classification in microarray experiments jane fridlyand, ucsf cancer center cbmb workshop, nov 15,...
Post on 20-Dec-2015
217 views
TRANSCRIPT

Classification in Microarray Experiments
Jane Fridlyand, UCSF Cancer CenterCBMB Workshop, Nov 15, 2003

cDNA gene expression data Data on G genes for n samples
Genes
mRNA samples
Gene expression level of gene i in mRNA sample j
= (normalized) Log( Red intensity / Green intensity)
sample1 sample2 sample3 sample4 sample5 …
1 0.46 0.30 0.80 1.51 0.90 ...2 -0.10 0.49 0.24 0.06 0.46 ...3 0.15 0.74 0.04 0.10 0.20 ...4 -0.45 -1.03 -0.79 -0.56 -0.32 ...5 -0.06 1.06 1.35 1.09 -1.09 ...
Any other microarray dataset (aCGH/Affy/Oligo …)can be represented in above matrix form.

Outline
•Background on Classification
•Feature selection
•Performance assessment
•Discussion

Classification
• Task: assign objects to classes (groups) on the basis of measurements made on the objects
• Unsupervised: classes unknown, want to discover them from the data (cluster analysis)
• Supervised: classes are predefined, want to use a (training or learning) set of labeled objects to form a classifier for classification of future observations

Supervised approach (discrimination + allocation)
• Objects (e.g. arrays) are to be classified as belonging to one of a number of predefined classes {1, 2, …, K}
• Each object associated with a class label (or response) Y {1, 2, …, K} and a feature vector (vector of predictor variables) of G measurements: X = (X1, …, XG)
• Aim: predict Y from X.

Example: Tumor Classification• Reliable and precise classification essential for
successful cancer treatment
• Current methods for classifying human malignancies rely on a variety of morphological, clinical and molecular variables
• Uncertainties in diagnosis remain; likely that existing classes are heterogeneous
• Characterize molecular variations among tumors by monitoring gene expression (microarray)
• Hope: that microarrays will lead to more reliable tumor classification (and therefore more appropriate treatments and better outcomes)

Tumor Classification Using Array Data
Three main types of statistical problems associated with tumor classification:
• Identification of new/unknown tumor classes using gene expression profiles (unsupervised learning – clustering)
• Classification of malignancies into known classes (supervised learning – discrimination)
• Identification of “marker” genes that characterize the different tumor classes (feature or variable selection).

Classification and Microarrays
Classification is an important question in experiments experiments, for purposes of classifying biological samples and and predicting clinical and other outcomes using array data.
•Tumor class: ALL vs AML, classic vs desmoplastic medullablastoma•Response to treatemnt, survival•Type of bacteria pathogen, etc.

Classification and Microarrays
•Large and complex multivariate datasets generated by microarray experiments raise new methodological and computational challenges
•Many articles have been published on classification using gene expression data
•The statistical literature on classification has been overlooked.
Old method with catchy namesNew methods with inadequate or unknown
propertiesImproper performance assessment

Taken from Nature Jan, 2002Paper by L van’t Veer et alGene expression profiling predicts clinical outcome of breast cancer. Further validated in the NewEngland Journal of Medicine on 295 women.

Classifiers• A predictor or classifier partitions the space of gene
expression profiles into K disjoint subsets, A1, ..., AK, such that for a sample with expression profile X=(X1, ...,XG) Ak the predicted class is k
• Classifiers are built from a learning set (LS)
L = (X1, Y1), ..., (Xn,Yn)
• Classifier C built from a learning set L:
C( . ,L): X {1,2, ... ,K}
• Predicted class for observation X:
C(X,L) = k if X is in Ak

Diagram of classification
Training set
(CV) Learning set
Parameters, features andMeta-parameters
ClassifierPerformanceassessmentFuture test
samples
(CV) Test set

Decision Theory (I)
• Can view classification as statistical decision theory: must decide which of the classes an object belongs to
• Use the observed feature vector X to aid in decision making
• Denote population proportion of objects of class k as pk = p(Y = k)
• Assume objects in class k have feature vectors with class conditional density pk(X) = p(X|Y = k)

Decision Theory (II)
When (unrealistically) both and
are known, the classification problem has asolution – Bayes rule.
This situation also gives an upper bound on The performance of the classifiers in the more realistic setting where these quantities are not known – Bayes risk.

