coarse grained molecular dynamics - auusers-birc.au.dk/cstorm/students/siuda_dec2010.pdf · coarse...
TRANSCRIPT

Coarse Grained Molecular Dynamics
with
Domain Movements of Large Proteins
Iwona Siuda
Progress Report
December 2010
Department of Molecular Biology
Bioinformatics Research Centre (BiRC)
Membrane Pumps in Cells and Disease (PUMPKIN)
Aarhus University
Denmark

CONTENT
Preface ........................................................................................................................ i
1. Introduction ......................................................................................................... 1
2. Multi-domain Proteins ......................................................................................... 3
2.1. Test Set ............................................................................................................................. 3
2.2. Periplasmic Leucine Binding Protein ............................................................................... 5
2.3. SERCA ............................................................................................................................... 6
3. Methods .............................................................................................................. 8
3.1. Modelling Setups ............................................................................................................. 8
3.2. Molecular Dynamics Simulations .................................................................................... 8
3.3. All-Atom MD .................................................................................................................. 10
3.4. MARTINI CG MD ............................................................................................................. 10
3.5. ELNEDIN MD ................................................................................................................... 12
3.6. domELNEDIN MD ........................................................................................................... 13
4. Results and Discussion ....................................................................................... 15
4.1. AA Simulations ............................................................................................................... 15
4.1.1. Leucine Interactions ............................................................................................................ 16
4.1.2. Intra-domain Changes ........................................................................................................ 17
4.2. CG Simulations ............................................................................................................... 18
4.3. ELNEDIN .......................................................................................................................... 19
4.3.1. Model A and Model B ......................................................................................................... 19
4.3.2. Model C and Model D ......................................................................................................... 22
4.4. domELNEDIN .................................................................................................................. 23
4.4.1. Model A and Model B ......................................................................................................... 23
4.4.2. Model C and Model D ......................................................................................................... 24
5. Conclusions and Future Perspectives .................................................................. 27
References ................................................................................................................ 29
Appendix: SLEU Parameterization ............................................................................. 31

i
Preface
I am a Ph.D. student at the Department of Molecular Biology, within the field of
bioinformatics, and a member of the Structural Bioinformatics group at the
Bioinformatics Research Centre (BiRC). I started my Ph.D. studies November 1st 2009,
under supervision of Christian N. S. Pedersen and Lea Thøgersen at BiRC. My Ph.D.
project is concerned with developing and applying coarse grained molecular dynamics
methods to protein pumps, of interest to research centre for Membrane Pumps in Cells
and Disease (PUMPKIN). Thus, during the first part of my studies I have focused mainly
on the development and application of the domELNEDIN model - a “protein domain
version” of the ELNEDIN model (1), which is based on the established MARTINI coarse
grained force field (2-4).
In this report I will briefly introduce multiscale methods for molecular dynamics
simulations and steps that were taken to collect a set of proteins for the purposes of the
development and application of the domELNEDIN model. Then I will present the
methods for which simulations were set up and carried out, both at the all-atom level,
the MARTINI CG level, the ELNEDIN level, and the domELNEDIN level. Thereafter, the
obtained results will be discussed and the used methods will be evaluated. I will finish
this report with conclusions about the presented models, and a discussion about future
plans for the second part of my Ph.D. studies.
Iwona Siuda

1
1. Introduction
The main objective of my Ph.D. project is the development and application of a
method and a protocol to model the dynamics of the domain motion in the P-type
ATPases and other large multi-domain proteins. There are many different modelling
techniques, each proper for a particular time scale and detail level of the simulated
system. One of the atomic resolution techniques is all-atom (AA) molecular dynamics
(MD) simulation. This method remains a powerful tool for investigating the structure,
dynamics and function of many important biomolecular systems, like proteins and lipid
bilayers. However, the properties that make atomically detailed MD simulation such a
powerful tool are also its limitations. For an average size of the system, the number of
simulated atoms can easily reach thousands to millions of atoms, and the time scale
currently approachable is limited (due to the computer efficiency) to hundreds of
nanoseconds (5). This means that the most relevant dynamics and interactions within
cells (like protein-protein docking or rearrangement upon ligand binding), which occur
on the micro- and millisecond time scale, are currently out of reach for AA simulations.
As the fast and slow molecular dynamics are sufficiently independent, it should be
possible to ignore fast vibrations for the study of slow dynamics. Thus, to study the
mechanisms, dynamics and structural changes of ATPase pumps (6), some level of
coarse grained (CG) description of the system, can be applied.
In CG models, molecules are described by the interaction sites representing groups
of atoms, providing a reduced resolution description of a given system. These models
are expected to be highly computationally efficient, both because mapping atoms into
the sites reduce some of the degrees of freedom, and also because high frequency intra-
molecular vibrations have been incorporated into averaged effective interactions
between sites. Consequently, it is possible to choose a larger time step Δt, and therefore
speed up computations. Very different levels of CG models have been considered (7-9)
ranging from the “united atoms” approach, where only non-polar hydrogen atoms are
ignored, to mesoscale models using the rigid regions of well-defined equilibrium
structures identified within a biomolecule as the natural coarse grained elements (10).
Another level of system description is the “residue” resolution level represented by the
MARTINI CG model (2-4), where the atoms of each residue are mapped into two to five
beads. In CG models with “residue” level resolution, the lack of proper hydrogen bond
description can make it necessary to combine CG model with an elastic network to
maintain the overall shape of the protein (1).
In the group of models named elastic network models (ENM) (7,9), the structure of a
macromolecule is described as a network of points of masses connected to each other
with springs when the distance between the point of masses is less than a predefined
cut-off distance Rc. The strength of the springs, and therefore the rigidity of the network,
is characterized by the spring force constant Ks. There are different usages of the
network models like e.g. combining them with normal mode analysis (NMA) for the

2
analysis of the principal modes of a large variety of different systems (11), or with CG
models to maintain the overall shape of the protein during MD simulations (1). This is
done in the extension to the MARTINI CG force field called ELNEDIN (1). The use of ENM
with MARTINI allows the study of large complex proteins and their interactions with the
surrounding and each other on the microsecond time scale of a resolution describing
specific residue interactions. However, as the ENM restrain the initial protein structure,
conformational shifts are impossible to observe.
With my project I therefore wished to experiment with a modification of the
ELNEDIN approach, where the ENM scaffold is put on each domain separately,
restraining movements inside domains, while at the same time allowing inter-domain
movements. Depending on the generality of such model, it will make a whole new range
of theoretical studies of the ATPase pumps as well as other multi-domain proteins
possible. This proposed approach is called domELNEDIN, and the preliminary testing of
this model is the core of the work presented in this report.

3
2. Multi-domain Proteins
The main target of my Ph.D. project are the cell membrane pumps, belonging to the
family of P-type ATPase, with a special focus on a sarco-endoplasmic reticulum Ca2+-
ATPase (SERCA). These cell membrane pumps are made of multiple functional domains
that may undergo substantial displacements essential for their functioning. Exploring the
conformational space of large-scale domain rearrangements may be useful, for example,
for testing hypotheses about the possibility of interactions between the multi-domain
protein and a small molecule, often a ligand, in docking procedure. There are two main
types of motions that can reproduce domain movements, the “shear” and “hinge-
bending” motions (12). An individual “shear” motion is small (due to involvement of
amino acid residues that are distributed over extended areas of the protein), and thus a
single one is usually not sufficient to produce a large domain movement (12). In the
“hinge-bending” movement a relatively small number of residues of a polypeptide chain
significantly changes mutual domain position (12). As multiple conformations SERCA are
known, it can be seen that domain movements in this membrane pump are of the
second type. For all the proteins that have two domains connected by linking hinge
regions, a few large torsion angle changes are sufficient to produce almost the whole
domain motion. The rest of the protein rotates essentially as a rigid body, thus the intra-
domain structure remains unchanged between the conformations. In order to develop
and test the domELNEDIN model for describing domain movements, a test set of multi-
domain proteins was built.
2.1. Test Set
To test the domELNEDIN model and confirm that for many proteins during
conformational shifts the protein intra-domain structure remains essentially unchanged,
a set of 40 protein structures resolved in at least two conformations has been compiled.
After further investigation eight proteins were selected (Fig. 1), where the root-mean-
square deviation (RMSD) between all Cα atoms for the two conformations of the same
protein was higher than 1.6 Å (Tab. 1).
Figure 1 A selection of the proteins in the test set collected for studying protein domain interfaces. For all of the proteins the structure is known in at least two conformations (Figure created using VMD (13)).

