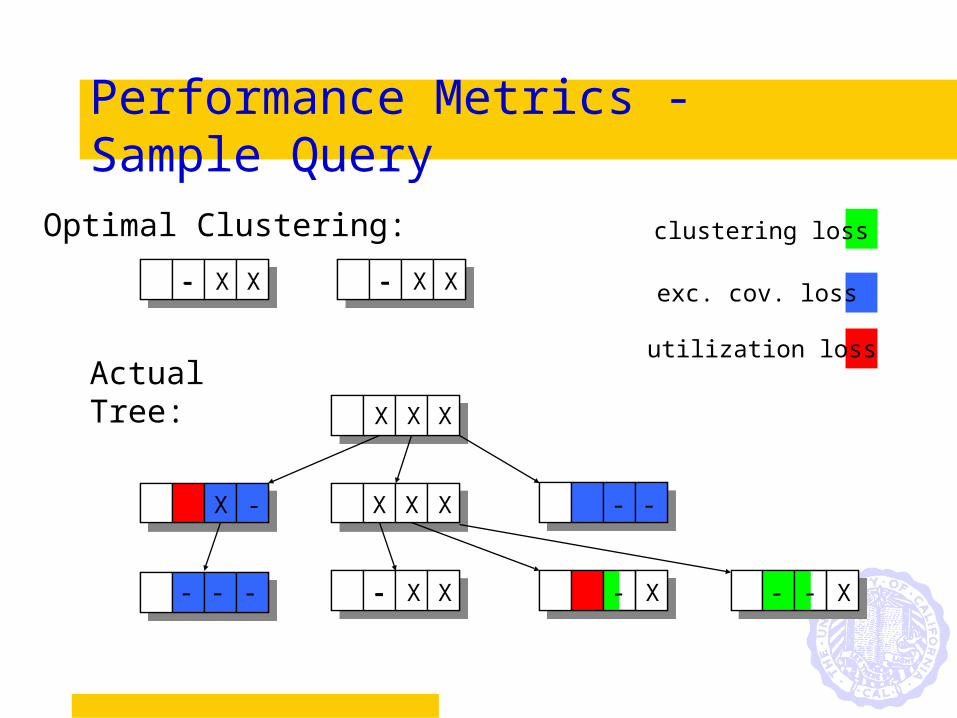
Performance Metrics - Sample Query
XXX X - - -
X -
- - - -
X X -
X XX
clustering loss
exc. cov. loss
utilization loss
X
-
-
X X-- X X--
Optimal Clustering:
Actual Tree:

Example 1: Unindexability Test
• Unindexable workload: aggregate leaf accesses in optimal tree take longer than sequential scan for each query– typical ratio of sequential/random I/Os: 14:1
• Conclusion: uniformly-distributed multi-dimensional point sets mostly unindexable

Example 2: Comparison of SP designs• Goal: assess effect of SP on nearest-neighbor
AMs– R*-trees: bounding rectangles, SS-trees: bounding spheres,
SR-trees: combination of BRs and BSs
• Experiment:– bulk-load 3 trees with identical data (only internal levels
differ)– data: 8-dim points, arranged into sphere-shaped clusters– measure excess coverage loss
• Results:– R*- and SR-tree identical, SS-tree order of magnitude worse
at leaf level– SR-tree paper came to contrary conclusion, because it
compared insertion-loaded trees

Summary (1)
• Analysis framework– workload (= data and queries) is part of input– comparison of observed with optimal performance– metrics express performance loss, subdivided into
clustering, utilization, excess coverage loss
• Advantages over current practice:– fixed point of reference allows AM to be assessed on
its own– metrics more meaningful than aggregate I/O
numbers, facilitate evaluation of individual design ideas
– metrics are independent of data or query semantics

Summary (2)
• amdb– implements framework, along with visualization and
debugging features– utilizes hypergraph partitioning to approximate opt.
clustering– user experience verifies usefulness of framework and
tool

Conclusion
• GiST-based AM extensibility is effective:– reduces implementation complexity w/o
performance/robustness penalty
• Focus on template data structure leads to general solutions:– generally applicable concurrency & recovery
protocols, performance analysis framework

Backup slides

Generalized Search Tree Overview• Search:
– traverse all subtrees for which Consistent(SP, qual) is true; return all leaf items for which Consistent(item, qual) is true
• Insert:– find leaf by following single path from root, guided
by Penalty()– if leaf is full, call PickSplit() to determine split info,
then perform split (recursively)– if SP needs to be updated, call Union(old SP, new
item) to determine new SP

Generalized Search Tree Overview• GiST = simple abstraction of search tree
– simple algorithms for basic functionality (search, insert, delete); easy to comprehend and extend
– full control over performance-relevant properties of tree:clustering and page util (PickSplit() and Penalty()), SPs
– captures essence of indexing:organize data into clusters, build directory structure to locate clusters

Extensibility Architecture: Overview
Q ueryProcessing
S torage, Buffer,Log, ...
G iSTPage
M anagem ent
G enericR -Tree
UnorderedLayout
C ircle
Point
R ect
UDF Call
C Function Call
Extension/ServerBoundary
GiST Core
AM Extension
Datatype Adapter

