autonomic sla-driven provisioning for cloud applications nicolas bonvin, thanasis papaioannou, karl...
TRANSCRIPT

Autonomic SLA-drivenProvisioning for CloudApplications
Nicolas Bonvin, Thanasis Papaioannou, Karl Aberer
Presented by Ismail Alan

●This paper discusses an economic approach to managing cloud resources for individual applications based on established Service Level Agreements (SLA).
●The approach attempts to mitigate the impact (to individual applications) of varying loads and random failures within the cloud.
About the Paper
●A distributed, component-based application running on an elasticinfrastructure
Cloud Apps – Issue #1 : Placement
2
C1C2 C3 C4

●A distributed, component-based application running on an elasticinfrastructure
Cloud Apps – Issue #1 : Placement
3
C2
VM1
C3
VM2
C4
VM3
C1
●
●
●
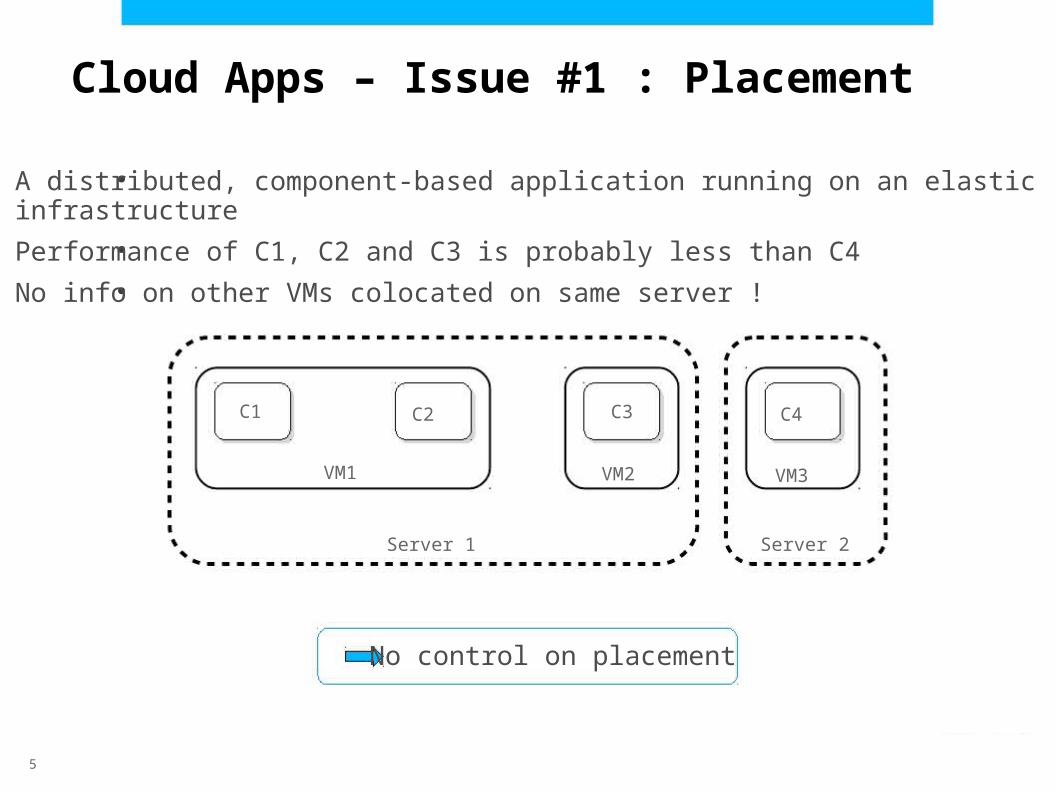
A distributed, component-based application running on an elasticinfrastructure
Performance of C1, C2 and C3 is probably less than C4
No info on other VMs colocated on same server !
