algorithm analysis: running time big o
DESCRIPTION
Algorithm Analysis: Running Time Big O. Introduction An algorithm analysis of a program is a step by step procedure for accomplishing that program In order to learn about an algorithm, we need to analyze it - PowerPoint PPT PresentationTRANSCRIPT

Sahar Mosleh California State University San Marcos Page 1
Algorithm Analysis:
Running Time Big O

Sahar Mosleh California State University San Marcos Page 2
Introduction
• An algorithm analysis of a program is a step by step procedure for accomplishing that program
• In order to learn about an algorithm, we need to analyze it
• This means we need to study the specification of the algorithm and draw conclusion about the implementation of that algorithm (the program) will perform in general

Sahar Mosleh California State University San Marcos Page 3
• The issues that should be considered in analyzing an algorithm are:
• The running time of a program as a function of its inputs
• The total or maximum memory space needed for program data
• The total size of the program code
• Whether the program correctly computes the desired result
• The complexity of the program. For example, how easy it is to read, understand, and modify the program
• The robustness of the program. For example, how well does it deal with unexpected or erroneous inputs

Sahar Mosleh California State University San Marcos Page 4
• In this course, we consider the running time of the algorithm.
• The main factors that effect the running time are the algorithm itself, input data, the computer system, etc.
• The performance of a computer is determined by• The hardware• The programming language used and • The operating system
• To calculate the running time of a general C++ program, we first need to define a few rules.
• In our rules , we are going to assume that the effect of hardware and software systems used in the machines are independent of the running time of our C++ program

Sahar Mosleh California State University San Marcos Page 5
Rule 1:• The time required to fetch an integer from memory is a
constant t(fetch),• The time required to store an integer in memory is also a
constant t(store)
For example the running time of x = y
is:t(fetch) + t(store)
because we need to fetch y from memory store it into x
Similarly the running time of x = 1
is also t(fetch) + t(store) because typically any constant is stored in the memory before it is fetched.

Sahar Mosleh California State University San Marcos Page 6
Rule 2 • The time required to perform elementary operations on integers,
such as addition t(+), subtraction t(-), multiplication t(*), division t(/), and comparison t(cmp), are all constants.
For Example the running time of y= x+1
is:2t(fetch) + t(store) + t (+)
because you need to fetch x and 1: 2*t(fetch) then add them together: t(+)and place the result into y: t(store)

Sahar Mosleh California State University San Marcos Page 7
Rule 3: • The time required to call a function is a constant, t(call) • And the time required to return a function is a constant, t(return)
Rule 4:
• The time required to pass an integer argument to a function or procedure is the same as the time required to store an integer in memory, t(store)

Sahar Mosleh California State University San Marcos Page 8
• For example the running time of y = f(x)
is:
t(fetch) + 2t(store) + t(call) + t(f(x))
Because you need • To fetch the value of x: t
(fetch)• Pass x to the function and store it into parameter: t (store)• Call the function f(x): t (call)• Run the function: t (f(x))• Store the returned result into y: t
(store)

Sahar Mosleh California State University San Marcos Page 9
Rule 5:• The time required for the address calculation implied by an array
subscripting operation like a[i] is a constant, t([ ]).
• This time does not include the time to compute the subscript expression, nor does it include the time to access (fetch or store) the array element
For example, the running time of y = a[i]
is:3t(fetch) + t([ ]) + t(store)
Because you need To fetch the value of i: t(fetch)To fetch the value of a: t(fetch)To find the address of a[i]: t([ ])To fetch the value of a[i]: t(fetch)To store the value of a[i] into y: t(store)

Sahar Mosleh California State University San Marcos Page 10
Rule 6: • The time required to calculate a fixed amount of storage from the
heap using operator new is a constant, t(new)• This time does not include any time required for initialization of
the storage (calling a constructor).
• Similarly, the time required to return a fixed amount of storage to the heap using operator delete is a constant, t(delete).
• This time does not include any time spent cleaning up the storage before it is returned to the heap (calling destructor)
For example the running time ofint* ptr = new int;
is:t(new) + t(store)
Because you need •To allocate a memory: t(new)•And to store its address into ptr: t(store)
For example the running time ofdelete ptr;
is:t(fetch ) + t(delete)
Because you need •To fetch the address from ptr : t(fetch)•And delete specifies location: t(delete)