Decision Theory (III)
• One criterion for assessing classifier quality is the misclassification rate,
p(C(X)Y)
• A loss function L(i,j) quantifies the loss incurred by erroneously classifying a member of class i as class j
• The risk function R(C) for a classifier is the expected (average) loss:
R(C) = E[L(Y,C(X))]

Decision Theory (IV)
• Typically L(i,i) = 0
• In many cases can assume symmetric loss with L(i,j) = 1 for i j (so that different types of errors are equivalent)
• In this case, the risk is simply the misclassification probability
• There are some important examples, such as in diagnosis, where the loss function is not symmetric

Decision Theory (V)

Decision Theory (VI)

Training set and population of interest
Beware of the relationship between your training set and population to which your classifier will be applied.
Unequal class representation: estimates of jointquantities such pooled covariance matrix
Loss function: differential misclassification costs
Biased sampling of classes: adjustment of priors

Example: biased sampling of classes (case-control studies)
Recurrence rate among node-negative early stage breast cancer patients is low, say, <10%. Suppose that at the time of surgery, we want to identify women who will recur to assign them to a more aggressive therapy.
Case-control studies are typical in such situations.A researcher goes back to the tumor bank andcollects a pre-defined number of tissue samples ofeach type, say, among 100 samples, 50 recur and 50 don’t. Thus, learning set has 50% rate of recurrence

Example (ctd) Assuming equal priors and misclassification cost,suppose the cross-validated misclassification error is 20/100 cases: 10 recurrences and 10 non-recurrences. So, we can discriminate samples based on their genetic data. Can thisclassifier be used for allocation of future samples?
Probably not. Among 100 future cases, we expect to see 10 recurrences. We also expect to misclassify2 (10*(10/50)) of them as non-recurrences and also misclassify 90*(10/50) = 18 non-recurrences asrecurrences. With equal misclassification costs we will do better by assuming that no patients in thisclinical group will recur.

Lessons learntTo make your classifier applicable to future samples,it is very important to incorporate population parameters such as priors into the classifier as wellAs to keep in mind clinically viable misclassificationcosts (it may be less of an error to aggressively treat someone who would not recur than miss someone who will.
Always keep sampling scheme in mind.
Ultimately, it is all about minimizing the total risk whichis a function of many quantities which have to holdin the population of interest.

Maximum likelihood discriminant rule
• A maximum likelihood estimator (MLE) chooses the parameter value that makes the chance of the observations the highest
• For known class conditional densities pk(X), the maximum likelihood (ML) discriminant rule predicts the class of an observation X by
C(X) = argmaxk pk(X)

Fisher Linear Discriminant Analysis
First applied in 1935 by M. Barnard at the suggestion of R. A. Fisher (1936), Fisher linear discriminant analysis (FLDA):
1. finds linear combinations of the gene expression profiles X=X1,...,XG with large ratios of between-groups to within-groups sums of squares - discriminant variables;
2. predicts the class of an observation X by the class whose mean vector is closest to X in terms of the discriminant variables

FLDA

Gaussian ML Discriminant Rules
• For multivariate Gaussian (normal) class densities X|Y= k ~ N(k, k), the ML classifier is
C(X) = argmink {(X - k) k-1
(X - k)’ + log| k |}
• In general, this is a quadratic rule (Quadratic discriminant analysis, or QDA)
• In practice, population mean vectors k and covariance matrices k are estimated by corresponding sample quantities

ML discriminant rules - special cases
1. Linear discriminant analysis, LDA. When the class densities have the same covariance matrix, k , the discriminant rule is based on the square of the Mahalanobis distance and is linear and given by
2. Diagonal linear discriminant analysis, DLDA. In this simplest case, when the class densities have the same diagonal covariance matrix = diag(s1
2, …, sp2)
Note. Weighted gene voting of Golub et al. (1999) is aminor variant of DLDA for two classes (wrong variance calculation).
p
j j
kjjx
kxC
1 2
2)(minarg)(
C(x) = arg min k (x-)’ -1(x - )

Linear and Quadratic Discriminant Analysis
•Simple and intuitive•Easy to implement•Good performance in practice (bias-variance trade-off)
•Linear/Quadratic boundaries may not be enough•Features may have mixture distributions within
classes Why not use it?•When too many features are used, performance may degrade quickly due to over-parametrization
Why use it?