4
Table 1 The RMSD between Cα of two different conformations of the same protein.
Molecule PDB Structure PDB Structure RMSD [Å]
1. Leucine Binding Protein 1USK (14) 1USG (14) 7.04
2. Aspartate Aminotransferase 1AMA (15) 9AAT (16) 1.66
3. Citrate Synthase 4CTS (17) 1CTS (18) 2.37
4. Fibronectin 1E8B (19) 1E88 (19) 2.79
5. Phosphotransferase System, Enzyme I 2EZA (20) 3EZA (21) 1.86
6. Cyanovirin-N 1L5B (22) 1L5E (22) 6.51
7. Cbl 1B47 (23) 2CBL (23) 1.87
8. HIV-1 Reverse Transcriptase 2HMI (24) 1HVU (25) 5.73
To develop and test a procedure for coarse graining at the protein domain level,
each domain had to be defined. In general, the functional domains can fold and function
independently. However, when it comes to dividing a protein into domains there is no
unambiguous definition of how to do it. There are several methods for the protein
domain identification, but for the purposes of this project an automatic domain-parsing
procedure called DDOMAIN (26), available as a web server at http://sparks.informatics.
iupui.edu/hzhou/ddomain.html, was used. It is based on the principle that inter-domain
interaction is weak under a correct domain assignment. All residues coordinates (Nr) for
a structure submitted to this server are considered as continuous from 1 to Nr. Then the
structure is divided into two candidate domains: residues from 1 to i and from i + 1 to Nr,
with the only assumption that a domain must be 40 residues or longer. The domain-
domain interactions are calculated either by the residue-residue contacts or by a
normalized residue-based or distance-based energy profile. The lowest value of the
energy profile indicates a boundary point between the domains. After defining two
domains, each of them is inspected in order to see if it can be further divided into
smaller domains. To optimize the results, energy profile parameters are trained, tested,
and compared to the annotations of the three following data sets: AUTHORS (domain
definitions are given by the authors who solved protein structures), CATH (37) and SCOP
(38). Results obtained from the DDOMAIN server were further investigated by visual
inspection using VMD (13). If the two conformations of the same protein did not get the
same domain definition it was changed manually to best fit based on visual inspection.
Based on the domain definitions for the eight selected proteins, the RMSDs between
the same domains in different protein conformations were computed (Tab. 2).
Comparing results from Table 2 to those from Table 1 shows that for some of the pdb
structures in the test set, like 1B47 and 2CBL, or 1USK and 1USG, each domain remains
essentially unchanged during the conformational shifts. Thus, it seems promising to
model conformational changes by coarse graining at the protein domain level.

5
Table 2 The RMSDs and average RMSDs computed for the same domains in different protein conformations.
RMSD [Å]
PDB Structures Domain 1 Domain 2 Domain 3 Domain 4 Average
1. 1USK - 1USG 0.73 0.63 - - 0.68
2. 1AMA - 9AAT 1.64 0.33 0.98 - 0.98
3. 4CTS - 1CTS 1.14 1.61 - - 1.38
4. 1E8B - 1E88 1.23 1.12 1.07 - 1.14
5. 2EZA - 3EZA 1.31 0.99 - - 1.15
6. 1L5B - 1L5E 1.72 0.45 - - 1.09
7. 1B47 - 2CBL 0.62 0.46 - - 0.54
8. 2HMI - 1HVU 1.87 2.09 0.77 0.90 1.41
2.2. Periplasmic Leucine Binding Protein
Based on the significant difference in the RMSD between the two conformations
(1USK and 1USG) of the periplasmic Leucine Binding Protein (LBP) (14) (RMSD of 7.04 Å),
and between the same domains in different conformations (RMSD of 0.68 Å), the LBP
was chosen as main test example for further method development.
The LBP is the primary receptor for the leucine transport system in E. coli, and
undergoes hinge movements associated with large conformational changes upon ligand
binding. The structure was resolved and refined in an open ligand-free form (PDB: 1USG
(14)) (Fig. 2B) to a resolution of 1.5 Å, and in a closed form with leucine bound (PDB:
1USK (14)) (Fig. 2A) to a resolution of 2.4 Å. LBP is a 346 residue protein made of two
domains each consisting of a central β-sheet flanked by α-helices. The first domain
contains residues 1-120 and 251-329 and the second contains residues 121-250 and 330-
345 (14). The domains are linked by a three stranded hinge (Fig. 2) spanning residues
117-121 for connection I, 248-252 for connection II and 325-331 for connection III (14).
Most of the changes in the main-chain torsion angles that determine the observed
motions occur in the connections I and III, which form the direct links between the β-
sheets of two domains. Connection II merely adapts, as a short helix (residues 251-255)
is placed next to the hinge region. In general, the residues in helices are subject to more
severe hydrogen-bonding and steric constraints than those in sheets, thus the possible
changes in helices torsion angles are correspondingly smaller than those of the residues
in sheets (12). In the holo form leucine binds to the LBP in a cleft formed between the
two domains involving hydrogen-bonding and non-polar contributions.
The domains in the LBP and the cytoplasmic domains in SERCA, share similar features
as they both contain both α-helical and β-sheet elements, and are subjected to hinge
movements. This, as well as the straight-forwarded coarse graining of the ligand leucine,
makes this protein a relevant and convenient test example.

6
Figure 2 The two conformations of LBP, domain 1 shown in blue, domain 2 in red, and hinge region in grey. A: the holo form (1USK) with leucine positioned in the cleft between the two domains; B: the apo form (1USG). Comparison of the Cα backbone of 1USK (blue) and 1USG (red) C: the whole structures, D: domain 2 from the two conformations, E: domain 1 from the two conformations (Figure created using VMD (13)).
2.3. SERCA
From the superfamily of P-type ATPases, SERCA is by far the most studied, and more
than 30 structures representing several conformational states with different inhibitors
and substrates along the catalytic cycle, are known. SERCA is therefore an obvious test
protein for the domELNEDIN model, before it is applied to the other membrane pumps.
SERCA is a 994 residue protein consisting of one transmembrane and three
cytoplasmic domains. The schematic figure (Fig. 3A) of the first-determined high-
resolution (2.6 Å) structure of SERCA (27) presents the cytoplasmic headpiece consisting
of three well defined domains: A (Actuator), N (Nucleotide-binding), and P
(Phosphorylation), and ten transmembrane α-helices denoted as TM1-TM10. The
functional cycle (Fig. 3B) is denoted by E1 and E2 states that refer to the binding and
active transport of cytoplasmic Ca2+ and the counter transport of luminal H+ to the
cytoplasm, respectively (6). The Ca2+ transport cycle starts in the E2 state, where 2‐3
protons are expected to be bound in the Ca2+ ion binding sites (the helices TM4-TM6 and
TM8 have been considered to form a binding site (27) for Ca2+ ions), and ATP is proposed
to be bound to the N‐domain. After dephosphorylation of ATP and phosphorylation of
the protein, the transition from the E2 to the Ca2E1~P state, associated with Ca2+
binding and release of protons, occurs. The energy derived from the ATP hydrolysis is
used to translocate the two Ca2+ ions from the cytoplasm to the sarcoplasmic reticulum
lumen against a steep concentration gradient. Consequently, after domain
rearrangement, the protein changes conformation to the E2P state in which the
transmembrane region opens and the Ca2+ ion binding sites are exposed to the luminal
pathway allowing the Ca2+ ions’ release. Next, 2-3 protons and ATP are taken up by the
cation binding sites and the transmembrane region closes off, causing conformational
change to the E2‐Pi state. The cycle is then completed with release of the inorganic
phosphate (6).
A B
C D E

7
Figure 3 A: The structure of SERCA. The three cytoplasmic domains are labelled A, N and P, and TM helices are labelled from 1-10. The colour changes gradually from blue in the N-terminus to red in the C-terminus. An ATP analogue bound to the N-domain is shown in CPK (Figure from (27)). B: The functional cycle of SERCA illustrated with four cornerstones. Domain A is shown in yellow, domain N in red, domain P in blue, TM1‐2 in purple, TM3‐4 in green, TM5‐6 in wheat and TM7‐10 in grey, Ca
2+ ions are shown as grey spheres
(Figure from (6)).
As mentioned before, SERCA is an obvious test protein for domELNEDIN model
before it is applied to the other membrane pumps. However, this protein is very
complex, and the method proposed in this project has not yet been tested with SERCA.
A B

8
3. Methods
The LBP was studied in four different simulation setups. As the interactions between
the CG sites are parameterized from atomic interactions, the results from the CG
simulations must be consistent with results obtained from the atomistic model. Thus, all
setups were studied; both at the AA level (28), the MARTINI CG level (2-4), the ELNEDIN
level (1), where an elastic network model is put on top of MARTINI model, as well as
with the domELNEDIN level where the elastic network is only set up internally in the
domains.
3.1. Modelling Setups
The four modelling setups of the LBP (Tab. 3) are as follows; Model A – the crystal
structure of the apo form, Model B – the crystal structure of the holo form, Model C –
the apo form with leucine bound, and Model D – the holo form without leucine bound.
In Model C, leucine was positioned in the cleft between the two domains of the crystal
structure of the apo form of the LBP by superimposing Cα atoms of the apo and holo
forms. In this manner the structures were aligned and the coordinates for leucine were
combined with the apo form and its crystal water molecules. Model D was built by
removing leucine coordinates from the pdb file. All crystal water molecules were kept in
the initial structures.
Table 3 The four modelling setups of the LBP.
Model Description
1. Model A apo form (1USG)
2. Model B holo form (1USK)
3. Model C apo form (1USG) with leucine bound
4. Model D holo form (1USK) without leucine bound
3.2. Molecular Dynamics Simulations
The simulations described in this report were carried out using classical molecular
dynamics technique, in which Newton’s equations of motion integrated with respect to
time {1}, are used for calculating trajectories of the particles.
{1}
The acceleration , together with the prior position and velocity of each atom i {1},
determines their new position after a small time step. Since most simulations start from
a static structure in which the velocities are not known, the velocities are assigned
randomly to the atoms from a Maxwell-Boltzmann distribution at a predetermined
temperature (29). The force , acting on each atom, is determined from the negative
gradient {2} of the potential energy surface V {3} which describes energy terms from the
bonded and non-bonded interactions between the particles.

