cluster computing kick-start seminar 16 december, 2009 high performance cluster computing centre...
Post on 19-Dec-2015
217 views
TRANSCRIPT

Cluster ComputingCluster Computing
Kick-start seminar
16 December, 2009
High Performance Cluster Computing Centre (HPCCC)Faculty of Science
Hong Kong Baptist University

2
Outline• Overview of Cluster Hardware and SoftwareOverview of Cluster Hardware and Software
• Basic Login and Running Program in a job Basic Login and Running Program in a job queuing systemqueuing system
• Introduction to ParallelismIntroduction to Parallelism
– Why Parallelism & Cluster ParallelismWhy Parallelism & Cluster Parallelism
• Message Passing InterfaceMessage Passing Interface
• Parallel Program ExamplesParallel Program Examples
• Policy for using sciblade.sci.hkbu.edu.hkPolicy for using sciblade.sci.hkbu.edu.hk
• ContactContact
http://www.sci.hkbu.edu.hk/hpccc2009/sciblade
2

Overview of Cluster Overview of Cluster Hardware and SoftwareHardware and Software

4
Cluster Hardware
This 256-node PC cluster (sciblade) consist of:
• Master node x 2• IO nodes x 3 (storage)• Compute nodes x 256• Blade Chassis x 16• Management network• Interconnect fabric• 1U console & KVM switch• Emerson Liebert Nxa 120k VA UPS
4

5
Sciblade Cluster
256-node clusters supported by fund from RGC
5
6
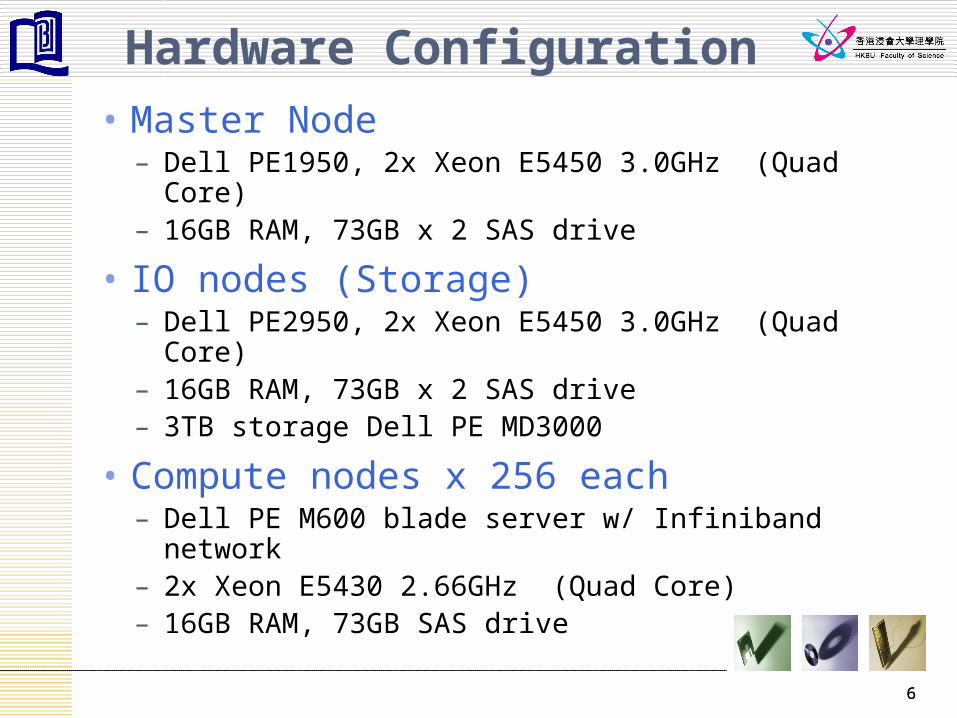
Hardware Configuration
• Master Node– Dell PE1950, 2x Xeon E5450 3.0GHz (Quad Core)– 16GB RAM, 73GB x 2 SAS drive
• IO nodes (Storage)– Dell PE2950, 2x Xeon E5450 3.0GHz (Quad Core)– 16GB RAM, 73GB x 2 SAS drive– 3TB storage Dell PE MD3000
• Compute nodes x 256 each– Dell PE M600 blade server w/ Infiniband network – 2x Xeon E5430 2.66GHz (Quad Core)– 16GB RAM, 73GB SAS drive
6

