creando su primera aplicación de big data en aws
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Creando su primera aplicación de
Big Data en AWS
Damián Traverso, AWS Solutions Architect
Mayo 2016 | Santiago de Chile
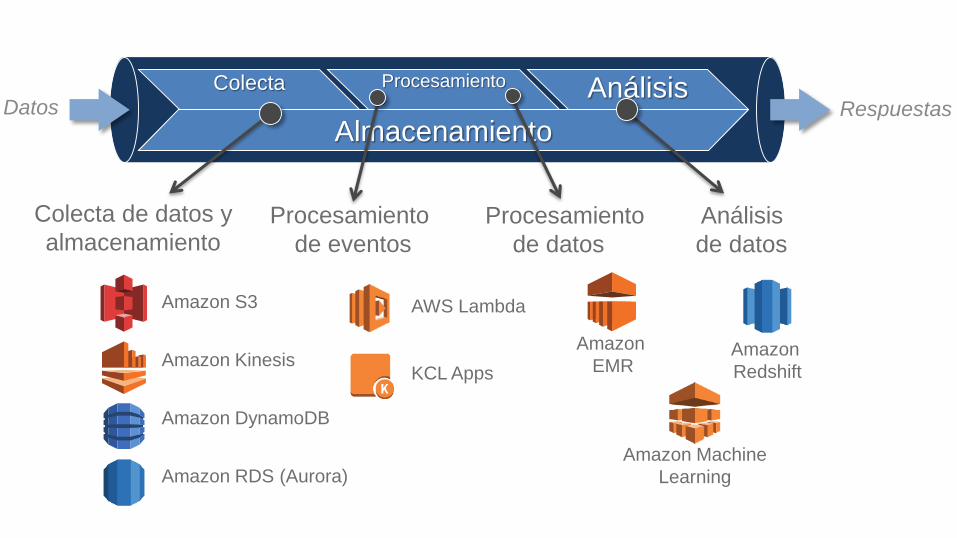
Amazon S3
Amazon Kinesis
Amazon DynamoDB
Amazon RDS (Aurora)
AWS Lambda
KCL Apps
Amazon
EMRAmazon
Redshift
Amazon Machine
Learning
Colecta Procesamiento Análisis
Almacenamiento
Colecta de datos y
almacenamientoProcesamiento
de datos
Procesamiento
de eventos
Análisis
de datos
Datos Respuestas

Su primera aplicación de Big Data en AWS
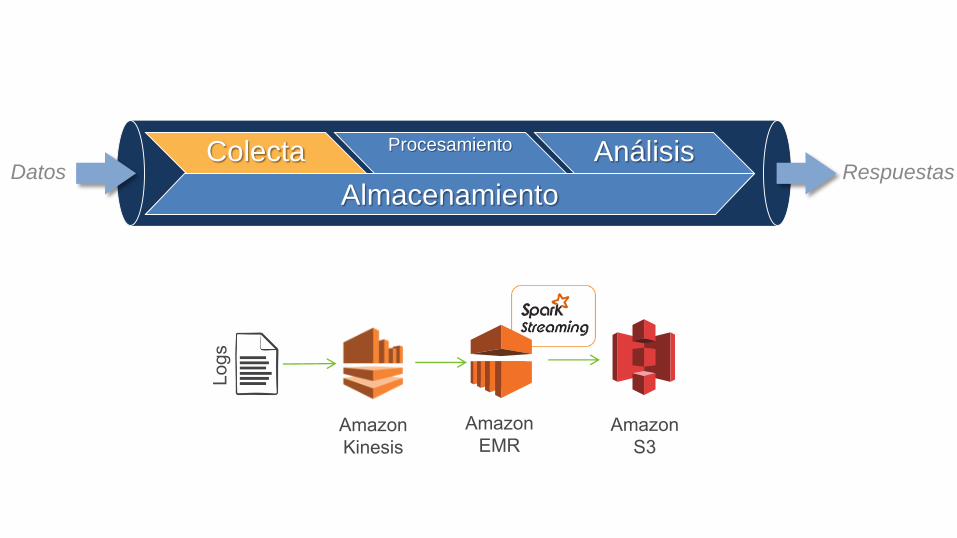
Colecta Procesamiento Análisis
AlmacenamientoDatos Respuestas