9
{2}
{3}
The bonded interactions are described by the following set of the potential energy
functions {4-7} acting between the bonded particles i, j, k, and l with the equilibrium
distance r0, angle θ0, dihedral angle φ (Fig. 4) and improper dihedral angle ω, and where
K indicates the force constants (29).
{4}
{5}
{6}
{7}
The stretching {4} and bending {5} energy equations are based on Hooke’s law, and they
estimate the energy associated with vibrations about
the equilibrium bond length and bond angle,
respectively. The dihedral angle {6} describes bond
rotation. The phase angle of the rotation is described
by , the torsional barrier by Vn, and the periodicity,
which is the number of energy minima during a full
rotation ( ) by n. The improper dihedral
angle potential {7} is used to prevent out-of plane
distortions of planar groups.
The non-bonded interactions can be described by two terms: the Lennard-Jones (LJ)
potential representing the Van der Waals interactions and Coulomb’s potential
representing electrostatic interactions. All particle pairs i and j at the distance rij = ri − rj
interact via the LJ potential {8} (29).
{8}
The strength of the interactions between the particles i and j is determined by the
value of ij. The distance represents the effective minimum distance of an approach
between the two particles. The first term in {8} describes the repulsion between two
particles and the second term the attraction between them. In addition to the LJ term,
the electrostatic interactions between charged groups of atoms bearing a charge q are
described by a Coulombic energy function {9} with a relative dielectric constant (29).
{9}
Figure 4 Internal coordinates for
bonded interactions: r governs bond
stretching; represents the bond angle;
gives the dihedral angle (Figure created using VMD (13)).
r

10
These energy functions {4-9}, together with the set of parameters required to
describe the behaviour of different kinds of atoms and bonds, fitted to the experimental
data are known as a force field. There are several types of force fields often with specific
focus on a subgroup of the biomolecules: proteins, nucleic acids, lipids, and
carbohydrates. The MD simulations presented in this report were performed using the
AMBER03 (30) and MARTINI-2.1 CG force fields (2-4).
3.3. All-Atom MD
The AA simulations were performed using the GROMACS simulation package (28)
version 4.0.7 with the AMBER03 force field (30) for the protein and the SPC water model
for solvent (31). The protonation of the protein was handled automatically by GROMACS
pdb2gmx program, which takes the most common protonation state for an amino acid
residue in solvent at pH 7. Thus, Lys was protonated, Asp and Glu were unprotonated,
and His was kept neutral. For simulations including the ligand leucine, parameters for
zwitterionic leucine had to be defined (see Appendix).
For each setup the protein structure was solvated in a cubic box with dimensions
10x10x10 nm and counter ions were added (9 Na+). For each group in the system (ions,
water, protein) the temperature (300 K) and isotropic pressure (1 bar) were kept
constant using the Berendsen coupling algorithm (32) with time constants τt = 0.1 ps and
τp = 1 ps, respectively. A twin-range cut-off was used for the non-bonded interactions.
Interactions within the short range cut-off (1.0 nm) were evaluated every time step (2
fs), whereas interactions within the long-range cut-off (1.4 nm) were updated every 10
steps together with the pair-list. Electrostatics interactions were modelled using PME
(33). Bond lengths were constrained using the LINCS algorithm (34) for the protein. The
setups were energy-minimized followed by a relaxation of the solvent and ions, with
position restraints (1000 kJ·mol-1·nm-2) applied to all heavy atoms of the protein. The
setups were then simulated for 100 ns without any restraints.
3.4. MARTINI CG MD
MARTINI (2-4) is a CG force field which has become very popular due to its success in
parameterizing a large library of the biologically relevant building blocks. In this model
each residue is mapped to a backbone bead and zero (Ala) to four (Trp) side chain beads
(Fig. 5A). On average, one bead represents four heavy atoms. A backbone bead for each
residue is placed at the center of mass (COM) of the backbone atoms: N , Cα, C, O. There
are four main types of a particle: polar (P), nonpolar (N), apolar (C), and charged (Q), and
they can be further divided denoting the hydrogen-bonding capabilities: d – donor, a –
acceptor, da – both, 0 – none, or by a number indicating the degree of polarity (from 1 –
low to 5 – high) (4) (Fig. 5B).

11
Figure 5 A: The representation of all protein amino acids mapped into beads (4). B: The scheme shows
different bead types (Figure from http://md.chem.rug.nl/cgmartini/).
The bonded and non-bonded interactions {4-9} between the beads are described (4) in a
manner similar to an AA force field. However, the strength of an interaction in the LJ
potential {8}, determined by the well-depth ij, depends on interacting particle types and
ranges from ij = 5.6 kJ/mol for the interactions between strongly polar groups to ij = 2.0
kJ/mol for groups mimicking hydrophobic effects. The effective size of beads σ, is σ =
0.47 nm for normal types of particle and σ = 0.43 nm for model ring-like molecules (4). In
the Coulombic energy function {9}, which describes
interactions between charged (Q type) beads, a
relative dielectric constant is set to εrel = 15 for explicit
screening as CG water is a neutral bead, and
therefore does not poses any screening capabilities.
Both of these potentials are cut off, and smoothly
shifted to avoid noise in the simulations.
The CG simulations were also performed using the
GROMACS (28) software package version 4.0.7. The
protein structure, as it appeared after 100 ns of
atomistic simulation for the four setups, was used as
input to the CG simulations. All scripts used to
generate the topology files were obtained from the
MARTINI home page: http://md.chem.rug.nl/
cgmartini/. To generate the protein topology the
protein sequence from the Protein Data Bank (35)
and secondary structure found with DSSP (36) were
given as an input file to the seq2itp.pl script, which
was modified to assign the correct charges on C- and
N-termini. After mapping atoms into beads (Fig. 6) each structure was energy-minimized
in vacuum and then solvated with CG water beads (representing each four water
molecules). Next, counter ion beads were added to neutralize the system (9 Na+). The
setups were energy-minimized and the solvent and ions were relaxed with position
restraints (1000 kJ·mol-1·nm-2) applied to all beads of the protein for 1.25 ns. The
Figure 6 The CG representation of the
holo form of the LBP (1USK).
Residues in the all-atom representation
(upper snapshot) were mapped into
beads (lower snapshot), where the
backbone beads are shown in green,
and side chain beads in yellow (Figure created using VMD (13)).
A B

12
temperature and pressure settings were as in the atomistic simulations, only with time
constants τt = 1 ps and τp = 5 ps (4). Non-bonded interactions were cut off at 1.2 nm and
shifted from 0.9 nm for the LJ potential and from 0.0 nm for the electrostatic potential
(2,3). Neighbour lists were updated every 10 steps. The systems were simulated for 25
ns using a 25 fs time step. In order to have comparable time scales of the MARTINI CG
simulations and the AA simulations, a scaling factor of 4, which is the speed up factor in
the diffusional dynamics of CG water compared to real water, was proposed (2). Thus, 25
ns of CG simulation correspond to 100 ns of AA simulation.
3.5. ELNEDIN MD
In the ELNEDIN model (1) an elastic network is put on top of a modified MARTINI CG
model to maintain the tertiary structure of the protein. Firstly, the modification includes
positioning the backbone beads at the location of Cα atoms, and not in the COM.
Secondly, there is a difference in how amino acids ring structures are represented. For
both Phe and Tyr an extra bond is used to maintain the ring structure, and in the case of
His and Trp the asymmetry in their rings is considered (Fig. 7). Those differences in the
side chains of Trp and Tyr ring structures, as well as their movement upon ligand binding
(in case of Trp and Tyr residues positioned in, and near the cleft) caused the simulation
to be unstable with the 25 fs time step. Thus, the time step was decreased to 10 fs.
Figure 7 The CG representation of residues Phe, Tyr, His and Trp in the ELNEDIN model, showing structural
mapping and bond connectivity (Figure from supplementary information for (1)).
The conversion from the AA model to the ELNEDIN representation (Fig. 8A) includes
two additional parameters for setting up the structural scaffold. Those parameters are:
the cut-off distance between the backbone beads Rc [nm], which describes the range of
beads that can be connected with the additional elastic bonds (Fig. 8B), and the spring
force constant Kspring *kJ·mol-1·nm-2], which describes the stiffness of the elastic bonds.
The default parameters that seems to work the best for the cases presented so far, are
Rc = 0.9 nm and Kspring = 500 kJ·mol-1·nm-2 (1).
A

