clusters part 2 - hardware lars lundberg the slides in this presentation cover part 2 (chapters 5-7)...
Post on 20-Dec-2015
213 views
TRANSCRIPT

Clusters Part 2 - HardwareLars Lundberg
The slides in this presentation cover Part 2 (Chapters 5-7) in Pfister’s book

Exposed vs. Enclosed Clusters
Intra-cluster communication
Enclosed
Exposed
Intra-cluster communication

Exposed Clusters
The nodes must communicate by messages, since public standard communication is always message-based
Communication has high overhead since it is based on standard protocols
The communication channel itself is not secure, so additional work must be done to ensure the privacy of intracluster communication
It is relatively easy to include computers that are spread out across a campus area or an company
These clusters are easy to build. In fact, you do not have to build them at all. It is just a matter of running the right software.

Enclosed Clusters
Communication can be by a number of means: shared disk, shared memory, messages etc.
It is possible to obtain communication with low overhead
The security of the communication is implicit It is easier to implement cluster software on
enclosed clusters, since security is not an issue, he cluster cannot be split into two parts that may have to be merged later

“Glass-House” vs. “Campus-Wide” Clusters
In the “glass-house” case the computers are fully dedicated to their use as shared computational resources and will therefor be located in a geographically compact arrangement (the glass-house)
In the “campus-wide” case (also know as NOW - Network Of Workstations) the computers are located on the users’ desks. Campus-wide clusters operate in a less-controlled environment and they must quickly and totally relinquish use of a node to a user.

The Four Categories of Cluster Hardware
I/O-Attached Message-Based I/O-Attached Shared Storage Memory-Attached Shared Storage Memory-Attached Message-Based

I/O-Attached Message-Based
Processor
Mem I/O
Processor
MemI/O
LANFDDIATMetc

I/O-Attached Shared Storage
Processor
Mem I/O
Processor
MemI/O

Memory-Attached Shared Storage(Global shared memory)
Processor
Mem I/O
Processor
MemI/OSharedMemory
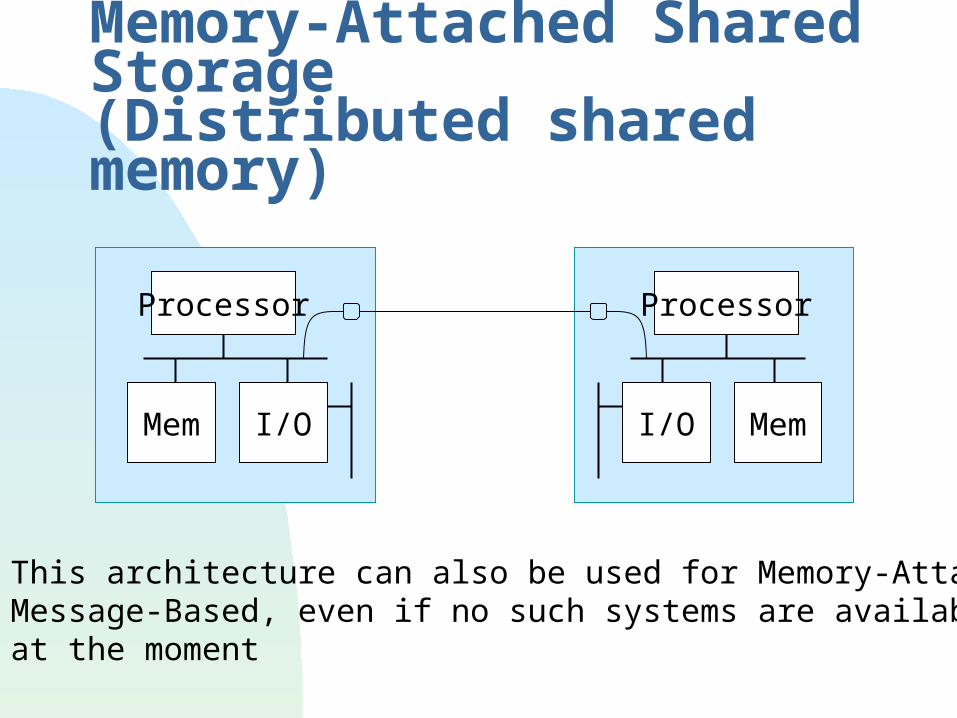
Memory-Attached Shared Storage(Distributed shared memory)
Processor
Mem I/O
Processor
MemI/O
This architecture can also be used for Memory-AttachedMessage-Based, even if no such systems are available at the moment