Nearest Neighbor Classification
• Based on a measure of distance between observations (e.g. Euclidean distance or one minus correlation)
• k-nearest neighbor rule (Fix and Hodges (1951)) classifies an observation X as follows:– find the k observations in the learning set closest to X– predict the class of X by majority vote, i.e., choose the
class that is most common among those k observations.
• The number of neighbors k can be chosen by cross-validation (more on this later)

Nearest neighbor rule

Classification Trees
• Partition the feature space into a set of rectangles, then fit a simple model in each one
• Binary tree structured classifiers are constructed by repeated splits of subsets (nodes) of the measurement space X into two descendant subsets (starting with X itself)
• Each terminal subset is assigned a class label; the resulting partition of X corresponds to the classifier

Classification Tree

Three Aspects of Tree Construction
• Split Selection Rule
• Split-stopping Rule
• Class assignment Rule
Different approaches to these three issues (e.g. CART: Classification And Regression Trees, Breiman et al. (1984); C4.5 and C5.0, Quinlan (1993)).

Three Rules (CART)
• Splitting: At each node, choose split maximizing decrease in impurity (e.g. Gini index, entropy, misclassification error)
• Split-stopping: Grow large tree, prune to obtain a sequence of subtrees, then use cross-validation to identify the subtree with lowest misclassification rate
• Class assignment: For each terminal node, choose the class minimizing the resubstitution estimate of misclassification probability, given that a case falls into this node





Other Classifiers Include…
• Support vector machines (SVMs)
• Neural networks
• Logistic regression
• Projection pursuit
• Bayesian belief networks

Features
• Feature selection– Automatic with trees– For DA, NN need preliminary selection– Need to account for selection when
assessing performance
• Missing data– Automatic imputation with trees– Otherwise, impute (or ignore)

Why select features?
Leukemia, 3 classaffymetrix chipLeft: no featureselectionRight: top 100 most variables genes
Lymphoma, 3 classlymphochipLeft: no featureselectionRight: top 100 most variables genes

Explicit feature selection I
One-gene-at-a-time approaches. Genes are ranked based on the value of a univariate test statisticsuch as: t- or F-statistic or their non-parametricvariants (Wilcoxon/Kruskal-Wallis); p-value.
Possible meta-parameters include the number of genes G or a p-value cut-off. A formal choice ofthese parameters may be achieved by cross-validation or bootstrap procedures.

Explicit feature selection IIMultivariate approaches. More refined feature selection procedures consider the joint distribution of the expression measures, in orderto detect genes with weak main effects but possibly strong interaction.
Bo & Jonassen (2002): Subset selection procedures for screening gene pairs to be used in classification
Breiman (1999): ranks genes according to importance statistic define in terms of prediction accuracy. Note that tree building itself does not involveexplicit feature selection.

Implicit feature selection Feature selection may also be performed implicitly by the classification rule itself.
In classification trees, features are selectedat each step based on reduction in impurity andThe number of features used (or size of the tree)is determined by pruning th tree using cross-validation. Thus, feature selection is inherent part of tree-building and pruning dealswith overfitting.
Shrinkage methods and adaptive distance functionMay be used for LDA and kNN.

Distance and StandardizationTrees. Trees are invariant under monotone transformation of individual features(genes), e.g. standardization. They are not invariantto standardization of observations (normalizationin microarray context).
DA. Based on Mahalanobis distance of the observations from the class means. Thus , the classifiers are invariant to standardization of the variables (genes) but not observations. (arrays)
k-NN. Related to deciding on distance function.affected by both, features and observationsstandardization.

Polychotomous classificationIt may be advantageous to convert a K-class classification problem (K > 2) into a series of binary problems.
•All pairwise binary classification problems. Consider all binary classification problems: thefinal predicted class is the class that is selected often among all binary comparisons.
•One-against-all binary classification problemApplication of K binary rules to a test case yields K estimates of class probabilities. Choosethe class with the largest posterior.

