clustering on database systems rkm
TRANSCRIPT

Clustering on Database Systems
Vahid Mirjalili
Michigan State University

Clustering• Partitioning data into groupsItems in the same group should have higher similarity to each
other than items from different groups
• A similarity/dissimilarity measure
• Examples: Clustering patients in a hospital
Genomic clustering
Hand-written character recognition
A. Jain, “Data Clustering: 50 years beyond K-means”
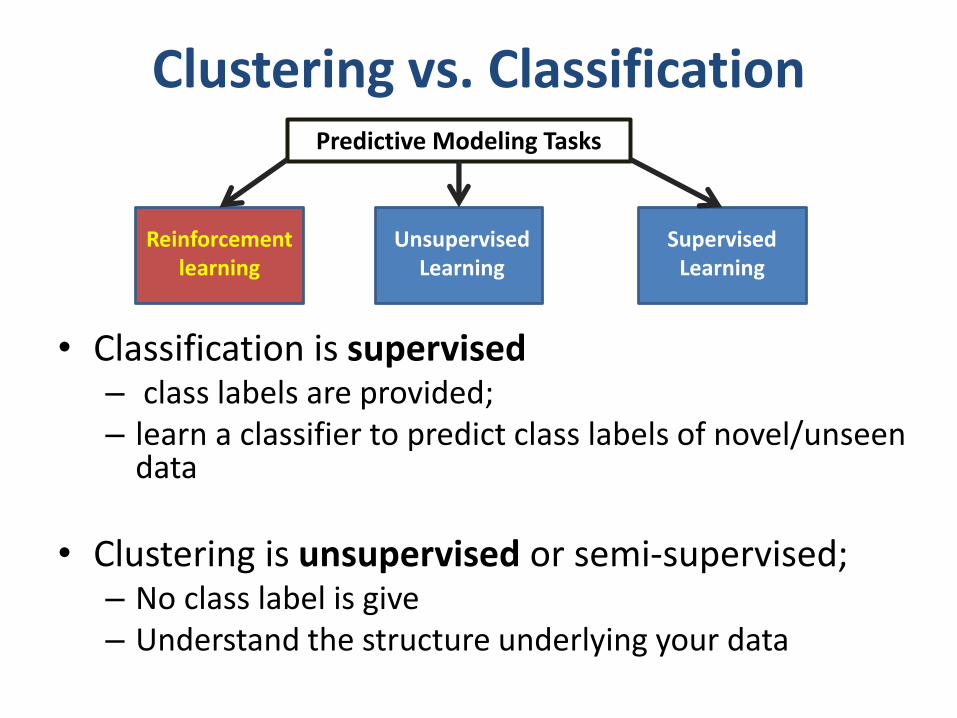
Clustering vs. Classification
• Classification is supervised– class labels are provided; – learn a classifier to predict class labels of novel/unseen
data
• Clustering is unsupervised or semi-supervised;– No class label is give– Understand the structure underlying your data
Reinforcement learning
Unsupervised Learning
Supervised Learning
Predictive Modeling Tasks

Clustering Approaches
Probability-based– Assuming statistical independence among features
– Inefficient updating and storing clusters
Distance-based– Assuming direct access to all data points
– Hierarchical clustering: O(N2), not giving the best clustering

Distance-Based Clustering Algorithms
• kmeans and its variants (kmedoids, kernel kmeans, fuzzy c-means, …)
• Density based methods (DBSCAN)
• Hierarchical methods

Challenges• Unknown number of clusters (from 1 to N)
Input data K=2 K=6
You always get some output as clusters
Are they really distinct clusters?
A. Jain, “Data Clustering: 50 years beyond K-means”

Challenges
• Clusters with different shapes, sizes and densities
Shapes: globular shape, linear vs. non-linear shapes
A. Jain, “Data Clustering: 50 years beyond K-means”

Standard K-Means Algorithm• Find initial Cluster centroids randomly
• An iterative algorithm1. Assignment step: assign each data point the
cluster whose mean is closest (smallest distance)
2. Update step: update the mean (centroid) of each cluster
Distance: squared Euclidean distance
Centroid: mean of feature vectors
Ci
i
C
XN
1
2
1
),(
d
j
jjxxdist

Standard K-Means Algorithm

Problem in Database-oriented Clustering
• Low memory available compared to size of dataset data doesn’t fit in main memory
• High I/O
• Necessary to avoid too many iterations

RKM: An Efficient Disk-based KMeansMethod
• Find the initial centroids by
• Only 3 iterations:– Assign every L points to nearest centroids;
– Update the cluster centroids
• Minor efficiency tricks:– Keep track of LS, SS and Nc for each cluster during
assignment update step:
NL
drallc /
cc NLS /

Implementation of RKM: storing data matrices
• D input dataset
• Pj cluster j (for j in [1..k])
• Mj, Qj, Nj Linear Sum, Squared Sum, cluster size
• Cj, Rj, Wj Centroids, Variances, Weights (accessed during update step)
kl
ljj
j
t
jjjjj
jjj
NNW
NMMNQR
NMC
..1
2
/
//
/

RKM avoids local minima: split large clusters
• Only performed if size of a cluster is less than a user-defined threshold
1. Remove the centroid of the small cluster
2. Find the largest cluster (largest Wj)
3. Randomly choose two centroids for the largest cluster (using Cj, and Rj)
4. Reassign the items of small and large clusters

RKM vs. Standard K-means: Random Dataset

RKM vs. Standard K-means: Initial Cluster Centroids
K = 3

Cluster assignment:Results after one pass over all the data
2 more iterationsMany iterations needed

RKM: Database design
• Relational schema for sparse data representation: D(pid, inx, value)
• For other matrices: doing 1 I/O per matrix row to minimize I/O
Matrix accessE step (assignment step)M step (update step)
Ordonez and Omiecinski, “Efficient Disk-Based K-Means Clustering for Relational Databases”

Performance Comparison• RKM (disk-based)
• Memory based:
– Standard K-means
– Scalable K-means
kj Pi
ji
j
CxdistC..1
),()(errorQuan.

Time Complexity of RKM
Ordonez and Omiecinski, “Efficient Disk-Based K-Means Clustering for Relational Databases”

Time Complexity
Ordonez and Omiecinski, “Efficient Disk-Based K-Means Clustering for Relational Databases”

Conclusion
• RKM resolve some of the limitations of K-means
• RKM limits disk access (I/O)
• Final clustering is achieved with 3 iterations
• On large datasets RKM outperforms standard K-means
• Other limitations of K-means clustering still remain

Read more …
General implementation in IPython notebook: http://goo.gl/YZScH9
http://www.vahidmirjalili.com