brescia dm 4 mlsupervised iiparte -...
TRANSCRIPT

Data Mining

Machine Learning & Statistical Models
M. Brescia - Data Mining - lezione 4 2
Neural
Networks
Feed Forward
Recurrent / Feedback
• Perceptron
• Multi Layer Perceptron
• Radial Basis Functions
• Competitive Networks
• Hopfield Networks
• Adaptive Reasoning Theory
• Bayesian Networks
• Hidden Markov Models
• Mixture of Gaussians
• Principal Probabilistic Surface
• Maximum Likelihood
• χ2
• Negentropy
Decision
Analysis
• Fuzzy Sets
• Genetic Algorithms
• K-Means
• Principal Component Analysis
• Support Vector Machine
• Soft ComputingStatistical
Models
• Decision Trees
• Random Decision Forests
• Evolving Trees
• Minimum Spanning TreesHybrid

Support Vector Machine
M. Brescia - Data Mining - lezione 4 3
Le Support vector machines (SVM) sono un insieme di metodi di apprendimento supervisionato che
possono essere utilizzati sia per classificazione sia per regressione. In un breve lasso temporale dalla loro
prima implementazione hanno trovato numerose applicazioni in vari settori scientifici come fisica, biologia,
chimica.
−preparazione di farmaci (discriminazione tra leganti e non leganti, inibitori e non inibitori, etc.)
−Ricerca di relazioni quantitative sulle attività di strutture (dove le SVM, utilizzate come regressori
sono usate per trovare varie proprietà fisiche, biologiche e chimiche),
−Chemiometria (ottimizzazione della separazione cromatografica o per la misura della
concentrazione di un composto basandosi sui dati spettrali ad esempio),
−Sensori (per ottenere informazioni su parametri non realmente misurati dal sensore ma di
interesse),
−Ingegneria chimica (ricerca degli errori e modellazione dei processi industriali),
−etc. (ad esempio riconoscimento di volti in una foto o in un filmato, utilizzato da alcuni aeroporti
americani per individuare ricercati)

SVM
M. Brescia - Data Mining - lezione 4 4
I modelli SVM furono originariamente definiti per la classificazione di
classi di oggetti lineramente separabili. Per ogni gruppo di oggetti divisi
in due classi una SVM identifica l’iperpiano avente il massimo margine di
separazione, nella figura a destra potete vedere come la linea verde non
separa le due classi, la linea blu le separa ma con un piccolo margine
mentre la linea rossa massimizza la distanza delle due classi.
Nella seconda figura l’iperpiano H1 definisce il bordo della classe i cui
oggetti sono rappresentati dai “+1” mentre l’iperpiano H2 quello degli
oggetti rappresentati dai “-1”.
Potete notare che due oggetti della classe “+1” servono a definire H1
(sono quelli cerchiati) e ne servono tre della classe “-1” per definire H2;
questi oggetti vengono chiamati “support vectors”, quindi il nostro
problema di identificare la miglior separazione tra le due classi è
risolto individuando i vettori di supporto che determinano il massimo
margine tra i due iperpiani.

SVM
M. Brescia - Data Mining - lezione 4 5
In un piano le combinazioni di tre punti possono essere separate da una linea però già quattro punti non è
detto che lo siano

SVM
M. Brescia - Data Mining - lezione 4 6
Ovviamente le SVM possono essereusate per separare classi che nonpotrebbero essere separate con unclassificatore lineare, altrimenti la loroapplicazione a casi di reale interessenon sarebbe possibile.
In questi casi le coordinate degli oggettisono mappate in uno spazio detto“feature space” utilizzando funzioni nonlineari, chiamate “feature function” ϕ. Ilfeature space è uno spazio fortementemultidimensionale in cui le due classipossono essere separate con unclassificatore lineare.
Quindi lo spazio iniziale viene rimappatonel nuovo spazio, a questo punto vieneidentificato il classificatore che poi vieneriportato nello spazio iniziale, comeillustrato in figura.

SVM
M. Brescia - Data Mining - lezione 4 7
La funzione ϕ combina quindi lo spazio iniziale (le
caratteristiche originali degli oggetti) nello spazio delle features
che potrebbe in linea di principio avere anche dimensione
infinita.
A causa del fatto che questo spazio ha molte dimensioni non
sarebbe pratico utilizzare una funzione generica per trovare
l’iperpiano di separazione, quindi vengono usate delle funzioni
dette “kernel” e si identifica la funzione ϕ tramite una
combinazione di funzioni di kernel.
L’implementazione più famosa delle SVM (libSVM) usa quattro
possibili kernel: http://www.csie.ntu.edu.tw/~cjlin/libsvm/

SVM for classification
M. Brescia - Data Mining - lezione 4 8
Per mostrare la capacità delle SVM di creare
classificatori anche nel caso non lineare e
valutare l’importanza della scelta del kernel
giusto consideriamo come esempio la
tabella qui a fianco.
E’ un piccolissimo dataset di 15 oggetti con
due parametri appartenenti a due classi +1 e
-1.
Nelle figure che seguiranno la classe +1 sarà
rappresentata da un + mentre la classe -1 da
un punto nero.
L’iperpiano trovato dalle SVM sarà
rappresentato da una linea continua.
I vettori di supporto saranno cerchiati per
individuarli meglio e il margine che
individuano sarà tracciato con una linea
tratteggiata.

SVM for classification
M. Brescia - Data Mining - lezione 4 9
Come si può vedere, il kernel lineare non è assolutamente adatto a questo esempio mentre gli altri 4
riescono a discriminare le due classi perfettamente.
Ma possiamo notare come le soluzioni siano molto differenti l’una dall’altra. E’ importante quindi avere un
set di prova che permetta di scegliere la migliore configurazione in modo da evitare quello che si chiama
usualmente “overfitting”, che significa adattarsi molto ai dati con cui è addestrato, specializzandosi troppo
e perdendo la capacità di generalizzazione.
Si può notare inoltre che eccezion fatta per il kernel lineare, parliamo non di funzioni semplici ma famiglie
di funzioni, che dipendono da un certo numero di parametri (detti usualmente “hyper-parameters”).
Questo, se da un lato fornisce maggiori speranze di individuare la soluzione ottimale, dall’altro complica il
nostro lavoro di ricerca, dal momento che dobbiamo cercare il kernel con i migliori parametri.

SVM for regression
M. Brescia - Data Mining - lezione 4 10
Le Support vector machines, che come detto nascono per risolvere problemi di classificazione, furono
estese da Vapnik al problema della regressione.
Il set di parametri con cui si addestra la rete è utilizzato per ottenere un modello di regressione che
può essere rappresentato come un ipertubo di raggio ε, che sarà quindi un hyper-parametro,
“fittato” sui dati.
Nel caso ideale, la regressione tramite le SVM trova una funzione che mappa tutti i dati di input con una
deviazione massima dal valore del “target”, pari proprio ad ε. In questo caso tutti i punti con cui si
addestrano le SVM si trovano all’interno del tubo di regressione.
Comunque, usualmente non è possibile “fittare” tutti gli oggetti all’interno del tubo. Quindi nel caso
generale le SVM in modalità di regressione considerano zero l’errore per gli oggetti all’interno del
tubo mentre quelli all’esterno hanno un errore che dipende dalla distanza dal margine del tubo

SVM for regression
M. Brescia - Data Mining - lezione 4 11
Si nota come l’uso di kernel più complessi faccia variare enormemente la forma del tubo
Polynomial Degree= 10 ε = 0.1 Radial Basis Function σ = 0.5 ε = 0.1
ε = 0.05 ε = 0.1
ε = 0.3 ε = 0.5
Esempio: Immaginiamo di aver
fatto vari addestramenti che
abbiano indicato un kernel
polinomiale di secondo grado
quello che offre un buon
modello e analizziamo il
parametro ε.
Quando il parametro è troppo
piccolo, il diametro del tubo
forza tutti gli oggetti ad essere
al di fuori del tubo. Questo
vorrà dire che avranno un
grosso errore e saranno quindi
male interpretati.

SVM - summary
M. Brescia - Data Mining - lezione 4 12
Le SVM nascono come modello supervisionato per fare classificazione tra 2 classi (in quasi tutte le
implementazioni attuali si lavora fino a 3 classi).
Abbiamo pure visto un esempio di come siano state riadattate per permettere di fare regressione. Ad oggi
esistono moltissime varianti delle SVM implementate nei più disparati linguaggi (c++, java, python,
matlab ed R per citare le sole libSVM)
Esistono ad esempio implementazioni che permettono di fare classificazione a molti classi, non
supervisionate per fare clustering, versioni che accettano come input del testo o delle immagini, per non
parlare delle miriadi di implementazioni di kernel differenti, tra cui uno che permette di usare l’algoritmo
delle svm per riprodurre una MLP
Il punto forte delle SVM è che, dato un generico problema, a patto di scegliere accuratamente il kernel (e
tutti i suoi parametri), esso è sempre risolvibile (facendo un overfitting totale del dataset di input)
Il problema è che il modello scala abbastanza male con la grandezza del dataset, gli viene attribuito
classicamente un fattore D2
Oltre a questo, il problema è identificare il miglior kernel e dotarlo dei parametri migliori. Parliamo di un
“neverending work” dal momento che, nella migliore delle ipotesi, i parametri sono tutti i numeri interi
positivi.

