cardiff feb 16-17 2005 1 statistical inference for astrophysics a short course for astronomers...
TRANSCRIPT

Cardiff Feb 16-17 20051
Statistical inference for astrophysicsA short course for astronomers
Cardiff University 16-17 Feb 2005
Graham Woan, University of Glasgow

Cardiff Feb 16-17 20052
Lecture Plan
• Why statistical astronomy?
• What is probability?
• Estimating parameters values o the Bayesian way
o the Frequentist way
• Testing hypothesesothe Bayesian way
o the Frequentist way
• Assigning Bayesian probabilities
• Monte-Carlo methods
Lectu
res 1
& 2
Lectu
res 3
& 4

Cardiff Feb 16-17 20053
Why statistical astronomy?
Benjamin DisraeliMark Twain
“There are three types of lies:lies, damned lies and
statistics”
Generally, statistics has got a bad reputation
Often for good reason:
Jun 3rd 2004
… two researchers at the University of Girona in Spain, have found that 38% of a sample of papers in Nature contained one or more statistical errors…
The Economist

Cardiff Feb 16-17 20054
Why statistical astronomy?
Data analysis methods are often regarded as simple recipes…
http://www.numerical-recipes.com/

Cardiff Feb 16-17 20055
Why statistical astronomy?
…but in analysis as in life, sometimes the recipes don’t work as you expect.
o Low number countso Distant sourceso Correlated ‘residuals’o Incorrect assumptions
Systematic errors and/orSystematic errors and/or
misleading resultsmisleading results
Data analysis methods are often regarded as simple recipes…

Cardiff Feb 16-17 20056
" The trouble is that what we [statisticians] call modern statistics was developed under strong
pressure on the part of biologists. As a result, there is practically nothing done by us which is directly
applicable to problems of astronomy."
Jerzy Neyman, founder of frequentist hypothesis testing.
Why statistical astronomy?
…and the tools can be clunky:

Cardiff Feb 16-17 20057
For example, we can observe only the one Universe:
(From Bennett et al 2003)
Why statistical astronomy?

Cardiff Feb 16-17 20058
The Astrophysicist’s Shopping List
We want tools capable of:
o dealing with very faint sources
o handling very large data sets
o correcting for selection effects
o diagnosing systematic errors
o avoiding unnecessary assumptions
o estimating parameters and testing models

Cardiff Feb 16-17 20059
Why statistical astronomy?
Key question:
How do we infer properties of the Universe from incomplete and imprecise astronomical data?
Our goal:
To make the best inference, based on our observed data and any prior knowledge, reserving the right to revise our position if new information comes to light.
Let’s come to this problem afresh with an astrophyicist’s eye, and bypass some of the jargon of orthodox statistics, going
right back to plain probability:

Cardiff Feb 16-17 200510
Herodotus, c.500 BC
“A decision was wise, even though it led to disastrous consequences, if with the evidence at hand indicated it was the best one to make; and a decision was foolish, even though it led to the happiest possible consequences, if it was unreasonable to expect those consequences”
We should do the best with what we have, not what we wished we had.
Right-thinking gentlemen #1

Cardiff Feb 16-17 200511
“Probability theory is nothing but common sense reduced to calculation”
Pierre-Simon Laplace(1749 – 1827)
Right-thinking gentlemen #2

Cardiff Feb 16-17 200512
“Frustra fit per plura, quod fieri potest per pauciora.”
“It is vain to do with more what can be done with less.”
Occam’s Razor
William of Occam(1288 – 1348 AD)
Everything else being equal, we favour models which are simple.
Right-thinking gentlemen #3

Cardiff Feb 16-17 200513
The meaning of probability
Definitions, algebra and useful distributions

Cardiff Feb 16-17 200514
But what is “probability”?
• There are three popular interpretations of the word, each with an interesting history:– Probability as a measure of our degree of belief in a statement– Probability as a measure of limiting relative frequency of outcome
of a set of identical experiments– Probability as the fraction of favourable (equally likely) possibilities
• We will call these the Bayesian, Frequentist and Combinatorial interpretations.
• Note there are signs of trouble here:– How do you quantify “degree of belief”?– How do you define “relative frequency” without using ideas of
probability?– What does “equally likely” mean?
• Thankfully, at some level, all three interpretations agree on the algebra of probability, which we will present in Bayesian terms:

Cardiff Feb 16-17 200515
Algebra of (Bayesian) probability
• Probability [of a statement, such as “y = 3”, “the mass of a neutron star is 1.4 solar masses” or “it will rain tomorrow”] is a number between 0 and 1, such that
• For some statement X,
where the bar denotes the negation of the statement -- The Sum Rule
• If there are two statements X and Y, then joint probability
where the vertical line denotes the conditional statement “X given Y is true” – The Product Rule
1)()( XpXp
1)sure notif (0
0)falseif (
1)trueif (
p
p
p
)|()(),( YXpYpYXp

Cardiff Feb 16-17 200516
Algebra of (Bayesian) probability
• From these we can deduce that
where “+” denotes “or” and I represents common background information -- The Extended Sum Rule
• …and, because p(X,Y)=p(Y,X), we get
which is called Bayes’ Theorem
• Note that these results are also applicablein Frequentist probability theory, with a suitable change in meaning of “p”.
)|,()|()|()|( IYXpIYpIXpIYXp
)|(),|()|(
),|(IYp
IXYpIXpIYXp
Thomas Bayes(1702 – 1761 AD)

Cardiff Feb 16-17 200517
Bayes’ theorem is the appropriate rule for updating our degree of belief when we have new data:
)|(),|()|(
),|(IYp
IXYpIXpIYXp
)|data()|model(),model|data(
)data,|model(Ip
IpIpIp
Likelihood Prior
Evidence
Posterior
We can usually calculate all these terms
Algebra of (Bayesian) probability
[note that the word evidence is sometimes used for something else (the ‘log odds’). We will
stick to the p(d|I) definition here.]

