aneuralembeddingcompressor forscalabledocumentsearchhamann/t/18.11.kolloq.pdfcontents 29.10.2018...
TRANSCRIPT

ANeural Embedding Compressorfor Scalable Document Search
29.10.2018Felix Hamann

Contents
29.10.2018 Felix Hamann 2/33
1. Information Retrieval and Document SimilarityWhat we are trying to accomplish
2. The Embedding CompressorTraining and evaluating the neural auto-encoder model
3. The Relaxed Hamming Word Movers Distance (RHWMD)Determining document similarity with binary hash codes
4. The Ungol IndexAn RHWMD implementation for information retrieval

29.10.2018 Felix Hamann 3/33
IR and Document Similarity
Information Retrieval
29.10.2018 Felix Hamann 4/33
Here: Searching for text documents given a text queryGood IR systems:
Sort results by relevance effectivelyHandle large amounts of dataAre fast
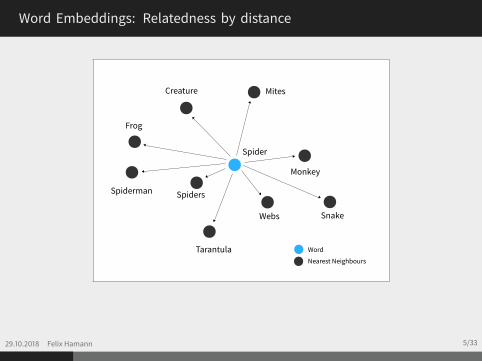
Word Embeddings: Relatedness by distance
29.10.2018 Felix Hamann 5/33
Spider
Spiders
Monkey
Webs
Tarantula
Spiderman
Snake
MitesCreature
Frog
Word
Nearest Neighbours
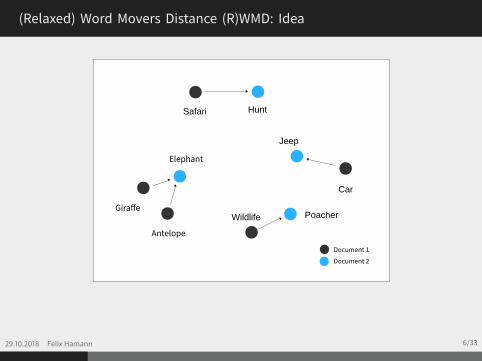
(Relaxed) Word Movers Distance (R)WMD: Idea
29.10.2018 Felix Hamann 6/33
Giraffe
Antelope
Car
Safari
Elephant
Wildlife
Jeep
Poacher
Hunt
Document 1
Document 2
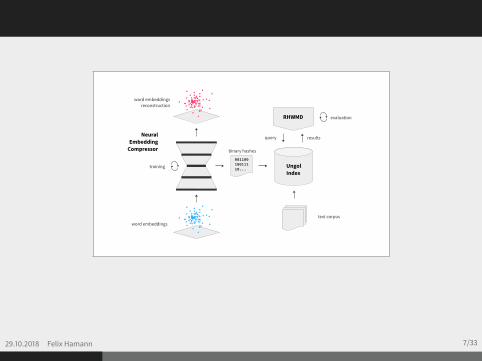
29.10.2018 Felix Hamann 7/33
NeuralEmbeddingCompressor
training
word embeddings
word embeddingsreconstruction
00110010011110...
binary hashes
text corpus
UngolIndex
evaluationRHWMD
resultsquery

29.10.2018 Felix Hamann 8/33
The Embedding Compressor

Compressor: Starting Point and Requirements
29.10.2018 Felix Hamann 9/33
What we have:
Real-valued word embeddings in Euclidean spaceSpatial word similarity structure
What we do with it:
Training a neural auto-encoder model to reconstructword embeddingsUse the encoder to create binary hash codesExamine whether the spatial properties are transferredinto Hamming space