Sahar Mosleh California State University San Marcos Page 11
1. int x Sum (int n)2. {3. int result =0;4. for (int i=1; i<=n; ++i)5. result += i;6. return result7. }
Statement Time Code
3 t(fetch)+ t(store) result = 0
4a t(fetch) + t(store) i = 1
4b (2t(fetch)+t(cmp)) * (n+1) i<=n
4c (2t(fetch)+t(+) +t(store)) *n ++i
5 (2t(fetch)+t(+) +t(store)) *n Result +=i
6 t(fetch)+ t(return) Return result
Total [6t(fetch) +2t(store) + t(cmp) + 2t(+)]*n+ [5t(fetch) + 2t(store) + t(cmp) + t(return) ]

Sahar Mosleh California State University San Marcos Page 12
1. int func (int a[ ], int n, int x)2. {3. int result = a[n];4. for (int i=n-1; i>=0; --i)5. result =result *x + a[i];6. return result7. }
Statement Time
3 3t(fetch)+ t([ ]) + t(store)4a 2t(fetch) + t(-) + t(store)4b (2t(fetch)+t(cmp)) * (n+1)4c (2t(fetch)+t(-) +t(store)) *n5 (5t(fetch)+t([ ])+t(+)+t(*)+t(store)) *n6 t(fetch)+ t(return)
Total [(9t(fetch) +2t(store) + t(cmp) +t([]) + t(*) + t(-)]*n+ [(8t(fetch) + 2t(store) + t([]) + t(-) +t(cmp) + t (return) )]

Sahar Mosleh California State University San Marcos Page 13
• Using constant times such as t(fetch), t(store), t(delete), t(new), t(+), …, ect makes our running time accurate
• However, in order to make life simple, we can consider the approximate running time of any constant to be the same time as t(1).
• For example, the running time of y = x + 1
is 3 because it includes two “fetches” and one “store” in which all are constants
• For a loop there are two cases:• If we know the exact number of iterations, the running time
becomes constant t(1)• If we do not know the exact number of iterations, the running
time becomes t(n) where n is the number of iterations
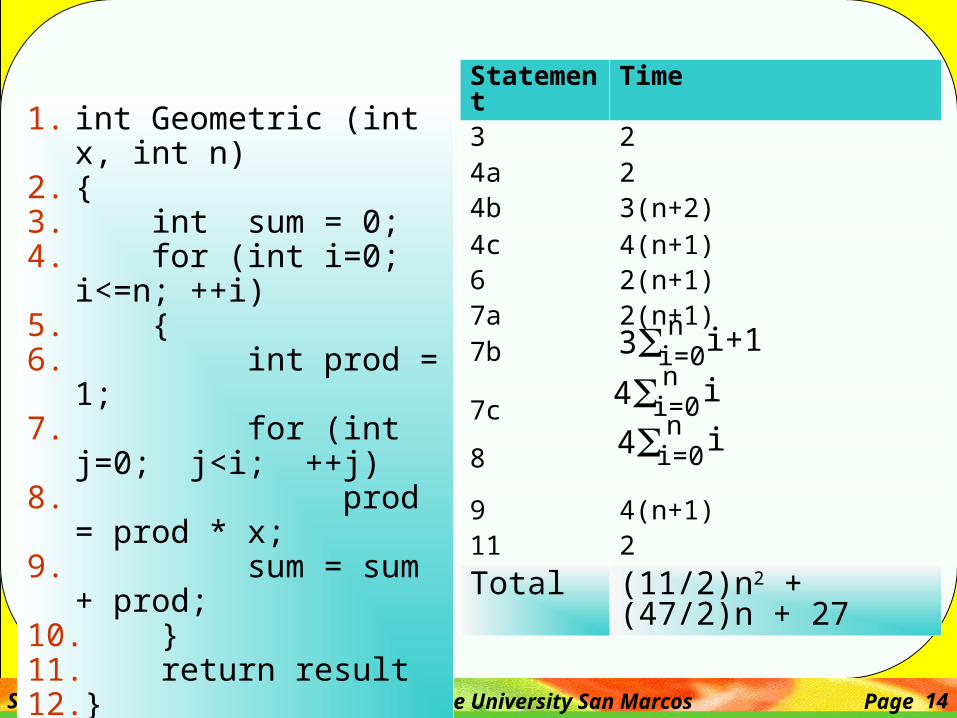
Sahar Mosleh California State University San Marcos Page 14
1. int Geometric (int x, int n)2. {3. int sum = 0;4. for (int i=0; i<=n; ++i)5. {6. int prod = 1;7. for (int j=0; j<i; ++j)8. prod = prod * x;9. sum = sum + prod;10. }11. return result12. }
Statement Time3 24a 24b 3(n+2)4c 4(n+1)6 2(n+1)7a 2(n+1)7b
7c
8
9 4(n+1)11 2
Total (11/2)n2 + (47/2)n + 27
i=0n
4 i
i=0n
4 i
i=0n
3 i+1

