building big data applications on aws
TRANSCRIPT

Ran Tessler, Manager, Solutions ArchitectureJune 2016
Building Big Data Applications on AWS

A Modern Take on Alchemy
Turning Data into Actionable Insights

What to Expect from this Session
Big Data architectural principles Reference Lambda ArchitectureCase study: ironSource Atom Data Flow ManagemnetLive demo

Architectural Principles
• Decoupled “data bus”Data → Store → Process → Answers
• Use the right tool for the jobLatency, throughput, access patterns
• Apply Lambda architecture ideasImmutable (append-only) log, batch/speed/serving layer
• Leverage AWS managed servicesNo/low admin
• Be cost conscious Big data ≠ big cost

Simplify Big Data Processing
Ingest / collect store process /
analyzeconsume /visualize
Time to Answer (data freshness)Throughput

Demo
http://aws.amazon.com/big-data/use-cases/

AccessLog - Common Log Format (CLF)
75.35.230.210 - - [20/Jul/2009:22:22:42 -0700]
"GET /images/pigtrihawk.jpg HTTP/1.1" 200 29236

Did NASA’s STS-69 Mission Land …
… On the right homepage?

Your First Big Data Application on AWS
PROCESS
STORE
ANALYZE & VISUALIZE
COLLECT

Your First Big Data Application on AWS
PROCESS
STORE
COLLECT: Amazon Kinesis Firehose
ANALYZE & VISUALIZE

Your First Big Data Application on AWS
STORE
COLLECT: Amazon Kinesis Firehose
ANALYZE & VISUALIZE
PROCESS: Amazon EMR with Spark & Hive
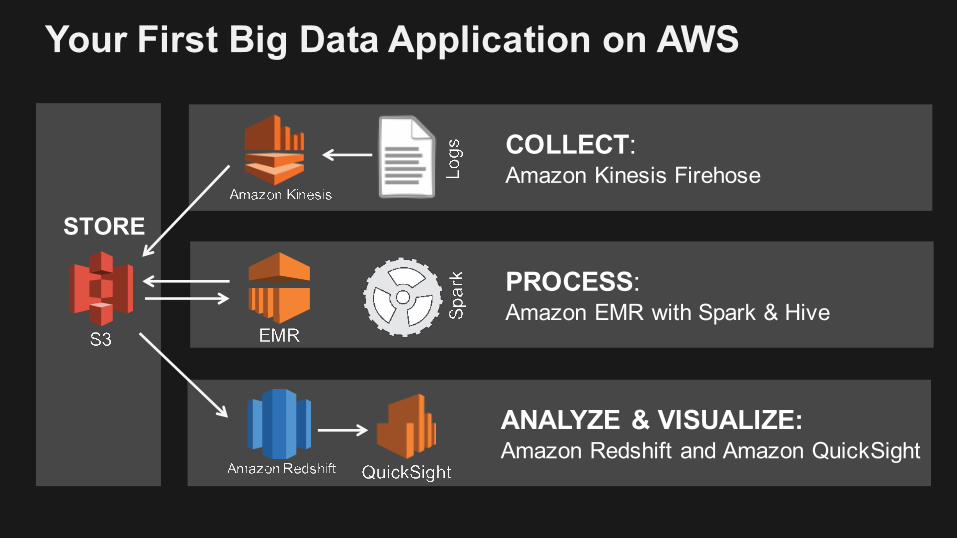
Your First Big Data Application on AWS
PROCESS: Amazon EMR with Spark & Hive
STORE
ANALYZE & VISUALIZE: Amazon Redshift and Amazon QuickSight
COLLECT: Amazon Kinesis Firehose

Shimon ToltsGeneral Manager, Data Solutions
ironSource Atom
Data Flow Management
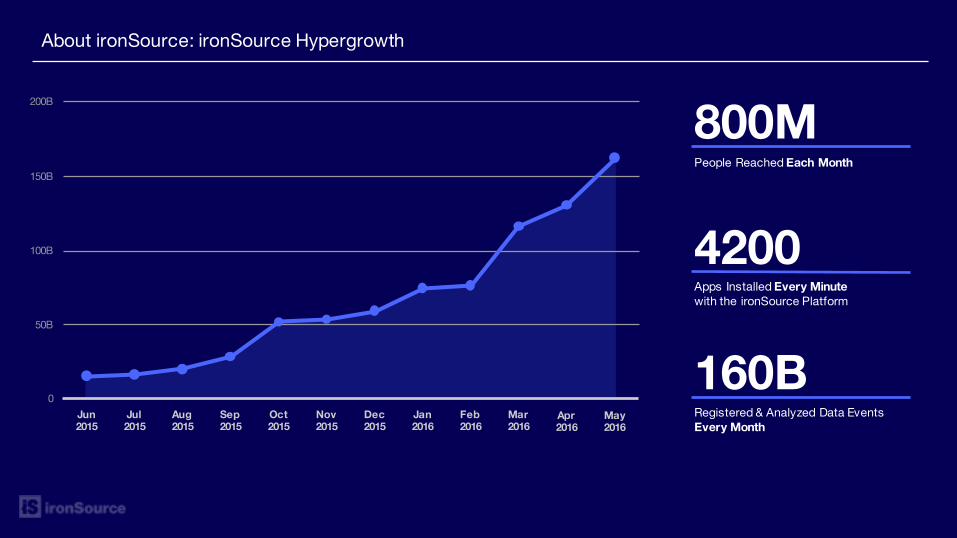
About ironSource: ironSource Hypergrowth
People Reached Each Month
4200Apps Installed Every Minutewith the ironSource Platform
Registered & Analyzed Data EventsEvery Month
160B
800M
50B
0
100B
150B
200B
Jun 2015
Jul 2015
Aug 2015
Sep 2015
Oct 2015
Nov 2015
Dec 2015
Jan 2016
Feb 2016
Mar 2016
Apr 2016
May 2016