I/O- vs. Memory-Attached I/O-attached message-passing is the only possibility for
heterogeneous systems Memory attachment in general is harder than I/O
attachment, for two reasons: The hardware of most machines is designed to accept
foreign attachments in its I/O system The software for the basic memory-to-memory is more
difficult to construct When memory attachment is operational is can
potentially provide communication that is dramatically faster than that of I/O attachment

Shared Storage vs. Message-based Shared storage are considered to be easier to use and
program (Pfister is not only considering shared-disk clusters but also SMP computers)
Message-passing is considered to more portable and scalable
The hardware aspect is mainly a performance issue, whereas the programming model concerns the usability of the system, e.g. a shared memory (or disk) model can be obtained without physically sharing the memory or disk.

Communication Requirements The required bandwidth between the cluster nodes is
(obviously) very depending on the workload. For I/O intensive workloads the intra-cluster
communication bandwidth should at least equal the aggregate bandwidth from all other I/O sources that each node has.
The bandwidth requirements are particularly difficult to meet in shared nothing (message-based) clusters.
A number of techniques have been developed for increasing the intra cluster communication bandwidth (see Section 5.5 in Pfister’s book).

Symmetric Multiprocessors (SMPs)
Processor ProcessorProcessorProcessor
I/OMemory
Disk
LAN

SMP Caches
Processor ProcessorProcessorProcessor
I/OMemory
Disk
LAN
Cache CacheCacheCache

NUMA Multiprocessors
Processor
MMU Memory
Processor
MMU Memory
Processor
MMU Memory
Processor node
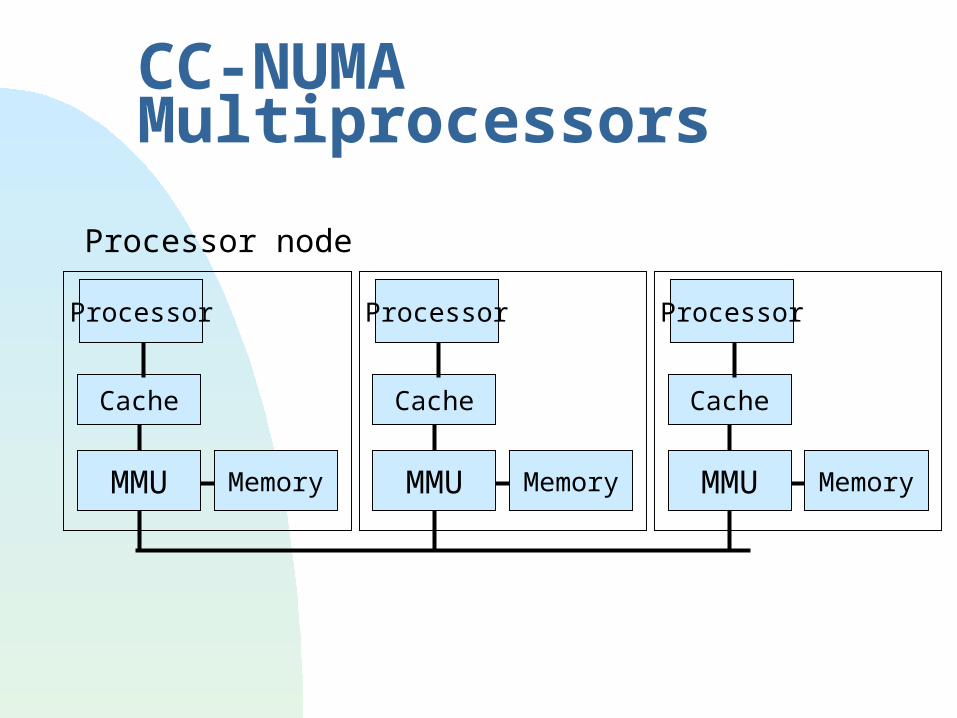
CC-NUMA Multiprocessors
Processor node
Cache
MMU Memory
Processor
Cache
MMU Memory
Processor
Cache
MMU Memory
Processor

