ambiguous frequent itemset mining and polynomial delay enumeration
DESCRIPTION
Ambiguous Frequent Itemset Mining and Polynomial Delay Enumeration. Takeaki Uno (1) , Hiroki Arimura (2) (1) National Institute of Informatics, JAPAN (The Guraduate University for Advanced Science) (2) Hokkaido University, JAPAN. May/25/2008 PAKDD 2008. Frequent Pattern Mining. - PowerPoint PPT PresentationTRANSCRIPT

Ambiguous Frequent Itemset MiningAmbiguous Frequent Itemset Mining
and Polynomial Delay Enumeration and Polynomial Delay EnumerationAmbiguous Frequent Itemset MiningAmbiguous Frequent Itemset Mining
and Polynomial Delay Enumeration and Polynomial Delay Enumeration
May/25/2008 PAKDD 2008
Takeaki UnoTakeaki Uno(1)(1), Hiroki Arimura, Hiroki Arimura(2)(2)
(1) National Institute of Informatics, JAPAN(The Guraduate University for Advanced Science)
(2) Hokkaido University, JAPAN

Frequent Pattern MiningFrequent Pattern MiningFrequent Pattern MiningFrequent Pattern Mining
•• Problem of finding all frequently appearing patterns from given database
database: transaction database (itemset), tree, graph, vectorpatterns: itemset, tree, path/cycle, graph, geometric graph…
genomeexperiments
databaseExtract frequentlyExtract frequentlyappearing patternsappearing patterns
ATGCGCCGTATAGCGGGTGGTTCGCGTTAGGGATATAAATGCGCCAAATAATAATGTATTATTGAAGGGCGACAGTCTCTCAATAAGCGGCT
ATGCGCCGTATAGCGGGTGGTTCGCGTTAGGGATATAAATGCGCCAAATAATAATGTATTATTGAAGGGCGACAGTCTCTCAATAAGCGGCT
実験1
実験2
実験3
実験4
● ▲ ▲ ● ▲
● ● ▲ ● ● ● ▲ ● ▲ ● ●
● ▲ ● ● ▲ ▲ ▲ ▲
・・ 実験 1● , 実験 3 ▲・・ 実験 2● , 実験 4●・・ 実験 2●, 実験 3 ▲, 実験4●・・ 実験 2▲ , 実験 3 ▲ . . .
・・ 実験 1● , 実験 3 ▲・・ 実験 2● , 実験 4●・・ 実験 2●, 実験 3 ▲, 実験4●・・ 実験 2▲ , 実験 3 ▲ . . . ・・ ATGCAT
・・ CCCGGGTAA・・ GGCGTTA・・ ATAAGGG . . .
・・ ATGCAT・・ CCCGGGTAA・・ GGCGTTA・・ ATAAGGG . . .

Researches on Pattern MiningResearches on Pattern MiningResearches on Pattern MiningResearches on Pattern Mining
•• So many studies and applications on itemsets, sequences, trees, graphs, geometric graphs
•• Thanks to the efficient algorithms, we would say any simple structures can be enumerated in practically short time
•• One of the next problems is “how to handle the noise, error, and ambiguity”
usual “inclusion” is too strict
we want to find patterns “mostly” included in many records
We consider ambiguous appearance of patternsWe consider ambiguous appearance of patterns

Related Works on AmbiguityRelated Works on AmbiguityRelated Works on AmbiguityRelated Works on Ambiguity
•• It is popular to detect “ambiguous XXXX”
dense substructures: clustering, community discovering…
homology search on genome sequence
•• Heuristic search is popular because of the difficulty on modeling and computation
AdvantageAdvantage: usually works efficiently
ProblemProblem: not easy to understand “what is found”
much more cost for additional conditions(for each solution)
•• Here we look at the problem from “algorithmic point of view”
(efficient models arising from efficient computation)