7
Hardware Configuration• Blade Chassis x 16
– Dell PE M1000e – Each hosts 16 blade servers
• Management Network– Dell PowerConnect 6248 (Gigabit Ethernet) x 6
• Inerconnect fabric– Qlogic SilverStorm 9120 switch
• Console and KVM switch – Dell AS-180 KVM– Dell 17FP Rack console
• Emerson Liebert Nxa 120kVA UPS7

8
Software List• Operating System
– ROCKS 5.1 Cluster OS– CentOS 5.3 kernel 2.6.18
• Job Management System – Portable Batch System– MAUI scheduler
• Compilers, Languages – Intel Fortran/C/C++ Compiler for Linux V11– GNU 4.1.2/4.4.0 Fortran/C/C++ Compiler
8

9
Software List
• Message Passing Interface (MPI) Libraries – MVAPICH 1.1– MVAPICH2 1.2– OPEN MPI 1.3.2
• Mathematic libraries – ATLAS 3.8.3– FFTW 2.1.5/3.2.1– SPRNG 2.0a(C/Fortran)
9

10
Software List
• Molecular Dynamics & Quantum Chemistry– Gromacs 4.0.5
– Gamess 2009R1
– Namd 2.7b1
• Third-party Applications – GROMACS, NAMD– MATLAB 2008b– TAU 2.18.2, VisIt 1.11.2– VMD 1.8.6, Xmgrace 5.1.22– etc
10

11
Software List
• Queuing system– Torque/PBS– Maui scheduler
• Editors– vi– emacs
11

12
Hostnames
• Master node– External : sciblade.sci.hkbu.edu.hk– Internal : frontend-0
• IO nodes (storage)– pvfs2-io-0-0, pvfs2-io-0-1, pvfs-io-0-2
• Compute nodes– compute-0-0.local, …, compute-0-255.local
12

Basic Login and Running Program in a Job Queuing System

14
Basic login• Remote login to the master node• Terminal login
– using secure shellssh -l username sciblade.sci.hkbu.edu.hk
• Graphical login– PuTTY & vncviewer e.g.
[username@sciblade]$ vncserver
New ‘sciblade.sci.hkbu.edu.hk:3 (username)' desktop is sciblade.sci.hkbu.edu.hk:3
It means that your session will run on display 3.
14

15
Graphical login
• Using PuTTY to setup a secured connection: Host Name=sciblade.sci.hkbu.edu.hk
15

16
Graphical login (con’t)
• ssh protocol version
16

17
Graphical login (con’t)
• Port 5900 +display numbe (i.e. 3 in this case)
17
18
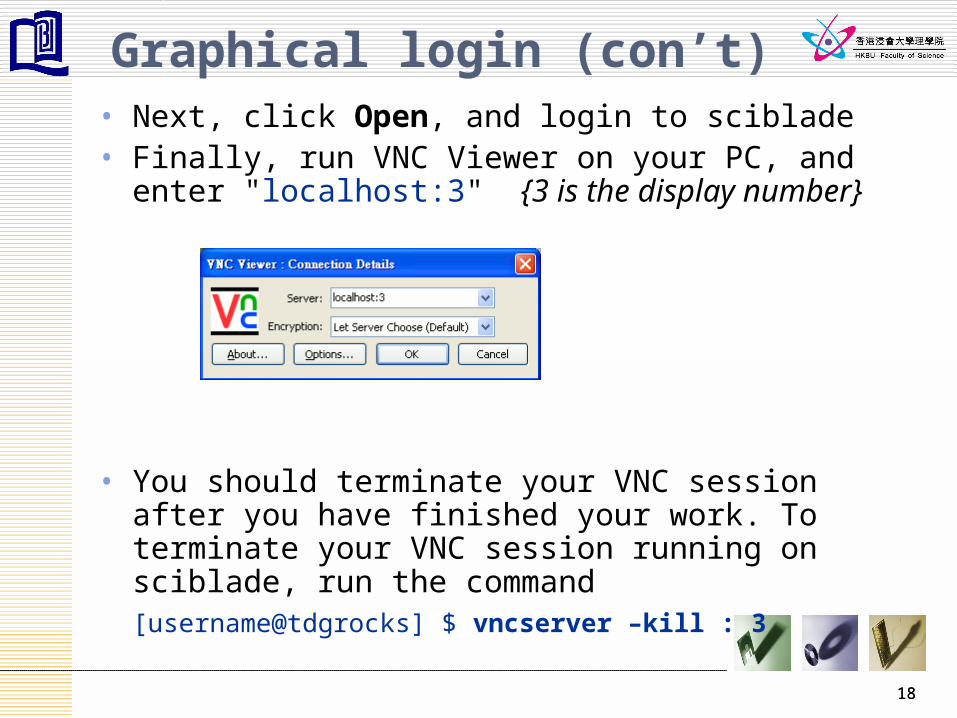
Graphical login (con’t)• Next, click Open, and login to sciblade• Finally, run VNC Viewer on your PC, and enter
"localhost:3" {3 is the display number}
• You should terminate your VNC session after you have finished your work. To terminate your VNC session running on sciblade, run the command[username@tdgrocks] $ vncserver –kill : 3
18

