confidence-weighted linear classification mark dredze, koby crammer university of pennsylvania...
TRANSCRIPT

Confidence-WeightedLinear Classification
Mark Dredze, Koby CrammerUniversity of Pennsylvania
Fernando PereiraPenn Google

2
Natural Language Processing
• Big datasets, large number of features
• Many features are only weakly correlated with target label
• Heavy-tailed feature distribution
• Linear classifiers: features are associated with word counts Feature Rank
Cou
nt

3
• Who needs this Simpsons book? You DOOOOOOOOThis is one of the most extraordinary volumes I've ever encountered encapsulating a television series … . Exhaustive, informative, and ridiculously entertaining, it is the best accompaniment to the best television show … . Even if you only "enjoy" the Simpsons (as opposed to being a raving fanatic, which most people who watch the show are, after all … Very highly recommended!
Sentiment Classification
• Who needs this Simpsons book? You DOOOOOOOOThis is one of the most extraordinary volumes I've ever encountered encapsulating a television series … . Exhaustive, informative, and ridiculously entertaining, it is the best accompaniment to the best television show … . Even if you only "enjoy" the Simpsons (as opposed to being a raving fanatic, which most people who watch the show are, after all … Very highly recommended!

4
Sentiment Classification
• Many positive reviews with the word best
Wbest
• Later negative review – “boring book – best if you want to sleep in seconds”
• Linear update will reduce both
Wbest
Wboring
• But best appeared more than boring• How to adjust weights at different rates?Wboring Wbest
5
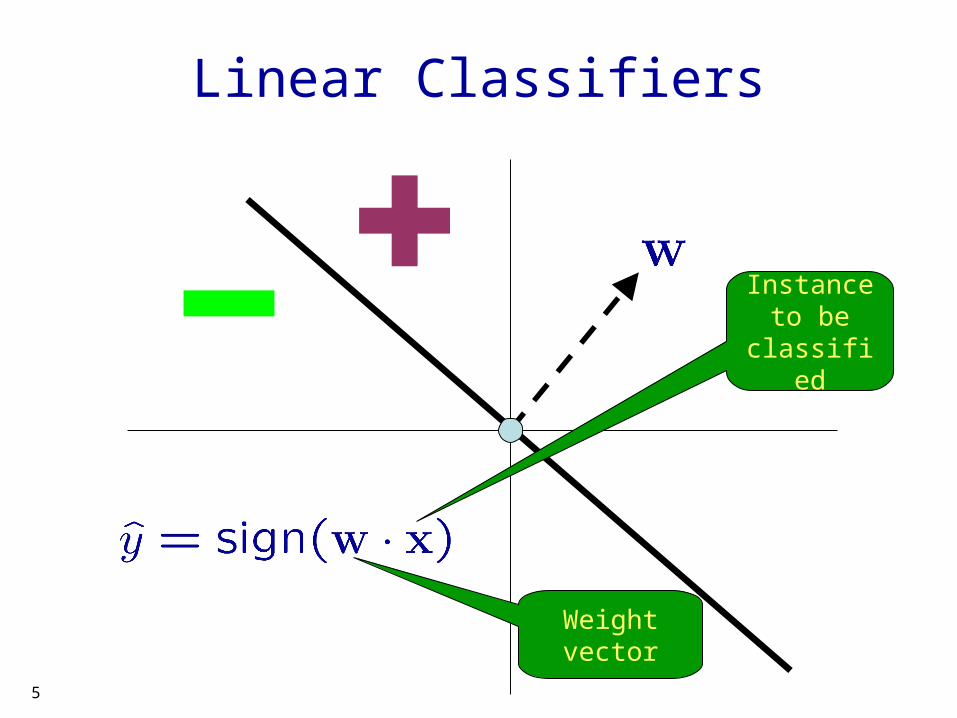
Linear Classifiers
Instance to be
classified
Weight vector

6
Online Learning
• Memory-efficient, simple to implement, often competitive
• Successive rounds– Get an input instance – Output a prediction– Receive a feedback label– Compute loss– Update the prediction rule

7
• The weight vector is a linear combination of examples
• Two rate schedules (among others):– Perceptron algorithm, conservative:
– Passive-aggressive
Span-based Update Rules
Value of feature f of instance
Target label, -1 or 1
Learning rateLearning rateWeight of feature f

8
Distributions in Version Space
Example
Mean weight-vector
QuickTime™ and a decompressor
are needed to see this picture.
QuickTime™ and a decompressorare needed to see this picture.