Cloud Apps – Issue #1 : Placement
5
No control on placement
C3
VM2
C4
VM3
Server 2
C1 C2
Server 1
VM1
●Load-balanced traffic to 4 identical components on 4 identical VMs
Cloud Apps – Issue #2 : Unstability
6
C1
VM2
100 ms
C1
VM3
100 ms
C1
VM4
100 ms
C1
VM1
100 ms
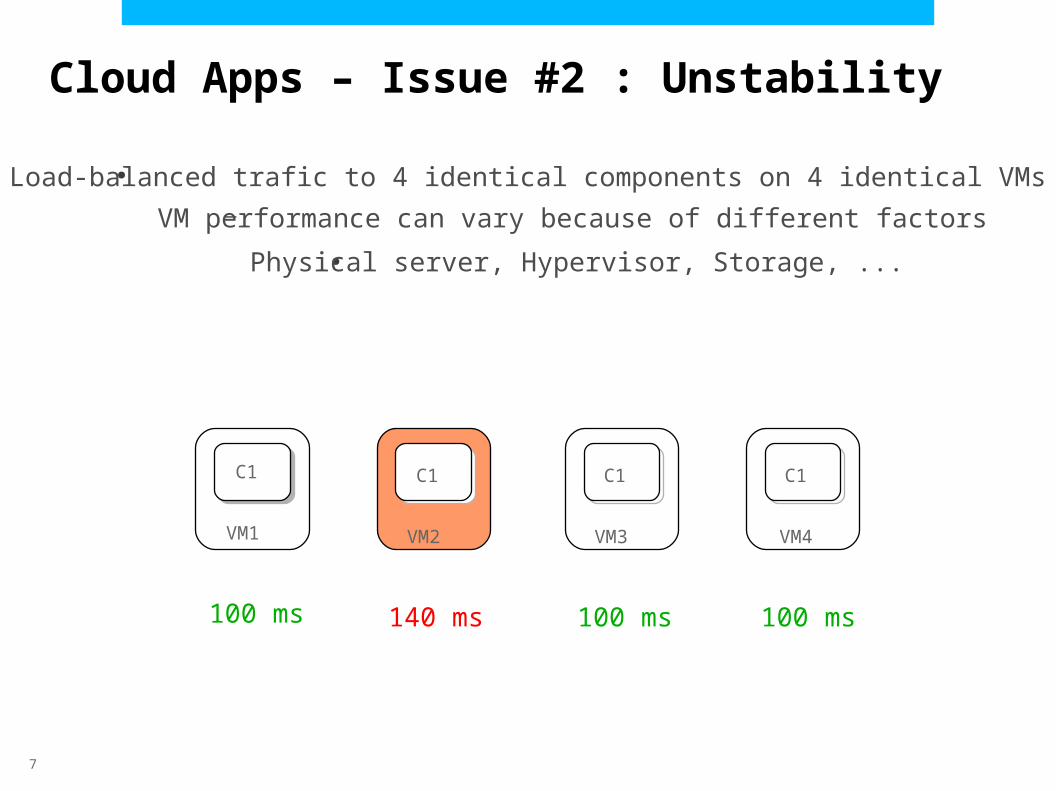
●Load-balanced trafic to 4 identical components on 4 identical VMs–VM performance can vary because of different factors
●Physical server, Hypervisor, Storage, ...
Cloud Apps – Issue #2 : Unstability
7
C1
VM2
140 ms
C1
VM3
100 ms
C1
VM4
100 ms
C1
VM1
100 ms
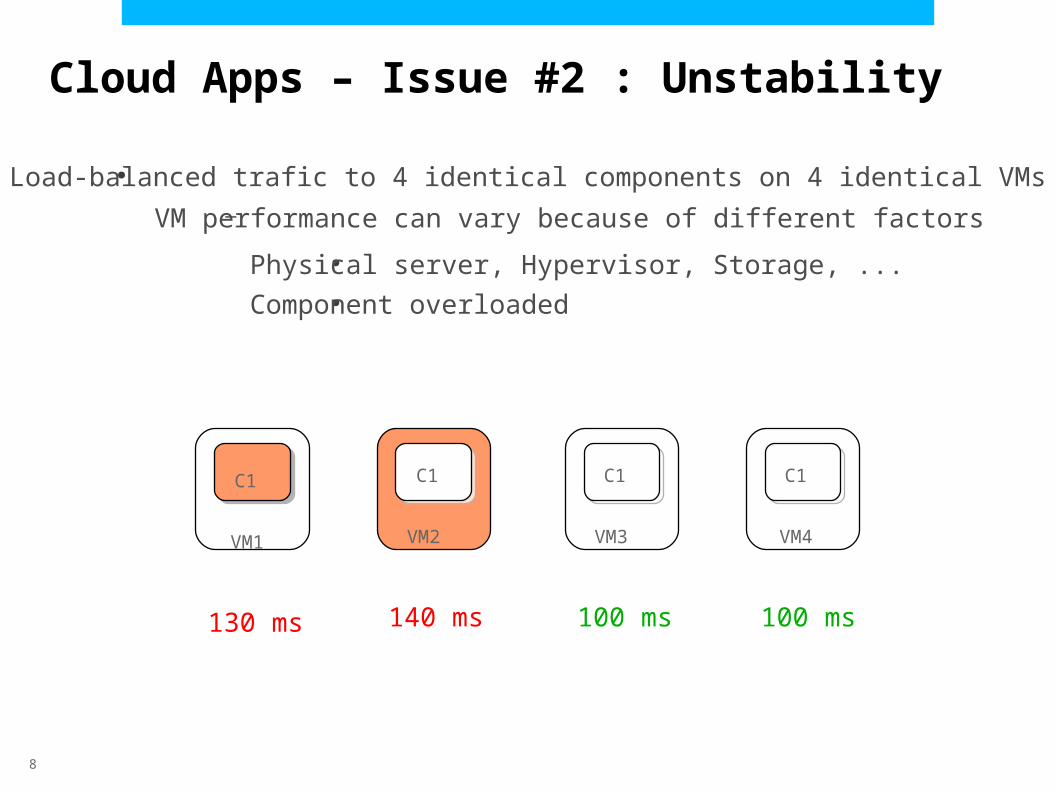
●Load-balanced trafic to 4 identical components on 4 identical VMs–VM performance can vary because of different factors
●
●
Physical server, Hypervisor, Storage, ...
Component overloaded
Cloud Apps – Issue #2 : Unstability
8
C1
VM1
130 ms
C1
VM2
140 ms
C1
VM3
100 ms
C1
VM4
100 ms
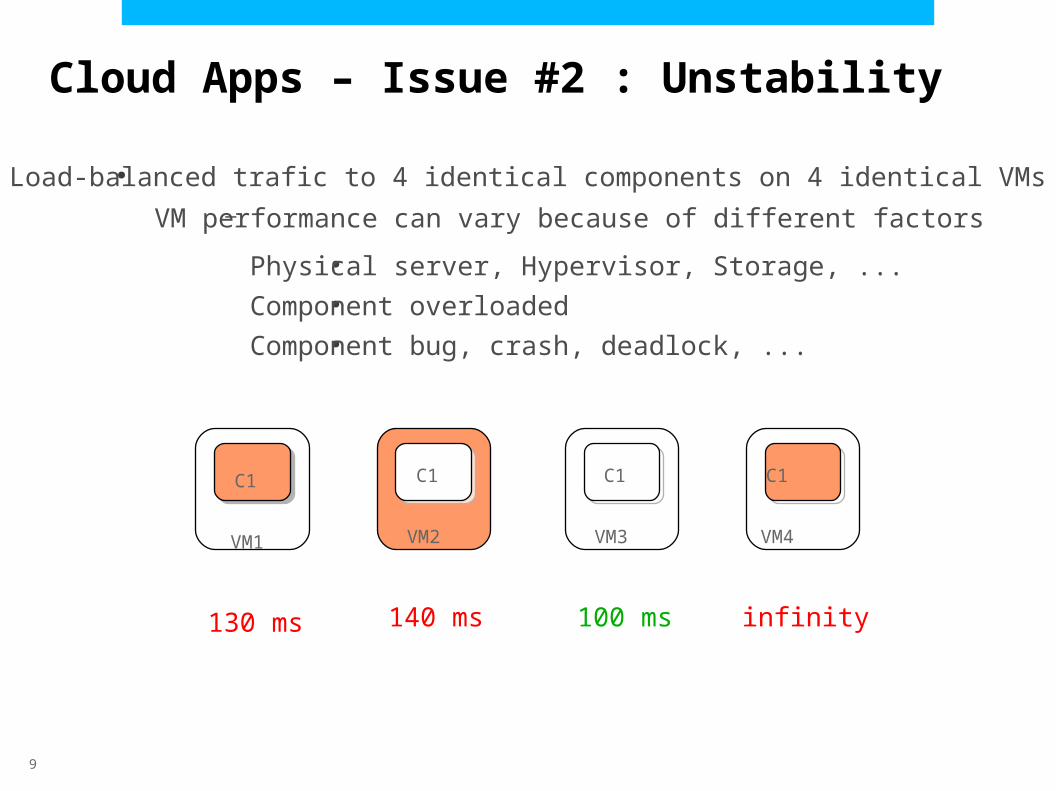
●Load-balanced trafic to 4 identical components on 4 identical VMs–VM performance can vary because of different factors
●
●
●