13
Figure 8 The ELNEDIN representation. A: After the conversion from AA to CG model (left, the backbone
beads are shown in green, and side chain beads in yellow) additional restraints are put on top of the CG beads (right). ELNEDIN scaffold built with Rc = 0.9 nm is shown in red lines, protein is shown as a Licorice, representation of backbone beads in green (Figure created using VMD (13)). B: Three ENM scaffolds built with different cut-off distances (Rc) (Figure from (1)).
The protein structures used as an input were the same as those used for the
MARTINI CG simulations. The parameters for the elastic network scaffold for Model A
and Model B were varied with cut off distances Rc [nm] є {0.8, 0.9, 1.0} and spring force
constants Kspring [kJ·mol-1·nm-2] є {50, 500, 5000}. For Model C and Model D, ELNEDIN
simulations were done for Rc [nm] є {0.8, 0.9} and Kspring = 500 *kJ·mol-1·nm-2] as it was
observed that those parameters provide reasonable overlap between the CG and
atomistic models for the LBP protein. To the scripts used to generate ELNEDIN topology
files, the same changes as for standard CG scripts to include charges on the C- and N-
terminus were applied. After conversion from AA to ELNEDIN representation, the
proteins were energy-minimized in vacuum, then solvated as in MARTINI CG, and
counter ions were added. The setups were energy-minimized and the solvent and ions
were relaxed while all protein beads were restrained (1000 kJ·mol-1·nm-2) for 50 ps using
1 fs time step followed by a 1 ns equilibration using 10 fs time steps with restraints put
only on the backbone beads of the protein. The temperature and pressure settings were
as in the atomistic simulations, only with constants τt = 0.5 ps and τp = 1.2 ps. The non-
bonded interactions were treated with the same shifts and cut offs as applied in the
MARTINI CG model. Model A and B were simulated for 25 ns using 10 fs time step,
whereas Model C and D were simulated for 1 μs with a 10 fs time step.
3.6. domELNEDIN MD
As domain movements in general are essential for the function of proteins, and as
this cannot be described within the ELNEDIN model, a modified version of ELNEDIN is
here proposed. In this model, named domELNEDIN, the ENM scaffold is put on each
domain separately, restraining movements inside domains, while at the same time
allowing complete freedom for inter-domain movements.
The setups for domELNEDIN simulations are the same as described for the ELNEDIN
method, with one crucial exception, that all network bonds connecting the two domains
of the LBP were left out (Fig. 9). Based on the domain predictions (described in 3.1), the
final domain definition of the LBP assigned residues 1 – 120 and 250 – 330 to domain 1,
and residues 121 -249 and 331 – 345 to domain 2. In order to generate the elastic
springs connecting only atoms from the same domain, the script generating the
B
Rc = 0.6 nm 0.9 nm 1.2 nm

14
topology file for the ELNEDIN method was modified. A section parsing an additional file
with the domain definitions obtained from domain predictions has been added to the
script, allowing setting up the elastic network exclusively inside the domains.
Additional simulations were performed for Model D where 2, 4 and 6 residues
around each of three linkers forming the hinge were unlocked. The simulations were run
for 1 μs with 10 fs time step.
Figure 9 The domELNEDIN representation of the 1USG (A) and 1USK (B) structures scaffold built with Rc = 0.9 nm is shown in red lines, protein is shown as a Licorice representation of backbone beads in green. The elastic springs that were in the ELNEDIN model and now are left out in the domELNEDIN model, are shown in blue (Figure created using VMD (13)).
A B

15
4. Results and Discussion
The work presented here is based on studying the use of the standard MARTINI CG
and the ELNEDIN model on the LBP and extending it to a “protein domain version” – the
domELNEDIN. To compare the structural and dynamical properties of the CG models
based on the MARTINI-2.1 force field, AA simulations were used as benchmarks.
Presentation and discussion of the results starts with the AA simulations, where the
ligand leucine influence on the conformational changes is investigated. Next the CG
models are presented starting from the standard MARTINI-2.1 CG, through the ELNEDIN
and ending with the domELNEDIN model. Evaluation of all four models was based on
three physical quantities: the RMSD, the RMSD per residue, RMSD_res, and the root-
mean-square fluctuation per residue, RMSF_res.
4.1. AA Simulations
All AA simulations were run for 100 ns for each of the four Models. To compute
RMSD_res and RMSF_res the last 80 ns of simulation were used. As shown in Fig. 10 all
models are stable during the AA simulation, which is important as the final structure at
100 ns, will be used as input structure to the CG models.
Figure 10 The RMSD plots of Model A in blue, Model B in red, Model C in green, and Model D in purple, for the AA simulations.
As expected Model A – the apo form of the LBP (blue) shows the highest deviation in
the structure. When the ligand leucine is bound to the apo form - Model C (green), the
RMSD plot shows smaller deviations than for the apo form without leucine bound, at the
level of around 2 Å, indicating that the creation of contacts between the protein and
ligand stabilize the structure. Also as expected Model B – the holo form with leucine
bound (red) is more stable than the apo form due to the additional connections
between the protein and ligand, and inter-domain interactions. However, at around 45
ns some deviations in the structure of Model B are observed. They are caused by a
ligand movement upward in the cleft causing small opening of the protein. At around 65
ns leucine moves back toward the bottom of the cleft and the protein closes returning to
the initial form. For the same starting structure of the closed form, without leucine,
0
1
2
3
4
5
6
0 20 40 60 80 100
RM
SD
[Å
]
Time [ns]
RMSD plots for Models A-D

16
Model D (purple), the structure remains very stable at a level of around 1.5 Å. The closed
form of the LBP, with or without leucine, seems to be very stable conformations. As LBP
is the primary receptor for the leucine transport system in E. coli, the interaction with
another protein or some other factor not included in the simulations might be necessary
to observe the closed form opening associated with ligand release.
The deviations and flexibility of each residue are plotted as the RMSD and RMSF per
residue (Fig. 11). As the AA simulations will be used as a benchmark for the CG models,
those measurements will indicate if the CG models can reproduce patterns observed in
the AA approach.
Figure 11 The plots of RMSD_res and RMSF_res for Model C in the AA simulations.
The plots above (Fig. 11) show deviations (on the left), and fluctuations (on the right) of
the residues in Model C (as an example). The distribution of the peaks and valleys across
the sequence is very similar for all the models (data not shown). The two big peaks
observed in the middle of the plot, indicates movements of the residues 160-169 and
178-181, which are loop regions. These residues are not placed in the hinge regions, but
on the surface of the protein in domain 2, and have no direct effect on the ligand
binding or hinge movement (14).
4.1.1. Leucine Interactions
The conformational changes in the LBP are associated with leucine binding and
release (14). The interactions between the ligand and LBP in the holo form (1USK),
involve both hydrogen-bonds and non-polar contributions (Fig. 12). The amino group of
the ligand forms hydrogen bonds with Gly100, Thr102, and Glu226, and the carboxylate
group of the ligand forms the hydrogen bonds with Ser79, Thr102, and Tyr202. The
hydrogen-bonding distances are ≤ 3.5 Å. Additional, the Trp18, Tyr150, and Tyr276
residues are within inter-atomic distance of ≤ 4 Å, and make the van der Waals contacts
with the hydrophobic side chain of the ligand (Fig. 12) (14).
When the interactions between leucine and the holo form of the LBP (Model B) are
investigated after 100 ns of AA simulation, it appears that the hydrogen bonds between
the amino group of the ligand and Gly100, Thr102, and Glu226, and interactions
between the carboxylate groups of leucine and Ser79, Thr102 are lost. Losing contacts
between the ligand and protein might be the result of a too simplified parameterization
0
1
2
3
4
5
6
0 50 100 150 200 250 300 350
RM
SD
[Å
]
Residue number
RMSD_res
0
1
2
3
4
0 50 100 150 200 250 300 350
RM
SF
[Å
]
Residue number
RMSF_res
Leu
Tyr202
Tyr150
Tyr276
Ser79
Gly100
Leu
Ser79
Tyr202

17
of the zwitterionic leucine for the AMBER03 force field. The partial charges were
assigned in a way decreasing the positive and negative contributions of the amino and
carboxylate groups, respectively (see Appendix). As this might very well influence ligand
binding and conformational changes of the LBP, the leucine ligand should be re-
parameterized and the simulations should be rerun.
Figure 12 Interactions between ligand leucine and apo form of LBP (1USK). Oxygen and nitrogen are shown in red and blue, respectively. The hydrogen bond between ligand and protein are shown in dashed lines. Residues that make van der Waals contacts with the hydrophobic side chain of the ligand, are shown in grey. (Figure created using VMD (13)).
4.1.2. Intra-domain Changes
The main assumption of the proposed domELNEDIN method is that the structural
changes inside the domains are relatively small compared to the inter-domain
movements (as shown in 3.1). Thus the elastic network can be put on each domain
separately retaining the intra-domain movements. To check if this assumption is still
adequate the RMSD between the same domains in different models at 100 ns of the AA
simulations was computed. Results (Tab. 4) show that the differences between domains
in different models are higher than the one obtained for the crystal structures of the LBP
(Tab. 2), but still much smaller than the differences between the two conformations of
the LBP protein (Tab. 1).
Table 4 The RMSD computed for the same domains in different Models.
Model A Model B Model C Model D
Model A 1.41 1.37 1.49 domain 1
Model B 1.47 1.49 1.52 domain 2
Model C 1.45 1.26 1.73 Model D 1.75 1.32 1.47
The average RMSD value between the domains 1, in different models is 1.55 Å, and is
slightly higher than for domains 2, which is 1.44 Å. This is expected as most of the
interactions upon ligand binding to the LBP are contributed by domain 1 (14).
Glu226
Trp18 Tyr202
Tyr276
Gly100
Thr102
Ser79
Tyr150
Leu
Leu
Tyr150
Ser79

