astudyofincrementallearning in chaotic neural network ·...
TRANSCRIPT

卒 業 研 究 報 告 題 目
指 導 教 員
岐阜工業高等専門学校 電気情報工学科
平 成 3 0 年( 2 0 1 8 年 ) 2 月 1 6 日 提 出
カオスニューラルネットワークによる逐次学習に関する研究
A Study of Incremental Learningin Chaotic Neural Network
出口 利憲 教授
2013E15 久保田 勘太郎

Abstract
The human brain consists of a large number of neurons connected to each other and
constituting a network.The action each cell performs is relatively simple. Simple things
get together and realize things such as superior memory ability, learning ability, thinking
ability by simply becoming a system.
A neural network is a model of a network of human neurons. In 1943 American
neurologist McCulloch and mathematician Pitts made a simplified neuron model from a
biological neuron. In 1949, the foundation of a neural network based on the proposal of
the Hebb rule was created. In 1958, the boom of the neural network started from the
development of Perceptron.
In this study, a recurrent type chaotic neural network model was used. According
to a certain rule, the coupling constant between neurons was changed, and the change
in learning result was investigated. Furthermore, the relation between the learning
pattern ratio confirmed in past research and the learning result was examined.
– i –

目 次Abstract
第 1章 序論 1
第 2章 ニューラルネットワーク 2
2.1 ニューロン . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2.2 ニューロンモデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.3 ニューラルネットワーク . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.4 ホップフィールドネットワーク . . . . . . . . . . . . . . . . . . . . . . . 5
第 3章 カオスニューラルネットワーク 6
3.1 カオス . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3.2 カオスニューロン . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.3 カオスニューラルネットワーク . . . . . . . . . . . . . . . . . . . . . . . 8
3.4 動的想起 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
第 4章 学習 11
4.1 学習法の分類 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4.2 誤差逆伝播法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
4.3 ヘッブ則 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.4 連想記憶 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4.5 逐次学習 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
第 5章 中期記憶 14
5.1 記憶の種類 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
5.2 大脳皮質 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
5.3 H.M.の臨床例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
5.4 中期記憶 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
第 6章 カオスニューラルネットワークの多層化 16
第 7章 実験 18
7.1 実験目的 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
7.2 実験モデル . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
7.3 実験 1 パターン素子の比率 1:1においての結合定数を変化させた学習 . . 19
– ii –

7.3.1 実験方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
7.3.2 実験結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
7.4 実験 2 パターン素子の比率 1:1以外においての結合定数を変化させた学習 1 21
7.4.1 実験方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
7.4.2 実験結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
7.5 実験 3 パターン素子の比率 1:1以外においての結合定数を変化させた学習 2 24
7.5.1 実験方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
7.5.2 実験結果 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
第 8章 結論 28
第 9章 謝辞 30
参考文献 31
– iii –

第1章 序論人間の脳は多数のニューロンが互いに接続し、ネットワークを構成することで成り立っ
ている。一つ一つの細胞が行う作用は比較的単純なものでありながら、それが集まり、シ
ステムとなるだけで優れた記憶能力や学習能力、思考能力といったものを実現している。9)
このニューロンによるネットワークを模倣し、モデル化したものがニューラルネットワー
クである。 ニューラルネットワークは 1943年にアメリカの神経学者であるMcCulloch
と数学者の Pittsが ニューロンを単純化して考案したニューロンモデルから始まったと
されている。1) 1949年にはカナダの心理学者Hebbがヘッブ則を提唱し、ニューラルネッ
トワークにおける学習の基礎を築き、1) 1958年にはアメリカの心理学者 Rosenblattが
ニューロンモデルとヘッブ則を基に パーセプトロンを開発してニューラルネットワーク
のブームが始まった。それ以降、ニューラルネットワークの研究は活発に行われ、ホッ
プフィールド型ニューラルネットワークや誤差逆伝播法、そしてカオスニューラルネッ
トワークといった技術が開発されてきた。
本研究で用いるカオスニューラルネットワークは、リカレント型ニューラルネットワー
クにカオス要素を取り入れたモデルである。これは、実際の脳神経系が「カオスダイナ
ミクスを有したカオスデバイス」で構成された システムとしてとらえられるという考え
に基づいて作成された。2)
本研究での目的は、過去の研究で使用されたカオスニューラルネットワークについて、
構成するパラメータを変化させ構築を変えることで、過去のニューラルネットワークモ
デルとの振る舞いの違いを調べることである。今回の研究では、梅田尭英氏の研究で用
いられた多層型ニューラルネットワークモデル 3)について、各モジュール間の結合定数
パラメータを変化させ、その時の学習結果の変化を調べた。
今回使用したニューラルネットワークモデルは、人間の脳の入力・海馬・連合野に見
立てた三つのモジュールによって構成されるカオスニューラルネットワークモデルであ
り、その中で入力ー連合野間でのやりとりを失くすことにより、古い記憶より新しい入
力の方を重要視する特性を持つモデルが作成できると予想される。
今回の研究では、パラメータの一定の規則に基づいた組み合わせに対する学習結果の
変化の調査を第一とし、多層型カオスニューラルネットワークモデルについて実験と考
察を行なった。
– 1 –

