biosignature-based drug design2018/10/19 · virtual biosignature fusion l1000(20k set, only)...
TRANSCRIPT

Biosignature-Based Drug Design
Joerg Kurt Wegner | 2018-10-19 | Montreal, Canada
Can Machine Learning enable a re-use of Large-Scalemultivariate data across novel Drug Design projects?
References https://goo.gl/HwEPQt
8th annual RQRM Symposium

For finding a new drug for a disease we need to rationalize at least two data challenges, actually we need to combine them for being efficient.
2
Drug space and assay data Patient data
Nitril+CarbocylicAcid 3 million compounds (80% success rate)Amine+Aldehyde 2 million compounds (81% success rate)…
Billions of compound, which to test?Which data will be created for which task?
What do we know about a patient?Which data will be created for which task?

Task: Use Machine Learning to help deciding what to connect and decide which part of a “healthy vs diseased” biosignature is most informative? Then connect biosignature treatment by choosing or creating perturbations (compounds, biologicals, functional genomics).
3
Patient with disease vs healthy
Imaging
Healthy Diseased
What to connect?Which data to create?

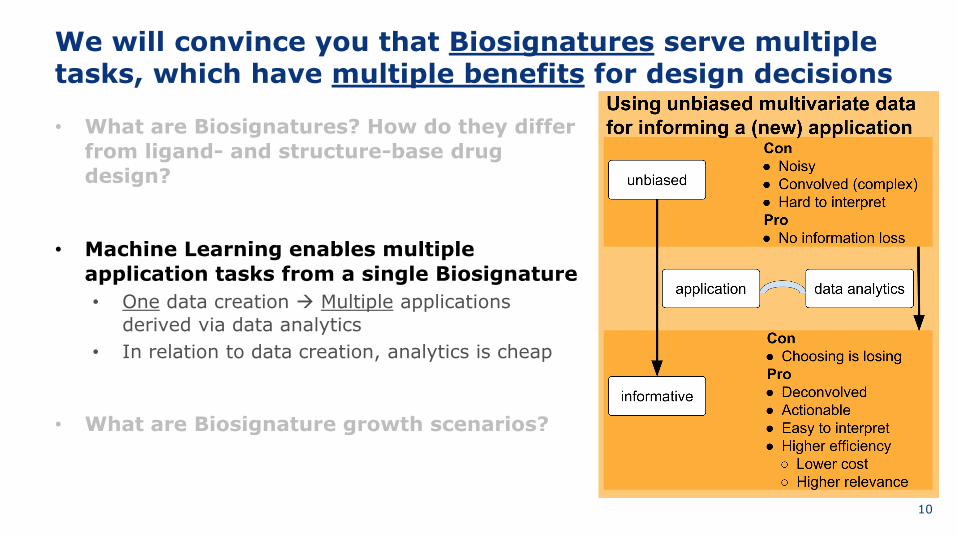
We will convince you that Biosignatures serve multiple tasks, which have multiple benefits for design decisions
• What are Biosignatures? How do they differ from ligand-and structure-base drug design?
• Machine Learning enables multiple application tasks from a single Biosignature• One data creation Multiple applications derived via data analytics• In relation to data creation, analytics is cheap
• What are Biosignature growth scenarios?
4

Biosignatures are complementing other design conceptsWe use more than 100 thousands biosignatures per technology
Ligand-Based Drug Design
(Protein) Structure-Based Drug Design
Biosignature-Based Drug Design
HCI (cell line – H4) 460,000HCI (cell line – Hepg2) 724,000HCI (patient samples - PHH) 175,000L1000 (cell line – MCF7) 237,000L1000 (patient samples - PBMC) 201,000Data fusion (Factorization) 458,000Data fusion (DeepLearning) 456,000Data fusion (LargeScale) 2,798,000
Biggest public data ~20, 000
Substructure fingerprint Interaction fingerprint (Rich) Pharmacological fingerprint
compounds

Biochemical assaySingle target
Single EndpointCellular
Single Endpoint
A metastudy on imaging data showed that 80% of publications are using only one feature (very traditional single endpoint assay)
Cellular (high-content)Multivariate Biosignature
14 days on 16 compute nodes (each with 24 cores), 30 TB per 500k compound image screen
Unpublished, now possible in 45 hours

Biosignature-Based Drug Design (BBDD)?
7
A Biosignature is capturing a multivariate response of a perturbed biological system or set of biological systems.
An Observation is a single marker in such a response space.
BBDD BBDD Pro BBDD Con
LBDD • Direct disease2compound mapping• Complementing design capacity• Enriching design capacity• Leveraging across projects
Multivariate analytics
SBDD No XRay needed
Applies for SBDD, too