Sahar Mosleh California State University San Marcos Page 15
Asymptotic Notation • Suppose the running time of two algorithms A and B are TA(n) and
TB(n), respectively where n is the size of the problem
• How can we determine TA(n) is better than TB(n)?
• One way to do that is if we know the size n ahead of time for some n=no. Then we may say that algorithm A is performing better than algorithm B for n= no
• But this is a special case for n=no. How about n = n1, or n=n2? Is A better than B for other cases too?
• Unfortunately, this is not an easy answer. We cannot expect that the size of n to be known ahead of time. But we may be able to say that under certain situations TA(n) is better than TB(n) for all n >= n1

Sahar Mosleh California State University San Marcos Page 16
• To understand the running times of the algorithms we need to make some definitions:
• Definition:• Consider a function f(n) which is non-negative for all
integers n>=0. We say that “f(n) is big oh of g(n)” which we write (f(n) is O(g(n)) if there exists an integer no and a constant c > 0 such that for all integers n >=0, f(n) <=c g(n)
• Example: • Show that f(n) = 8n + 128 is O(n2)
8n + 128 <= c n2 (lets set c = 1)0 <= cn2 -8n -1280 <= (n-16) (n+8)
• Thus we can say that for constant c =1 and no >= 16 f(n) is O(n2)
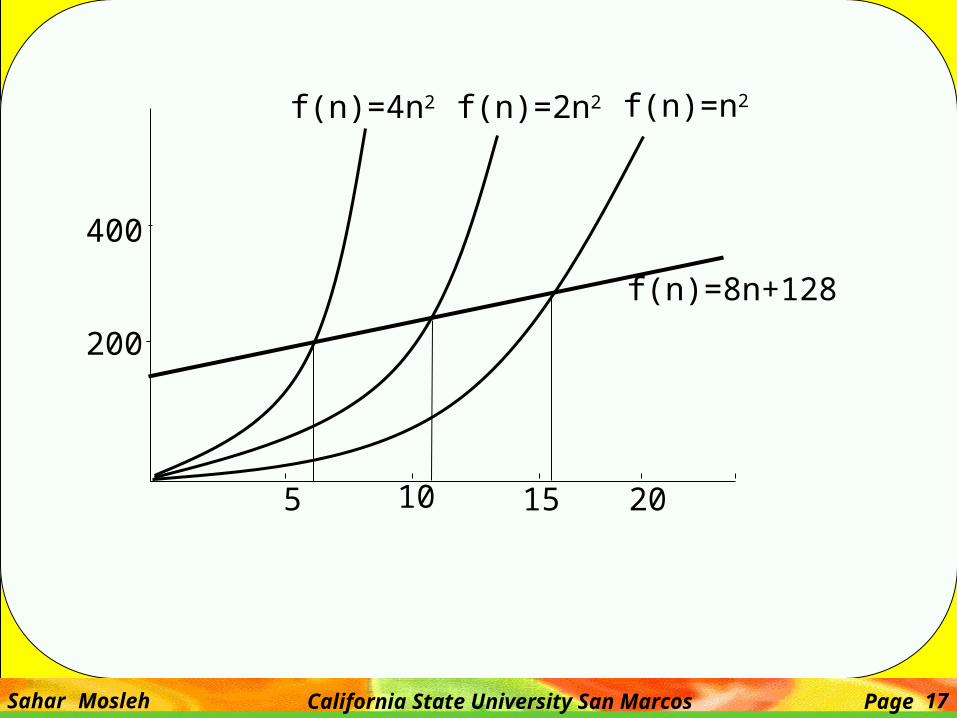
Sahar Mosleh California State University San Marcos Page 17
f(n)=n2f(n)=2n2f(n)=4n2
f(n)=8n+128
5 10 15 20
200
400

