seminar for new cluster users 18 may, 2010 high performance cluster computing centre (hpccc) faculty...
Post on 19-Dec-2015
216 views
TRANSCRIPT

Seminar forSeminar for
New Cluster Users
18 May, 2010
High Performance Cluster Computing Centre (HPCCC)Faculty of Science
Hong Kong Baptist University
2
Outline
• Hardware configurations Hardware configurations
• Recent Software InstalledRecent Software Installed
• Basic Login and job submission Basic Login and job submission procedureprocedure
• Parallel Program ExamplesParallel Program Examples• Policy Policy for usingfor using
sciblade.sci.hkbu.edu.hksciblade.sci.hkbu.edu.hk
• AcknowledgementAcknowledgementhttp://www.sci.hkbu.edu.hk/hpccc/sciblade
2

Latest Cluster Latest Cluster Hardware configurationsHardware configurations

4
Cluster Hardware
This 256-node PC cluster (sciblade) consist of:
• Master node x 2• IO nodes x 3 (storage)• Compute nodes x 256• Blade Chassis x 16• Management network• Interconnect fabric• 1U console & KVM switch• Emerson Liebert Nxa 120k VA UPS
4

5
Sciblade Cluster
256-node clusters supported by fund from RGC
5
6
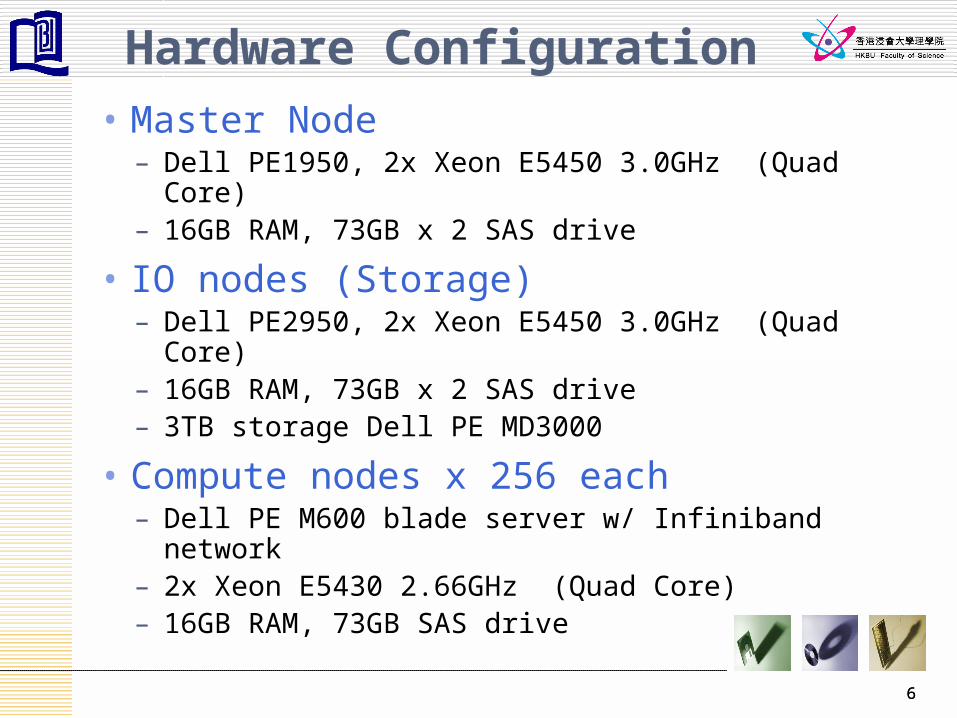
Hardware Configuration
• Master Node– Dell PE1950, 2x Xeon E5450 3.0GHz (Quad Core)– 16GB RAM, 73GB x 2 SAS drive
• IO nodes (Storage)– Dell PE2950, 2x Xeon E5450 3.0GHz (Quad Core)– 16GB RAM, 73GB x 2 SAS drive– 3TB storage Dell PE MD3000
• Compute nodes x 256 each– Dell PE M600 blade server w/ Infiniband network – 2x Xeon E5430 2.66GHz (Quad Core)– 16GB RAM, 73GB SAS drive
6