18
4.2. CG Simulations
All CG simulations were run for 25 ns for each model, which corresponds to 100 ns of
real time. The RMSD for the protein structures show large structural deformations for all
models (Fig. 13). Moreover, for each models it has an upward trend, indicating that the
protein cannot find stable conformation. The protein structures at 25 ns have RMSDs
ranging from 5.5 – 7.5 Å. Visual inspection of those structures showed that models
involving the open form of the LBP (Models A and C), to some extent changed their
conformation to a more closed form and models of the closed form (Models B and D)
remain in a closed conformation. To check if closing of the open forms of the LBP is
related to conformational changes, the RMSD between them and the closed crystal
structure form of the LBP (1USK) was computed. The result in both cases were higher
than 7.1 Å, which suggests that observed changes are rather associated with tertiary
structure collapse than shifting from one conformation to another. Thus, with this model
in its current form, the LBP cannot be studied, as it is not able to keep the protein
structure stable.
Figure 13 The RMSD plot for 25 ns of CG simulations for four models. Model A in blue, Model B in red, Model C in green, Model D in purple.
The RMSD_res and RMSF_res were computed for the last 20 ns (last 80 ns in real time)
(Fig. 14). Also these plots show that MARTINI CG model is too flexible; residues in the CG
model (in blue) fluctuate much more than the residues represented in the AA model (in
red). However, even if the system is much less stable and more flexible than observed
from the AA approach, the same patterns, like the two biggest peaks corresponding to
the large fluctuations of residues 160-169 and 178-181, can still be observed (Fig. 14).
0
2
4
6
8
10
0 5 10 15 20 25
RM
SD
[Å
]
Time [ns]
RMSD for MARTINI CG model

19
Figure 14 The plots of RMSD_res and RMSF_res for Model C, showing that the same patterns for residues deviations (left) and fluctuations (right) as in the AA model in red, can be observed with the MARTINI CG model in blue.
4.3. ELNEDIN
The simulations presented in this section were used to get familiar with the ELNEDIN
method, as it is modified to establish the domELNEDIN model. Simulations are divided
into two groups. In the first one, simulations were carried out for Model A and Model B
which are the crystal structures of the apo and holo form of the LBP, respectively. In the
second group, simulations were carried out for the modified structures of the LBP,
where Model C is the apo form with leucine bound and Model D is the holo form
without leucine bound. For the first group various structural scaffold parameters were
tested and the optimal parameters then were used for the simulations in the second
group.
4.3.1. Model A and Model B
In order to test the ELNEDIN method, nine simulations for Model A and B were set
up with different parameters for the elastic network, ranging for the cut off distance Rc
[nm] є { 0.8, 0.9, 1.0} and spring force constant Kspring *kJ·mol-1·nm-2] є {50, 500, 5000}.
Simulations were run for 25 ns and the results are shown on the RMSD plot (Fig. 15) for
Model B (Run 11) example. The RMSD plots show that protein is very stable, and as the
ENM restrain the initial protein structure no conformational shifts are observed. In these
simulations, leucine stays in the cleft between two domains. However, as now model is
described by beads, specificity of leucine and thus, all interactions with protein,
involving hydrogen-bonding, are lost. The RMSD plots show also, that the global changes
of the protein decreases when both Rc and Kspring are increased. For both Models A (data
not shown) and B the deviations in the protein structure are highest using a combination
of different values of Rc and the smallest value of Kspring = 50 kJ·mol-1·nm-2, or the
1 For Model B (the holo form of the LBP), two AA simulations were in fact carried out. For the first one,
denoted as Run 1, some deviations were observed in the RMSD after 100 ns of simulation associated with leucine flipping in the binding pocket. Thus, for investigating the protein flexibility dependency on the structural scaffold parameters the structure at 50 ns of Run 1 was used as the protein structure was already stabilized at this point. However, to be consistent with the rest of the models, the AA simulation for Model B was rerun (denoted as Run 2). All results presented in this report for Model B are based on Run 2, unless clearly noted.
0
2
4
6
8
10
12
14
0 50 100 150 200 250 300 350
RM
SD
[Å
]
Residue number
RMSD_res
0
1
2
3
4
5
6
0 50 100 150 200 250 300 350
RM
SF
[Å
]
Residue num
RMSF_res

20
smallest value for cut off distance Rc = 0.8 nm, with different Kspring values. This
behaviour indicates that Rc and Kspring compensate each other to maintain the overall
structure of the protein, and is in agreement with the results presented in the ELNEDIN
paper (1).
Figure 15 RMSD plots showing effect of the Kspring and Rc values on the structure and dynamics of Model B (Run 1).
The influence of the Rc value on the flexibility of the protein is depicted on the figure
below (Fig. 16). Red indicates the common bonds (1602 present) for both the cut off
values Rc = 0.8 nm and Rc = 0.9 nm. The additional bonds (622) generated for Rc = 0.9 nm
are shown in blue. This illustrates the effect of increasing Rc by 0.1 nm, thus further
constraining the protein, which results in reduced protein flexibility.
Figure 16 Model A with a visualization of elastic bonds for Rc = 0.8 nm in red, and additional bonds for the Rc = 0.9 nm cut off in blue. A: side view; B: top view (Figure created using VMD (13)).
The protein deformation dependence on scaffold parameters is also observed when
inspecting RMSD_res (Fig. 17) and RMSF_res (Fig. 18). Both measurements were
computed for the last 20 ns of simulation (last 80 ns in real time). To evaluate the
0
1
2
3
4
5
0
1
2
3
4
5
0
1
2
3
4
5
0 5 10 15 20 25 0 5 10 15 20 25 0 5 10 15 20 25
A B
50
50
0
5
00
0
RM
SD
[Å
]
Time [ns]
Rc [nm]
0.8 0.9 1.0
Ksp
ring [k
J·mo
l -1·nm
-2]

21
residue fluctuations, deformations and amplitudes, the results are compared to those
obtained from the AA simulation.
Figure 17 The RMSD_res plots showing the effect of the Kspring and Rc values on the structure and dynamics of Model B, Run 1. The ELNEDIN simulations are shown in blue, AA simulations shown in red.
Figure 18 The RMSF_res plots showing the effect of the Kspring and Rc values on the structure and dynamics of Model B, Run 1. The ELNEDIN simulations are shown in blue, AA simulations shown in red.
0
2
4
6
8
0
2
4
6
8
0
2
4
6
8
0 100 200 300 0 100 200 300 0 100 200 300
0
1
2
3
4
5
0
1
2
3
4
5
0
1
2
3
4
5
0 100 200 300 0 100 200 300 0 100 200 300
RM
SD
_re
s [Å
]
Residue number
Rc [nm]
0.8 0.9 1.0
50
50
0
50
00
Ksp
ring [k
J·mo
l -1·nm
-2]
RM
SF
_re
s [Å
]
Residue number
Rc [nm]
0.8 0.9 1.0
50
50
0
50
00
Ksp
ring [k
J·mo
l -1·nm
-2]