Practical information?
M. Brescia - Data Mining - lezione 4 13
MLP trained by several learning rules (BP, GAs, QNA)
SVM
Other machine learning models
There are user manuals and technical details on this page:
http://dame.dsf.unina.it/dameware.html

Fuzzy Logic
M. Brescia - Data Mining - lezione 4 14
Lofti Zadeh has coined the term “Fuzzy Set” in 1965 and opened a new field of
research and applications
A Fuzzy Set is a class with different degrees of membership. Almost all real world
classes are fuzzy!
Examples of fuzzy sets include: ‘Tall people’, ‘Nice day’, ‘Round object’ …
What if we also know that he is an NBA player?
If a person’s height is 1.88 meters is he considered ‘tall’?
Fuzzy sets. Information and Control. 1965; 8: 338–353.
Height, cm Crisp value Fuzzy 208 1 1.00
205 1 1.00
198 1 0.98
181 1 0.82
179 0 0.78
172 0 0.24
167 0 0.15
158 0 0.06
155 0 0.01
152 0 0.00
tall
Very tall
Extremely tall

A crisp definition of Fuzzy Logic
M. Brescia - Data Mining - lezione 4 15
Does not exist, however …
- It generalizes bivalent Aristotelian (Crisp) logic:
Aristotele’s modus ponens
IF <Antecedent == True> THEN <Do Consequent>
IF (X is a prime number) THEN (Send TCP packet)
Generalized modus ponens
IF “a region is green and highly textured” AND “the region is somewhat below a sky region”THEN “the region contains trees with high confidence”

An example of FL: temperature
M. Brescia - Data Mining - lezione 4 16
Fuzzy Logic (for ‘Temperature’)
100.0 Extremely Hot
Extremely Cold
Hot
Quite Hot
Quite Cold
Cold

An example of FL: temperature
M. Brescia - Data Mining - lezione 4 17
Membership Function
Cold Cool Warm Hot
0
1
-10 0 10 20 30ºC
Expresses the shift of temperature more natural and smooth

An example of FL: washing machine
M. Brescia - Data Mining - lezione 4 18

Fuzzy Inference – Expert System
M. Brescia - Data Mining - lezione 4 19
Input_1Fuzzy
IF-THEN
RulesOutputInput_2
Input_3

Membership Function
M. Brescia - Data Mining - lezione 4 20
What is a MF?
Linguistic Variable
A Normal MF attains ‘1’ and ‘0’ for some input
How do we construct MFs?
Heuristic
Rank ordering
Mathematical Models
Adaptive (Neural Networks, Genetic Algorithms …)
( ) ( ) 1 2 1 2, 1, 0A Ax x x xµ µ∃ ∈ Ω = =

MF examples
M. Brescia - Data Mining - lezione 4 21
TrapezoidalTriangular
( ) ( )1
, ,1
smf a x cf x a c
e− −=+
Sigmoid
( )( )2
22; ,x c
gmff x c e σσ− −
=Gaussian
( ); , , , max min ,1, ,0x a d x
f x a b c db a d c
− − = − − ( ); , , max min , , 0
x a c xf x a b c
b a c b
− − = − −

MF Examples
M. Brescia - Data Mining - lezione 4 22
( ) AA x X xα µ α= ∈ ≥
( ) AA x X xα µ α+ = ∈ >Strong Alpha Cut
Alpha Cut 0α =
0.2α = 0.5α = 0.8α = 1α =

Linguistic Variables
M. Brescia - Data Mining - lezione 4 23
Operate on the Membership Function (Linguistic Variable)
1. Expansive (“Less”, ”Very Little”)
2. Restrictive (“Very”, “Extremely”)
3. Reinforcing/Weakening (“Really”, “Relatively”)
( )Less xµ=
( )4Very Little xµ=
( )( )2Very xµ=
( )( )4Extremely xµ=
( ) ( )A Ax x cµ µ→ ±

Aggregation Operators
M. Brescia - Data Mining - lezione 4 24
( )αααα
α
1
2121 ,,,
+++=
n
aaaaaah n
n
LK
( )0 0, ,1ia n d a i i nα α∈ ℜ ≠ ≥ ∀ ∈ ≤ ≤
, min
1 ,
0 ,
1 ,
, max
h
h Harmonic Mean
h Geometric Mean
h Al gebraic Mean
h
α
α
α
α
α
ααααα
→ − ∞ →= − =→ == =→ ∞ →
Generalized Mean:
• Fixed Norms (Drastic, Product, Min)
• Parametric Norms (Yager)
T-norms: intersection logic
( ), 1
, , 1
0 ,D
b if a
T a b a if b
otherwise
== =
Drastic Product
( ) ( ), min ,ZT a b a b=( ),T a b a b• = ⋅
Zadehianp p

Aggregation Operators
M. Brescia - Data Mining - lezione 4 25
( ),BSS a b a b a b= + − ⋅ ( ), 0
, , 0
1 ,D
b if a
S a b a if b
otherwise
== =
S-Norms: union logic (the dual of T-norm)
( ) ( ), max ,ZS a b a b=
Bounded Sum DrasticZadehian p p
Drastic
T-NormProduct
Zadehian
minp p
Generalized Mean
Zadehian
max
Bounded
Sum
Drastic
S-Normp p
Algebraic (Mean)
Geometric
Harmonic
b (=0.8)a (=0.3)
( ) ( )( ) ( )1, min 1, 0,w w wu a b a b for w= + ∈ ∞Yager S-Norm
Yager S-Norm for varying w

Crisp vs Fuzzy Sets
M. Brescia - Data Mining - lezione 4 26
Fuzzy Sets• Membership values on [0,1]
• Law of Excluded Middle and Non-Contradiction do not necessarily hold:
• Fuzzy Membership Function
• Flexibility in choosing the Intersection (T-Norm), Union (S-Norm) and Negation operations
• Crisp Sets
• True/False 0,1
• Law of Excluded Middle and Non-
Contradiction hold:
• Crisp Membership Function
• Intersection (AND) , Union (OR),
and Negation (NOT) are fixed
A A
A A
∧ ≥ ∅∨ ≤ Ω
A A
A A
∩ = ∅∪ = Ω

Fuzzy Logic vs Vagueness
M. Brescia - Data Mining - lezione 4 27
Vagueness=Insufficient Specificity
“I will be back sometime”
Fuzzy Vague
“I will be back in a few minutes”
Fuzzy
Fuzziness=Unsharp Boundaries

Example: find an image threshold
M. Brescia - Data Mining - lezione 4 28
Membership Value
Gray Level
( ) ( )1
, ,1
smf a x cf x a c
e− −=+

Fuzzy Inference: Defuzzification
M. Brescia - Data Mining - lezione 4 29
We have a fuzzy result, however in many cases we need to make a crisp
decision (On/Off)
Methods of defuzzifying are:
Centroid (Center of Mass)
Maximum
Other methods
( )( )
A
A
x x dxCentroid
x dx
µ
µ∫∫
Input_1Fuzzy
IF-THEN
Rules
Tip LevelInput_2
Input_3
Fuzzify:
Apply MF on inputGeneralized Modus Ponens
with specified aggregation
operationsDefuzzify:
Method of Centroid,
Maximum, ...

Fuzzy Logic – Flow example
M. Brescia - Data Mining - lezione 4 30
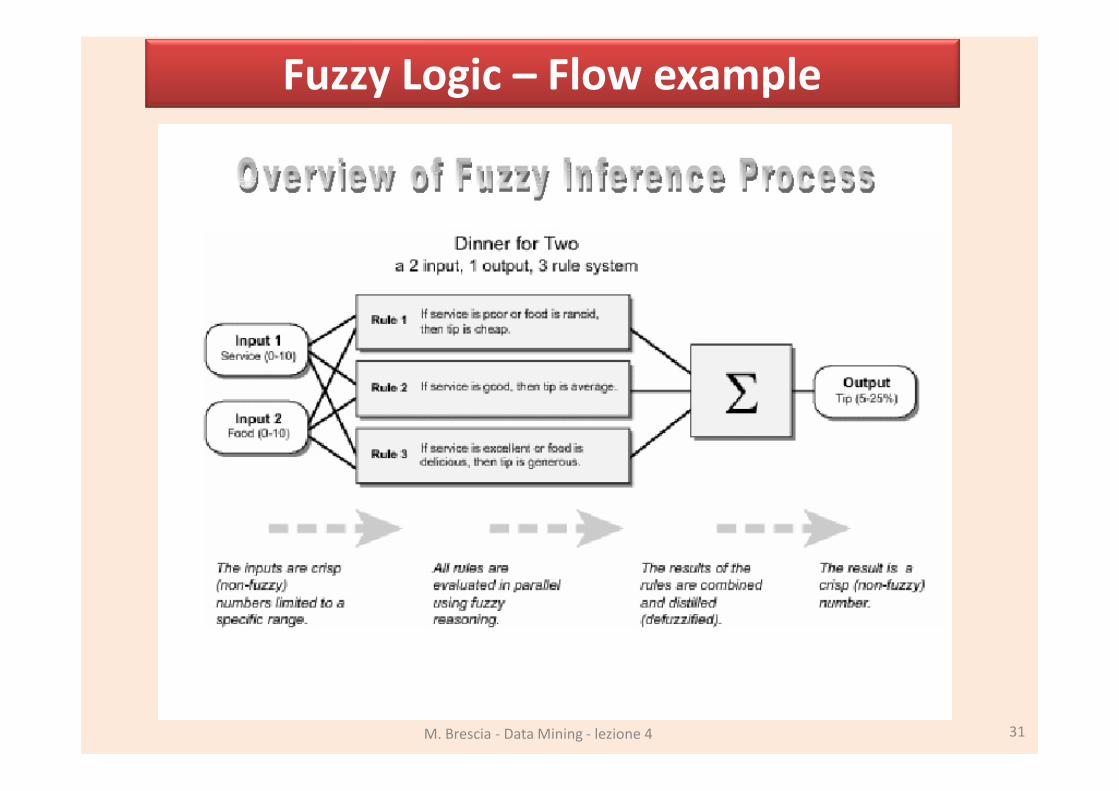
Fuzzy Logic – Flow example
M. Brescia - Data Mining - lezione 4 31