Cardiff Feb 16-17 200518
Algebra of (Bayesian) probability
• We can also deduce the marginal probabilities. If X and Y are propositions that can take on values drawn from and then
this gives use the probability of X when we don’t care about Y. In these circumstances, Y is known as a nuisance parameter.
• All these relationships can be smoothly extended from discrete probabilities to probability densities, e.g.
where “p(y)dy” is the probability that y lies in the range y to y+dy.
},,...,,{ 21 nxxxX },,...,,{ 21 myyyY
mj
jimj
ijimj
ijii yxpxypxpxypxpxp..1..1..1
),()|()()|()()(
=1
yyxpxp d),()(

Cardiff Feb 16-17 200519
These equations are the key to Bayesian Inference – the methodology upon which (much) astronomical data analysis is now founded.
Clear introduction by Devinder Sivia (OUP).
(fuller bibliography tomorrow)
Algebra of (Bayesian) probability
See also the free book by Praesenjit Saha (QMW, London).
http://ankh-morpork.maths.qmw.ac.uk/%7Esaha/book

Cardiff Feb 16-17 200520
Example…
• A gravitational wave detector may have seen a type II supernova as a burst of gravitational radiation. Burst-like signals can also come from instrumental glitches, and only 1 in 10,000 bursts is really a supernova, so the data are checked for glitches by examining veto channels. The test is expected to confirm the burst is astronomical in 95% of cases in which it truly is, and in 1% when it truly is not.
The burst passes the veto test!! What is the probability we have seen a supernova?
Answer: Denote
Let I represent the information that the burst seen is typical of those used to deduce the information in the question. Then we are told that:
glitch” a sit' says “test
supernova” a sit' says “test
glitch” a isreally “burst
supernova” a isreally “burst
G
S
01.0),|(
95.0),|(
9999.0)|(
0001.0)|(
IGp
ISp
IGp
ISp }}
Prior probabilities for S and G
Likelihoods for S and G

Cardiff Feb 16-17 200521
Example cont…
• But we want to know the probability that it’s a supernova, given it passed the veto test:
By Bayes, theorem
and we are directly told everything on the rhs except , the probability that any burst candidate would pass the veto test. If the burst is either a supernova or a hardware glitch then we can marginalise over these alternatives:
so
).,|( ISp
,)|(),|(
)|(),|(IpISp
ISpISp
)|( Ip
)|,()|,()|( IGpISpIp ),|()|(),|()|( ISpISpIGpIGp
0.9999 0.01 0.0001 0.95
01.095.00001.001.09999.0
95.00001.0),|(
ISp

Cardiff Feb 16-17 200522
Example cont…
• So, despite passing the test there is only a 1% probability that the burst is a supernova!Veto tests have to be blisteringly good if supernovae are rare.
• Why? Because most bursts that pass the test are just instrumental glitches – it really is just common sense reduced to calculation.
• Note however that by passing the test, the probability that this burst is from a supernova has increased by a factor of 100 (from 0.0001 to 0.01).
• Moral:),|(),|( ISpISp
Probability that a supernova burst gets
through the veto
(0.95)
Probability that it’s a supernova burst if it
gets through the veto(0.01)
This is the likelihood: how consistent is the data with
a particular model?
This is the posterior: how probable is the
model, given the data?

Cardiff Feb 16-17 200523
the basis of frequentist probability

Cardiff Feb 16-17 200524
•Bayesian probability theory is simultaneously a very old and a very young field:
•Old : original interpretation of Bernoulli, Bayes, Laplace…•Young: ‘state of the art’ in (astronomical) data analysis
•But BPT was rejected for several centuries because probability as degree of belief was seen as too subjective
Basis of frequentist probability
Frequentist approach

Cardiff Feb 16-17 200525
Probability = ‘long run relative frequency’ of an event
it appears at first that this can be measured objectively
e.g. rolling a die. What is ?
If die is ‘fair’ we expect
These probabilities are fixed (but unknown) numbers.
Can imagine rolling die M times.
Number rolled is a random variable – different outcome each time.
61
)6()2()1( ppp
)1(p
Basis of frequentist probability

Cardiff Feb 16-17 200526
•We define If die is ‘fair’
•But objectivity is an illusion:
assumes each outcome equally likely
(i.e. equally probable)
•Also assumes infinite series of identical trials
•What can we say about the fairness of the die after (say) 5 rolls, or 10, or 100 ?
Mn
pM
)1(lim)1(
61)1( p
Mn
pM
)1(lim)1(
Basis of frequentist probability

Cardiff Feb 16-17 200527
In the frequentist approach, a lot of mathematical machinery is specifically defined to let us address frequency questions:
•We take the data as a random sample of size M , drawn from an assumed underlying pdf
•Sampling distribution, derived from the underlying pdf and M
•Define an estimator – function of the sample data that is used to estimate properties of the pdf
But how do we decide what makes an acceptable estimator?
Basis of frequentist probability

Cardiff Feb 16-17 200528
Example: measuring a galaxy redshift
• Let the true redshift = z0 -- a fixed but unknown parameter. We use two telescopes to estimate z0 and compute sampling distributions for and modelling errors
1. Small telescopelow dispersion spectrometer
Unbiased:
Repeat observation alarge number of times average estimate isequal to z0
BUT is large due to the low dispersion.
1zp
2zp
zp ˆ
010111 |)( zzdzzpzzE
1varz
1z
2z
Basis of frequentist probability

Cardiff Feb 16-17 200529
Example: measuring a galaxy redshift
• Let the true redshift = z0 -- a fixed but unknown parameter. We use two telescopes to estimate z0 and compute sampling distributions for and modelling errors
2. Large telescopehigh dispersion spectrometer
but faulty astronomer!(e.g. wrong calibration)
Biased:
BUT is small. Which is the better estimator?
1zp
2zp
zp ˆ
2varz
1z
2z
020222 |)( zzdzzpzzE
Basis of frequentist probability

Cardiff Feb 16-17 200530
What about the sample mean?• Let be a random sample from pdf with
mean
and variance . Then
= sample mean
Can show that -- an unbiased estimator
But bias is defined formally in terms of an infinite set of randomly chosen samples, each of size M.
What can we say with a finite number of samples, each of finite size?
Before that…
Mxx ,,1 )(xp
M
iix
M 1
1
)( E
2
Basis of frequentist probability

Cardiff Feb 16-17 200531
Some important probability
distributionsquick definitions

Cardiff Feb 16-17 200532
1) Poisson pdf
e.g. number of photons / second counted by a CCD,
number of galaxies / degree2 counted by a survey
!)(
ne
npn
n = number of detections
Poisson pdf assumes detections are independent, and there is a constant rate
Can show that
01)(
nnp
Some important pdfs: discrete case

Cardiff Feb 16-17 200533
1) Poisson pdf
e.g. number of photons / second counted by a CCD,
number of galaxies / degree2 counted by a survey
!)(
ne
npn
)(np
Some important pdfs: discrete case
n

Cardiff Feb 16-17 200534
2. Binomial pdf
number of ‘successes’ from N observations, for two mutuallyexclusive outcomes (‘Heads’ and ‘Tails’)
e.g. number of binary stars, Seyfert galaxies, supernovae…
r = number of ‘successes’
= probability of ‘success’ for single observation
rNrN rNr
Nrp
)1(
)!(!!
)(
Can show that
0
1)(r
N rp
Some important pdfs: discrete case

Cardiff Feb 16-17 200535
1) Uniform pdf
otherwise 0
1)(
bxaabxp
0 a b
1b-a
p(x)
x
Some important pdfs: continuous case