Sahar Mosleh California State University San Marcos Page 18
The names of common big O expressions
Expression NameO(1) ConstantO (log n) logarithmicO(log2 n) log squaredO (n) LinearO (n*log n) nlognO(n2) QuadraticO(n3) CubicO(2n) exponential

Sahar Mosleh California State University San Marcos Page 19
Conventions for writing Big Oh Expression
• Certain conventions have evolved which concern how big oh expression normally written:
• First, it is common practice when writing big oh expression to drop all but the most significant items. Thus instead of O(n2 + nlogn + n) we simply write O(n2)
• Second, it is common practice to drop constant coefficients. Thus, instead of O(3n2), we write O(n2). As a special case of this rule, if the function is a constant, instead of, say O(1024), we simply write O(1)

Sahar Mosleh California State University San Marcos Page 20
1. int func (int a[ ], int n, int x)2. {3. int result = a[n];4. for (int i=n-1; i>=0; --i)5. result =result *x + a[i];6. return result7. }
Statement Simple Time model
Big O
3 5 O(1)4a 4 O(1)4b 3n + 3 O(n)4c 4n O(n)5 9n O(n)6 2 O(1)Total 16n + 14 O(n
)
The total running time is:
O(16n + 14) = O(max(16n, 14))= O(16n)= O(n)

Sahar Mosleh California State University San Marcos Page 21
1. int PrefixSums (int a[ ], int n)2. {3. for (int j=n-1; i>=0; --j)4. {5. int sum = 0;6. for (int i=0; i<=j; ++i)7. sum = sum + a[i];8. a[j] = sum;9. }10. return result11. }
Statement Big O
3a O(1)3a O(1)*O(n)3c O(1)*O(n)5 O(1)*O(n)6a O(1)*O(n)6b O(1)*O(n2)6c O(1)*O(n2)7 O(1)*O(n2)9 O(1)*O(n)Total O(n2)

Sahar Mosleh California State University San Marcos Page 22
Sorting

Sahar Mosleh California State University San Marcos Page 23
• The efficiency of data handling can often be substantially increased if the data are sorted
• For example, it is practically impossible to find a name in the telephone directory if the items are not sorted
• In order to sort a set of item such as numbers or words, two properties must be considered
• The number of comparisons required to arrange the data• The number of data movement

Sahar Mosleh California State University San Marcos Page 24
• Depending on the sorting algorithm, the exact number of comparisons or exact number of movements may not always be easy to determine
• Therefore, the number of comparisons and movements are approximated with big-O notations
• Some sorting algorithm may do more movement of data than comparison of data
• It is up to the programmer to decide which algorithm is more appropriate for specific set of data
• For example, if only small keys are compared such as integers or characters, then comparison are relatively fast and inexpensive
• But if complex and big objects should be compared, then comparison can be quite costly

Sahar Mosleh California State University San Marcos Page 25
• If on the other hand, the data items moved are large, and the movement is relatively done more, then movement stands out as determining factor rather than comparison
• Further, a simple method may only be 20% less efficient than a more elaborated algorithm
• If sorting is used in a program once in a while and only for small set of data, then using more complicated algorithm may not be desirable
• However, if size of data set is large, 20% can make significant difference and should not be ignored
• Lets look at different sorting algorithms now

Sahar Mosleh California State University San Marcos Page 26
Insertion Sort
• Start with first two element of the array, data[0], and data[1]
• If they are out of order then an interchange takes place
• Next data[2] is considered and placed into its proper position
• If data[2] is smaller than data[0], it is placed before data[0] by shifting down data[0] and data[1] by one position
• Otherwise, if data[2] is between data[0] and data[1], we just need to shift down data [1] and place data[2] in the second position
• Otherwise, data[2] remain as where it is in the array
• Next data[3] is considered and the same process repeats
• And so on