Colecta Procesamiento Análisis
AlmacenamientoDatos Respuestas

SQL
Colecta Procesamiento Análisis
AlmacenamientoDatos Respuestas

Configuración con la AWS CLI

Amazon Kinesis
Creamos un stream de Amazon Kinesis, con un único shard
para la data entrante:
aws kinesis create-stream \
--stream-name AccessLogStream \
--shard-count 1
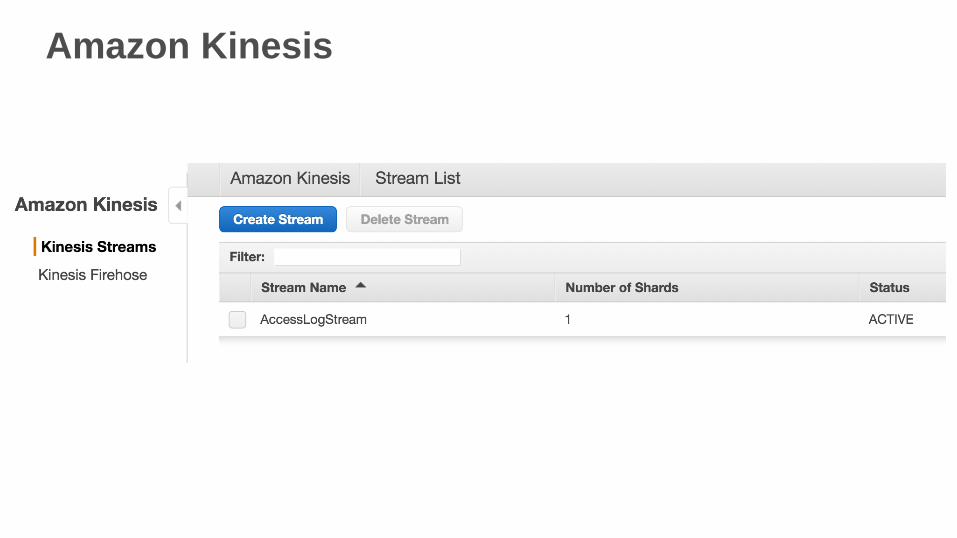
Amazon Kinesis

Amazon S3
YOUR-BUCKET-NAME

Amazon S3

Amazon EMR
Lanzamos un cluster de 3 nodos en Amazon EMR con Spark
y Hive:
m3.xlarge
YOUR-AWS-SSH-KEY

Amazon EMR

Amazon Redshift
\
CHOOSE-A-REDSHIFT-PASSWORD

Amazon Redshift

Su primera aplicación de Big Data en AWS
2. Procesamiento: Procesamos
los datos con Amazon EMR
usando Spark & Hive
STORE
3. Análisis: Analizamos los datos
en Amazon Redshift usando SQLSQL
1. Colecta: Envío de datos a
Amazon Kinesis usando Log4J

1. Colecta

Amazon Kinesis Log4J Appender
En una ventana de terminal separada en su máquina local, descargamos Log4J Appender:
Ahora bajamos y guardamos el ejemplo de archivo log de Apache:

Amazon Kinesis Log4J Appender
Creamos un archivo llamado AwsCredentials.propertiescon las credenciales de usuario IAM que tiene permisos para escribir en Amazon Kinesis:
accessKey=YOUR-IAM-ACCESS-KEYsecretKey=YOUR-SECRET-KEY
Luego iniciamos el Log4J Appender para Amazon Kinesis:

Formato de log de acceso

Spark
• Rápido motor de propósito
general para procesamiento de
datos en larga escala.
• Escriba aplicaciones
rápidamente en Java, Scala o
Python
• Combine SQL, streaming y
análisis complejas

Amazon Kinesis y Spark Streaming
Log4J
Appender
Amazon
KinesisAmazon
S3
Amazon
DynamoDBSpark-Streaming usa el
Kinesis Client Library
Amazon
EMR