7
Hardware Configuration• Blade Chassis x 16
– Dell PE M1000e – Each hosts 16 blade servers
• Management Network– Dell PowerConnet 6248 (Gigabit Ethernet) x 6
• Inerconnect fabric– Qlogic SilverStorm 9120 switch
• Console and KVM switch – Dell AS-180 KVM– Dell 17FP Rack console
• Emerson Liebert Nxa 120kVA UPS7
8
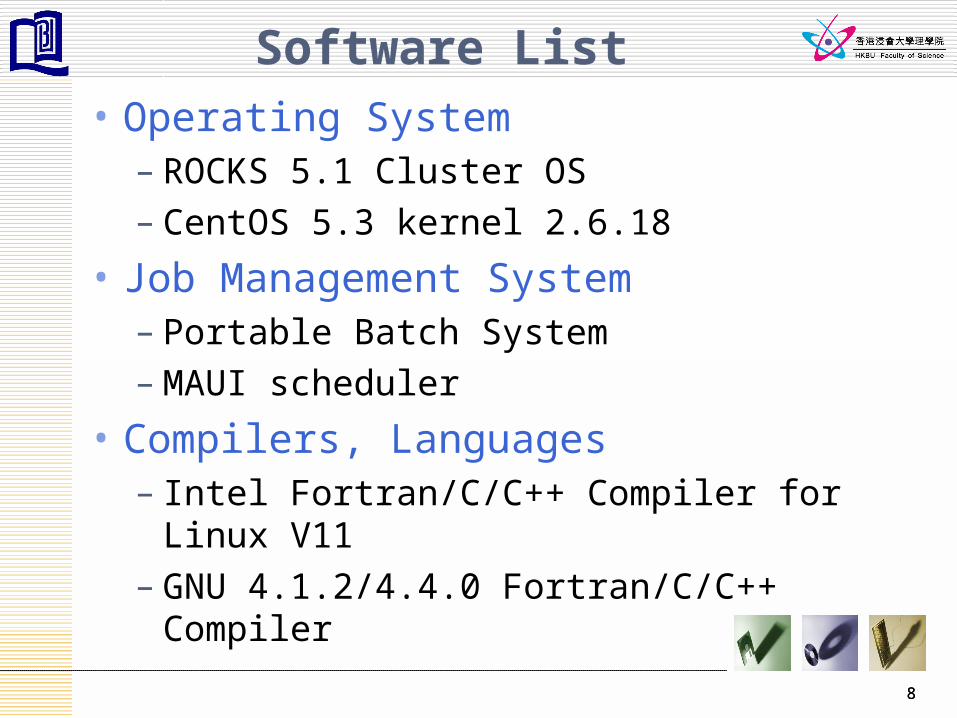
Software List• Operating System
– ROCKS 5.1 Cluster OS– CentOS 5.3 kernel 2.6.18
• Job Management System – Portable Batch System– MAUI scheduler
• Compilers, Languages – Intel Fortran/C/C++ Compiler for Linux V11– GNU 4.1.2/4.4.0 Fortran/C/C++ Compiler
8
9
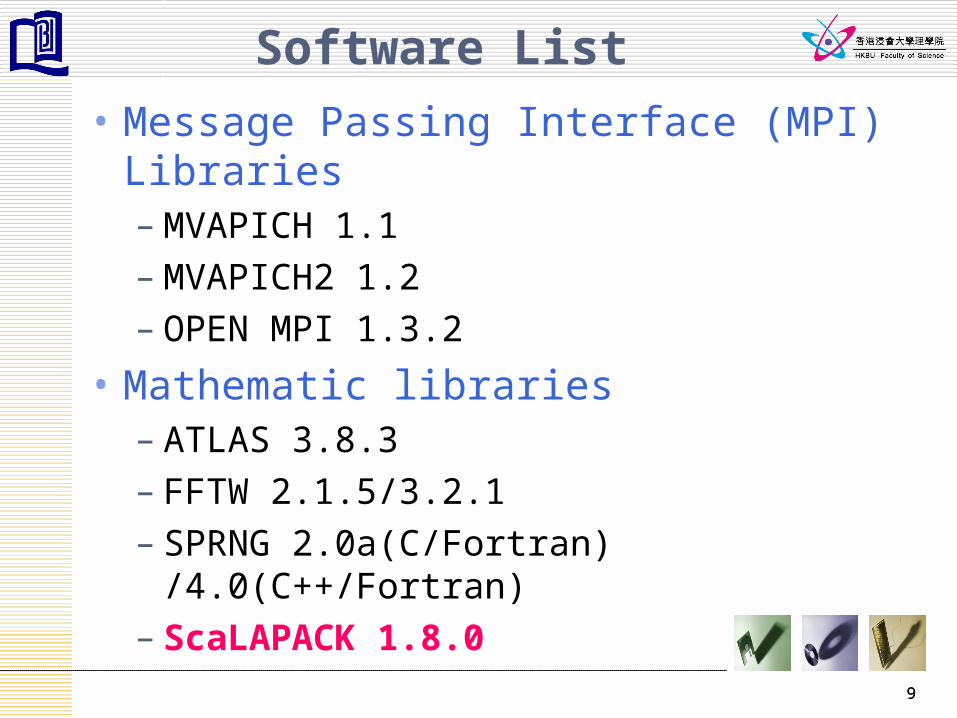
Software List
• Message Passing Interface (MPI) Libraries – MVAPICH 1.1– MVAPICH2 1.2– OPEN MPI 1.3.2
• Mathematic libraries – ATLAS 3.8.3– FFTW 2.1.5/3.2.1– SPRNG 2.0a(C/Fortran) /4.0(C++/Fortran)– ScaLAPACK 1.8.0
9
10
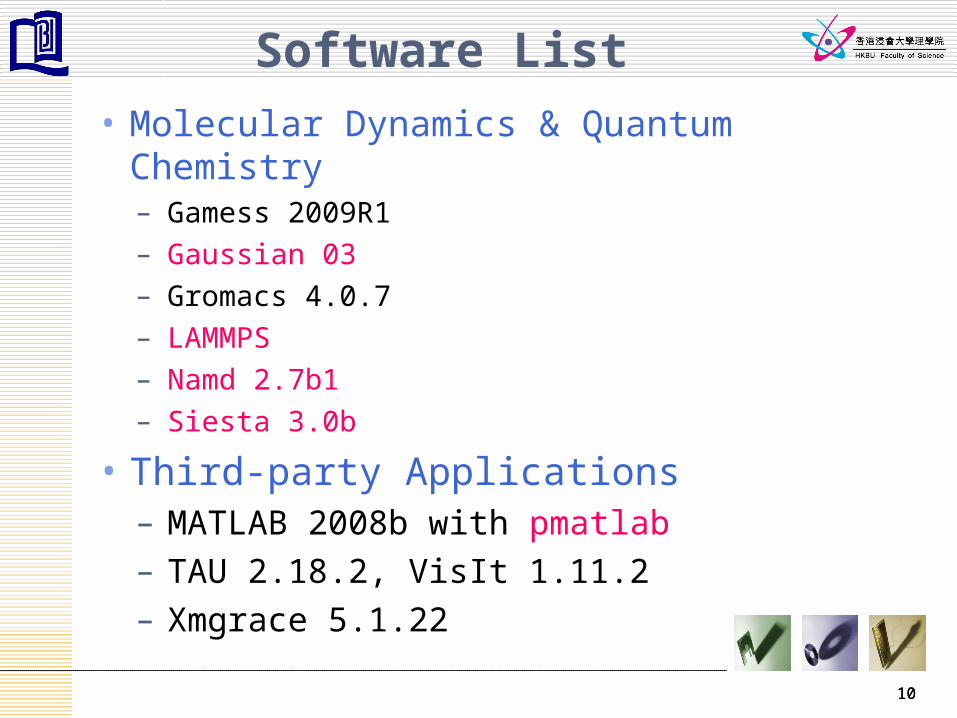
Software List
• Molecular Dynamics & Quantum Chemistry– Gamess 2009R1
– Gaussian 03
– Gromacs 4.0.7
– LAMMPS
– Namd 2.7b1
– Siesta 3.0b
• Third-party Applications – MATLAB 2008b with pmatlab– TAU 2.18.2, VisIt 1.11.2– Xmgrace 5.1.22
10
11
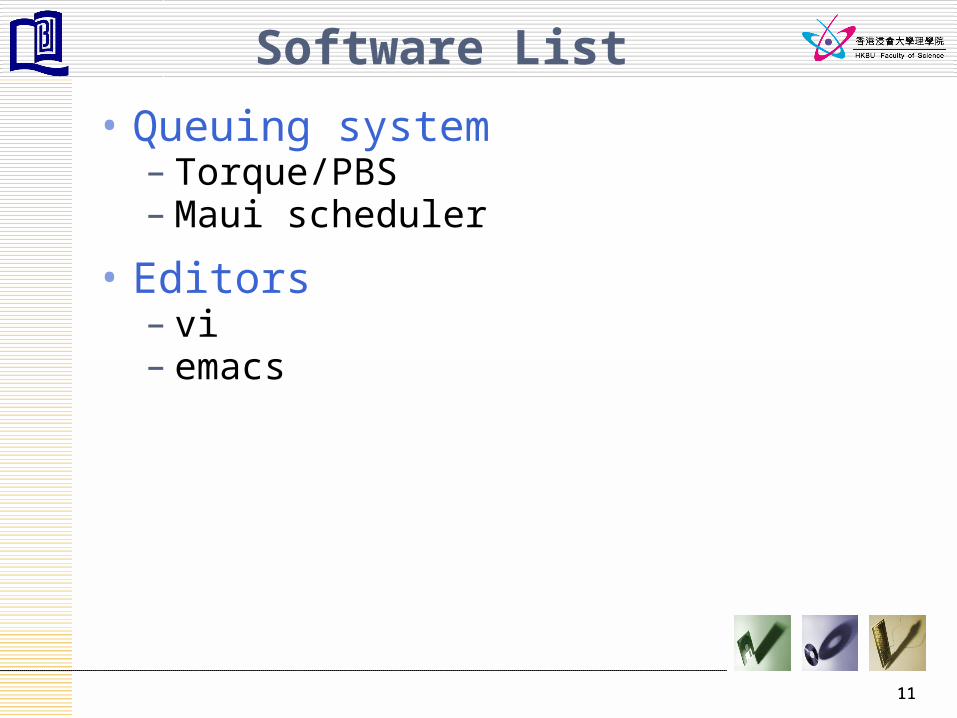
Software List
• Queuing system– Torque/PBS– Maui scheduler
• Editors– vi– emacs
11
12
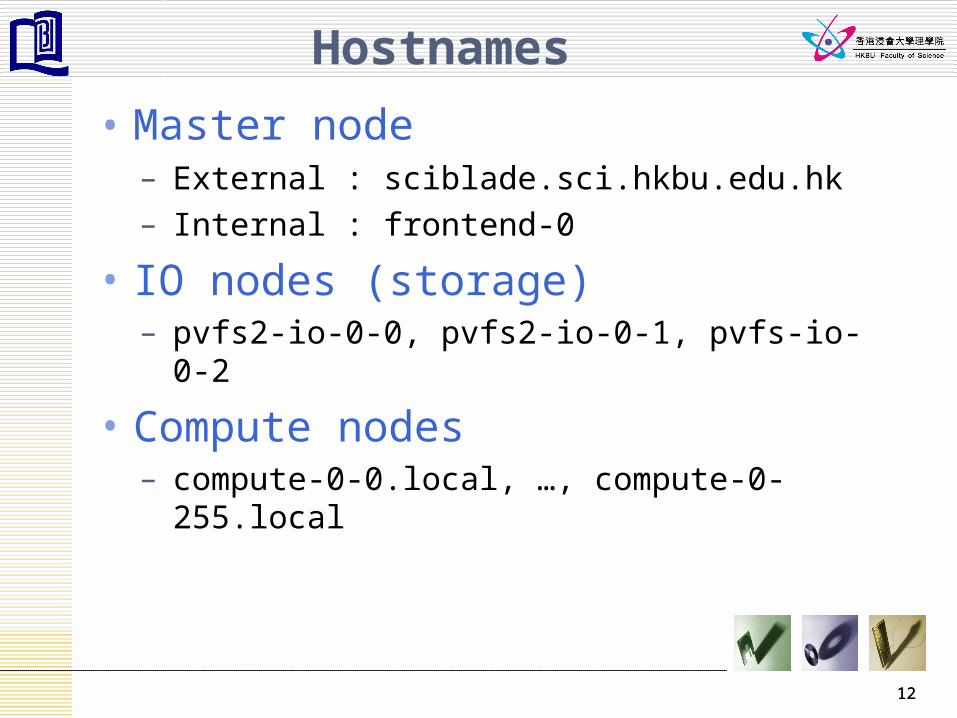
Hostnames
• Master node– External : sciblade.sci.hkbu.edu.hk– Internal : frontend-0
• IO nodes (storage)– pvfs2-io-0-0, pvfs2-io-0-1, pvfs-io-0-2
• Compute nodes– compute-0-0.local, …, compute-0-255.local
12

