data intelligence for all distributed - spark summit · pdf filedistributed dataframe on...
TRANSCRIPT

Distributed DataFrame on Spark: Simplifying Big Data For The Rest Of UsChristopher Nguyen, PhD Co-Founder & CEO
DATA INTELLIGENCE FOR ALL

1. Challenges & Motivation
2. DDF Overview
3. DDF Design & Architecture
4. Demo
Agenda

• Former Engineering Director of Google Apps (Google Founders’ Award)
• Former Professor and Co-Founder of the Computer Engineering program at HKUST
• PhD Stanford, BS U.C. Berkeley Summa cum Laude
• Extensive experience building technology companies that solve enterprise challenges
Christopher Nguyen, PhD Adatao Inc.
Co-Founder & CEO
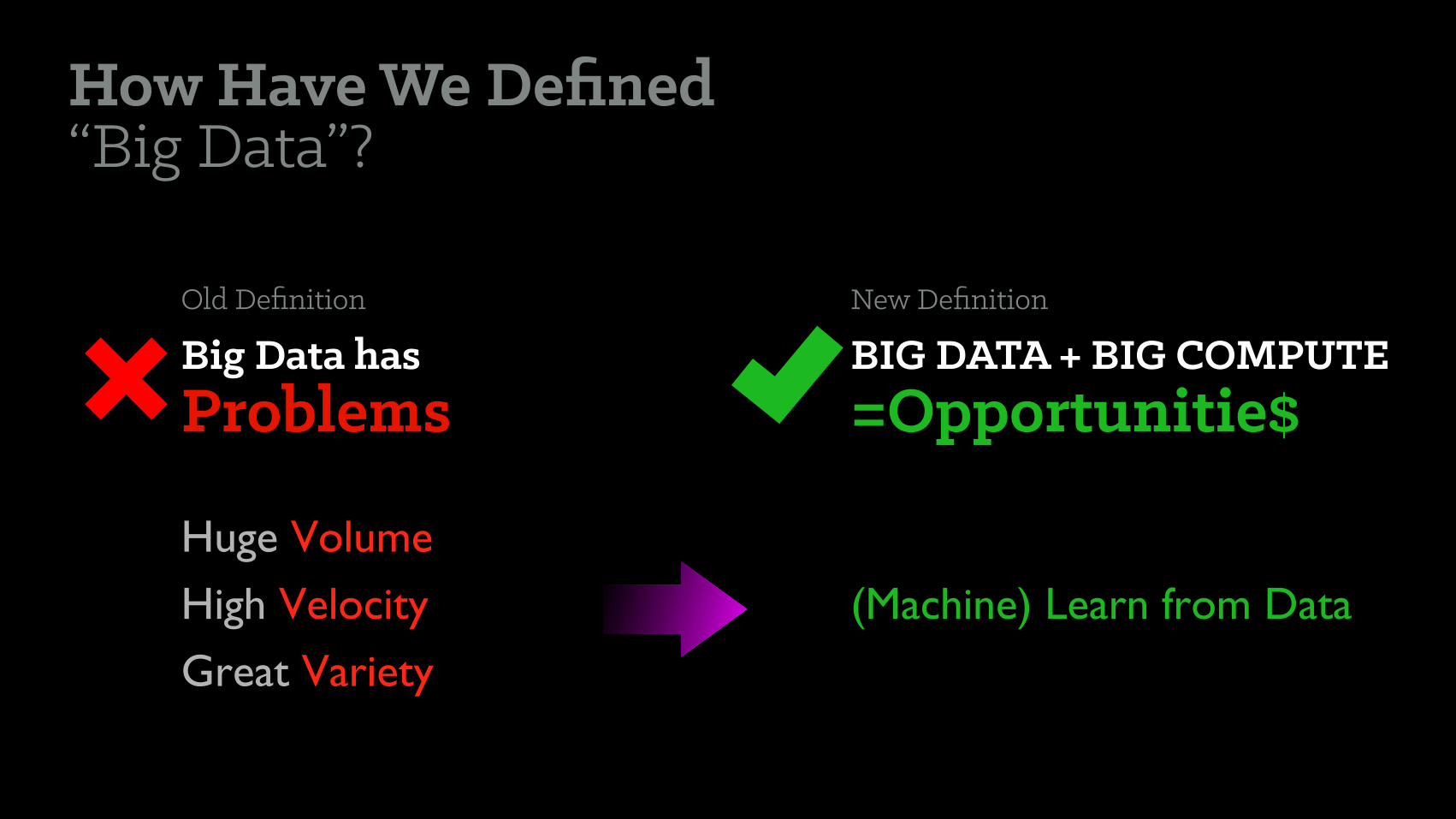
How Have We Defined “Big Data”?
Huge Volume
High Velocity
Great Variety
Big Data has Problems
BIG DATA + BIG COMPUTE =Opportunitie$
(Machine) Learn from Data
Old Definition New Definition
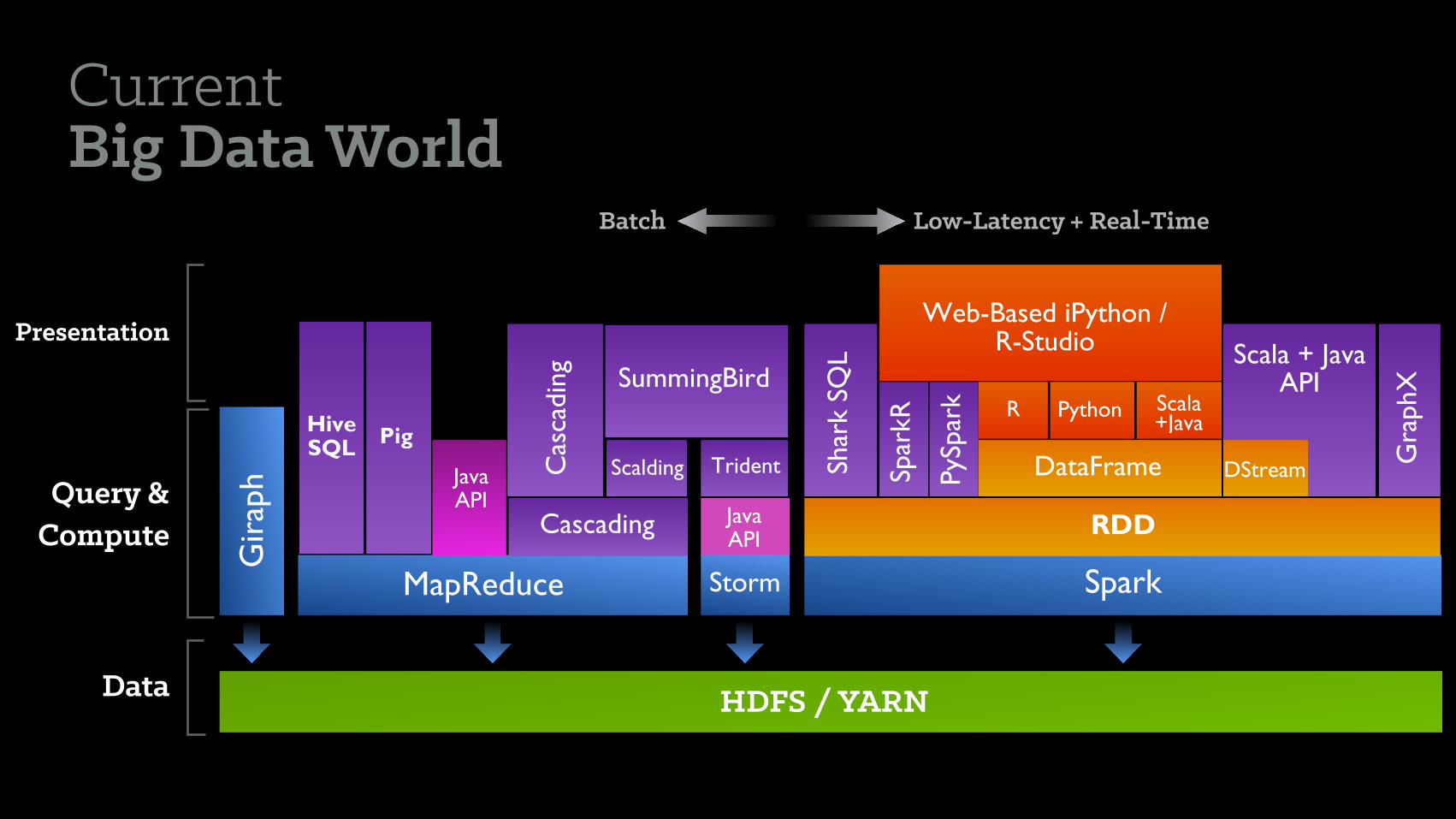
Data
Query & Compute
Presentation
HDFS / YARN
Scala + Java API
DStream
MapReduce Spark
Java API
RDD
Gir
aph
Hive SQL
Pig
CascadingC
asca
din
g
Scalding
Java API
Storm
Trident
SummingBird
DataFrameShar
k S
QL
R Python Scala+Java
Web-Based iPython / R-Studio
Gra
phX
Low-Latency + Real-TimeBatch
Spar
kR
PyS
par
k
Current Big Data World

CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT 'IP Address of the User', country STRING COMMENT 'country of origination') COMMENT 'This is the staging page view table' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054' STORED AS TEXTFILE LOCATION '<hdfs_location>';
INSERT OVERWRITE TABLE page_view PARTITION(dt='2008-06-08', country='US') SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url, null, null, pvs.ip WHERE pvs.country = ‘US’;!public static DistributedRowMatrix runJob(Path markovPath, Vector diag, Path outputPath, Path tmpPath) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(markovPath.toUri(), conf); markovPath = fs.makeQualified(markovPath); outputPath = fs.makeQualified(outputPath); Path vectorOutputPath = new Path(outputPath.getParent(), "vector"); VectorCache.save(new IntWritable(Keys.DIAGONAL_CACHE_INDEX), diag, vectorOutputPath, conf); ! // set up the job itself Job job = new Job(conf, "VectorMatrixMultiplication"); job.setInputFormatClass(SequenceFileInputFormat.class); job.setOutputKeyClass(IntWritable.class);
- sample and copy data to local - lrfit <- glm( using ~ + age + education) - Export model
- export model to XML - Deploy model using java
Maintenance is
too painful!

I have a dream…

In the Ideal World…data = load housePrice
data dropNA
data transform (duration = now - begin)
data train glm(price, bedrooms)
It just works!!!