Physical server, Hypervisor, Storage, ...
Component overloaded
Component bug, crash, deadlock, ...
Cloud Apps – Issue #2 : Unstability
9
C1
VM1
130 ms
C1
VM2
140 ms
C1
VM3
100 ms
C1
VM4
infinity
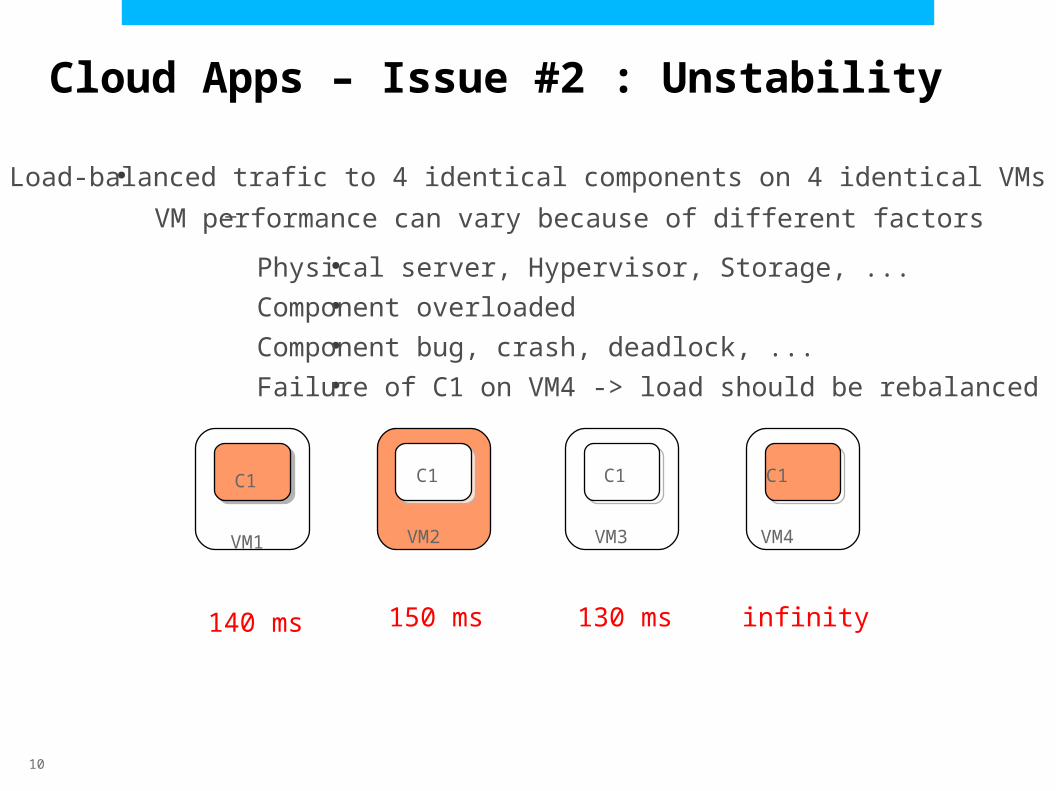
●Load-balanced trafic to 4 identical components on 4 identical VMs–VM performance can vary because of different factors
●
●
●
●
Physical server, Hypervisor, Storage, ...
Component overloaded
Component bug, crash, deadlock, ...
Failure of C1 on VM4 -> load should be rebalanced
Cloud Apps – Issue #2 : Unstability
10
C1
VM1
140 ms
C1
VM2
150 ms
C1
VM3
130 ms
C1
VM4
infinity
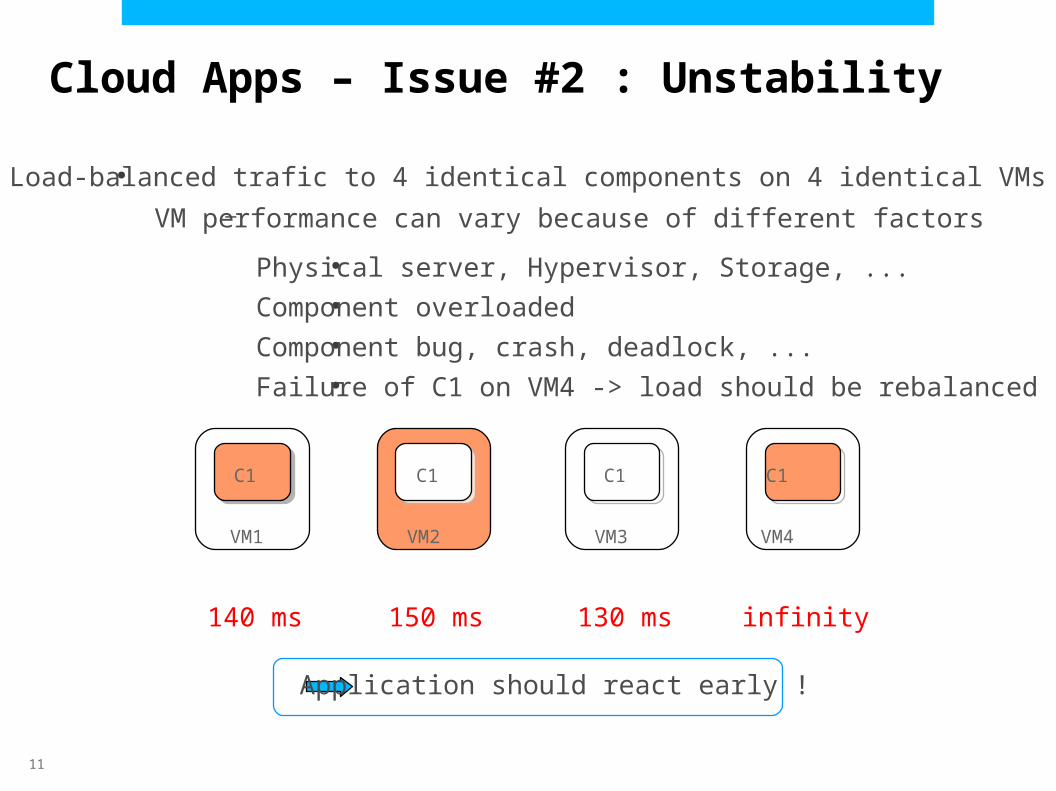
●Load-balanced trafic to 4 identical components on 4 identical VMs–VM performance can vary because of different factors
●
●
●
●
Physical server, Hypervisor, Storage, ...
Component overloaded
Component bug, crash, deadlock, ...
Failure of C1 on VM4 -> load should be rebalanced
Cloud Apps – Issue #2 : Unstability
11
C1
VM1
140 ms
C1
VM2
150 ms
C1
VM3
130 ms
C1
VM4
infinity
Application should react early !