The Neural Embedding Compressor
29.10.2018 Felix Hamann 10/33
Training objective: reducereconstruction loss
L(et, e′t) :=1
2||et − e′t||
2
2
(ψθ ◦ ϕθ)(et) := e′t
θ := {A,b, A′,b′, C}
b’
b
A’
A
e
E
MK / 2
MK
K
f 1
f 2
σ σ σ σ σ σ g-softmax
e’
E
+
C
Φ
Ψ
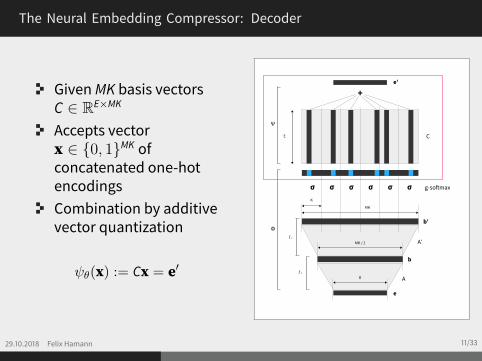
The Neural Embedding Compressor: Decoder
29.10.2018 Felix Hamann 11/33
GivenMK basis vectorsC ∈ RE×MK
Accepts vectorx ∈ {0, 1}MK ofconcatenated one-hotencodingsCombination by additivevector quantization
ψθ(x) := Cx = e′
b’
b
A’
A
e
E
MK / 2
MK
K
f 1
f 2
σ σ σ σ σ σ g-softmax
e’
E
+
C
Φ
Ψ

The Neural Embedding Compressor: One-Hot Encoding
29.10.2018 Felix Hamann 12/33
Encoder output areone-hot encodingsHere:M = 6,K = 5
Code: (1, 3, 2, 4, 1, 3)
X =
0 1 2 3 4
0 0 1 0 0 01 0 0 0 1 02 0 0 1 0 03 0 0 0 0 14 0 1 0 0 05 0 0 0 1 0
b’
b
A’
A
e
E
MK / 2
MK
K
f 1
f 2
σ σ σ σ σ σ g-softmax
e’
E
+
C
Φ
Ψ
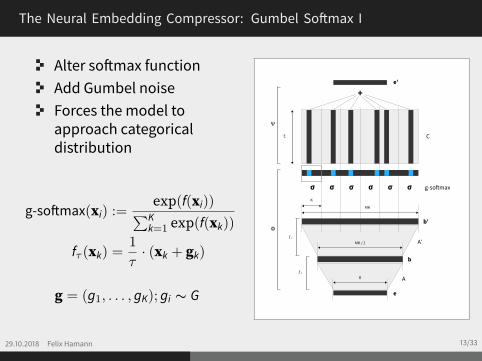
The Neural Embedding Compressor: Gumbel Softmax I
29.10.2018 Felix Hamann 13/33
Alter softmax functionAdd Gumbel noiseForces the model toapproach categoricaldistribution
g-softmax(xi) :=exp(f(xi))∑Kk=1 exp(f(xk))
fτ (xk) =1
τ· (xk + gk)
g = (g1, . . . , gK); gi ∼ G
b’
b
A’
A
e
E
MK / 2
MK
K
f 1
f 2
σ σ σ σ σ σ g-softmax
e’
E
+
C
Φ
Ψ
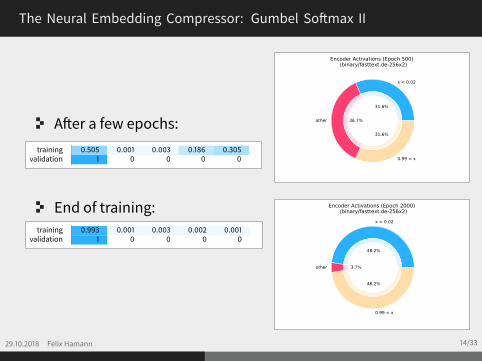
The Neural Embedding Compressor: Gumbel Softmax II
29.10.2018 Felix Hamann 14/33
After a few epochs:training 0.505 0.001 0.003 0.186 0.305
validation 1 0 0 0 0
End of training:training 0.993 0.001 0.003 0.002 0.001
validation 1 0 0 0 0

