csc 352 performance tuning saumya debray dept. of computer science the university of arizona, tucson...
TRANSCRIPT

CSc 352Performance Tuning
Saumya DebrayDept. of Computer Science
The University of Arizona, [email protected]

Background
• Performance tuning modifying software to make it more efficient– often the performance metric is execution speed– other metrics also possible, e.g., memory footprint,
response time, energy efficiency
• How to get performance improvements– “system tweaking” (e.g., compiler optimizations) can get
some improvement; typically this is relatively small– most large improvements are algorithmic in nature
needs active and focused human intervention requires data to identify where to focus efforts
2

When to optimize?
1. Get the program working correctly– calculating incorrect results quickly isn’t useful– “premature optimization is the root of all evil” – Knuth (?)
2. Determine whether performance is adequate– Optimization unnecessary for many programs
3. Figure out what code changes are necessary to improve performance
3
be cognizant of the possibility that performance tuning may be necessary later on ►design and write the program with this in mind

Compiler optimizations
• Invoked using compiler options, e.g., “gcc –O2”– usually several different levels supported (gcc: -O0 … -O3)– may also allow fine-grained control over code optimization
• gcc supports ~200 optimization-related command-line options
• They address machine-level inefficiencies, not algorithm-level inefficiencies– e.g., gcc optimizations improve hardware register usage…– … but not sequential search over a long linked list
• Significant performance improvements usually need human intervention
4
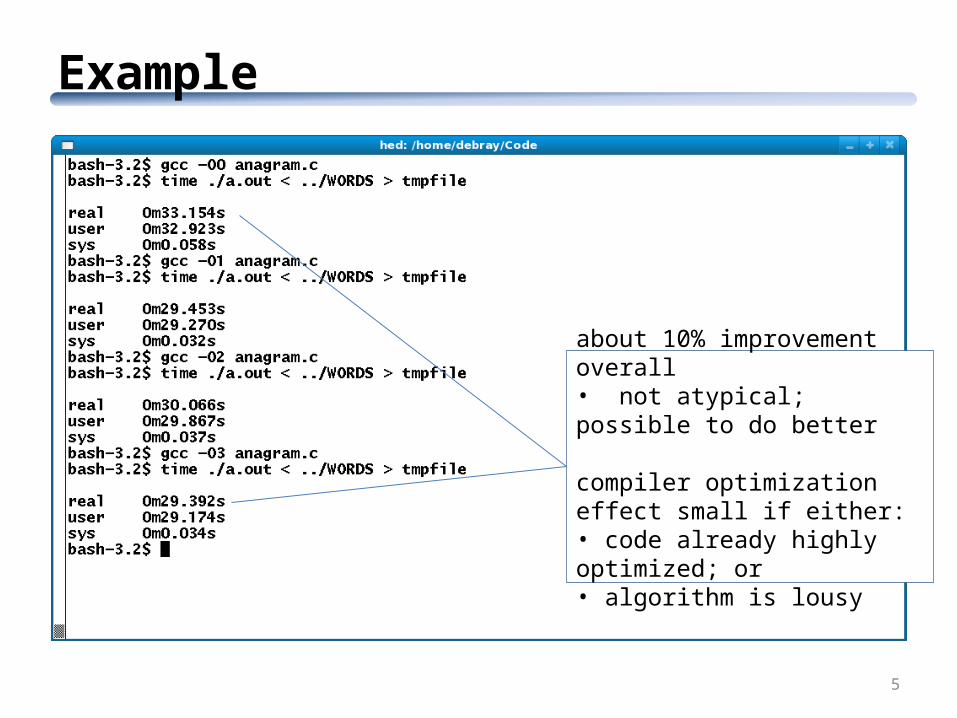
Example
5
about 10% improvement overall• not atypical; possible to do better
compiler optimization effect small if either:• code already highly optimized; or• algorithm is lousy
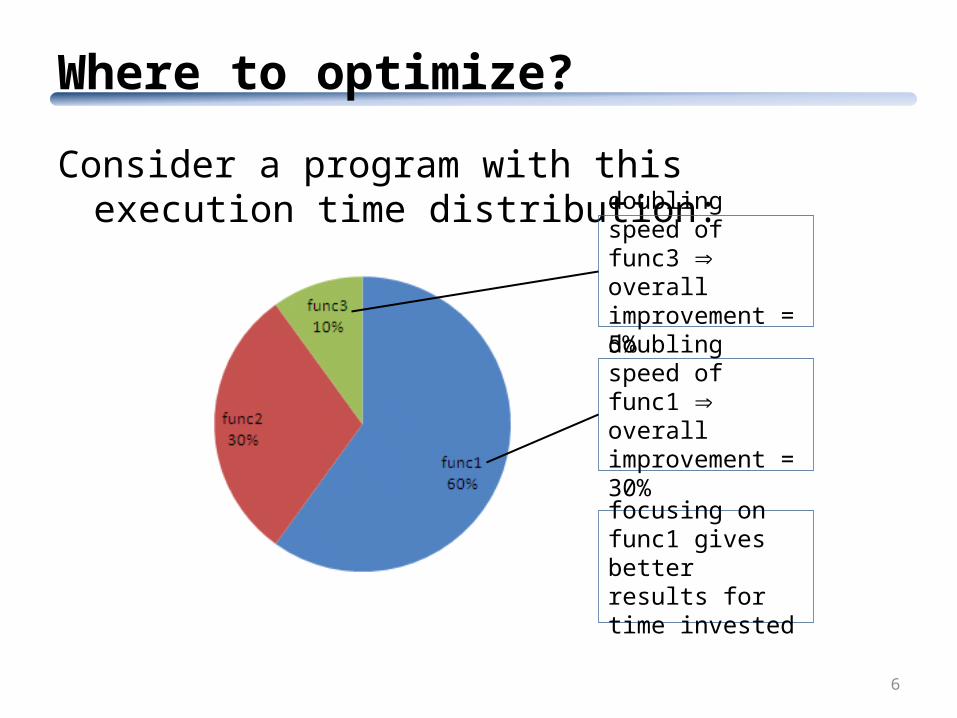
Where to optimize?
Consider a program with this execution time distribution:
6
doubling speed of func3 overall improvement = 5%
doubling speed of func1 overall improvement = 30%
focusing on func1 gives better results for time invested