Basic Login and Job Submission Procedure
14
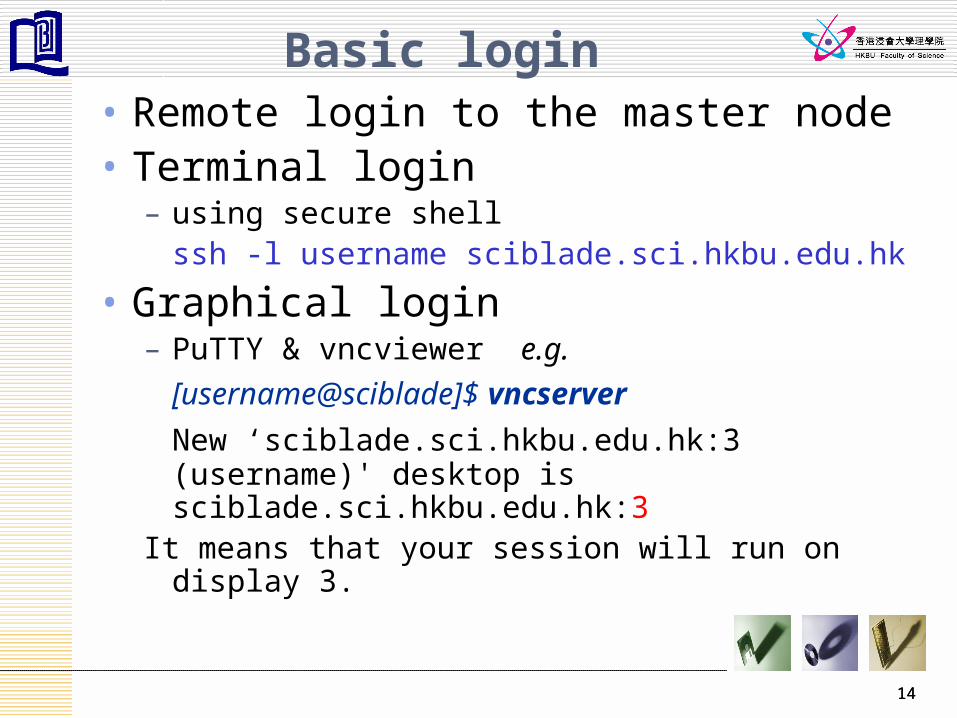
Basic login• Remote login to the master node• Terminal login
– using secure shellssh -l username sciblade.sci.hkbu.edu.hk
• Graphical login– PuTTY & vncviewer e.g.
[username@sciblade]$ vncserver
New ‘sciblade.sci.hkbu.edu.hk:3 (username)' desktop is sciblade.sci.hkbu.edu.hk:3
It means that your session will run on display 3.
14
15
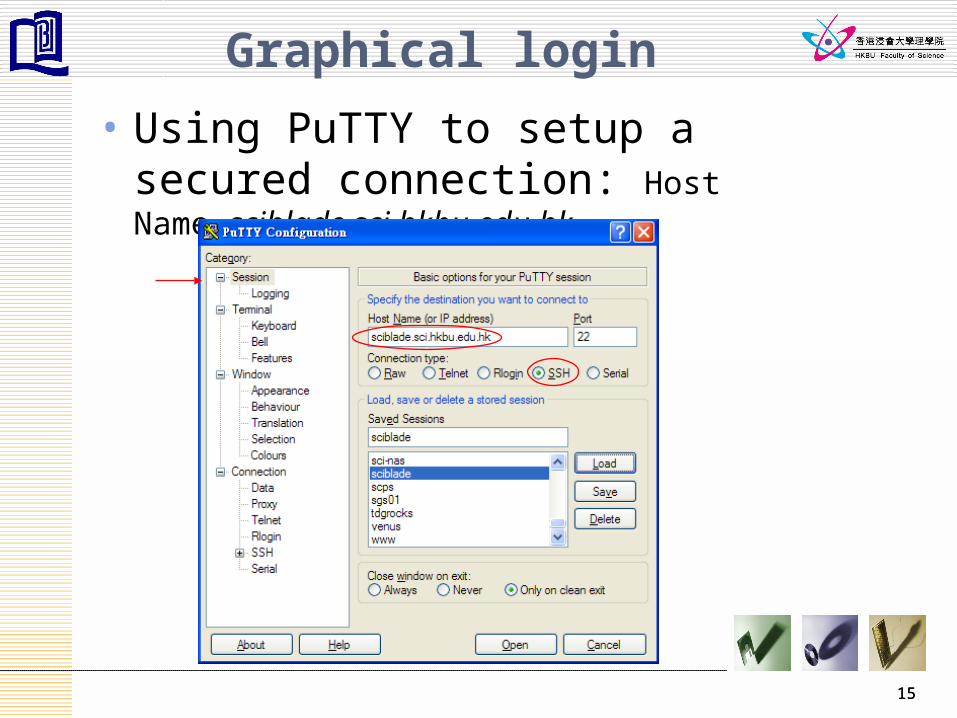
Graphical login
• Using PuTTY to setup a secured connection: Host Name=sciblade.sci.hkbu.edu.hk
15
16
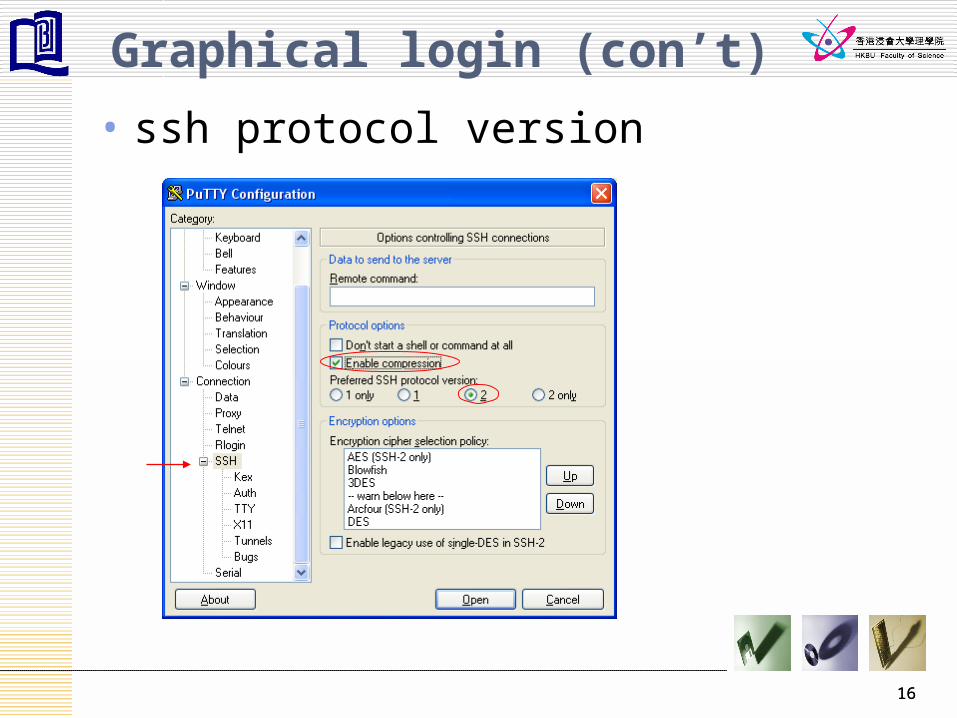
Graphical login (con’t)
• ssh protocol version
16
17
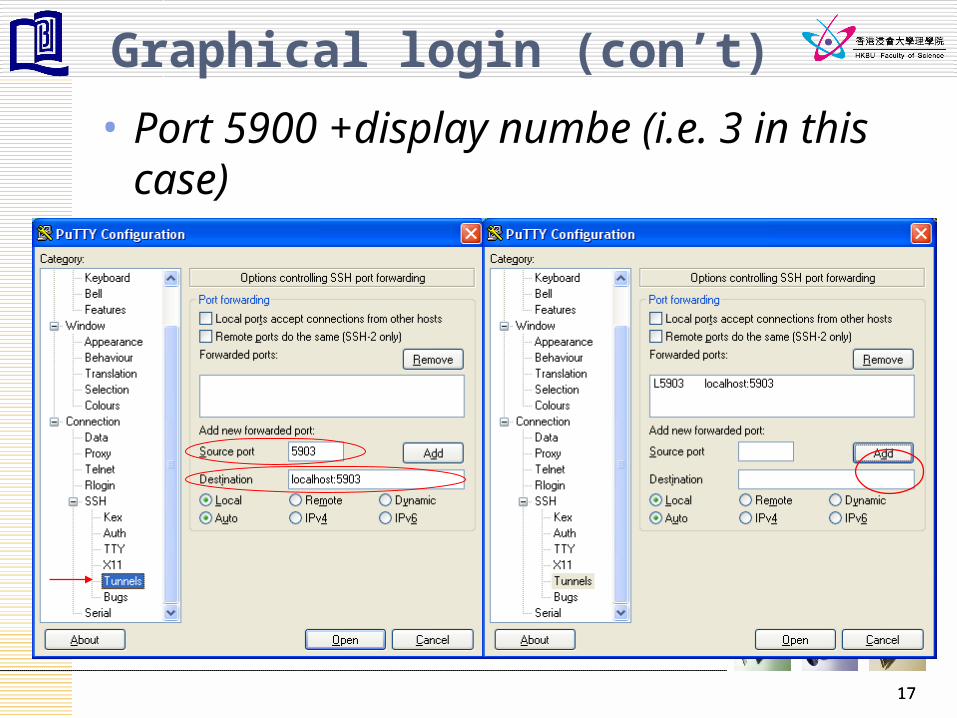
Graphical login (con’t)
• Port 5900 +display numbe (i.e. 3 in this case)
17
18
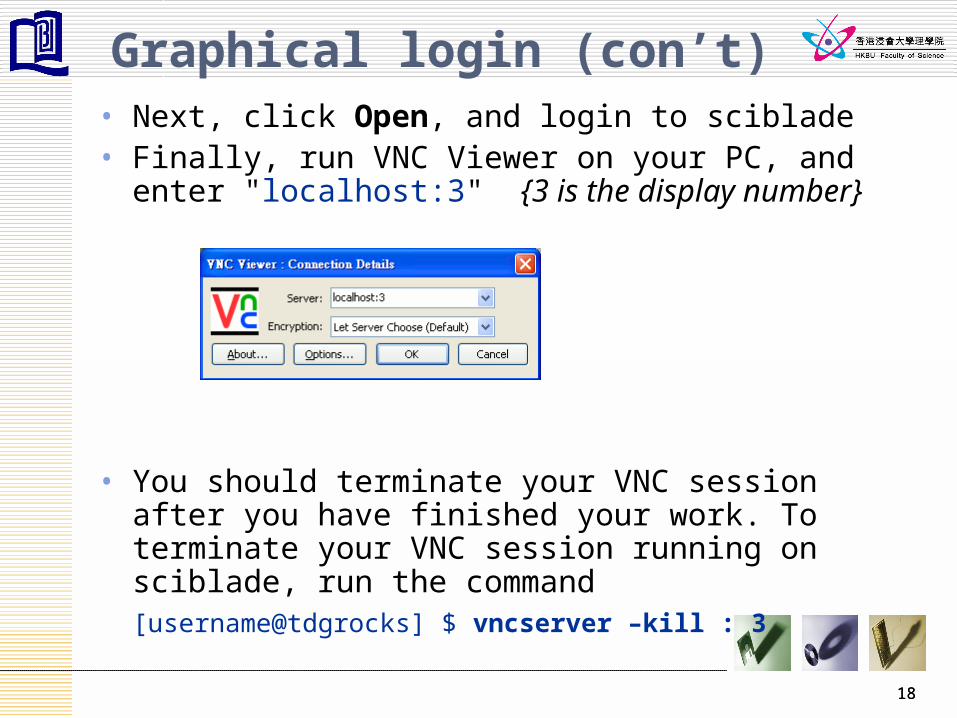
Graphical login (con’t)• Next, click Open, and login to sciblade• Finally, run VNC Viewer on your PC, and enter
"localhost:3" {3 is the display number}
• You should terminate your VNC session after you have finished your work. To terminate your VNC session running on sciblade, run the command[username@tdgrocks] $ vncserver –kill : 3
18
19
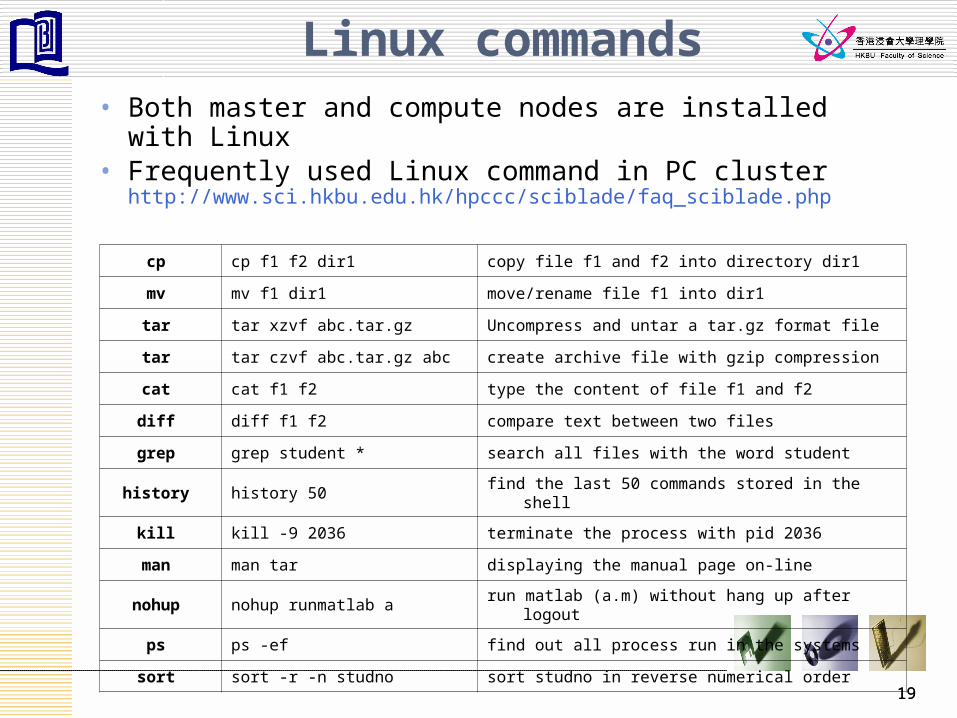
Linux commands• Both master and compute nodes are installed with
Linux• Frequently used Linux command in PC cluster
http://www.sci.hkbu.edu.hk/hpccc/sciblade/faq_sciblade.php
cp cp f1 f2 dir1 copy file f1 and f2 into directory dir1
mv mv f1 dir1 move/rename file f1 into dir1
tar tar xzvf abc.tar.gz Uncompress and untar a tar.gz format file
tar tar czvf abc.tar.gz abc create archive file with gzip compression
cat cat f1 f2 type the content of file f1 and f2
diff diff f1 f2 compare text between two files
grep grep student * search all files with the word student
history history 50 find the last 50 commands stored in the shell
kill kill -9 2036 terminate the process with pid 2036
man man tar displaying the manual page on-line
nohup nohup runmatlab a run matlab (a.m) without hang up after logout
ps ps -ef find out all process run in the systems
sort sort -r -n studno sort studno in reverse numerical order
19