Itemset MiningItemset MiningItemset MiningItemset Mining
•• In this talk, we focus on the itemset mining
transaction database transaction database DD:: each record called transaction is a subset of itemset E, that is, ∀∀T ∈DD, T ⊆ E
Occ(P): set of transactions including P
frq(P) = |Occ(P)|: #transactions including P
P is a frequent itemset frq(P) ≥σ (σ is minimum support)
•• Problem is to enumerate all frequent itemsets in DD
We introduce ambiguous inclusion for frequent itemset miningWe introduce ambiguous inclusion for frequent itemset mining

Related worksRelated worksRelated worksRelated works
•• fault-tolerant pattern 、 degenerate pattern 、 soft occurrence, etc.mainly two approaches
(1)(1) generalize inclusion:
(1-a) (1-a) the ratio of included items ≥θ include lose monotonicity; no subset may be frequent in the worst case several heuristic-search-based algorithms
(1-b) (1-b) at most k items are not included include satisfy monotonicity; so many small itemsets are frequent maximal enumeration or complete enumeration with small k
1,22,31,3
θ=66%

Related works 2Related works 2Related works 2Related works 2
(2)(2) find pairs of itemset and transaction set such that few of them do not satisfy inclusion
equivalent to finding dense submatrix, or dense bicluster
so many equivalent patterns will be found
mainly, heuristic search for
finding one such dense substructure
•• ambiguity on the transaction set
an itemset can have many partners
We introduce a new model for (2)(2) to avoid redundancy, and propose an efficient depth-first search type algorithm We introduce a new model for (2)(2) to avoid redundancy,
and propose an efficient depth-first search type algorithm
items
transactions

Average InclusionAverage InclusionAverage InclusionAverage Inclusion
•• inclusion ratio of t for P ⇔ ⇔ | t∩P | / |P|
•• average inclusion ratio of transaction set T for P
⇔ ⇔ average of inclusion ratio over all transactions in T
∑ |t ∩ P| / ( |P| × |T| )
equivalent to dense submatrix/subgraph of transaction-item inclusion matrix/graph
•• For a density threshold θ, maximum co-occurrence size cov(P) of itemset P ⇔⇔ maximum size of transaction set s.t. average inclusion ratio ≥θ
1,3,42,4,51,2
1,3,42,4,51,2
2,350%4,550%1,266%
2,350%4,550%1,266%

Problem DefinitionProblem DefinitionProblem DefinitionProblem Definition
•• For a density threshold θ, the maximum co-occurrence size cov(P) of itemset P ⇔ ⇔ maximum size of transaction set s.t. average inclusion ratio ≥θ •• Ambiguous frequent itemset: itemset P s.t., cov(P) ≥ σ (σ: minimum support)
•• Ambiguous frequent itemsets are not monotone !!
1,3,42,4,51,2
1,3,42,4,51,2
θ=66%:cov({3}) = 1cov({2}) = 3cov({1,3}) = 2cov({1,2}) = 3
θ=66%:cov({3}) = 1cov({2}) = 3cov({1,3}) = 2cov({1,2}) = 3
Ambiguous frequent itemset enumeration: the problem of outputting all ambiguous frequent itemsets for given database D, density threshold θ, minimum support σ
Ambiguous frequent itemset enumeration: the problem of outputting all ambiguous frequent itemsets for given database D, density threshold θ, minimum support σ
The goal is to develop an efficient algorithm for this problemThe goal is to develop an efficient algorithm for this problem

Hardness for Branch-and-BoundHardness for Branch-and-BoundHardness for Branch-and-BoundHardness for Branch-and-Bound
•• A straightforward approach to this problem is branch-and-bound
•• In each iteration, divide the problem into two non-empty problems by the inclusion of an item
ii1, 1, ii22 ii1, 1, ii22 ii1, 1, ii22 ii1, 1, ii22
ii11 vv1 1
Checking the existence of ambiguous frequent itemset is NP-comp. (Theorem 1)
Checking the existence of ambiguous frequent itemset is NP-comp. (Theorem 1)