Fuzzy Logic – Flow example
M. Brescia - Data Mining - lezione 4 32

Fuzzy Logic – Flow example
M. Brescia - Data Mining - lezione 4 33

Fuzzy Logic – Flow example
M. Brescia - Data Mining - lezione 4 34

Fuzzy Logic – Flow example
M. Brescia - Data Mining - lezione 4 35

Fuzzy Logic – Flow example
M. Brescia - Data Mining - lezione 4 36

Fuzzy Logic – Flow example summary
M. Brescia - Data Mining - lezione 4 37

Fuzzy Logic vs Statistics
M. Brescia - Data Mining - lezione 4 38
Walking in the desert, close to being dehydrated, you find two
bottles of water:
The first contains deadly poison with a probability of 0.1
The second has a 0.9 membership value in the Fuzzy Set “Safe
drinks”
Which one will you choose to drink from???

Decision Trees
M. Brescia - Data Mining - lezione 4 39
• A flow-chart-like tree structure
• Internal node denotes a test on a single attribute
• Branch represents an outcome of the test
• Leaf nodes represent class labels or class distribution
Use of decision tree: Classifying an unknown sample Test the attribute values of the sample
against the decision tree
Generally a decision tree is first constructed in a top-down manner by recursively splitting the
training set using conditions on the attributes. How these conditions are found is one of the
key issues of decision tree induction.
Decision tree generation consists of two phases
Tree construction
• At start, all the training samples are at the root
• Partition samples recursively based on selected attributes After the tree construction it
usually is the case that at the leaf level the granularity is too fine, i.e. many leaves represent
some kind of exceptional data.
Tree pruning
• Identify and remove branches that reflect noise or outliers. Thus in a second phase such
leaves are identified and eliminated

Decision Trees
M. Brescia - Data Mining - lezione 4 40
attribute values of an unknown sample are tested against the conditions in the tree nodes,
and the class is derived from the class of the leaf node at which the sample arrives.
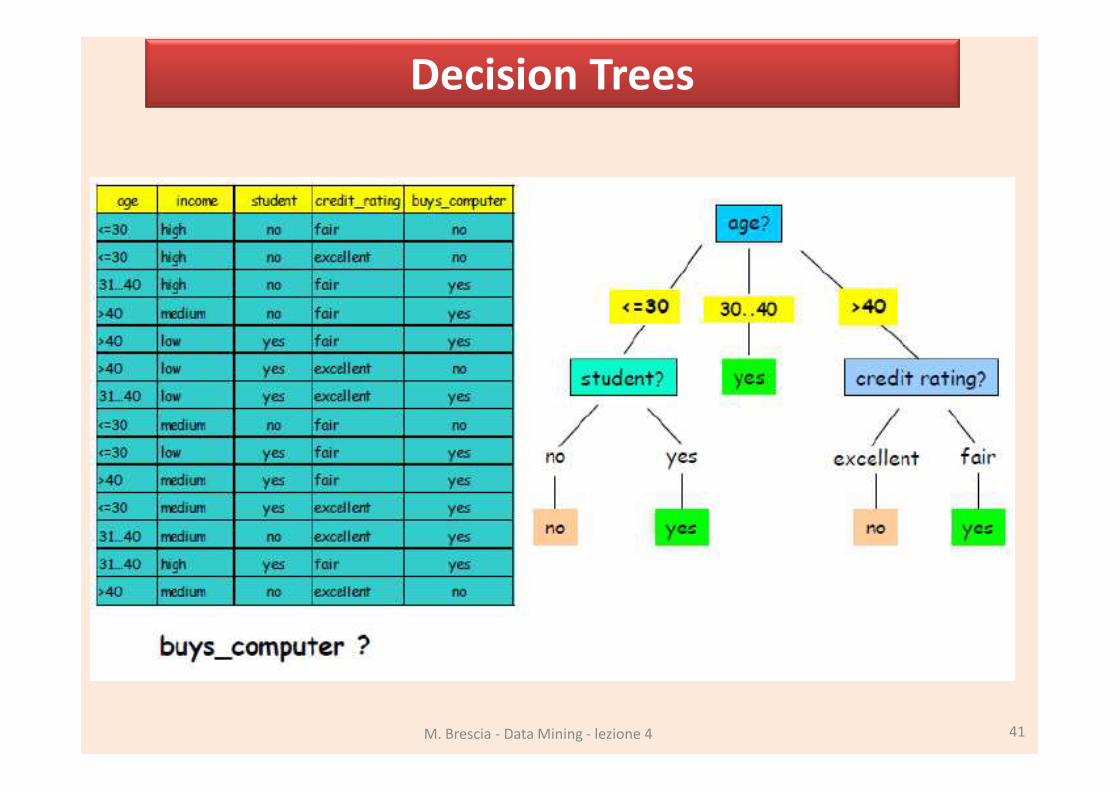
Decision Trees
M. Brescia - Data Mining - lezione 4 41

Algorithm for DT
M. Brescia - Data Mining - lezione 4 42
Algorithm for Decision Tree Construction
Basic algorithm for categorical attributes (greedy)
The tree is constructed in a top-down recursive divide-and-conquer manner
• At start, all the training samples are at the root
• Examples are partitioned recursively based on test attributes
• Test attributes are selected on the basis of a heuristic or statistical measure (e.g.,
information gain)
Conditions for stopping partitioning
• All samples for a given node belong to the same class
• There are no remaining attributes for further partitioning – majority voting is employed for
classifying the leaf
• There are no samples left
Attribute Selection
Measure Information Gain

Splitting Based on Nominal Attributes
M. Brescia - Data Mining - lezione 4 43

Splitting Based on Ordinal Attributes
M. Brescia - Data Mining - lezione 4 44

Splitting Based on Continuous Attributes
M. Brescia - Data Mining - lezione 4 45

Tree Induction
M. Brescia - Data Mining - lezione 4 46
Greedy strategy
–Split the records based on an attribute test that optimizes certain criterion.
Issues
–Determine how to split the records
•How to specify the attribute test condition?
•How to determine the best split?
–Determine when to stop splitting
Before Splitting: 10 records of class 0, 10 records of class 1
Which test
condition is the
best?

How to determine the best split
M. Brescia - Data Mining - lezione 4 47
Greedy approach:
– Nodes with homogeneous class distribution are preferred
• Need a measure of node impurity: the easy way is to assign a distance threshold among
classes (to prevent ambiguity in the decision flow).

How to split during DT building
M. Brescia - Data Mining - lezione 4 48
Assuming that we have a binary category, i.e. two classes P and N into which a data
collection S needs to be classified:
compute the amount of information required to determine the class, by I(p, n), the standard
entropy measure, where p and n denote the cardinalities of P and N.
Given an attribute A that can be used for partitioning the data collection in the decision
tree,
calculate the amount of information needed to classify the data after the split, according to
attribute A.
Attribute A partitions S into S1, S2 , …, SM
If Si contains pi examples of P and ni examples of N, the expected information needed to
classify objects in all subtrees Si is