9
Margin as a Random Variable
• Signed margin
is a Gaussian-distributed variable
• Thus:

10
Place most of the probability mass in this region
Weight Vector (Version) Space
11
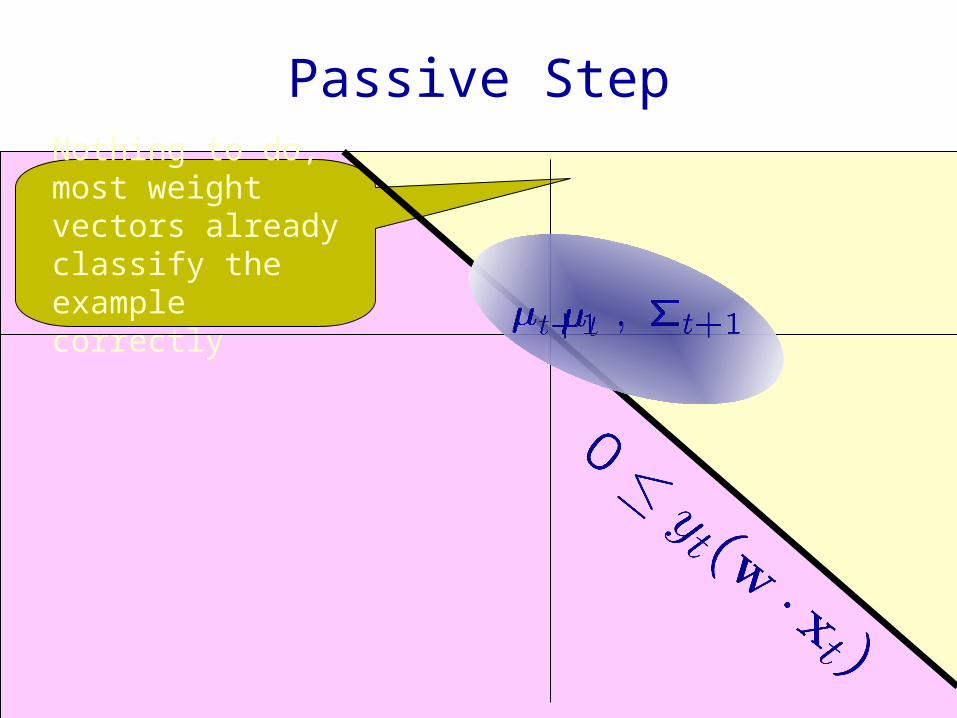
Nothing to do, most weight vectors already classify the example correctly
Passive Step

12
Project the current Gaussian distribution onto the half-space
Aggressive Step
The covariance is shirked in the direction of the new example
Mean moved past the mistake line(large margin)

13
PA-like Update
• PA:
• New Update :
Confidence Parameter
14
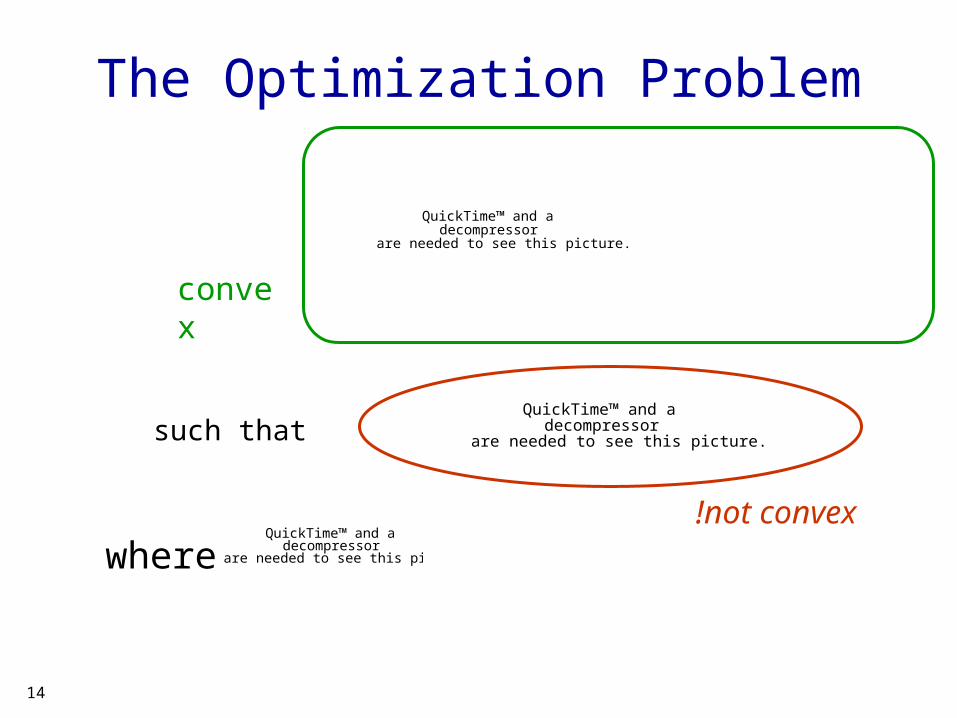
The Optimization Problem
QuickTime™ and a decompressor
are needed to see this picture.
convex
such thatQuickTime™ and a
decompressorare needed to see this picture.
QuickTime™ and a decompressor
are needed to see this picture.
QuickTime™ and a decompressor
are needed to see this picture.
not convex!QuickTime™ and a
decompressorare needed to see this picture.where