第2章 ニューラルネットワーク2.1 ニューロンニューロンとは脳にのみ存在する情報処理を行う神経細胞のことである。(図2.1)ニュー
ロンは外部から一定以上の電気信号を受け取り、それらがある一定を超えると興奮し、自
らも電気信号を他のニューロンへと出力する。これらのニューロンが互いに結合しあい、
ネットワークを形成することで動物の脳は情報を処理している。また、一度興奮した細
胞は、その後絶対不応期と呼ばれる状態になり、一定の期間は興奮しにくくなる。その
後も相対不応期と呼ばれる状態になり閾値が高くなるため興奮しにくくなる。
ニューロンには細胞体 (cell body)、軸索 (axon)、樹状突起 (dendrite)、シナプス (synapse)
と呼ばれる部位がある。細胞体は細胞核を含むニューロンの中核で、タンパク合成など
でニューロンに必要な物質を供給する。軸索は細胞体から伸びた突起で、他のニューロ
ンの樹状突起へと繋がり、電気信号の出力を行う。樹状突起は細胞体から文字通り木の
枝状に広がる複数の突起で、接続した他のニューロンの軸索から発せられた電気信号を
受け取る。 シナプスは、軸索と樹状突起の接合面に存在する部位である。
シナプスは興奮性と抑制性の 2種類に分けられ、興奮性のシナプスで接続されたニュー
ロンは片方が興奮するともう一方も興奮しやすくなる (強調作用)。逆に、抑制性のシナ
プスで接続されたニューロンは、一方が興奮するともう一方のニューロンが興奮しにく
くなる (競合作用)。
Figure 2.1 Neuron
– 2 –
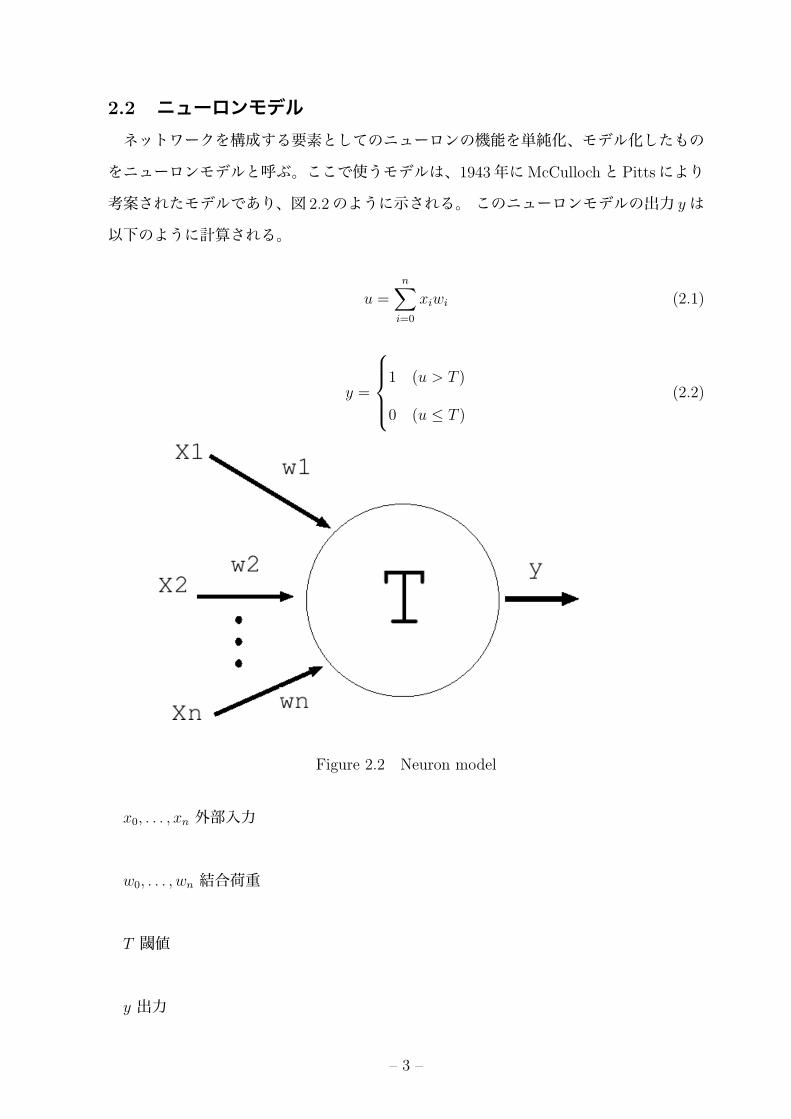
2.2 ニューロンモデルネットワークを構成する要素としてのニューロンの機能を単純化、モデル化したもの
をニューロンモデルと呼ぶ。ここで使うモデルは、1943年にMcCullochとPittsにより
考案されたモデルであり、図 2.2のように示される。 このニューロンモデルの出力 yは
以下のように計算される。
u =n∑
i=0
xiwi (2.1)
y =
⎧⎪⎪⎨
⎪⎪⎩
1 (u > T )
0 (u ≤ T )
(2.2)
Figure 2.2 Neuron model
x0, . . . , xn 外部入力
w0, . . . , wn 結合荷重
T 閾値
y 出力
– 3 –

2.3 ニューラルネットワークニューラルネットワークとは、ニューロンモデルによって構成されたネットワークの
総称である。ニューロンが脳内で行うように、ニューロンモデルの出力を他のニューロ
ンモデルの外部入力に伝達することでネットワークを構成し状態を変化、出力する。
ニューラルネットワークにはフィードフォアード型やリカレント型など様々な構成パ
ターンがある。図 2.3のフィードフォアード型はニューロンモデルの信号が一方向にの
み流れる。逆に、図 2.4のリカレント型ではニューロンモデルが相互に結合しており、信
号は双方向に伝播する。
Figure 2.3 Feed forward type
Figure 2.4 Recurrent type
– 4 –
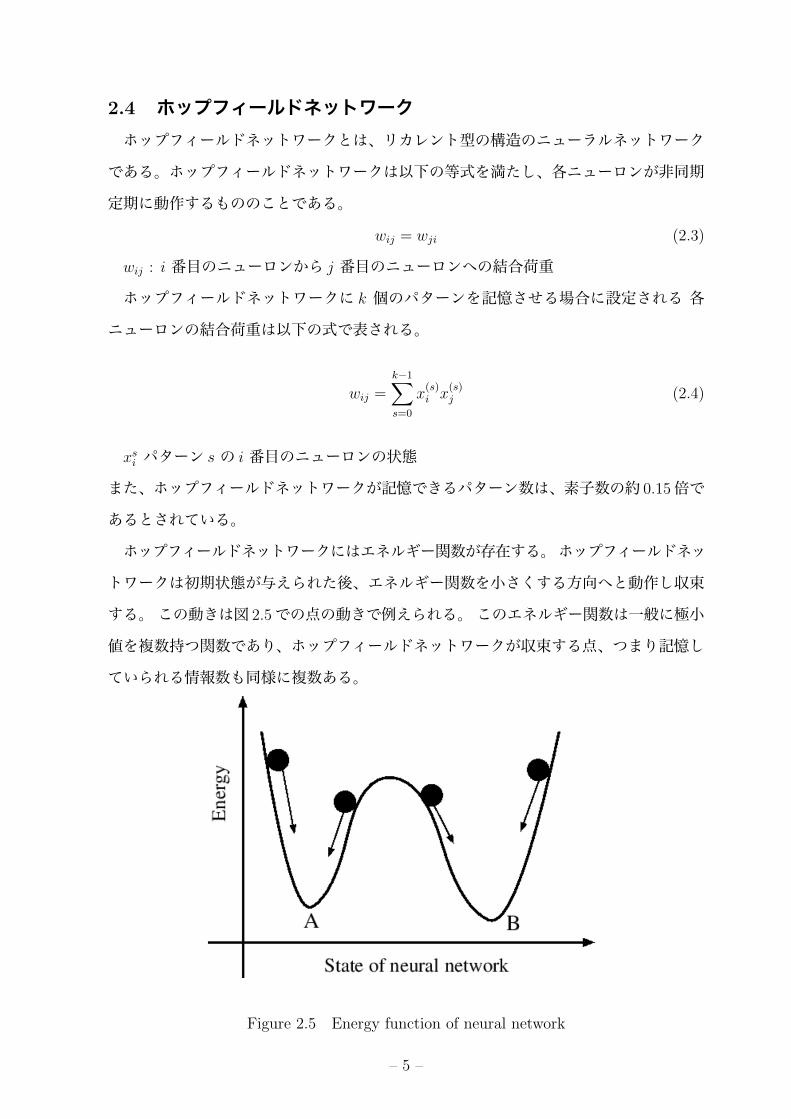
2.4 ホップフィールドネットワークホップフィールドネットワークとは、リカレント型の構造のニューラルネットワーク
である。ホップフィールドネットワークは以下の等式を満たし、各ニューロンが非同期
定期に動作するもののことである。
wij = wji (2.3)
wij : i 番目のニューロンから j 番目のニューロンへの結合荷重
ホップフィールドネットワークに k 個のパターンを記憶させる場合に設定される 各
ニューロンの結合荷重は以下の式で表される。
wij =k−1∑
s=0
x(s)i x(s)
j (2.4)
xsi パターン s の i 番目のニューロンの状態
また、ホップフィールドネットワークが記憶できるパターン数は、素子数の約 0.15倍で
あるとされている。
ホップフィールドネットワークにはエネルギー関数が存在する。ホップフィールドネッ
トワークは初期状態が与えられた後、エネルギー関数を小さくする方向へと動作し収束
する。この動きは図 2.5での点の動きで例えられる。このエネルギー関数は一般に極小
値を複数持つ関数であり、ホップフィールドネットワークが収束する点、つまり記憶し
ていられる情報数も同様に複数ある。
Figure 2.5 Energy function of neural network
– 5 –