Is This Really Hard?Is This Really Hard?Is This Really Hard?Is This Really Hard?
•• We proved NP-hardness for "very dense graphs"
unclear for middle dense graph
not impossible for polynomial time enumeration
θ= 1
θ= 0
easyeasy
easyeasy
hardhard
????????????????????
polynomial time in (input size) + (output size)polynomial time in (input size) + (output size)
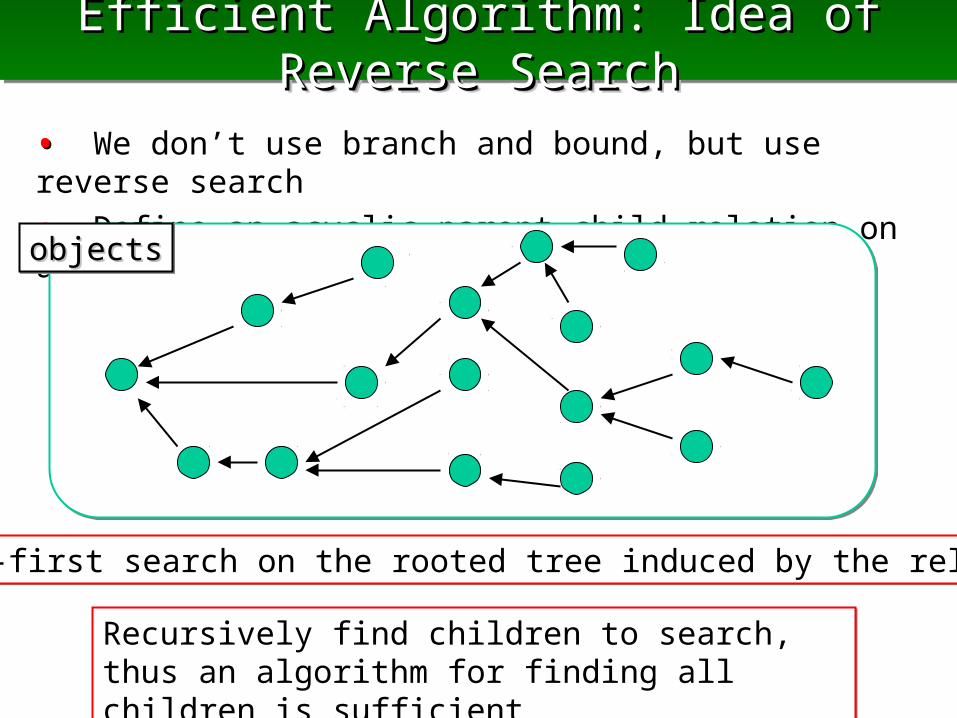
Efficient Algorithm: Idea of Reverse Efficient Algorithm: Idea of Reverse SearchSearch
Efficient Algorithm: Idea of Reverse Efficient Algorithm: Idea of Reverse SearchSearch
•• We don’t use branch and bound, but use reverse search
•• Define an acyclic parent-child relation on all objects to be found
Recursively find children to search, thus an algorithm for finding all children is sufficientRecursively find children to search, thus an algorithm for finding all children is sufficient
objectsobjectsobjectsobjects
Depth-first search on the rooted tree induced by the relationDepth-first search on the rooted tree induced by the relation

