chapter 7 space and time tradeoffs. space-for-time tradeoffs two varieties of space-for-time...
TRANSCRIPT

Chapter 7Chapter 7
Space and Time Space and Time TradeoffsTradeoffs

Space-for-time tradeoffsSpace-for-time tradeoffs
Two varieties of space-for-time algorithms: Two varieties of space-for-time algorithms: input enhancementinput enhancement —— preprocess the input (or its part) to preprocess the input (or its part) to
store some info to be used later in solving the problem store some info to be used later in solving the problem
• counting sortscounting sorts
• string searching algorithmsstring searching algorithms
prestructuringprestructuring —— preprocess the input to make accessing its preprocess the input to make accessing its elements easierelements easier
• hashinghashing
• indexing schemes (e.g., B-trees)indexing schemes (e.g., B-trees)

Sorting by countingSorting by counting

Sorting by countingSorting by counting
Algorithm uses same number of key comparisons as selection sort and Algorithm uses same number of key comparisons as selection sort and In addition, uses a linear amount of extra spaceIn addition, uses a linear amount of extra space It is not recommended for practical useIt is not recommended for practical use

Review: String searching by brute forceReview: String searching by brute force
patternpattern: a string of : a string of mm characters to search for characters to search for
texttext: a (long) string of : a (long) string of nn characters to search in characters to search in
Brute force algorithmBrute force algorithm
Step 1Step 1 Align pattern at beginning of textAlign pattern at beginning of text
Step 2Step 2 Moving from left to right, compare each character ofMoving from left to right, compare each character ofpattern to the corresponding character in text until pattern to the corresponding character in text until either all characters are found to match (successful either all characters are found to match (successful search) or a mismatch is detectedsearch) or a mismatch is detected
Step 3 While a mismatch is detected and the text is not yet Step 3 While a mismatch is detected and the text is not yet exhausted, realign pattern one position to the right and exhausted, realign pattern one position to the right and repeat Step 2repeat Step 2

String searching by preprocessingString searching by preprocessing
Several string searching algorithms are based on the inputSeveral string searching algorithms are based on the inputenhancement idea of preprocessing the pattern enhancement idea of preprocessing the pattern
Knuth-Morris-Pratt (KMP) algorithm preprocesses Knuth-Morris-Pratt (KMP) algorithm preprocesses pattern left to right to get useful information for later pattern left to right to get useful information for later searchingsearching
Boyer -Moore algorithm preprocesses pattern right to left Boyer -Moore algorithm preprocesses pattern right to left and store information into two tablesand store information into two tables
Horspool’s algorithm simplifies the Boyer-Moore algorithm Horspool’s algorithm simplifies the Boyer-Moore algorithm by using just one tableby using just one table

Horspool’s AlgorithmHorspool’s Algorithm
A simplified version of Boyer-Moore algorithm:A simplified version of Boyer-Moore algorithm:
• preprocesses pattern to generate a shift table that preprocesses pattern to generate a shift table that determines how much to shift the pattern when a determines how much to shift the pattern when a mismatch occurs mismatch occurs
• always makes a shift based on the text’s character always makes a shift based on the text’s character c c aligned with the aligned with the lastlast character in the pattern according character in the pattern according to the shift table’s entry for to the shift table’s entry for cc

How far to shift?How far to shift?
Look at first (rightmost) character in text that was compared: Look at first (rightmost) character in text that was compared: The character is not in the patternThe character is not in the pattern ..........cc...................... ...................... ((cc not in pattern) not in pattern)
BAOBABBAOBAB
The character is in the pattern (but not the rightmost)The character is in the pattern (but not the rightmost) .....O...................... .....O...................... ((OO occurs once in pattern) occurs once in pattern)
BAOBAB BAOBAB .....A...................... .....A...................... ((AA occurs twice in pattern) occurs twice in pattern) BAOBABBAOBAB
The rightmost characters do matchThe rightmost characters do match .....B...................... .....B...................... BAOBABBAOBAB

