cpe232 memory hierarchy1 cpe 232 computer organization spring 2006 memory hierarchy dr. gheith...
TRANSCRIPT

CPE232 Memory Hierarchy 1
CPE 232 Computer Organization
Spring 2006
Memory Hierarchy
Dr. Gheith Abandah
[Adapted from the slides of Professor Mary Irwin (www.cse.psu.edu/~mji) which in turn Adapted from Computer Organization and Design,
Patterson & Hennessy, © 2005, UCB]

CPE232 Memory Hierarchy 2
Review: Major Components of a Computer
Processor
Control
Datapath
Memory
Devices
Input
Output

CPE232 Memory Hierarchy 3
Processor-Memory Performance Gap
1
10
100
1000
10000
1980 1984 1988 1992 1996 2000 2004
Year
Per
form
ance
“Moore’s Law”
µProc55%/year(2X/1.5yr)
DRAM7%/year(2X/10yrs)
Processor-MemoryPerformance Gap(grows 50%/year)

CPE232 Memory Hierarchy 4
The “Memory Wall”
Logic vs DRAM speed gap continues to grow
0.01
0.1
1
10
100
1000
VAX/1980 PPro/1996 2010+
Core
Memory
Clo
cks
per
inst
ruct
ion
Clo
cks
per
DR
AM
acc
ess

CPE232 Memory Hierarchy 5
Memory Performance Impact on Performance
Suppose a processor executes at ideal CPI = 1.1 50% arith/logic, 30% ld/st, 20% control
and that 10% of data memory operations miss with a 50 cycle miss penalty
CPI = ideal CPI + average stalls per instruction= 1.1(cycle) + ( 0.30 (datamemops/instr)
x 0.10 (miss/datamemop) x 50 (cycle/miss) )= 1.1 cycle + 1.5 cycle = 2.6
so 58% of the time the processor is stalled waiting for memory!
A 1% instruction miss rate would add an additional 0.5 to the CPI!
Ideal CPI, 1.1
DataMiss, 1.5
InstrMiss, 0.5

CPE232 Memory Hierarchy 6
The Memory Hierarchy Goal
Fact: Large memories are slow and fast memories are small
How do we create a memory that gives the illusion of being large, cheap and fast (most of the time)?
With hierarchy With parallelism

CPE232 Memory Hierarchy 7
SecondLevelCache
(SRAM)
A Typical Memory Hierarchy
Control
Datapath
SecondaryMemory(Disk)
On-Chip Components
RegF
ile
MainMemory(DRAM)
Data
Cache
InstrC
ache
ITLB
DT
LB
eDRAM
Speed (%cycles): ½’s 1’s 10’s 100’s 1,000’s
Size (bytes): 100’s K’s 10K’s M’s G’s to T’s
Cost: highest lowest
By taking advantage of the principle of locality Can present the user with as much memory as is available in the
cheapest technology at the speed offered by the fastest technology

CPE232 Memory Hierarchy 8
Characteristics of the Memory Hierarchy
Increasing distance from the processor in access time
L1$
L2$
Main Memory
Secondary Memory
Processor
(Relative) size of the memory at each level
Inclusive– what is in L1$ is a subset of what is in L2$ is a subset of what is in MM that is a subset of is in SM
4-8 bytes (word)
1 to 4 blocks
1,024+ bytes (disk sector = page)
8-32 bytes (block)

CPE232 Memory Hierarchy 9
Memory Hierarchy Technologies Caches use SRAM for speed
and technology compatibility Low density (6 transistor cells),
high power, expensive, fast Static: content will last
“forever” (until power turned off)
Main Memory uses DRAM for size (density) High density (1 transistor cells), low power, cheap, slow Dynamic: needs to be “refreshed” regularly (~ every 8 ms)
- 1% to 2% of the active cycles of the DRAM
Addresses divided into 2 halves (row and column)- RAS or Row Access Strobe triggering row decoder
- CAS or Column Access Strobe triggering column selector
Dout[15-0]SRAM
2M x 16
Din[15-0]
Address
Chip select
Output enable
Write enable
16
16
21