● Build for failures–
–
Do not trust the underlying infrastructure
Do not trust your components either !●Components should adapt to the changing conditions
–
–
–
Quickly
Automatically
e.g. by replacing a wonky VM by a new one
Cloud Apps – Overview
12

Scarce:a framework to build scalable cloud applications
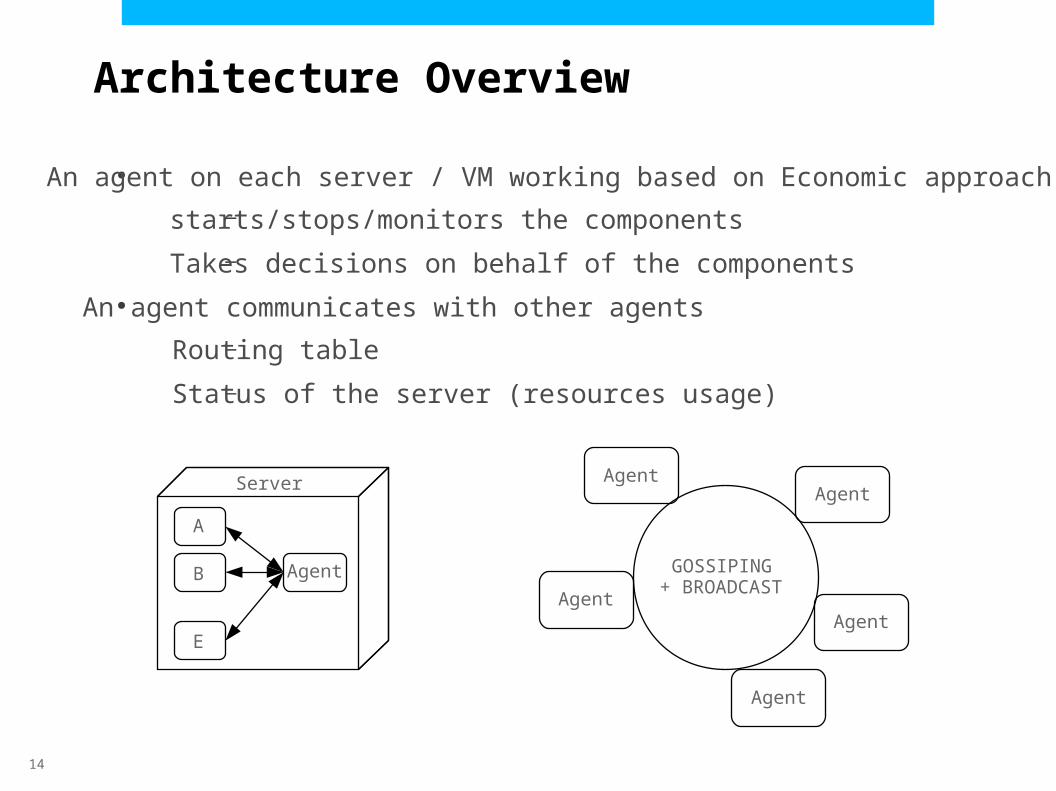
Architecture Overview
14
Agent
Server
GOSSIPING+ BROADCAST
Agent
A
B
E
●An agent on each server / VM working based on Economic approach–
–
starts/stops/monitors the components
Takes decisions on behalf of the components●An agent communicates with other agents
–
–
Routing table
Status of the server (resources usage)
Agent
Agent
Agent
Agent