Cardiff Feb 16-17 200536
1) Central, or Normal pdf(also known as Gaussian )
2
21
exp21
)(
xxp
5.0
1
x
p(x)
x
Some important pdfs: continuous case

Cardiff Feb 16-17 200537
= Prob( x < a )
a
dxxpaP )()(
x
)(xP
x
Cumulative distribution function (CDF)

Cardiff Feb 16-17 200538
The nth moment of a pdf is defined as
dxIxpxx
Ixpxx
nn
x
nn
)|(
)|(0
Discrete case
Continuous case
Measures and moments of a pdf

Cardiff Feb 16-17 200539
The 1st moment is called the mean or expectation value
dxIxpxxxE
IxpxxxEx
)|()(
)|()(0
Discrete case
Continuous case
Measures and moments of a pdf

Cardiff Feb 16-17 200540
The 2nd moment is called the mean square
dxIxpxx
Ixpxxx
)|(
)|(
22
0
22Discrete case
Continuous case
Measures and moments of a pdf

Cardiff Feb 16-17 200541
The variance is defined as
and is often written . is called the standard deviation
Discrete case
Continuous case
2 2
22var xxx In general
Measures and moments of a pdf
dxIxpxxx
Ixpxxxx
)|(var
)|(var
2
0
2

Cardiff Feb 16-17 200542
pdf mean variance
2
Poisson
Binomial
Uniform
Normal
!)(
re
rpr
rNrN rNr
Nrp
)1(
)!(!!
)( N )1( N
2
21
exp21
)(
XXp
abXp 1)( ba 21 212
1 ab
Measures and moments of a pdf
discrete
continuous
Cardiff Feb 16-17 200543
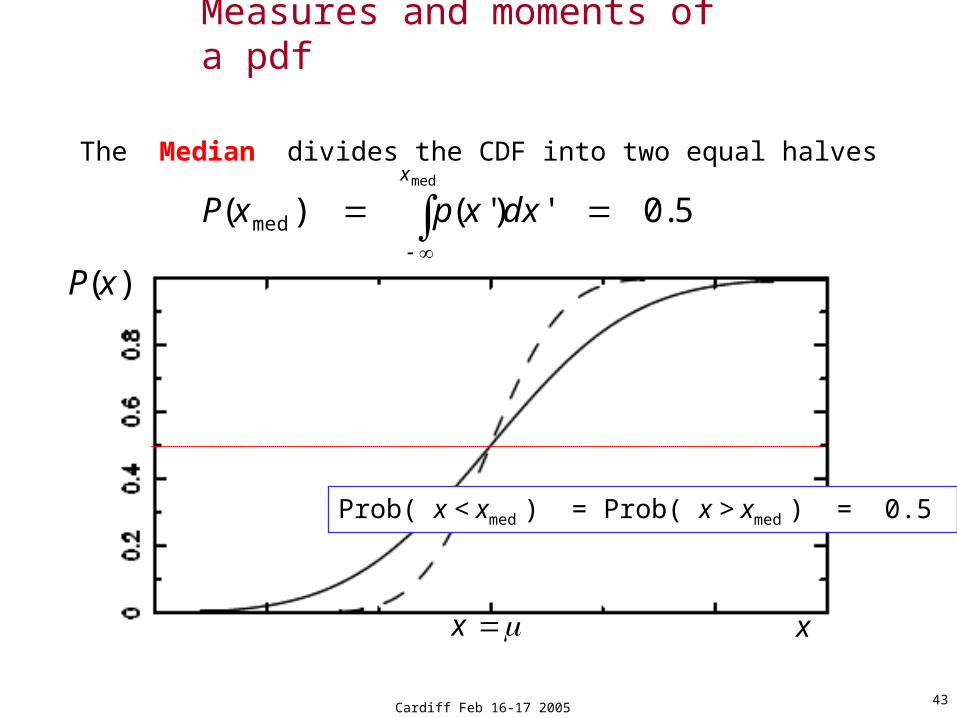
The Median divides the CDF into two equal halves
x
)(xP
x
5.0')'()(med
med
x
dxxpxP
Prob( x < xmed ) = Prob( x > xmed ) = 0.5
Measures and moments of a pdf

Cardiff Feb 16-17 200544
The Mode is the value of x for which the pdf is a maximum
5.0
1
x
p(x)
x
For a Normal pdf, mean = median = mode =
Measures and moments of a pdf

Cardiff Feb 16-17 200545
Parameter estimation
The Bayesian way

Cardiff Feb 16-17 200546
)|model(),model|data()data,|model( IpIpIp
Likelihood PriorPosterior
What we know now Influence of our observations
What we knew before
In the Bayesian approach, we can test our model, in the light of our data (i.e. rolling the die) and see how our degree of belief in its ‘fairness’ evolves, for any sample size, considering only the data that we did actually observe.
Bayesian parameter estimation

Cardiff Feb 16-17 200547
We want to know the fraction of Seyfert galaxies that are type 1.
How large a sample do we need to reliably measure this?
Model as a binomial pdf: = global fraction of Seyfert 1s
Suppose we sample N Seyferts, and observe r Seyfert 1srNr
N Nrp )1(),|( probability of obtainingobserved data, given model – the likelihood of
Astronomical example #1:
Probability that a galaxy is a Seyfert 1
Bayesian parameter estimation

Cardiff Feb 16-17 200548
• But what do we choose as our prior? This has been the source of much argument between Bayesians and frequentists, though it is often not that important.
•We can sidestep this for a moment, realising that if our data are good enough, the choice of prior shouldn’t matter!
)|model(),model|data()data,|model( IpIpIp
Likelihood PriorPosterior
Dominates
Bayesian parameter estimation

Cardiff Feb 16-17 200549
p(
|
I )
Flat prior; all values of
equally probable
Normal prior;peaked at = 0.5
Consider a simulation of this problem using two different priors
Bayesian parameter estimation

Cardiff Feb 16-17 200550
After observing 0 galaxies
p(
| d
ata
, I )

Cardiff Feb 16-17 200551
After observing 1 galaxy: Seyfert 1
p(
| d
ata
, I )

Cardiff Feb 16-17 200552
After observing 2 galaxies: S1 + S1
p(
| d
ata
, I )

Cardiff Feb 16-17 200553
After observing 3 galaxies: S1 + S1 + S2
p(
| d
ata
, I )

Cardiff Feb 16-17 200554
After observing 4 galaxies: S1 + S1 + S2 + S2
p(
| d
ata
, I )

Cardiff Feb 16-17 200555
After observing 5 galaxies: S1 + S1 + S2 + S2 + S2
p(
| d
ata
, I )

Cardiff Feb 16-17 200556
After observing 10 galaxies: 5 S1 + 5 S2
p(
| d
ata
, I )