Sahar Mosleh California State University San Marcos Page 27
InsertionSort(data[], n)for (i=1, i<n, i++)
move all elements data[j] greater than data[i] by one position;
place data[i] in its proper position;
Algorithm and code for insertion sort
Sahar Mosleh California State University San Marcos Page 28
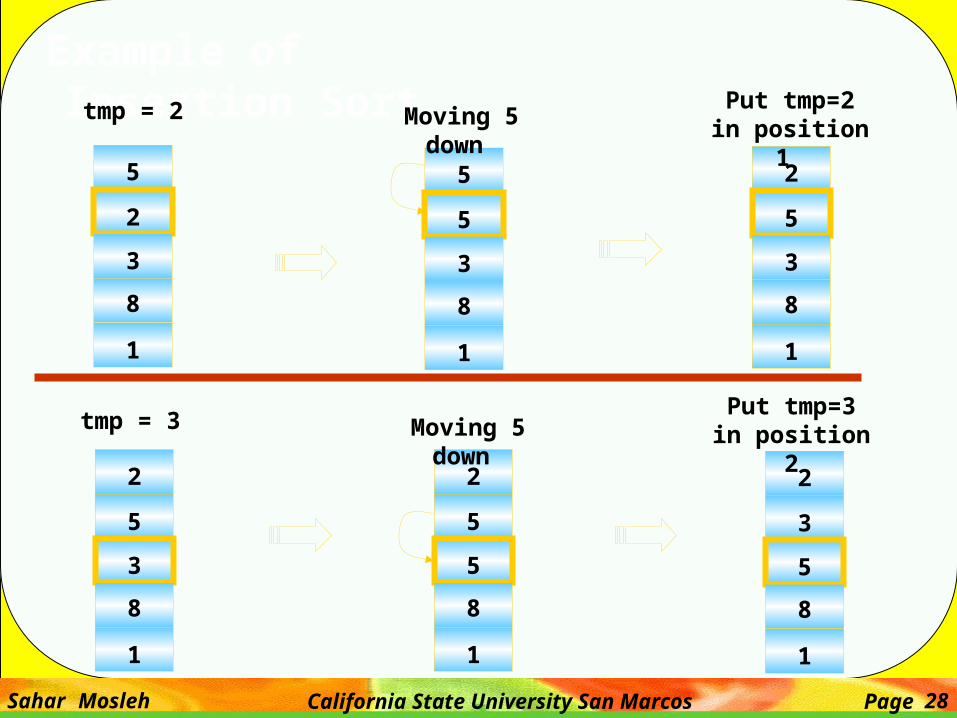
Example of Insertion Sort
5
2
3
8
1
tmp = 2
5
5
3
8
1
Moving 5 down
2
5
3
8
1
Put tmp=2 in position 1
2
5
3
8
1
2
5
5
8
1
2
3
5
8
1
Moving 5 down Put tmp=3 in
position 2tmp = 3
Sahar Mosleh California State University San Marcos Page 29
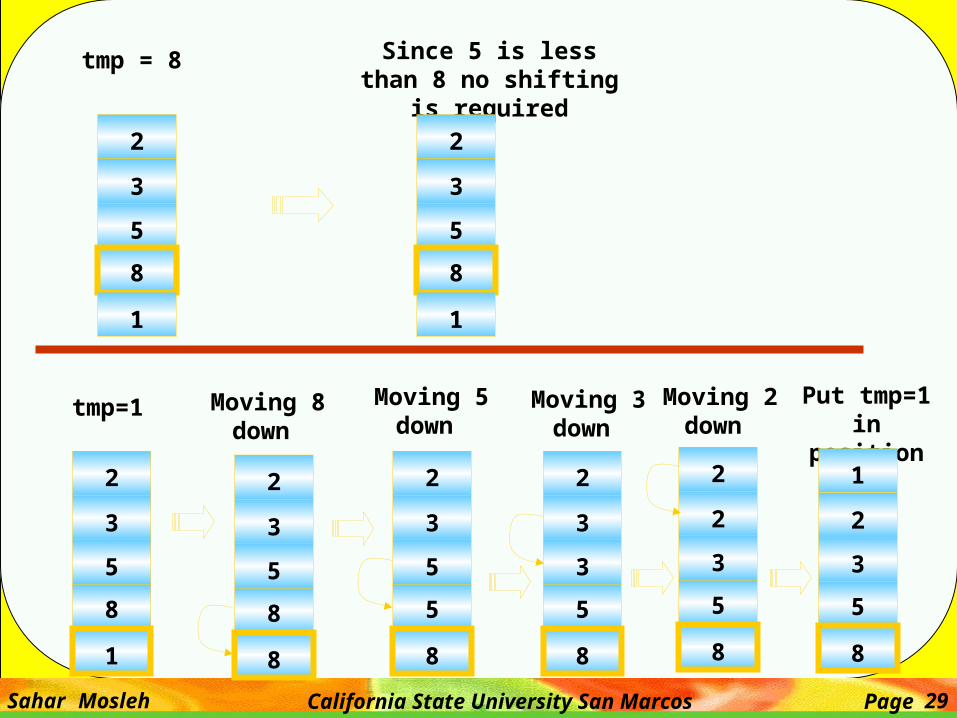
tmp = 8 Since 5 is less than 8 no shifting is required
tmp=1 Moving 8 down
Put tmp=1 in position 1
2
3
5
8
1
2
3
5
8
1
2
3
5
8
1
2
3
5
8
8
2
3
5
5
8
Moving 5 down
2
3
3
5
8
Moving 3 down
2
2
3
5
8
Moving 2 down
1
2
3
5
8
Sahar Mosleh California State University San Marcos Page 30
• Advantage of insertion sort:• If the data are already sorted, they remain sorted and
basically no movement is not necessary
• Disadvantage of insertion sort:• An item that is already in its right place may have to be
moved temporary in one iteration and be moved back into its original place
• Complexity of Insertion Sort:• Best case: This happens when the data are already sorted. It
takes O(n) to go through the elements
• Worst case: This happens when the data are in reverse order, then for the ith item (i-1) movement is necessary
Total movement = 1 + 2 + .. . +(n-1) = n(n-1)/2 which is O(n2)
• The average case is approximately half of the worst case which is still O(n2)