20
ROCKS specific commands
• ROCKS provides the following commands for users to run programs in all compute node. e.g.– cluster-fork
• Run program in all compute nodes
– cluster-fork ps• Check user process in each compute node
– cluster-kill• Kill user process at one time
– tentakel• Similar to cluster-fork but run faster
20
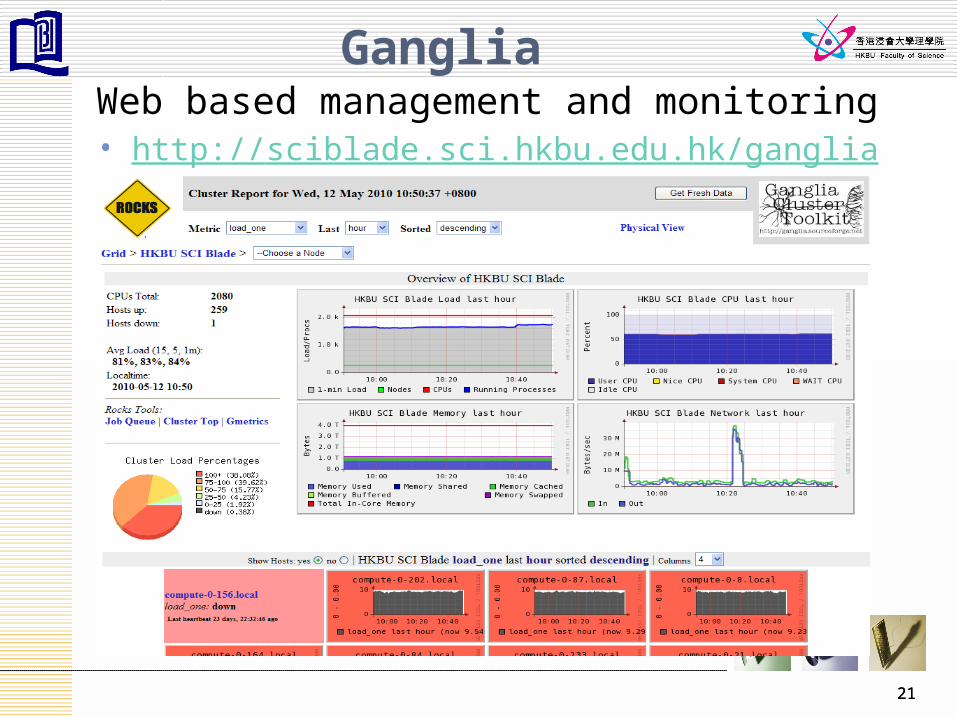
21
GangliaWeb based management and monitoring• http://sciblade.sci.hkbu.edu.hk/ganglia
21