Cardiff Feb 16-17 200557
After observing 20 galaxies: 7 S1 + 13 S2
p(
| d
ata
, I )

Cardiff Feb 16-17 200558
After observing 50 galaxies: 17 S1 + 33 S2
p(
| d
ata
, I )

Cardiff Feb 16-17 200559
After observing 100 galaxies: 32 S1 + 68 S2
p(
| d
ata
, I )

Cardiff Feb 16-17 200560
After observing 200 galaxies: 59 S1 + 141 S2
p(
| d
ata
, I )

Cardiff Feb 16-17 200561
After observing 500 galaxies: 126 S1 + 374 S2
p(
| d
ata
, I )

Cardiff Feb 16-17 200562
After observing 1000 galaxies: 232 S1 + 768 S2
p(
| d
ata
, I )

Cardiff Feb 16-17 200563
What do we learn from all this?
•As our data improve (e.g. our sample increases), the posterior pdf narrows and becomes less sensitive to our choice of prior.
• The posterior conveys our (evolving) degree of belief in different values of , in the light of our data
• If we want to express our result as a single number we could perhaps adopt the mean, median, or mode
• We can use the variance of the posterior pdf to assign anuncertainty for
• It is very straightforward to define confidence intervals
Bayesian parameter estimation
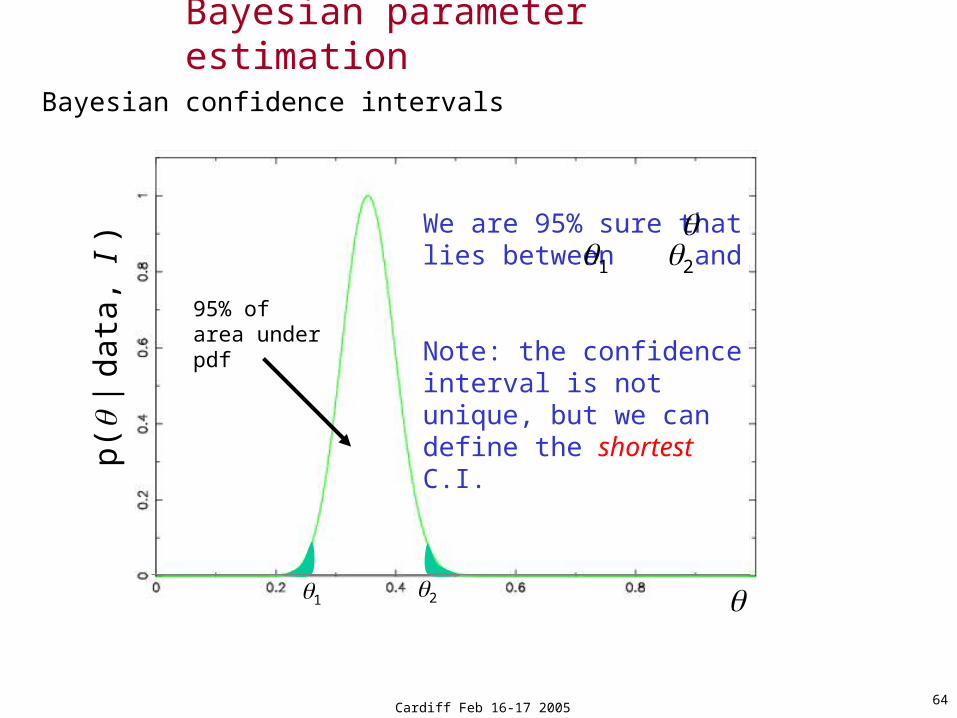
Cardiff Feb 16-17 200564
p(
| d
ata
, I )
95% of area under pdf
12
We are 95% sure thatlies between and
Note: the confidence interval is not unique, but we can define the shortest C.I.
1 2
Bayesian confidence intervals
Bayesian parameter estimation

Cardiff Feb 16-17 200565
Bayesian parameter estimation
Astronomical example #2:
Flux density of a GRBTake Gamma Ray Bursts to be equally luminous events, distributed homogeneously in the Universe. We see three gamma ray photons from a GRB in an interval of 1 s. What is the flux of the source, F?
•The seat-of-the-pants answer is F=3 photons/s, with an uncertainty of about , but we can do better than that by including our prior information on luminosity and homogeneity. Call this background information I:
3
Homogeneity implies that the probability the source is in any particular volume of space is proportional to the volume, so the prior probability that the source is in a thin shell of radius r is
drrdrIrp 24)|(

Cardiff Feb 16-17 200566
• But the sources have a fixed luminosity, L, so r and F are directly related by
• The prior on F is therefore
Interpretation: low flux sources are intrinsically more probable, as there is more space for them to sit in.
• We now apply Bayes’ theorem to determine the posterior for F after seeing n photons:
Bayesian parameter estimation
3
24
rdrdF
rL
F
hence
2/5)|()|( FdFdr
IrpIFpF
p(F|I)
),|()|(),|( IFnpIFpInFp
Cardiff Feb 16-17 200567
1 2 3 4 50
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
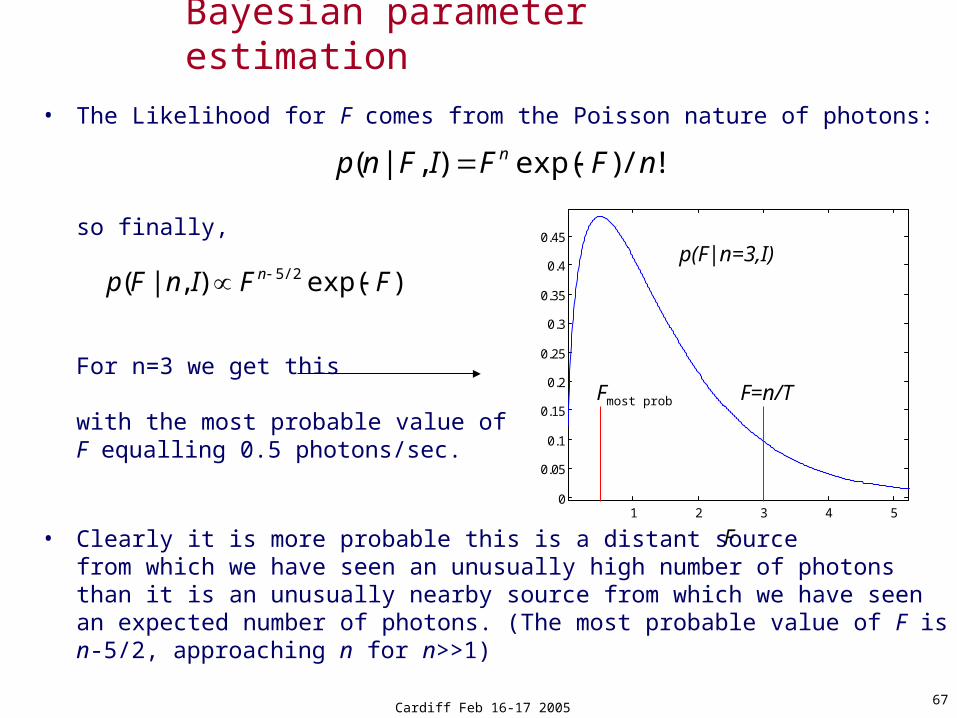
• The Likelihood for F comes from the Poisson nature of photons:
so finally,
For n=3 we get this
with the most probable value ofF equalling 0.5 photons/sec.
• Clearly it is more probable this is a distant sourcefrom which we have seen an unusually high number of photons than it is an unusually nearby source from which we have seen an expected number of photons. (The most probable value of F is n-5/2, approaching n for n>>1)
Bayesian parameter estimation
!/)exp(),|( nFFIFnp n
)exp(),|( 2/5 FFInFp n
F
p(F|n=3,I)
F=n/T
Fmost prob