How to split during DT building
M. Brescia - Data Mining - lezione 4 49
calculate I(p, n) for each of the partitions and weight these values by the probability that a
data item belongs to the respective partition.
The information gained by a split can be determined as the difference of the amount of
information needed for correct classification before and after the split.
Thus we calculate the reduction in uncertainty that is obtained by splitting according to
attribute A and select, among all possible attributes, the one that leads to the highest
reduction.
G a in ( A) = I ( p , n ) − E ( A)
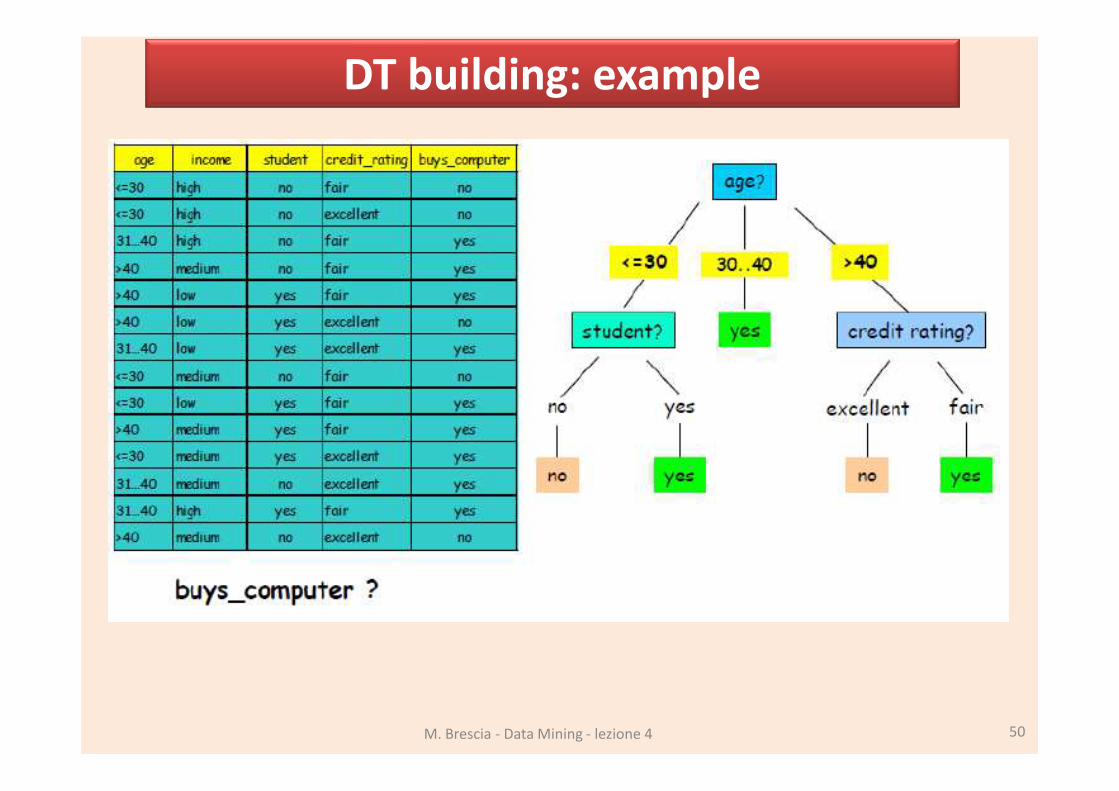
DT building: example
M. Brescia - Data Mining - lezione 4 50

DT building: example
M. Brescia - Data Mining - lezione 4 51
514 0.971
4140
5140.971 0,69
G a in ( A) = I ( p , n ) − E ( A)

DT building: example
M. Brescia - Data Mining - lezione 4 52
Thus we calculate the reduction in uncertainty that is
obtained by splitting according to attribute A and select
the one that leads to the highest reduction.
So far, we start from age (the best
gain). Proceed further with student
and credit range. We do not consider
the worst gain (income).

Common problems in Machine Learning
M. Brescia - Data Mining - lezione 4 53
In almost all machine learning models there are common learning problems, often
affecting the performances. When you approach ML in data mining, take care about
them…
Redundancy of parameter space
Sub-optimal solutions (local minima)
Underfitting / Overfitting (lack / excess of specialization)
Convergence speed and scalability

Underfitting & overfitting
M. Brescia - Data Mining - lezione 4 54

Overfitting due to noise
M. Brescia - Data Mining - lezione 4 55
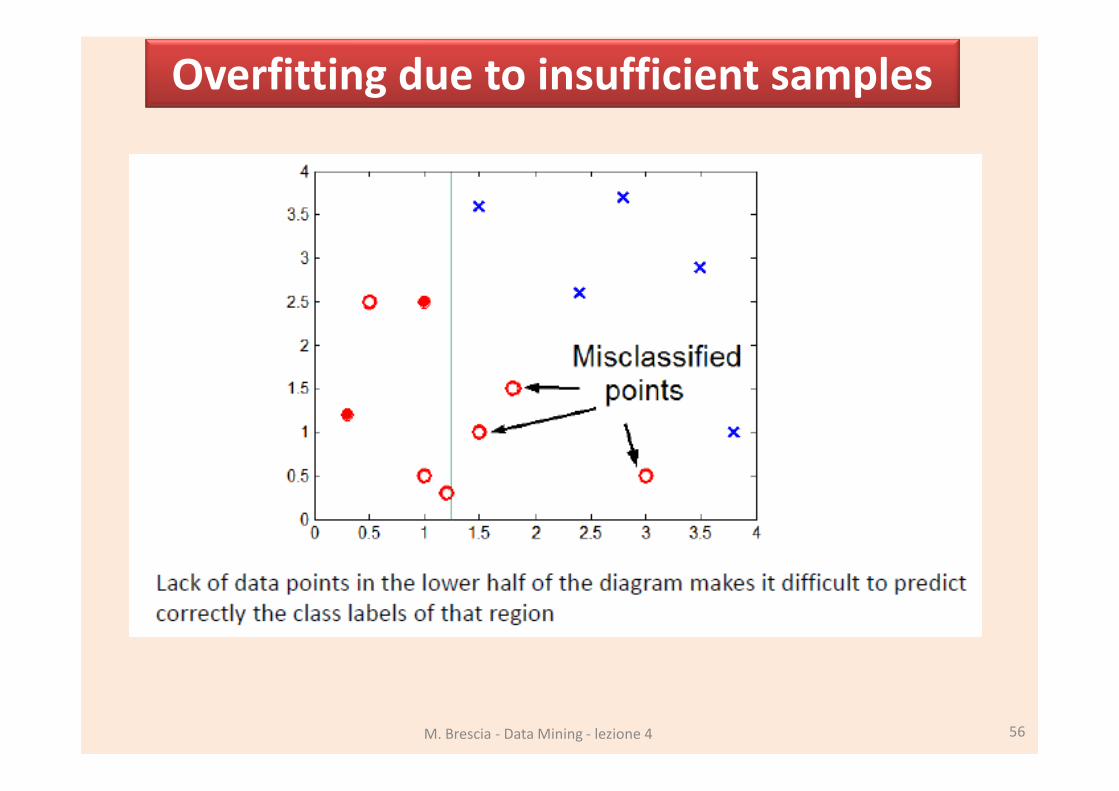
Overfitting due to insufficient samples
M. Brescia - Data Mining - lezione 4 56

K-fold Cross Validation
M. Brescia - Data Mining - lezione 4 57
Cross-validation è un metodo statistico per eliminare l’overfitting. Preso un campione di dati, esso viene
suddiviso in sottoinsiemi, alcuni dei quali usati per la costruzione del modello (training sets) e altri da
confrontare con le predizioni del modello (validation sets). Mediando la qualità delle predizioni tra i vari
insiemi di validazione si ha una misura dell'accuratezza delle predizioni.
la K-fold cross-validation, divide i dati in K sottoinsiemi, ognuno dei quali è lasciato fuori a turno come
insieme di validazione
La Leave-one-out cross validation lascia fuori una singola osservazione alla volta
Tutti i dati sono utilizzati per il training ed il test inmodo indipendente.Si hanno K classificatori (2≤K≤n) i cui output possonoessere mediati.Problema: per grandi dataset il metodo leave-one-outrichiede molto tempo di calcolo

Redundancy of parameter space
M. Brescia - Data Mining - lezione 4 58
By definition, machine learning models are based on learning and self-adaptive techniques.
A priori, real world data are intrinsically carriers of embedded information, hidden by noise.
In almost all cases the signal-to-noise (S/N) ratio is low and the amount of data prevents the
human exploration. We don’t know which features of a pattern is much carrier of good
information and how and where the correlation of features give the best knowledge of the
solution.
There are basically two techniques to extract information from a parameter space.
DIMENSIONALITY REDUCTION (FEATURE EXTRACTION)
PRUNING

Feature extraction: Filter model
M. Brescia - Data Mining - lezione 4 59

Feature extraction: Wrapper model
M. Brescia - Data Mining - lezione 4 60

Feature Extraction evaluation
M. Brescia - Data Mining - lezione 4 61
Filter model
Wrapper model

Feature Extraction example
M. Brescia - Data Mining - lezione 4 62
Statisticamente, la crescita volumetricadell’ippocampo è correlata all’occorrenzadella patologia di alzheimer.
Definire perfettamente il volume diinteresse (VOI) da IRM 3D è dunqueimportante ai fini della diagnosi precoce.
L'analisi manuale è molto lunga efortemente dipendente dall’esperienzadello specialista e dal macchinarioimpiegato.
L’idea è eliminare l’intervento umano,delegando la classificazione a sistemiautomatici dotati d’intelligenza.
classificazione di ippocampi umani da immagini 3D di risonanza magneticaperdiagnostica precoce della malattia di Alzheimer

Feature Extraction example
M. Brescia - Data Mining - lezione 4 63
Features:1 - posizione2 - livello di grigio66 - gradienti – maschera 3x366 - gradienti – maschera 5x566 - gradienti – maschera 7x766 - gradienti – maschera 9x949 - features tessiturali 3D
TOTALE: 315 feature E’ possibile ottenere risultati accettabili
riducendo drasticamente il numero di feature?