第3章 カオスニューラルネットワーク3.1 カオスカオスとは「決定論的システムにおいて起こる確率論的な振る舞い」のことである。4)
つまり、構造自体は理論的に示されているが、条件の変化による振る舞いに規則性を見
出しにくい、もしくは見出せない振る舞いのことを指す。カオスは初期条件が決まれば,
常に同じ振る舞いをするという点でランダムとは異なるものの、ランダムのように不規
則で将来の予測が困難な挙動である。カオスは初期値の僅かな差によってその後の挙動
が大きく変化する、初期値鋭敏性を持つ。 また非線型性を持ち、非周期的でもある。
カオスの代表的なものに、ロジスティック写像がある。これは, 式 (3.1)で表される方
程式で、与えられた α の値によって極めて複雑な振る舞いをする。ロジスティック写像
の振る舞いの一つを図 3.1に示す。
Xn+1 = αXn(1−Xn) (3.1)
Figure 3.1 α=3.9、X0=0.5
– 6 –

3.2 カオスニューロンカオスニューロンは、ニューロンモデルにカオスを導入したモデルである。現実での
ニューロンに見られる、カオス的な振る舞いをニューロンモデルで再現したモデルで、
合原一幸らによって提唱された。5)このモデルはMcCullochと Pittsのニューロンモデ
ルでは考慮されなかった, 一度興奮した後、一定期間興奮しなくなる、興奮しにくくな
るといった性質や、時間とともに電気信号が減衰していく性質を再現している。カオス
ニューロンモデルの式は以下のように表される。
x(t+ 1) = f [A(t)− αt∑
d=0
kdg{x(t− d)}− θ] (3.2)
x(t) 時刻 t におけるニューロンの出力
A(t) 時刻 t における外部入力の大きさ
α 不応性に対する係数
k 不応性の時間減衰定数
g 軸索の伝達関数
不応性は、一度興奮したニューロンは興奮後、興奮しにくくなる現象を再現するため
に設定された性質である。関数 f は出力を一定範囲に制限する関数で、以下のシグモイ
ド関数 (式 (3.3))を用いる。
f(y) =1
1 + exp(−yϵ )
(3.3)
Figure 3.2 Sigmoid function( ε = 1 )
– 7 –

3.3 カオスニューラルネットワークカオスニューラルネットワークとは、カオスニューロンによって構成されたニューラ
ルネットワークのことである。カオスニューラルネットワークは、相互に結合したリカ
レント型の構造を持ち、以下の式で表される。
xi (t+ 1) = f [M∑
i=1
vij
t∑
d=0
KdsAj (t− d)
+N∑
i=1
wij
t∑
d=0
Kdmh {xj (t− d)} (3.4)
−αt∑
d=0
kdrg {xi (t− d)}− θi]
M 外部入力数 N ニューロン数
xi(t) 時刻 t における i 番目のニューロンの出力
vij 外部入力からの i 番目のニューロンに対する結合荷重
ωij j 番目のニューロンから i 番目のニューロンへの結合荷重
h 出力と不応性との関係を与える関数
ks 外部入力の時間減衰定数
km 他ニューロンからの入力の時間減衰定数
kr 不応性の時間減衰定数
θ i番目のニューロンの閾値
式 (3.5)の関数 f において, 外部入力を表す第一項を ζi , ニューロン結合を表す第二項
を ηi , 不応性を表す第三項を ξi とすると, 式 (3.5)は以下のように簡略化できる。
ζi(t+ 1) =M∑
j=1
vij
t∑
d=0
kdsAj(t− d) = ksζi(t) +
M∑
j=1
vijAj(t)
ηi(t+ 1) =N∑
j=1
ωij
t∑
d=0
kdmh{xj(t− d)} = kmηi(t) +
N∑
j=1
ωijxj(t) (3.5)
ξi(t+ 1) = −αt∑
d=0
kdrg{xi(t− d)}− θi = krξ(t)− αxi(t)− θi(1− kr)
xi (t+ 1) = f [ξi (t+ 1) + ηi (t+ 1) + ζi (t+ 1)] (3.6)
– 8 –

3.4 動的想起ネットワークが記憶したパターンを出力する現象を想起するという。いくらかのパター
ンを学習させたカオスニューラルネットワークを外部から入力を与えずに動作させ続け
ると、ネットワークは学習したパターンの中からいくつかのパターンを動的に想起し出
力 していく。カオスニューラル ネットワークの特徴の一つに、動的想起というものがあ
げられる。動的想起とは、出力が収束せず、記憶したパターンを含む様々なパターンを
出力する現象である。ネットワークが動的想起を示す時、ネットワークは動的想起状態
にあるという。動的想起の原因には、カオスニューロンに含まれる不応性が挙げられる。
これは記憶検索と呼ばれる、ネットワークに記憶してある検索したいパターンそのも
のを入力して探し出すのではなく、検索したいパターンの特徴のみを入力することによっ
て、目的とするパターンを見つ け出す手法において非常に重要な現象である。
例として、A,B,Cの形を順に学習させたカオスニューラルネットワークの動的想起の
状態を、 図 3.3に示す。図 3.3より、t = 36までは最後に学習したCを想起し続け てい
るが、次のステップからは形が崩れ始めているのがわかる。また、t = 43から、学習し
たパターンであるBを想起していることがわかる。このように、学習したパターンを入
力を与えられずに動的に想起する現象が、動的想起である。6)
– 9 –

Figure 3.3 Dynamical Recollection
– 10 –

第4章 学習4.1 学習法の分類生物の神経系において脳は過去の経験を記憶として蓄え、これを活用して処理を行な
う。さらに、自己の動作をより適切なものへと変化させていく。 このように自身の構造
をより適切な状態に変化させる事を学習と呼ぶ。
脳は多数のニューロンからなるネットワークによって構成されているため、脳の特性
の変化とはニューロン間の相互結合の強さを変換させる事で実現する。結合の強さの変
換というのは具体的には、結合を断ち切ったり、新しい結合を作成したりする事を指す。
このような脳の仕組みをプログラムとして実現させる。ニューラルネットワークでの
学習は、特定のアルゴリズムに基づきニューロン間の伝達係数である結合荷重を変化させ
る事を指す。意味のある学習をするためには、それに応じた何らかの機構が必要である。
学習の指針として、ある入力に対して回路網が出力すべき望ましい出力が外部から与
えられる場合、これを教師信号と呼ぶ。その教師信号 (正解)の入力によって、問題に最
適化されていく教師あり学習と、教師信号を必要としない教師なし学習の 2つに分けら
れる。明確な解答が用意される場合には教師あり学習が、データ・クラスタリングには
教師なし学習が用いられる。結果としていずれも次元削減されるため、画像や統計など
多次元量のデータでかつ線形分離不可能な問題に対して、比較的小さい計算量で良好な
解を得られることが多い 7)。
このことから、データ予測やパターン認識をはじめ、さまざまな分野において応用さ
れている。
4.2 誤差逆伝播法誤差逆伝播法 (バックプロパゲーション)とは、1986年に米スタンフォード大学のRumel-
hart教授らが発表した多層階層型ニューラルネットワークの学習方法である。8)
方法の要約は次の通りである。
1. ニューラルネットワークに学習のためのサンプルを与える。
2. ネットワークの出力とそのサンプルの最適解を比較する。各出力ニューロンにつ
いて誤差を計算する。
3. ここのニューロンの期待される出力値と倍率を、要求された出力と実際の出力の
– 11 –