The Neural Embedding Compressor: Training Results (Binary)
29.10.2018 Felix Hamann 15/33
Training excerpt for K = 2
Good loss and entropy forM = 256
GloVe fasttext.deM |Θ| Loss Entropy Loss Entropy
32 19200 16.82 0.972 8.037 0.96064 38400 14.99 0.981 6.809 0.932128 76800 11.72 0.985 5.319 0.909256 153600 6.986 0.961 3.682 0.873512 307200 6.921 0.970 3.762 0.849
entropy(x) := 1
log2K
K∑i=1
{0 if p(xi) = 0
−p(xi) · log2 p(xi) else
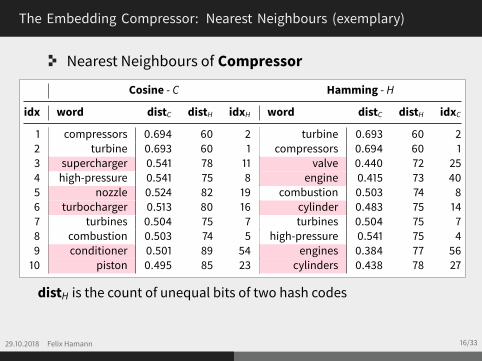
The Embedding Compressor: Nearest Neighbours (exemplary)
29.10.2018 Felix Hamann 16/33
Nearest Neighbours of Compressor
Cosine - C Hamming - H
idx word distC distH idxH word distC distH idxC
1 compressors 0.694 60 2 turbine 0.693 60 22 turbine 0.693 60 1 compressors 0.694 60 13 supercharger 0.541 78 11 valve 0.440 72 254 high-pressure 0.541 75 8 engine 0.415 73 405 nozzle 0.524 82 19 combustion 0.503 74 86 turbocharger 0.513 80 16 cylinder 0.483 75 147 turbines 0.504 75 7 turbines 0.504 75 78 combustion 0.503 74 5 high-pressure 0.541 75 49 conditioner 0.501 89 54 engines 0.384 77 5610 piston 0.495 85 23 cylinders 0.438 78 27
distH is the count of unequal bits of two hash codes
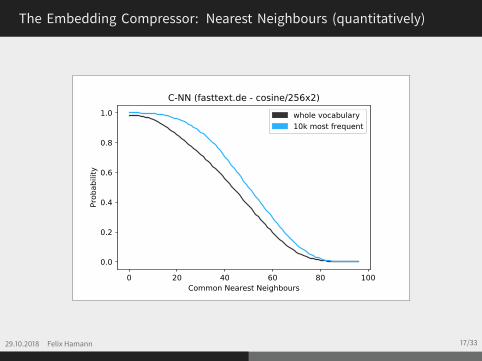
The Embedding Compressor: Nearest Neighbours (quantitatively)
29.10.2018 Felix Hamann 17/33

29.10.2018 Felix Hamann 18/33
The Relaxed HammingWMD

RHWMD: Starting Point and Requirements
29.10.2018 Felix Hamann 19/33
What we have:
Binary hash codes of wordsHamming distance as similarity measure
What we do with it:
Measure similarity between documentsFollowing the RWMD: Select nearest neighbour pairsQuantify similarity of documents by using the distance ofall nearest neighbour pairs