Sahar Mosleh California State University San Marcos Page 31
Selection Sort
• Select the minimum in the array and swap it with the first element
• Then select the second minimum in the array and swap it with the second element
• And so on until everything is sorted

Sahar Mosleh California State University San Marcos Page 32
SelectionSort(data[ ],n) for (i=0; i<n-1; i++)
Select the smallest element among data[i] … data[n-1]; Swap it with data[i]
Algorithm and code for selection sort

Sahar Mosleh California State University San Marcos Page 33
Example of Selection Sort
5
2
3
8
1
The first minimum is searched in the entire array which is 1Swap 1 with the first position
1
2
3
8
5
1
2
3
8
5
The second minimum is 2Swap it with the second position
1
2
3
8
5

Sahar Mosleh California State University San Marcos Page 34
The third minimum is 3Swap 1 with the third position
1
2
3
8
5
The fourth minimum is 5Swap it with the forth position
1
2
3
5
8
1
2
3
8
5
1
2
3
8
5

Sahar Mosleh California State University San Marcos Page 35
Complexity of Selection Sort
• The number of comparison and/or movements is the same in each case (best case, average case and worst case)
• The number of comparison is equal to
Total = (n-1) + (n-2) + (n-3) + …. + 1 = n(n-1)/2 which is O(n2)

Sahar Mosleh California State University San Marcos Page 36
Bubble Sort
• Start from the bottom and move the required elements up (i.e. bubble the elements up)
• Two adjacent elements are interchanged if they are found to be out of order with respect to each other
• First data[n-1] and data[n-2] are compared and swapped if they are not in order
• Then data[n-2] and data[n-3] are swapped if they are not in order
• And so on

Sahar Mosleh California State University San Marcos Page 37
BubbleSort(data[ ],n) for (i=0; i<n-1; i++)
for (j=n-1; j>i; --j) swap elements in position j and j-1 if they are out of order
Algorithm and code for bubble sort

Sahar Mosleh California State University San Marcos Page 38
Example of Bubble Sort
5
2
3
8
1
Iteration 1: Start from the last element up to the first element and bubble the smaller elements up
5
2
3
1
8swap
swap
5
2
1
3
8
swap
5
1
2
3
8
1
5
2
3
8
swap
1
5
2
3
8
1
5
2
3
8no swap
no swap
1
5
2
3
8
swap
1
2
5
3
8
Iteration 2: Start from the last element up to second element and bubble the smaller elements up

Sahar Mosleh California State University San Marcos Page 39
Example of Bubble Sort
Iteration 4: Start from the last element up to fourth element and bubble the smaller elements up
1
2
5
3
8
1
2
5
3
8no swap
swap
1
2
3
5
8
Iteration 3: Start from the last element up to third element and bubble the smaller elements up
1
2
3
5
8no swap

