chapter 7: channel coding: convolutional codes · i viterbi proposed an ml decoding by...
TRANSCRIPT

OutlineChannel coding
Convolutional encoderDecoding
Chapter 7: Channel coding:Convolutional codes
Vahid Meghdadi
University of [email protected]
Reference : Digital communications by John Proakis;Wireless communication by Andreas Goldsmith
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Channel coding
Convolutional encoderEncoder representation
DecodingMaximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Communication system
ChannelEncoder
Interleaver Modulator
Channel
ChannelDencoder
Deinterleaver Demodulator
Data
Output
The data is first coded then interleaved. The interleaving is usedto avoid the channel presenting burst errors. Then it is transmittedthrough a kind of modulation over a noisy channel. At thereceiver, all the operations must be inversed to estimate thetransmitted data.
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Channel coding
Channel coding can be classified in two categories:I block coding
I Cylclic codesI BCHI Reed-SolomonI Product Turbo codeI LDPC
I trellis codingI Convolutional codingI TCM (Trellis code modulation)I Turbo codes (SCCC or PCCC)I Turbo TCM
Here, we are concentrating on convolutional coding.
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Encoder representation
Convolutional encoder
ChannelEncoder
Interleaver Modulator
Channel
ChannelDencoder
Deinterleaver Demodulator
Data
Output
cv(1)
v(2)
This is the simplest convolutional encoder. The input sequence is
c = (..., c−1, c0, c1, ..., cl , ...)
where l is the time index. The output sequences are:
v(1) = (..., v(1)−1 , v
(1)0 , v
(1)1 , ..., v
(1)l , ...)
v(2) = (..., v(2)−1 , v
(2)0 , v
(2)1 , ..., v
(2)l , ...)
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Encoder representation
Convolutional code characteristics
I The constraint length of a CC is the number of input bitinvolved to generate each output bit. It is the number of thedelay elements plus one. For the previous example, theconstraint length is 3.
I Once all the output are serialized and get out of the coder, kright shift occurs.
I The code rate is defined as Rc = k/n where n is the numberof output.
I For the previous example n = 2, k = 1, and Rc = 0.5.
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Encoder representation
Describing a CC by its generator
I In the previous example, assuming all-zero state, the sequence
v(1)1 will be [101] for a 1 at the input (impulse response).
I At the same time the sequence v(2)1 will be [111] for a 1 at the
input.
I Therefore, there are two generators g1 = [101] and g2 = [111]and the encoder is completely known.
I It is convenient to represent the encoder in octal form of as(g1, g2) = (5, 7).
Exercise: Draw the encoder circuit of the code (23,35).
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Encoder representation
State diagram representation
ChannelEncoder
Interleaver Modulator
Channel
ChannelDencoder
Deinterleaver Demodulator
Data
Output
cv(1)
v(2)
State01
State00
State10
State11
00
11
00
10
01
10
11
01
input=0
input=1
Code (7,5)
Using this diagram one can easily calculate the output of the coder.Exercise: What is the coded sequence of [10011]?
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes
OutlineChannel coding
Convolutional encoderDecoding
Encoder representation
Trellis representation
00
00
1111
10
10
0101
00
00
1111
10
10
0101
00
00
1111
10
10
0101
00
11
10
01
00
11
00
11
10
01
input 0 input 1
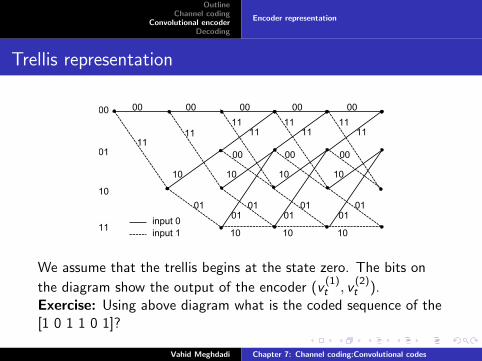
We assume that the trellis begins at the state zero. The bits on
the diagram show the output of the encoder (v(1)t , v
(2)t ).
Exercise: Using above diagram what is the coded sequence of the[1 0 1 1 0 1]?
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Modulation and the channel
The coded sequence is denoted by C. The output of the encoder ismodulated, then sent to the channel.We assume a BPSK modulation with 0→ −1 volt and 1→ +1volt. The channel adds a white Gaussian to the signal.The RX receives a real sequence R. The decoder should estimatethe transmitted sequence by observing the channel output.For the i-th information bit, corresponding to the i-th branch inthe trellis, the code sequence of size n is denoted by Cij where0 < i < n− 1. Assuming a memoryless channel, the received signalfor the i-th information bit is:
rij =√
Ec(2Cij − 1) + nij
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Maximum Likelihood decoding
Given the received sequence R, the decoder decides that the codedsequence C∗ was transmitted if
p(R|C∗) ≥ p(R|C) ∀C
It means that the decoder finds the maximum likelihood path inthe trellis given R. Thus, over an AWGN channel and for a code ofrate 1/n and for an information sequence of size L, the likelihoodcan be written as:
p(R|C) =L−1∏i=0
p(Ri |Ci ) =L−1∏i=0
n−1∏j=0
p(Rij |Cij)
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Log Likelihood function
Taking logarithm:
log p(R|C) =L−1∑i=0
log p(Ri |Ci ) =L−1∑i=0
n−1∑j=0
log p(Rij |Cij)
The expression Bi =∑n−1
j=0 log p(Rij |Cij) is called the branchmetric. Maximizing the likelihood function is equivalent tomaximizing the log likelihood function.The log likelihood function corresponding to a given path in thetrellis is called the path metric, which is the sum of the branchmetrics in the path.