How does BBDD differ from ligand- and structure-base drug design?
BBDD perspective under revision @JMedChem~200 references vouching for it
8
Leverage insights across conditions, and technology is a condition…
Improving inhibitor potency for a single protein target might not be good enough
Observing a disease relevance by an -omics tech in one biological system might not be good enough
Believing the same data analytics process will work again might not be good enough

Traditional biosignatures have been published without consolidating commonalities of a BBDD drug design paradigm
9
Assay endpoint biosignatures (#observations » 30)Hit enrichment• HTS-FP compound expansion proves more efficient than chemical structure-based methods
in terms of retrieving active compounds and diverse scaffolds.Compound MOA identification• NCI-60 cancer cell panel tubulin mitotic spindle interference• JFCR-39 cancer cell panel (1) telomerase compounds, and (2) PI3K inhibitor. • Cerep BioPrint phospholipid binders without putative target CYP51 in biosignature• BioMAPmitochondrial dysfunction, cAMP elevators, tubulin inhibitors, inducers of
endoplasmic reticulum stress, or NFκB pathway inhibitorsTranscript-omics biosignatures • A reduced gene biosignature is sufficient to categorize B-Cell Lymphoma patients after drug
treatment (Microarray Quantigene AI, cost efficiency)
We will convince you that Biosignatures serve multiple tasks, which have multiple benefits for design decisions
• What are Biosignatures? How do they differ from ligand- and structure-base drug design?
• Machine Learning enables multiple application tasks from a single Biosignature• One data creation Multiple applications
derived via data analytics• In relation to data creation, analytics is cheap
• What are Biosignature growth scenarios?
10

Large-scale machine learning for translating high-dimensional biological responses into drug design decisionson –omics biosignatures
11
Assay endpoint biosignatures (#observations » 30)• Cancer cell line panel (Sanger Institute) enables a
patient-centric quantitative personalized estimate for drug sensitivity, since it can estimate on novel cell lines.
Transcript-omics biosignatures • Hit rate increase of 300-fold for NR3C1, by also depleting unwanted HSP90 activity.
Our case study. Published.Phen-omics: High-content imaging biosignatures • Identify a subset of genes, including the tumor suppressor PTEN, which regulate a cell shape
in both mouse and human metastatic melanoma cells.• 50- to 250-fold hit rate increase with multiple novel Murcko scaffolds compared to previous
HTS hits. Our case study. Published. (15TB of data, four weeks on 1000 core CPU cluster)

HDAC
PLK
PI3K-mTOR
BRD
Unsupervised biosignatures and similarities are ok, and can be improved via supervision
mTOR-PI3KCDK
HSP90HDAC
HDAC
Tubulin
AR
DMSO Control
t-distributed Stochastic Neighbor Embedding
kNN, single biosignature
unsupervisedbiosignature
single vs fusedbiosignatures
unsupervisedbiosignature

Our imaging case study. Analytics is key!
13
ABCD Janssen
ChEMBL
Inactiveat concetration X
Activeat concetration X
1000s of assays
millions of compounds
~100 million data points
Analytics? Artificial Intelligence?Which projects can we support?Should we create more data?

14
CellProfilerMacau
CellProfilerDeepLearning
ImageDeepLearning
AUC > 0.931
AUC > 0.7218
AUC > 0.943
AUC > 0.7245
CellProfilerkNN
AUC > 0.90
AUC > 0.793
AUC > 0.9(58)ongoing
AUC > 0.7(373)ongoing
ActiveInactiveUnknown
Transfer learningof a noise reduced biosignature to other challenges
unsupervisedbiosignature
supervisedbiosignature
GR Translocation screen in H4 cells
2 h compound incubationfor NS/Mood
460K compounds
Our imaging case study. Analytics is key!

many vacuoles
no vacuolesfew vacuoles
0.3 uM
1 uM
9 uM
LO project with biosignature profiling indicates concentration dependent toxicity on top of wanted activity

Large-scale machine learning for translating high-dimensional biological responses into drug design decisionson virtual biosignatures
16
• NCI-DREAM challenge46 teams, one wins!
• Screening only 10% of the screening collection 50% of hits are found.
• Our case studies. Published. Prospective applications to be submitted.
Virtual biosignatures (#observations » 30)

Single compound enrichment: Can we find more kinase inhibitors for two known reference compounds with XRay data? Yes!
HCI1:DeepLearning machine learningVirtual biosignature fusion
L1000(20k set, only)
Docking
L1000(20k set, only) inverse query
BED-
ROC
Percentage screened(single compounds)
0.5
0 10 30 50
Transcriptomics biosignature query based on MicroArray’s (a 22,000 gene transcript biosignature) after compound perturbation

Plate compound hit enrichment Can we enrich hits more consistently over 40 HTS initiatives?
biosignaturemix
tanimoto
diversityrandom
Screened non-pilot (non-seeding) plates [%]
New unique chemical clusters [%]New chemical starting points [%]
Non-Incremental screening using
plate enrichment using information from a pilot screening deck

We will convince you that Biosignatures serve multiple tasks, which have multiple benefits for design decisions
• What are Biosignatures? How do they differ from ligand-and structure-base drug design?
• Machine Learning enables multiple application tasks from a single Biosignature• One data creation Multiple applications derived via data analytics• In relation to data creation, analytics is cheap
• What are Biosignature growth scenarios?
19

Combining multiple large-scale imaging biosignatures is improving scientific accuracy.
20Our case study. Published.