Performance assessment
Any classifier needs to be evaluated for its performance on the future samples. It is almost never the case in microarray studies that a large independent population-based collection of samplesis available at the time of intial classifier-building phase.
One needs to estimate future performance based on what is available: often the same set that isused to build the classifier.
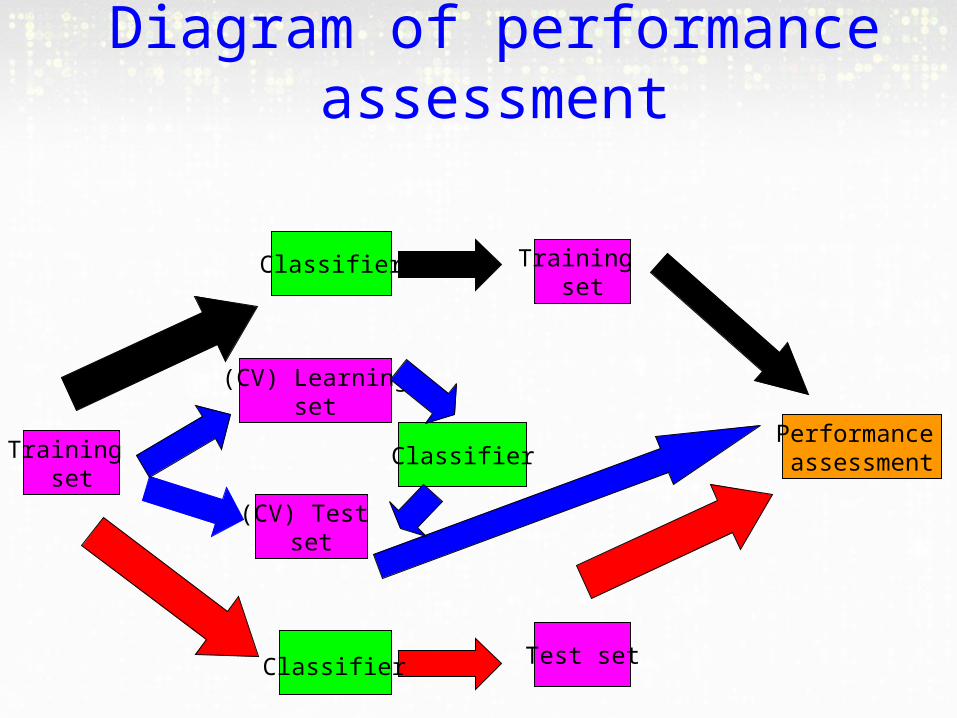
Diagram of performance assessment
Training set
Classifier
(CV) Test set
Performance assessment
Test set
Training set
(CV) Learningset
Classifier
Classifier

Performance assessment (I)
• Resubstitution estimation: error rate on the learning set– Problem: downward bias
• Test set estimation: divide cases in learning set into two sets, L1 and L2; classifier built using L1, error rate computed for L2. L1 and L2 must be iid.
– Problem: reduced effective sample size

Performance assessment (II)
• V-fold cross-validation (CV) estimation: Cases in learning set randomly divided into V subsets of (nearly) equal size. Build classifiers leaving one set out; test set error rates computed on left out set and averaged. – Bias-variance tradeoff: smaller V can give
larger bias but smaller variance– Computationally intensive

Performance assessment (III)
• Leave-one-out cross validation (LOOCV).
(Special case for V=n). Works well for stable classifiers (k-NN, LOOCV)
• Out-of-bag estimation: covered below

Performance assessment (III)
• Common to do feature selection using all of the data, then CV only for model building and classification
• However, usually features are unknown and the intended inference includes feature selection. Then, CV estimates as above tend to be downward biased.
• Features should be selected only from the learning set used to build the model (and not the entire learning set)

Aggregating classifiers
• Breiman (1996, 1998) found that gains in accuracy could be obtained by aggregating predictors built from perturbed versions of the learning set; the multiple versions of the predictor are aggregated by voting.
• Let C(., Lb) denote the classifier built from the bth perturbed learning set Lb, and let wb denote the weight given to predictions made by this classifier. The predicted class for an observation x is given by
argmaxk ∑b wbI(C(x,Lb) = k)

Diagram of aggregating classifiers
classifier500Sample500
Sample499
dot dot dot
classifier1
classifier2
classifier499
Aggregatedclassifierdot dot dot
Training
Set:
X1 …X100
Sample1
Sample2
Test set

Bagging
• Bagging = Bootstrap aggregating
• Non-parametric Bootstrap (standard bagging): perturbed learning sets drawn at random with replacement from the learning sets; predictors built for each perturbed dataset and aggregated by plurality voting (wb = 1)
• Parametric Bootstrap: perturbed learning sets are multivariate Gaussian
• Convex pseudo-data (Breiman 1996)

Boosting
Freund and Schapire (1997), Breiman (1998). The data are resampled adaptively so that the weights in the resampling are increased for those cases most often misclassified.
The aggregation of predictors is done by weighted voting.