RHWMD Definition
29.10.2018 Felix Hamann 20/33
Calculate a score s for a document pair:
s(d, d′) :=∑t∈d
n-idf(t) ·(1− η(ht, ht′)
)(1)
n-idf(t) :=idf(t)∑
t′∈d idf(t′)and η(ht, ht′) :=
1
M
∣∣∣∣{i | hti ̸= ht′i
}∣∣∣∣ (2)
t′ ∈ d′ is the nearest neighbour token of t ∈ dhti is the i-th bit of hash code ht withM bitsHeuristic normalisation with n-idfThis score is not symmetric:
rrhwmd(d, d′) := s(d, d′) + s(d′, d)
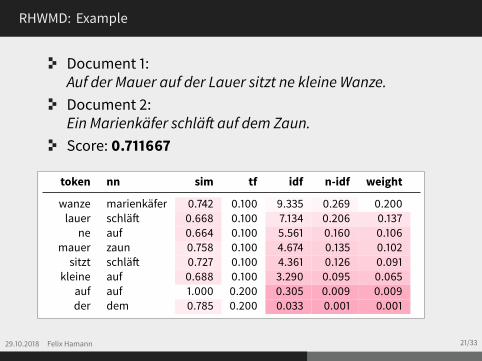
RHWMD: Example
29.10.2018 Felix Hamann 21/33
Document 1:Auf der Mauer auf der Lauer sitzt ne kleine Wanze.Document 2:Ein Marienkäfer schläft auf dem Zaun.Score: 0.711667
token nn sim tf idf n-idf weight
wanze marienkäfer 0.742 0.100 9.335 0.269 0.200lauer schläft 0.668 0.100 7.134 0.206 0.137
ne auf 0.664 0.100 5.561 0.160 0.106mauer zaun 0.758 0.100 4.674 0.135 0.102sitzt schläft 0.727 0.100 4.361 0.126 0.091
kleine auf 0.688 0.100 3.290 0.095 0.065auf auf 1.000 0.200 0.305 0.009 0.009der dem 0.785 0.200 0.033 0.001 0.001

29.10.2018 Felix Hamann 22/33
The Ungol Index

RHWMD: Starting Point and Requirements
29.10.2018 Felix Hamann 23/33
What we have:
Binary codes for wordsRHWMD for measuring similarity between documents
What we do with it:
Evaluation of the RHWMD for Information Retrieval (IR)Calculate the RHWMD for query/candidate-documentsMeasure the execution speed of the implementationCompare the ranking quality to TF-IDF, BM25 and WMD
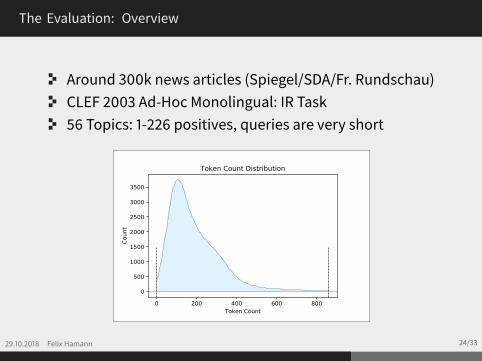
The Evaluation: Overview
29.10.2018 Felix Hamann 24/33
Around 300k news articles (Spiegel/SDA/Fr. Rundschau)CLEF 2003 Ad-Hoc Monolingual: IR Task56 Topics: 1-226 positives, queries are very short

The Evaluation: Example and Preprocessing
29.10.2018 Felix Hamann 25/33
An example query:Finde Berichte über den Kruzifixstreit in bayerischen Schulen.
München, 22. Sept. (sda/Reuter) Erstmals seit dem Kruzifix-Urteil des deutschenBundesverfassungsgerichts sind in zwei bayerischen Schulen Kreuze abgehängtworden. Dies erklärte am Freitag in München der Sprecher des bayerischenKultusministeriums. (...)
Preprocessing includes:tokenizinglower casingcompound splittingsanitizing
180921_ungol.db.pickle
Documents 294659Vocabulary 400000Code Size 256
Unique Tokens 258391Avg. Doc. Length 197
Skipped 8
Memory Footprint ∼ 3 GB

The Algorithm I
29.10.2018 Felix Hamann 26/33
How to calculate the RHMWD fast with Python?Problem: |d| · |d′|many token combinations
Approach:
Create lookup table with each xi = number of ones for i2
Ξ := (x0, . . . x255) = (0, 1, 1, 2, 1, . . . )

