csc 461/561 csc 461/561 multimedia systems part b: 1. lossless compression
Post on 19-Dec-2015
221 views
TRANSCRIPT

CSc 461/561
CSc 461/561Multimedia Systems Part B: 1. Lossless Compression

CSc 461/561
Summary
(1) Information
(2) Types of compression
(3) Lossless compression algorithms(a) Shannon-Fano Algorithm
(b) Huffman coding
(c) Run-length coding
(d) LZW compression
(e) Arithmetic Coding
(4) Example: Lossless image compression

CSc 461/561
1. Information (1)
Information is decided by three parts:• The source
• The receiver
• The delivery channel
We need a way to measure information:
• Entropy: a measure of uncertainty; min bits– alphabet set {s1, s2, …, sn}
– probability {p1, p2, …, pn}
– entropy: - p1 log2 p1 - p2 log2 p2 - … - pn log2 pn

CSc 461/561
1. Entropy examples (2)
• Alphabet set {0, 1}
• Probability: {p, 1-p}
• Entropy: H = - p log2 p - (1-p) log2 (1-p)
– when p=0, H=0– when p=1, H=0
– when p=1/2, Hmax=1• 1 bit is enough!
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.2
0.4
0.6
0.8
1
p
Ent
ropy

CSc 461/561
2. Types of compression (1)
• Lossless compression: no information loss
• Lossy compression: otherwise

CSc 461/561
2. Compression Ratio (2)
• Compression ratio– B0: # of bits to represent before compression
– B1: # of bits to represent after compression
– compression ratio = B0/B1

CSc 461/561
3.1 Shannon-Fano algorithm (1)
• Fewer bits for symbols appear more often
• “divide-and-conquer”– also known as “top-down” approach– split alphabet set into subsets of (roughly) equal
probabilities; do it recursively– similar to building a binary tree
CSc 461/561
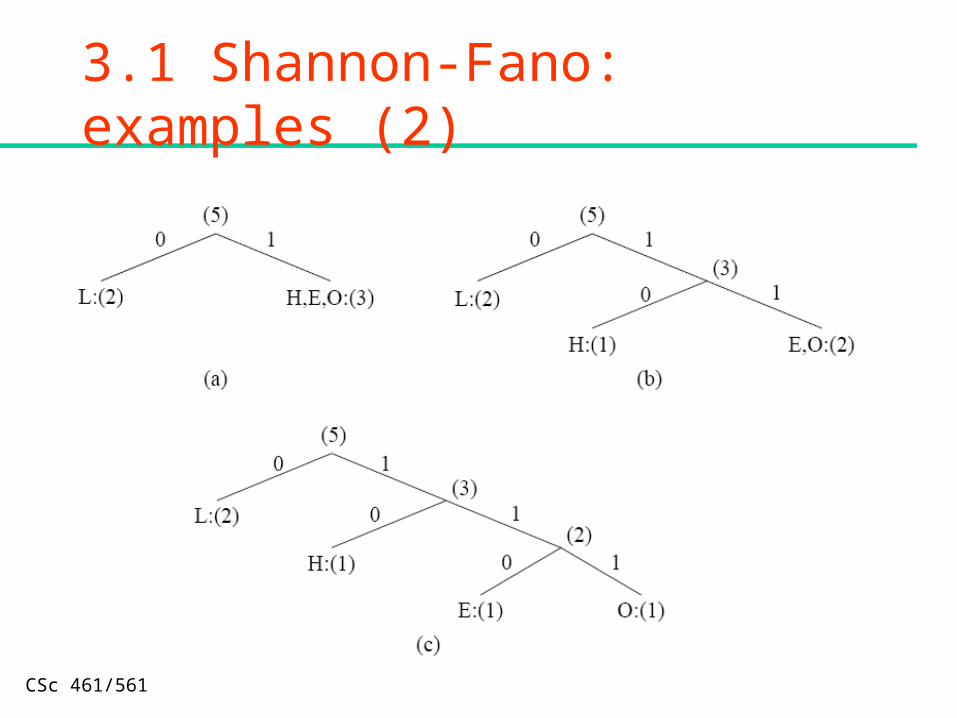
3.1 Shannon-Fano: examples (2)

CSc 461/561
3.1 Shannon-Fano: results (3)
• Prefix-free code– no code is a prefix of other codes– easy to decode

CSc 461/561
3.1 Shannon-Fano: more results (4)
• Encoding is not unique– roughly equal
Encoding 2
Encoding 1

CSc 461/561
3.2 Huffman coding (1)
• “Bottom-up” approach– also build a binary tree
• and know alphabet probability!
– start with two symbols of the least probability• s1: p1
• s2: p2
• s1 or s2: p1+p2
– do it recursively

CSc 461/561
3.2 Huffman coding: examples (2)
• Encoding not unique; prefix-free code
• Optimality: H(S) <= L < H(S)+1
a2 (0.4)
a1(0.2)
a3(0.2)
a4(0.1)
a5(0.1)
Sort
0.2
combine Sort
0.4
0.2
0.2
0.2
0.4
combine Sort
0.4
0.2
0.4
0.6
combine
0.6
0.4
Sort
1
combine
Assign code
0
1
1
00
01
1
000
001
01
1
000
01
0010
0011
1
000
01
0010
0011

CSc 461/561
3.3 Run-length coding
• Run: a string of the same symbol
• Example– input: AAABBCCCCCCCCCAA– output: A3B2C9A2– compression ratio = 16/8 = 2
• Good for some inputs (with long runs)– bad for others: ABCABC– how about to treat ABC as an alphabet?

CSc 461/561
3.4 LZW compression (1)
• Lempel-Ziv-Welch (LZ77, W84)– Dictionary-based compression– no a priori knowledge on alphabet probability– build the dictionary on-the-fly– used widely: e.g., Unix compress
• LZW coding– if a word does not appear in the dictionary, add it
– refer to the dictionary when the word appears again

CSc 461/561
3.4 LZW examples (2)
• Input– ABABBABCABABBA
• Output– 1 2 4 5 2 3 4 6 1

CSc 461/561
3.5 Arithmetic Coding (1)
• Arithmetic coding determines a model of the data -- basically a prediction of what patterns will be found in the symbols of the message. The more accurate this prediction is, the closer to optimality the output will be.
• Arithmetic coding treats the whole message as one unit.

CSc 461/561
3.5 Arithmetic Coding (2)

CSc 461/561
3.5 Arithmetic Coding (3)

CSc 461/561
3.5 Arithmetic Coding (4)

CSc 461/561
3.5 Arithmetic Coding (5)

CSc 461/561
4. Lossless Image Compression (1)

CSc 461/561
4. Lossless Image Compression (2)

CSc 461/561
4. Lossless JPEG
NNeighboring Pixels for Predictors in Lossless JPEG
NeighPredictors for Lossless JPEG