22
Testing different combinations of the scaffold parameters, allowed to choose the set of
parameters that gave optimal agreement with the flexibility observed in the AA
simulations. As shown on the example of Model B, there are only small differences
observed for the scaffolds built with the cut off Rc = 0.8 nm and Rc = 0.9 nm, and Kspring =
500 kJ·mol-1·nm-2. The default setting for the ELNEDIN model is Rc = 0.9 nm and Kspring =
500 kJ·mol-1·nm-2, however it may vary for different proteins (1). Thus, simulations for
Model C and D were set up with both cut off Rc = 0.8 nm and Rc = 0.9 nm values, and
spring force constant Kspring = 500 kJ·mol-1·nm-2 value.
4.3.2. Model C and Model D
Simulations for Model C and D were run for 1 μs (which corresponds to 4 μs of the
real time). This time range allowed the study of long time-scale behaviour for the
Models C and D, where it could be expected to observe the closing of the open form and
opening of the closed form. The RMSD plots for Model C are shown below (Fig. 19).
Figure 19 The RMSD of the 1μs simulation of Model C. Plot on left shows ELNEDIN model with Rc = 0.8 nm and Kspring = 500 kJ·mol
-1·nm
-2, and on right with Rc = 0.9 nm and Kspring = 500 kJ·mol
-1·nm
-2. Dashed lines 1
and 2 indicate structural changes in the system.
In the RMSD (Fig. 19) plot for Model C (the open form with leucine bound) with the
parameters Rc = 0.8 nm and Kspring = 500 kJ·mol-1·nm-2 some significant changes in the
RMSD are observed. After 70 ns leucine escapes from the cleft but still oscillates on the
surface of the first domain. Around 120 ns leucine escapes out of the vicinity of the
protein (Fig. 19; line 1) and after around 380 ns the protein starts to close (Fig. 19; line
2). When the structure of Model C at 1 μs of ELNEDIN simulation is superimposed on the
crystal structure of the holo form of LBP (PDB: 1USK (14)), significant differences in the
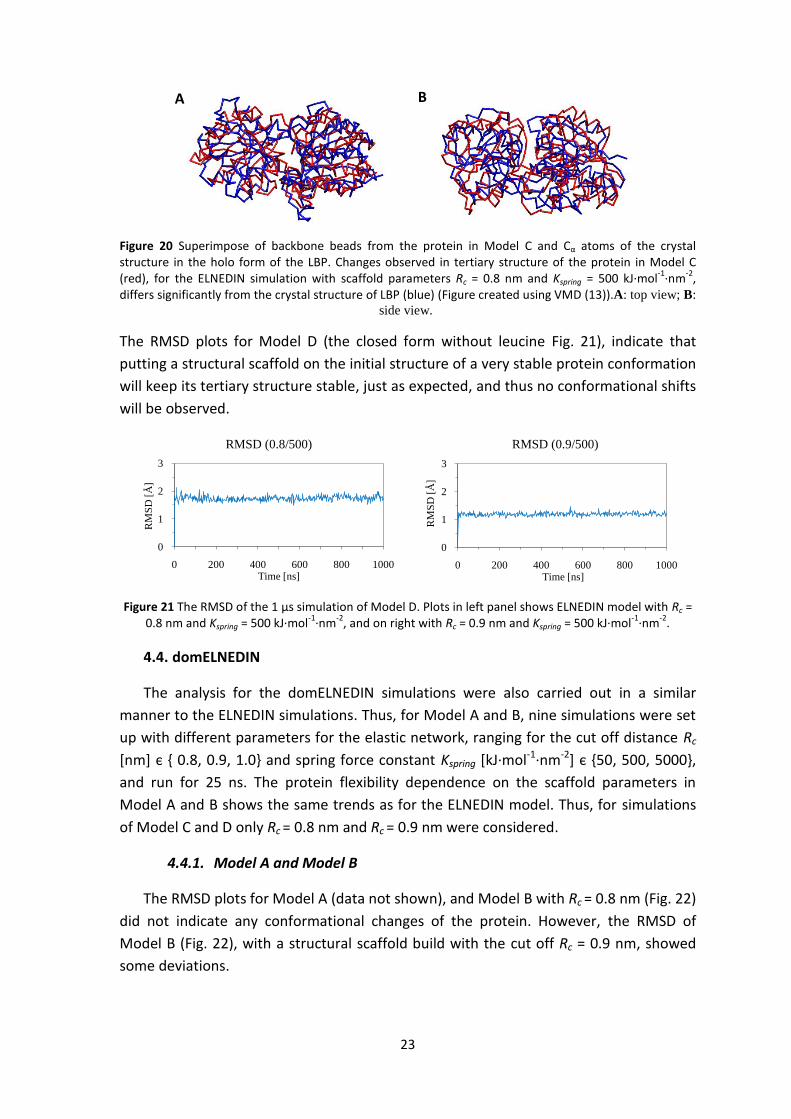
structures are observed (Fig. 20) with the RMSD between the structures equal to 7.20 Å.
In this simulation Model C folds in manner not comparable to the known closed
conformation and the changes observed during the simulation are therefore not
associated with a true conformational shift, from the open to closed form, of the
protein.
0
2
4
6
8
0 200 400 600 800 1000
RM
SD
[Å
]
Time [ns]
RMSD (0.8/500)
0
2
4
6
8
0 200 400 600 800 1000
RM
SD
[Å
]
Time [ns]
RMSD (0.9/500)
1 2
23
Figure 20 Superimpose of backbone beads from the protein in Model C and Cα atoms of the crystal structure in the holo form of the LBP. Changes observed in tertiary structure of the protein in Model C (red), for the ELNEDIN simulation with scaffold parameters Rc = 0.8 nm and Kspring = 500 kJ·mol
-1·nm
-2,
differs significantly from the crystal structure of LBP (blue) (Figure created using VMD (13)).A: top view; B:
side view.
The RMSD plots for Model D (the closed form without leucine Fig. 21), indicate that
putting a structural scaffold on the initial structure of a very stable protein conformation
will keep its tertiary structure stable, just as expected, and thus no conformational shifts
will be observed.
Figure 21 The RMSD of the 1 μs simulation of Model D. Plots in left panel shows ELNEDIN model with Rc = 0.8 nm and Kspring = 500 kJ·mol
-1·nm
-2, and on right with Rc = 0.9 nm and Kspring = 500 kJ·mol
-1·nm
-2.
4.4. domELNEDIN
The analysis for the domELNEDIN simulations were also carried out in a similar
manner to the ELNEDIN simulations. Thus, for Model A and B, nine simulations were set
up with different parameters for the elastic network, ranging for the cut off distance Rc
*nm+ є , 0.8, 0.9, 1.0- and spring force constant Kspring *kJ·mol-1·nm-2+ є ,50, 500, 5000-,
and run for 25 ns. The protein flexibility dependence on the scaffold parameters in
Model A and B shows the same trends as for the ELNEDIN model. Thus, for simulations
of Model C and D only Rc = 0.8 nm and Rc = 0.9 nm were considered.
4.4.1. Model A and Model B
The RMSD plots for Model A (data not shown), and Model B with Rc = 0.8 nm (Fig. 22)
did not indicate any conformational changes of the protein. However, the RMSD of
Model B (Fig. 22), with a structural scaffold build with the cut off Rc = 0.9 nm, showed
some deviations.
0
1
2
3
0 200 400 600 800 1000
RM
SD
[Å
]
Time [ns]
RMSD (0.8/500)
0
1
2
3
0 200 400 600 800 1000
RM
SD
[Å
]
Time [ns]
RMSD (0.9/500)
B A

24
Figure 22 The RMSD plots for Model B. Plot in left panel shows domELNEDIN model with Rc = 0.8 nm and Kspring = 500 kJ·mol
-1·nm
-2, and on right with Rc = 0.9 nm and Kspring = 500 kJ·mol
-1·nm
-2 parameters.
Further investigation, showed that after around 4 ns (Fig. 22 right) leucine moves
upward the cleft and protein slightly opens, remaining in this form until the end of the
simulation. As this might suggest opening of the closed form, the simulation was rerun
for 1 μs to check if the behaviour was reproducible. The result is shown on the RMSD
plot Fig. 23. In this simulation leucine escapes from the cleft after 38 ns and the protein
starts to close slightly, and after around 250 ns it stays in this form for the rest of the
simulation.
Figure 23 The RMSD plot for the rerun of Model B, 1 μs. The domELNEDIN model with Rc = 0.9 nm and Kspring = 500 kJ·mol
-1·nm
-2 parameters.
Again, this behaviour may suggest the opening of the closed form of the LBP, but the
release of leucine is obtained without the protein changing to an open conformation.
However, it should be noted that as the structure of the closed form without leucine
was observed to be very stable, in the AA simulation, the total opening of the closed
form of the LBP could involve the interaction with another protein or some other factor
not included in the simulations.
4.4.2. Model C and Model D
Like in the ELNEDIN simulations Model C and D were set up with a cut off distance
either of Rc = 0.8 nm or Rc = 0.9 nm and with force constant Kspring = 500 kJ·mol-1·nm-2.
Simulations were run for 1 μs in order to check if conformational changes were observed
within these models. Both the RMSD plots for Model C (Fig. 24) show a conformational
shift.
0
1
2
3
4
0 5 10 15 20 25
RM
SD
[Å
]
Time [ns]
RMSD (0.8/500)
0
1
2
3
4
0 5 10 15 20 25
RM
SD
[Å
]
Time [ns]
RMSD (0.9/500)
0 200 400 600 800 1000
0
1
2
3
4
Time [ns]
RM
SD
[Å
]
RMSD (0.9/500)

25
Figure 24 RMSD of Model C. Plot in left panel shows the domELNEDIN model with Rc = 0.8 nm and Kspring = 500 kJ·mol
-1·nm
-2, and on right with Rc = 0.9 nm and Kspring = 500 kJ·mol
-1·nm
-2.
In in both cases leucine stays in the cleft between the two domains. Moreover, the
RMSD between the structure of Model C at 1 μs of simulation, compared to the crystal
structure of the holo form of the LBP (1USK) is 5.54 Å for Rc = 0.8 nm and 3.44 Å for Rc =
0.9 nm. The RMSD values suggest that the structure in Model C changes its
conformation towards the closed form (Fig. 25) for both scaffold cut offs Rc = 0.8 nm and
Rc = 0.9 nm, and thus indicates that conformational changes can be studied with the
domELNEDIN model. The closed structure observed for the scaffold with cut off distance
Rc = 0.9 nm gives a final structure with great similarity to the known closed structure
(Fig. 25 B).
Figure 25 Superimpose of backbone beads of Model C and Cα atoms of the crystal structure of the holo form of LBP. Changes observed in tertiary structure of the protein in Model C (red), for domELNEDIN simulations with scaffold parameters A: Rc = 0.8 nm (top – on left, side – on right view) and B: Rc = 0.9 nm (top – on left, side – on right view) with Kspring = 500 kJ·mol
-1·nm
-2, compared to the holo structure (blue)
(Figure created using VMD(13)).
For Model D, both RMSD plots (Fig. 26) show some deviations, however as this structure
is the most stable of all the models and there is no leucine bound that might initiate
structure rearrangements, only small structural changes are observed.
Figure 26 RMSD of Model D. Plot in left panel shows domELNEDIN model with Rc = 0.8 nm and Kspring = 500 kJ·mol
-1·nm
-2, and on right with Rc = 0.9 nm and Kspring = 500 kJ·mol
-1·nm
-2.
0
2
4
6
8
10
0 200 400 600 800 1000
RM
SD
[Å
]
Time [ns]
RMSD (0.8/500)
0
2
4
6
8
10
0 200 400 600 800 1000
RM
SD
[Å
]
Time [ns]
RMSD (0.9/500)
0
1
2
3
4
0 200 400 600 800 1000
RM
SD
[Å
]
Time [ns]
RMSD (0.8/500)
0
1
2
3
4
0 200 400 600 800 1000
RM
SD
[Å
]
Time [ns]
RMSD (0.9/500)
A B