Neighboring RelationNeighboring RelationNeighboring RelationNeighboring Relation•• AmbiOcc(P) of an ambiguous frequent itemset P
⇔ ⇔ lexicographically minimum one among transaction sets whose average inclusion ratio ≥θ and size = cov(P)
•• e*(P):e*(P): the item e e in P s.t. # transactions in AmbiOcc(P) including e e is the minimum (ties are broken by taking the minimum index)
•• the parent Prt(P) of P: P \ e*(P)e*(P)
A: 1,3,4,7B: 2,4,5C: 1,2,7D: 1,4,5,7E: 2,3,6F: 3,4,6
A: 1,3,4,7B: 2,4,5C: 1,2,7D: 1,4,5,7E: 2,3,6F: 3,4,6
{1,4,5} D, A,B, C,F, E
AmbiOcc({1,4,5}) = {D,A,B,C}
{1,4,5} D, A,B, C,F, E
AmbiOcc({1,4,5}) = {D,A,B,C}
θ = 66%, σ= 4
e*(P) = 5Prt({1,4,5}) {1,4}
AmbiOcc({1,4}) = {D,A, B,C, F}
e*(P) = 5Prt({1,4,5}) {1,4}
AmbiOcc({1,4}) = {D,A, B,C, F}

Properties of ParentProperties of ParentProperties of ParentProperties of Parent
•• The parent Prt(P) of P: P \ e*(P)e*(P)
uniquely defined
•• Average inclusion ratio of AmbiOcc(P) for P does not decrease
Prt(P) is an ambiguous frequent itemset
•• |Prt(P)| < |P| (parent is always smaller)
the relation is acyclic, and induces a tree (rooted at φ)
A: 1,3,4,7B: 2,4,5C: 1,2,7D: 1,4,5,7E: 2,3,6F: 3,4,6
A: 1,3,4,7B: 2,4,5C: 1,2,7D: 1,4,5,7E: 2,3,6F: 3,4,6
{1,4,5} D, A,B, C,F, E
AmbiOcc({1,4,5}) = {D,A,B,C}
{1,4,5} D, A,B, C,F, E
AmbiOcc({1,4,5}) = {D,A,B,C}
θ = 66%, σ= 4
e*(P) = 5Prt({1,4,5}) {1,4}
AmbiOcc({1,4}) = {D,A, B,C, F}
e*(P) = 5Prt({1,4,5}) {1,4}
AmbiOcc({1,4}) = {D,A, B,C, F}

Enumeration TreeEnumeration TreeEnumeration TreeEnumeration Tree
•• The relation is acyclic, and induces a tree (rooted at φ)
•• We call the tree enumeration tree
A: 1,3,4,7B: 2,4,5,C: 1,2,7D: 1,4,5,7E: 2,3,6F: 3,4,6
A: 1,3,4,7B: 2,4,5,C: 1,2,7D: 1,4,5,7E: 2,3,6F: 3,4,6
θ = 66%, σ= 4
1,71,73,43,4 4,54,51,41,4 4,74,7
1,4,71,4,71,4,51,4,5 1,3,41,3,4 3,4,73,4,7 4,5,74,5,7 1,2,71,2,7 1,3,71,3,7 1,5,71,5,7
φφ
11 22 33 44 77
1,3,4,71,3,4,7 1,4,5,71,4,5,7

Listing ChildrenListing ChildrenListing ChildrenListing Children
•• To perform a depth-first search on enumeration tree, what we have to do is “finding all children of given itemset”
•• P = Prt(P’) is obtained by removing an item from P’
a child P’ of P is obtained by adding an item to P
to find all children, we examine all possible items
itemsetsitemsetsitemsetsitemsets
φ

Check CandidatesCheck CandidatesCheck CandidatesCheck Candidates
•• An item addition does not always yield a child
They are just “candidates”
•• If the parent of a candidate P’ = P∪e is P (satisfies e*(P’) = e ),
P’ is a child of P
checking by computing e*(P∪e), for each candidate P∪e
itemsetsitemsetsitemsetsitemsetsEnumeration is done in O(||
D||n) time for each ambifuous frequent itemset
Enumeration is done in O(||D||n) time for each
ambifuous frequent itemset
TheoremTheorem
φ

Algorithm DescriptionAlgorithm DescriptionAlgorithm DescriptionAlgorithm Description
Algorithm AFIM ( P:pattern, D:database )
output P
compute cov(P∪e) for all item e not in P
for each e s.t. cov(P∪e) ≥ σ do
compute AmbiOcc(P∪e)
compute e*(P∪e)
if e*(P∪e) = e then call AFIM ( P∪e, D )
done