CPE232 Memory Hierarchy 10
Memory Performance Metrics
Latency: Time to access one word Access time: time between the request and when the data is
available (or written) Cycle time: time between requests Usually cycle time > access time Typical read access times for SRAMs in 2004 are 2 to 4 ns for
the fastest parts to 8 to 20ns for the typical largest parts
Bandwidth: How much data from the memory can be supplied to the processor per unit time
width of the data channel * the rate at which it can be used
Size: DRAM to SRAM 4 to 8 Cost/Cycle time: SRAM to DRAM 8 to 16
CPE232 Memory Hierarchy 11
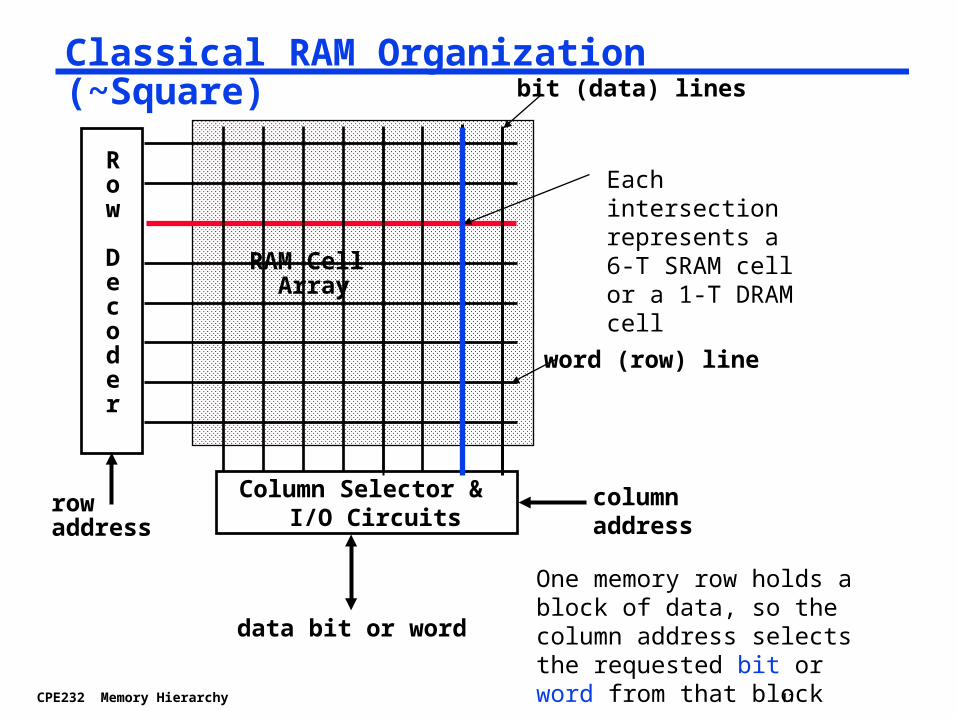
Classical RAM Organization (~Square)
Row
Decoder
rowaddress
data bit or word
RAM Cell Array
word (row) line
bit (data) lines
Each intersection represents a 6-T SRAM cell or a 1-T DRAM cell
Column Selector & I/O Circuits
columnaddress
One memory row holds a block of data, so the column address selects the requested bit or word from that block

CPE232 Memory Hierarchy 12
data bitdata bit
Classical DRAM Organization (~Square Planes)
Row
Decoder
rowaddress
Column Selector & I/O Circuits
columnaddress
data bit
word (row) line
bit (data) lines
Each intersection represents a 1-T DRAM cell
The column addressselects the requested bit from the row in eachplane
data word
. . .
. . .
RAM Cell Array

CPE232 Memory Hierarchy 13
Classical DRAM Operation
DRAM Organization: N rows x N column x M-bit Read or Write M-bit at a time Each M-bit access requires
a RAS / CAS cycle
Row Address
CAS
RAS
Col Address Row Address Col Address
N r
ows
N cols
DRAM
M bit planes
RowAddress
ColumnAddress
M-bit Output
1st M-bit Access 2nd M-bit Access
Cycle Time