Job Submission Procedures

23
Job Submission Procedure
• Prepare and compile a program, e.g. mpicc –o hello hello.c
• Prepare a job submission script, e.g.Qhello.pbs
• Submit the job using qsub. e.g.qsub Qhello.pbs
• Note the jobID. Monitor with showq or qstat
• Examine the error and output file. e.g.hello.oJobID, hello.eJobID
23
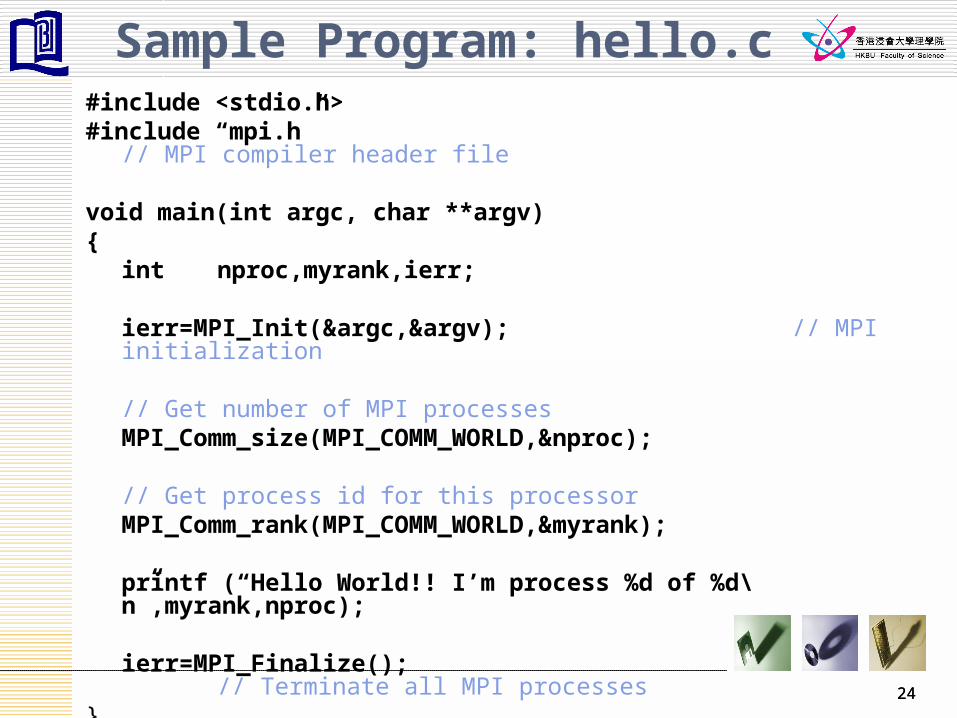
24
Sample Program: hello.c#include <stdio.h>#include “mpi.h” // MPI compiler header file
void main(int argc, char **argv) {
int nproc,myrank,ierr;
ierr=MPI_Init(&argc,&argv); // MPI initialization
// Get number of MPI processesMPI_Comm_size(MPI_COMM_WORLD,&nproc);
// Get process id for this processorMPI_Comm_rank(MPI_COMM_WORLD,&myrank);
printf (“Hello World!! I’m process %d of %d\n”,myrank,nproc);
ierr=MPI_Finalize(); // Terminate all MPI processes
}
24

25
Compiling & Running MPI Programs
• Using mvapich 1.1
1. Setting path, at the command prompt, type: export PATH=/u1/local/mvapich1/bin:$PATH
(uncomment this line in .bashrc)
2. Compile using mpicc, mpiCC, mpif77 or mpif90, e.g.mpicc –o hello hello.c
3. Prepare hostfile (e.g. machines) number of compute nodes:
compute-0-0compute-0-1compute-0-2compute-0-3
4. Run the program with a number of processor node:mpirun –np 4 –machinefile machines ./hello
25

26
Prepare parallel job script, Qhello.pbs#!/bin/sh
### Job name
#PBS -N hello
### Declare job non-rerunable
#PBS -r n
#PBS -l nodes=20
#PBS -l walltime=00:08:00
# This job's working directory
cd $PBS_O_WORKDIR
echo Running on host `hostname`
echo Time is `date`
echo Directory is `pwd`
echo This jobs runs on the following processors:
echo `cat $PBS_NODEFILE`
# Define number of processors
NPROCS=`wc -l < $PBS_NODEFILE`
echo This job has allocated $NPROCS nodes
# Run the parallel MPI executable “hello"
/u1/local/mvapich1/bin/mpirun -v -machinefile $PBS_NODEFILE -np $NPROCS ./hello
26
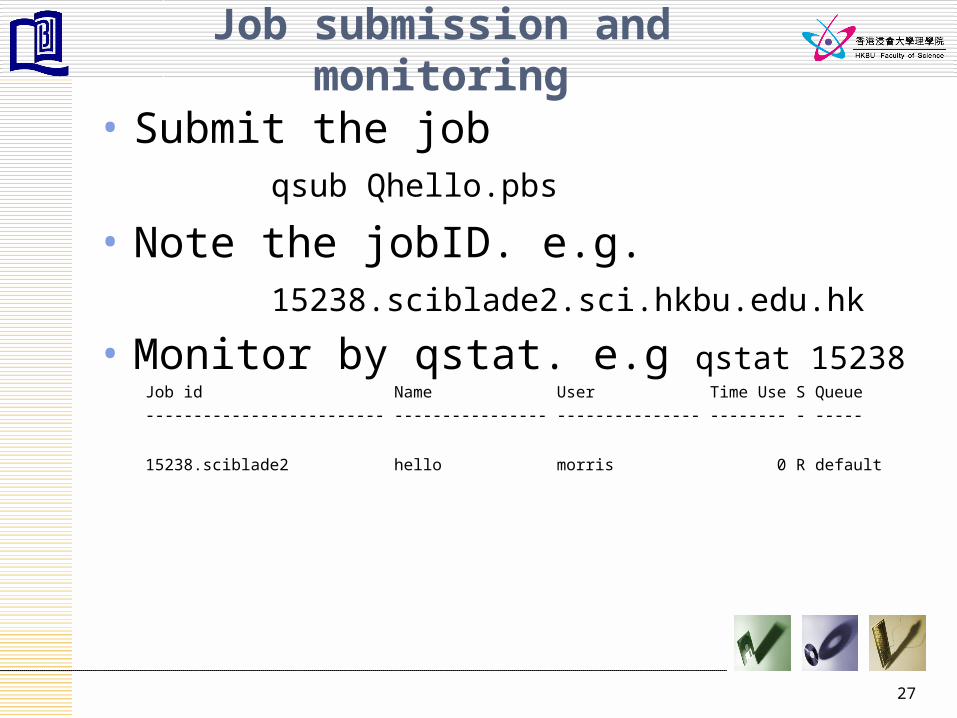
27
Job submission and monitoring
• Submit the jobqsub Qhello.pbs
• Note the jobID. e.g.15238.sciblade2.sci.hkbu.edu.hk
• Monitor by qstat. e.g qstat 15238Job id Name User Time Use S Queue
------------------------- ---------------- --------------- -------- - -----
15238.sciblade2 hello morris 0 R default
28
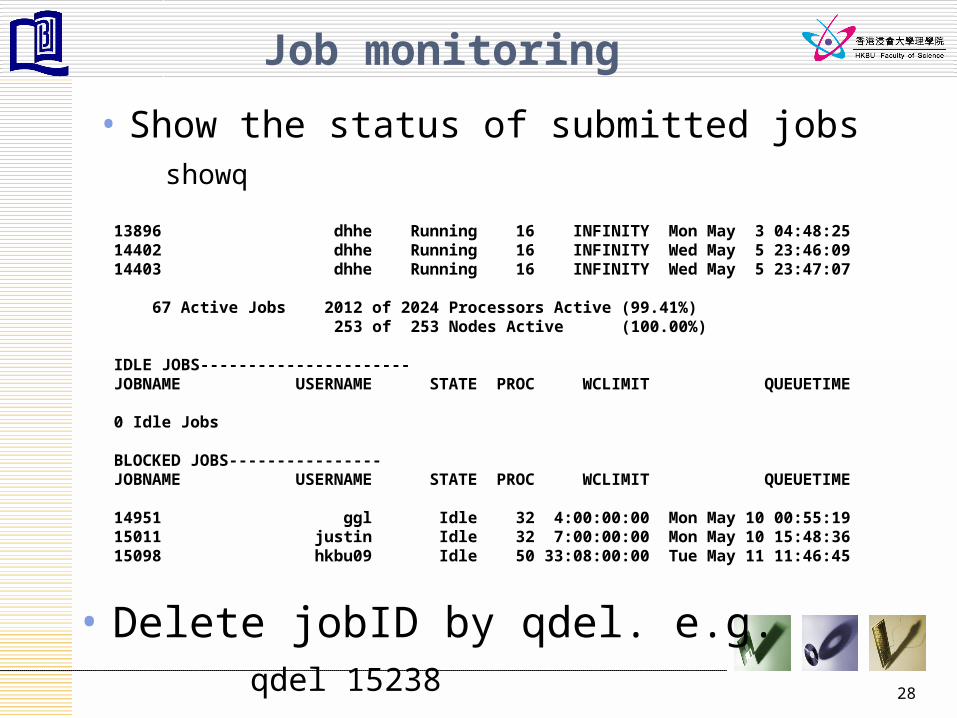
Job monitoring
• Show the status of submitted jobsshowq
13896 dhhe Running 16 INFINITY Mon May 3 04:48:2514402 dhhe Running 16 INFINITY Wed May 5 23:46:0914403 dhhe Running 16 INFINITY Wed May 5 23:47:07
67 Active Jobs 2012 of 2024 Processors Active (99.41%) 253 of 253 Nodes Active (100.00%)
IDLE JOBS----------------------JOBNAME USERNAME STATE PROC WCLIMIT QUEUETIME
0 Idle Jobs
BLOCKED JOBS----------------JOBNAME USERNAME STATE PROC WCLIMIT QUEUETIME
14951 ggl Idle 32 4:00:00:00 Mon May 10 00:55:1915011 justin Idle 32 7:00:00:00 Mon May 10 15:48:3615098 hkbu09 Idle 50 33:08:00:00 Tue May 11 11:46:45
• Delete jobID by qdel. e.g.qdel 15238