Profiling tools
• These are tools that:– monitor the program’s execution at runtime– give data on how often routines are called, where the
program spends its time– provide guidance on where to focus one’s efforts
• Many different tools available, we’ll focus on two: – gprof: connected to gcc– kcachegrind: connected to valgrind
7

Using gprof
• Compile using “gcc –pg”– this adds some book-keeping code, so this will be a little
slower
• Run this executable, say a.out, on “representative” inputs– creates a data file “gmon.out”
• Run “gprof a.out”– extracts information from gmon.out– “flat profile” : time and #calls info per function– “call graph” : time and #calls per function broken down on
each place where the function is called
8

Using gprof: example
9
% time spent in each function
time accounted for by each function alone
no. of times called
ave. time per call spent in the function
ave. time per call spent in the function and its descendants
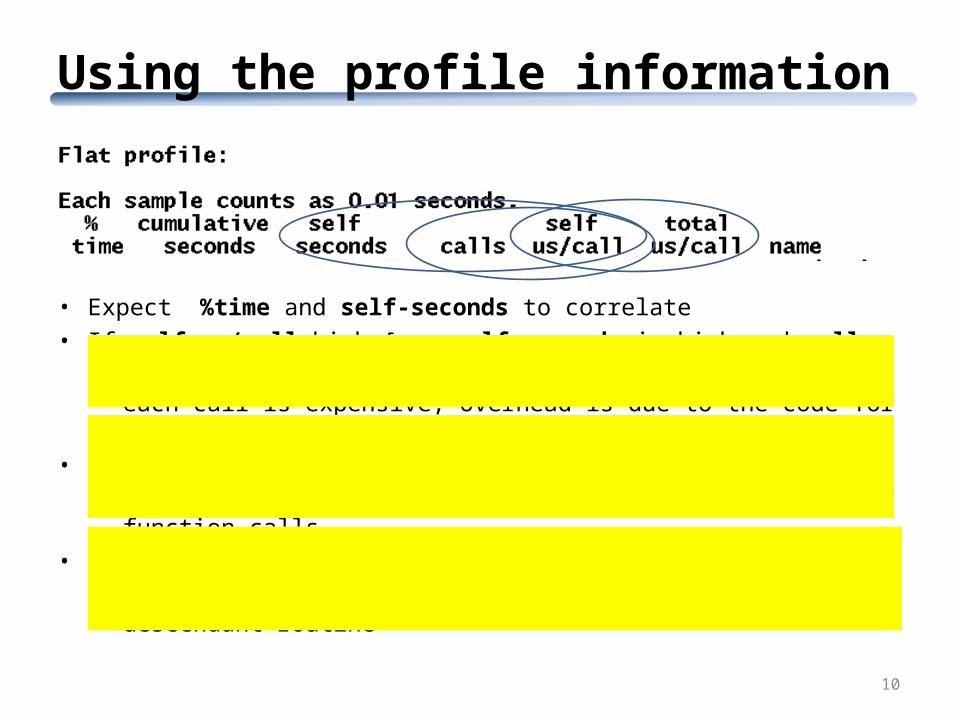
Using the profile information
10
• Expect %time and self-seconds to correlate• If self μs/call high [or: self-seconds is high and calls is low]:
– each call is expensive; overhead is due to the code for the function• if calls is high and self μs/call is low:
– each call is inexpensive; overhead mainly due to no. of function calls
• if self μs/call is low and total μs/call is high:– each call is expensive, but overhead due to some descendant
routine