CPE232 Memory Hierarchy 14
N r
ows
N cols
DRAM
ColumnAddress
M-bit Output
M bit planes N x M SRAM
RowAddress
Page Mode DRAM Operation Page Mode DRAM
N x M SRAM to save a row
After a row is read into the DRAM “register”
Only CAS is needed to access other M-bit words on that row
RAS remains asserted while CAS is toggled
Row Address
CAS
RAS
Col Address Col Address Col Address Col Address
1st M-bit Access 2nd M-bit 3rd M-bit 4th M-bit
Cycle Time
CPE232 Memory Hierarchy 15
N r
ows
N cols
DRAM
ColumnAddress
M-bit Output
M bit planes N x M SRAM
RowAddress
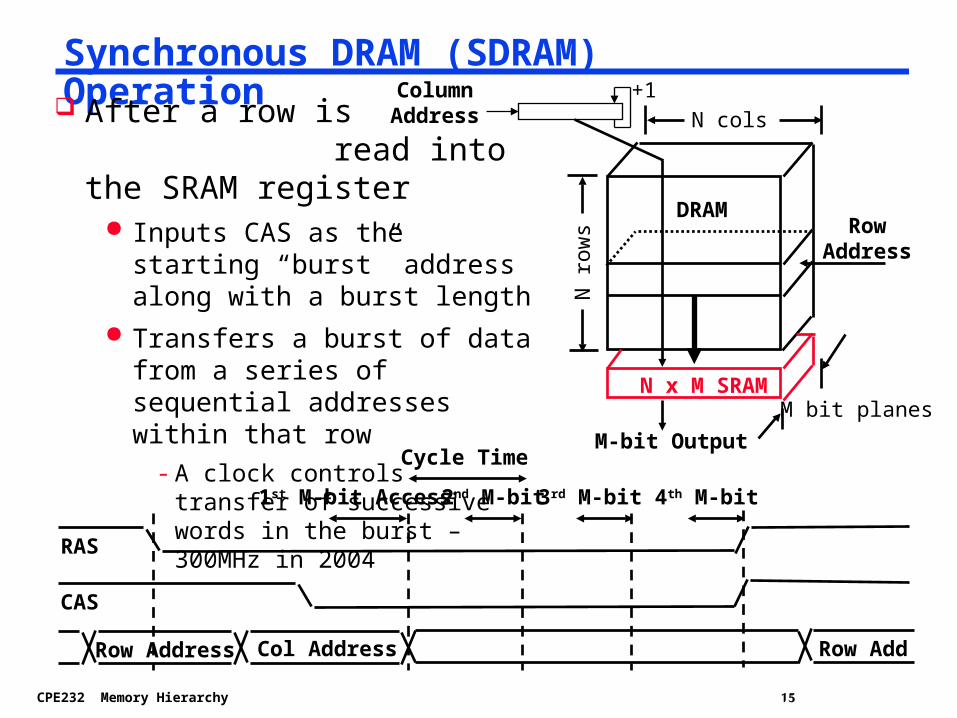
Synchronous DRAM (SDRAM) Operation After a row is
read into the SRAM register Inputs CAS as the starting “burst”
address along with a burst length Transfers a burst of data from a
series of sequential addresses within that row- A clock controls transfer of
successive words in the burst – 300MHz in 2004
+1
Row Address
CAS
RAS
Col Address
1st M-bit Access 2nd M-bit 3rd M-bit 4th M-bit
Cycle Time
Row Add

CPE232 Memory Hierarchy 16
Other DRAM Architectures
Double Data Rate SDRAMs – DDR-SDRAMs (and DDR-SRAMs)
Double data rate because they transfer data on both the rising and falling edge of the clock
Are the most widely used form of SDRAMs
DDR2-SDRAMs
http://www.corsairmemory.com/corsair/products/tech/memory_basics/153707/main.swf