19
Linux commands• Both master and compute nodes are installed with
Linux• Frequently used Linux command in PC cluster
http://www.sci.hkbu.edu.hk/hpccc2009/sciblade/faq_sciblade.php
cp cp f1 f2 dir1 copy file f1 and f2 into directory dir1
mv mv f1 dir1 move/rename file f1 into dir1
tar tar xzvf abc.tar.gz Uncompress and untar a tar.gz format file
tar tar czvf abc.tar.gz abc create archive file with gzip compression
cat cat f1 f2 type the content of file f1 and f2
diff diff f1 f2 compare text between two files
grep grep student * search all files with the word student
history history 50 find the last 50 commands stored in the shell
kill kill -9 2036 terminate the process with pid 2036
man man tar displaying the manual page on-line
nohup nohup runmatlab a run matlab (a.m) without hang up after logout
ps ps -ef find out all process run in the systems
sort sort -r -n studno sort studno in reverse numerical order
19

20
ROCKS specific commands
• ROCKS provides the following commands for users to run programs in all compute node. e.g.– cluster-fork
• Run program in all compute nodes
– cluster-fork ps• Check user process in each compute node
– cluster-kill• Kill user process at one time
– tentakel• Similar to cluster-fork but run faster
20

21
GangliaWeb based management and monitoring• http://sciblade.sci.hkbu.edu.hk/ganglia
21

Why ParallelismWhy Parallelism

23
Why Parallelism – Passively
• Suppose you are using the most efficient algorithm with an optimal implementation, but the program still takes too long or does not even fit onto your machine
• Parallelization is the last chance.
23

24
Why Parallelism – Initiative
• Faster– Finish the work earlier
= Same work in shorter time
– Do more work= More work in the same time
• Most importantly, you want to predict the result before the event occurs
24

25
ExamplesMany of the scientific and engineering problems require enormous computational power.
Following are the few fields to mention:
– Quantum chemistry, statistical mechanics, and relativistic physics
– Cosmology and astrophysics
– Computational fluid dynamics and turbulence
– Material design and superconductivity
– Biology, pharmacology, genome sequencing, genetic engineering, protein folding, enzyme activity, and cell modeling
– Medicine, and modeling of human organs and bones
– Global weather and environmental modeling
– Machine Vision
25

26
Parallelism
• The upper bound for the computing power that can be obtained from a single processor is limited by the fastest processor available at any certain time.
• The upper bound for the computing power available can be dramatically increased by integrating a set of processors together.
• Synchronization and exchange of partial results among processors are therefore unavoidable.
26

27
Multiprocessing Clustering
IS
CU CU CU CU
PU PU PU PU
Shared Memory
1 n-1 n2
21 n-1 n
ISISIS
DSDSDSDS
DS
LM LM LM LM
CPU CPU CPU CPU
Interconnecting Network
1 n-1 n2
21 n-1 n
DSDSDS
Distributed Memory – Cluster
Shared Memory – Symmetric multiprocessors (SMP)
Parallel Computer Architecture
27