Shift tableShift table Shift sizes can be precomputed by the formulaShift sizes can be precomputed by the formula
distance from distance from cc’s rightmost occurrence in pattern’s rightmost occurrence in pattern among its first among its first m-m-1 characters to its right end1 characters to its right end
tt((cc) = ) = pattern’s length pattern’s length mm, otherwise, otherwise by scanning pattern before search begins and stored in aby scanning pattern before search begins and stored in a
table called table called shift tableshift table
Shift table is indexed by text and pattern alphabet Shift table is indexed by text and pattern alphabet Eg, for Eg, for BAOBAB:BAOBAB:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
1 2 6 6 6 6 6 6 6 6 6 6 6 6 3 6 6 6 6 6 6 6 6 6 6 6

Example of Horspool’s alg. applicationExample of Horspool’s alg. application
BARD LOVED BANANASBARD LOVED BANANAS
BAOBABBAOBAB
BAOBABBAOBAB
BAOBABBAOBAB
BAOBAB BAOBAB (unsuccessful search)(unsuccessful search)
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
1 2 6 6 6 6 6 6 6 6 6 6 6 6 3 6 6 6 6 6 6 6 6 6 6 6
_
6

Boyer-Moore algorithmBoyer-Moore algorithm
Based on same two ideas:Based on same two ideas:
• comparing pattern characters to text from right to leftcomparing pattern characters to text from right to left
• precomputing shift sizes in two tablesprecomputing shift sizes in two tables
– bad-symbol table bad-symbol table indicates how much to shift based on indicates how much to shift based on text’s character causing a mismatchtext’s character causing a mismatch
– good-suffix tablegood-suffix table indicates how much to shift based on indicates how much to shift based on matched part (suffix) of the patternmatched part (suffix) of the pattern

Bad-symbol shift in Boyer-Moore algorithmBad-symbol shift in Boyer-Moore algorithm
If the rightmost character of the pattern doesn’t match, BM If the rightmost character of the pattern doesn’t match, BM algorithm acts as Horspool’salgorithm acts as Horspool’s
If the rightmost character of the pattern does match, BM If the rightmost character of the pattern does match, BM compares preceding characters right to left until either all compares preceding characters right to left until either all pattern’s characters match or a mismatch on text’s pattern’s characters match or a mismatch on text’s character character c c is encountered after is encountered after k k > 0 matches> 0 matches
text text
pattern pattern
bad-symbol shift bad-symbol shift dd11 == max{max{tt11((c c ) - ) - kk, 1} , 1}
c
k matches

Good-suffix shift in Boyer-Moore algorithmGood-suffix shift in Boyer-Moore algorithm
Good-suffix shift Good-suffix shift dd22 is applied after 0 < is applied after 0 < k k < < mm last characters last characters
were matchedwere matched dd22((kk) = the distance between matched suffix of size ) = the distance between matched suffix of size kk and its and its
rightmost occurrence in the pattern that is not preceded by rightmost occurrence in the pattern that is not preceded by the same character as the suffixthe same character as the suffix
Example: Example: CABABA CABABA dd22(1) = 4 (1) = 4
If there is no such occurrence, match the longest part of the If there is no such occurrence, match the longest part of the kk-character suffix with corresponding prefix; -character suffix with corresponding prefix; if there are no such suffix-prefix matches, if there are no such suffix-prefix matches, dd2 2 ((kk) = ) = mm
Example: Example: WOWWOW WOWWOW dd22(2) = 5, (2) = 5, dd22(3) = 3, (3) = 3, dd22(4) = 3, (4) = 3, dd22(5) = 3 (5) = 3