Cardiff Feb 16-17 200568
Parameter estimation
The frequentist way

Cardiff Feb 16-17 200569
• Recall that in frequentist (orthodox) statistics, probability is limiting relative frequency of outcome, so :
only random variables can have frequentist probabilities
as only these show variation with repeated measurement. So we can’t talk about the probability of a model parameter, or of a hypothesis. E.g., a measurement of a mass is a RV, but the mass itself is not.
• So no orthodox probabilistic statement can be interpreted as directly referring to the parameter in question! For example, orthodox confidence intervals do not indicate the range in which we are confident the parameter value lies. That’s what Bayesian intervals do.
• So what do they mean? …
Frequentist parameter estimation

Cardiff Feb 16-17 200570
• Orthodox parameter estimate proceeds as follows: Imagine we have some data, {di}, that we want to use to estimate the value of a parameter, a, in a model. These data must depend on the true value of a in a known way, but as they are random variables all we can say is that we know, or can estimate, p({di}) for some given a.
1. Use the data to construct a statistic (i.e. a function of the data) that can be used as an estimator for a called . A good estimator will have a pdf that depends heavily on a, and which is sharply peaked at, or very close to, a.
Frequentist parameter estimation
a
)|ˆ( aap
a
Measured value of a
a

Cardiff Feb 16-17 200571
2. One such estimator is the maximum likelihood (ML) estimator, constructed in the following way: given the distribution from which the data are drawn, p(d|a), construct the sampling distribution p({di}|a), which is just p(d1|a). p(d2|a). p(d3|a)… if the data are independent. Interpret this as a function of a, called the Likelihood of a, and call the value of a that maximises it for the given data . The corresponding sampling distribution, , is the one from which the data were ‘most likely’ drawn.
Frequentist parameter estimation
a
)(aL
MLa
)ˆ|}({MLi
adpML
a

Cardiff Feb 16-17 200572
…but remember that this is just one value of , albeit drawn from a population that has an attractive average behaviour:
And we still haven’t said anything about a.
3. Define a confidence interval around a enclosing, say, 95% of the expected values of from repeated experiments:
Frequentist parameter estimation
MLa
)|ˆ( aapML
a
Measured value of ML
a
MLa
MLa
MLa
)|ˆ( aapML
a
2

Cardiff Feb 16-17 200573
may be known from the sampling pdf or it may have to be estimated too.
4. We can now say that . Note this is a probabilistic statement about the estimator, not about a. However this expression can be restated: 0.95 is the relative frequency with which the statement ‘a lies in the region ’ is true, over many repeated experiments.
Frequentist parameter estimation
95.0)ˆ(Prob aaaML
ML
a
Different experiments
No
No
Yes
Yes
Yes
The disastrous shorthand for this is
Note that this is not a statement about our degree of belief that a
lies in the numerical interval generated in our particular
experiment.
a
"confidence 95% with ˆ" ML
aa

Cardiff Feb 16-17 200574
Example: B and F compared
• Two gravitational wave (GW) detectors see 7 simultaneous burst-like signal in the data from one hour, consisting of GW signals and spurious signals. When the two sets of data are offset in time by 10 minutes there are 9 simultaneous signals. What is the true GW burst rate?
(Note: no need to be a expert to realise there is not much GW activity here!)
• A frequentist solution:Take the events as Poisson, characterised by the background rate, rb and the GW rate, rg. We get
479ˆ and
2)97(ˆ so
9ˆ ;9ˆ
7ˆ ;7
g
g
bb
gbgb
r
r
rr
Where is the variance of the sampling
distribution
2
Cardiff Feb 16-17 200575
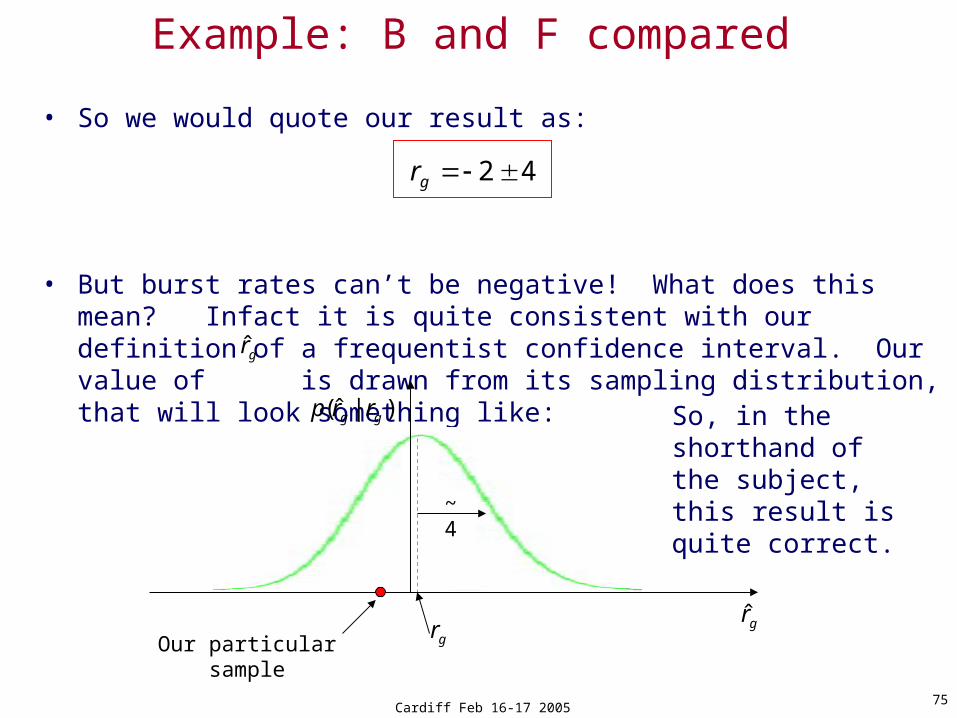
• So we would quote our result as:
• But burst rates can’t be negative! What does this mean? Infact it is quite consistent with our definition of a frequentist confidence interval. Our value of is drawn from its sampling distribution, that will look something like:
Example: B and F compared
42gr
gr
gr
)|ˆ( gg rrp
grOur particular sample
~4
So, in the shorthand of the subject, this result is quite correct.