Usando Spark Streaming en Amazon EMR
Usamos SSH para conectarnos al cluster:
-o TCPKeepAlive=yes -o ServerAliveInterval=30 \
YOUR-AWS-SSH-KEY YOUR-EMR-HOSTNAME
En el cluster, descargamos el Amazon Kinesis client para
Spark:

Eliminando el ruido de la consola:
Iniciando el Spark shell:
spark-shell --jars /usr/lib/spark/extras/lib/spark-streaming-kinesis-asl.jar,amazon-kinesis-client-1.6.0.jar --driver-java-options "-Dlog4j.configuration=file:///etc/spark/conf/log4j.properties"
Usando Spark Streaming en Amazon EMR

Usando Spark Streaming en Amazon EMR
/* import required libraries */

Usando Spark Streaming en Amazon EMR
/* Set up the variables as needed */
YOUR-REGION
YOUR-S3-BUCKET
/* Reconfigure the spark-shell */

Leyendo de Amazon Kinesis con Spark Streaming
/* Setup the KinesisClient */val kinesisClient = new AmazonKinesisClient(new DefaultAWSCredentialsProviderChain())kinesisClient.setEndpoint(endpointUrl)
/* Determine the number of shards from the stream */val numShards = kinesisClient.describeStream(streamName).getStreamDescription().getShards().size()
/* Create one worker per Kinesis shard */val ssc = new StreamingContext(sc, outputInterval)val kinesisStreams = (0 until numShards).map { i =>KinesisUtils.createStream(ssc, streamName,
endpointUrl,outputInterval,InitialPositionInStream.TRIM_HORIZON, StorageLevel.MEMORY_ONLY)}

Escribiendo en Amazon S3 con Spark Streaming
/* Merge the worker Dstreams and translate the byteArray to string */
/* Write each RDD to Amazon S3 */

Ver archivos de salida en Amazon S3
YOUR-S3-BUCKET
YOUR-S3-BUCKETyyyy mm dd HH

2. Procesamiento

Spark SQL
Módulo de Spark para trabajar con datos estructurados
usando SQL
Realizando queries Hive sobre los datos existentes

Usando Spark SQL en Amazon EMR
Use SSH para conectarse al cluster Amazon EMR:
YOUR-AWS-SSH-KEY YOUR-EMR-HOSTNAME
Inicie el shell Spark SQL:
spark-sql --driver-java-options "-Dlog4j.configuration=file:///etc/spark/conf/log4j.properties"

Creación de una tabla que apunta a su bucket Amazon
S3
CREATE EXTERNAL TABLE access_log_raw(host STRING, identity STRING, user STRING, request_time STRING, request STRING, status STRING,size STRING, referrer STRING, agent STRING
)PARTITIONED BY (year INT, month INT, day INT, hour INT, min INT)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'WITH SERDEPROPERTIES ("input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|\\[[^\\]]*\\]) ([^
\"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\"[^\"]*\") ([^ \"]*|\"[^\"]*\"))?") LOCATION 's3://YOUR-S3-BUCKET/access-log-raw';
msck repair table access_log_raw;

Realice Queries de datos con Spark SQL
-- return the first row in the stream
-- return count all items in the Stream
-- find the top 10 hosts

Preparación de datos para ser importados a
Amazon RedshiftVamos a transformar los datos que son entregados por la query antes
de escribirlos en la tabla Hive externa almacenada en Amazon S3
Funciones Hive definidas por el usuario (UDF) en uso para las
transformaciones de texto:
from_unixtime, unix_timestamp and hour
El valor ”hour” es importante: esto es usado para separar y organizar
los archivos de salida antes de escribirlos en Amazon S3. Esta
separación va a permitirnos más adelante cargar datos a Amazon
Redshift más eficientemente usando el comando paralelo ”COPY”.