An economic approach
15
●
●
Time is split into epochs
At each epoch servers charge a virtual rent for hosting a component
according to–
–
–
Current resource usage (I/O, CPU, ...) of the server
Technical factors (HW, connectivity, ...)
Non-technical factors (location)

An economic approach
16
● Components–
–
–
Pay virtual rent at each epoch
Gain virtual money by processing requests
Take decisions based on balance ( = gain – rent )●Replicate, migrate, suicide, stay
●Virtual rents are updated by gossiping (no centralized board)
●
●
Time is split into epochs
At each epoch servers charge a virtual rent for hosting a component
according to–
–
–
Current resource usage (I/O, CPU, ...) of the server
Technical factors (HW, connectivity, ...)
Non-technical factors (location)

Economic model (i)
17
Balance of the component
Utility of component
Usage % of the server resources by component c
Migration threshold
Rent paid by component

Economic model (ii)
18
●Based on the negative balance a component may migrate or stop
Calculate the availability
If satisfactory, the component stops.
Otherwise, try to find a less expensive server.
●Based on the positive balance a component may replicate
Verify that can afford replication
If it can afford replication for consecutive epochs, replicate
Otherwise, continue to run.

Economic model (iii)
19
●Choosing a candidate server j during replication/migration of acomponent i
netbenefit maximization
● 2 optimization goals :
high-availability by geographical diversity of replicas
low latency by grouping related components
●
●
gj : weight related to the proximity of the server location to thegeographical distribution of the client requests to the component
Si is the set of server hosting a replica of component I
Diversity function returns geographical distance among each server pair.●
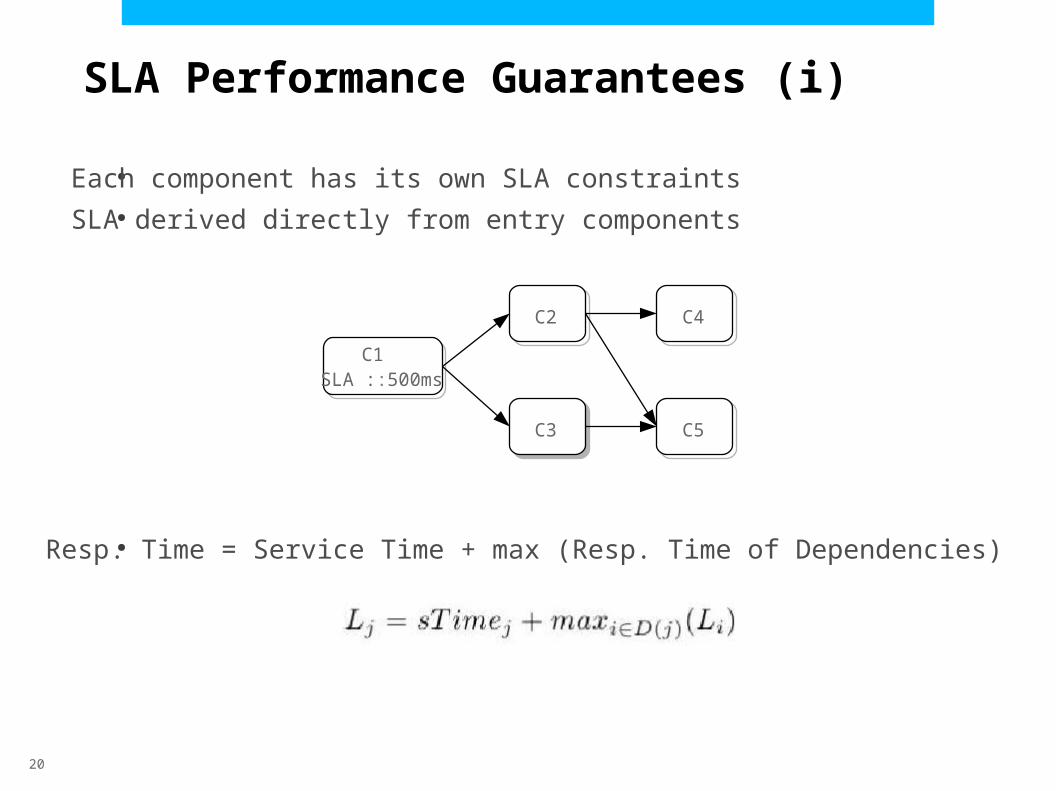
SLA Performance Guarantees (i)
20
●
●
Each component has its own SLA constraints
SLA derived directly from entry components
●Resp. Time = Service Time + max (Resp. Time of Dependencies)
C1SLA ::500ms
C2
C3
C4
C5