差を計算する。
4. 各ニューロンの重みを局所誤差が小さくなるよう調整する。
5. より大きな重みで接続された前段のニューロンに対して、局所誤差の責任がある
と判定する。
6. そのように判定された前段のニューロンのさらに前段のニューロン群について同
様の処理を行う。
この方法によって、従来のパーセプトロンでは学習することのできなかった非線形分
離問題を解決できるようになった。
4.3 ヘッブ則ヘッブ則は、Hebbが提唱したニューロン間の結合荷重の変化に関する法則である。ヘッ
ブ則では、2つのニューロンが同時に興奮した時、その間の結合荷重を増大させ、片方の
ニューロンのみが興奮し、もう一方が興奮しない場合は結合荷重を減少させる。1)この法
則に基づき、ニューロン間の結合定数を変化させていくとが、特定のニューロン間の繋
がりが太くなり、その結果特定の細胞への情報伝達経路が形成される (流れやすくなる)。
4.4 連想記憶人間は自分の脳に蓄積された記憶を、連想によって検索すると言われている。ニュー
ラルネットワークにおける連想記憶(Associate memory)とは、複数個の入力パターン
のうち一つをニューラルネットワークに入力したときに、対応する出力パターンを出力
するように、入出力パターンを記憶することである。入力パターンと出力パターンが同
じベクトル空間となる連想記憶を自己相関連想記憶(Autoassociative memory)と呼ぶ。
異なるベクトル関数空間となるものを相互相関連想記憶(Hereroassciative memory)と
呼ぶ。 自己相関連想記憶とは、例えば、ワープロの文字を記憶しておき、 手書きの文
字などを入力した場合、記憶しているワープロの文字がどれに一番近いかを答えること
に相当する。 相互相関連想記憶とは、「りんご」は「赤い」と連想するように、入力と
出力の関係を記憶して、与えられた入力に対してそれにあうような出力を出すことに相
当している。9)
– 12 –

4.5 逐次学習逐次学習とは、カオスニューラルネットワークの学習に用いられる学習方法である。
この方法は入力の度にニューロンが結合荷重を入力に合わせて変化させ、逐次的に学習
を行う方法である。逐次学習はヘッブ則に基づいて行われ、2つのニューロンが同時に
興奮した場合は結合荷重を増加させ、片方が興奮してもう片方が興奮しなかった場合は
結合荷重を減少させる。 ニューロンが学習を行う条件は以下の式で与えられる。10)
ζi × (ηi + ξi) < 0 (4.1)
式 (4.1)を満たしていないニューロンは、現在の入力を既に学習しているためこれ以
上結合荷重を変化させない。一方、条件を満たすニューロンは 現在の入力をまだ学習し
きっていないため、以下の式 (4.2)に基づいて 結合荷重を変化させ学習を行う。
ωnewij =
⎧⎪⎪⎨
⎪⎪⎩
ωoldij +∆ωold
ij −∆ω [ζi(t)× xj(t− 1) > 0]
ωoldij −∆ωold
ij −∆ω [ζi(t)× xj(t− 1) ≤ 0]
(4.2)
ωoldij 変化前の結合荷重
ωnewij 変化後の結合荷重
∆ω 結合荷重の変化量
– 13 –

第5章 中期記憶5.1 記憶の種類記憶とは、環境との相互作用によって生ずる、経験の記銘、これの保持、これの再生
をする過程を指す脳内の持続的変化である。この記憶には、一時的な短期記憶と、より
永続的な長期記憶がある。また、記憶される情報のタイプで分類すると、認知記憶と手
続き記憶と分けられる。前者は、以前見たことがある出来事や風景の記憶を思い出すこ
とによって意識にのぼってくるもの、後者は熟練した技能や条件反射など、意識しない
でも行動に現れる記憶とされる。
短期記憶の過程は脳内の特定の神経回路を信号が巡回する動的過程であるとされてい
る。海馬に対して高頻度で連続刺激が行われると、長時間 (約 1時間~数日にわたる)の
伝達効率の上昇が起こる。この現象を長期増強といい、短期記憶の基礎をなすと考えら
れている。
5.2 大脳皮質大脳皮質は、大脳の機能を制御する部位であり、脳の中心的存在である大脳半球の中
でも非常に重要な部分である。大脳皮質はその発生から古い部分と新しい部分に分けら
れる。
古い部分は古皮質と呼ばれ、すべての脊椎動物に見られる脳の系統の中で最も古い時
期に発生した皮質であり、主として嗅覚情報を処理する皮質領域である。高等な哺乳類
や人間では退化する傾向にある。
原皮質は両生類以上の生物に見ることができ、哺乳類になっても退化せず複雑な構造を
示す。海馬は原皮質の代表的な構造であり、記憶などの高度な神経機能に役立っている。
新皮質は哺乳類が著しく発達しており、両生類や爬虫類は古皮質や原皮質が大脳のほと
んどを覆っているが、哺乳類になると新皮質が発達し、それらは内側に押しやられる。特
に人のような極度に新皮質が発達した動物では大脳のほとんどが新皮質に覆われている。
5.3 H.M.の臨床例脳内の海馬と呼ばれる部位は、記憶形成において重要な役割を担っていると考えられ
ている。 そして、その機能の解明に大きな貢献をした人物としてHenry Molaison(以下
– 14 –

「H.M.」と称する)が挙げられる。 H.M.はてんかん治療のため海馬とその近傍の摘出手
術を受けた後、術前 3年間の記憶に対する部分的な逆向性健忘症と、術後の記憶の定着
ができなくなる順向性健忘症を発症した。しかし、術前 3年以上前の記憶は思い出すこ
とが可能であり、短期記憶も問題がない等、記憶能力が全て失われていたわけではなかっ
た。14)
これらの症例から、海馬は非永続的な記憶を保持すると共に、記憶の形成に大きな影
響を与えていると推測されている。
5.4 中期記憶中期記憶は海馬が記憶している非永続的な記憶である。 伊藤真らはH.M.の臨床例で
失われた海馬が保持する非永続的な記憶を、連合野が保持する永続的な長期記憶とは異
なるものであるとして、中期記憶と名付けた。11)
– 15 –

第6章 カオスニューラルネットワークの多層化カオスニューラルネットワークを多層化したモデルとして, 図 6.1のように 表される江
本らによって提唱されたモデルがある。12)このモデルは、入力層、海馬モジュール、連
合野モジュールの 3層からなるモデルであり、以下の現象を発現可能としたものである。
• 逐次記憶
• メタ記憶
• 由想起性
• 中期記憶による長期記憶の形成
• H.M.の臨床例に対応する現象
• エピソード記憶
• 意味記憶
Figure 6.1 Network structure of model modeled by Emoto etc.
– 16 –

このモデルの海馬モジュールのニューロンの状態は次の式で与えられる。
xcai (t+ 1) = f [
t∑
d=0
kdsA
caj (t− d)
+t∑
d=0
kdf
N∑
j=1
ωcaij x
caj (t− d) (6.1)
−αt∑
d=0
kdrx
cai (t− d)− θ]
Acai (t) = s[xip
i (t)] (6.2)
s(uip, u|cx) =
⎧⎪⎪⎨
⎪⎪⎩
8.75 if uip > 0.5 or ucx > 0.5
1.25 else
(6.3)
ca , cx , ip はそれぞれ、海馬モジュール、連合野モジュール、入力層を示すインデッ
クスである。このモデルでは式 (6.4)、式 (6.5)の条件を共に満たすとき、式 (6.6)の式に
基づいて学習を行う。
similarity(t− 2) ̸= N (6.4)
similarity(t− 1) = similarity(t) = N (6.5)
∆ωij = β(2xi(t)− 1)(2xj(t− 1)− 1)
similarity =N∑
i=1
xindex1i xindex2
i (6.6)
N 素子数
β 学習定数
– 17 –