Boyer-Moore AlgorithmBoyer-Moore Algorithm
After matching successfully 0 < After matching successfully 0 < k k < < mm characters, the algorithm characters, the algorithm shifts the pattern right by shifts the pattern right by
dd = max { = max {dd11, , dd22}}
where where dd11 == max{max{tt11((cc) - ) - kk, 1} is bad-symbol shift, 1} is bad-symbol shift
dd22((kk) is good-suffix shift) is good-suffix shift
Example: Find pattern Example: Find pattern ATAT__THAT THAT inin
WHICHWHICH__FINALLYFINALLY__HALTS.HALTS. _ _ _ _ ATAT__THATTHAT

Boyer-Moore Algorithm (cont.)Boyer-Moore Algorithm (cont.)
Step 1 Fill in the bad-symbol shift tableStep 1 Fill in the bad-symbol shift tableStep 2 Fill in the good-suffix shift tableStep 2 Fill in the good-suffix shift tableStep 3 Align the pattern against the beginning of the textStep 3 Align the pattern against the beginning of the textStep 4 Repeat until a matching substring is found or text ends:Step 4 Repeat until a matching substring is found or text ends: Compare the corresponding characters right to left. Compare the corresponding characters right to left.
If no If no characters match, retrieve entry characters match, retrieve entry tt11((cc) from the bad-) from the bad-symbol table for the text’s character symbol table for the text’s character c c causing the causing the mismatch and shift the pattern to the right by mismatch and shift the pattern to the right by tt11((cc).).If 0 < If 0 < k k < < mm characters are matched, characters are matched, retrieve entry retrieve entry tt11((cc) ) from the bad-symbol table for the text’s character from the bad-symbol table for the text’s character c c causing the mismatch and entry causing the mismatch and entry dd22((kk) from the good-) from the good-suffix table and shift the pattern to the right bysuffix table and shift the pattern to the right by
dd = max { = max {dd11, , dd22}}where where dd11 == max{max{tt11((cc) - ) - kk, 1}., 1}.

Example of Boyer-Moore alg. applicationExample of Boyer-Moore alg. application
B E S S _ K N E W _ A B O U T _ B A O B A B SB E S S _ K N E W _ A B O U T _ B A O B A B S B A O B A BB A O B A B dd11 = = tt11((KK) = 6) = 6 B A O B A B B A O B A B dd11 = = tt11((__)-2 = 4)-2 = 4
dd22(2) = 5(2) = 5 B A O B A BB A O B A B dd11 = = tt11((__)-1 = 5)-1 = 5
dd22(1) = 2(1) = 2 B A O B A B B A O B A B
(success)(success)
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
1 2 6 6 6 6 6 6 6 6 6 6 6 6 3 6 6 6 6 6 6 6 6 6 6 6
_
6
k pattern d2
1 BAOBAB 2
2 BAOBAB 5
3 BAOBAB 5
4 BAOBAB 5
5 BAOBAB 5

HashingHashing
A very efficient method for implementing a A very efficient method for implementing a dictionary, dictionary, i.e.,i.e., a set with the operations: a set with the operations:
– find find – insert insert – deletedelete
Based on representation-change and space-for-time Based on representation-change and space-for-time tradeoff ideastradeoff ideas
Important applications:Important applications:– symbol tablessymbol tables– databases (databases (extendible hashingextendible hashing))

Hash tables and hash functionsHash tables and hash functions
The idea of The idea of hashinghashing is to map keys of a given file of size is to map keys of a given file of size n n intointoa table of size a table of size m, m, called the called the hash tablehash table,, by using a predefinedby using a predefinedfunction, called the function, called the hash functionhash function,, hh: : K K location (cell) in the hash table location (cell) in the hash table
Example: student records, key = SSN. Hash function:Example: student records, key = SSN. Hash function:hh((KK) = ) = KK mod mod m m where where mm is some integer (typically, prime) is some integer (typically, prime)If If mm = 1000, where is record with SSN= 314159265 stored? = 1000, where is record with SSN= 314159265 stored?
Generally, a hash function should:Generally, a hash function should:• be easy to computebe easy to compute• distribute keys about evenly throughout the hash tabledistribute keys about evenly throughout the hash table