Extensibility Architecture: Overview (2)• GiST core:
– built into server, written by ORDBMS vendor– defines GiST interface, exports page mgmt interface– implements iterator interface defined by server– calls AM extension during insert(), delete(), getnext()– fully encapsulates locking and logging (to be shown)
• AM extension:– written by AM developer– defines extension interface – implements GiST interface defined by GiST core– calls GiST’s page mgmt interface functions

Extensibility Architecture: Overview (3)• Datatype adapter:
– written by (datatype) domain expert– implements extension interface defined by AM
extension

GiST Interface Overview
• Page-based, not entry-based– reduce # of UDF calls from 1 per entry to 1 per page– find_min_pen(): find page entry with smallest
insertion penalty– search(): find matching entries on page
• Leave page format to AM extension:– call AM extension fcts to update or extract data on
pages– insert(): add entry to page– update_pred(): update predicate part of entry– get_key(): extract key from page entry– remove(): remove entries from page

Conclusion
• GiST works!– reduces AM implementation complexity considerably
by factoring out common operation functionality (no locking and logging)
– separation of functionality achieves tight integration of external AM with server: same degree of concurrency and recoverability as built-in AMs
– improved GiST interface reduces # of costly UDF calls: more efficient than (naïve) built-in extensible AM
– improved GiST interface increases flexibility: customizable page layout

Implementation Details
• Two mechanisms for synchronization in DBMS
• Latches:– like mutexes, addressed physically– used for physical mem-resident resources (buffers)– no “latch manager”, no “deadlatch” detection– cheap
• Locks– addressed logically (lock name = integer)– used for non-mem-resident resources (pages, tuples)– lock manger (hash table) provides deadlock detection– not as cheap

Implementation Details (cont.)
• use latches to synchronize access to index pages(physical concurrency control)
• use locks to synchronize access to data(logical concurrency control)
• want deadlock-free protocol for AMs: can use latches
• want to avoid node latches during I/Os for GiST: high concurrency

Node Deletion
• No latch-coupling possible, can’t avoid incorrect pointers
• must delay deletion until there are no more traversals with pointer to node
• how to:– traversal sets S-lock on node when reading pointer– deletion sets X-lock on node– not pretty: replicate S-locks on node split (or prevent
them)

Implementing NSNs
• Global counter can become bottleneck:– read at each visited node– avoid by storing maximum child NSN in parent
• Global counter needs to be recoverable– end-of-log LSN is a good candidate– if not available, need to write log records

Transaction Isolation
• SQL Isolation Levels and how to achieve them– read uncommitted: no locks– read committed: instant-duration locks– repeatable read (read set won’t change): xact-dur.
locks– serializable (same op, same result, no phantoms): ??
• Phantom Problem:– SELECT specifies logical range– need to prevent insertions into that range– can’t lock non-existing items

AM Recovery
• Recovery affects concurrency:need to lock what you log (until commit)
• Keys to high concurrency:– separate updates into contents change and structure
modification (operation, SMO)– “commit” SMOs separately and immediately– “logical” undo of contents change:
re-locate leaf, compensate update, only lock data, not structure
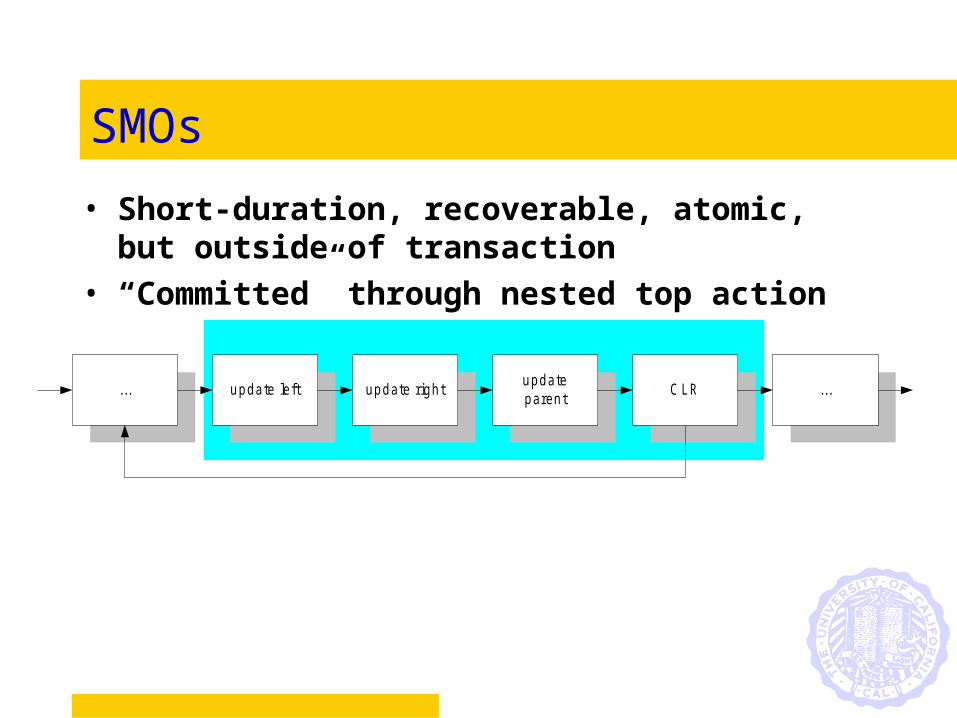
SMOs
• Short-duration, recoverable, atomic, but outside of transaction
• “Committed” through nested top action
update leftupdateparent
update right... ...CLR