Feature Extraction example
M. Brescia - Data Mining - lezione 4 64
Sovrapponendo le varie immagini 2D output, si ottiene la VOI finale.
Perdita
accettabile

Methods for result evaluation
M. Brescia - Data Mining - lezione 4 65

Subjects of feature extraction
M. Brescia - Data Mining - lezione 4 66

Unsupervised Feature Extraction: PCA
M. Brescia - Data Mining - lezione 4 67

Geometric view of PCs
M. Brescia - Data Mining - lezione 4 68

Algebric form of PCs
M. Brescia - Data Mining - lezione 4 69

Optimality property of PCA
M. Brescia - Data Mining - lezione 4 70

Limits of PCA
M. Brescia - Data Mining - lezione 4 71
PCA finds linear principal components, based on the euclidean distance. It is well
suited for clustering problems
We will show better methods, discussing unsupervised machine learning

Pruning: Wrapper model + statistics
M. Brescia - Data Mining - lezione 4 72
Pruning of data consists of an heuristic evaluation of quality performance of a machine
learning technique, based on the Wrapper model of feature extraction, mixed with statistical
indicators. It is basically used to optimize the parameter space in classification and
regression problems.
All permutations
of data featuresRegression
Confusion matrix
Completeness
Purity
Contamination
Bias
Standard deviation
MAD
RMS
Outlier percentages
Classification

Statistics for classification
M. Brescia - Data Mining - lezione 4 73
Una rappresentazione utile è la matrice di confusione.
L’elemento sulla riga i e sulla colonna j è il numero assoluto oppure la percentuale di casi della
classe “vera” i che il classificatore ha classificato nella classe j.
Sulla diagonale principale ci sono i casi classificati correttamente. Gli altri sono errori.
A B C Totale
A 60 14 13 87 69,0%B 15 34 11 60 56,7%C 11 0 42 53 79,2%
Totale 86 48 66 200 68,0%
Sulla classe A l’accuratezza è 60 / 87 = 69,0%.Sulla classe B è 34 / 60 = 56,7% e sulla classe C è 42 / 53 = 79,2%.L’accuratezza complessiva è (60 + 34 + 42) / 200 = 136 / 200 = 68,0%.Gli errori sono il 32%, cioè 64 casi su 200. Il valore di questaclassificazione dipende non solo dalle percentuali, ma anche dalcosto delle singole tipologie di errore. Ad es. se C è la classe che èpiù importante classificare bene, il risultato è considerabilepositivo…
Nel training set ci sono 200 casi. Nella
classe A ci sono 87 casi:
• 60 classificati correttamente come A
• 27 classificati erroneamente, dei quali
14 come B e 13 come C

Classification indicators
M. Brescia - Data Mining - lezione 4 74
Classification accuracy: fraction of patterns (objects) correctly
classified, with respect to the total number of objects in the
sample;
Purity/Completeness: fraction of objects correctly classified,
for each class;
Contamination: fraction of objects erroneously classified, for
each class
4 quality evaluation criteria, by exploiting the output
representation through the confusion matrix

Classification indicators
M. Brescia - Data Mining - lezione 4 75
75
• Efficienza totale;
• Completezza;
• Purezza;
• Contaminazione.
NAA = veri positivi
NBB = veri negativi
NAB = falsi positivi
NBA = falsi negativi
4 quality evaluation criteria, by exploiting the output
representation through the confusion matrix

Classification example
M. Brescia - Data Mining - lezione 4 76
NGC1399
We want to detect and classify
globular clusters in the elliptical
galaxy fornax NGC1399

Classification example
M. Brescia - Data Mining - lezione 4 77
Chandra ACIS-I + ACIS-S (X-ray)
HST ACS g-z colors for central region
Keck Ground-based photometry for part of the
sources over the whole field

Classification example
M. Brescia - Data Mining - lezione 4 78
The GCs have been extracted in multi-band, by
evaluating PSF, color cuts and correlations. But
the selection is incomplete for the largest GC
with Reff>5 pc
Moreover, the use of space-borne data is very
expensive.
A ML classifier is able to detect GCs only with
ground-based photometry information?
Also, it is possible to have good results
without structural parameters obtained by
HST and Chandra bands?

Classification example
M. Brescia - Data Mining - lezione 4 79
All experiments were performed on the Base of Knowledge (BoK) sample presented in the
picture, assuming that bona fide GCs are represented by sources selected according to the
discussed color cuts. We decided to approach the experiment by comparing several ML
models.
Three variants of Multi Layer Perceptron (MLP)
o BP: trained by Back Propagation rule;
o GA: trained by Genetic Algorithms;
o QNA: trained by Quasi Newton rule;
Support Vector Machine (SVM)
Genetic Algorithm Model Experiment (GAME)

Classification example
M. Brescia - Data Mining - lezione 4 80
isophotal magnitude (feature 1);
3 aperture magnitudes (features 2–4) obtained through circular apertures of radii 2,
6 and 20 arcsec, respectively;
Kron radius, ellipticity and the FWHM of the image (features 5–7);
4 structural parameters (features 8–11) which are, respectively, the central surface
brightness, the core radius, the effective radius and the tidal radius;
One target value ONLY for training set: class labels 0 (no GC), 1 (yes GC);
24.4753,26.7468,24.3789,0.0205,3.72,0.067,4.12,16.25,-0.1139,1.822,51.29,0
24.2342,26.5263,24.1632,0.0196,3.5,0.027,4.01,16.61,0.1321,1.856,35.38,0
23.1554,25.5964,23.1654,0.016,3.5,0.032,4.09,14.47,-0.3295,2.638,129.2,1
22.6316,25.3519,22.6808,0.0151,3.5,0.039,4.69,16.33,0.8065,5.002,80.45,1
22.4708,24.4951,22.4699,0.0216,3.5,0.066,3.45,12.81,-0.3912,-7.425,5.66,0
23.9033,27.5896,23.9168,0.0255,4.49,0.272,9.63,19.99,8.397,14.79,88.5,1
24.1972,26.4219,24.0978,0.0192,3.7,0.079,4.04,15.72,-0.1447,1.514,44.77,0
20.2423,22.1866,20.2963,0.017,3.5,0.03,3.23,6.68,-0.6999,-0.1492,1.899,0
23.5134,26.0983,23.511,0.0167,3.76,0.05,4.55,16.6,0.3777,4.75,105.8,1
…2100 training
patterns
KB
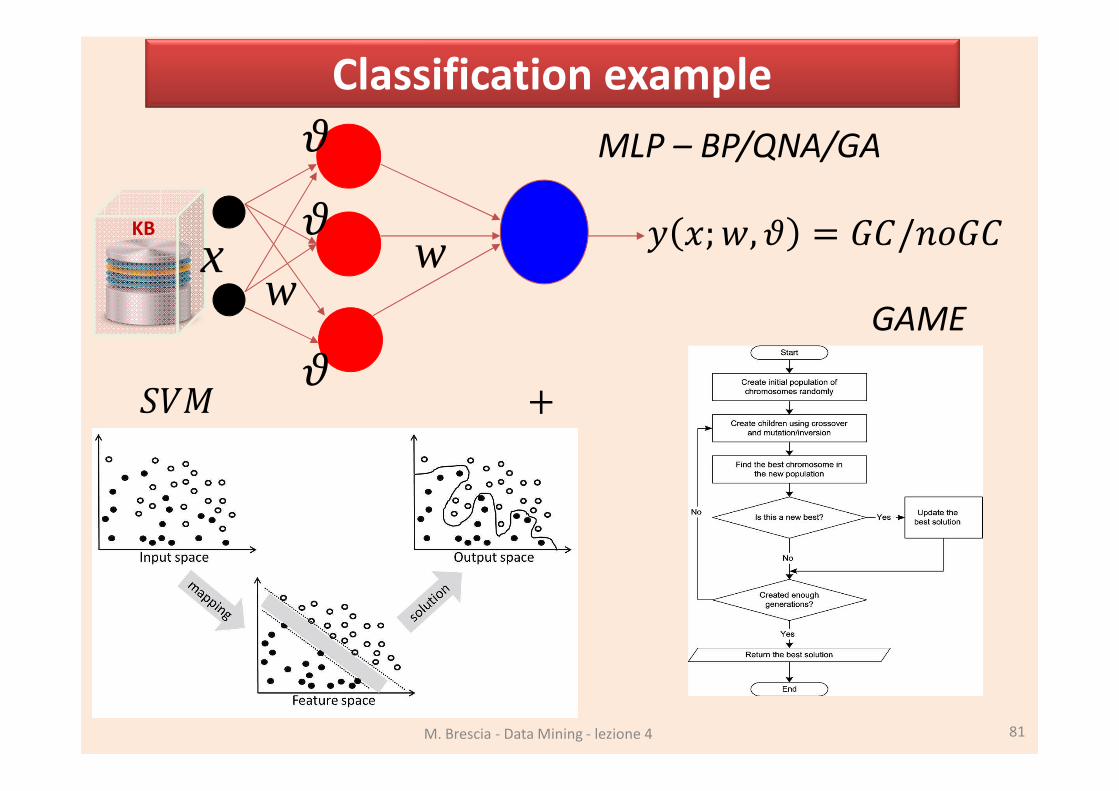
Classification example
M. Brescia - Data Mining - lezione 4 81
ww
KB
x
;, /
GAME
MLP – BP/QNA/GA

Classification example
M. Brescia - Data Mining - lezione 4 82
2100
training patterns
11 features each
KBMulti Layer Perceptron
trained by:
• Back Propagation
• Quasi Newton
• Genetic Algorithm
Support Vector Machines
GAME
5 classifiers
Classification accuracy: fraction of patterns
(objects) correctly classified (either GCs or
non-GCs), with respect to the total number
of objects in the sample;
completeness: fraction of objects correctly
classified as GCs;
contamination: fraction of non-GC objects
erroneously classified as GCs
3 quality evaluation criteria
425 pruning experiments (85 for each classifier), by alternately removing subsets of features,
in order to evaluate the minimal set of required (highly correlated) parameters.
K-fold (k=10) cross validation to avoid
overfitting;
Cross entropy formula for statistical
evaluation of training error (not simple
MSE): , 1 !"#$%&
'
%()