CollisionsCollisions
If If hh((KK11)) = h = h((KK22), there is a ), there is a collisioncollision
Good hash functions result in fewer collisions but some Good hash functions result in fewer collisions but some collisions should be expected (collisions should be expected (birthday paradoxbirthday paradox))
Two principal hashing schemes handle collisions differentlyTwo principal hashing schemes handle collisions differently: :
• Open hashingOpen hashing – – each cell is a header of linked list of all keys hashed to iteach cell is a header of linked list of all keys hashed to it
• Closed hashingClosed hashing
– one key per cell one key per cell
– in case of collision, finds another cell by in case of collision, finds another cell by
– linear probing:linear probing: use next free bucket use next free bucket
– double hashing:double hashing: use second hash function to compute increment use second hash function to compute increment

Open hashing (Separate chaining)Open hashing (Separate chaining)
Keys are stored in linked lists Keys are stored in linked lists outsideoutside a hash table whose a hash table whose
elements serve as the lists’ headers.elements serve as the lists’ headers.
Example: Example: A, FOOL, AND, HIS, MONEY, ARE, SOON, PARTEDA, FOOL, AND, HIS, MONEY, ARE, SOON, PARTED
hh((KK) = sum of ) = sum of KK ‘s letters’ positions in the alphabet MOD 13 ‘s letters’ positions in the alphabet MOD 13
KeyKey AA FOOLFOOL ANDAND HISHIS MONEYMONEY AREARE SOON SOON PARTEDPARTED
hh((KK)) 11 99 66 1010 77 1111 1111 1212
AA FOOLFOOLANDAND HISHISMONEYMONEY AREARE PARTEDPARTED
SOONSOON
1211109876543210
Search for Search for KIDKID

Open hashing (cont.)Open hashing (cont.)
If hash function distributes keys uniformly, average length of If hash function distributes keys uniformly, average length of linked list will be linked list will be αα = = n/m. n/m. This ratio is called This ratio is called load factorload factor..
Average number of probes in successful, Average number of probes in successful, SS, and unsuccessful , and unsuccessful searches, searches, UU::
SS 1+ 1+αα/2, /2, U = U = αα
Load Load αα is typically kept small (ideally, about 1) is typically kept small (ideally, about 1)
Open hashing still works if Open hashing still works if n > mn > m
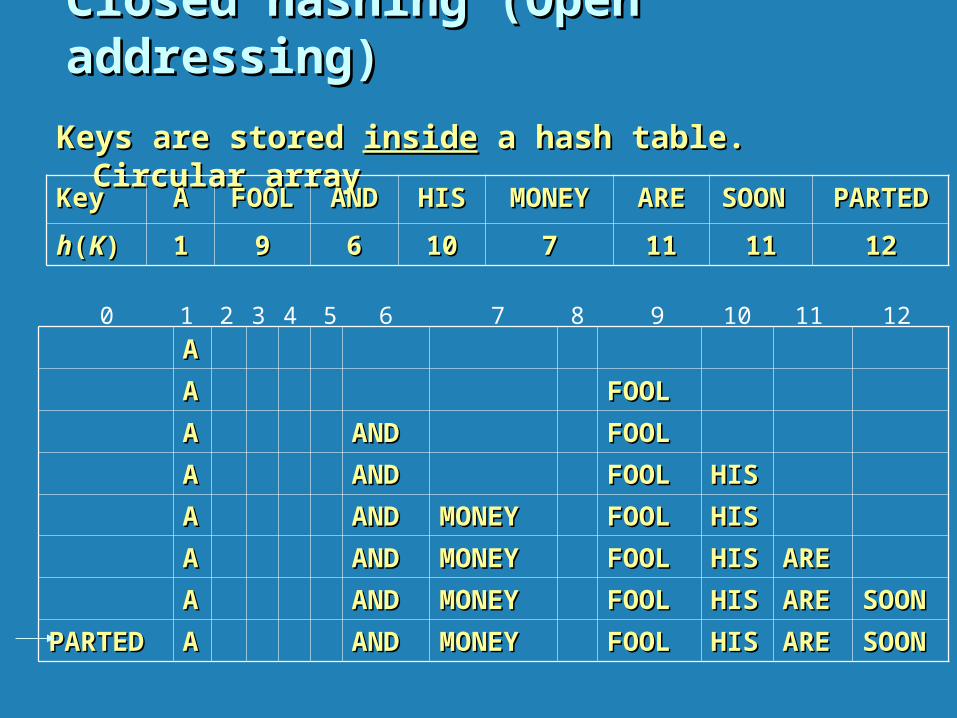
Closed hashing (Open addressing)Closed hashing (Open addressing)
Keys are stored Keys are stored insideinside a hash table. Circular array a hash table. Circular array
AA
AA FOOLFOOL
AA ANDAND FOOLFOOL
AA ANDAND FOOLFOOL HISHIS
AA ANDAND MONEYMONEY FOOLFOOL HISHIS
AA ANDAND MONEYMONEY FOOLFOOL HISHIS AREARE
AA ANDAND MONEYMONEY FOOLFOOL HISHIS AREARE SOONSOON
PARTEDPARTED AA ANDAND MONEYMONEY FOOLFOOL HISHIS AREARE SOONSOON
KeyKey AA FOOLFOOL ANDAND HISHIS MONEYMONEY AREARE SOON SOON PARTEDPARTED
hh((KK)) 11 99 66 1010 77 1111 1111 1212
0 1 2 3 4 5 6 7 8 9 10 11 12