Sahar Mosleh California State University San Marcos Page 40
Complexity of Bubble Sort
• The number of comparison and/or movements is the same in each case (best case, average case and worst case)
• The number of comparison is equal to
Total = (n-1) + (n-2) + (n-3) + …. + 1 = n(n-1)/2 which is O(n2)

Sahar Mosleh California State University San Marcos Page 41
• Comparing the bubble sort with insertion and selection sorts we can say that:
• For the average case, bubble sort makes approximately twice as many comparisons and the same number of moves as insertion sort
• Bubble sort also, on average, makes as many comparison as selection sort and n times more moves than selection sort
• Between theses three types of sorts “Selection Sort” is generally better algorithm because if array is already sorted running time only takes O(n) which is relatively faster than other algorithms

Sahar Mosleh California State University San Marcos Page 42
Quick Sort
• This is known to be the best sorting method.
• In this scheme:• One of the elements in the array is chosen as pivot• Then the array is divided into sub-arrays• The elements smaller than the pivot goes into one sub-array• The elements bigger than the pivot goes into another sub-
array• The pivot goes in the middle of these two sub-arrays• Then each sub-array is partitioned the same way as the
original array and process repeats recursively

Sahar Mosleh California State University San Marcos Page 43
Algorithm of quick sortQuickSort(array[ ])
if length (array) > 1 choose a pivot; // partition array into array1 and array2 while there are elements left in array include elements either in array1 // if element <= pivot or in array2 // if element >= pivot QuickSort(array1); QuickSort(array2);
Complexity of quick sort
• The best case is when the arrays are always partitioned equally
• For the best case, the running time is O(nlogn)
• The running time for the average case is also O(nlogn)
• The worst case happens if pivot is always either the smallest element in the array or largest number in the array.
• In the worst case, the running time moves toward O(n2)

Sahar Mosleh California State University San Marcos Page 44
Example of Quick Sort
• By example
• Select pivot
• Partition
8131 75
13
43
57
92
65260
65
0 1326 43
3157
6592
8175

Sahar Mosleh California State University San Marcos Page 45
• Recursively apply quicksort to both partitions
• Result will ultimately be a sorted array
0 13 26 31 43 57 65 75 81 92
0 1326 43
31 57
9281
7565

Sahar Mosleh California State University San Marcos Page 46
Radix Sort
• Radix refers to the base of the number. For example radix for decimal numbers is 10 or for hex numbers is 16 or for English alphabets is 26.
• Radix sort has been called the bin sort in the past
• The name bin sort comes from mechanical devices that were used to sort keypunched cards
• Cards would be directed into bins and returned to the deck in a new order and then redirected into bins again
• For integer data, the repeated passes of a radix sort focus on the ones place value, then on the tens place value, then on the thousands place value, etc
• For character based data, focus would be placed on the right-most character, then the second most right-character, etc

Sahar Mosleh California State University San Marcos Page 47
Algorithm and Code for Radix Sort
Assuming the numbers to be sorted are all decimal integers
RadixSort(array[ ]) for (d = 1; d <= the position of the leftmost digit of longest number; i+=) distribute all numbers among piles 0 through 9 according to he dth digit Put all integers on one list

Sahar Mosleh California State University San Marcos Page 48
Example of Radix Sort
• Assume the data are:459 254 472 534 649 239 432 654 477
• Radix sort will arrange the values into 10 bins based upon the ones place value
012 472 43234 254 534 654567 47789 459 649 239

Sahar Mosleh California State University San Marcos Page 49
• The sublists are collected and made into one large bin (in order given)
472 432 254 534 654 477 459 649 239• Then Radix sort will arrange the values into 10 bins based
upon the tens place value
0123 432 534 2394 6495 254 654 45967 472 47789