28
Clustering: Pros and Cons
• Advantages – Memory scalable to number of processors.
∴Increase number of processors, size of memoryand bandwidth as well.
– Each processor can rapidly access its own memory without interference
• Disadvantages – Difficult to map existing data structures to this
memory organization – User is responsible for sending and receiving data
among processors
28
29
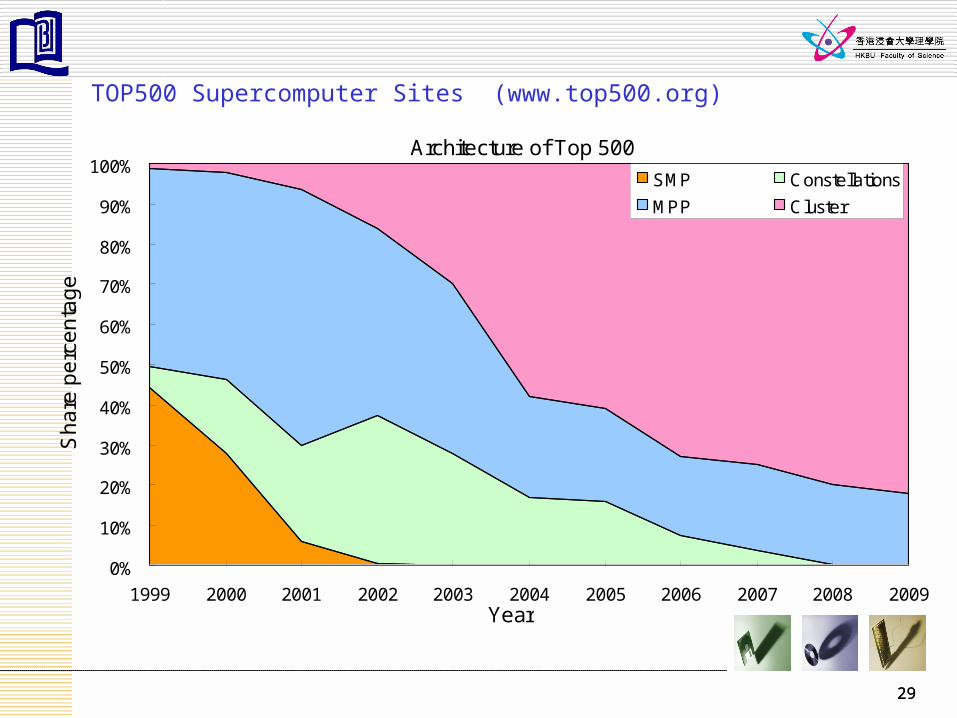
TOP500 Supercomputer Sites (www.top500.org)
Architecture of Top 500
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009Year
Sh
are
pe
rce
nta
ge
SMP Constellations
MPP Cluster
29

Cluster ParallelismCluster Parallelism

31
Parallel Programming Paradigm
Multithreading – OpenMP
Message Passing– MPI (Message Passing Interface)– PVM (Parallel Virtual Machine)
Shared memory, Distributed memory
Shared memory only
31

32
Distributed Memory• Programmers view:
– Several CPUs– Several block of memory– Several threads of action
• Parallelization– Done by hand
• Example– MPI
time
P1
P1 P2 P3
P2
P3
Process 0
Process 1
Process 2
SerialSerial
Data exchange viainterconnection
Process
MessageMessagePassingPassing
32

33
Message Passing Model
Message Passing
The method by which data from one processor's memory is copied to the memory of another processor.
ProcessA process is a set of executable instructions (program) which runs on a processor.
Message passing systems generally associate only one process per processor, and the terms "processes" and "processors" are used interchangeably
Data exchange
timetime
P1
P1 P2 P3
P2
P3
Process 0
Process 1
Process 2
SerialSerial
MessageMessagePassingPassing
33

Message Passing Interface (MPI)