Classification example
M. Brescia - Data Mining - lezione 4 83
isophotal magnitude (feature 1);
3 aperture magnitudes (features 2–4) obtained through circular apertures of radii 2,
6 and 20 arcsec, respectively;
Kron radius, ellipticity and the FWHM of the image (features 5–7);
4 structural parameters (features 8–11) which are, respectively, the central surface
brightness, the core radius, the effective radius and the tidal radius;

Regression indicators
M. Brescia - Data Mining - lezione 4 84
∆+ , -./!0+12 ∆+3 $, &$1 ,&
40/5 ∑ $|∆+%|&'%() 5,/2/-22190/,0:
∑ ∆+% ∑ ∆+%'%() #
'%()
; 120/ ∆+ 120/ ∆+ ; 1.4826: > ∑ $∆+%&#'%()
RMS 40/5# :#
By supposing that the target (desired) value of any regression problem is t, while the output
of the learning model is o, the following statistical operators are useful for quality
evaluation.
Although the RMS and standard deviation are
in principle different, sometimes they differ
very little when the errors are sufficiently small
but a little bit higher in some error bins.
the median of the absolute deviations from
the data's median
(1, 1, 2, 2, 4, 6, 9). It has a median value of
2. The absolute deviations about 2 are (1,
1, 0, 0, 2, 4, 7) which in turn have a median
value of 1 (because the sorted absolute
deviations are (0, 0, 1, 1, 2, 4, 7)). So the
median absolute deviation for this data is 1

Outliers evaluation in regression
M. Brescia - Data Mining - lezione 4 85
The MAD is a robust statistic, measure of statistical dispersion. Moreover, the MAD is less
sensible to outliers in a data set than the standard deviation. In the standard deviation, the
distances from the mean are squared, so large deviations are weighted more heavily, and
thus outliers can heavily influence it. In the MAD, the deviations of a small number of
outliers are irrelevant.
So far, MAD could give more reliable information on the dispersion of data, without being
influenced by the outlier distribution.
Besides such consideration, outliers percentage is very important. Especially to identify
anomalies within data (serendipity).
%|Δz|> 1:% |Δz|> 2:% |Δz|> 3:% |Δz|> 4:
…

Regression Example: redshift
M. Brescia - Data Mining - lezione 4 86
Se un galassia si sta muovendo con velocità v, una riga spettrale emessa a lunghezza d’onda λ
verrà osservata a λoss.
Avrà, quindi uno shift D λ =(λoss – λ )
In termini di velocità v = c D λ / λ
Se v << c v/c ~ z
Attenzione, già per V=3000km/s la formula approssimata causa un errore di 15km/s

Regression Example: redshift
M. Brescia - Data Mining - lezione 4 87
Se un galassia si sta muovendo con velocità v, una riga spettrale emessa a lunghezza d’onda λ
verrà osservata a λoss.
Avrà, quindi uno shift D λ =(λoss – λ )
In termini di velocità v = c D λ / λ
Se v << c v/c ~ z
Attenzione, già per V=3000km/s la formula approssimata causa un errore di 15km/s

Regression Example: redshift
M. Brescia - Data Mining - lezione 4 88
Se un galassia si sta muovendo con velocità v, una riga spettrale emessa a lunghezza d’onda λ
verrà osservata a λoss.
Avrà, quindi uno shift D λ =(λoss – λ )
In termini di velocità v = c D λ / λ
Se v << c v/c ~ z
Attenzione, già per V=3000km/s la formula approssimata causa un errore di 15km/s

Regression Example: redshift
M. Brescia - Data Mining - lezione 4 89
Con osservazioni spettroscopiche si può ricavare il redshift spettroscopico con estrema
precisione, ma ad un elevato costo, poiché occorre utilizzare per molto tempo grandi
strumenti da terra o dallo spazio, oltre ad analisi fisiche molto complesse e dispendiose
(spettro per spettro).
X
Photometric system - Si(λ)Galaxy spectrum - F(λ)
=
( ) ( )( ) u
U
U
U cdS
dSFm +−=
∫∫
λλ
λλλ10log5.2
( ) ( )( ) B
B
B
B cdS
dSFm +−=
∫∫
λλ
λλλ10log5.2
Etc…
.
U B
B R
U B m m
B R m m
etc
− ≡ −− ≡ −
Color indexes
B-R
U-B
Point moves as a
function of z and
morphological type
Photo-z are an
inverse problem
Spectral Energy Distribution convolved with band filters

Regression Example: redshift
M. Brescia - Data Mining - lezione 4 90
Photometric redshifts are treated as a regression problem (i.e. function approximation),
hence a DM problem: The idea is to build a subset of spectroscopic samples (with Zspec
known) to train a machine learning model to learn how to predict the Zphot by using
correlated info among objects observed through photometric bands
BoK
(set of templates)Mapping function Knowledge (phot-z’s)
ww
BoK
x
;, +BC,
932,891,133 PHOTOMETRIC OBJECTS
2,353,524 SPETTROSCOPIC OBJECTS
~ 400 times more objects!!!
Best model: MLP+QNA

Regression Example: redshift
M. Brescia - Data Mining - lezione 4 91
Spectroscopic redshift distribution for the training (blue) and test (red) sets.
This is the BoK obtained from the whole spectroscopic (known redshift) + photometric
(bands) dataset.
The split method is random but maintaining homogeneous both redshift distribution.

Regression Example: redshift
M. Brescia - Data Mining - lezione 4 92
SDSS (VIS + NIR)
SDSS + UKIDSS (VIS + NIR +
MIR)
SDSS + GALEX + UKIDSS
(UV + VIS + NIR + MIR)
SDSS + GALEX + UKIDSS + WISE
(UV + VIS + NIR + MIR + FIR)SDSS + GALEX (UV + VIS +
NIR)

Regression Example: redshift
M. Brescia - Data Mining - lezione 4 93
Ref. |bias| sigma MAD RMS |biasnorm| snorm MADnorm RMSnorm
SDSS 0.016 0.34 0,083 0.34 0.034 0.19 0.060 0.19
Bovy 2012 0.46
Ref. |bias| sigma MAD RMS |biasnorm| snorm MADnorm RMSnorm
SDSS+GALEX 0.005 0.24 0.091 0.24 0.017 0.13 0.046 0.13
Bovy 2012 0.26
Ref. |bias| sigma MAD RMS |biasnorm| snorm MADnorm RMSnorm
SDSS+UKIDSS 0.003 0.21 0.084 0.21 0.010 0.11 0.040 0.11
Bovy 2012 0.28
Ref. |bias| sigma MAD RMS |biasnorm| snorm MADnorm RMSnorm
SDSS+GALEX+UKIDSS 0.005 0.15 0.072 0.15 0.006 0.075 0.036 0.075
Bovy 2012 0.21
Ref. |bias| sigma MAD RMS |biasnorm| snorm MADnorm RMSnorm
SDSS+GALEX+UKIDSS+WISE 0.003 0.15 0.063 0.15 0.005 0.15 0.063 0.15
∆+ +5B1D +BC, ∆+3 ∆+EFGH $+5B1D +BC,&$1 +5B1D&

Where we are in brain emulation?
M. Brescia - Data Mining - lezione 4 94
• connessionismo
• apprendimento
•generalizzazione
Reti Neurali
• incertezza
• incompletezza
• approssimazione
Logica Fuzzy
• ottimizzazione
• casualità
• evoluzione
Algoritmi Genetici
•robustezza
• probabilità
• dipendenza eventi
• attendibilità
BayesianModels

Bayesian Models
M. Brescia - Data Mining - lezione 4 95
I Modelli Bayesiani (MB) possono essere considerati ottimi strumenti per strutturare erisolvere problemi di natura molto complessa e in presenza di una grande mole di datie di incertezza sulle cause-effetto (quindi in cui siano coinvolte delle probabilità).
Sono strutturati come grafi orientati aciclici dove ogni nodo rappresenta una variabile(es. un evento, un attributo...ecc.), mentre gli archi rappresentano le dipendenze traun nodo ed un altro (es. dipendenza tra un sintomo ed una malattia).
Ogni nodo possiede al proprio interno una tabella chiamata CPT (ConditionalProbability Table) che quantifica gli effetti che i “genitori” hanno sul nodo.
ll nome deriva dal teorema di T. Bayes (teorema della probabilità delle cause).
teorema di Bayes: p(C|E) = p(E|C) · p(C)/p(E)
dove:
p(C|E) = Probabilità che, dato l'effetto 'E', la causa 'C' si verifichi.
p(E|C) = Probabilità che, data la causa 'C', l'effetto 'E' si verifichi.
p(C) = Probabilità che la causa 'C' si verifichi.
p(E) = Probabilità che l'effetto 'E' si verifichi, qualunque sia la causa.