Cardiff Feb 16-17 200576
• The Bayesian solution: We’ll go through this carefully. Our job is to determine rg. In Bayesian terms that means we are after p(rg|data). We start by realising there are two experiments here: one to determine the background rate and one to determine the joint rate, so we will also determine p(rb|data).
If the background count comes from a Poisson process of mean rb then the probability of n events is
which is our Bayesian likelihood for rb. We will choose a prior probability for rb proportional to 1/rb. This is the scale invariant prior that encapsulates total ignorance of the non-zero rate (of course in reality we may have something that constrains rb more tightly a priori). See later…
Example: B and F compared
!)exp(
)|(n
rrrnp b
nb
b

Cardiff Feb 16-17 200577
• So our posterior for rb, based on the background counts, is
which, normalising and setting n=9, gives
• The probability of seeing m coincident bursts, given the two rates, is
Example: B and F compared
!)exp(1
)|(n
rrr
nrp bnb
bb
)exp(!81
)9|( 8bbb rrnrp
0 2 4 6 8 10 12 14 16 18 200
0.05
0.1
rb
p(r b|n=9)
Background rate
!
)](exp[)(),|(
m
rrrrrrmp gb
mgb
gb

Cardiff Feb 16-17 200578
• And our joint posterior for the rates is, by Bayes’ theorem,
The joint prior in the above can be split into a probability for rb, which we have just evaluated, and a prior for rg. This may be zero, so we will say that we are equally ignorant over whether to expect 0,1,2,… counts from this source. This translates into a uniform prior on rg, so our joint prior is
Finally we get the posterior on rg by marginalising over rb:
Example: B and F compared
),|(),()|,( gbgbgb rrmprrpmrrp
)exp(!81
),( 8bbbg rrrrp
bgbgbbbg drrrrrrrmrp )](exp[)(!7
1).exp(!81)7|( 78
prior likelihood

Cardiff Feb 16-17 200579
0 1 2 3 4 5 6 7 8 9 100
0.05
0.1
0.15
0.2
0.25
rg
p(r g|n=9,m=7)
Example: B and F compared
...giving our final answer to the problem
Note that p(rg<0)=0, due to the prior, and that the true value of rg could very easily be as high as 4 or 5
42gr
Compare with our
frequentist result:
to 1-sigma
rg
p(rg|n=9,m=7)

Cardiff Feb 16-17 200580
0 5 10 150
0.02
0.04
0.06
0.08
0.1
0.12
0.14
rg
p(r g|n=3,m=7)
Let’s see how this result would change if the background count was 3, rather than 9 (joint count still 7):
Example: B and F compared
Again, this looks very reasonable
p(rg|n=3,m=7)
rg

Cardiff Feb 16-17 200581
Bayesian hypothesis testing
And why we already know how to do it

Cardiff Feb 16-17 200582
Bayesian hypothesis testing
• In Bayesian analysis, hypothesis testing can be performed as a generalised application of Bayes’ theorem. Generally a hypothesis differs from a parameter in that many values of the parameter(s) are consistent with one hypothesis. Hypotheses are models that depend of parameters.
• Note however that we cannot define the probability of one hypothesis given some data, d, without defining all the alternatives in its class, i.e.
and often this is impossible. So questions like “do the data fit a gaussian?” are not well-formed until you list all the curves the data could fit. A well-formed question would be “do the data fit a gaussian better than these other curves?”, or more usually “do the data fit a gaussian better than a lorentzian?”.
• Simple comparisons can be expressed as an odds ratio, O
hypotheses possible all
111 ),|prob()|prob(
),|prob()|prob(),|prob(
IHdIHIHdIH
IdHii
),|prob()|prob(),|prob()|prob(
),|prob(),|prob(
22
11
2
112 IHdIH
IHdIHIdHIdH
O

Cardiff Feb 16-17 200583
• The odds ratio an be divided into the prior odds and the Bayes’ factor
• The prior odds simply express our prior preference for H1 over H2, and is set to 1 if you are indifferent.
• The Bayes’ factor is just the ratio of the evidences, as defined in the earlier lectures. Recall that for a model that depends on a parameter a
so the evidence is simply the joint probability of the parameter(s) and the data, marginalised over all hypothesis parameter values:
factor Bayes'
2
1
oddsprior
2
1
2
112 ),|prob(
),|prob()|prob()|prob(
),|prob(),|prob(
IHdIHd
IHIH
IdHIdH
O
Bayesian hypothesis testing
),|(),,|(),|(
),,|(1
111 IHdp
IHadpIHapIHdap
aIHadpIHapIHdp d),,|(),|(),|( 111

Cardiff Feb 16-17 200584
• Example: A spacecraft is sent to a moon of Saturn and, using a penetrating probe, detects a liquid sea deep under the surface at 1 atmosphere pressure and a temperature of -3°C. However, the thermometer has a fault, so that the temperature reading may differ from the true temperature by as much as ±5°C, with a uniform probability within this range.
Determine the temperature of the liquid, assuming it is water (liquid within 0<T<100°C) and then assuming it is ethanol (liquid within -80<T<80°C). What are the odds of it being ethanol?
[based loosely on a problem by John Skilling]
Bayesian hypothesis testing
Ethanol is liquid
water is liquid
-80 0 80 100 °C
measurement

Cardiff Feb 16-17 200585
• Call the water hypothesis H1 and the ethanol hypothesis H2.For H1:The prior on the temperature is
the likelihood of the temperature is the probability of the data d, given the temperature:
thought of as a function of T, for d=-3,
Bayesian hypothesis testing
otherwise 0
1000for 01.0)|( 1
THTp
0 100 T
otherwise 0
5||for 1.0),|( 1
TdHTdp
)|( 1HTp
T d10
),|( 1HTdp
-3
T
10
),|3( 1HTdp

Cardiff Feb 16-17 200586
The posterior for T is the normalised product of the prior and the likelihood, giving
H1 only allows the temperature to be between 0 and 2°C.
The evidence for water (as we defined it) is
• For H2:By the same arguments
and the evidence for ethanol is
Bayesian hypothesis testing
otherwise 0
20for 5.0),|( 1
THdTp
0 2 T
),|( 1HdTp
002.0d)|(),|()|( 111 THTpHTdpHdp
otherwise 0
28for 1.0),|( 2
THdTp
-8 0 2 T
),|( 2HdTp
00625.0d)|(),|()|( 222 THTpHTdpHdp