SLA Performance Guarantees (ii)
21
●
●
●
●
SLA propagation from parents to children
Parent j sends its performance constraints (e.g. response time upperbound) to its dependencies D(j) :
Child i computes its own performance constraints :
: group of constraints sent by the replicas of the parent g
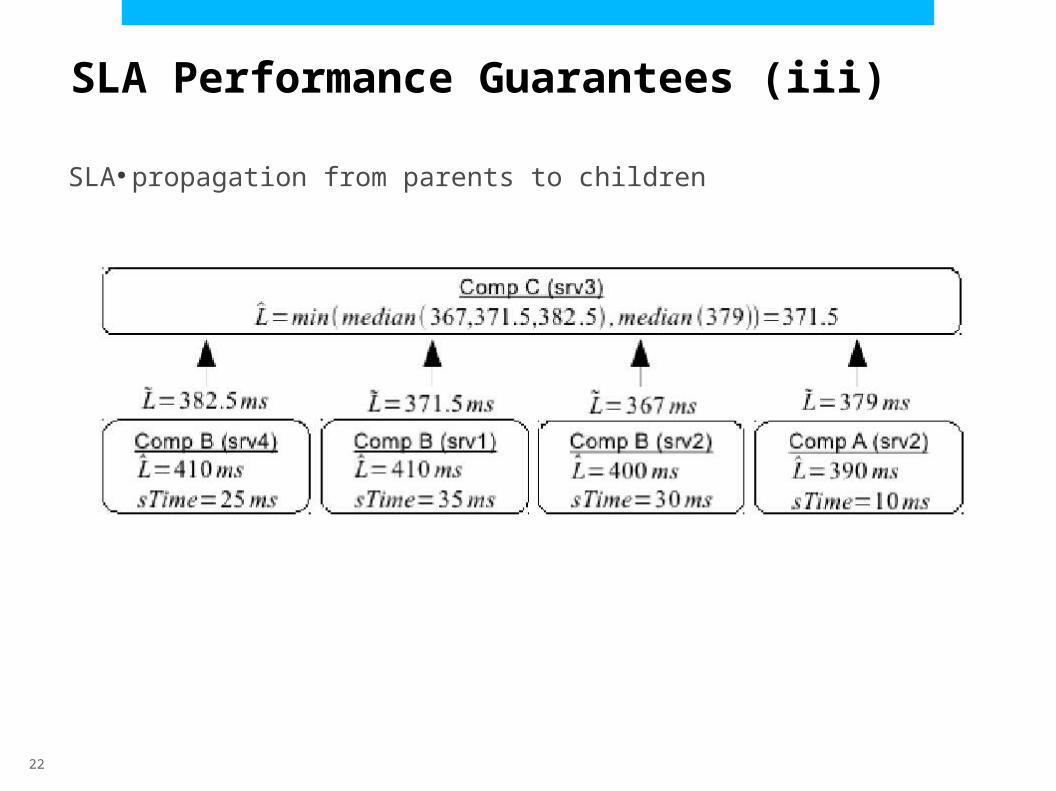
SLA Performance Guarantees (iii)
22
●SLA propagation from parents to children

Automatic Provisioning
23
●Usage of allocated resources is maximized :–
–
autonomic migration / replication / suicide of components
not enough to ensure end-to-end response time
●Each individual component has to satisfy its own SLA–
–
SLA easily met -> decrease resources (scale down)
SLA not met -> increase resources (scale up, scale out)
● Cloud resources managed by framework via cloud API

Adaptivity to slow servers
24
●Each component keeps statistics about its children–e.g. 95th perc. response time
●A routing coefficient is computed for each child at each epoch–Send more requests to more performant children