Logical Undo
• Example for compensating action: re-traverse tree and delete leaf item to undo insert op
• Recovery affects concurrency, part II:at restart, no latches to protect inconsistent structure
• in GiST, cannot re-traverse tree, but can follow rightlinks
• in B-tree (Aries/IM), need tree-global latch to avoid this situation
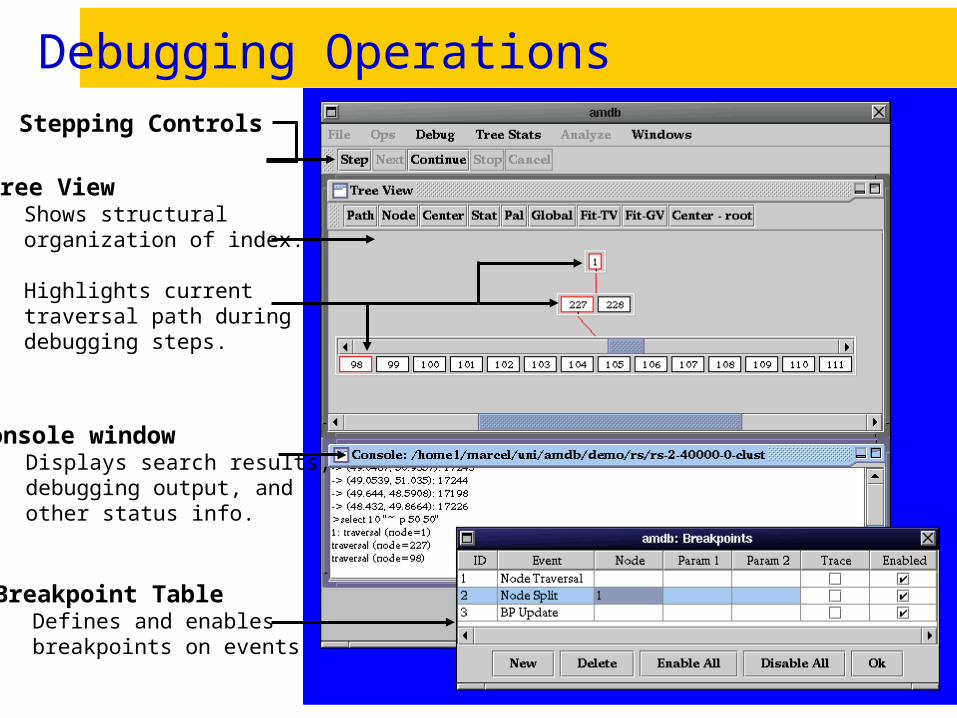
Debugging Operations
Tree View Shows structural organization of index.
Highlights current traversal path during debugging steps.
Stepping Controls
Breakpoint Table Defines and enables breakpoints on events
Console window Displays search results, debugging output, and other status info.

Subtree Predicate Statistics
Views highlightnodes traversed by query
Query breakdown in terms of “empty” and required I/O.
Excess Coverage Overheads due to loose/wide BPs

Conclusion
• GiST-based AM extensibility is effective:– reduces implementation complexity w/o
performance/robustness penalty
• Focus on template data structure leads to general solutions:– generally applicable concurrency & recovery
protocols, performance analysis framework
• Open problems:– automatic reorganization– automatic SP refinement– automatic AM design?

Motivation^2
• Before we launch into the details...– why worry about databases?– what are ORDBMSs again?– access methods...?

Motivation^2 (2)
• Why worry about databases– declarative access– transaction - simplicity for application– concurrency - 10,000s of simultaneous users– recovery - restore data after failure– flexibility - separate data from application– scalability - automatic parallelization

Motivation^2 (3)
• What are ORDBMSs again?– “object-relational DBMS”– combines object-oriented concepts with relational
DBMS functionality– in practice: extensibility of DBMS with new data
types– now supported by most big vendors (IBM, Informix,
Oracle), standardized in SQL3

Motivation^2 (4)
• Example: Geospatial data in Informix– implementation of user-defined type “GeoObject”
provided by dynamic library– register type and functions with system:
create opaque type GeoObject (...);create function Contains (GeoObject, GeoObject) returns boolean external name “<library path>”;
– store inside DBMS:create table customers (..., loc GeoObject, ...);insert into customers (...) values (..., “<x, y>”, ...);
– query data:select * from customers where Contains(“<area>”, loc);

Motivation^2 (5)
• Access methods...?– aka indices, e.g., B-trees– more generally: persistent data structure for
associative access– B-tree reminder:
• height-balanced tree structure• data at leaves in sorted order• directory structure in internal nodes• search proceeds from root to leaf• predictable performance