MAPREDUCE
RHADOOP MONOIDSMONADSSparkR
PythonPySpark
Java
HIVE
HBASE
Make Big-Data API simple & accessible
MAPREDUCE
RHADOOP MONOIDSMONADSSparkR
PythonPySpark
Java
HIVE
HBASE
OR
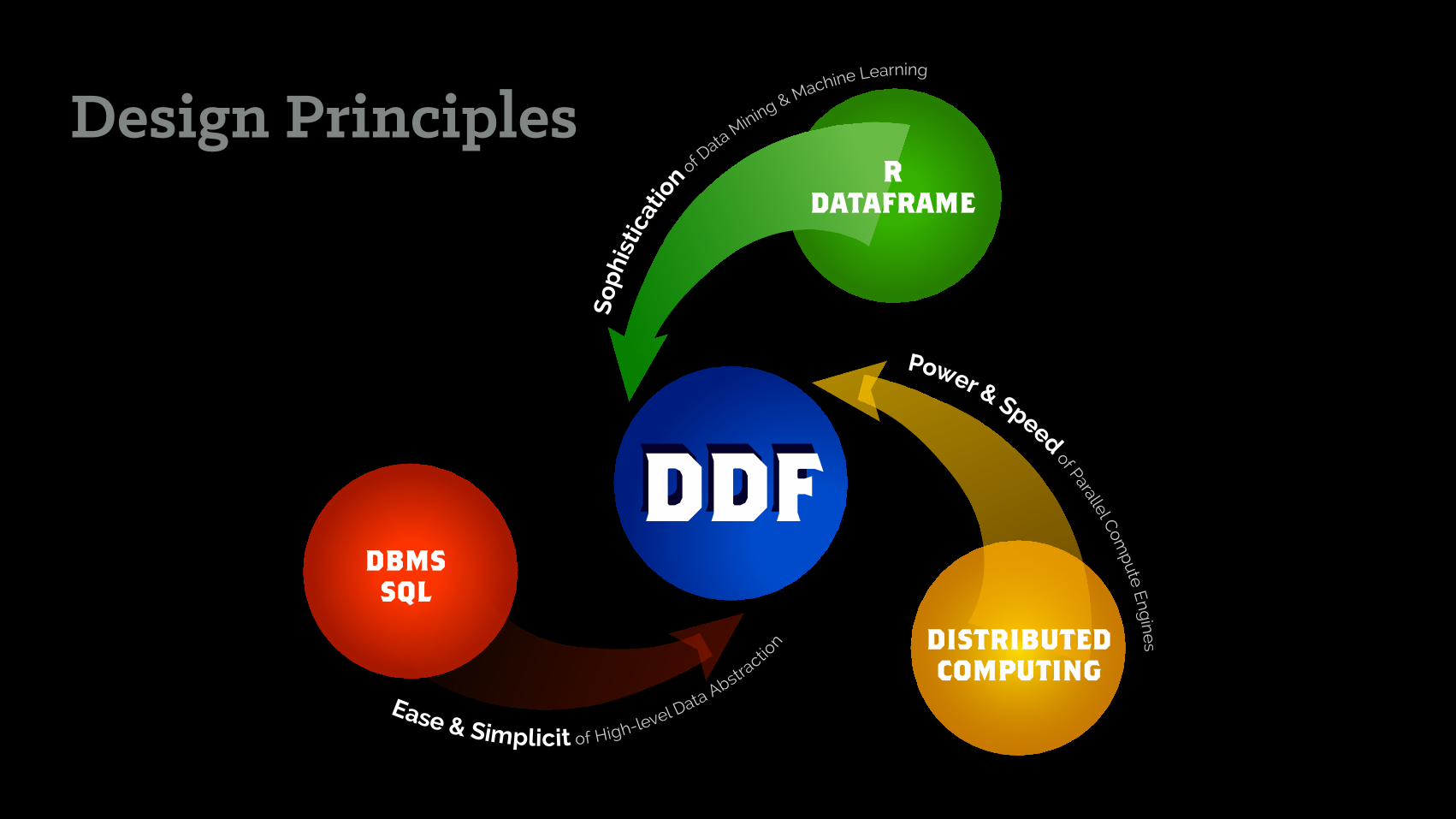
Design Principles

DDF is Simple
DDFManager manager = DDFManager.get(“spark”); DDF ddf = manager.sql2ddf(“select * from airline”);