Examining the possibilities 1
• Code for the function is expensive [self μs/call high]– need to get a better idea of where time is being spent in
the function body– may help to pull parts of the function body into separate
functions• allows more detailed profile info• can be “inlined back” after performance optimization
• Optimization approach:– reduce the cost of the common-case execution path
through the function
11

Examining the possibilities 2
• No. of calls to a function is the problem [calls is high but self μs/call is low]:– need to reduce the number/cost of calls– possible approaches:
• [best] avoid the call entirely whenever possible, e.g.:– use hashing to reduce the set of values to be considered; or– see if the call can be avoided in the common case (e.g., maybe
by maintaining asome extra information)• reduce the cost of making the call
– inline the body of the called function into the caller
12

Examining the possibilities
• Often, performance improvement will involve a tradeoff. E.g.:– transform linear to binary search:
• reduces no. of values considered in the search• requires sorting
– transform a simple linked list into a hash table• reduces the no. of values considered when searching• requires more memory (hash table), some computation (hash
values)
• Need to be aware of this tradeoff
13

Approaching performance optimization
• Different problems may require very different solutions
• Essential idea: – avoid unnecessary work whenever possible– prefer cheap operations to expensive ones
• Apply these ideas at all levels:– library routines used– language-level operations (e.g., function calls vs. macros)– higher-level algorithms
14

Optimization 1: Filtering
• Useful when:– we are searching a large collection of items, most of which
don’t match the search criteria– determining whether a particular item matches is
expensive– there is a (relatively) cheap check that is satisfied iff an
item does not match
• What we do:– use the cheap check to quickly disqualify items that won’t
match– effectiveness depends on how many items get disqualifed
15

Filtering
• Hashing– particularly useful for strings (but not restricted to them)– can give order-of-improvement performance
improvements– sensitive to quality of hash function
• Binary search– knowing that the data items are sorted allows us to quickly
exclude many of them that won’t match
16

Filters can apply to complex structures
• In a research project, we were searching through a large no. of code fragments looking for repetition:– code in compiler’s internal form (directed graph), not
source code– we used a 64-bit “fingerprint” for each code region
17
16 bitssize of region
48 bitstype and size of the first 8 code blocks in the region
(6 bits per block: 2 bits for type, 6 bits for no. of instrs)

Optimization 2: Buffering
• Useful when:– an expensive operation is being applied to a large no. of
items– the operation can also be applied collectively to a group of
items
• What we do:– collect the items into groups– apply the operation to the groups instead of individual
items
• Most often used for I/O operations
18

Optimization technique 3: precomputation
• Useful when:– a result can be computed once and reused many times– we can predict which results will be computed– we can look up a result cheaply
• What we do:– identify operations that get executed over and over– compute the result ahead of time and save it– use the saved result later in the program
19

Optimization 3: cacheing
• Useful when:– we repeatedly perform an expensive operation– there is a cheap way to check whether a computation has
been done before
• What we do:– keep a cache of computations and results; reuse a result if
it is already in the cache
• Difference from precomputation:– caches usually have a limited size– the cache may need to be emptied if it fills up
20

Optimization 4: Using cheaper operations
• Macros vs. functions– sometimes it may be cheaper to write a code fragment as
a macro than as a function– the macro does not incur the cost of function call/return– macro arguments may be evaluated multiple times
#define foo(x, y, z) …. x …. y … x … y … x… y … z … x … y …foo(e1, e2, e3) …. e1 …. e2 … e1 … e2 … e1 … e2 … e3 … e1 … e2 …
• Function inlining– conceptually similar to (but slightly different from) macros– replace a call to a function by a copy of the function body
• eliminates function call/return overhead
21
Optimization 4: Using cheaper operations
22