Random Forests
•Perturbed learning sets are drawn at random with replacement from the learning sets
•The exploratory tree is built for each perturbed dataset in a way that at each node, thepre-specified number of features is randomly sub-sampled without replacement and only thesevariables are used to decide the split at that node.
• The resulting trees are aggregated by plurality voting (wb = 1)

Aggregation By-products: Out-of-bag estimation of error rate
• Out-of-bag error rate estimate: unbiased
Use the left out cases from each bootstrap sample as a test set
Classify these test set cases by aggregating relevant predictors and compare to the class labels of the learning set to get the out-of-bag estimate of the error rate

Aggregation By-products: Case-wise information
• Class probability estimates (votes) (0,1): the proportion of votes for the “winning” class; gives a measure of prediction confidence
• Vote margins (–1,1) : the proportion of votes for the true class minus the maximum of the proportion of votes for each of the other classes; can be used to detect mislabeled (learning set) cases

Aggregation By-products: Variable Importance Statistics
• Measure of predictive power
• For each tree, randomly permute the values of the j-th variable for the out-of-bag cases, use to get new classifications
• Several possible importance measures

Aggregation By-products: Intrinsic Case Proximities
• Proportion of trees for which cases i and j are in the same terminal node
• “Clustering”
• Outlier detection:
1/sum(squared proximities of cases in same class)

Boosting
• Freund and Schapire (1997), Breiman (1998)
• Data resampled adaptively so that the weights in the resampling are increased for those cases most often misclassified
• Predictor aggregation done by weighted voting

Comparison of classifiers
• Dudoit, Fridlyand, Speed (JASA, 2002)
• FLDA
• DLDA
• DQDA
• NN
• CART
• Bagging and boosting

Comparison study datasets
• Leukemia – Golub et al. (1999)n = 72 samples, G = 3,571 genes
3 classes (B-cell ALL, T-cell ALL, AML)
• Lymphoma – Alizadeh et al. (2000)n = 81 samples, G = 4,682 genes
3 classes (B-CLL, FL, DLBCL)
• NCI 60 – Ross et al. (2000)N = 64 samples, p = 5,244 genes
8 classes

Leukemia data, 2 classes: Test set error rates;150 LS/TS runs

Leukemia data, 3 classes: Test set error rates;150 LS/TS runs
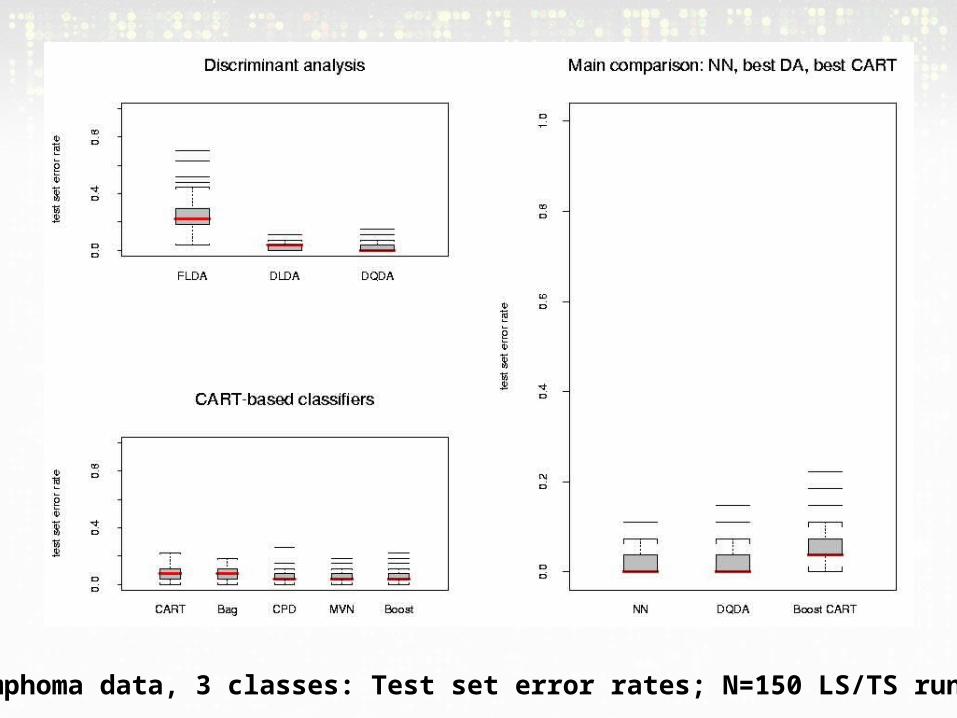
Lymphoma data, 3 classes: Test set error rates; N=150 LS/TS runs
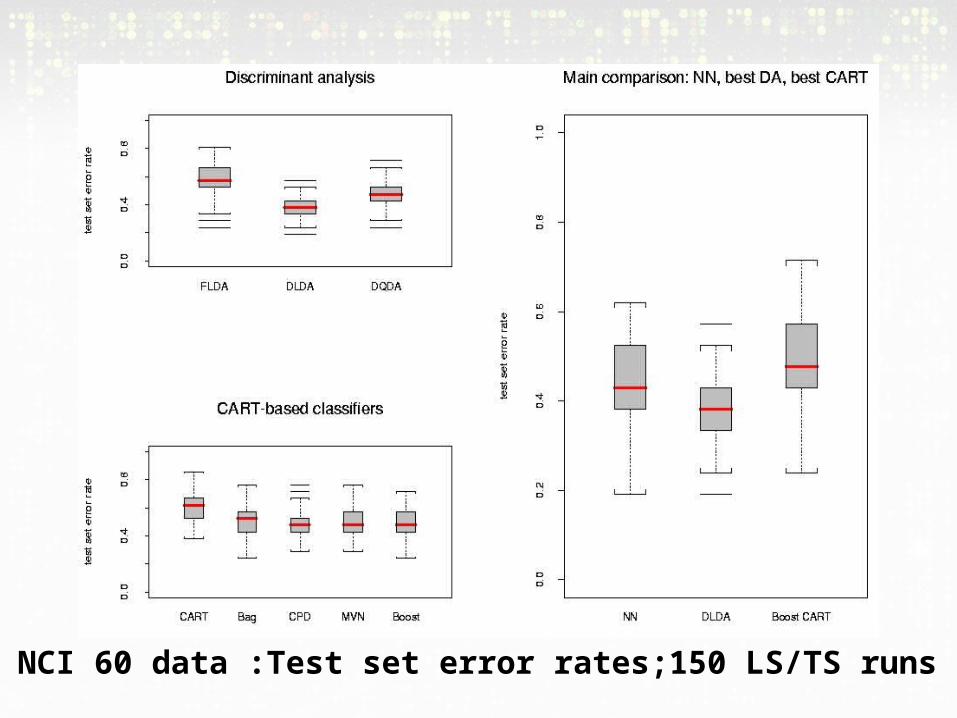
NCI 60 data :Test set error rates;150 LS/TS runs