The Algorithm II
29.10.2018 Felix Hamann 27/33
Given two documents (d, d′):Construct twomatrices H,H′ ∈ {0, . . . , 255}|d|×|d′|×B
H :=
h1 . . . h1...
. . ....
h|d| . . . h|d|
H′ :=
h′1 . . . h′|d′|...
. . ....
h′1 . . . h′|d′|
Use numpy’s vectorized XOR implementation Z := H⊕v H′
Select from lookup table and collapse last dimension:
Tij =1
M
B∑k=1
ΞZijk
Create two vectors with nearest neighbours along each axis:
vd := (v1, . . . , v|d|) with vi := minj
Tij
vd′ := (v′1, . . . , v′|d′|) with v′i := min
iTij
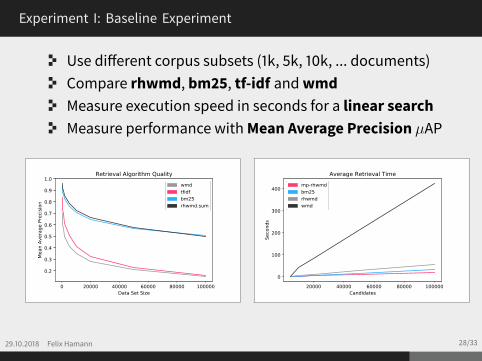
Experiment I: Baseline Experiment
29.10.2018 Felix Hamann 28/33
Use different corpus subsets (1k, 5k, 10k, ... documents)Compare rhwmd, bm25, tf-idf andwmdMeasure execution speed in seconds for a linear searchMeasure performance withMean Average Precision µAP
Experiment II: Re-Ranking
29.10.2018 Felix Hamann 29/33
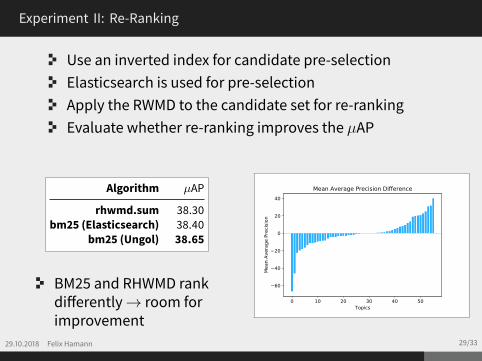
Use an inverted index for candidate pre-selectionElasticsearch is used for pre-selectionApply the RWMD to the candidate set for re-rankingEvaluate whether re-ranking improves the µAP
Algorithm µAP
rhwmd.sum 38.30bm25 (Elasticsearch) 38.40
bm25 (Ungol) 38.65
BM25 and RHWMD rankdifferently→ room forimprovement

RHWMD: Reasonable False Positive
29.10.2018 Felix Hamann 30/33
token nn sim idf weight
zöliakie erkrankungen 0.738 11.900 0.187erkrankten erkrankten 1.000 6.363 0.135diskutieren diskutieren 1.000 4.760 0.101
finde habe 0.758 5.330 0.086ernährungs gesundheit 0.754 5.999 0.096
bzw und 0.770 5.027 0.082berichte berichtete 0.809 4.304 0.074
probleme probleme 1.000 3.020 0.064von von 1.000 0.221 0.005die die 1.000 0.050 0.001
Approach works correctly but ranks worse
RHWMD: Nice True Positive
29.10.2018 Felix Hamann 31/33
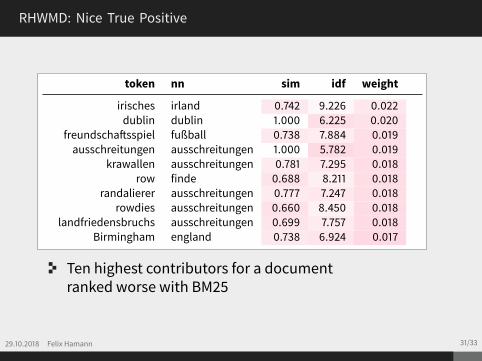
token nn sim idf weight
irisches irland 0.742 9.226 0.022dublin dublin 1.000 6.225 0.020
freundschaftsspiel fußball 0.738 7.884 0.019ausschreitungen ausschreitungen 1.000 5.782 0.019
krawallen ausschreitungen 0.781 7.295 0.018row finde 0.688 8.211 0.018
randalierer ausschreitungen 0.777 7.247 0.018rowdies ausschreitungen 0.660 8.450 0.018
landfriedensbruchs ausschreitungen 0.699 7.757 0.018Birmingham england 0.738 6.924 0.017
Ten highest contributors for a documentranked worse with BM25