Hashing and Filtering
• Many computations involve looking through data to find those that have some property
for each data item X {if (X has property) { process X}
}
• This can be expensive if: no. of items is large; and /or checking for the property is expensive.
• Hashing and filtering can be used to reduce the cost of checking.
23
Total cost = no. of data items
x cost of checking each item

Filtering: Basic Idea
• Given:– a set of items S– some property P
• Find:– a function h such that1. h() is easy to compute;2. h(x) says something
useful about whether x has property P
24
h
Goal: (Cheaply) reduce no. of items to process

Filtering: Examples
• isPrime(n):– full test: check for
divisors between 1 and n – filter: n == 2 or n is odd
• filters out even numbers > 2
• equality of two strings s1 and s2
– full test: strcmp(s1, s2)
– filter: s1[0] == s2[0]
• isDivisibleBy3(n)
• s1 and s2 are anagrams
25
The filter depends on the property we’re testing!
Must be a necessary condition:(forall x)[filter (x) full_test(x)]

Hashing
• Conceptually related to filtering• Basic idea: Given a set of items S and a property P:
– use a hash function h() to divide up the set S into a number of “buckets”
• usually, h() maps S to integers (natural numbers)
– h(x) == h(y) means x and y are in the same bucket• if x and y fall in the same bucket, they may share the property P
(need to check)• if x and y are in different buckets, they definitely don’t share the
property P (no need to check)
26
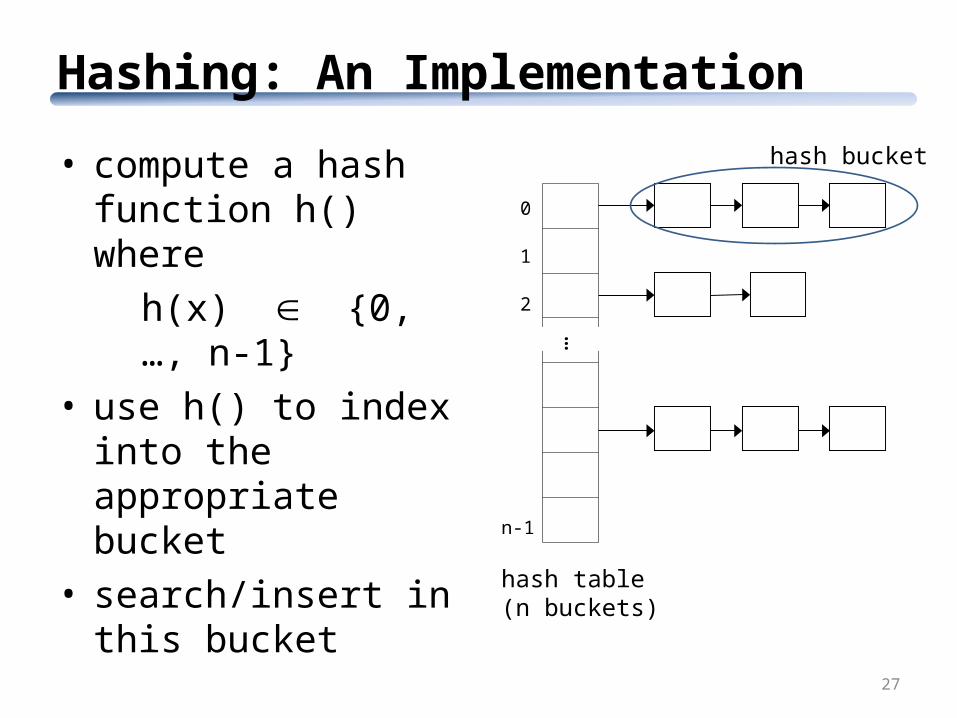
Hashing: An Implementation
27
hash table(n buckets)
hash bucket
…
• compute a hash function h() where
h(x) {0, …, n-1}• use h() to index into the
appropriate bucket• search/insert in this
bucket
0
1
2
n-1

Performance Tuning: Summary
• Big improvements come from algorithmic changes– but don’t ignore code-level issues (e.g., cheaper
operations)
• Use profiling to understand performance behavior– where to focus efforts– reasons for performance overheads
• Figure out how to transform the program based on nature of overheads
• Good design, modularization essential
28