Assorted Program Examples

30
Example codes
• Updated example codes have been stored in /u1/local/share/examples/
• Copy all codes in one file /u1/local/share/examples.tar.gz
• Unzip and Untar using
tar xzvf examples.tar.gz

Example 1: OpenMP
/u1/local/share/examples/omp

32
OpenMP• The OpenMP Application Program Interface
(API) supports multi-platform shared-memory parallel programming in C/C++ and Fortran on all architectures, including Unix platforms and Windows NT platforms.
• Jointly defined by a group of major computer hardware and software vendors.
• OpenMP is a portable, scalable model that gives shared-memory parallel programmers a simple and flexible interface for developing parallel applications for platforms ranging from the desktop to the supercomputer.
32

33
OpenMP compiler choice
• gcc 4.40 or above– compile with -fopenmp
• Intel 10.1 or above– compile with –Qopenmp on Windows– compile with –openmp on linux
• PGI compiler– compile with –mp
• Absoft Pro Fortran– compile with -openmp
33

34
Sample openmp example
#include <omp.h>
#include <stdio.h>
int main() {
#pragma omp parallelprintf("Hello from thread %d, nthreads %d\n", omp_get_thread_num(), omp_get_num_threads());
}
34
35
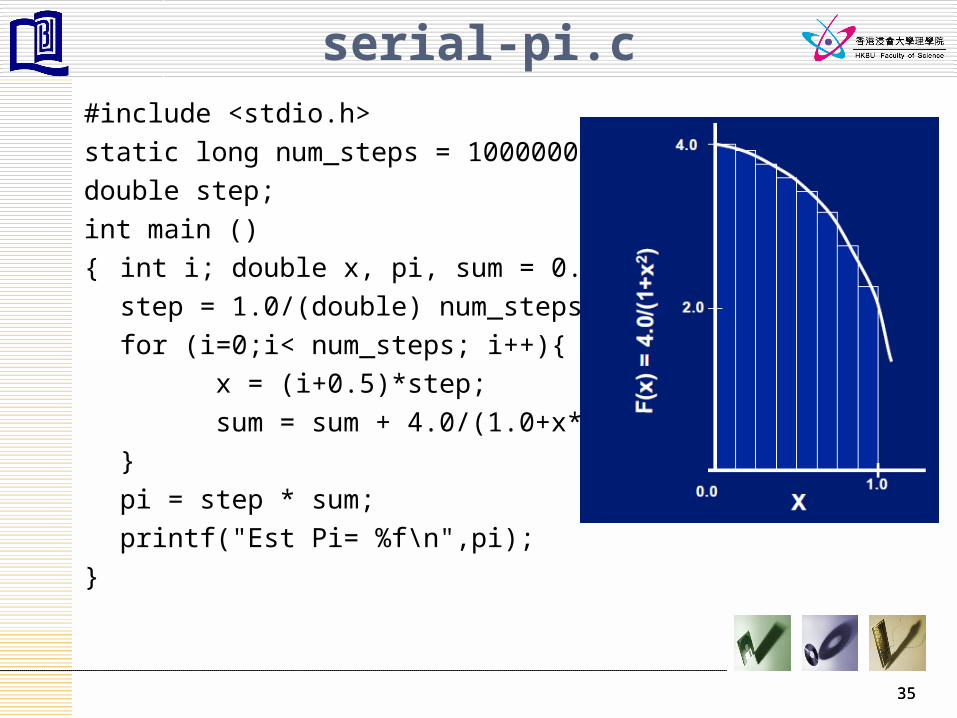
serial-pi.c#include <stdio.h>
static long num_steps = 10000000;
double step;
int main ()
{ int i; double x, pi, sum = 0.0;
step = 1.0/(double) num_steps;
for (i=0;i< num_steps; i++){
x = (i+0.5)*step;
sum = sum + 4.0/(1.0+x*x);
}
pi = step * sum;
printf("Est Pi= %f\n",pi);
}
35
36
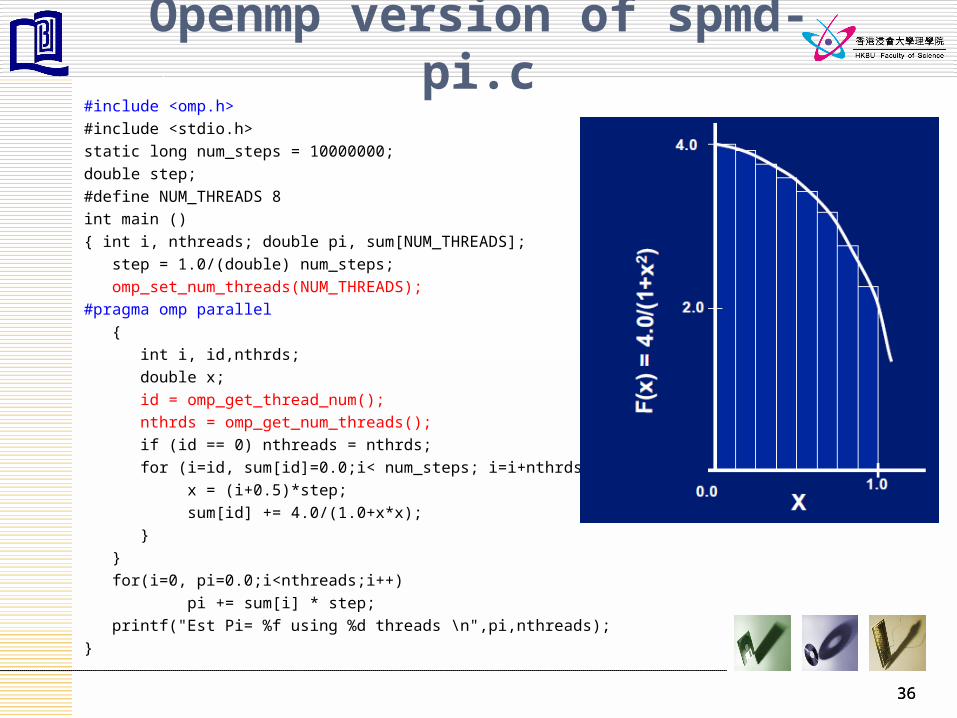
Openmp version of spmd-pi.c#include <omp.h>
#include <stdio.h>
static long num_steps = 10000000;
double step;
#define NUM_THREADS 8
int main ()
{ int i, nthreads; double pi, sum[NUM_THREADS];
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS);
#pragma omp parallel
{
int i, id,nthrds;
double x;
id = omp_get_thread_num();
nthrds = omp_get_num_threads();
if (id == 0) nthreads = nthrds;
for (i=id, sum[id]=0.0;i< num_steps; i=i+nthrds) {
x = (i+0.5)*step;
sum[id] += 4.0/(1.0+x*x);
}
}
for(i=0, pi=0.0;i<nthreads;i++)
pi += sum[i] * step;
printf("Est Pi= %f using %d threads \n",pi,nthreads);
}
36