第7章 実験7.1 実験目的本研究室では、カオスニューラルネットワークを用いた逐次学習についての研究を行っ
てきた。前年度までの研究で、この逐次学習に適したパラメータや学習データの比率、
海馬による中期記憶、順向性健忘の再現を行った。今回の実験では、過去の研究 3)にお
ける、入力・海馬・連合野の各モジュールの組み合わせによる中期記憶再現を目的とし
たニューラルネットワークモデルにおいて、入力から連合野への伝達が無くなった場合
の特性を調べた。
7.2 実験モデル今回実験に使用したカオスニューラルネットワークモデルを図 7.1に示す。これは過
去の研究で扱われたネットワークモデルにおいて、入力モジュールから連合野モジュー
ルへの伝達を無くしたものである。実質的には入力層-中間層-出力層のモジュールの繋
がりからなり、出力層から中間層へのフィードバックが追加されたモデルと言える。
Figure 7.1 Neural network model
今回の研究では、このモデルのうち海馬-連合野の結合定数 (v-hc)を 2.0に固定し、入
力-海馬、連合野-海馬の結合定数 (前者は v-ih、後者は v-ch)の総和を 2.0となるようにし
たうえでその比率が変化する。海馬、連合野モジュールの i番目のニューロンの状態は
– 18 –

次の式 (7.1)で与えられる。
xi (t+ 1) = f [ξi (t+ 1) + ηi (t+ 1) + ζi (t+ 1)] (7.1)
式 (7.1)において、外部入力を表す第一項は ζi , ニューロン結合を表す第二項は ηi , 不
応性を表す第三項は ξi で表され、各式は次の式 (7.2)~(7.4)で表される。
ζi(t+ 1) =M∑
j=1
vij
t∑
d=0
kdsAj(t− d) = ksζi(t) +
M∑
j=1
vijAj(t) (7.2)
ηi(t+ 1) =N∑
j=1
ωij
t∑
d=0
kdmh{xj(t− d)} = kmηi(t) +
N∑
j=1
ωijxj(t) (7.3)
ξi(t+ 1) = −αt∑
d=0
kdrg{xi(t− d)}− θi = krξ(t)− αxi(t)− θi(1− kr) (7.4)
また、学習方法については参考文献 3)と同条件の、ヘッブ則に基づいた式に従って逐
次学習で行うこととした。本実験で使うモデルの各種パラメータの値を表 7.1に示す。
Table 7.1 Various parameters
ε 0.015
km 0.1
kr 0.95
ks 0.95
alp 0.0006
dw c 0.000003
dw-h 0.000003
7.3 実験 1 パターン素子の比率 1:1においての結合定数を変化させた学習
7.3.1 実験方法前年度までの研究の中で、逐次学習における学習パターンの素子数の比率が 1:1の時、
学習結果に影響する現象が見られた (参考文献 13))。よって素子比率 1:1の条件下での結合
– 19 –

係数パラメータを変動させ、その時の学習成功数を調べた。今回の研究では一貫して学
習パターンは「1」「-1」2種類の素子 100個の羅列で表され、この実験では「1 : -1 = 1 :
1」の比率となる。つまり 1パターン 100素子で構成され、その内訳は「1」50素子、「-1」
50素子がランダムで配列されたものとなる。これを 300パターン学習させ、1パターン
学習するごとにこの条件のもと、入力-海馬、連合野-海馬の結合定数を変化させ、その
時の学習結果を測定した。結合定数以外のパラメータは表 7.1に従う。
7.3.2 実験結果「1」と「-1」の比率が 1:1の学習パターンにおいて、入力-海馬、連合野-海馬の結合定
数パラメータを変動させた時の、学習パターン数と学習成功パターン数の関係のグラフ
を図 7.2に示す。
Figure 7.2 Number of learning successes (Pattern ratio 1:1)
x軸が入力された学習パターン数、y軸が学習成功パターン数を表す。
ih1.0、ch1.0の時を除き、学習パターン数と学習成功パターン数が同値となる完全学習
となっている。今までの研究の中で、学習パターンの素子数に対して 1.5倍程度の学習パ
– 20 –