Bayesian Models
M. Brescia - Data Mining - lezione 4 96
In campo probabilistico capita che si debba valutare una probabilità avendo già delle
informazioni su quanto già accaduto in precedenza.
Dati due eventi A e B, se sono in qualche modo correlati, è ragionevole pensare che il sapere
che uno dei due sia già avvenuto, possa migliorare la conoscenza della probabilità dell'altro.
P(C|E) = P(C,E) / P(E) (per P(E)≠0), dove P(C,E)=P(E|C) P(C)
Forma completa:
dato lo spazio di probabilità ( Ω spazio campionario, E spazio degli eventi, P()), siano E1,E2,...En
appartenenti ad E;
per ogni Ei appartenente ad E e t.c. P(Ei) > 0:
P(Ek|C) = P(C|Ek) P(Ek) / (Σ i P(C|Ei) P(Ei) )
“regola fondamentale del calcolo delle probabilità” : p(C,E) = p(C|E) · p(E)
p(C,E1,E2,...,En) = p(C|E1,E2,...,En) · p(E1) · p(E2) .... · p(En)
“regola di Bayes” :
generalizzazione

Bayesian Models: Example
M. Brescia - Data Mining - lezione 4 97
I parametri in gioco sono:
L’allarme suona ogni volta che un ladro entra in casa (eventi positivi);
L’allarme può suonare anche in caso di piccole scosse di terremoto (falsi positivi);
Abbiamo 2 vicini, John e Mary, che avvisano nel caso in cui l'allarme si attivi in
nostra assenza (occorrenza eventi corretti/falsi positivi);
John è affidabile, e chiama sempre quando l'allarme suona, ma a volte si confonde
e chiama anche quando in realtà l'allarme non ha suonato (corretti/falsi positivi);
Mary invece ama la musica a tutto volume e quindi è probabile che non senta
l'allarme (corretti/falsi negativi);
Abbiamo una statistica di eventi di un anno, del tipo: chi ha chiamato, quante volte è suonato
l'allarme...ecc (targets eventi);
Problema: allarme domestico molto sensibile.
In presenza di conoscenza sulla statistica degli eventi e sulle condizioni, è possibile definire a
priori il grafo, potendo scegliere i possibili output del problema!

Bayesian Models: Example
M. Brescia - Data Mining - lezione 4 98
Passo 1:
Determinare le dipendenze e creare un grafo aciclico
Passo 2:
Creazione delle tabelle CPT iniziali
(tramite informazioni ottenute in un certo tempo)
Come possiamo notare, la realizzazione
del grafo e delle tabelle CPT viene
effettuata esclusivamente tramite
“considerazioni locali”, su ciascun
nodo, e sui suoi genitori.

Bayesian Models: Example
M. Brescia - Data Mining - lezione 4 99
Con il termine “Inferenza” si indica l'operazione di deduzione della veridicità di una
proposizione, partendo da un'altra proposizione precedentemente accolta come vera;
Nei modelli bayesiani l'inferenza avviene tramite le informazioni contenute all'interno delle
CPT di ogni nodo;
Ma in che modo?
Riprendiamo l'esempio precedente.
Prima di iniziare le operazioni di inferenza,
Per ogni nodo figlio (A, J ed M)
calcoliamoci la seguente tabella:
P(Figlio,Genitore1...GenitoreN)
P(Figlio,Genitore1...GenitoreN) è una tabella delle probabilità che prende in considerazione
esclusivamente gli elementi figlio,g1...gN (Es. "con quanta probabilità figlio è falso mentre g1,
g2...gn sono vere?")

Bayesian Models: Example
M. Brescia - Data Mining - lezione 4 100
Nel nostro caso dobbiamo calcolarci:
- P(A,Fu,Te)
- P(J,A)
- P(J,M)
Applichiamo la regola fondamentale:
P(A,Fu,Te) = P(A|Fu,Te) · P(Fu) · P(Te)
P(A|Fu,Te); Questa rappresenta le probabilità di occorrenza dell'evento 'A' in relazione agli
eventi 'Fu' e 'Te‘. Queste probabilità si trovano nella tabella CPT relativa all'evento 'A'
(Es. supponiamo che 'Fu' sia vera, mentre 'Te' sia falsa, la probabilità di occorrenza dell'evento
'A', conoscendo 'Fu' e 'Te‘, è uguale a P(A|Fu,Te) che nel nostro caso è uguale a 0,94).
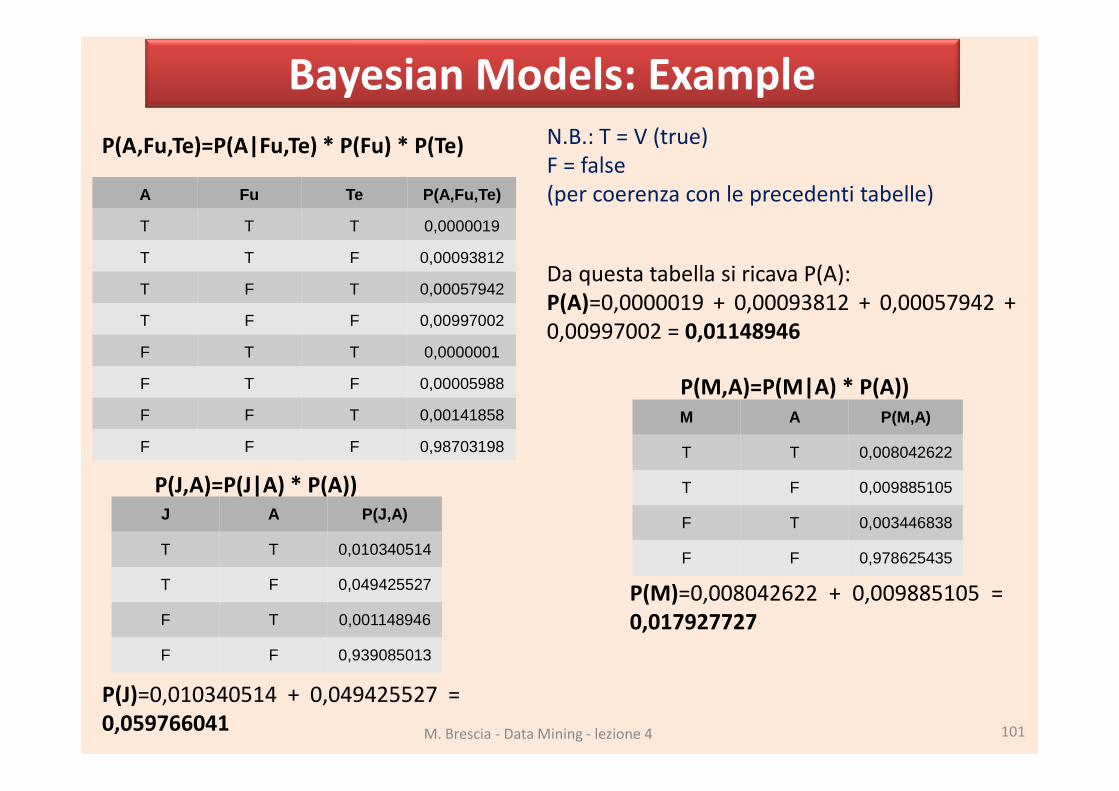
Bayesian Models: Example
M. Brescia - Data Mining - lezione 4 101
A Fu Te P(A,Fu,Te)
T T T 0,0000019
T T F 0,00093812
T F T 0,00057942
T F F 0,00997002
F T T 0,0000001
F T F 0,00005988
F F T 0,00141858
F F F 0,98703198
P(A,Fu,Te)=P(A|Fu,Te) * P(Fu) * P(Te)
Da questa tabella si ricava P(A):
P(A)=0,0000019 + 0,00093812 + 0,00057942 +
0,00997002 = 0,01148946
N.B.: T = V (true)
F = false
(per coerenza con le precedenti tabelle)
J A P(J,A)
T T 0,010340514
T F 0,049425527
F T 0,001148946
F F 0,939085013
P(J,A)=P(J|A) * P(A))
P(J)=0,010340514 + 0,049425527 =
0,059766041
M A P(M,A)
T T 0,008042622
T F 0,009885105
F T 0,003446838
F F 0,978625435
P(M,A)=P(M|A) * P(A))
P(M)=0,008042622 + 0,009885105 =
0,017927727

Bayesian Models: Example
M. Brescia - Data Mining - lezione 4 102
Ora, cosa succede se ad un certo punto arriva una telefonata di John??
Questa “certezza” va ora propagata nelle tabelle interessate;
Per prima cosa andiamo ad aggiornare la tabella che più è interessata a
questo cambiamento: P(J,A)
L'aggiornamento avverrà tramite la seguente formula:
P*(J,A) = P(J,A) · P*(J) / P(J)
J A P(J,A) P*(J,A)
T T 0,010340514 0,173016546
T F 0,049425527 0,826983454
F T 0,001148946 0
F F 0,939085013 0
Da questa tabella appena ricavata ci troviamo la nuova P(A) che chiameremo P*(A)
J A P(J,A)
T T 0,010340514
T F 0,049425527
F T 0,001148946
F F 0,939085013
* 1 /0,059766041
* 1 /0,059766041
* 0 /0,940233959
* 0 /0,940233959
P*(J,A)=
Andremo a creare una nuova variabile P*(J) = 1, che rappresenta la
certezza che John ha chiamato.