37
Submit parallel jobs into torque batch queue Prepare a job script, say omp.pbs like the following
#!/bin/sh
### Job name
#PBS -N OMP-spmd
### Declare job non-rerunable
#PBS -r n
### Mail to user
##PBS -m ae
### Queue name (small, medium, long, verylong)
### Number of nodes
#PBS -l nodes=1:ppn=8
#PBS -l walltime=00:08:00
cd $PBS_O_WORKDIR
export OMP_NUM_THREADS=8
./omp_hello
./omp_test
./serial-pi
./omp-spmd-pi
Submit it using qsubqsub omp.pbs
37
38
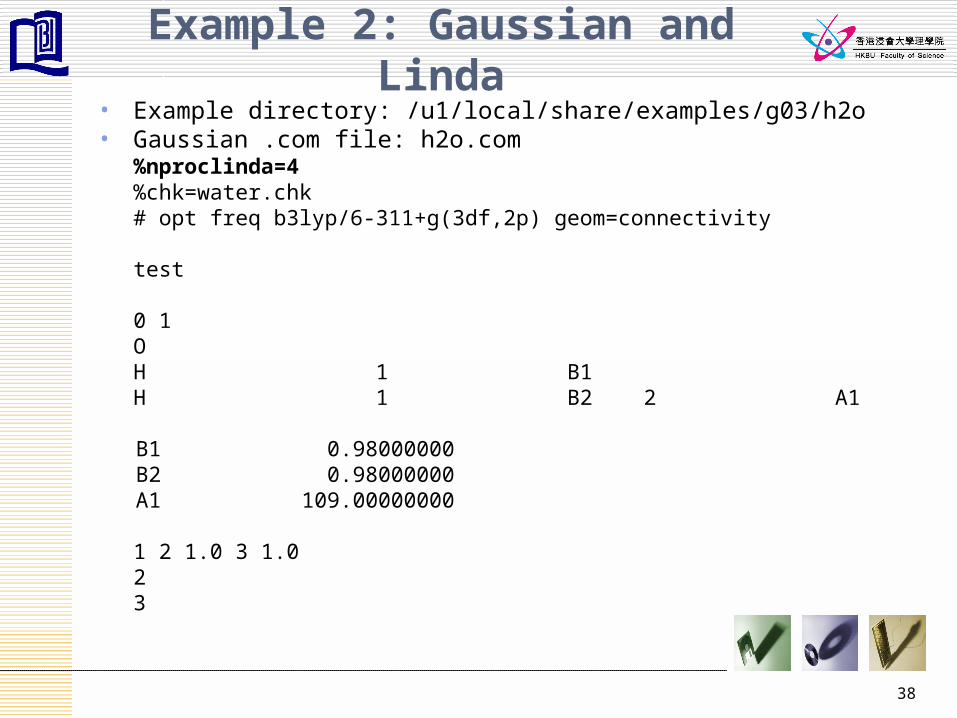
Example 2: Gaussian and Linda• Example directory: /u1/local/share/examples/g03/h2o• Gaussian .com file: h2o.com
%nproclinda=4%chk=water.chk# opt freq b3lyp/6-311+g(3df,2p) geom=connectivity
test
0 1O
H 1 B1 H 1 B2 2 A1
B1 0.98000000 B2 0.98000000 A1 109.00000000
1 2 1.0 3 1.0 2 3
39
Gaussian and Linda (Cont)
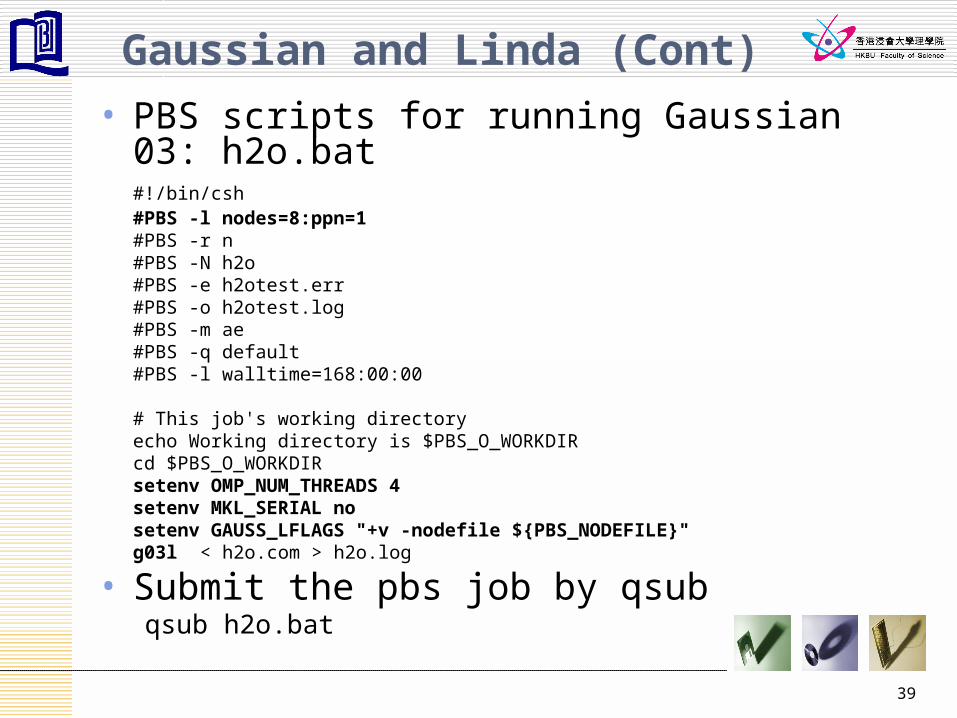
• PBS scripts for running Gaussian 03: h2o.bat#!/bin/csh#PBS -l nodes=8:ppn=1#PBS -r n#PBS -N h2o#PBS -e h2otest.err#PBS -o h2otest.log#PBS -m ae#PBS -q default#PBS -l walltime=168:00:00
# This job's working directoryecho Working directory is $PBS_O_WORKDIRcd $PBS_O_WORKDIRsetenv OMP_NUM_THREADS 4setenv MKL_SERIAL nosetenv GAUSS_LFLAGS "+v -nodefile ${PBS_NODEFILE}"g03l < h2o.com > h2o.log
• Submit the pbs job by qsubqsub h2o.bat