Conclusion
29.10.2018 Felix Hamann 32/33
Summary
Producing binary hash codes using the compressormodel works nicelyFast similarity computation:much faster than the WMDCompetitive ranking algorithm even in this state
Ad-Hoc Improvements
Faster native implementation forquery→ batch of candidate documentsUse the rank of the nearest neighbourIDF combination (use IDF of NN)

29.10.2018 Felix Hamann 33/33
Thank you! Questions?

The Neural Embedding Compressor: Loss
29.10.2018 Felix Hamann 34/33
Training objective: reducereconstruction lossLoss: Mean squared errorof the Euclidean distanceInput: embedding vectoret of a token tOutput: embeddingvector e′t given et
L(et, e′t) :=1
2||et − e′t||
2
2
b’
b
A’
A
e
E
MK / 2
MK
K
f 1
f 2
σ σ σ σ σ σ g-softmax
e’
E
+
C
Φ
Ψ

The Neural Embedding Compressor: Encoder/Decoder
29.10.2018 Felix Hamann 35/33
M: Code componentsK: Code domainE: Embedding dims.
Encoder:ϕ : RE 7→ {0, 1}MK
Decoder:ψ : {0, 1}MK 7→ RE
Model:(ψθ ◦ ϕθ)(et) = e′t
b’
b
A’
A
e
E
MK / 2
MK
K
f 1
f 2
σ σ σ σ σ σ g-softmax
e’
E
+
C
Φ
Ψ
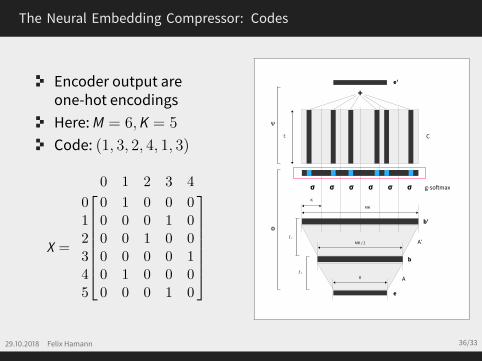
The Neural Embedding Compressor: Codes
29.10.2018 Felix Hamann 36/33
Encoder output areone-hot encodingsHere:M = 6,K = 5
Code: (1, 3, 2, 4, 1, 3)
X =
0 1 2 3 4
0 0 1 0 0 01 0 0 0 1 02 0 0 1 0 03 0 0 0 0 14 0 1 0 0 05 0 0 0 1 0
b’
b
A’
A
e
E
MK / 2
MK
K
f 1
f 2
σ σ σ σ σ σ g-softmax
e’
E
+
C
Φ
Ψ
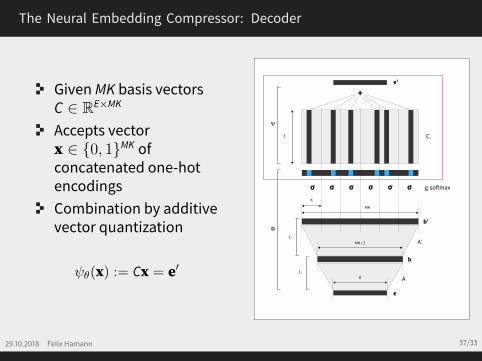
The Neural Embedding Compressor: Decoder
29.10.2018 Felix Hamann 37/33
GivenMK basis vectorsC ∈ RE×MK