It’s like table
ddf.Views.project(“origin, arrdelay”); ddf.groupBy(“dayofweek”, “avg(arrdelay)”); ddf.join(otherddf)
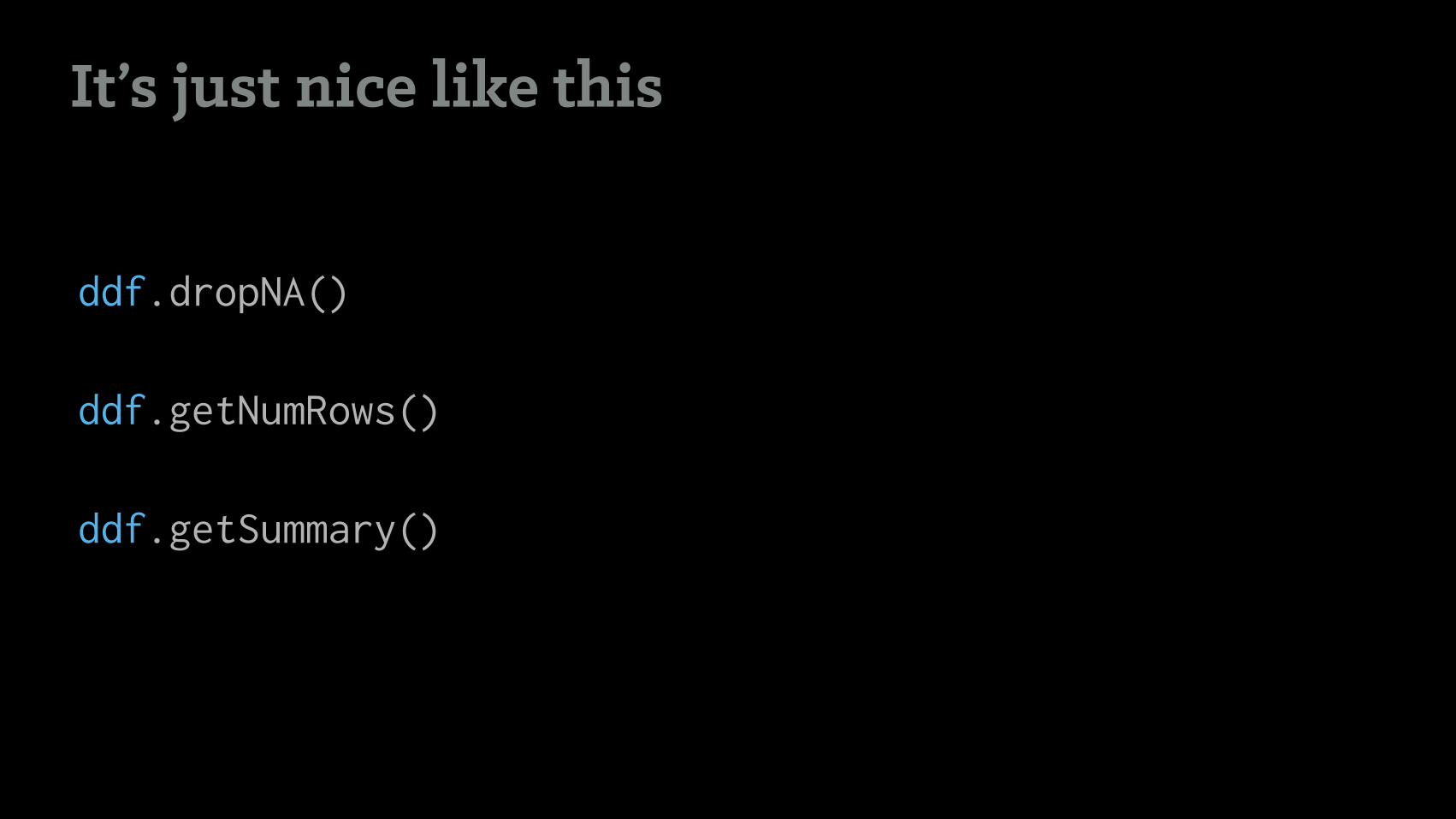
It’s just nice like this
ddf.dropNA() !
ddf.getNumRows() !
ddf.getSummary()
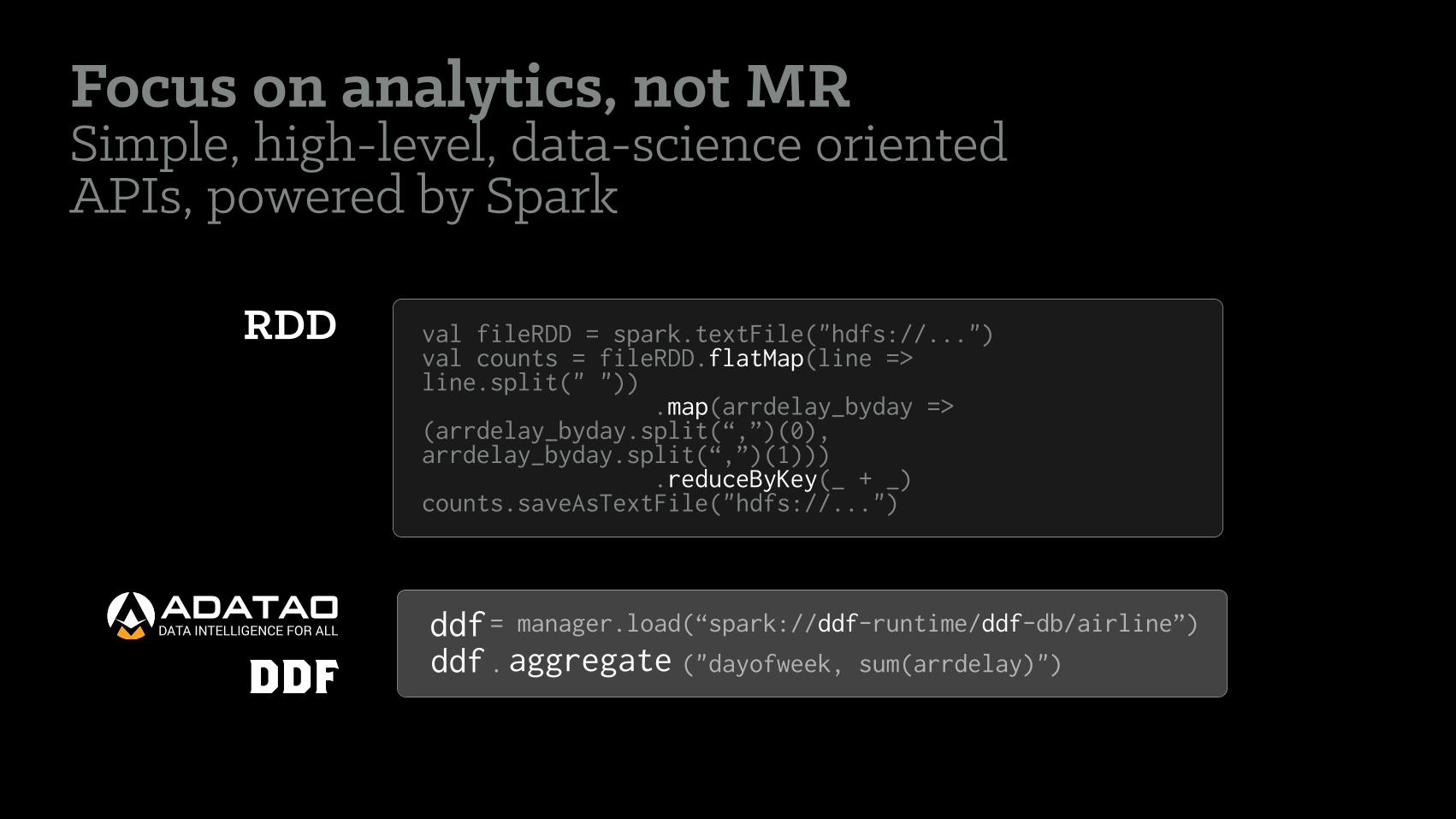
Focus on analytics, not MR Simple, high-level, data-science oriented APIs, powered by Spark
RDD val fileRDD = spark.textFile("hdfs://...") val counts = fileRDD.flatMap(line => line.split(" ")) .map(arrdelay_byday => (arrdelay_byday.split(“,”)(0), arrdelay_byday.split(“,”)(1))) .reduceByKey(_ + _) counts.saveAsTextFile("hdfs://...")
= manager.load(“spark://ddf-runtime/ddf-db/airline”)
. ("dayofweek, sum(arrdelay)")ddf
aggregateddf