ターン数が完全学習可能な数であり、今回の素子数は 100の場合は実際は 150パターン
前後で完全学習は終わるはずであるが、最終的に 300パターンすべてを完全学習できて
いる。これは参考文献 13)における実験結果と同様の結果であり、すなわち約 150パター
ンを学習する前に 1:1の比率の性質の学習が完了したために起きた現象であると考えら
れる。
また、結合定数パラメータを変動させてもほぼ同様な結果が得られたため、学習パター
ン素子の比率 1:1により起こる学習結果への影響は今回のカオスニューラルネットワー
クモデルにおいても同様に発生する可能性があると考えられる。実験の目的である「入
力-海馬、連合野-海馬の結合定数の変化による学習結果」を求める上において、学習パ
ターン素子の比率が 1:1となることは結果を固定してしまう要素であると考えられる。
7.4 実験2 パターン素子の比率1:1以外においての結合定数を変化させた学習1
7.4.1 実験方法実験 1において、学習パターン素子の比率が 1:1であるとき、参考文献 3)と同様に今回
のカオスニューラルネットワークモデルにおいても、学習結果が全パターン完全学習か
逆に一つも学習できないかのどちらかになってしまうことが考えられた。よって、素子比
率を変化させ 1:1の条件から外した状態で、入力-海馬、連合野-海馬の結合定数パラメー
タを変化させたときの学習成功数を調べた。この実験では「1」、「-1」の比率を「49:51」
または「51:49」で順番ランダムの 100素子 1パターンとして計 300パターンを学習させ
た。結合定数パラメータは、入力-海馬、連合野-海馬の結合定数の和が 2.0となることを
条件に、以下の表に示すパラメータの組み合わせで実験した。それ以外のパラメータに
ついては、表 7.1に従う。また、学習結果について、各パラメータごとに学習パターン
数=学習成功パターン数が続く最大値である完全学習数 (Maximum complete learning)
と、学習終了までの間での最多学習成功数 (Maximum number of learning successes)に
ついて調べた。(以下、図中にてMcl(完全学習数)、Mnls(最多学習成功数)と略)
7.4.2 実験結果「1」と「-1」の比率が「49:51」もしくは「51:49」である学習パターンにおいて、入
力-海馬 (Input-Hippocampus、以下”i-h”と略)、連合野-海馬 (Cortex-Hippocampus、以
– 21 –
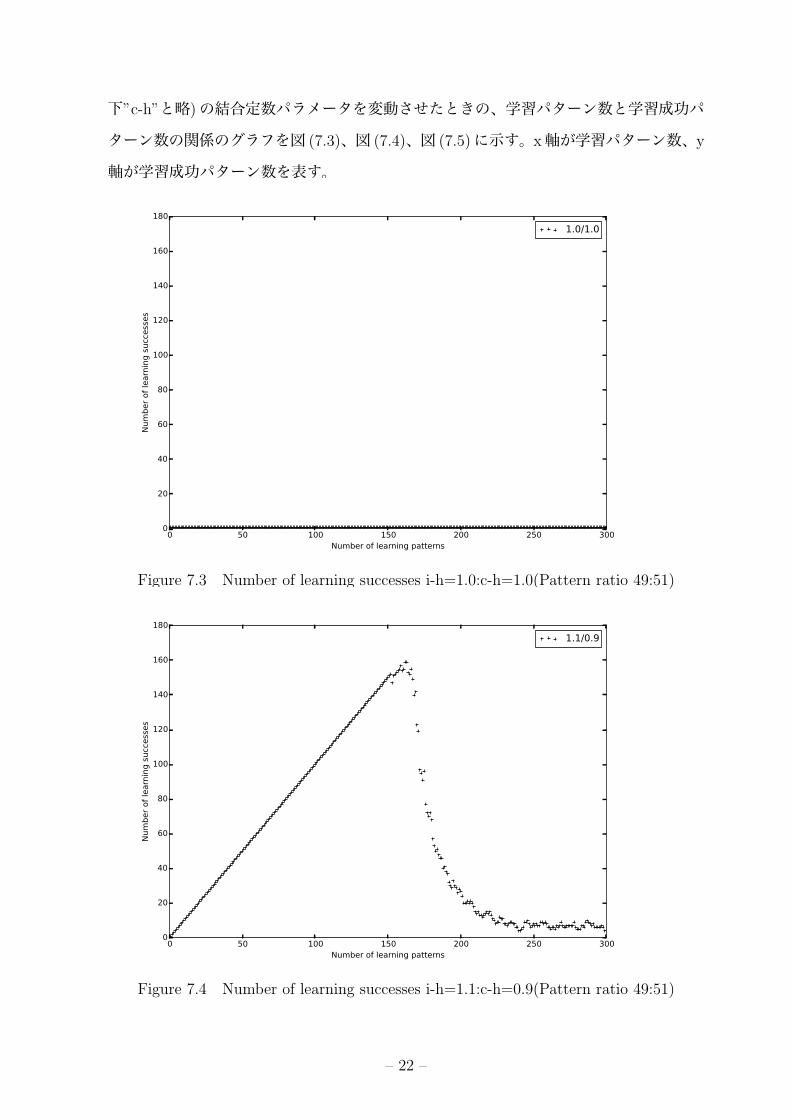
下”c-h”と略)の結合定数パラメータを変動させたときの、学習パターン数と学習成功パ
ターン数の関係のグラフを図 (7.3)、図 (7.4)、図 (7.5)に示す。x軸が学習パターン数、y
軸が学習成功パターン数を表す。
Figure 7.3 Number of learning successes i-h=1.0:c-h=1.0(Pattern ratio 49:51)
Figure 7.4 Number of learning successes i-h=1.1:c-h=0.9(Pattern ratio 49:51)
– 22 –
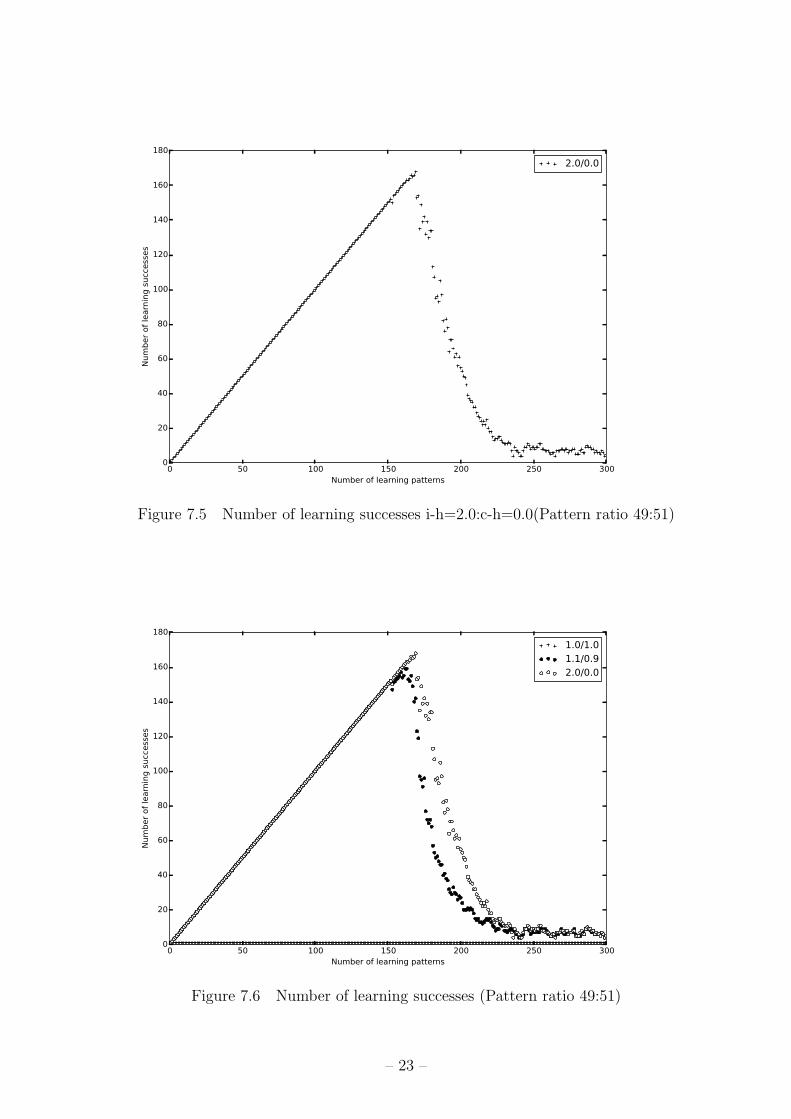
Figure 7.5 Number of learning successes i-h=2.0:c-h=0.0(Pattern ratio 49:51)
Figure 7.6 Number of learning successes (Pattern ratio 49:51)
– 23 –