Cardiff Feb 16-17 200587
• So under the water hypothesis we have a tighter possible range for the liquid’s temperature, but it may not be water. In fact, the odds of it being water rather than ethanol are
which means 3:1 in favour of ethanol. Of course this depends on our prior odds too, which we have set to 1. If the choice was between water and whisky under the surface of the moon the result would be very different, though the Bayes’ factor would be roughly the same!
• Why do we prefer the ethanol option? Because too much of the prior for temperature, assuming water, falls at values that are excluded by the data. In other words, the water hypothesis is unnecessarily complicated . Bayes’ factors naturally implement Occam’s razor in a quantitative way.
Bayesian hypothesis testing
32.000625.0002.0
1),|prob(),|prob(
)|prob()|prob(
),|prob(),|prob(
factor Bayes'
2
1
oddsprior
2
1
2
112
IHdIHd
IHIH
IdHIdH
O

Cardiff Feb 16-17 200588
),|( 1HTdp
),|( 2HTdp
)|( 1HTp
)|( 2HTp
T
T
Overlap integral (=evidence) is greater for H2 (ethanol) than for H1 (water)
Bayesian hypothesis testing
-8 0 2
-8 0 2
0.01
0.00625
0.1
0.1
002.001.01.02d)|(),|( 11 THTpHTdp
00625.000625.01.010d)|(),|( 22 THTpHTdp

Cardiff Feb 16-17 200589
• To look at this a bit more generally, we can split the evidence into two approximate parts, the maximum of the likelihood and an “Occam factor”:
i.e., evidence = maximum likelihood x Occam factorThe Occam factor penalises models that include wasted parameter space, even if they show a good ML fit.
Bayesian hypothesis testing
prior
likelihood
xPrior_range
Likelihood_range
factor' Occam' the
max eprior_rang_rangelikelihood
d),|()|()|( LxHxdpHxpHdp
Lmax

Cardiff Feb 16-17 200590
• This is a very powerful property of the Bayesian method.
Example: your given a time series of 1000 data points comprising a number of sinusoids embedded in gaussian noise. Determine the number of sinusoids and the standard deviation of the noise.
• We could think of this as comparing hypotheses Hn that there are n sinusoids in the data, with n ranging from 0 to nmax. Equivalently, we could consider it as a parameter fitting problem, with n an unknown parameter within the model.
The joint posterior for the n signals, with amplitudes {A}n and frequencies {}n and noise variance given the overall model and data {D} is
The likelihood term, based on gaussian noise is
and we can set the priors as independent and uniform over sensible ranges.
Bayesian hypothesis testing
),}{,}{,|}({)|,}{,}{,()},{|,}{,}{,( nnnnnn AnDpIAnpIDAnp
2
j
n
ijiijnn tADAnDp
0
22 )sin(
21
exp21
),}{,}{,|}({

Cardiff Feb 16-17 200591
• Our result for n is just its marginal probability:
and similarly we could marginalise for . Recent work, in collaboration with Umstatter and Christensen, has explored this:
d}{d}{d)},{|,}{,}{,()},{|( ,}{,}{ nnnnA nn AIDAnpIDnp
Bayesian hypothesis testing
•1000 data points with 50 embedded signals
=2.6
Result: around 33 signals can be recovered from the data, the rest are indistinguishable from noise, and is consequentially higher

Cardiff Feb 16-17 200592
• This has implications for the analysis of LISA data, which is expected to contain many (perhaps 50,000) signals from white dwarf binaries. The data will contain resolvable binaries and binaries that just contribute to the overall noise (either because they are faint or because their frequencies are too close together).
Bayes can sort these out without having to introduce ad hoc acceptance and rejection criteria, and without needing to know the “true noise level” (whatever that means!).
Bayesian hypothesis testing

Cardiff Feb 16-17 200593
Frequentist hypothesis testing
And why we should tread carefully, if at all

Cardiff Feb 16-17 200594
• A note on why these should really be avoided!• The method goes like this:
– To test a hypothesis H1 consider another hypothesis, called the null hypothesis, H0, the truth of which would deny H1. Then argue against H0…
– Use the data you have gathered to compute a test statistic Tobs (eg, the chisquared statistic) which has a calculable pdf if H0 is true. This can be calculated analytically or by Monte Carlo methods.
– Look where your observed value of the statistic lies in the pdf, and reject H0 based on how far in the wings of the distribution you have fallen.
Frequentist hypothesis testing – significance tests
p(T|H0) Reject H0 if your result lies in here
T

Cardiff Feb 16-17 200595
• H0 is rejected at the x% level if x% of the probability lies to the right of the observed value of the statistic (or is ‘worse’ in some other sense):
and makes no reference to how improbable the value is under any alternative hypothesis (not even H1!). So…
Frequentist hypothesis testing – significance tests
An hypothesis [H0] that may be true is rejected because it has failed to predict observable results that have not occurred. This seems a remarkable procedure. On the face of it, the evidence might more reasonably be taken as evidence for the hypothesis,
not against it. Harold Jeffreys Theory of Probability
1939
p(T|H0)
TTobs
X% of the area

Cardiff Feb 16-17 200596
• Eg, You are given a data point Tobs affected by gaussian noise, drawn either from N(mean=-1,=0.5) or N(+1,0.5). H0: The datum comes from = -1 H1: The datum comes from = +1 Test whether H1 is true.
• Here our statistic is simply the value of the observed data. We will chose a critical region of T>0, so that if Tobs>0 we reject H0 and therefore accept H1.
Frequentist hypothesis testing – significance tests
H0
H1
T -1 +1

Cardiff Feb 16-17 200597
• Formally, this can go wrong in two ways:– A Type I error occurs when we reject the null hypothesis when it is true– A Type II error occurs when we accept the null hypothesis when it is false
both of which we should strive to minimise• The probabilities (‘p-values’) of these are shown as the coloured areas
above (about 5% for this problem)
• If Tobs>0 then we ‘reject the null hypothesis at the 5% level’ and therefore accept H1.
Frequentist hypothesis testing
T
Type II error
Type I error

Cardiff Feb 16-17 200598
• But note that we do not consider the relative probabilities of the hypotheses (we can’t! Orthodox statistics does not allow the idea of hypothesis probabilities), so the results can be misleading.
• For example, let Tobs=0.01. This lies just on the boundary of the critical region, so we reject H0 in favour of H1 at the 5% level, despite the fact that we know a value of 0.01 is just as likely under both hypotheses (acutally just as unlikely, but it has happened).
• Note that the Bayes’ factor for this same result is ~1, reflecting the intuitive answer that you can’t decide between the hypotheses based on such a datum.
Moral
The subtleties of p-values are rarely reflected in papers that quote them, and many errors of Type III (misuse!) occur. Always take them with a pinch of salt, and avoid them if possible – there are better tools available.
Frequentist hypothesis testing

Cardiff Feb 16-17 200599
Assigning Bayesian probabilities
(you have to start somewhere!)