Quickly Access to a Rich set of familiar ML idioms
Model Deployment
manager.loadModel(lm)
lm.predict(point)
Data Wrangling
ddf.setMutable(true)
ddf.dropNA()
ddf.transform(“speed=distance/duration”)
ddf.lm(0.1, 10)
ddf.roc(testddf)
Model Building & Validation

Seamless Integration with MLLib
//plug-in algorithm linearRegressionWithSGD = org.apache.spark.mllib.regression.LinearRegressionWithSGD !
//run algorithm ddf.ML.train("linearRegressionWithSGD", 10, 0.1, 0.1)

Easily Collaborate with Others
Can I see your Data?
DDF://com.adatao/airline

DDF on Multiple Languages

Data Scientist/Engineer
DDF Architecture
DDF
DDF Manager
ETL Handlers
Config Handler
Owns
Have access to
Statistics Handlers
ML Handlers
Representation Handlers

DemoDATA INTELLIGENCE FOR ALL
Cluster Configuration 8 nodes x 8 cores x 30G RAM
Data size 12GB/120 millions of rows

DDF offers
Table-like Abstraction on Top of Big Data
Native R Data.Frame Experience
Work with APIs Using Preferred LanguagesMulti Language Support (Java, Scala, R, Python)
Easily Test & Deploy New Components Pluggable Components by Design
Focus on Analytics, not MapReduceSimple, Data-Science Oriented APIs, Powered by Spark
Collaborate Seamlessly & Efficiently Mutable & Sharable
HDFS
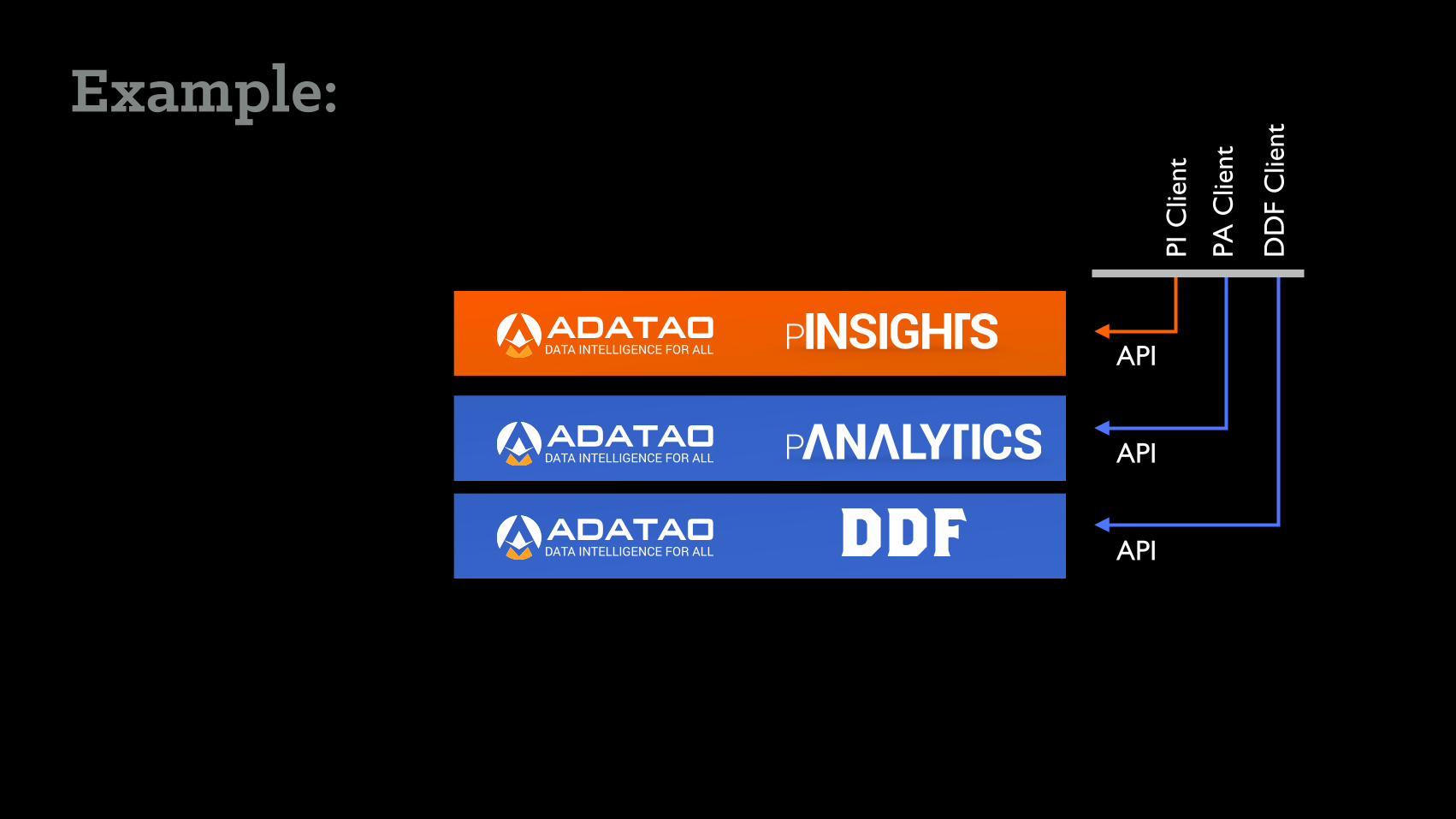
Web Browser R-Studio Python
Business Analyst Data Scientist Data Engineer
API
API
API
DD
F C
lient
PA
Clie
nt
PI C
lient
Example:

www.adatao.com
DATA INTELLIGENCE FOR ALL
To learn more about Adatao & DDF
contact us