35
MPI
• Is a library but not a language, for parallel programming
• An MPI implementation consists of– a subroutine library with all MPI functions– include files for the calling application program– some startup script (usually called mpirun, but not
standardized)
• Include the lib file mpi.h (or however called) into the source code
• Libraries available for all major imperative languages (C, C++, Fortran …)
35

36
General MPI Program Structure
MPI include file
#include <mpi.h>void main (int argc, char *argv[]){int np, rank, ierr;ierr = MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank);MPI_Comm_size(MPI_COMM_WORLD,&np);/* Do Some Works */ierr = MPI_Finalize();}
variable declarations #include <mpi.h>void main (int argc, char *argv[]){int np, rank, ierr;ierr = MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank);MPI_Comm_size(MPI_COMM_WORLD,&np);/* Do Some Works */ierr = MPI_Finalize();}
Initialize MPI environment
#include <mpi.h>void main (int argc, char *argv[]){int np, rank, ierr;ierr = MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank);MPI_Comm_size(MPI_COMM_WORLD,&np);/* Do Some Works */ierr = MPI_Finalize();}
Do work and make message passing calls
#include <mpi.h>void main (int argc, char *argv[]){int np, rank, ierr;ierr = MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank);MPI_Comm_size(MPI_COMM_WORLD,&np);/* Do Some Works */ierr = MPI_Finalize();}
Terminate MPI Environment
#include <mpi.h>void main (int argc, char *argv[]){int np, rank, ierr;ierr = MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank);MPI_Comm_size(MPI_COMM_WORLD,&np);/* Do Some Works */ierr = MPI_Finalize();}
36
37
Sample Program: Hello World!
• In this modified version of the "Hello World" program, each processor prints its rank as well as the total number of processors in the communicator MPI_COMM_WORLD.
• Notes:– Makes use of the pre-defined
communicator MPI_COMM_WORLD.– Not testing for error status of routines!
37

38
Sample Program: Hello World!#include <stdio.h>#include “mpi.h” // MPI compiler header file
void main(int argc, char **argv) {
int nproc,myrank,ierr;
ierr=MPI_Init(&argc,&argv); // MPI initialization
// Get number of MPI processesMPI_Comm_size(MPI_COMM_WORLD,&nproc);
// Get process id for this processorMPI_Comm_rank(MPI_COMM_WORLD,&myrank);
printf (“Hello World!! I’m process %d of %d\n”,myrank,nproc);
ierr=MPI_Finalize(); // Terminate all MPI processes
}
38

39
Performance
• When we write a parallel program, it is important to identify the fraction of the program that can be parallelized and to maximize it.
• The goals are:– load balance– memory usage balance– minimize communication overhead– reduce sequential bottlenecks– scalability
39