26
As mentioned before, Model D is a very stable form and even with a scaffold put only on
each domain separately (Fig. 27A), a switch from one conformation to another is not
observed. Thus, to test if unlocking more residues at the hinge region may lead to
protein opening, additional simulations were carried out, where elastic bonds for 2, 4,
and 6 residues at each of the hinge connections were left out (Fig. 27B). However, no
significant changes that would suggest conformational shifts were observed.
Figure 27 The domELNEDIN representation of Model D, scaffold built with Rc = 0.9 nm is shown in red lines, protein is shown as a Licorice representation of backbone beads in green. A: ENM is put on each domain separately. B: As in A, but with 4 residues unlocked at each connection of hinge region (Figure
created using VMD (13)).
A B

27
5. Conclusions and Future Perspectives
The main goal of this report was to describe and present the steps and methods
used for establishing the domELNEDIN method for modelling of protein domain
rearrangements. Thus, different CG methods were investigated. The first approach, the
MARTINI CG model, is providing a relatively detailed description of the studied structure
at the amino acid resolution, allowing at the same time to cover a time scale of several
microseconds. However, as shown with the example of the two-domain LBP, this model
is too flexible and is not capable of keeping the overall structure of the protein. This lead
to the test of another approach called ELNEDIN, where an elastic network was put on
the top of the MARTINI CG model of the LBP to keep its tertiary structure stable. Within
this model, no conformational shifts were observed. Thus, the domELNEDIN approach
was proposed, where the elastic network bonds between domains are left out. In this
manner, the tertiary structure of the protein is still kept stable, allowing at the same
time for inter-domain movements. The Model C example where the apo form of the LBP
changes its conformation to a closed form shows that conformational changes can be
studied within this model. However, for the two closed forms of the LBP with (Model B)
and without (Model D) leucine bound, conformational shifts are not observed. Thus, for
Model D, which is a very stable form, additional simulations were carried out, where the
elastic bonds for 2, 4, and 6 residues at the hinge connections were left out. However,
even in this case no opening of the closed form of LBP was observed. Thus, it might
suggest that this very stable closed form of LBP needs an additional stimulating factor –
like a transporter - to change its conformation. The combination of Rc = 0.9 nm and Kspring
= 500 kJ·mol-1·nm-2 parameters for structural scaffold, as well as this Rc = 0.9 nm and
Kspring = 500 kJ·mol-1·nm-2 combination gives the best agreement with the flexibility of the
protein presented by AA simulations. The domELNEDIN method compared to the
ELNEDIN model, seems to be a better alternative as it shows the same overall stability,
while allowing domain movement. Still, more tests should be done on proteins with
different types of domain movement.
In the further method development, the way of assigning residues to the domains
and hinges, should be reconsidered. Knowing exactly which residues are involved in
domain movements, different parts of the protein could be restrained with different
strengths of the elastic network. An applied structural scaffold would then keep the
tertiary structure of the protein stable and at the same time allow the regions crucial for
the protein conformational changes (even inside the domains), to be flexible enough to
rearrange.
The application of the domELNEDIN model should also include reverse CG
simulations (39,40), which reintroduce the atomic details from the CG description. This
would allow to test the stability of the structure at the more established AA MD level
after the conformational changes have taken place in the domELNEDIN simulation.

28
At this point of my Ph.D. the domELNEDIN model needs further investigation and
improvement. Tests should be made with more proteins, including proteins with more
than two domains. This, as well as repeating simulations, would give a better feeling for
the qualities and the problems of the domELNEDIN model and give ideas for how to
further improve the model. Membrane proteins should also be included in the testing,
approaching a state where the domELNEDIN model can be used to simulate the
dynamics and structural rearrangements associated with the conformational changes in
the catalytic cycle of P-type ATPases. I will have great opportunity to carry on with this
work during my research stay in Calgary, Canada, at Peter Tielemans group, which I will
be visiting from February to July 2011.

29
References
(1) Periole X, Cavalli M, Marrink S, Ceruso MA. Combining an Elastic Network With a Coarse-Grained
Molecular Force Field: Structure, Dynamics, and Intermolecular Recognition. Journal of Chemical Theory
and Computation 2009 SEP;5(9):2531-2543.
(2) Marrink SJ, de Vries AH, Mark AE. Coarse grained model for semiquantitative lipid simulations. J Phys
Chem B 2004 JAN 15;108(2):750-760.
(3) Marrink SJ, Risselada HJ, Yefimov S, Tieleman DP, de Vries AH. The MARTINI force field: Coarse grained
model for biomolecular simulations. J Phys Chem B 2007 JUL 12;111(27):7812-7824.
(4) Monticelli L, Kandasamy SK, Periole X, Larson RG, Tieleman DP, Marrink S. The MARTINI coarse-grained
force field: Extension to proteins. Journal of Chemical Theory and Computation 2008 MAY;4(5):819-834.
(5) Dror RO, Jensen MO, Borhani DW, Shaw DE. Exploring atomic resolution physiology on a femtosecond
to millisecond timescale using molecular dynamics simulations. J.Gen.Physiol. 2010 JUN;135(6):555-562.
(6) Olesen C, Picard M, Winther AL, Gyrup C, Morth JP, Oxvig C, et al. The structural basis of calcium
transport by the calcium pump. Nature 2007 DEC 13;450(7172):1036-U5.
(7) Tozzini V. Coarse-grained models for proteins. Curr.Opin.Struct.Biol. 2005 APR;15(2):144-150.
(8) Tozzini V. Multiscale Modeling of Proteins. Acc.Chem.Res. 2010 FEB;43(2):220-230.
(9) Sherwood P, Brooks BR, Sansom MSP. Multiscale methods for macromolecular simulations.
Curr.Opin.Struct.Biol. 2008 OCT;18(5):630-640.
(10) Gohlke H, Thorpey MF. A natural coarse graining for simulating large biomolecular motion. Biophys.J.
2006 SEP;91(6):2115-2120.
(11) Tirion MM. Large amplitude elastic motions in proteins from a single-parameter, atomic analysis.
Phys.Rev.Lett. 1996 AUG 26;77(9):1905-1908.
(12) Gerstein M, Lesk AM, Chothia C. Structural Mechanisms for Domain Movements in Proteins.
Biochemistry (N.Y.) 1994 JUN 7;33(22):6739-6749.
(13) Humphrey W, Dalke A, Schulten K. VMD: Visual molecular dynamics. J.Mol.Graph. 1996 FEB;14(1):33-
&.
(14) Magnusson U, Salopek-Sondi B, Luck LA, Mowbray SL. X-ray structures of the leucine-binding protein
illustrate conformational changes and the basis of ligand specificity. J.Biol.Chem. 2004 MAR
5;279(10):8747-8752.
(15) Mcphalen CA, Vincent MG, Picot D, Jansonius JN, Lesk AM, Chothia C. Domain Closure in
Mitochondrial Aspartate-Aminotransferase. J.Mol.Biol. 1992 SEP 5;227(1):197-213.
(16) Mcphalen CA, Vincent MG, Jansonius JN. X-Ray Structure Refinement and Comparison of 3 Forms of
Mitochondrial Aspartate-Aminotransferase. J.Mol.Biol. 1992 MAY 20;225(2):495-517.
(17) Wiegand G, Remington S, Deisenhofer J, Huber R. Crystal-Structure Analysis and Molecular-Model of a
Complex of Citrate Synthase with Oxaloacetate and S-Acetonyl-Coenzyme-a. J.Mol.Biol. 1984;174(1):205-
219.
(18) Remington S, Wiegand G, Huber R. Crystallographic Refinement and Atomic Models of 2 Different
Forms of Citrate Synthase at 2.7-a and 1.7-a Resolution. J.Mol.Biol. 1982;158(1):111-152.
(19) Pickford AR, Smith SP, Staunton D, Boyd J, Campbell ID. The hairpin structure of the (6)F1(1)F2(2)F2
fragment from human fibronectin enhances gelatin binding. EMBO J. 2001 APR 2;20(7):1519-1529.
(20) Tjandra N, Garrett DS, Gronenborn AM, Bax A, Clore GM. Defining long range order in NMR structure
determination from the dependence of heteronuclear relaxation times on rotational diffusion anisotropy.
Nat.Struct.Biol. 1997 JUN;4(6):443-449.
(21) Garrett DS, Seok YJ, Peterkofsky A, Gronenborn AM, Clore GM. Solution structure of the 40,000 M-r
phosphoryl transfer complex between the N-terminal domain of enzyme I and HPr. Nat.Struct.Biol. 1999
FEB;6(2):166-173.
(22) Barrientos LG, Gronenborn AM. The domain-swapped dimer of cyanovirin-N contains two sets of
oligosaccharide binding sites in solution. Biochem.Biophys.Res.Commun. 2002 NOV 8;298(4):598-602.