We expect that biosignatures keep growing exponentially
21
BBDD perspective under revision @JMedChem

We expect that biosignatures keep growing exponentially
22
Technology advancement (<cost)Machine learning

BBDD enables to
Unique concept for BBDD
• employ a gene signature compound search, which is a BBDD unique design concept not existing for LBDD and SBDD.
• an imaging single cell population analytics being a BBDD unique design concept.
Exceeds compare to LBDD and SBDD
• exceeded a hit expansion compared to a LBDD (or SBDD) leading to a higher number of hits and to a higher number of novel scaffolds.
• exceed the performance of individual data sources, like 2D or 3D drug descriptors or transcriptomics microarrays
• estimate a drug sensitivity prediction for novel cell lines. 23

We have convinced you that BBDD is complementing or enriching as design concept, andthat multivariate data analytics skills are key.
Questions?
Referenceshttps://goo.gl/HwEPQt
24

Backup – Just in case the discussion requires it
25

26Single compound enrichment.A biosignature expansion yields 6-80 fold enrichments in novel and diverse hits
Onco1 IDV1 IDV2 CNS2(primary, only)
Biosignature fusionMacau fusion HCI:H4max(fusion1,fusion2)HCI:A549 clustering + fusion1 RF fusion on L1000max(fusion1,fusion5)random
CNS1
11(127)
3(94)
0(21)
2(50)
6(97)
Novel Murcko scaffold, duplicate+(Novel singleton scaffolds)
Novel diverse chemical hits
(Chemical) analogs
Introduction – Applications - Conclusion

Multi-task learningexpands the applicability domain of models
overlapping chem space⇒ mutual assay information
assay X
assay Y
predict activity in Ybased on observations in X
predict activity in Xbased on observations in Y unimpressive at small
scale,awesome at massive scale

A model built in isolation needs 2 x more datapoints than one built together with other models to reach same performance
All our methods scale to all our data set sizes.
Multi-task learningtends to win from single-task (55% of cases); it never loses

A DeepLearning imaging fusion biosignature on correlating columns with activity and toxic endpoints is able to separate toxic from non-toxic compounds
Chemical structure mapping DeepLearning imaging fusion biosignature mapping
Size: target activityColor: toxicity
30
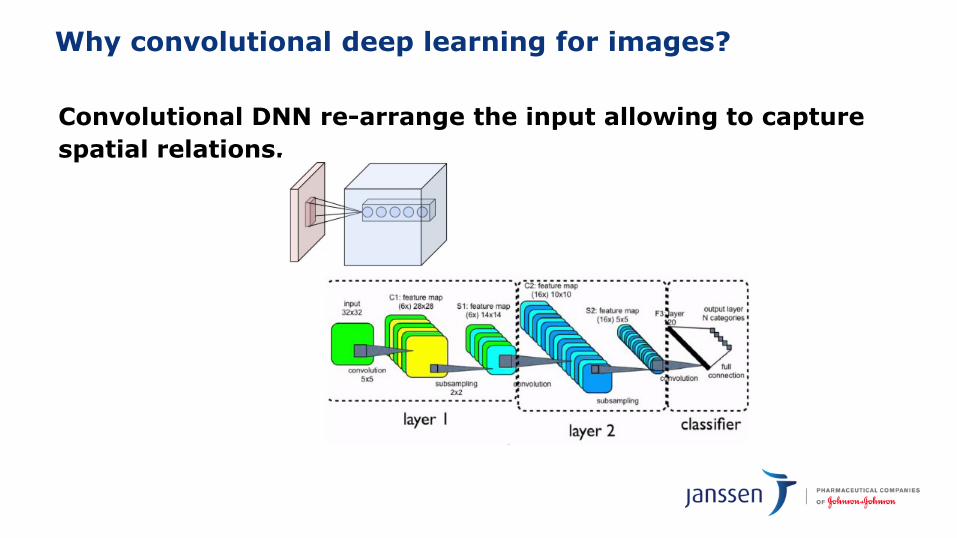
Why convolutional deep learning for images?
Convolutional DNN re-arrange the input allowing to capture spatial relations.


32
DeepTox

How does BBDD differ from ligand- and structure-base drug design?
BBDD perspective under revision @JMedChem~200 references vouching for it
33
Leverage insights across conditions, and technology is a condition…
All listed use-cases in the original articles show that BBDD outperforms or complements LBDD or SBDD paradigms