Efficient Computation of cov’sEfficient Computation of cov’sEfficient Computation of cov’sEfficient Computation of cov’s
•• For efficient computation, we classify transactions by inclusion ratio
•• When we compute cov(P∪e), we compute the intersection of each group and Occ(e)
inclusion ratio increases, for transactions included in Occ(e)
by moving such transactions, classification for P∪e is obtained
•• This task for all items is done efficiently by Delivery, which takes O(||G||) time where ||G|| is the sum of transaction sizes in group G computation of cov(P∪e) can be done in linear time
0 miss0 miss 1 miss1 miss 2 miss2 miss 3 miss3 miss 4 miss4 miss 5 miss5 miss

Computing AmbiOcc and e*Computing AmbiOcc and e*Computing AmbiOcc and e*Computing AmbiOcc and e*
•• Computation of AmbiOcc(P∪e) needs greedy choice of transactions, in the decreasing order of (inclusion ratio & index)
•• Computation of e*(P∪e) needs intersection of AmbiOcc(P∪e) and Occ(i) for each i∈P Delivery
need O(||D||) time in the worst case
•• However, when cov(P) is small, not so many transactions may be scanned, thus we expect the average computation time is not so long

Bottom-widenessBottom-widenessBottom-widenessBottom-wideness
•• DFS search generates several recursive calls in each iteration
Recursion tree grows exponentially, by going down
Computation time is dominated by the lowest levels
•• Computation time decreases by going down
Near by bottom levels, computation time may be close to σ, thus an iteration may take O(σt) time
where t is the average size of transactions
Near by bottom levels, computation time may be close to σ, thus an iteration may take O(σt) time
where t is the average size of transactions
・・・・・・
long timelong time
short timeshort time

Computational ExperimentsComputational ExperimentsComputational ExperimentsComputational Experiments
CPU: Pentium M 1.1GHz,memory: 256MBOS: Windows XP + CygwinCode: CCompiler: gcc 2.3
•• Test instances are taken from benchmark datasets for frequent itemset mining

BMS-WebView 2BMS-WebView 2BMS-WebView 2BMS-WebView 2
•• A real-world web access data (sparse; transaction siz = 4.5)
BMS-WebView2
0.1
1
10
100
1000
10000
100000
1000000
10000000
1% 0.50% 0.30% 0.15% 0.05% supporttime(
sec)
/num
ber
LCM time1.0 number1.0 time1.0 time/ M0.9 number0.9 time0.9 time/ M0.8 number0.8 time0.8 time/ M

MushroomMushroomMushroomMushroom
•• A real-world machine learning data of mushrooms (density = 1/3)
Mushroom
0.01
0.1
1
10
100
1000
10000
100000
1000000
10000000
80% 70% 60% 50% 40% 30% 20% supporttime(
sec)
/num
ber
LCM time1.0 number1.0 time1.0 time/ M0.9 number0.9 time0.9 time/ M0.8 number0.8 time0.8 time/ M

Possibility for Further ImprovementsPossibility for Further ImprovementsPossibility for Further ImprovementsPossibility for Further Improvements
•• Ratio of unnecessary operations, non-maximal patterns
Mushroom
1
10
100
80% 70% 60% 50% 40% 30% support
ratio
0.9 max0.9 prt0.9 occ0.8 max0.8 prt0.8 occ

ConclusionConclusionConclusionConclusion
•• Introduced a new model for frequent itemset mining with ambiguous inclusion relation, which avoids redundancy
•• Showed a hardness result for branch-and-bound
•• Showed efficiency on practical (sparse) datasets
Future Works:
•• Reduce the time complexity and fill the gap from the practice
•• Efficient models and computation for maximal ones
•• Application of the technique to the other problems
(ambiguous pattern mining for graph, tree, vector data, etc.)