15
Simplified Optimization Problem
QuickTime™ and a decompressor
are needed to see this picture.
convex!
• Exact variance method• High dimension restrict to diagonal

16
Approximate Diagonal Algorithm
• Approximate by projecting onto the diagonal• Closed form solution
QuickTime™ and a decompressor
are needed to see this picture.
variable learning rate
scaled counts (binary features)

17
Visualizing Learning Rates
• 20 features, only two informative• Covariance ellipses (20 x cov)
– Black: the two informative features
– Blue: several pairs of noise features
– Green: target weight vector
Full Diagonal
30 rounds

18
Visualizing Learning Rates
Full (2 x) Diagonal (20 x)
90 rounds

19
Experiments
• Online to batch :– Multiple passes over the training data– Evaluate on a different test set after each
pass– Compute error/accuracy
• Binary problems from– Newsgroups– Reuters
• Sentiment classification

20
Data
• Sentiment– Sentiment reviews from 6 Amazon domains (Blitzer et al)– Classify a product review as either positive or negative
• Reuters, pairs of labels– Three divisions:
• Insurance: Life vs. Non-Life, Business Services: Banking vs. Financial, Retail Distribution: Specialist Stores vs. Mixed Retail.
– Bag of words representation with binary features.
• 20 newsgroups, pairs of labels– Three divisions:
• comp.sys.ibm.pc.hardware vs. comp.sys.mac.hardware.instances, sci.electronics vs. sci.med.instances, and talk.politics.guns vs. talk.politics.mideast.instances.
– Bag of words representation with binary features.
21
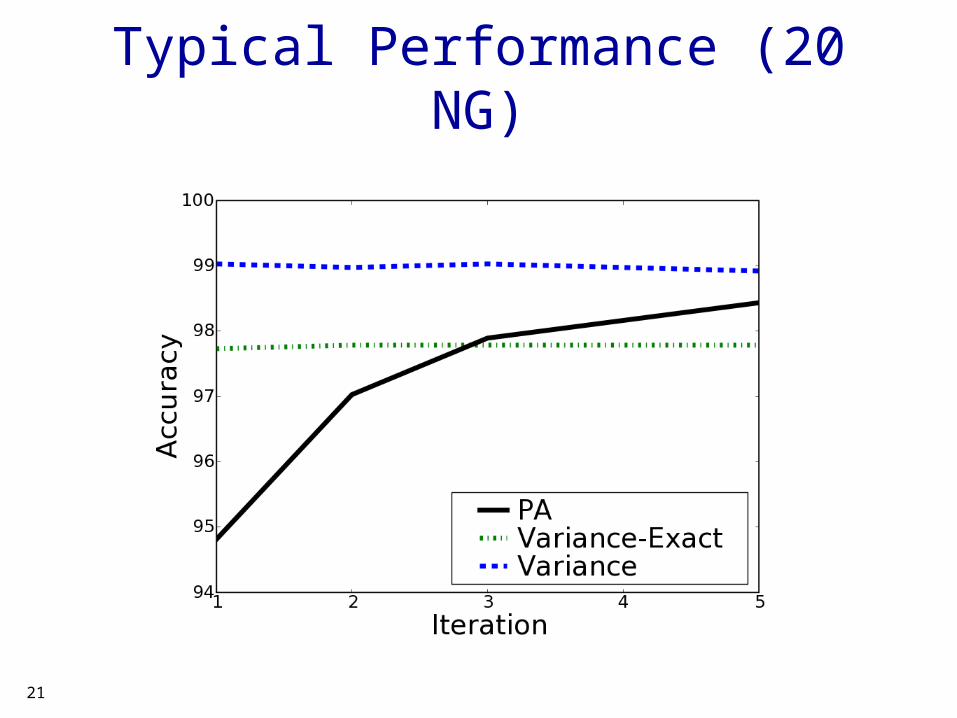
Typical Performance (20 NG)

22
Summary Statistics

23
Parallel Training
• Split large data into disjoint sets• Train using each set independently• Combine resulting classifiers
– Average Average performance of individual classifiers– Uniform mean of weight vectors
– Weighted mean of weight vectors using confidence information

24
Parallel Training
• Sentiment ~1M ; Reuters ~0.8M• #Features/#Docs: Sentiment ~13 ; Reuters ~0.35• Performance degrades with number of splits• Weighting improves performance

25
Summary
• Online learning is fast and effective …… but NLP data has skewed feature distributions
• Confidence-weighted linear prediction represents explicitly how much to trust feature weights– Higher accuracy than previous methods– Faster convergence– Effective model combination
• Current work:– Direct convex version of original optimization– Batch algorithm– Explore full covatiance versions