30
(23) Meng WY, Sawasdikosol S, Burakoff SJ, Eck MJ. Structure of the amino-terminal domain of Cbl
complexed to its binding site on ZAP-70 kinase. Nature 1999 MAR 4;398(6722):84-90.
(24) Ding J, Das K, Tantillo C, Zhang W, Clark AD, Jessen S, et al. Structure of Hiv-1 Reverse-Transcriptase in
a Complex with the Nonnucleoside Inhibitor Alpha-Apa-R-95845 at 2.8-Angstrom Resolution. Structure
1995 APR 15;3(4):365-379.
(25) Jaeger J, Restle T, Steitz TA. The structure of HIV-1 reverse transcriptase complexed with an RNA
pseudoknot inhibitor. EMBO J. 1998 AUG 3;17(15):4535-4542.
(26) Zhou H, Xue B, Zhou Y. DDOMAIN: Dividing structures into domains using a normalized domain-
domain interaction profile. Protein Sci. 2007 MAY;16(5):947-955.
(27) Toyoshima C, Nakasako M, Nomura H, Ogawa H. Crystal structure of the calcium pump of
sarcoplasmic reticulum at 2.6 angstrom resolution. Nature 2000 JUN 8;405(6787):647-655.
(28) Van der Spoel D, Lindahl E, Hess B, Groenhof G, Mark AE, Berendsen HJC. GROMACS: Fast, flexible,
and free. Journal of Computational Chemistry 2005 DEC;26(16):1701-1718.
(29) Leach AR. Molecular modelling : principles and applications. 2. ed ed. Essex: Pearson; 2001.
(30) Duan Y, Wu C, Chowdhury S, Lee MC, Xiong GM, Zhang W, et al. A point-charge force field for
molecular mechanics simulations of proteins based on condensed-phase quantum mechanical
calculations. J.Comput.Chem. 2003 DEC;24(16):1999-2012.
(31) Berendsen HJC, Postma JPM, Vangunsteren WF, Hermans J. Interaction Models for Water in Relation
To Protein Hydration. . B. Pullman ed.: D. Reidel Publishing Company; 1981. p. 331-338.
(32) Berendsen HJC, Postma JPM, Vangunsteren WF, Dinola A, Haak JR. Molecular-Dynamics with Coupling
to an External Bath. J.Chem.Phys. 1984;81(8):3684-3690.
(33) Essmann U, Perera L, Berkowitz ML, Darden T, Lee H, Pedersen LG. A Smooth Particle Mesh Ewald
Method. J.Chem.Phys. 1995 NOV 15;103(19):8577-8593.
(34) Hinsen K. Analysis of domain motions by approximate normal mode calculations. Proteins 1998 NOV
15;33(3):417-429.
(35) Berman HM, Westbrook J, Feng Z, Gilliland G, Bhat TN, Weissig H, et al. The Protein Data Bank.
Nucleic Acids Res. 2000 JAN 1;28(1):235-242.
(36) Kabsch W, Sander C. Dictionary of Protein Secondary Structure - Pattern-Recognition of Hydrogen-
Bonded and Geometrical Features. Biopolymers 1983;22(12):2577-2637.
(37) Murzin AG, Brenner SE, Hubbard T, Chothia C. Scop - a Structural Classification of Proteins Database
for the Investigation of Sequences and Structures. J.Mol.Biol. 1995 APR 7;247(4):536-540.
(38) Orengo CA, Michie AD, Jones S, Jones DT, Swindells MB, Thornton JM. CATH - a hierarchic
classification of protein domain structures. Structure 1997 AUG 15;5(8):1093-1108.
(39) Thogersen L, Schiott B, Vosegaard T, Nielsen NC, Tajkhorshid E. Peptide Aggregation and Pore
Formation in a Lipid Bilayer: A Combined Coarse-Grained and All Atom Molecular Dynamics Study.
Biophys.J. 2008 NOV 1;95(9):4337-4347.
(40) Rzepiela AJ, Schafer LV, Goga N, Risselada HJ, De Vries AH, Marrink SJ. Software News and Update
Reconstruction of Atomistic Details from Coarse-Grained Structures. J.Comput.Chem. 2010 APR
30;31(6):1333-1343.

31
Appendix: SLEU Parameterization
In the AMBER03 force field residues are named according to their position in the
sequence. For C- and N-terminal amino acids a C or N prefix, respectively, has to be
included, so the C-terminal leucine is CLEU and N-terminal leucine is NLEU. Based on the
definitions of C-terminus and N-terminus leucine (shown below) the single zwitterion
leucine SLEU residue was defined.
CLEU
N amber99_34 -0,3821 H amber99_17 0,2681
CA amber99_11 -0,2847
HA amber99_19 0,1346
CB amber99_11 -0,2469
HB1 amber99_18 0,0974
HB2 amber99_18 0,0974
CG amber99_11 0,3706
HG amber99_18 -0,0374
CD1 amber99_11 -0,4163
HD11 amber99_18 0,1038
HD12 amber99_18 0,1038
HD13 amber99_18 0,1038
CD2 amber99_11 -0,4163
HD21 amber99_18 0,1038
HD22 amber99_18 0,1038
HD23 amber99_18 0,1038
C amber99_2 0,8326
OC1 amber99_45 -0,8199
OC2 amber99_45 -0,8199
NLEU
N amber99_39 0,101
H1 amber99_17 0,2148
H2 amber99_17 0,2148
H3 amber99_17 0,2148
CA amber99_11 0,0104
HA amber99_28 0,1053
CB amber99_11 -0,0244
HB1 amber99_18 0,0256
HB2 amber99_18 0,0256
CG amber99_11 0,3421
HG amber99_18 -0,038
CD1 amber99_11 -0,4106
HD11 amber99_18 0,098
HD12 amber99_18 0,098
HD13 amber99_18 0,098
CD2 amber99_11 -0,4104
HD21 amber99_18 0,098
HD22 amber99_18 0,098
HD23 amber99_18 0,098
C amber99_2 0,6123
O amber99_41 -0,5713
In the representation of NLEU and CLEU the first column indicates atom name, the
second describes atom type, and the last one the atomic partial charge δ. In simple case
the δ for SLEU was calculated as an average value of δ for the same atom in both
definitions: NLEU and CLEU. However, when one atom, i.e. H in CLEU corresponds to
three H1, H2 and H3 atoms from NLEU, δ of H from CLEU was divided by a number of
atoms from corresponding definition of NLEU, and then this value was taken to calculate
an average δ value for SLEU representation. The idea of computing δ for SLEU is shown
below.
NLEU CLEU SLEU
δ of N + δ of N /2 = δ of N
δ of H1 + (δ of H)/3 /2 = δ of H1
(δ of O)/2 + δ of OC1 /2 = δ of OC1
Calculated partial charges with atom types were assigned to each numbered atom of
SLEU. In addition bonds, dihedrals and impropers were defined accordingly with the
AMBER03 nomenclature. Below definition of SLEU (Fig. 27) is shown.
[ SLEU ]
[ atoms ]
N amber99_39 -0.14054 1

32
H1 amber99_17 0.15208 2
H2 amber99_17 0.15208 3
H3 amber99_17 0.15208 4
CA amber99_11 -0.13715 5
HA amber99_28 0.11995 6
CB amber99_11 -0.13565 7
HB1 amber99_18 0.0615 8
HB2 amber99_18 0.0615 9
CG amber99_11 0.35635 10
HG amber99_18 -0.0377 11
CD1 amber99_11 -0.41345 12
HD11 amber99_18 0.1009 13
HD12 amber99_18 0.1009 14
HD13 amber99_18 0.1009 15
CD2 amber99_11 -0.41335 16
HD21 amber99_18 0.1009 17
HD22 amber99_18 0.1009 18
HD23 amber99_18 0.1009 19
C amber99_2 0.72245 20
OC1 amber99_45 -0.552775 21
OC2 amber99_45 -0.552775 22
[ bonds ]
N H1
N H2
N H3
N CA
CA HA
CA CB
CA C
CB HB1
CB HB2
CB CG
CG HG
CG CD1
CG CD2
CD1 HD11
CD1 HD12
CD1 HD13
CD2 HD21
CD2 HD22
CD2 HD23
C OC1
C OC2
[ dihedrals ]
H1 N CA CB backbone_prop_3
H1 N CA C backbone_prop_4
[ impropers ]
CA OC1 C OC2
Figure 28 L-Leucine in zwitterionic form.