Sahar Mosleh California State University San Marcos Page 50
• The sublists are collected and made into one large bin (in order given)
432 534 239 649 254 654 459 472 477
• Radix sort will arrange the values into 10 bins based upon the hundreds place value (done!)
012 239 25434 432 459 472
4775 5346 649 654789
• The sublists are collected and the numbers are sorted
239 254 432 459 472 477 534 649 654
Sahar Mosleh California State University San Marcos Page 51
Another Example of Radix Sort
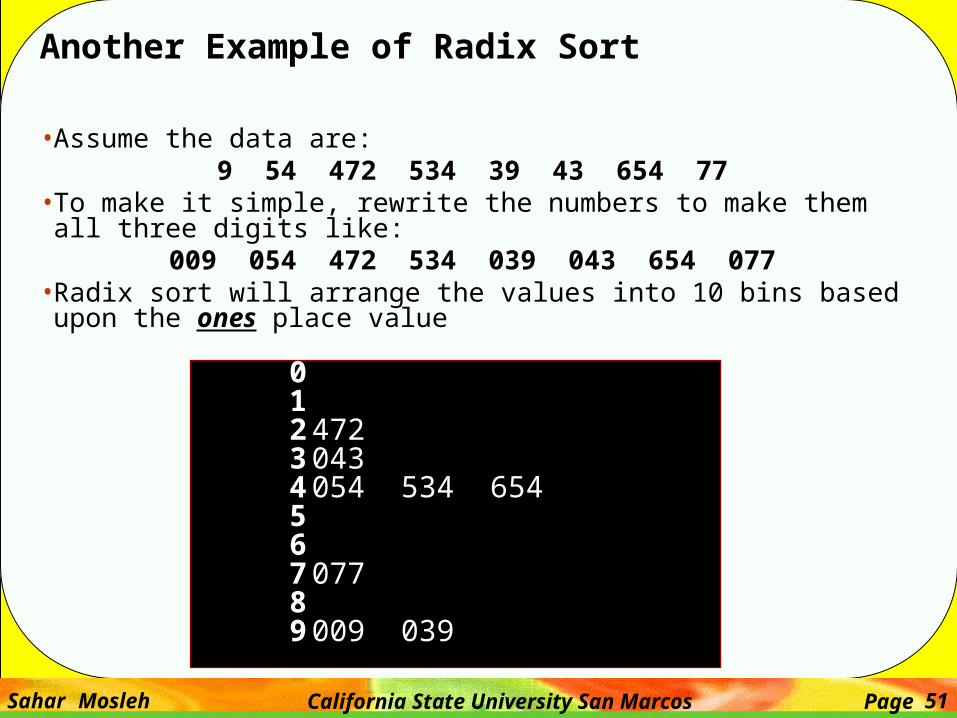
• Assume the data are:9 54 472 534 39 43 654 77
• To make it simple, rewrite the numbers to make them all three digits like:009 054 472 534 039 043 654 077
• Radix sort will arrange the values into 10 bins based upon the ones place value
012 472 3 0434 054 534 654567 07789 009 039

Sahar Mosleh California State University San Marcos Page 52
• The sublists are collected and made into one large bin (in order given)
472 043 054 534 654 077 009 039• Then Radix sort will arrange the values into 10 bins based
upon the tens place value
0 009123 534 0394 0435 054 65467 472 07789

Sahar Mosleh California State University San Marcos Page 53
• The sublists are collected and made into one large bin (in order given)
009 534 039 043 054 654 472 077
• Radix sort will arrange the values into 10 bins based upon the hundreds place value (done!)
• The sublists are collected and the numbers are sorted
009 039 043 054 077 472 534 654
0 009 039 043 054 077
1234 472 5 5346 654789

Sahar Mosleh California State University San Marcos Page 54
• Assume the data are:area book close team new place prince
• To sort the above elements using the radix sort you need to have 26 buckets, one for each character.
• You also need one more character to represent space which has the lowest priority. Suppose that letter is underscore “?” represents space
• You can rewrite the data as follows:area? Book? Close Team? New?? Place Print
• Now all letters have 5 characters and it is easy to compare them with each other
• To do the sorting, you can start from the right most character, place the data into appropriate buckets and collect them. Then place them into bucket based on the second right most character and collect them again and so on.

Sahar Mosleh California State University San Marcos Page 55
Complexity of Radix Sort
• The complexity is O(n)
• However, keysize (for example, the maximum number of digits) is a factor, but will still be a linear relationship because for example for at most 3 digits 3n is still O(n) which is linear
• Although theoretically O(n) is an impressive running time for sort, it does not include the queue implementation
• Further, if radix r (the base) is a large number and a large amount of data has to be sorted, then radix sort algorithm requires r queues of at most size n and the number r*n is O(rn) which can be substantially large depending of the size of r.