i-h=1.0:c-h=1.0の組み合わせでは、学習開始から終了まで想起成功したのは 1パター
ンのみのままであった。(図 7.3) ei-h=1.1:c-h=0.9の組み合わせでは、150付近までは完
全学習できており、160パターン前付近で学習性能が落ちた。(図 7.4) i-h=2.0:c-h=0.0の
組み合わせは、全パターンの中で最も学習成功パターン数が多いが、160パターンを超
えたあたりから学習性能が落ちた。(図 7.5)
これらのグラフを重ねたものを図 7.1 に示す。これに示した 3つの組み合わせ以外の
パターンは i-h=1.1と i-h=2.0の間をばらつく程度の違いになった。どの組み合わせにお
いても、実験 1の時のような 200以上のパターンの学習ができたものは無かった。基本
的に 150パターン前後までの完全学習の後、急激に想起できたパターン数が減少して、
10パターン前後で落ち着く。今回変化させた結合定数パラメータの学習結果への影響は、
i-hの比率が大きくなるほど学習できているパターンの数が多く、減少が始まるまでのパ
ターン数が多くなり、逆に c-hの比率が大きくなると学習できるパターン数は少なく、よ
り早く減少が始まるようになった。
これらの結果について、各パラメータごとの最大学習数 (Mcl)と最多学習成功数 (Mnls)
を図7.7に示す。x軸はパラメータの組み合わせ、y軸は学習パターン数を表す。「i-h=1.0:c-
h=1.0」以外のパラメータについては、横並びで完全学習数に関しては差がなく、最多学
習成功数については、わずかだが i-hの比率が大きいものほど高い傾向がみられた。
7.5 実験3 パターン素子の比率1:1以外においての結合定数を変化させた学習2
7.5.1 実験方法実験 2において、各パラメータごとの学習結果を得ることができたが、その結果の中
でも「i-h=1.0:c-h=1.0」とそれ以外との結果が非常に大きな差になっていた。そのため
追加で「ih=1.0-1.1:ch=1.0-0.9」までの間でさらに細かくパラメータを取り、実験 2と同
様の条件において以下の表に示すパラメータの組み合わせで実験した。それ以外のパラ
メータについては、表 7.1に従う。また、学習結果についても実験 2と同様に完全学習数
(Mcl)と最多学習成功数 (Mnls)を求めた。
– 24 –
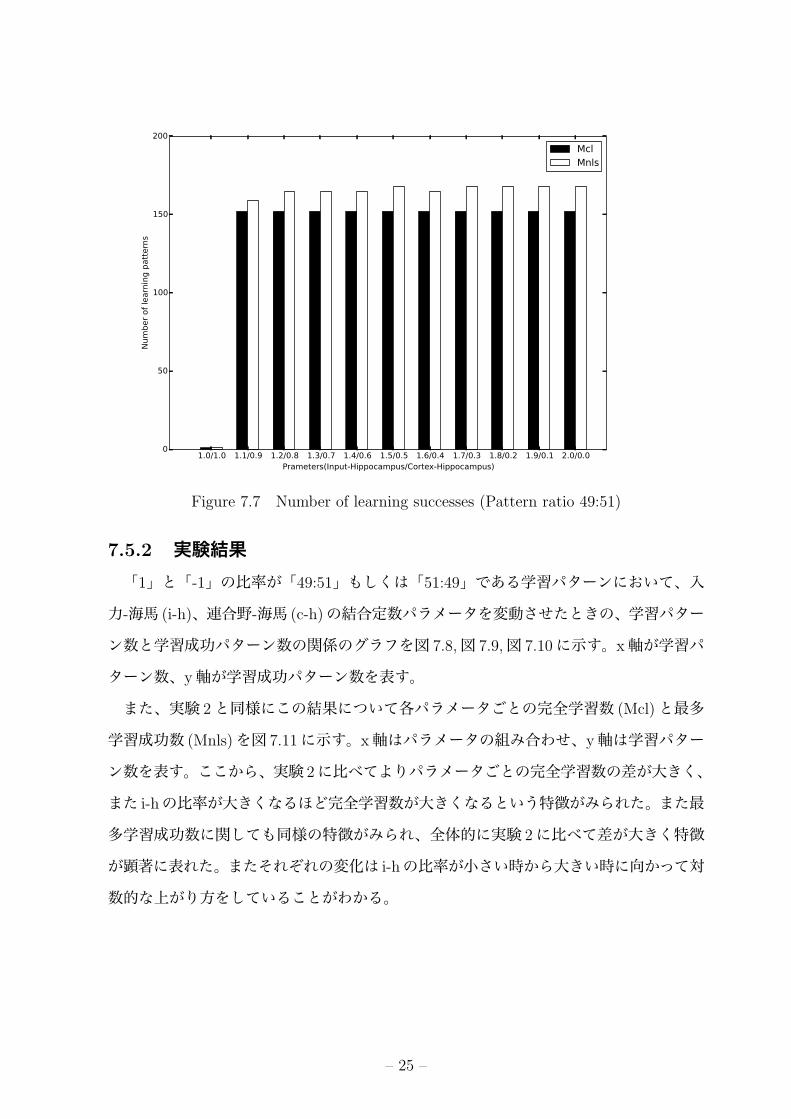
Figure 7.7 Number of learning successes (Pattern ratio 49:51)
7.5.2 実験結果「1」と「-1」の比率が「49:51」もしくは「51:49」である学習パターンにおいて、入
力-海馬 (i-h)、連合野-海馬 (c-h)の結合定数パラメータを変動させたときの、学習パター
ン数と学習成功パターン数の関係のグラフを図 7.8,図 7.9,図 7.10に示す。x軸が学習パ
ターン数、y軸が学習成功パターン数を表す。
また、実験 2と同様にこの結果について各パラメータごとの完全学習数 (Mcl)と最多
学習成功数 (Mnls)を図 7.11に示す。x軸はパラメータの組み合わせ、y軸は学習パター
ン数を表す。ここから、実験 2に比べてよりパラメータごとの完全学習数の差が大きく、
また i-hの比率が大きくなるほど完全学習数が大きくなるという特徴がみられた。また最
多学習成功数に関しても同様の特徴がみられ、全体的に実験 2に比べて差が大きく特徴
が顕著に表れた。またそれぞれの変化は i-hの比率が小さい時から大きい時に向かって対
数的な上がり方をしていることがわかる。
– 25 –
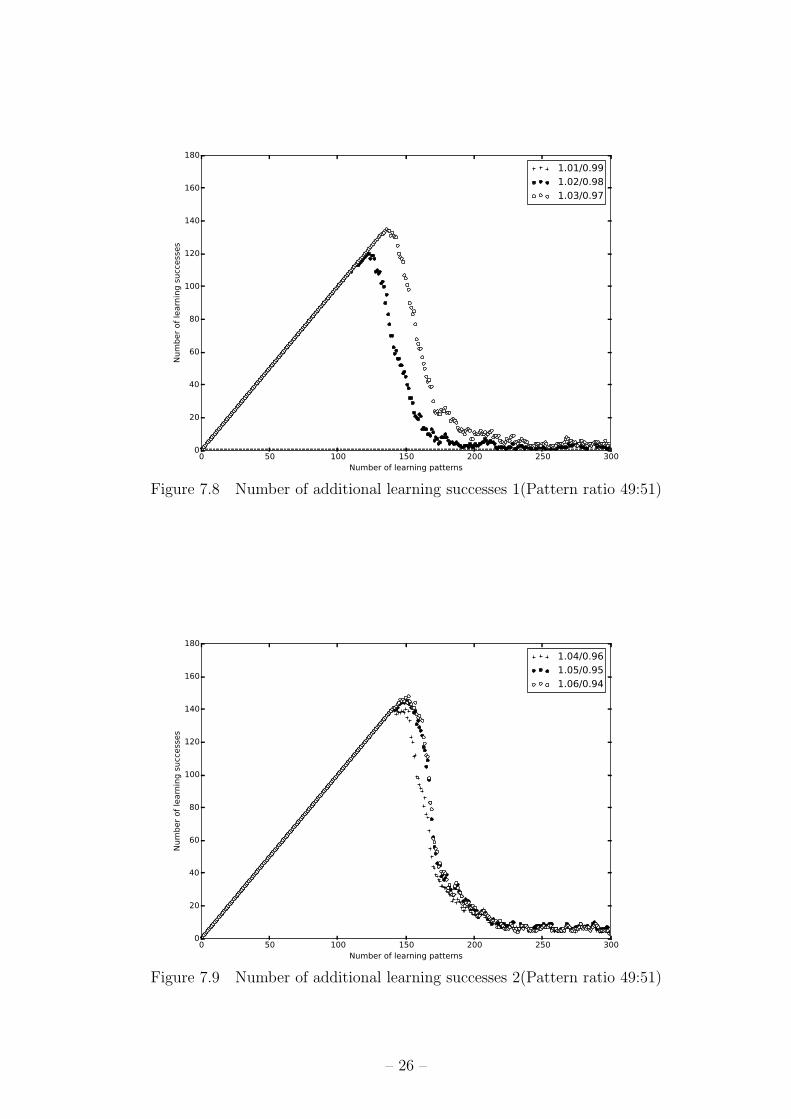
Figure 7.8 Number of additional learning successes 1(Pattern ratio 49:51)
Figure 7.9 Number of additional learning successes 2(Pattern ratio 49:51)
– 26 –
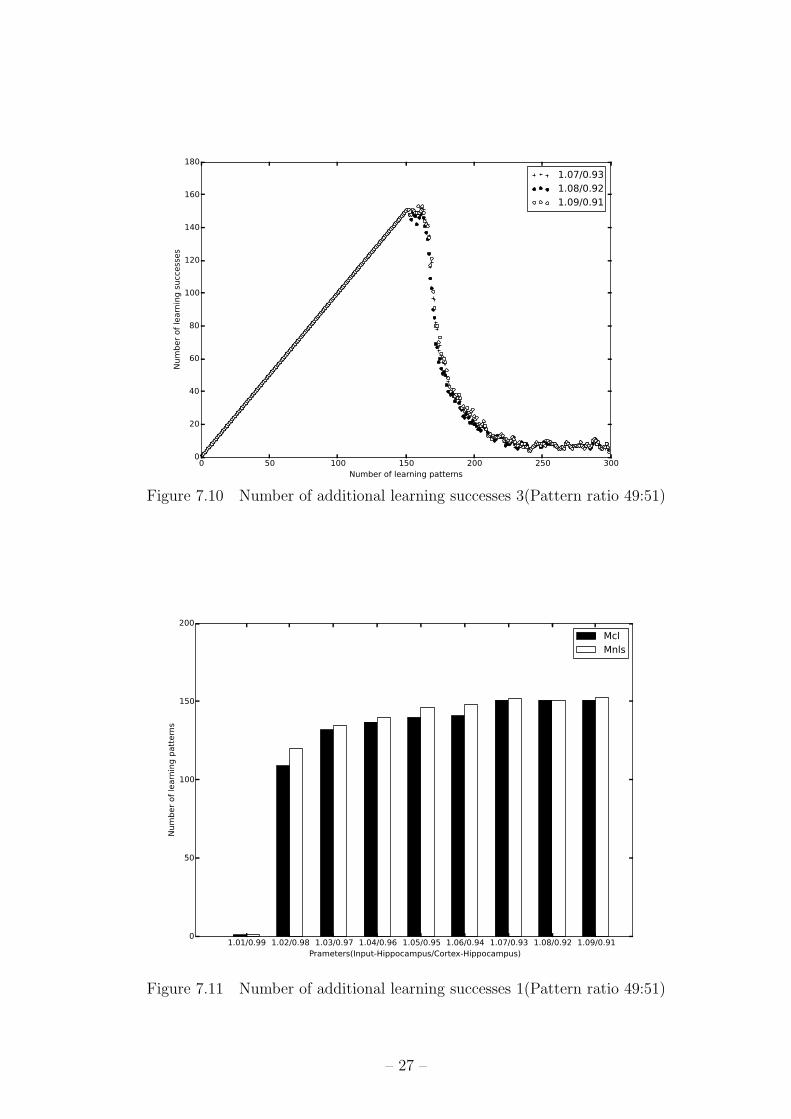
Figure 7.10 Number of additional learning successes 3(Pattern ratio 49:51)
Figure 7.11 Number of additional learning successes 1(Pattern ratio 49:51)
– 27 –