40
Compiling & Running MPI Programs
• Using mvapich 1.1
1. Setting path, at the command prompt, type: export PATH=/u1/local/mvapich1/bin:$PATH
(uncomment this line in .bashrc)
2. Compile using mpicc, mpiCC, mpif77 or mpif90, e.g.mpicc –o cpi cpi.c
3. Prepare hostfile (e.g. machines) number of compute nodes:
compute-0-0compute-0-1compute-0-2compute-0-3
4. Run the program with a number of processor node:mpirun –np 4 –machinefile machines ./cpi
40
41
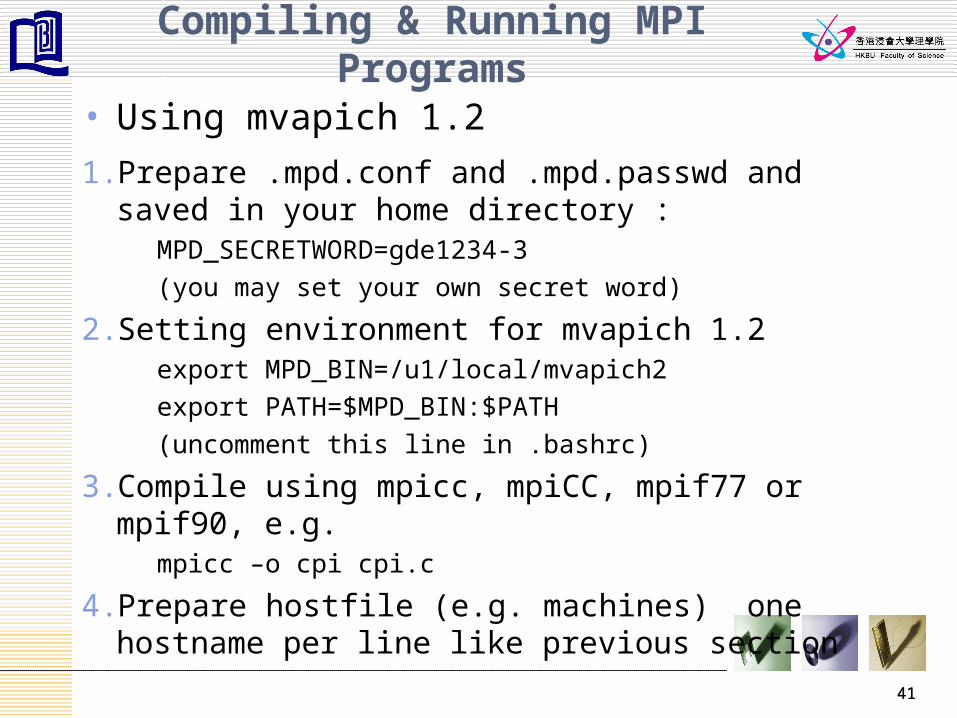
Compiling & Running MPI Programs
• Using mvapich 1.2
1. Prepare .mpd.conf and .mpd.passwd and saved in your home directory :
MPD_SECRETWORD=gde1234-3
(you may set your own secret word)
2. Setting environment for mvapich 1.2export MPD_BIN=/u1/local/mvapich2
export PATH=$MPD_BIN:$PATH
(uncomment this line in .bashrc)
3. Compile using mpicc, mpiCC, mpif77 or mpif90, e.g.mpicc –o cpi cpi.c
4. Prepare hostfile (e.g. machines) one hostname per line like previous section
41

42
Compiling & Running MPI Programs
5. Pmdboot with the hostfile mpdboot –n 4 –f machines
6. Run the program with a number of processor node:mpiexec –np 4 ./cpi
7. Remember to clean after running jobs by mpdallexitmpdallexit
42

43
Compiling & Running MPI Programs
• Using openmpi:1.21. Setting environment for openmpi
export LD-LIBRARY_PATH=/u1/local/openmpi/
lib:$LD-LIBRARY_PATH
export PATH=/u1/local/openmpi/bin:$PATH
(uncomment this line in .bashrc)
2. Compile using mpicc, mpiCC, mpif77 or mpif90, e.g.mpicc –o cpi cpi.c
3. Prepare hostfile (e.g. machines) one hostname per line like previous section
4. Run the program with a number of processor nodempirun –np 4 –machinefile machines ./cpi
43

44
Submit parallel jobs into torque batch queue
Prepare a job script (name it runcpi)– For program compiled with mvapich 1.1– For program compiled with mvapich 1.2– For program compiled with openmpi 1.2– For GROMACS
(refer to your handout for detail scripts)• Submit the above script (gromacs.pbs) qsub gromacs.pbs
44

Parallel Program Examples

46
Example 1: Matrix-vector Multiplication
• The figure below demonstrates schematically how a matrix-vector multiplication, A=B*C, can be decomposed into four independent computations involving a scalar multiplying a column vector.
• This approach is different from that which is usually taught in a linear algebra course because this decomposition lends itself better to parallelization.
• These computations are independent and do not require communication, something that usually reduces performance of parallel code.
46

47
Example 1: Matrix-vector Multiplication (Column wise)
Figure 1: Schematic of parallel decomposition for vector-matrix multiplication, A=B*C. The vector A is depicted in yellow. The matrix B and vector C are depicted in multiple colors representing the portions, columns, and elements assigned to each processor, respectively.
47

48
Example 1: MV Multiplication
A=B*C
33,322,311,300,3
33,222,211,200,2
33,122,111,100,1
33,022,011,000,0
3
2
1
0
cbcbcbcb
cbcbcbcb
cbcbcbcb
cbcbcbcb
a
a
a
a
P0 P1 P2 P3
+
+
+
+
+
+
+
+
+
+
+
+
Reduction (SUM)
P0 P1 P2 P3
48