Closed hashing (cont.)Closed hashing (cont.) Does not work if Does not work if n > mn > m Avoids pointersAvoids pointers Deletions are Deletions are notnot straightforward straightforward Number of probes to find/insert/delete a key depends on Number of probes to find/insert/delete a key depends on
load factor load factor αα = = nn//m m (hash table density) and collision (hash table density) and collision resolution strategy. For linear probing: resolution strategy. For linear probing:
S S = (½) (1+ 1/(1- = (½) (1+ 1/(1- αα)) and )) and U = U = (½) (1+ 1/(1- (½) (1+ 1/(1- αα)²))²) As the table gets filled (As the table gets filled (αα approaches 1), number of probes approaches 1), number of probes
in linear probing increases dramatically: in linear probing increases dramatically:

7.4 B-Trees7.4 B-Trees
Extends idea of using extra space to facilitate faster access Extends idea of using extra space to facilitate faster access This is done to access a data set on disk.This is done to access a data set on disk. Extends the idea of a 2-3 treeExtends the idea of a 2-3 tree
All data records are stored at the leaves in increasing order of All data records are stored at the leaves in increasing order of the keysthe keys
The parental nodes are used for indexingThe parental nodes are used for indexing• Each parental node contains n-1 ordered keysEach parental node contains n-1 ordered keys
• The keys are interposed with n pointers to the node’s childrenThe keys are interposed with n pointers to the node’s children
• All keys in the subtree TAll keys in the subtree T00 are smaller than K are smaller than K11, ,
• All the keys in subtree TAll the keys in subtree T11 are greater than or equal to K are greater than or equal to K1 1 and smaller and smaller
than Kthan K22 with K with K11 being equal to the smallest key in T being equal to the smallest key in T11
• etc etc