第8章 結論これまでの実験により、過去の研究で用いたカオスニューラルネットワークモデル 3)
において、入力層、海馬モジュール、連合野モジュールのうち、入力-連合野間の結合を
無くした場合のニューラルネットワークモデルの学習性能の特性を知ることができた。
過去の研究 13) に、学習データの素子数とその比率が学習結果に影響してくる性質が
述べられたものがあった。「実験 1」より、そのの研究のカオスニューラルネットワーク
モデルにおいて起こった学習パターンの素子数やその比率が学習結果に影響する、とい
う性質が今回のネットワークモデルにおいても同様の現象が発生することがわかった。
この現象については過去の研究論文でも述べられているが、基本的に今までの研究の中
で、カオスニューラルネットワークモデルの完全学習数は入力される学習素子の数の約
1.5倍程度になるとの結果が出ている。これは「実験 2」からもわかる通り、完全学習数
は今回の素子数が 100の 1.5倍、約 150パターン前後が最大となっている。しかし、学習
パターン素子の比率が 1:1となる場合、学習能力が落ちず 300パターンの完全学習がで
きている。これは理論上の完全学習数 150に到達する前に 1:1の比率の学習が完了して
いたためであると考えられる。また、今回の結果では過去の研究 13)とは異なり、素子数
100時の学習において、最後まで学習能力が低下することなく 300パターンまでの完全
学習を終えることができており、今回のようなネットワークモデルの場合、全パターン
完全学習における学習性能が向上している可能性が考えられる。
「実験 2」は今回の研究の目的である、「入力-海馬 (以下、i-hと略)、連合野-海馬 (以
下、c-hと略)の結合定数を変化させた時の学習性能」についての調査である。「実験 1」
より、今回使用するカオスニューラルネットワークモデルにおいても学習パターン素子
の比率が学習結果に大きな影響を及ぼすと考えられた為、「実験 2」では学習パターンの
比率を変化させ、「49:51」の比率の条件のもとで、i-hと c-hの和が一定になるようパラ
メータを変化させ調べた。結果として、「i-h=2.0/c-h=0.0」である時、つまり一方向の
みのフィードバックなしである3層型カオスニューラルネットワークモデルであるとき、
最大学習数、最多学習成功数共に最大となり、c-hの比率が増えていくに従って最大学習
数と最多学習成功数は減少していくことがわかった。またその現象の仕方についても、
比例的な変化ではなく対数的な変化であり、「i-h=1.0:c-h=1.0」から「i-h=1.1:c-h=0.9」
までの間で特に大きく変化していることがわかった。また、「i-hより c-hの方が大きい」
– 28 –

パラメータパターンでは全く学習できないこともわかった。
以上のことから、入力層、海馬モジュール、連合野モジュールで構成される本カオス
ニューラルネットワークモデルにおいて、入力ー連合野間の結合を無くした場合の学習
性能は、学習パターンの素子比率が 1:1である場合においては学習性能の向上の可能性
が見られ、それ以外の比率においては最大でも3層型カオスニューラルネットワークモ
デルと同等程度、パラメータを変えると学習性能が低下していくことがわかった。
今後の研究では他の比率における学習結果への影響 13)の再現性、結合定数パラメー
タ、ニューロンの状態式と学習結果の関係、その他のパラメータの変更による学習性能
への影響などについて調べる必要がある。
学習性能評価の指標として今回は、学習パターン数と学習成功パターン数が完全に一
致する「完全学習数」と、学習終了までの間での学習成功パターン数の最大値である「最
多学習成功数」の二つを使用した。これらを元に性能の評価をしたが、それ以外の評価
法による結果の変化も考えられる。
– 29 –

第9章 謝辞最後に、本研究において一年間多大なご指導をしていただいた出口利憲先生に深く感
謝いたします。また、同研究室において共に研究を協力してくれた船橋聡太氏、稲垣天
斗氏、竹中一生氏に感謝の意を表します。
– 30 –

参考文献1) 中野馨: ニューロコンピュータの基礎, コロナ社 (1990)
2) 合原一幸: ニューロ・ファジィ・カオス, オーム社 (1993)
3) 梅田尭英:カオスニューラルネットワークにおける逐次学習の多層化に関する研究,
岐阜工業高等専門学校電気情報工学科卒業論文 (2016)
4) Ian・Stewart: カオス的世界像, 白揚社 (1992)
5) 合原一幸: ニューラルネットワークにおけるカオス, 東京電機大学出版局 (1993)
6) 家入 悠至 カオスニューラルネットによる逐次学習を用いた動的想起に関する研究,
岐阜工業高等専門学校電気情報工学科卒業論文 (2005)
7) 平野廣美 : Cでつくるニューラルネットワーク, パーソナルメディア (2003)
8) M.A.アービブ : ニューラルネットと脳理論,サイエンス社 (1992)
9) 吉富康成: ニューラルネットワーク, 朝倉書店 (2002)
10) 浅川新也: カオスニューラルネットによる未知パターンの学習, 岐阜工業高等専門
学校専攻科電子システム工学専攻特別研究報告 (2000)
11) 伊藤真,三宅章吾,猪苗代盛,黒岩丈介,沢田康次: 海馬-連合野モデルによる時系列パ
ターンの長期記憶形成, 電子情報通信学会技術研究報告, NLP2000-18 / NC2000-12
(2000)
12) 江本伸悟, 淺間一, 大武美保子: 逐次学習可能な多層カオスニューラルネットワーク
を用いた長期記憶形成, 電子情報通信学会技術研究報告, NC2007-113 (2008)
13) 坂井菜月:逐次学習における学習パターンの影響に関する研究,岐阜工業高等専門学
校電気情報工学科卒業論文 (2015)
14) Brenda Milner, Suzanne Corkin, H. L. Teuber: Further analysis if the hippocampal
amnesic syndrome, 14-year follow-up study of h.m. Neuropsychologia, Vol.6, pp-
215-234 (1968)
– 31 –