Results• In the main comparison, NN and DLDA had the
smallest error rates, FLDA had the highest
• Aggregation improved the performance of CART classifiers, the largest gains being with boosting and bagging with convex pseudo-data
• For the lymphoma and leukemia datasets, increasing the number of genes to G=200 didn't greatly affect the performance of the various classifiers; there was an improvement for the NCI 60 dataset.
• More careful selection of a small number of genes (10) improved the performance of FLDA dramatically.

Issues in discrimination
• Classifier selection• Feature selection• Standardization or transformation.• Relationship between sample on hand and
population of interest• Aggregation of classifiers• Assessing performance of the classifier based on
– Cross-validation.– Test set– Independent testing on future dataset

Comparison study – Discussion (I)
• “Diagonal” LDA: ignoring correlation between genes helped here
• Unlike classification trees and nearest neighbors, LDA is unable to take into account gene interactions
• Although nearest neighbors are simple and intuitive classifiers, their main limitation is that they give very little insight into mechanisms underlying the class distinctions

Comparison study – Discussion (II)• Classification trees are capable of handling and revealing
interactions between variables
• Useful by-product of aggregated classifiers: prediction votes, variable importance statistics
• Variable selection: A crude criterion such as F-statistic may not identify the genes that discriminate between all the classes and may not reveal interactions between genes
• With larger training sets, expect improvement in performance of aggregated classifiers
• Not cross-validating feature selection introduces downward bias in misclassification estimate.

Summary (I)Bias-variance trade-off. Simple classifiers do wellon small datasets. As the number of samples increases, we expect to see that classifiers capable of considering higher-order interactions will have an edge.
Cross-validation . It is of utmost importance to cross-validate for every parameter that has beenchosen based on the data, including meta-parameters (what and how many features/how many neighbors/pooled or unpooled variance/classifier itself). If this is not done, it is possibleto wrongly declare having discrimination power when there is none.

Summary (II)
Generalization error rate estimation. It is necessary to keep sampling scheme in mind.
Thousands and thousands of independent samples from variety of sources are needed to be ableto address the true performance of the classifier.
We are not at that point yet with microarraysstudies. Rosetta/Van Veer study is probably the only study to date with ~300 test samples.

Acknowledgements
• Sandrine Dudoit
• Yee Hwa (Jean) Yang
• Terry Speed