Evaluation
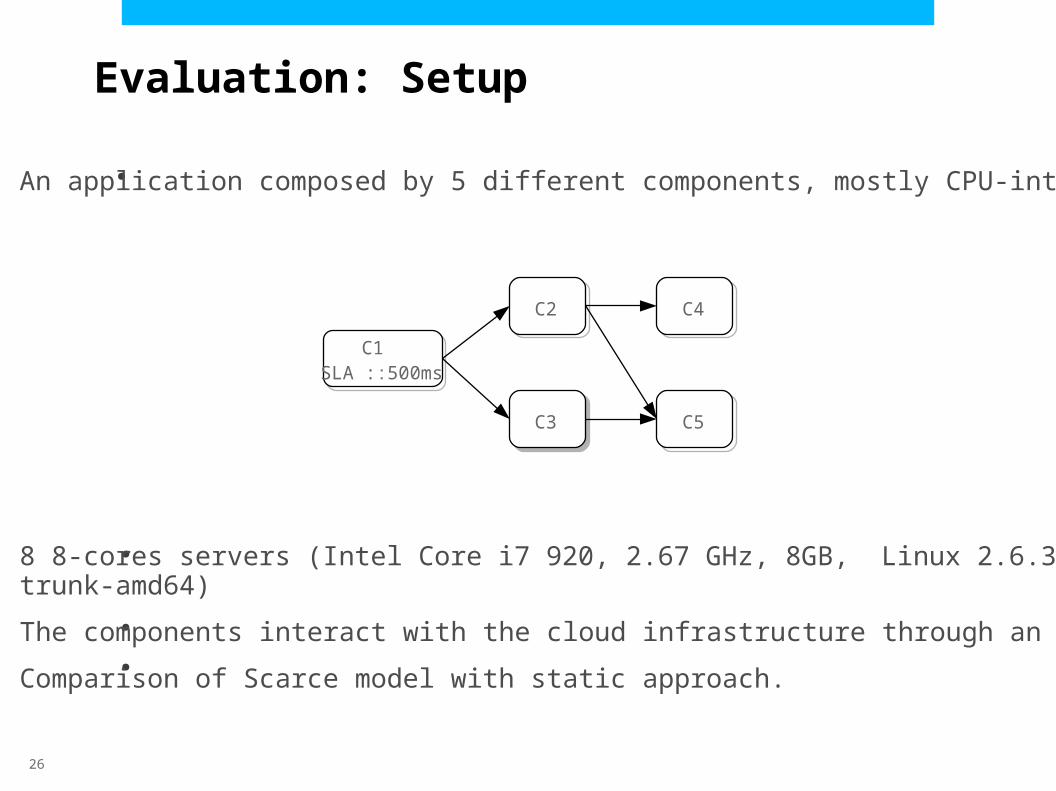
Evaluation: Setup
26
●An application composed by 5 different components, mostly CPU-intensive
●
●
●
8 8-cores servers (Intel Core i7 920, 2.67 GHz, 8GB, Linux 2.6.32-trunk-amd64)
The components interact with the cloud infrastructure through an API
Comparison of Scarce model with static approach.
C1SLA ::500ms
C2
C3
C4
C5
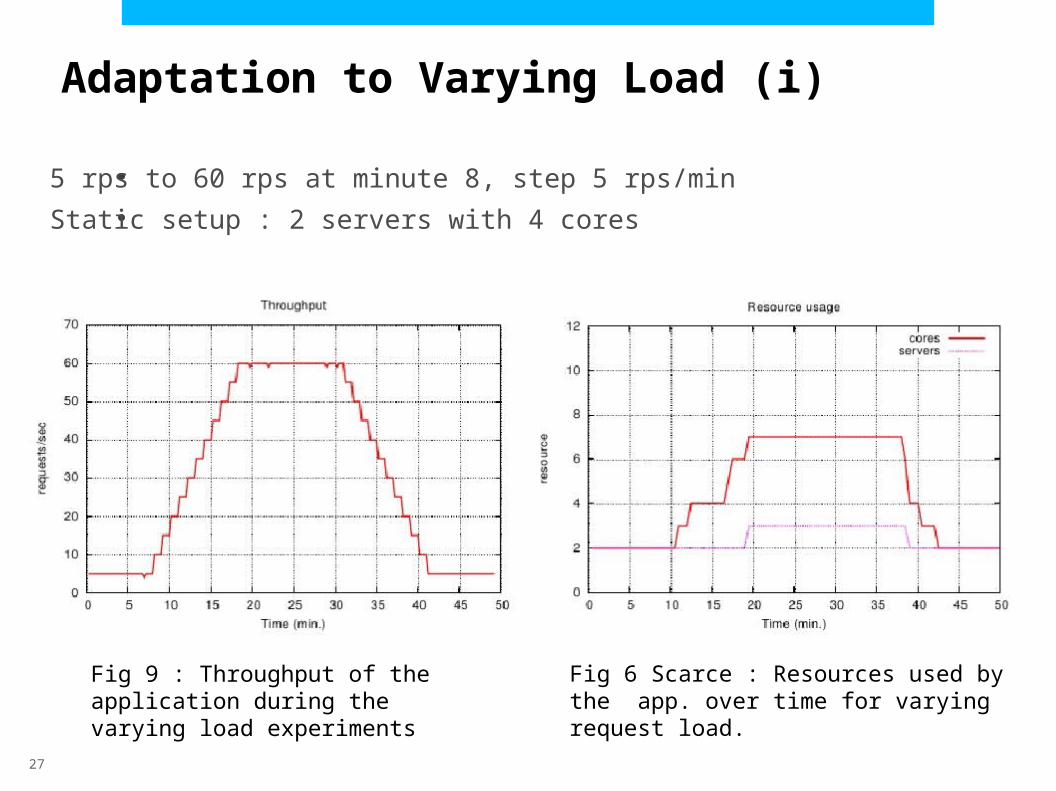
Adaptation to Varying Load (i)
27
●
●
5 rps to 60 rps at minute 8, step 5 rps/min
Static setup : 2 servers with 4 cores
Fig 9 : Throughput of the application during the varying load experiments
Fig 6 Scarce : Resources used by the app. over time for varying request load.
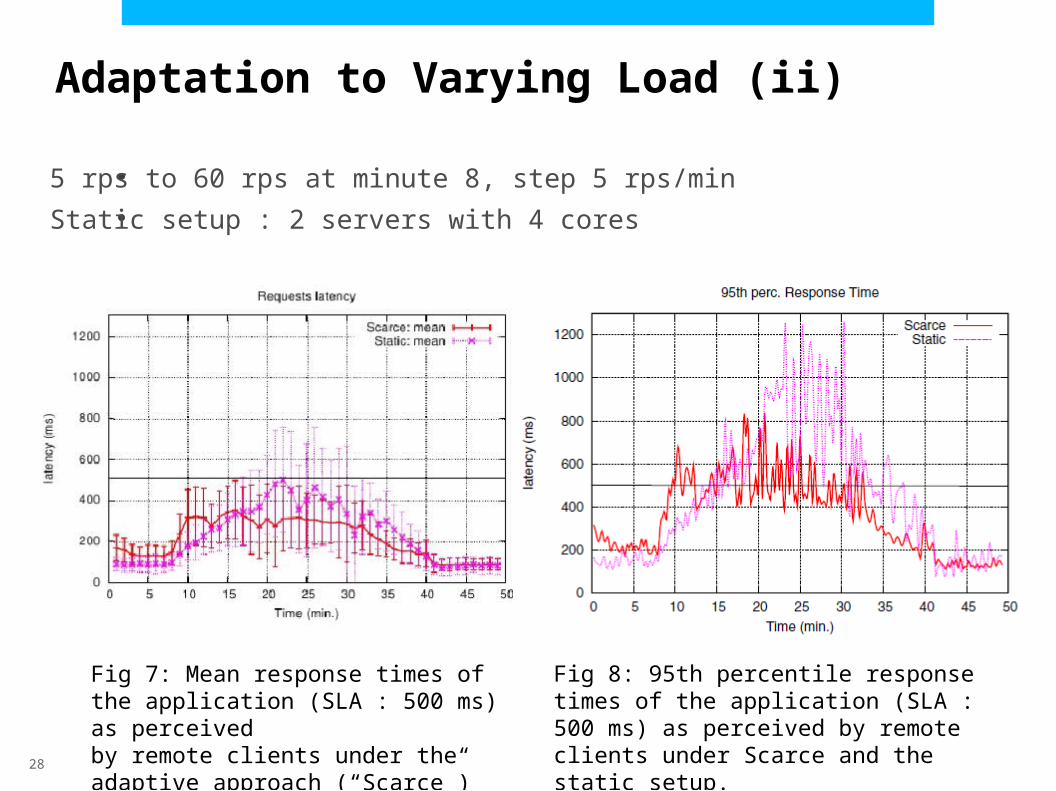
Adaptation to Varying Load (ii)
28
●
●
5 rps to 60 rps at minute 8, step 5 rps/min
Static setup : 2 servers with 4 cores
Fig 7: Mean response times of the application (SLA : 500 ms) as perceivedby remote clients under the adaptive approach (“Scarce”) and the static setup.
Fig 8: 95th percentile response times of the application (SLA : 500 ms) as perceived by remote clients under Scarce and the static setup.
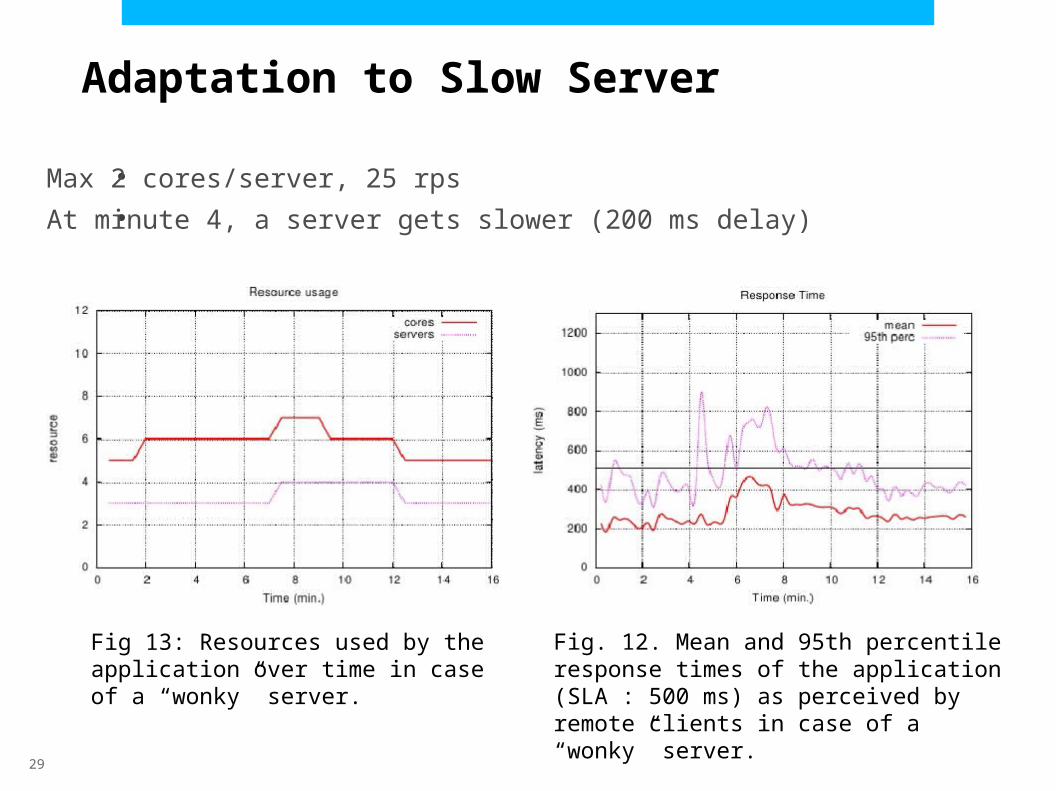
Adaptation to Slow Server
29
●
●
Max 2 cores/server, 25 rps
At minute 4, a server gets slower (200 ms delay)
Fig 13: Resources used by the application over time in case of a “wonky” server.
Fig. 12. Mean and 95th percentile response times of the application (SLA : 500 ms) as perceived by remote clients in case of a “wonky” server.

Scalability
30
●
●
Add 5 rps
per minute until 150 rps
Max 6 cores/server
Fig 14: Mean and 95th percentile response times of the application (SLA:500ms) as perceived by remote clients in the scalability experiment.
Fig 16: Resources used by the application over time during the scalability experiment.
Fig 15: Scarce : Throughput of the application during the scalability experiment.

Conclusion

Conclusion
32
●
●
●
●
Framework for building cloud applications
Elasticity : add/remove resources
High Availability : software, hardware, network failures
Scalability : growing load, peaks, scaling down, ...–Quick replication of busy components
●Load Balancing : load has to be shared by all available servers
–
–
–
Replication of busy components
Migration of less busy components
Reach equilibrium when load is stable●SLA performance guarantees
–Automatic provisioning●No synchronization, fully decentralized

Thank you !