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
ML and hard decoding
In hard decoding, the sequence R is demodulated and containsonly 0 and 1. This is called hard decision. The probability of errorin hard decision depends to the channel state and is represented byp. If R and C are N symbol long and differ in d places (i.e.Hamming distance), then
p(R|C) = pd(1− p)N−d
log p(R|C) = −d log1− p
p+ N log(1− p)
The second term is independent of C. Therefore only the first termshould be maximized. Conclusion: the sequence C with minimumHamming distance to the received sequence R corresponds to theML sequence.
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Soft decoding
In an AWGN with a zero mean Gaussian noise of varianceσ2 = N0/2,
p(Rij |Cij) =1√2πσ
exp
[−
(Rij −√
Ec(2Cij − 1))2
2σ2
]ML is equivalent to choose the Cij that is closest in Euclideandistance to Rij .Taking logarithm and neglecting all scaling factor and commonterms to all Ci , the branch metric is:
µi =n∑
j=1
Rij(2Cij − 1)
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Viterbi algorithm (1967)
I There are a huge number of paths to test for even moderatevalues of L. The Viterbi algorithm reduces considerably thisamount.
I Viterbi proposed an ML decoding by systematically removingpaths that cannot achieve the highest path metric.
I When two paths enter into a given node, the path with lowestlikelihood cannot be the survivor path: it can be removed.
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Viterbi algorithm
ML path
P1
P2
P3
N
Bn+1
Bn+2
Bk
Survivor path
I P1 is the survivor path because the partial path metric P1 isgreater than P2 and P3 where Pi =
∑n−1k=0 B i
k .
I The ML path starting from node N to infinity has the pathmetric of Pi +
∑∞k=n Bk (i = 1, 2, 3).
I Thus, the paths P2 and P3 cannot complete the path from nto ∞ and give a ML path. They will be discarded.
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes
OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
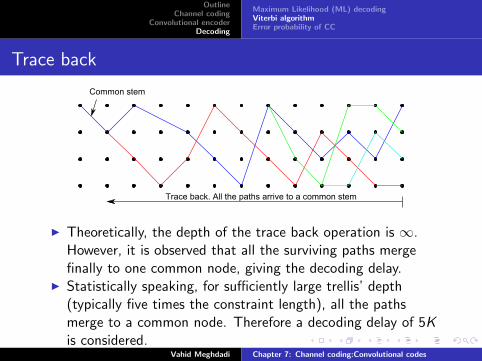
Trace back
ML path
P1
P2
P3
N
Bn+1
Bn+2
Bk
Survivor path
Trace back. All the paths arrive to a common stem
Common stem
I Theoretically, the depth of the trace back operation is ∞.However, it is observed that all the surviving paths mergefinally to one common node, giving the decoding delay.
I Statistically speaking, for sufficiently large trellis’ depth(typically five times the constraint length), all the pathsmerge to a common node. Therefore a decoding delay of 5Kis considered.
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Distance properties (example CC(7,5))
ML path
P1
P2
P3
N
Bn+1
Bn+2
Bk
Survivor path
Trace back. All the paths arrive to a common stem
Common stem
t0 t1 t2 t3 t4 t50 0 0 0 0
2 2
1 11
0
22 2
11
00
01
10
11
00
00
1111
10
10
0101
00
00
1111
10
10
0101
00
00
1111
10
10
0101
00
11
10
01
00
11
00
11
10
01
input 0 input 1
Survivor Path
tk tk+1 tk+2
path 1
path 2
path 3
Bt+1 Bt+2
00
00
1111
10
10
0101
I The error occurs when the survivor path is to be selected.
I If the Hamming distance between two sequences entering to anode is large, the probability of making error becomes small.
I The free distance of CC(7,5) is 5 corresponding to the path00-10-01-00.
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Good codes
Testing all the possible combinations of encoders, the best codesfor a given constraint length are proposed in tables.
Constraint Length Generaor in octal dfree
3 (5,7) 54 (15,17) 65 (13,35) 76 (53,75) 87 (133,171) 10
Rate 1/2 maximum free distance CC
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Good codes
Constraint Length Generaor in octal dfree
3 (5,7,7) 84 (13,15,17) 105 (25,33,37) 126 (47,53,75) 137 (133,145,175) 15
Rate 1/3 maximum free distance CC
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Error probability
I Convolutional code is linear so the Pe is calculated bysupposing all zero sequence is sent.
I Coherent BPSK over AWGN is assumed.I The energy per coded bit is related to the energy per
information bit by Ec = RcEb.I The probability of mistaking all zero sequence by another
sequence with Hamming distance of d is:
Pe(d) = Q
(√2Ec
N0d
)= Q (2γbRcd)
I This probability is called pairwise error probability.I There is no analytic expression for bit error rate but just some
upper bounds.
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes

OutlineChannel coding
Convolutional encoderDecoding
Maximum Likelihood (ML) decodingViterbi algorithmError probability of CC
Error probability
Vahid Meghdadi Chapter 7: Channel coding:Convolutional codes