Accepts vectorx ∈ {0, 1}MK ofconcatenated one-hotencodingsCombination by additivevector quantization
ψθ(x) := Cx = e′
b’
b
A’
A
e
E
MK / 2
MK
K
f 1
f 2
σ σ σ σ σ σ g-softmax
e’
E
+
C
Φ
Ψ
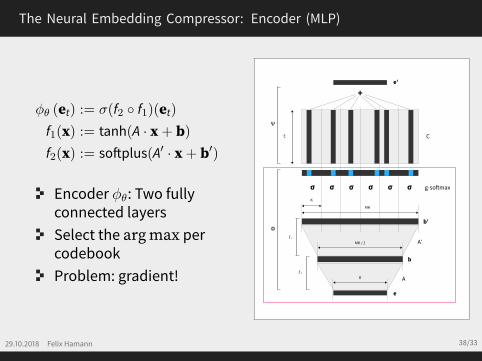
The Neural Embedding Compressor: Encoder (MLP)
29.10.2018 Felix Hamann 38/33
ϕθ (et) := σ(f2 ◦ f1)(et)f1(x) := tanh(A · x+ b)f2(x) := softplus(A′ · x+ b′)
Encoder ϕθ: Two fullyconnected layersSelect the argmax percodebookProblem: gradient!
b’
b
A’
A
e
E
MK / 2
MK
K
f 1
f 2
σ σ σ σ σ σ g-softmax
e’
E
+
C
Φ
Ψ
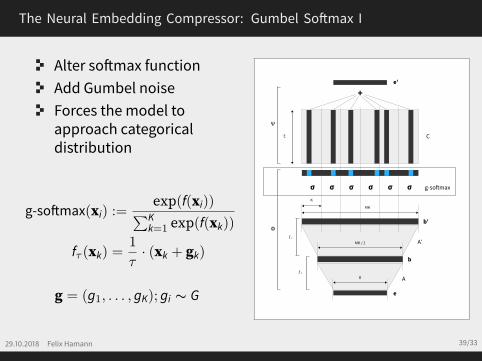
The Neural Embedding Compressor: Gumbel Softmax I
29.10.2018 Felix Hamann 39/33
Alter softmax functionAdd Gumbel noiseForces the model toapproach categoricaldistribution
g-softmax(xi) :=exp(f(xi))∑Kk=1 exp(f(xk))
fτ (xk) =1
τ· (xk + gk)
g = (g1, . . . , gK); gi ∼ G
b’
b
A’
A
e
E
MK / 2
MK
K
f 1
f 2
σ σ σ σ σ σ g-softmax
e’
E
+
C
Φ
Ψ

The Index
29.10.2018 Felix Hamann 40/33
No redundant informationAllow for multiprocessing
Index used for evaluation:
180921_ungol.db.pickle
Documents 294659Vocabulary 400000Code Size 256
Unique Tokens 258391Avg. Doc. Length 197
Skipped 8
Memory Footprint ∼ 3 GB
Database (Ungol Index)
+ avg_doclen: float
+ docref: DocReferences
+ mapping: Dict[str, Doc]
DocReferences
+ vocabulary: Dict[str, int]
+ lookup: Dict[int, str]
+ codemap: numpy bytearray [NxM]
+ termfreqs: Dict[int, int]
+ docfreqs: Dict[int, int]
+ unknown: Dict[str, int]
Doc
+ name: str
+ ref: DocReferences
+ idx: numpy int [n]
+ cnt: numpy int [n]
+ freq: numpy float [n]
+ unknown: Dict[str, int]
+ tokens(): List[str]