Creación de una tabla externa en Amazon S3
YOUR-S3-BUCKET

Configuración de particiones y compresión
-- setup Hive's "dynamic partitioning"
-- this will split output files when writing to Amazon S3
-- compress output files on Amazon S3 using Gzip

Escribir los resultados en Amazon S3
-- convert the Apache log timestamp to a UNIX timestamp
-- split files in Amazon S3 by the hour in the log lines
INSERT OVERWRITE TABLE access_log_processed PARTITION (hour)
SELECT
from_unixtime(unix_timestamp(request_time,
'[dd/MMM/yyyy:HH:mm:ss Z]')),
host,
request,
status,
referrer,
agent,
hour(from_unixtime(unix_timestamp(request_time,
'[dd/MMM/yyyy:HH:mm:ss Z]'))) as hour
FROM access_log_raw;

Ver los archivos de salida en Amazon S3
Listar todos los prefijos de las particiones:
YOUR-S3-BUCKET
Listar una partición de los archivos de salida:
YOUR-S3-BUCKET

3. Analizar

Connect to Amazon Redshift
# using the PostgreSQL CLI
YOUR-REDSHIFT-ENDPOINT
Or use any JDBC or ODBC SQL client with the PostgreSQL
8.x drivers or native Amazon Redshift support
• Aginity Workbench for Amazon Redshift
• SQL Workbench/J

Crear una tabla en Amazon Redshift para poner los
datos

Cargar los datos a Amazon Redshift
“COPY” command loads files in parallel
COPY accesslogs
FROM 's3://YOUR-S3-BUCKET/access-log-processed'
CREDENTIALS
'aws_access_key_id=YOUR-IAM-ACCESS_KEY;aws_secret_access_key=YOUR-IAM-SECRET-KEY'
DELIMITER '\t' IGNOREHEADER 0
MAXERROR 0
GZIP;

Queries de prueba en Amazon Redshift
-- find distribution of status codes over days
-- find the 404 status codes
-- show all requests for status as PAGE NOT FOUND
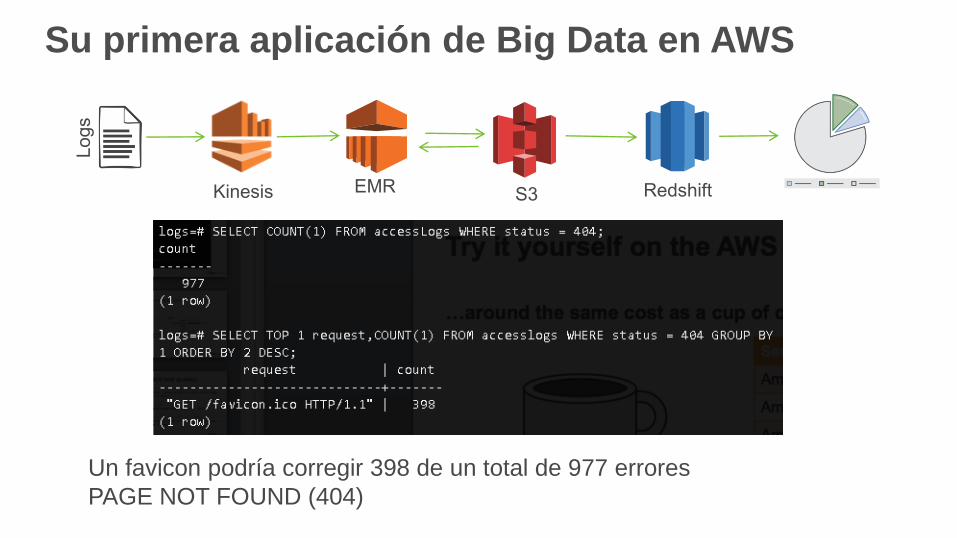
Su primera aplicación de Big Data en AWS
Un favicon podría corregir 398 de un total de 977 errores
PAGE NOT FOUND (404)

…cerca del costo de una taza de buen café
Inténtelo usted mismo en la nube de AWS…
Service Est. Cost*
Amazon Kinesis $1.00
Amazon S3 (free tier) $0
Amazon EMR $0.44
Amazon Redshift $1.00
Est. Total $2.44
*Estimated costs assumes: use of free tier where available, lower cost instances, dataset no bigger than 10MB and instances running
for less than 4 hours. Costs may vary depending on options selected, size of dataset, and usage.
$3.50

Aprenda sobre AWS big data con
nuestros expertos
blogs.aws.amazon.com/bigdata

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Q&A