Cardiff Feb 16-17 2005100
Assigning Bayesian probabilities
• We have done much on the manipulation of probabilities, but not much on the initial assignments of likelihoods and priors. Here are a few words…
The principle of insufficient reason (Bernoulli, 1713) helps us out: If we have N mutually exclusive possibilities for an outcome, and no reason to believe one more than another, then each should be assigned the probability 1/N.
• So the probability of throwing a 6 on a die is 1/6, if all you know is it has 6 faces.
• The key is to realise that this is one example of a more general principle. Your state of knowledge is such that the probabilities are invariant under some transformation group (here, the exchange of numbers on faces).
• Using this idea we can extend the principle of insufficient reason to continuous parameters.

Cardiff Feb 16-17 2005101
• So, a parameter that is not known to within a change of origin (a ‘location parameter’) should have a uniform probability
• A parameter for which you have no knowledge of scale (a ‘scale parameter’) is a location parameter in its log so
the so-called ‘Jeffreys prior’.
• Note that both these prior are improper – you can’t normalise them, so their unfettered use is restricted. However, you are rarely that ignorant about the value of a parameter.
Assigning Bayesian probabilities
constant)()( axpxp
xxp
1)(

Cardiff Feb 16-17 2005102
• More generally, given some information, I, that we wish to use to assign probabilities {p1…pn} to n different possibilities, then the most honest way of assigning the probabilities is the one that maximises
subject to the constraints imposed by I. H is traditionally called the information entropy of the distribution and measures the amount of uncertainty in the distribution in the sense of Shannon (though there are several routes to the same result). Honesty demands we maximise this, otherwise we are implicitly imposing further constraints not contained in I.
• For example, the maximum entropy solution for the probability of seeing k events given only the information that they are characterised by a single rate constant is the Poisson distribution. If you are told the first and second moments of a continuous distribution the maxent solution is a gaussian etc…
Assigning Bayesian probabilities
n
iii ppH
1log

Cardiff Feb 16-17 2005103
Monte Carlo methods
How to do those nasty marginalisations

Cardiff Feb 16-17 2005104
1. Uniform random number, U[0,1]
See Numerical Recipes!
http://www.numerical-recipes.com/
Monte Carlo Methods

Cardiff Feb 16-17 2005105
2. Transformed random variables
Suppose we have
Let
Then
)(xyy
]1,0[~Ux
xxpyyp d)(d)(
Probability of number between y and y+dy
Probability of number between x and x+dx
xyyxp
ypdd))((
)(
Because probability must be positive
Monte Carlo Methods

Cardiff Feb 16-17 2005106
2. Transformed random variables
Suppose we have
Let
Then
]1,0[~Ux
xabay )(
],[~ baUy
0 a b
1b-a
p(y)
y
Monte Carlo Methods
Numerical Recipes uses the transformation method to provide )1,0(~Ny

Cardiff Feb 16-17 2005107
3. Probability integral transform
Suppose we can compute the CDF of some desired random variable
1)
2) Compute
3) Then
]1,0[~Uy
)(1 yPx
)(~ xpx
Monte Carlo Methods

Cardiff Feb 16-17 2005108
4. Rejection Sampling
Suppose we want to sample from some pdf p(x) and we know that
where q(x) is a simpler pdf called the proposal distribution
xxqxp )()(
)(xp
)(xq1) Sample x1 from q(x)
2) Sample y~U[0,q(x1)]
3) If y<p(x) ACCEPTotherwise REJECT
1x
y
Set of accepted values {xi} are a sample from p(x).
Monte Carlo Methods

Cardiff Feb 16-17 2005109
4. Rejection Sampling
The method can be very slow if the shaded region is too large -particularly in high-N problems, such as the LISA problem considered earlier.
LISA
Monte Carlo Methods

Cardiff Feb 16-17 2005110
5. Metropolis-Hastings Algorithm
Speed this up by letting the proposal distribution depend on the current sample:
x)(p
o Sample initial point
o Sample tentative new state from (e.g. Gaussian)
o Compute
o If Accept Otherwise Accept with probability a
)1(x
)x;x'( )1(Q
)x;x'()x()x';x()x'(
(1)(1)
(1)
QpQp
a
1a
Acceptance:
Rejection:
x'x(2) (1)(2) xx
X is a Markov Chain. Note that rejected samples appear in the chain as repeated values of the current state.
Monte Carlo Methods

Cardiff Feb 16-17 2005111
http://www.statslab.cam.ac.uk/~mcmc/pages/links.html
Monte Carlo Methods
A histogram of the contents of the chain for a parameter
converges to the marginal pdf for that parameter.
In this way, high-dimensional posteriors can be explored and
marginalised to return parameter ranges and
interrelations inferred fro complex data sets (eg, the
WMAP results)

Cardiff Feb 16-17 2005112

Cardiff Feb 16-17 2005113
The end
nearly

Cardiff Feb 16-17 2005114
Final thoughts
• Things to keep in mind:
– Priors are fundamental, but not always influential. If you have good data most reasonable priors return very similar posteriors.
– Degree of belief is subjective but not arbitrary. Two people with the same degree of belief agree about the value of the corresponding probability.
– Write down the probability of everything, and marginalise over those parameters that are of no interest.
– Don’t pre-filter if you can help it. Work with the data, not statistics of the data.

Cardiff Feb 16-17 2005115
Bayesian bibliography for astronomy
There are an increasing number of good books and articles on Bayesian methods. Here are just a few:
• E.T. Jaynes, Probability theory: the logic of science, CUP 2003• D.J.C. Mackay, Information theory, inference and learning algorithms,
CUP, 2004• D.S. Sivia, Data analysis – a Bayesian tutorial, OUP 1996• T.J. Loredo, From Laplace to Supernova SN 1987A: Bayesian Inference in
Astrophysics, 1990, copy at http://bayes.wustl.edu/gregory/articles.pdf
• G.L. Bretthorst, Bayesian Spectrum Analysis and Parameter Estimation, 1988 copy at http://bayes.wustl.edu/glb/book.pdf,
• G. D'Agostini, Bayesian reasoning in high-energy physics: principles and applications http://preprints.cern.ch/cgi-bin/setlink?base=cernrep&categ=Yellow_Report&id=99-03
• Soon to appear: P. Gregory, Bayesian Logical Data Analysis for the Physical Sciences, 2005, CUP
Review sites:• http://bayes.wustl.edu/• http://www.bayesian.org/