Bayesian Models: Example
M. Brescia - Data Mining - lezione 4 103
A Fu Te P*(A,Fu,Te)
T T T 0,000028612
T T F 0,014126885
T F T 0,008725323
T F F 0,150135726
F T T 0,000000084
F T F 0,000050095
F F T 0,001186778
F F F 0,825746497
* 0,173016546 / 0,01148946
* 0,826983454 / 0,98851054
A Fu Te P(A,Fu,Te)
T T T 0,0000019
T T F 0,00093812
T F T 0,00057942
T F F 0,00997002
F T T 0,0000001
F T F 0,00005988
F F T 0,00141858
F F F 0,98703198
* 0,173016546 / 0,01148946
* 0,173016546 / 0,01148946* 0,173016546 / 0,01148946
* 0,826983454 / 0,98851054* 0,826983454 / 0,98851054
* 0,826983454 / 0,98851054
Quindi, aggiornato P(A) con P*(A), effettuiamo l’aggiornamento sulla tabella P(A,Fu,Te)

Bayesian Models: Example
M. Brescia - Data Mining - lezione 4 104
Dopo questa modifica, la situazione delle tabelle sarà la seguente:
P(A)=0,173016546
J A P(J,A)
T T 0,173016546
T F 0,826983454
F T 0
F F 0
M A %
T T 0,008042622
T F 0,009885105
F T 0,003446838
F F 0,978625435
P(J)=1 P(M)= 0,017927727
A Fu Te P(A,Fu,Te)
T T T 0,000028612
T T F 0,014126885
T F T 0,008725323
T F F 0,150135726
F T T 0,000000084
F T F 0,000050095
F F T 0,001186778
F F F 0,825746497
Le tabelle possono essere ulteriormente
modificate nel caso in cui altri eventi vengano
acclarati (Es. anche Mary telefona, o si appura
che l'allarme stia veramente suonando...ecc)
E' proprio questa “dinamicità” che rende i
modelli bayesiani un ottimo strumento per
strutturare i problemi e analizzare i dati in
presenza di incertezze, in particolare quando
le relazioni (probabilistiche), causa-effetto
siano particolarmente complicate

Bayesian Models: a real problem
M. Brescia - Data Mining - lezione 4105
Il sistema a priori non conosce la struttura interna della rete bayesiana da applicare, né è
possibile definire il grafo orientato e relative CPT in modo preciso;
Prima di utilizzare il sistema dobbiamo effettuare una fase di “training” tramite una BoK (Base
of Knowledge) estratta ad hoc;
La BoK si rappresenta sottoforma di una matrice di pattern e features, in cui troviamo le
dichiarazioni di quelli che sono gli eventi/attributi che andranno a costituire i nodi della nostra
BN (Bayesian Network);
eventi\attributi
Dati campione
# MAG_ISO MAG_APER1 MAG_APER2 MAG_APER3 target
24.4753 26.7468 24.3789 0.0205 0
26.3361 29.8375, 25.6474 0.0846 2
24.2342 26.5263 24.1632 0.0196 0
23.1554 25.5964 23.1654 0.016 1
22.6316 25.3519 22.6808 0.0151 1
24.1556 28.5664 24.2824 0.0372 0
22.4708 24.4951 22.4699 0.0216 2
eventi\attributi
Dati campione
Un piccolo esempio di un
dataset di 3-class
classificazione
Un piccolo esempio
di un dataset di
regressione

Bayesian models
M. Brescia - Data Mining - lezione 4 106
I modelli probabilistici grafici sono grafi in cui i nodi rappresentano variabili aleatorie e gli archi
assunzioni di dipendenza condizionata. Come abbiamo visto nell’introduzione, tali grafi sono
dunque una rappresentazione grafica compatta dei principi enunciati dal teorema
fondamentale del calcolo delle probabilità e dalla teoria di Bayes.
Da un punto di vista tassonomico si suole distinguere tra:
Modelli basati su grafi non-orientati;
Modelli basati su grafi orientati;
I modelli a grafo non-orientato, anche chiamati Markov Random Fields (MRF) o Markov
Networks, si basano sulla semplice definizione di indipendenza: 2 insiemi di nodi A e B sono
condizionalmente indipendenti, dato un terzo insieme C, se tutti i percorsi tra i nodi di A e B
sono separati da un nodo di C.
I modelli a grafo orientato, anche chiamati Reti Bayesiane (BN), si basano su definizioni di
indipendenza più complesse, che tiene conto della direzionalità degli archi. Ma presentano dei
vantaggi. Il più importante è la possibilità di considerare un arco da A a B come una legge «A
causa B». Questa semplice legge può essere usata come guida per definire la struttura del
grafo.

Bayesian models
M. Brescia - Data Mining - lezione 4 107
Visto che non possiamo calcolarci un esatto modello bayesiano “ad-hoc” per ogni problema,
non ci resta che generalizzare il problema per renderlo adattabile ad ogni circostanza.
Il problema generalizzato diventa dunque il seguente: Dato in ingresso un insieme di dati “X”,
si vuole ottenere un insieme di risultati “Y”, avendo a disposizione un insieme di coppie (X,Y)
note a priori;
Una possibile soluzione sarebbe quella di utilizzare morfologie standard per la realizzazione
della Rete Bayesiana.
Prima di tutto dobbiamo analizzare il problema generalizzato con i componenti del grafo:
Nodi di tipo X: → Rappresentano gli insiemi di INPUT della nostra struttura
Nodi di tipo Y: → Rappresentano gli insiemi di OUTPUT della nostra struttura
Nodi di tipo Q: → Rappresentano la logica applicativa della nostra struttura;
cioè la funzione Q() tale che: Q(X)=Y

Bayesian models
M. Brescia - Data Mining - lezione 4 108
Dai nodi precedentemente ottenuti, possiamo ricavarci un numero elevato di grafi
aciclici...ma, data la tipologia dei nostri problemi, ci focalizzeremo esclusivamente sulle
seguenti:
Struttura con una
sola logica
applicativa
Struttura con 2 o più
logiche applicative
serializzate.
I “nodi” Q1...Qn sono il cuore del nostro
grafo, e possono essere implementati
utilizzando i più disparati modelli di
calcolo statistico (es. Gaussian mixture,
decision tree, neural network o addirittura
un'altra rete Bayesiana...).
Qualsiasi sia il modello prescelto, prima di
poterlo utilizzare, bisogna in ogni caso
effettuare le seguenti fasi:
- Training + validation
- Testing
Ognuna di queste fasi viene implementata
in maniera differente a seconda del
modello prescelto.

Bayesian probability theory
M. Brescia - Data Mining - lezione 4 109

Bayesian probability theory
M. Brescia - Data Mining - lezione 4 110

Ensemble of classifiers
M. Brescia - Data Mining - lezione 4 111
Construct a set of classifiers from the training data
Predict class label of previously unseen records by aggregating predictions made by
multiple classifiersWHY IT WORKS?
Suppose there are 5 base
classifiers
Each classifier has error rate
ε = 0.35, considered as good rate
Assume classifiers are
independent
Probability that the ensemble
classifier makes a good prediction:
I 50 J% 1 J KL%
K
%() 0.89

Gated experts
M. Brescia - Data Mining - lezione 4 112
La banale ma vera affermazione che più cervelli lavorano meglio di uno solo si può applicare al machine
learning e al pattern recognition.
Ciò ha portato alla teoria dei Multiple Classifier Systems (MCS) o Gated Experts.
Un MCS consiste in un “ensemble” di differenti algoritmi di classificazione ed una funzione f(.) che combini
gli output dei classificatori.
Uno dei metodi più generalizzati è il cosiddetto “Stacked Approach”. I k output dei classificatori si possono
considerare come features di un nuovo problema di classificazione, cui applicarvi quindi in stacking un
altro gruppo o singolo classificatore. In tal caso il Combiner è un altro classificatore (“gating network”) al
secondo livello. Questo approccio è particolarmente usato quando la rete di classificatori è composta da
reti neurali.

Gated experts (clustering+classification)
M. Brescia - Data Mining - lezione 4 113
MIN
Optimal number of clusters
Step 1 - Per ogni partizione si
producono n clusters
Step 2
Train di una rete per ogni cluster.
Ogni rete diviene “esperta” per una
certa regione dello spazio
Step 3
Una rete di “gating” correla i vari
gradi di esperienza delle singole reti
per le varie regioni dello spazio
Artificial Brain
M. Brescia - Data Mining - lezione 4 114
Reti
NeuraliDecision
Trees
Fuzzy
Logic
Algoritmi
Genetici
Bayesian
Models

References
M. Brescia - Data Mining - lezione 4 115
Brescia, M.; 2011, New Trends in E-Science: Machine Learning and Knowledge Discovery in
Databases, Contribution to the Volume Horizons in Computer Science Research, Editors:
Thomas S. Clary, Series Horizons in Computer Science, ISBN: 978-1-61942-774-7, available
at Nova Science Publishers
http://dame.dsf.unina.it/beta_info.html
http://www.csie.ntu.edu.tw/~cjlin/libsvm/
Zadeh, L., Fuzzy sets. Information and Control. 1965; 8: 338–353.
Duda R. O., Hart P. D., Storck D. G., 2004, Pattern Classification, 2nd edn. Wiley, NY
Bishop C. M., 1995, Neural Networks for Pattern Recognition. Oxford Univ. Press, Oxford
Chang C.-C., Lin C.-J., 2011, ACM Trans. Intelligent Syst. Technol., 2, 27
Shanno D. F., 1970, Math. Comput., 24, 647
Holland J. H., 1975, Adaptation in Natural and Artificial Systems. University of Michigan Press,
Ann Arbor
Bayesian Networks with Matlab http://code.google.com/p/bnt/