CPE232 Memory Hierarchy 17
DRAM Memory Latency & Bandwidth Milestones
In the time that the memory to processor bandwidth doubles the memory latency improves by a factor of only 1.2 to 1.4 every year.
To deliver such high bandwidth, the internal DRAM has to be organized as interleaved memory banks
DRAM Page DRAM
FastPage DRAM
FastPage DRAM
Synch DRAM
DDR SDRAM
Module Width 16b 16b 32b 64b 64b 64b
Year 1980 1983 1986 1993 1997 2000
Mb/chip 0.06 0.25 1 16 64 256
Die size (mm2) 35 45 70 130 170 204
Pins/chip 16 16 18 20 54 66
BWidth (MB/s) 13 40 160 267 640 1600
Latency (nsec) 225 170 125 75 62 52
Patterson, CACM Vol 47, #10, 2004

CPE232 Memory Hierarchy 18
The off-chip interconnect and memory architecture can affect overall system performance in dramatic ways
Memory Systems that Support Caches
CPU
Cache
Memory
bus
One word wide organization (one word wide bus and one word wide memory) Assume
1. 1 clock cycle to send the address
2. 25 clock cycles for DRAM cycle time, 8 clock cycles access time
3. 1 clock cycle to return a word of data
Memory-Bus to Cache bandwidth
number of bytes accessed from memory and transferred to cache/CPU per clock cycle
32-bit data&
32-bit addrper cycle
on-chip

CPE232 Memory Hierarchy 19
One Word Wide Memory Organization
CPU
Cache
Memory
bus
on-chip
If the block size is one word, then for a memory access due to a cache miss, the pipeline will have to stall the number of cycles required to return one data word from memory
cycle to send address
cycles to read DRAM
cycle to return data
total clock cycles miss penalty
Number of bytes transferred per clock cycle (bandwidth) for a single miss is
bytes per clock
1
25
1
27
4/27 = 0.148

CPE232 Memory Hierarchy 20
One Word Wide Memory Organization, con’t
CPU
Cache
Memory
bus
on-chip
What if the block size is four words? cycle to send 1st address
cycles to read DRAM
cycles to return last data word
total clock cycles miss penalty
Number of bytes transferred per clock cycle (bandwidth) for a single miss is
bytes per clock
25 cycles
25 cycles
25 cycles
25 cycles
1
4 x 25 = 100
1
102
(4 x 4)/102 = 0.157

CPE232 Memory Hierarchy 21
One Word Wide Memory Organization, con’t
CPU
Cache
Memory
bus
on-chip
What if the block size is four words and if a fast page mode DRAM is used?
cycle to send 1st address
cycles to read DRAM
cycles to return last data word
total clock cycles miss penalty
Number of bytes transferred per clock cycle (bandwidth) for a single miss is
bytes per clock
25 cycles
8 cycles
8 cycles
8 cycles
1
25 + 3*8 = 49
1
51
(4 x 4)/51 = 0.314

CPE232 Memory Hierarchy 22
What if the memory is two words wide?
cycle to send 1st address
cycles to read DRAM
cycles to return last data word
total clock cycles miss penalty
Number of bytes transferred per clock cycle (bandwidth) for a single miss is
bytes per clock
Wide Memory Organization
CPU
Cache
Memory
bus
on-chip
1
25 + 25 = 50
1
52
(4 x 4)/52 = 0.308

CPE232 Memory Hierarchy 23
Interleaved Memory Organization
For a block size of four words cycle to send 1st address
cycles to read DRAM
cycles to return last data word
total clock cycles miss penalty
CPU
Cache
Memorybank 1
bus
on-chip
Memorybank 0
Memorybank 2
Memorybank 3
Number of bytes transferred per clock cycle (bandwidth) for a single miss is
bytes per clock
25 cycles
25 cycles
25 cycles
25 cycles
(4 x 4)/30 = 0.533
1
25 + 3 = 28
1
30

CPE232 Memory Hierarchy 24
DRAM Memory System Summary
Its important to match the cache characteristics caches access one block at a time (usually more than one
word)
with the DRAM characteristics use DRAMs that support fast multiple word accesses,
preferably ones that match the block size of the cache
with the memory-bus characteristics make sure the memory-bus can support the DRAM access
rates and patterns with the goal of increasing the Memory-Bus to Cache
bandwidth