49
Example 2: Quick Sort
• The quick sort is an in-place, divide-and-conquer, massively recursive sort.
• The efficiency of the algorithm is majorly impacted by which element is chosen as the pivot point.
• The worst-case efficiency of the quick sort, O(n2), occurs when the list is sorted and the left-most element is chosen.
• If the data to be sorted isn't random, randomly choosing a pivot point is recommended. As long as the pivot point is chosen randomly, the quick sort has an algorithmic complexity of O(n log n).
Pros: Extremely fast.Cons: Very complex algorithm, massively recursive
49

50
Quick Sort Performance
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1 2 4 8 16 32 64 128
Processes
Tim
e(se
c)
Processes Time
1 0.410000
2 0.300000
4 0.180000
8 0.180000
16 0.180000
32 0.220000
64 0.680000
128 1.300000
50

51
Example 3: Bubble Sort• The bubble sort is the oldest and simplest sort in use.
Unfortunately, it's also the slowest. • The bubble sort works by comparing each item in the
list with the item next to it, and swapping them if required.
• The algorithm repeats this process until it makes a pass all the way through the list without swapping any items (in other words, all items are in the correct order).
• This causes larger values to "bubble" to the end of the list while smaller values "sink" towards the beginning of the list.
51

52
Bubble Sort Performance
Processes Time
1 3242.327
2 806.346
4 276.4646
8 78.45156
16 21.031
32 4.8478
64 2.03676
128 1.240197
0
500
1000
1500
2000
2500
3000
3500
1 2 4 8 16 32 64 128
Processes
Tim
e (s
ec)
52

53
Monte Carlo Integration
• "Hit and miss" integration
• The integration scheme is to take a large number of random points and count the number that are within f(x) to get the area
53

54
SPRNG (Scalable Parallel Random Number Generators )
• Monte Carlo Integration to Estimate Pi
4
141
square inside hittingpt of no.
area shaded hittingpt of no.2
2
r
r
for (i=0;i<n;i++) { x = sprng(); y = sprng(); if ((x*x + y*y) < 1) in++; } pi = ((double)4.0)*in/n;
SPRNG is used to generate different sets of random numbers on different compute nodes while run n parallel
54

55
Example 1: Ring
ring/ring.cring/Makefilering/machines
Compile program by the command: makeRun the program in parallel bympirun –np 4 –machinefile machines ./ring < in
Example 3: Sorting
sorting/qsort.csorting/bubblesort.csorting/script.shsorting/qsort sorting/bubblesort
Submit job to PBS queuing system byqsub script.sh
Example 2: Prime
prime/prime.cprime/prime.f90prime/primeParallel.cprime/Makefileprime/machines
Compile by the command: makeRun the serial program by./prime or ./primefRun the parallel program bympirun –np 4 –machinefile machines ./primeParallel
Example 4: mcPi
mcPi/mcPi.cmcPi/mc-Pi-mpi.cmcPi/MakefilemcPi/QmcPi.pbs
Compile by the command: makeRun the serial program by: ./mcPi ##Submit job to PBS queuing system byqsub QmcPi.pbs
0
13
2
55

Policy for using sciblade.sci.hkbu.edu.hk
57
Policy1. Every user shall apply for his/her own computer user
account to login to the master node of the PC cluster, sciblade.sci.hkbu.edu.hk.
2. The account must not be shared his/her account and password with the other users.
3. Every user must deliver jobs to the PC cluster from the master node via the PBS job queuing system. Automatically dispatching of job using scripts or robots are not allowed.
4. Users are not allowed to login to the compute nodes.
5. Foreground jobs on the PC cluster are restricted to program testing and the time duration should not exceed 1 minutes CPU time per job.

58
Policy (continue)6. Any background jobs run on the master node
or compute nodes are strictly prohibited and will be killed without prior notice.
7. The current restrictions of the job queuing system are as follows,– The maximum number of running jobs in the job
queue is 8.– The maximum total number of CPU cores used in
one time cannot exceed 1024.8. The restrictions in item 5 will be reviewed
timely for the growing number of users and the computation need.