40
Example 3: Siesta 3.0b
• Spanish Initiative for Electronic Simulations with Thousands of Atoms
• perform electronic structure calculations and ab initio molecular dynamics simulations of molecules and solids.
• Project website: http://www.icmab.es/siesta
• Example directory: /u1/local/share/examples/siesta/h2o
41
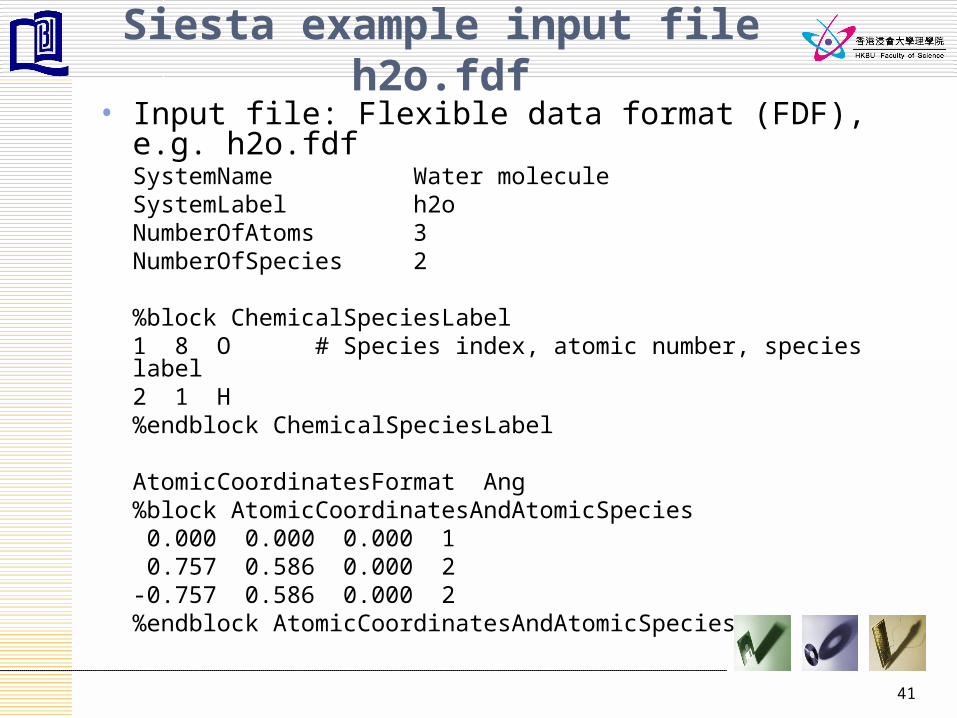
Siesta example input file h2o.fdf• Input file: Flexible data format (FDF), e.g. h2o.fdf
SystemName Water moleculeSystemLabel h2oNumberOfAtoms 3NumberOfSpecies 2
%block ChemicalSpeciesLabel 1 8 O # Species index, atomic number, species
label 2 1 H
%endblock ChemicalSpeciesLabel
AtomicCoordinatesFormat Ang%block AtomicCoordinatesAndAtomicSpecies 0.000 0.000 0.000 1 0.757 0.586 0.000 2-0.757 0.586 0.000 2%endblock AtomicCoordinatesAndAtomicSpecies
42
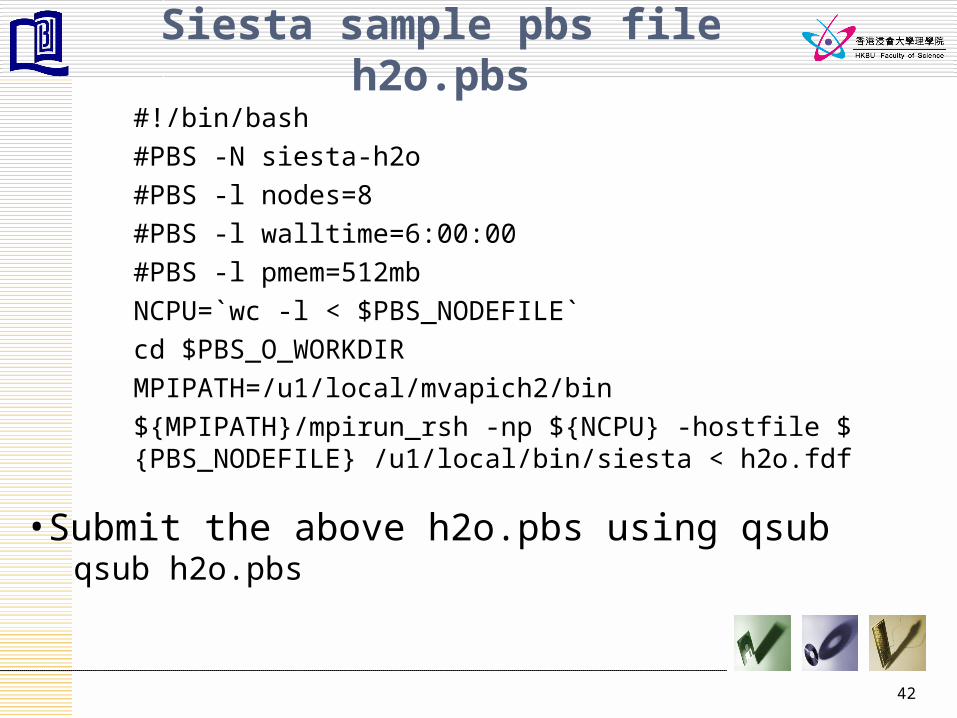
Siesta sample pbs file h2o.pbs
#!/bin/bash
#PBS -N siesta-h2o
#PBS -l nodes=8
#PBS -l walltime=6:00:00
#PBS -l pmem=512mb
NCPU=`wc -l < $PBS_NODEFILE`
cd $PBS_O_WORKDIR
MPIPATH=/u1/local/mvapich2/bin
${MPIPATH}/mpirun_rsh -np ${NCPU} -hostfile ${PBS_NODEFILE} /u1/local/bin/siesta < h2o.fdf
•Submit the above h2o.pbs using qsubqsub h2o.pbs
43
Example 4: pmatlab
• Pmatlab developed by MIT Lincoln Laboratory
• Installed with MATLAB 2008b• Example directory:
/u1/local/share/examples/pmatlab• Startup.m : matlab startup file• RUN.m : control file for running in
compute nodes• sample_app.m : main program• Qpmatlab.pbs : submit script

44
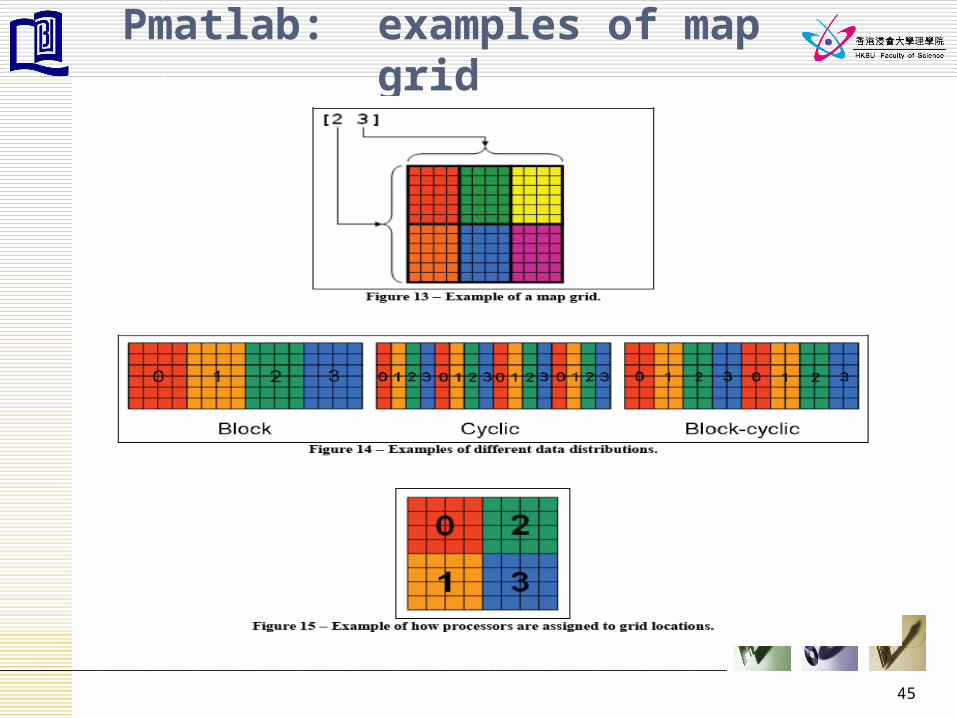
Pmatlab : idea of distributed matrix
• New data type: dmat• Overload functions: zeros, ones, rand, with
an additional parameter Map• Map tell pmatlab how and where dmat must
be distributed• Four components:
– Grids, e.g [2 3], 2 x 3 grids– Distributions:
• block – contiguous block of data• Cyclic – data are interleaved with processors• Block cyclic
– Processor lists, e.g. [0:nCPUs]
45
Pmatlab: examples of map grid

46
Example: Ring
ring/ring.cring/Makefilering/machines
Compile program by the command: makeRun the program in parallel bympirun –np 4 –machinefile machines ./ring < in
Example: Sorting
sorting/qsort.csorting/bubblesort.csorting/script.shsorting/qsort sorting/bubblesort
Submit job to PBS queuing system byqsub script.sh
Example: Prime
prime/prime.cprime/prime.f90prime/primeParallel.cprime/Makefileprime/machines
Compile by the command: makeRun the serial program by./primeC or ./primeFRun the parallel program bympirun –np 4 –machinefile machines ./primeMPI
Example: mcPi
mcPi/mcPi.cmcPi/mc-Pi-mpi.cmcPi/MakefilemcPi/QmcPi.pbs
Compile by the command: makeRun the serial program by: ./mcPi ##Submit job to PBS queuing system byqsub QmcPi.pbs
0
13
2
46

Policy for using sciblade.sci.hkbu.edu.hk
48
Policy1. Every user shall apply for his/her own computer user
account to login to the master node of the PC cluster, sciblade.sci.hkbu.edu.hk.
2. The account must not be shared his/her account and password with the other users.
3. Every user must deliver jobs to the PC cluster from the master node via the PBS job queuing system. Automatically dispatching of job using scripts or robots are not allowed.
4. Users are not allowed to login to the compute nodes.
5. Foreground jobs on the PC cluster are restricted to program testing and the time duration should not exceed 1 minutes CPU time per job.

49
Policy (continue)6. Any background jobs run on the master node or
compute nodes are strictly prohibited and will be killed without prior notice.
7. The current restrictions of the job queuing system are as follows,– The maximum number of running jobs in the job queue is 8.– The maximum total number of CPU cores used in one time
cannot exceed 512.
8. The restrictions in item 7 will be reviewed timely for the growing number of users and the computation need.

50
Good Practice in using sciblade
• logout from the master node after use
• delete unused files or compress temporary data
• estimate the walltime for running jobs and acquire just enough walltime for running.
• never run foreground job within the master node and the compute node
• report abnormal behaviours.

51
Acknowledgement
• When you make presentations or publish papers, we would appreciate it if you would kindly acknowledge the HPCCC by including: "This research was conducted using the resources of the High Performance Cluster Computing Centre, Hong Kong Baptist University, which receives funding from Research Grant Council, University Grant Committee of the HKSAR and Hong Kong Baptist University."
• Use of Center resources constitutes an agreement to provide copies of any publication or news stories concerning research conducted using our systems and/or consulting services.
• Please send acknowledgement e-mail to [email protected]. Thank you