COMA Multiprocessors
Processor node
Cache
MMUAttractionMemory
Processor
Cache
MMUAttractionMemory
Processor
Cache
MMUAttractionMemory
Processor

Running serial programs on a cluster It is simple (almost trivial), but very useful to run a number
of serial jobs on cluster. The relevant performance metric in this case is throughput.
Three types of serial workloads can be distinguished: Batch processing Interactive logins, e.g. one can log onto a cluster without
specifying a node. Useful in number-crunching applications with intermediate results
Multijob parallel, e.g. a sequence of coarse grained jobs (almost the same as batch processing)

Running parallel programs on a clusterWe classify parallel programs into two categories: Programs that justify that a large effort is used for making
them run efficiently on a cluster, e.g.: Grand challenge problems: global weather simulation etc. Heavily used programs, DBMS, LINPACK etc. Academic research
Programs where only a minimal effort is justified for making them run efficiently on a cluster, e.g.: Database applications - use parallel DBMS Technical computing - use parallel LINPACK etc. Programs that are parallelized automatically by the compiler

Amdahl’s Law
Total execution time = serial part + parallel part
If we use N processors (computers), the best we can hope for is the following:
Total execution time = serial part + (parallel part / N)
For instance, if the serial part is 5% of the total execution time, the best we can hope for is a speedup of 20 even if we use hundreds or thousands of processors.

Programming models Programs written to exploit SMP parallelism
will not work (efficiently) on clusters Programs written to exploit message-based
cluster parallelism will not work (efficiently) on SMPs
Pfister has a long discussion about this in chapter 9.

Serial program
do forever max_change = 0; for y = 2 to N-1 for x = 2 to N-1 old_value = v[x,y] v[x,y] = (v[x-1,y] + v[x+1,y] + v[x,y-1] + v[x,y+1])/4 max_change = max(max_change, abs(old_value - v[x,y])) end for x end for y if max_change < close_enough then leave do foreverend do forever

Parallel program - first attempt
do forever max_change = 0; forall y = 2 to N-1 forall x = 2 to N-1 old_value = v[x,y] v[x,y] = (v[x-1,y] + v[x+1,y] + v[x,y-1] + v[x,y+1])/4 max_change = max(max_change, abs(old_value - v[x,y])) end forall x end forall y if max_change < close_enough then leave do foreverend do forever

Parallel program - second attemptdo forever max_change = 0; forall y = 2 to N-1 forall x = 2 to N-1 old_value = v[x,y] v[x,y] = (v[x-1,y] + v[x+1,y] + v[x,y-1] + v[x,y+1])/4 aquire(max_change_lock) max_change = max(max_change, abs(old_value - v[x,y])) release(max_change_lock) end forall x end forall y if max_change < close_enough then leave do foreverend do forever

Parallel program - third attemptdo forever max_change = 0; forall y = 2 to N-1 row_max = 0; for x = 2 to N-1 old_value = v[x,y] v[x,y] = (v[x-1,y] + v[x+1,y] + v[x,y-1] + v[x,y+1])/4 row_max = max(row_max, abs(old_value-v[x,y])) end for x aquire(max_change_lock) max_change = max(max_change,row_max) release(max_change_lock) end forall y if max_change < close_enough then leave do foreverend do forever

Commercial programming models
For systems with a small (< 16) processors: Threads Processes that share a memory segment
For larger systems: Global I/O, i.e. all computers use the same
file system RPC (Remote Procedure Calls) Global Locks