B-TreesB-Trees
This is a n-nodeThis is a n-node All the nodes in a binary search tree are 2-nodesAll the nodes in a binary search tree are 2-nodes
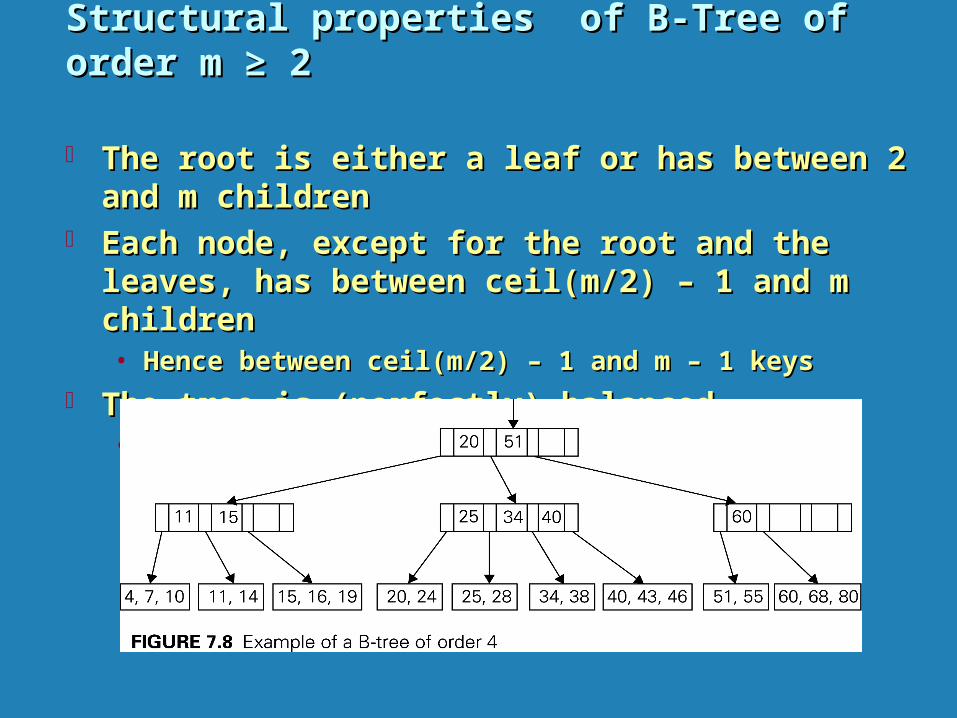
Structural properties of B-Tree of order m ≥ 2Structural properties of B-Tree of order m ≥ 2
The root is either a leaf or has between 2 and m childrenThe root is either a leaf or has between 2 and m children Each node, except for the root and the leaves, has between Each node, except for the root and the leaves, has between
ceil(m/2) – 1 and m childrenceil(m/2) – 1 and m children• Hence between ceil(m/2) – 1 and m – 1 keysHence between ceil(m/2) – 1 and m – 1 keys
The tree is (perfectly) balancedThe tree is (perfectly) balanced• All its leaves are at the same levelAll its leaves are at the same level

SearchingSearching
Starting at the root Starting at the root Follow a chain of pointers to the leaf that may contain the Follow a chain of pointers to the leaf that may contain the
search keysearch key Search for the search key among the keys of the leafSearch for the search key among the keys of the leaf
• Keys are in sorted order – can use binary search if number of keys is Keys are in sorted order – can use binary search if number of keys is largelarge
How many nodes to we have to access during a search of a How many nodes to we have to access during a search of a record with a given key?record with a given key?

Insertion is O(log n)Insertion is O(log n)
Apply the search procedure to the new record’s key K Apply the search procedure to the new record’s key K • To find the appropriate leaf for the new recordTo find the appropriate leaf for the new record
If there is enough room in the leaf, place it thereIf there is enough room in the leaf, place it there• In the appropriate sorted key positionIn the appropriate sorted key position
If there is no room for the recordIf there is no room for the record• The leaf is split in half by sending the second half of records to a The leaf is split in half by sending the second half of records to a
new nodenew node
• The smallest key in the new node and the pointer to it will have to be The smallest key in the new node and the pointer to it will have to be inserted in the old leaf’s parentinserted in the old leaf’s parent
– Immediately after the key and pointer to the old leafImmediately after the key and pointer to the old leaf
• This recursive procedure may percolate up to the tree’s rootThis recursive procedure may percolate up to the tree’s root– If the root is full, a new root is created If the root is full, a new root is created
– Two halves of the old root’s keys split between two children of the new Two halves of the old root’s keys split between two children of the new rootroot

Insertion in actionInsertion in action
To thisTo this