Reference Lambda Architecture
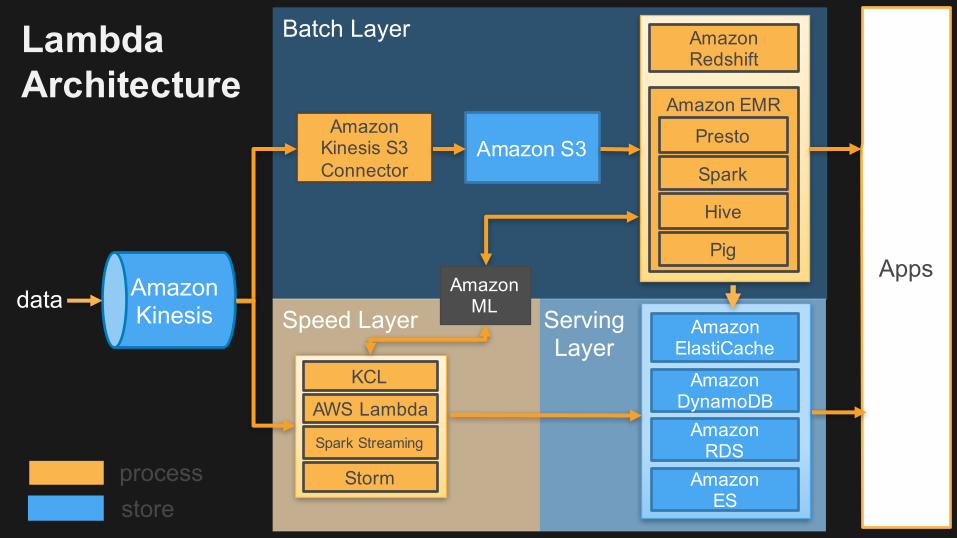
processstore
Apps
Batch Layer
Amazon Kinesis S3 Connector
Amazon S3
Amazon Redshift
Amazon EMRPresto
Hive
Pig
Spark
Lambda Architecture
Serving Layer
AmazonElastiCache
AmazonDynamoDB
AmazonRDS
AmazonES
Amazon Kinesis Speed Layer
KCL
AWS Lambda
Spark Streaming
Storm
AmazonMLdata
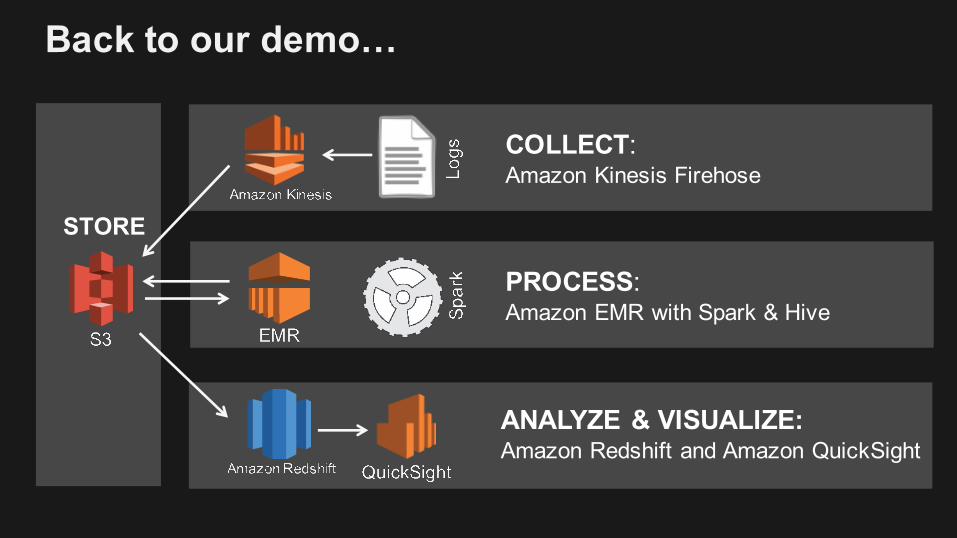
Back to our demo…
PROCESS: Amazon EMR with Spark & Hive
STORE
ANALYZE & VISUALIZE: Amazon Redshift and Amazon QuickSight
COLLECT: Amazon Kinesis Firehose

DIYDownload all steps: http://bit.ly/29fhcwu
http://aws.amazon.com/big-data/use-cases/
